
dify 源码分析(二)agent
dify 本地源码启动
Ollama 安装部署
dify 智能体实践
dify 源码分析(一)概述
dify 源码分析(二)agent
文章目录
1. Agent 系统架构
1.1. dify 架构
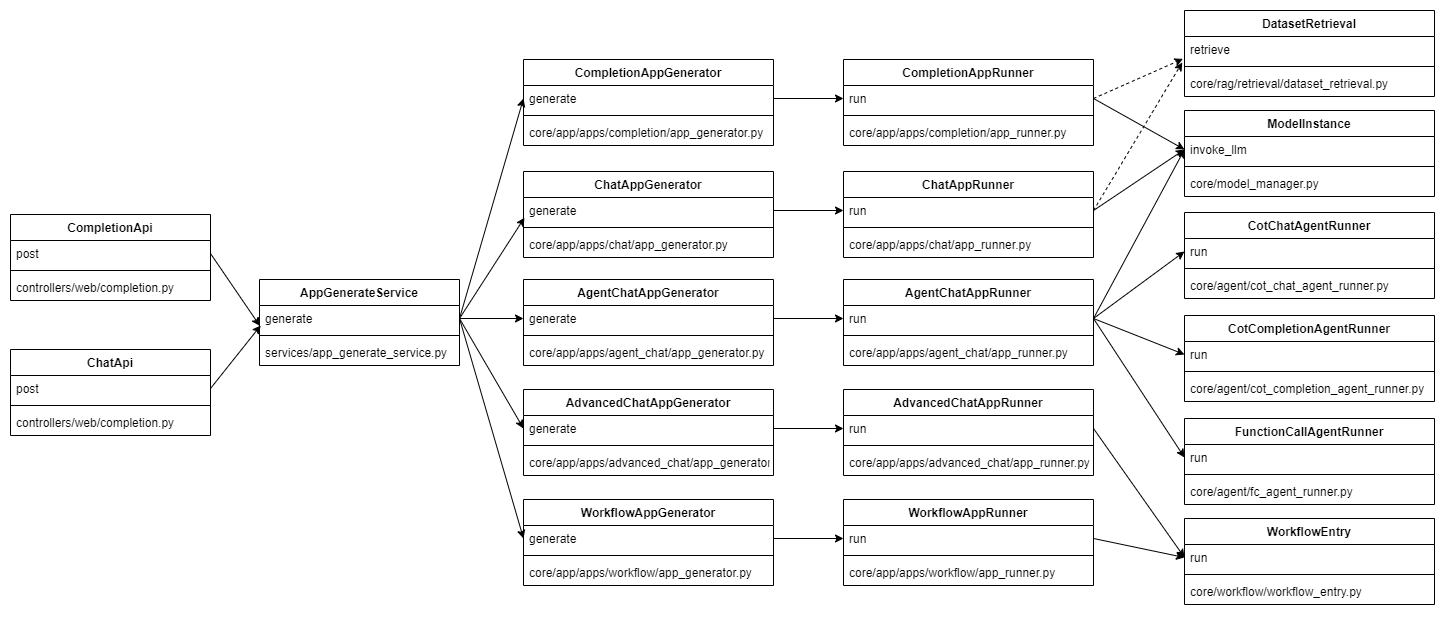
● 接口暴露实现:dify/api/controllers
● 接口逻辑细节基本都是调用封装了的各种 Service 来操作:dify/api/services
● 各个模块的实现细节:dify/api/core
● celery 的异步任务实现:dify/api/tasks
1.2. Agent 结构
1.2.1. 源码结构
api/core/agent
├── output_parser
│ └── cot_output_parser.py # Chain of Thought输出解析器的实现
├── prompt #
│ └── template.py # Agent提示模板的实现
├── strategy
│ ├── base.py
│ └── plugin.py # Agent提示模板的实现
├── __init__.py
├── base_agent_runner.py # Agent框架的基础实现
├── cot_agent_runner.py # Chain of Thought (CoT) Agent Runner的实现
├── cot_chat_agent_runner.py # CoT Chat Agent Runner的实现
├── cot_completion_agent_runner.py # CoT Completion Agent Runner的实现
├── fc_agent_runner.py # CoT Completion Agent Runner的实现
├── entities.py # 定义了Agent框架中的核心实体和数据结构
└── plugin_entities.py
1.2.1. 继承结构图
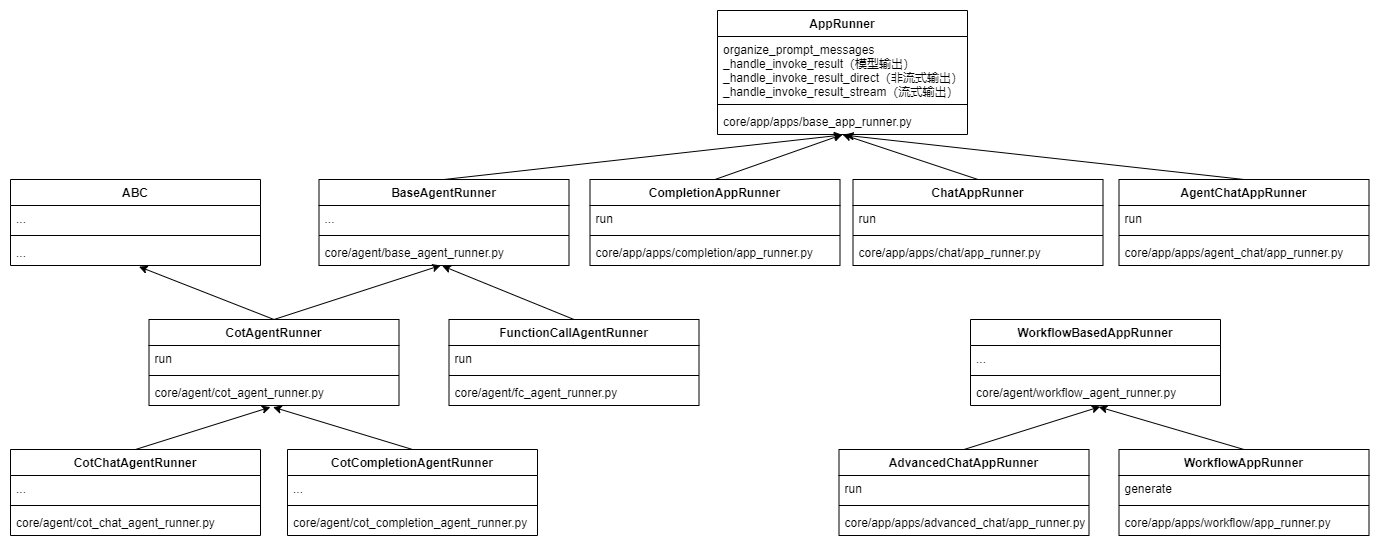
1.2.2. 类简介
系统主要包含以下几种 Agent Runner:
- BaseAgentRunner:所有 Agent Runner 的基类,提供了基础功能如:
工具初始化和转换
Agent 思考过程的创建和保存
历史消息的组织和处理
文件处理 - CoT Agent Runner:基于 Chain of Thought 的 Agent 实现
继承自 BaseAgentRunner
实现了反应式思考过程
支持多轮迭代工具调用
使用 CotAgentOutputParser 解析模型输出 - CoT Chat/Completion Agent Runner:针对不同场景的 CoT 实现
继承自 CotAgentRunner
分别处理聊天和完成任务两种场景 - Function Calling Agent Runner:基于函数调用的 Agent 实现
继承自 BaseAgentRunner
专门处理支持函数调用的模型
2. BaseAgentRunner
https://blog.csdn.net/orchidofocean/article/details/149393292?spm=1001.2014.3001.5502
2.1. 功能定位:代理(Agent)运行的「中枢协调器」
BaseAgentRunner 类,是代理聊天应用的核心运行器。它的核心职责是:协调代理(Agent)在处理用户请求时的全流程操作,包括:
- 整合历史对话与上下文
- 管理可用工具(如数据集检索工具、第三方 API 工具)
- 与大语言模型(LLM)交互,生成思考或工具调用指令
- 记录代理的「思考过程」(如调用了哪些工具、观察到什么结果)
- 处理模型特性(如流式工具调用、视觉能力)
简单说:当用户向 AI 代理提问时,BaseAgentRunner 就是背后「指挥代理思考、调用工具、生成回答」的总指挥。
2.2. 核心架构:5 大模块的协同设计
类的结构可拆解为 5 个核心模块,彼此配合完成代理的运行逻辑:
| 模块 | 作用 | 关键属性/方法 |
|---|---|---|
| 初始化模块 | 接收外部参数,初始化运行环境 | init 方法 |
| 工具管理模块 | 将工具转换为模型可识别的格式,管理工具实例 | _convert_tool_to_prompt_message_tool,_init_prompt_tools |
| 历史消息模块 | 整理历史对话与代理思考记录,构建模型输入的上下文 | organize_agent_history,organize_agent_user_prompt |
| 思考记录模块 | 创建和保存代理的思考过程(如调用工具的输入输出、LLM 使用量) | create_agent_thought,save_agent_thought |
| 模型交互模块 | 适配模型特性(如流式调用、视觉能力),准备模型输入 | 模型特性检查(stream_tool_call、files) |
2.3. 关键流程:用户提问后,代理如何「思考并行动」
假设用户提问:「帮我查下本季度产品销量,并总结趋势」,我们结合流程理解代码逻辑:
2.3.1. 初始化:接收参数,搭建运行环境(__init__ 方法)
当用户提问触发代理运行时,__init__ 会先完成初始化,核心操作包括:
- 接收核心参数
租户 ID(多租户隔离)、对话实例(conversation)、模型配置(model_config)、用户消息(message)等。 - 初始化工具与回调
初始化回调处理器(如 DifyAgentCallbackHandler),用于实时反馈代理状态(如 “正在检索数据”);
加载数据集检索工具(dataset_tools = DatasetRetrieverTool.get_dataset_tools()),用于查询「产品销量数据」。 - 记录思考计数
查询当前消息已有的代理思考次数(agent_thought_count),用于后续排序。 - 检查模型能力
通过 model_schema 判断模型是否支持「流式工具调用」(stream_tool_call)—— 若支持,可边调用工具边返回结果;
若模型支持「视觉能力」(ModelFeature.VISION),则接收用户上传的图片(files)。
2.3.2. 工具准备:让模型「知道如何调用工具」(工具管理模块)
代理要查销量,需调用「数据集检索工具」。但模型无法直接理解工具的参数格式,因此需要先将工具「翻译」为模型可识别的格式:
- 工具转模型格式:_convert_tool_to_prompt_message_tool 方法将工具(如 AgentToolEntity)转换为 PromptMessageTool 格式,包含:
例:数据集检索工具可能被转换为:
def _convert_tool_to_prompt_message_tool(self, tool: AgentToolEntity) -> tuple[PromptMessageTool, Tool]:
......
message_tool = PromptMessageTool(
name=tool.tool_name,
description=tool_entity.entity.description.llm,
parameters={
"type": "object",
"properties": {},
"required": [],
},
)
# 工具名称(name)、描述(description)—— 告诉模型 “这个工具能做什么”;
# 参数定义(parameters)—— 告诉模型 “调用时需要传哪些参数”(如查询的时间范围 start_date、end_date)。
# name="dataset_search",
# description="查询指定时间范围的产品销量数据",
# parameters={
# "properties": {
# "start_date": {
# "type": "string",
# "description": "开始日期,格式YYYY-MM-DD"
# },
# "end_date": {
# "type": "string",
# "description": "结束日期,格式YYYY-MM-DD"
# }
# },
# "required": [
# "start_date",
# "end_date"
# ]
# }
- 初始化工具集:_init_prompt_tools 方法整合所有可用工具(应用配置的工具 + 数据集工具),生成 tool_instances(工具实例,用于实际调用)和 prompt_messages_tools(模型可识别的工具列表)。
def _init_prompt_tools(self) -> tuple[dict[str, Tool], list[PromptMessageTool]]:
"""
Init tools
"""
tool_instances = {}
prompt_messages_tools = []
for tool in self.app_config.agent.tools or [] if self.app_config.agent else []:
try:
prompt_tool, tool_entity = self._convert_tool_to_prompt_message_tool(tool)
except Exception:
# api tool may be deleted
continue
# save tool entity
tool_instances[tool.tool_name] = tool_entity
# save prompt tool
prompt_messages_tools.append(prompt_tool)
# convert dataset tools into ModelRuntime Tool format
# 将数据集工具转换为ModelRuntime工具格式
for dataset_tool in self.dataset_tools:
prompt_tool = self._convert_dataset_retriever_tool_to_prompt_message_tool(dataset_tool)
# save prompt tool
prompt_messages_tools.append(prompt_tool)
# save tool entity
tool_instances[dataset_tool.entity.identity.name] = dataset_tool
return tool_instances, prompt_messages_tools
2.3.3. 上下文构建:让模型「了解历史」(历史消息模块)
模型需要结合历史对话生成回答,organize_agent_history 方法会整理两类历史信息:
-
用户与代理的对话记录:
从数据库查询当前对话的历史消息(messages),排除当前消息后,按时间顺序整理为用户消息(UserPromptMessage)和代理消息(AssistantPromptMessage)。 -
代理的历史思考过程:
若历史消息中包含代理的思考记录(MessageAgentThought),则将其拆分为「思考内容」+「工具调用记录」+「工具返回结果」,例如:
思考内容:agent_thought.thought(如 “我需要调用销量查询工具”)
工具调用:tool_calls(如调用 dataset_search 时的参数)
工具结果:tool_call_response(如工具返回的销量数据)
2.3.4. 思考与行动:代理如何「调用工具并记录过程」(思考记录模块)
当模型决定调用工具(如 dataset_search)时,需要记录这一过程,以便后续追溯或计费:
- 创建思考记录:
create_agent_thought 方法在数据库中创建一条 MessageAgentThought 记录,包含工具名称、输入参数、位置序号(position)等初始信息。 - 更新思考记录:
save_agent_thought 方法在工具调用完成后,更新记录:
补充工具返回结果(observation);
记录 LLM 的 token 使用量(llm_usage),用于计算成本;
序列化工具输入输出(如将字典转为 JSON 字符串),确保存储格式统一。
2.3.5. 模型交互:适配模型特性,准备最终输入
最后,BaseAgentRunner 会根据模型特性,调整输入格式:
若模型支持「流式工具调用」(stream_tool_call=True),则采用流式方式返回工具调用结果,提升用户体验;
若模型支持「视觉能力」,则将用户上传的图片(files)转换为模型可识别的格式(如 ImagePromptMessageContent),作为上下文输入。
3. CotAgentRunner(思维链)
https://blog.csdn.net/orchidofocean/article/details/149403070?spm=1001.2014.3001.5502
要理解 CotAgentRunner 类,需要从「思维链(Chain of Thought, CoT)」的核心逻辑出发。这类代理的特点是:通过多轮「思考→调用工具→观察结果→再思考」的循环,逐步解决复杂问题,而不是一次性生成答案。下面我们结合代码,从「功能定位→核心流程→关键模块→实战场景」四个层面深入剖析。
3.1. 功能定位:思维链代理的「迭代决策引擎」
CotAgentRunner 继承自 BaseAgentRunner,是基于思维链逻辑的代理运行器。它的核心使命是:让 AI 代理像人类一样「逐步思考」—— 面对复杂问题时,先分析需求,调用工具获取信息,根据结果调整策略,直到得出最终答案。
例如:当用户提问「分析近 3 个月公司产品销量 Top3 的地区,并预测下月趋势」时,普通代理可能直接回答(或失败),而 CotAgentRunner 会:
- 思考:“需要先查近 3 个月的销量数据(调用销售数据集工具)”;
- 调用工具:获取各地区销量数据;
- 观察结果:发现北京、上海、广州是 Top3;
- 再思考:“需要基于历史数据预测趋势(调用预测工具)”;
- 调用工具:获取预测结果;
- 最终整理:输出分析和预测。
这种「分步拆解」的能力,正是 CotAgentRunner 的核心价值。
3.2. 核心流程:多轮迭代的「思考 - 行动 - 观察」循环
run 方法是整个类的核心,它实现了思维链的迭代逻辑。我们以「用户查询季度销量趋势」为例,拆解完整流程:
3.2.1. 初始化与参数准备
class CotAgentRunner(BaseAgentRunner, ABC):
_is_first_iteration = True
_ignore_observation_providers = ["wenxin"]
_historic_prompt_messages: list[PromptMessage]
_agent_scratchpad: list[AgentScratchpadUnit]
_instruction: str
_query: str
_prompt_messages_tools: Sequence[PromptMessageTool]
def run(
self,
message: Message,
query: str,
inputs: Mapping[str, str],
) -> Generator:
"""
Run Cot agent application
"""
app_generate_entity = self.application_generate_entity
self._repack_app_generate_entity(app_generate_entity) # 整理输入参数
self._init_react_state(query) # 初始化思维链状态(如记录思考步骤)
trace_manager = app_generate_entity.trace_manager
# check model mode
# 处理模型 stop 词(确保模型输出在"Observation"处停止,避免输出混乱)
if "Observation" not in app_generate_entity.model_conf.stop:
if app_generate_entity.model_conf.provider not in self._ignore_observation_providers:
app_generate_entity.model_conf.stop.append("Observation")
app_config = self.app_config
assert app_config.agent
# init instruction
# 初始化指令(填充用户输入到提示模板)
inputs = inputs or {}
instruction = app_config.prompt_template.simple_prompt_template or ""
self._instruction = self._fill_in_inputs_from_external_data_tools(instruction, inputs)
iteration_step = 1
max_iteration_steps = min(app_config.agent.max_iteration, 99) + 1
# convert tools into ModelRuntime Tool format
# 初始化工具(同BaseAgentRunner,转换为模型可识别的格式)
tool_instances, prompt_messages_tools = self._init_prompt_tools()
self._prompt_messages_tools = prompt_messages_tools
关键操作:
为模型添加 Observation 作为停止词:确保模型在生成工具调用结果(观察)前停止,避免输出冗余内容。
初始化思维链状态:通过 _init_react_state 初始化 _agent_scratchpad(记录每步思考的列表),用于跟踪代理的「思考 - 行动 - 观察」过程。
3.2.2. 多轮迭代循环(核心逻辑)
代理通过循环迭代(最多 max_iteration_steps 次)完成思考过程,每次迭代包含「生成思考→决定是否调用工具→执行工具→记录结果」四步:
while function_call_state and iteration_step <= max_iteration_steps:
# continue to run until there is not any tool call
function_call_state = False
if iteration_step == max_iteration_steps:
# the last iteration, remove all tools
self._prompt_messages_tools = []
message_file_ids: list[str] = []
# 1. 创建本轮思考记录(数据库中保存)
agent_thought_id = self.create_agent_thought(
message_id=message.id, message="", tool_name="", tool_input="", messages_ids=message_file_ids
)
if iteration_step > 1:
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
# recalc llm max tokens
# 2. 调用LLM生成思考或工具调用指令
prompt_messages = self._organize_prompt_messages() # 构建包含历史的提示
self.recalc_llm_max_tokens(self.model_config, prompt_messages)
# invoke model
# 流式调用LLM
chunks = model_instance.invoke_llm(
prompt_messages=prompt_messages,
model_parameters=app_generate_entity.model_conf.parameters,
tools=[],
stop=app_generate_entity.model_conf.stop,
stream=True,
user=self.user_id,
callbacks=[],
)
usage_dict: dict[str, Optional[LLMUsage]] = {}
# 解析LLM输出为思维链结构
react_chunks = CotAgentOutputParser.handle_react_stream_output(chunks, usage_dict)
# 3. 解析LLM输出,提取思考和工具调用指令
# 记录本轮思考的细节(思考内容、行动指令等)
scratchpad = AgentScratchpadUnit(
agent_response="",
thought="",
action_str="",
observation="",
action=None,
)
# publish agent thought if it's first iteration
if iteration_step == 1:
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
for chunk in react_chunks:
if isinstance(chunk, AgentScratchpadUnit.Action): # 若输出是工具调用指令
action = chunk # 记录工具名称和参数
# detect action
assert scratchpad.agent_response is not None
scratchpad.agent_response += json.dumps(chunk.model_dump())
scratchpad.action_str = json.dumps(chunk.model_dump())
scratchpad.action = action
else: # 若输出是自然语言思考
assert scratchpad.agent_response is not None
scratchpad.agent_response += chunk # 记录思考内容
assert scratchpad.thought is not None
scratchpad.thought += chunk
yield LLMResultChunk(
model=self.model_config.model,
prompt_messages=prompt_messages,
system_fingerprint="",
delta=LLMResultChunkDelta(index=0, message=AssistantPromptMessage(content=chunk), usage=None),
) # 流式返回思考过程(用户可实时看到代理"思考")
assert scratchpad.thought is not None
scratchpad.thought = scratchpad.thought.strip() or "I am thinking about how to help you"
self._agent_scratchpad.append(scratchpad)
# get llm usage
if "usage" in usage_dict:
if usage_dict["usage"] is not None:
increase_usage(llm_usage, usage_dict["usage"])
else:
usage_dict["usage"] = LLMUsage.empty_usage()
self.save_agent_thought(
agent_thought_id=agent_thought_id,
tool_name=(scratchpad.action.action_name if scratchpad.action and not scratchpad.is_final() else ""),
tool_input={scratchpad.action.action_name: scratchpad.action.action_input} if scratchpad.action else {},
tool_invoke_meta={},
thought=scratchpad.thought or "",
observation="",
answer=scratchpad.agent_response or "",
messages_ids=[],
llm_usage=usage_dict["usage"],
)
# 4. 判断是否需要调用工具
if not scratchpad.is_final():
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
if not scratchpad.action:
# failed to extract action, return final answer directly
final_answer = ""
else:
if scratchpad.action.action_name.lower() == "final answer": # 若代理决定输出最终答案
# action is final answer, return final answer directly
# 提取答案
try:
if isinstance(scratchpad.action.action_input, dict):
final_answer = json.dumps(scratchpad.action.action_input, ensure_ascii=False)
elif isinstance(scratchpad.action.action_input, str):
final_answer = scratchpad.action.action_input
else:
final_answer = f"{scratchpad.action.action_input}"
except TypeError:
final_answer = f"{scratchpad.action.action_input}"
else: # 若代理决定调用工具
# 继续下一轮迭代
function_call_state = True
# action is tool call, invoke tool
# 调用工具并获取结果
tool_invoke_response, tool_invoke_meta = self._handle_invoke_action(
action=scratchpad.action,
tool_instances=tool_instances,
message_file_ids=message_file_ids,
trace_manager=trace_manager,
)
# 记录工具返回结果
scratchpad.observation = tool_invoke_response
scratchpad.agent_response = tool_invoke_response
self.save_agent_thought(
agent_thought_id=agent_thought_id,
tool_name=scratchpad.action.action_name,
tool_input={scratchpad.action.action_name: scratchpad.action.action_input},
thought=scratchpad.thought or "",
observation={scratchpad.action.action_name: tool_invoke_response},
tool_invoke_meta={scratchpad.action.action_name: tool_invoke_meta.to_dict()},
answer=scratchpad.agent_response,
messages_ids=message_file_ids,
llm_usage=usage_dict["usage"],
)
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
# update prompt tool message
for prompt_tool in self._prompt_messages_tools:
self.update_prompt_message_tool(tool_instances[prompt_tool.name], prompt_tool)
iteration_step += 1 # 迭代次数+1
核心逻辑解析:
- 多轮迭代的必要性:复杂问题无法一次解决(如需要多次调用工具),循环确保代理能「逐步逼近答案」。
- 流式输出:通过 yield 返回 LLMResultChunk,让用户实时看到代理的思考过程(如 “我现在需要查询销量数据…”),提升交互体验。
- 状态记录:AgentScratchpadUnit 类是核心状态容器,记录每轮的「思考内容(thought)→工具调用(action)→观察结果(observation)」,确保迭代过程可追溯。
3.2.3. 工具调用与结果处理
当代理决定调用工具(如「销量查询工具」)时,_handle_invoke_action 方法负责执行调用并返回结果:
def _handle_invoke_action(
self,
action: AgentScratchpadUnit.Action,
tool_instances: Mapping[str, Tool],
message_file_ids: list[str],
trace_manager: Optional[TraceQueueManager] = None,
) -> tuple[str, ToolInvokeMeta]:
"""
handle invoke action
:param action: action
:param tool_instances: tool instances
:param message_file_ids: message file ids
:param trace_manager: trace manager
:return: observation, meta
"""
# action is tool call, invoke tool
# 获取工具实例
tool_call_name = action.action_name
tool_call_args = action.action_input
tool_instance = tool_instances.get(tool_call_name)
if not tool_instance:
answer = f"there is not a tool named {tool_call_name}"
return answer, ToolInvokeMeta.error_instance(answer)
# 解析工具参数(如将JSON字符串转为字典)
if isinstance(tool_call_args, str):
try:
tool_call_args = json.loads(tool_call_args)
except json.JSONDecodeError:
pass
# invoke tool
# 调用工具
tool_invoke_response, message_files, tool_invoke_meta = ToolEngine.agent_invoke(
tool=tool_instance,
tool_parameters=tool_call_args,
user_id=self.user_id,
tenant_id=self.tenant_id,
message=self.message,
invoke_from=self.application_generate_entity.invoke_from,
agent_tool_callback=self.agent_callback,
trace_manager=trace_manager,
)
# publish files
# 发布工具返回的文件(如图表)
for message_file_id in message_files:
# publish message file
self.queue_manager.publish(
QueueMessageFileEvent(message_file_id=message_file_id), PublishFrom.APPLICATION_MANAGER
)
# add message file ids
message_file_ids.append(message_file_id)
return tool_invoke_response, tool_invoke_meta
关键操作:
- 工具参数兼容性处理:支持字符串或字典格式的参数,通过 json.loads 容错解析。
- 工具调用结果实时发布:若工具返回文件(如销量趋势图),通过队列管理器实时推送给用户。
3.2.4. 结束迭代与结果发布(回到 run())
当迭代达到最大次数或代理生成最终答案时,循环结束,发布最终结果:
def run(
self,
message: Message,
query: str,
inputs: Mapping[str, str],
) -> Generator:
......
# 输出最终答案
yield LLMResultChunk(
model=model_instance.model,
prompt_messages=prompt_messages,
delta=LLMResultChunkDelta(
index=0, message=AssistantPromptMessage(content=final_answer), usage=llm_usage["usage"]
),
system_fingerprint="",
)
# save agent thought
# 保存最后一轮思考记录
self.save_agent_thought(
agent_thought_id=agent_thought_id,
tool_name="",
tool_input={},
tool_invoke_meta={},
thought=final_answer,
observation={},
answer=final_answer,
messages_ids=[],
)
# publish end event
# 发布结束事件(通知前端对话完成)
self.queue_manager.publish(
QueueMessageEndEvent(
llm_result=LLMResult(
model=model_instance.model,
prompt_messages=prompt_messages,
message=AssistantPromptMessage(content=final_answer),
usage=llm_usage["usage"] or LLMUsage.empty_usage(),
system_fingerprint="",
)
),
PublishFrom.APPLICATION_MANAGER,
)
3.3. 关键模块:支撑思维链逻辑的 5 大核心组件
CotAgentRunner 的复杂逻辑依赖于多个模块的协同,以下是最关键的 5 个组件:
| 模块 / 类 | 作用 | 核心方法 / 属性 |
|---|---|---|
| 思维链解析器 | 将 LLM 的原始输出(字符串)解析为结构化的「思考 - 行动 - 观察」数据 | CotAgentOutputParser.handle_react_stream_output |
| 状态容器 | 记录每轮迭代的思考、工具调用和结果,是迭代的「记忆载体」 | AgentScratchpadUnit 类 |
| 工具调用引擎 | 执行工具调用,处理参数解析和结果返回 | ToolEngine.agent_invoke、_handle_invoke_action |
| 历史消息转换器 | 将历史对话转换为思维链格式,确保代理能基于历史继续思考 | _organize_historic_prompt_messages |
| 迭代控制器 | 管理迭代次数、判断是否终止循环(如达到最大步数或生成最终答案) | function_call_state 变量、max_iteration_steps |
3.4. 实战场景:一次完整的思维链交互示例
假设用户提问:「查询本季度(2024Q3)产品销量 Top3 的地区,并生成趋势图表」,我们跟踪 CotAgentRunner 的执行过程:
-
初始化:
接收用户 query,初始化 _agent_scratchpad(空列表)。
加载工具:「销量数据集检索工具」「图表生成工具」。
设置最大迭代次数(如 5 次),避免无限循环。 -
第 1 轮迭代:
生成思考:调用 LLM,输入包含用户问题和工具列表的提示,LLM 输出:“我需要先查询 2024Q3 各地区的销量数据,使用销量数据集检索工具。”
解析输出:CotAgentOutputParser 将上述内容解析为 AgentScratchpadUnit,其中 action 为 {“action_name”: “sales_dataset”, “action_input”: {“quarter”: “2024Q3”}}。
调用工具:_handle_invoke_action 调用「销量数据集检索工具」,返回结果:{“北京”: 1200, “上海”: 1000, “广州”: 800}。
记录状态:scratchpad.observation 保存工具返回结果,迭代次数变为 2。 -
第 2 轮迭代:
生成思考:LLM 基于历史(第 1 轮的思考和结果),输出:“已获取销量数据,Top3 为北京、上海、广州。需要生成趋势图表,使用图表生成工具。”
解析输出:action 为 {“action_name”: “chart_generator”, “action_input”: {“data”: {…}}}。
调用工具:调用「图表生成工具」,返回图表文件 ID(如 file_123)。
发布文件:通过 QueueMessageFileEvent 将图表推送给用户,用户此时可看到图表预览。 -
第 3 轮迭代:
生成思考:LLM 基于图表结果,输出:“趋势显示北京销量持续上升,上海稳定,广州略有下降。可以得出最终结论。”
解析输出:is_final() 为 True,提取最终答案:“2024Q3 销量 Top3 地区为北京(1200)、上海(1000)、广州(800)…(附趋势图表)”。 -
结束迭代:
输出最终答案,发布 QueueMessageEndEvent 通知对话完成,保存所有思考记录到数据库。
4. CotChatAgentRunner
https://blog.csdn.net/orchidofocean/article/details/149428878?spm=1001.2014.3001.5502
CotChatAgentRunner 类继承自 CotAgentRunner,是专门为聊天场景优化的思维链代理运行器。其核心职责是构建符合思维链范式的提示模板,将系统指令、用户问题、历史对话和工具信息整合为大语言模型可理解的格式。下面我们从「功能定位→核心方法→构建流程→技术细节」四个层面进行剖析。
4.1. 功能定位:聊天场景下的「提示工程师」
CotChatAgentRunner 的核心作用是将复杂的对话上下文转化为引导模型思考的提示信息。它解决了两个关键问题:
- 结构化提示构建
将系统指令、工具列表、历史对话等信息组织成特定格式(如 ReACT 范式),引导模型按思维链方式思考。 - 多模态支持
处理用户上传的文件(如图像),将其转化为模型可理解的格式(如文本描述)。
例如,当用户发送包含图片的问题(如「分析这张销售图表的趋势」)时,CotChatAgentRunner 会:
- 将图片转换为文本描述(如「一张柱状图,展示了 2024 年 1-6 月各地区销售额」);
- 结合系统指令(如「你是数据分析师,请使用工具分析图表数据」);
- 历史对话(如用户之前的问题);
- 可用工具(如「数据可视化工具」「趋势预测工具」);
- 构建完整的提示模板,发送给模型。
4.2. 核心方法:三大提示构建器
类中定义了三个核心方法,分别负责构建系统提示、用户查询和完整提示链:
4.2.1. _organize_system_prompt():构建系统指令
def _organize_system_prompt(self) -> SystemPromptMessage:
"""
Organize system prompt
"""
assert self.app_config.agent
assert self.app_config.agent.prompt
prompt_entity = self.app_config.agent.prompt
if not prompt_entity:
raise ValueError("Agent prompt configuration is not set")
first_prompt = prompt_entity.first_prompt
# 填充模板变量
system_prompt = (
first_prompt.replace("{{instruction}}", self._instruction)
.replace("{{tools}}", json.dumps(jsonable_encoder(self._prompt_messages_tools)))
.replace("{{tool_names}}", ", ".join([tool.name for tool in self._prompt_messages_tools]))
)
return SystemPromptMessage(content=system_prompt)
关键操作:
- 从配置中获取初始提示模板(如 first_prompt);
- 动态填充三个关键变量:
{{instruction}}:用户指令(如「分析销量趋势」);
{{tools}}:可用工具列表的 JSON 字符串(包含工具名称、描述、参数);
{{tool_names}}:工具名称的逗号分隔列表(如 sales_dataset, chart_generator)。
示例输出(简化版):
你是一位专业的数据分析师。可用工具包括:
[
{"name": "sales_dataset", "description": "查询销售数据集", ...},
{"name": "chart_generator", "description": "生成图表", ...}
]
请根据用户需求,合理使用工具解决问题。
4.2.2. _organize_user_query():处理用户输入(含多模态)
def _organize_user_query(self, query, prompt_messages: list[PromptMessage]) -> list[PromptMessage]:
"""
Organize user query
"""
if self.files: # 如果用户上传了文件(如图像)否则为纯文本输入
# get image detail config
# 获取图像细节配置(如高/中/低描述)
image_detail_config = (
self.application_generate_entity.file_upload_config.image_config.detail
if (
self.application_generate_entity.file_upload_config
and self.application_generate_entity.file_upload_config.image_config
)
else None
)
image_detail_config = image_detail_config or ImagePromptMessageContent.DETAIL.LOW
prompt_message_contents: list[PromptMessageContentUnionTypes] = []
# 将每个文件转换为模型可理解的格式
for file in self.files:
prompt_message_contents.append(
file_manager.to_prompt_message_content(
file,
image_detail_config=image_detail_config,
)
)
prompt_message_contents.append(TextPromptMessageContent(data=query))
prompt_messages.append(UserPromptMessage(content=prompt_message_contents))
else: # 纯文本输入
prompt_messages.append(UserPromptMessage(content=query))
return prompt_messages
关键操作:
- 处理多模态输入:将用户上传的文件(如图片)转换为 ImagePromptMessageContent 对象,包含图像描述;
- 图像细节配置:通过 image_detail_config 控制描述的详细程度(如「低」仅包含基本信息,「高」包含像素级细节)。
示例场景:
- 用户发送问题「分析这张图表」并上传图片 → 方法将图片转换为「一张包含 2024 年各季度销量数据的折线图」,与文本问题合并为多模态输入。
4.2.3. _organize_prompt_messages():整合所有提示组件
def _organize_prompt_messages(self) -> list[PromptMessage]:
"""
Organize
"""
# organize system prompt
# 1. 构建系统提示
system_message = self._organize_system_prompt()
# organize current assistant messages
# 2. 构建当前助手回复(基于历史思考步骤)
agent_scratchpad = self._agent_scratchpad
if not agent_scratchpad:
assistant_messages = []
else:
assistant_message = AssistantPromptMessage(content="")
assistant_message.content = "" # FIXME: type check tell mypy that assistant_message.content is str
for unit in agent_scratchpad:
if unit.is_final():
assert isinstance(assistant_message.content, str)
assistant_message.content += f"Final Answer: {unit.agent_response}"
else:
assert isinstance(assistant_message.content, str)
assistant_message.content += f"Thought: {unit.thought}\n\n"
if unit.action_str:
assistant_message.content += f"Action: {unit.action_str}\n\n"
if unit.observation:
assistant_message.content += f"Observation: {unit.observation}\n\n"
assistant_messages = [assistant_message]
# query messages
# 3. 构建用户查询
query_messages = self._organize_user_query(self._query, [])
# 4. 整合历史消息和当前消息
if assistant_messages:
# organize historic prompt messages
historic_messages = self._organize_historic_prompt_messages(
[system_message, *query_messages, *assistant_messages, UserPromptMessage(content="continue")]
)
messages = [
system_message,
*historic_messages,
*query_messages,
*assistant_messages,
UserPromptMessage(content="continue"),
]
else:
# organize historic prompt messages
historic_messages = self._organize_historic_prompt_messages([system_message, *query_messages])
messages = [system_message, *historic_messages, *query_messages]
# join all messages
return messages
关键操作:
- 思维链格式化:将历史思考步骤(_agent_scratchpad)转换为 ReACT 格式的文本(如 Thought: … Action: … Observation: …);
- 历史对话整合:通过 _organize_historic_prompt_messages 方法,将历史消息转换为模型可理解的格式,并添加 continue 标记,引导模型继续思考;
- 多轮对话支持:在多轮迭代中,动态更新 assistant_messages,保留完整的思考链条。
4.3. 构建流程:从用户输入到模型提示
以用户提问「分析近 3 个月销量趋势」为例,看 CotChatAgentRunner 如何构建提示:
4.3.1. 系统提示(简化版)
你是一位专业的数据分析师。可用工具包括:[“sales_dataset”, “chart_generator”]。
请按以下格式回答:
Thought: 我需要...
Action: {"name": "工具名", "parameters": {"param1": "value"}}
Observation: 工具返回的结果
...(重复思考-行动-观察)
Final Answer: 最终答案
4.3.2. 用户查询
User: 分析近3个月销量趋势
4.3.3. 第一轮思考(假设模型输出)
Assistant:
Thought: 我需要先获取近3个月的销量数据,使用sales_dataset工具。
Action: {"name": "sales_dataset", "parameters": {"time_range": "近3个月"}}
4.3.4. 工具调用与观察
系统调用 sales_dataset 工具,获取数据;
将结果作为 Observation 添加到思考链:
Observation: 近3个月销量数据:1月1000,2月1200,3月1300,呈上升趋势。
4.3.5. 第二轮思考(模型基于观察继续思考)
Thought: 已获取数据,销量呈上升趋势。需要生成图表可视化,使用chart_generator工具。
Action: {"name": "chart_generator", "parameters": {"data": [...]}}
4.3.6. 最终答案
Final Answer: 近3个月销量呈上升趋势(1月1000→2月1200→3月1300)。已为您生成趋势图(见附件)。
5. CotCompletionAgentRunner
https://blog.csdn.net/orchidofocean/article/details/149428923?spm=1001.2014.3001.5502
CotCompletionAgentRunner 类承自 CotAgentRunner,是专为完成式(Completion)场景优化的思维链代理实现。与聊天场景不同,完成式场景更注重将所有上下文整合为单个提示,引导模型生成连贯的回答。下面我们从架构定位、核心功能、设计模式和技术细节四个层面进行剖析。
5.1. 架构定位:完成式场景的思维链代理
与 CotChatAgentRunner 的对比:
- 聊天场景: 以对话形式交互,维护多轮消息列表(如 [System, User, Assistant, User, …])
- 完成式场景: 将所有上下文整合为单个提示,更接近传统的「指令 - 回答」模式
这种设计遵循了「单一职责原则」,通过继承实现功能复用,同时针对不同场景进行特化优化。
5.2. 核心功能:三大提示构建器
类中定义了三个核心方法,分别负责构建指令提示、历史提示和整合所有提示组件:
5.2.1. _organize_instruction_prompt():构建指令提示
class CotCompletionAgentRunner(CotAgentRunner):
def _organize_instruction_prompt(self) -> str:
"""
Organize instruction prompt
"""
if self.app_config.agent is None:
raise ValueError("Agent configuration is not set")
prompt_entity = self.app_config.agent.prompt
if prompt_entity is None:
raise ValueError("prompt entity is not set")
first_prompt = prompt_entity.first_prompt
# 填充模板变量
system_prompt = (
first_prompt.replace("{{instruction}}", self._instruction)
.replace("{{tools}}", json.dumps(jsonable_encoder(self._prompt_messages_tools)))
.replace("{{tool_names}}", ", ".join([tool.name for tool in self._prompt_messages_tools]))
)
return system_prompt
关键操作:
- 从配置中获取基础提示模板(如 first_prompt)
- 动态填充三个关键变量:
{{instruction}} 用户指令(如「分析销量趋势」)
{{tools}} 可用工具列表的 JSON 字符串
{{tool_names}} 工具名称的逗号分隔列表
与聊天场景的区别:
- 直接返回字符串而非 SystemPromptMessage 对象
- 不区分系统消息和用户消息,全部整合为单个提示
5.2.2. _organize_historic_prompt():构建历史提示
def _organize_historic_prompt(self, current_session_messages: Optional[list[PromptMessage]] = None) -> str:
"""
Organize historic prompt
"""
historic_prompt_messages = self._organize_historic_prompt_messages(current_session_messages)
historic_prompt = ""
for message in historic_prompt_messages:
if isinstance(message, UserPromptMessage):
historic_prompt += f"Question: {message.content}\n\n"
elif isinstance(message, AssistantPromptMessage):
if isinstance(message.content, str):
historic_prompt += message.content + "\n\n"
elif isinstance(message.content, list):
for content in message.content:
if not isinstance(content, TextPromptMessageContent):
continue
historic_prompt += content.data
return historic_prompt
关键操作:
- 将历史消息转换为特定格式(如 Question: … 和 Answer: …)
- 处理不同类型的消息内容(字符串或列表)
- 过滤非文本内容(如图片、文件)
设计亮点:
- 使用 Question: 和 Answer: 标签明确区分用户问题和 AI 回答
- 支持嵌套内容(如多模态消息中的文本部分)
- 通过 _organize_historic_prompt_messages 方法复用历史消息处理逻辑
5.2.3. _organize_prompt_messages():整合所有提示组件
def _organize_prompt_messages(self) -> list[PromptMessage]:
"""
Organize prompt messages
"""
# organize system prompt
# 1. 构建系统提示
system_prompt = self._organize_instruction_prompt()
# organize historic prompt messages
# 2. 构建历史提示
historic_prompt = self._organize_historic_prompt()
# organize current assistant messages
# 3. 构建当前助手消息(思维链)
agent_scratchpad = self._agent_scratchpad
assistant_prompt = ""
for unit in agent_scratchpad or []:
if unit.is_final():
assistant_prompt += f"Final Answer: {unit.agent_response}"
else:
assistant_prompt += f"Thought: {unit.thought}\n\n"
if unit.action_str:
assistant_prompt += f"Action: {unit.action_str}\n\n"
if unit.observation:
assistant_prompt += f"Observation: {unit.observation}\n\n"
# query messages
# 4. 构建当前查询
query_prompt = f"Question: {self._query}"
# join all messages
# 5. 整合所有提示
prompt = (
system_prompt.replace("{{historic_messages}}", historic_prompt)
.replace("{{agent_scratchpad}}", assistant_prompt)
.replace("{{query}}", query_prompt)
)
return [UserPromptMessage(content=prompt)]
关键操作:
- 将系统提示、历史对话、当前思考步骤和用户查询整合为单个字符串
- 通过模板替换({{historic_messages}}, {{agent_scratchpad}}, {{query}})动态组合内容
- 返回包含完整提示的单个 UserPromptMessage
与聊天场景的区别:
- 不区分消息类型(系统 / 用户 / 助手),全部整合为用户消息
- 使用额外的模板变量(如 {{historic_messages}})来组织更复杂的提示结构
5.3. 设计模式分析
5.3.1. 模板方法模式
与 CotChatAgentRunner 类似,CotCompletionAgentRunner 重写了父类的几个关键方法:
def _organize_instruction_prompt(self) -> str:
# 特化实现...
def _organize_historic_prompt(self, current_session_messages: Optional[list[PromptMessage]] = None) -> str:
# 特化实现...
def _organize_prompt_messages(self) -> list[PromptMessage]:
# 特化实现...
模式应用:
父类 CotAgentRunner 定义算法骨架
子类重写特定步骤以适应完成式场景
整体流程保持一致,但具体实现不同
5.3.2. 策略模式
在处理不同类型的历史消息时,代码使用了策略模式的变体:
for message in historic_prompt_messages:
if isinstance(message, UserPromptMessage):
# 处理用户消息的策略
elif isinstance(message, AssistantPromptMessage):
# 处理助手消息的策略
设计优势:
- 可扩展性:若需支持新的消息类型(如系统通知),只需添加新的条件分支
- 单一职责:每种消息类型的处理逻辑分离
- 松耦合:消息类型与处理逻辑解耦
5.3.3. 组合模式
在组织最终提示时,代码使用了组合模式:
prompt =(
system_prompt.replace("{{historic_messages}}", historic_prompt)
.replace("{{agent_scratchpad}}", assistant_prompt)
.replace("{{query}}", query_prompt)
)
设计特点:
不同类型的提示组件(系统提示、历史对话、思维链)被组合成一个整体
组件之间松耦合,可独立变化
整体提示对 LLM 呈现为统一的输入
6. FunctionCallAgentRunner
https://blog.csdn.net/orchidofocean/article/details/149428953?spm=1001.2014.3001.5502
在 AI 代理系统中,「工具调用能力」是区分普通对话机器人与智能助手的核心标志。FunctionCallAgentRunner 作为 Dify 框架中处理函数调用的核心组件,实现了 AI 代理「感知需求→调用工具→整合结果→生成回答」的完整逻辑。本文将从架构定位、核心流程、关键技术到设计智慧,全面剖析这一组件的实现。
6.1. 架构定位:函数调用代理的「总指挥」
FunctionCallAgentRunner 继承自 BaseAgentRunner,是专为「结构化工具调用」场景设计的代理运行器。其核心使命是:让 AI 代理能够理解工具调用规范,根据用户需求自动选择工具、传递参数,并将工具返回结果整合为自然语言回答。
与之前分析的 CotChatAgentRunner(基于自然语言思维链)不同,FunctionCallAgentRunner 的特点是:
- 结构化工具调用:依赖 LLM 返回的tool_calls字段(而非自然语言中的 “Action” 标记),更直接、更规范;
- 原生函数调用支持:适配 LLM 的函数调用 API(如 OpenAI 的function_call),减少自然语言解析的歧义;
- 流式与阻塞双模式:同时支持流式工具调用(边生成边处理)和阻塞式调用(完整结果后处理)。
6.2. 核心流程:从用户提问到工具调用的闭环
run 方法是 FunctionCallAgentRunner 的核心,包含了「初始化→LLM 交互→工具调用→结果整合」的完整闭环。我们以「查询今日北京天气并生成温度趋势图」为例,拆解其工作流程:
6.2.1. 初始化与参数准备
class FunctionCallAgentRunner(BaseAgentRunner):
def run(self, message: Message, query: str, **kwargs: Any) -> Generator[LLMResultChunk, None, None]:
"""
Run FunctionCall agent application
"""
self.query = query
app_generate_entity = self.application_generate_entity
app_config = self.app_config
assert app_config is not None, "app_config is required"
assert app_config.agent is not None, "app_config.agent is required" # 校验必要配置
# convert tools into ModelRuntime Tool format
# 初始化工具:将工具转换为LLM可识别的格式(名称、参数等)
tool_instances, prompt_messages_tools = self._init_prompt_tools()
assert app_config.agent
# 迭代控制:限制最大工具调用次数(避免无限循环)
iteration_step = 1
max_iteration_steps = min(app_config.agent.max_iteration, 99) + 1
# continue to run until there is not any tool call
function_call_state = True # 标记是否需要继续调用工具
llm_usage: dict[str, Optional[LLMUsage]] = {"usage": None} # 记录LLM的token使用量
final_answer = "" # 最终回答
# get tracing instance
# 追踪管理器(用于调试/监控)
trace_manager = app_generate_entity.trace_manager
......
关键操作:
- 校验应用配置(如app_config),确保工具和代理参数已设置;
- 通过_init_prompt_tools加载可用工具(如「天气查询工具」「图表生成工具」),并转换为 LLM 可理解的格式(包含名称、参数描述);
- 限制最大迭代次数(max_iteration_steps),防止因工具调用逻辑错误导致无限循环。
6.2.2. 迭代工具调用循环
代理通过循环迭代实现「调用工具→处理结果→决定是否继续调用」的逻辑,直到无需工具或达到最大次数:
class FunctionCallAgentRunner(BaseAgentRunner):
def run(self, message: Message, query: str, **kwargs: Any) -> Generator[LLMResultChunk, None, None]:
......
model_instance = self.model_instance
while function_call_state and iteration_step <= max_iteration_steps:
function_call_state = False # 默认为不需要继续调用,除非检测到工具调用指令
if iteration_step == max_iteration_steps:
# the last iteration, remove all tools
prompt_messages_tools = []
message_file_ids: list[str] = []
# 1. 创建本轮思考记录(数据库存储,用于追踪)
agent_thought_id = self.create_agent_thought(
message_id=message.id, message="", tool_name="", tool_input="", messages_ids=message_file_ids
)
# recalc llm max tokens
# 2. 组织提示信息(系统指令+历史对话+用户查询)
prompt_messages = self._organize_prompt_messages()
# 计算LLM最大token限制
self.recalc_llm_max_tokens(self.model_config, prompt_messages)
# invoke model
# 3. 调用LLM,获取响应(支持流式/阻塞式)
chunks: Union[Generator[LLMResultChunk, None, None], LLMResult] = model_instance.invoke_llm(
prompt_messages=prompt_messages,
model_parameters=app_generate_entity.model_conf.parameters,
tools=prompt_messages_tools, # 告诉LLM可用工具
stop=app_generate_entity.model_conf.stop,
stream=self.stream_tool_call, # 是否流式响应(由模型能力决定)
user=self.user_id,
callbacks=[],
)
tool_calls: list[tuple[str, str, dict[str, Any]]] = []
# save full response
response = ""
# save tool call names and inputs
tool_call_names = ""
tool_call_inputs = ""
current_llm_usage = None
......
核心逻辑:
- 每次迭代创建 agent_thought 记录,用于存储本轮的思考、工具调用、结果等信息(可追溯);
- _organize_prompt_messages 整合上下文(系统指令、历史对话、用户当前查询),确保 LLM 理解完整场景;
- 调用 LLM 时传入tools参数,明确告知可用工具的结构(名称 + 参数),引导 LLM 生成规范的工具调用指令。
6.2.3. 处理 LLM 响应:提取工具调用指令
LLM 的响应分为「流式」和「阻塞式」两种,代码需分别处理并提取工具调用指令:
- (1)处理流式响应(stream=self.stream_tool_call=True)
若模型支持流式工具调用(如 GPT-4),响应会以「分块」形式返回,需逐块解析:
if isinstance(chunks, Generator): # 流式响应(分块返回)
is_first_chunk = True
for chunk in chunks: # 遍历每个响应块
if is_first_chunk: # 首次接收块时,发布「开始思考」事件(前端可显示"AI正在思考...")
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
is_first_chunk = False
# check if there is any tool call
# 检查当前块是否包含工具调用指令
if self.check_tool_calls(chunk):
function_call_state = True # 需要继续调用工具
# 提取工具调用信息:(工具调用ID, 工具名称, 调用参数)
tool_calls.extend(self.extract_tool_calls(chunk) or [])
# 记录工具名称和参数(用于存储)
tool_call_names = ";".join([tool_call[1] for tool_call in tool_calls])
try:
tool_call_inputs = json.dumps(
{tool_call[1]: tool_call[2] for tool_call in tool_calls}, ensure_ascii=False
)
except TypeError:
# fallback: force ASCII to handle non-serializable objects
tool_call_inputs = json.dumps({tool_call[1]: tool_call[2] for tool_call in tool_calls})
# 累加响应内容(用于生成最终回答)
if chunk.delta.message and chunk.delta.message.content:
if isinstance(chunk.delta.message.content, list):
for content in chunk.delta.message.content:
response += content.data
else:
response += str(chunk.delta.message.content)
# 累加 token 使用量(用于计费/监控)
if chunk.delta.usage:
increase_usage(llm_usage, chunk.delta.usage)
current_llm_usage = chunk.delta.usage
yield chunk # 实时返回给前端,实现"边想边说"的效果
- (2)处理阻塞式响应(stream=False)
若模型不支持流式工具调用,响应会一次性返回,直接解析完整结果:
else: # 阻塞式响应(完整返回)
result = chunks
# check if there is any tool call
# 检查是否包含工具调用指令
if self.check_blocking_tool_calls(result):
function_call_state = True
tool_calls.extend(self.extract_blocking_tool_calls(result) or [])
tool_call_names = ";".join([tool_call[1] for tool_call in tool_calls])
try:
tool_call_inputs = json.dumps(
{tool_call[1]: tool_call[2] for tool_call in tool_calls}, ensure_ascii=False
)
except TypeError:
# fallback: force ASCII to handle non-serializable objects
tool_call_inputs = json.dumps({tool_call[1]: tool_call[2] for tool_call in tool_calls})
if result.usage:
increase_usage(llm_usage, result.usage)
current_llm_usage = result.usage
# 累加响应内容和token使用量
if result.message and result.message.content:
if isinstance(result.message.content, list):
for content in result.message.content:
response += content.data
else:
response += str(result.message.content)
if not result.message.content:
result.message.content = ""
# 发布思考事件并返回结果
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
yield LLMResultChunk(
model=model_instance.model,
prompt_messages=result.prompt_messages,
system_fingerprint=result.system_fingerprint,
delta=LLMResultChunkDelta(
index=0,
message=result.message,
usage=result.usage,
),
)
关键方法:
- check_tool_calls/check_blocking_tool_calls:检查 LLM 响应中是否包含工具调用指令(通过 tool_calls 字段判断);
- extract_tool_calls/extract_blocking_tool_calls:从响应中提取工具调用细节(如工具 ID、名称、参数),例如从 tool_calls 中解析出(“call_123”, “weather_query”, {“city”: “北京”, “date”: “today”})。
6.2.4. 执行工具调用并处理结果
提取工具调用指令后,代理需执行工具并处理返回结果:
assistant_message = AssistantPromptMessage(content="", tool_calls=[])
if tool_calls:
assistant_message.tool_calls = [
AssistantPromptMessage.ToolCall(
id=tool_call[0],
type="function",
function=AssistantPromptMessage.ToolCall.ToolCallFunction(
name=tool_call[1], arguments=json.dumps(tool_call[2], ensure_ascii=False)
),
)
for tool_call in tool_calls
]
else:
assistant_message.content = response
self._current_thoughts.append(assistant_message)
# save thought
self.save_agent_thought(
agent_thought_id=agent_thought_id,
tool_name=tool_call_names,
tool_input=tool_call_inputs,
thought=response,
tool_invoke_meta=None,
observation=None,
answer=response,
messages_ids=[],
llm_usage=current_llm_usage,
)
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
final_answer += response + "\n"
# call tools
# 调用工具并收集结果
tool_responses = []
for tool_call_id, tool_call_name, tool_call_args in tool_calls:
# 获取工具实例(如"weather_query"对应「天气查询工具」)
tool_instance = tool_instances.get(tool_call_name)
if not tool_instance: # 工具不存在(容错处理)
tool_response = {
"tool_call_id": tool_call_id,
"tool_call_name": tool_call_name,
"tool_response": f"there is not a tool named {tool_call_name}",
"meta": ToolInvokeMeta.error_instance(f"there is not a tool named {tool_call_name}").to_dict(),
}
else: # 调用工具
# invoke tool
tool_invoke_response, message_files, tool_invoke_meta = ToolEngine.agent_invoke(
tool=tool_instance,
tool_parameters=tool_call_args, # 参数:{"city": "北京", "date": "today"}
user_id=self.user_id,
tenant_id=self.tenant_id,
message=self.message,
invoke_from=self.application_generate_entity.invoke_from,
agent_tool_callback=self.agent_callback,
trace_manager=trace_manager,
app_id=self.application_generate_entity.app_config.app_id,
message_id=self.message.id,
conversation_id=self.conversation.id,
)
# publish files
# 发布工具返回的文件(如图表生成工具返回的图片)
for message_file_id in message_files:
# publish message file
self.queue_manager.publish(
QueueMessageFileEvent(message_file_id=message_file_id), PublishFrom.APPLICATION_MANAGER
)
# add message file ids
message_file_ids.append(message_file_id)
tool_response = {
"tool_call_id": tool_call_id,
"tool_call_name": tool_call_name,
"tool_response": tool_invoke_response, # 如"北京今日气温25℃,晴"
"meta": tool_invoke_meta.to_dict(),
}
# 将工具结果添加到上下文(供下一轮LLM参考)
tool_responses.append(tool_response)
if tool_response["tool_response"] is not None:
self._current_thoughts.append(
ToolPromptMessage(
content=str(tool_response["tool_response"]),
tool_call_id=tool_call_id,
name=tool_call_name,
)
)
关键操作:
- 通过 ToolEngine.agent_invoke 执行工具调用,传入参数(如城市、日期);
- 处理工具返回的文件(如图表),通过 QueueMessageFileEvent 实时推送给用户,提升体验;
- 将工具结果封装为 ToolPromptMessage,添加到上下文(_current_thoughts),确保下一轮 LLM 能参考该结果。
6.2.5. 记录与更新状态
工具调用完成后,更新本轮思考记录,并决定是否继续迭代:
if len(tool_responses) > 0:
# save agent thought
# 保存本轮思考记录(包含工具调用、结果、token使用量)
self.save_agent_thought(
agent_thought_id=agent_thought_id,
tool_name="",
tool_input="",
thought="",
tool_invoke_meta={
tool_response["tool_call_name"]: tool_response["meta"] for tool_response in tool_responses
},
observation={
tool_response["tool_call_name"]: tool_response["tool_response"]
for tool_response in tool_responses
},
answer="",
messages_ids=message_file_ids,
)
self.queue_manager.publish(
QueueAgentThoughtEvent(agent_thought_id=agent_thought_id), PublishFrom.APPLICATION_MANAGER
)
# update prompt tool
for prompt_tool in prompt_messages_tools:
self.update_prompt_message_tool(tool_instances[prompt_tool.name], prompt_tool)
iteration_step += 1 # 迭代次数+1
关键逻辑:
- save_agent_thought 将工具调用细节、结果、token 使用量等存入数据库,支持后续审计、计费或调试;
- 发布 QueueAgentThoughtEvent 事件,通知前端或其他服务「本轮思考已完成」,可更新 UI 显示(如展示工具调用结果)。
6.2.6. 生成最终回答并结束
当无需继续调用工具(function_call_state=False)或达到最大迭代次数时,生成最终回答并发布结束事件:
# publish end event
# 发布结束事件(包含最终回答和token使用量)
self.queue_manager.publish(
QueueMessageEndEvent(
llm_result=LLMResult(
model=model_instance.model,
prompt_messages=prompt_messages,
message=AssistantPromptMessage(content=final_answer), # 最终回答
usage=llm_usage["usage"] or LLMUsage.empty_usage(), # 总 token 使用量
system_fingerprint="",
)
),
PublishFrom.APPLICATION_MANAGER,
)
6.3. 核心方法解析:支撑代理运行的「关键齿轮」
除了 run 方法,类中其他核心方法负责处理提示构建、工具调用检测、多模态输入等关键逻辑,共同构成代理的「运转齿轮」。
6.3.1. 提示信息组织:_organize_prompt_messages
该方法整合系统指令、历史对话、用户查询和工具调用记录,生成 LLM 的完整输入:
def _organize_prompt_messages(self):
# 1. 初始化系统提示(如"你是智能助手,可调用工具解决问题...")
prompt_template = self.app_config.prompt_template.simple_prompt_template or ""
self.history_prompt_messages = self._init_system_message(prompt_template, self.history_prompt_messages)
# 2. 组织用户查询(支持多模态,如文本+图片)
query_prompt_messages = self._organize_user_query(self.query or "", [])
# 3. 整合历史消息与当前思考(确保上下文连贯)
self.history_prompt_messages = AgentHistoryPromptTransform(
model_config=self.model_config,
prompt_messages=[*query_prompt_messages, *self._current_thoughts], # 当前查询+工具调用记录
history_messages=self.history_prompt_messages, # 历史对话
memory=self.memory, # 内存管理(避免token超限)
).get_prompt()
# 4. 组装最终提示(历史+当前查询+当前思考)
prompt_messages = [*self.history_prompt_messages, *query_prompt_messages, *self._current_thoughts]
# 5. 首次迭代后清除图片信息(部分模型不支持多轮图片输入)
if len(self._current_thoughts) != 0:
# clear messages after the first iteration
prompt_messages = self._clear_user_prompt_image_messages(prompt_messages)
return prompt_messages
核心作用:
- 确保 LLM 获得完整上下文(历史对话 + 当前查询 + 工具调用记录);
- 处理多模态输入(如用户上传的图片),转换为模型可理解的格式;
- 通过 AgentHistoryPromptTransform 管理上下文长度(避免超过模型 token 限制)。
6.3.2. 多模态输入处理:_organize_user_query
该方法将用户输入(文本 + 文件 / 图片)转换为统一格式,支持多模态工具调用:
def _organize_user_query(self, query: str, prompt_messages: list[PromptMessage]) -> list[PromptMessage]:
"""
Organize user query
"""
if self.files: # 处理用户上传的文件(如图像) 否则为纯文本输入
# get image detail config
image_detail_config = (
self.application_generate_entity.file_upload_config.image_config.detail
if (
self.application_generate_entity.file_upload_config
and self.application_generate_entity.file_upload_config.image_config
)
else None
)
# 图像细节配置(高/中/低,控制描述详细程度)
image_detail_config = image_detail_config or ImagePromptMessageContent.DETAIL.LOW
prompt_message_contents: list[PromptMessageContentUnionTypes] = []
# 转换文件为模型可理解的格式(如图片→文本描述)
for file in self.files:
prompt_message_contents.append(
file_manager.to_prompt_message_content(
file,
image_detail_config=image_detail_config,
)
)
prompt_message_contents.append(TextPromptMessageContent(data=query))
prompt_messages.append(UserPromptMessage(content=prompt_message_contents))
else: # 纯文本输入
prompt_messages.append(UserPromptMessage(content=query))
return prompt_messages
示例场景:
- 用户提问「分析这张北京天气趋势图」并上传图片 → 方法将图片转换为文本描述(如「一张展示北京近 7 天气温的折线图,最高温 30℃,最低温 20℃」),与文本问题合并为多模态输入,确保 LLM 能理解图片内容。
6.3.3. 工具调用检测与提取
LLM 的工具调用指令通过tool_calls字段传递(结构化格式),以下方法负责检测和提取:
- check_tool_calls/check_blocking_tool_calls:检查流式响应中是否包含工具调用
def check_tool_calls(self, llm_result_chunk: LLMResultChunk) -> bool:
"""
Check if there is any tool call in llm result chunk
"""
# 若有 tool_calls 则返回True
if llm_result_chunk.delta.message.tool_calls:
return True
return False
def check_blocking_tool_calls(self, llm_result: LLMResult) -> bool:
"""
Check if there is any blocking tool call in llm result
"""
if llm_result.message.tool_calls:
return True
return False
- extract_tool_calls/extract_blocking_tool_calls:从流式响应中提取工具调用细节
def extract_tool_calls(self, llm_result_chunk: LLMResultChunk) -> list[tuple[str, str, dict[str, Any]]]:
"""
Extract tool calls from llm result chunk
Returns:
List[Tuple[str, str, Dict[str, Any]]]: [(tool_call_id, tool_call_name, tool_call_args)]
"""
tool_calls = []
for prompt_message in llm_result_chunk.delta.message.tool_calls:
args = {}
# 解析参数(如{"city": "北京"})
if prompt_message.function.arguments != "":
args = json.loads(prompt_message.function.arguments)
tool_calls.append(
(
prompt_message.id,
prompt_message.function.name,
args,
)
)
return tool_calls
def extract_blocking_tool_calls(self, llm_result: LLMResult) -> list[tuple[str, str, dict[str, Any]]]:
"""
Extract blocking tool calls from llm result
Returns:
List[Tuple[str, str, Dict[str, Any]]]: [(tool_call_id, tool_call_name, tool_call_args)]
"""
tool_calls = []
for prompt_message in llm_result.message.tool_calls:
args = {}
# 解析参数(如{"city": "北京"})
if prompt_message.function.arguments != "":
args = json.loads(prompt_message.function.arguments)
tool_calls.append(
(
prompt_message.id,
prompt_message.function.name,
args,
)
)
return tool_calls
关键作用:
- 从 LLM 响应中精准提取工具调用信息(ID、名称、参数),为后续工具执行提供输入;
- 支持流式和阻塞式两种响应格式,兼容不同模型特性(如 GPT-4 支持流式,部分模型仅支持阻塞式)。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)