
让Agent“记得对、做得准、跑得快”:上下文工程深度解析,优化AI Agent的5大策略,小白必学,建议收藏!!
文章详细介绍了Context Engineering(上下文工程)的概念,它与传统Prompt Engineering的区别在于处理来自机器的动态上下文信息。文章探讨了Context Engineering面临的挑战,包括System Prompt设计、上下文获取和质量控制,以及long context导致的性能下降问题。针对这些挑战,提出了五种核心策略:Offload(卸载到外部存储)、Retr
前言
最近看了一个非常不错的 关于 Context Engineering 的分享[1],里面综合讨论了 Anthropic,Cognition,Manus,Chroma,LangChain 等公司在这个领域方面的最新思考和实践,有点像当年分享过的 Applied LLMs[2],非常值得一看。
AI Agent 开发这个领域还处在比较早期的阶段,相信很多从业者都能体会到在实际开发过程中会遇到各种问题,从中积累了不少经验和小技巧。尤其是在与 LLM 这么个“神奇物种”打交道,有很多心得体验甚至有种难以用语言表达的微妙感觉。如果你也正好是一名同行,相信在看这个分享过程中会有很多共鸣。以下内容不会做逐字翻译,而会结合自己的一些经验和理解提供一些额外信息,供大家参考。
定义
之前 Prompt Engineering 的概念有点宽泛,但实际上,这里有两种非常不一样的场景:
- 作为用户,日常与 LLM 或者 ChatGPT 这样的产品交互时,如何写好 Prompt,才能让模型更好地理解各种背景信息和用户意图,给出令人满意的结果。这些往往都是“一次性”的交互。
- 作为开发者,如何设计一个 Prompt 自动构建的系统,利用 LLM 来完成某个复杂任务。这里往往是类似场景的海量交互,需要追求整体的效率和效果。
Context Engineering 的确能够更好地描述后者的场景,得到了开发者群体的广泛认可。
Lance 的分享中提到 Context Engineering 与 Prompt Engineering 的核心区别在于:
- 信息来源:Prompt Engineering 的上下文主要来自用户输入;而 Context Engineering 处理的上下文,绝大部分来自于机器(工具)的输出。
- 动态性:Prompt Engineering 通常是静态的、一次性的;而 Context Engineering 是高度动态的,上下文在代理的整个运行周期中不断累积和变化。
挑战
根据前面的背景和定义,我们也能看到 Context Engineering 要达到的主要目标是效果和效率。因为这部分构建的 prompt 会被成千上万次重复调用,如果成功率不高,那么开发者就会面临大量的技术支持和 bad case 排查工作。同样因为调用次数非常多,如果每次调用的 token 开销量巨大,也会影响整体成本和响应速度方面的体验。更具体地说,我们在日常实践中主要关注以下几个方面的挑战:
- “System Prompt” 的设计,这部分有点像通用的 prompting 技巧,怎么把任务描述清楚,覆盖面广,逻辑一致,且表达上要尽可能精简等。
- 通过工具调用等方式,来获取足够全面和高质量的上下文信息。对于很多企业级场景来说,困难往往在于“全面”上,这方面问题的解决往往需要较长的时间周期。而中短期来看,开发者更能快速做出贡献的可能主要是通过工具设计来提升信息的“LLM 友好度”上。
- 有了足够的信息后,下一步才是考虑 LLM 当前对于 long context 能力的局限性。比如分享中提到,当上下文过长时,模型的性能会显著下降,出现注意力不集中、遗忘关键信息等 context rot[3] 问题。工具调用加上多轮对话,严重放大了这个问题。
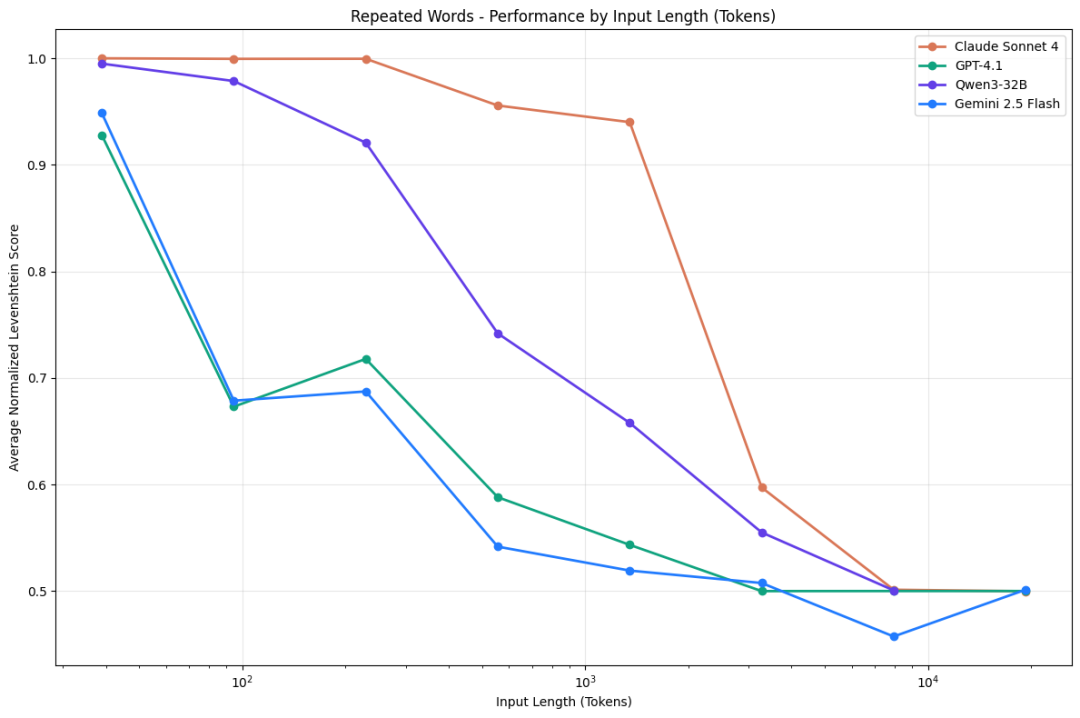
Chroma 关于 Context Rot 问题的研究
这个 long context 的问题也挺值得深入看看的,对于日常的“context debugging”工作会有些启发。一些常见的现象包括:
- 幻觉引发的“中毒”,典型研究可以参考 Gemini 2.5 Pro 技术报告[4] 中玩 Pokémon 的部分。当模型因为自己的预先训练数据产生幻觉时,后续输出往往会被这些信息持续带偏。
- 信息冲突,自然语言本身就存在大量的模糊性,再叠加 long context 的情况下,很容易出现前后信息不一致的情况,这时候模型的行为就会变得不可预测。
- 关键信息被稀释,随着上下文的增长,模型的注意力会被更多的信息分散,导致对真正重要的信息关注度下降。
- 大量重复文本导致的“行动瘫痪”,Gemini 的报告中也提到,当 context 中已经包含了模型之前大量的行动历史时,模型的输出往往会进入“复读机”模式,而无法做出新的决策。Manus 的分享中也提到了这一点。

在后面的策略部分,我们会看到一些应对这些问题的思路。下图来自 LangChain 博客,基本对应了分享中的内容,不过在策略名称上略有调整。
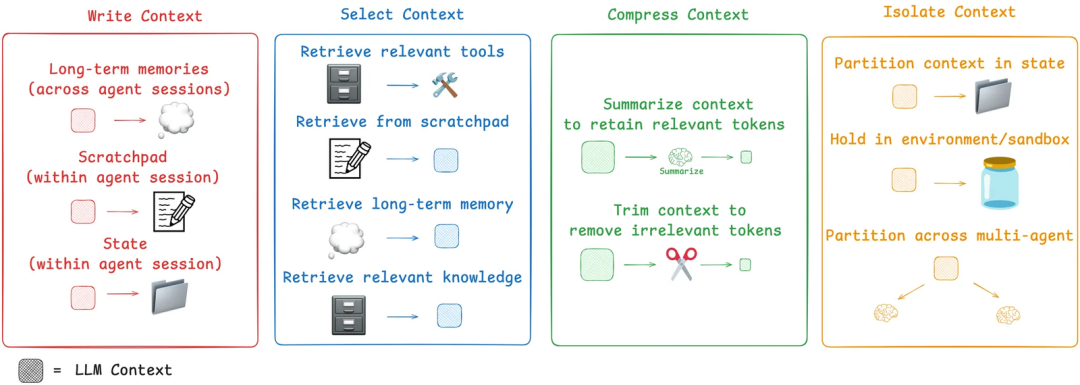
LangChain 博客中的策略总览
策略一:Offload
核心思想:不要将工具返回的全部原始信息都直接喂给 LLM。相反,应将其“卸载”到外部存储(如文件系统、数据库或一个专门的代理状态对象中),然后只将一个轻量级的“指针”(如摘要、文件名或 URL)返回给模型。当模型需要细节时,再根据这个标识检索外部内容。
类比一下人类也经常用类似的方式,例如针对 Context Engineering 这个主题,我只要记得 YouTube 上有个视频介绍了这个话题下的一些挑战和重要策略就可以了。在需要的时候我可以再打开这个视频,根据任务需要来获取相关细节信息。
在实战中,使用最多的外部存储可能就是文件系统了,比如 Manus 中会使用文件系统来记录和持续追踪 TODO list,Anthropic 的 Research Agent[5] 也会让 sub agents 把成果写到文件中,省去了模型在互相沟通时还需要重复“抄写”大量内容。
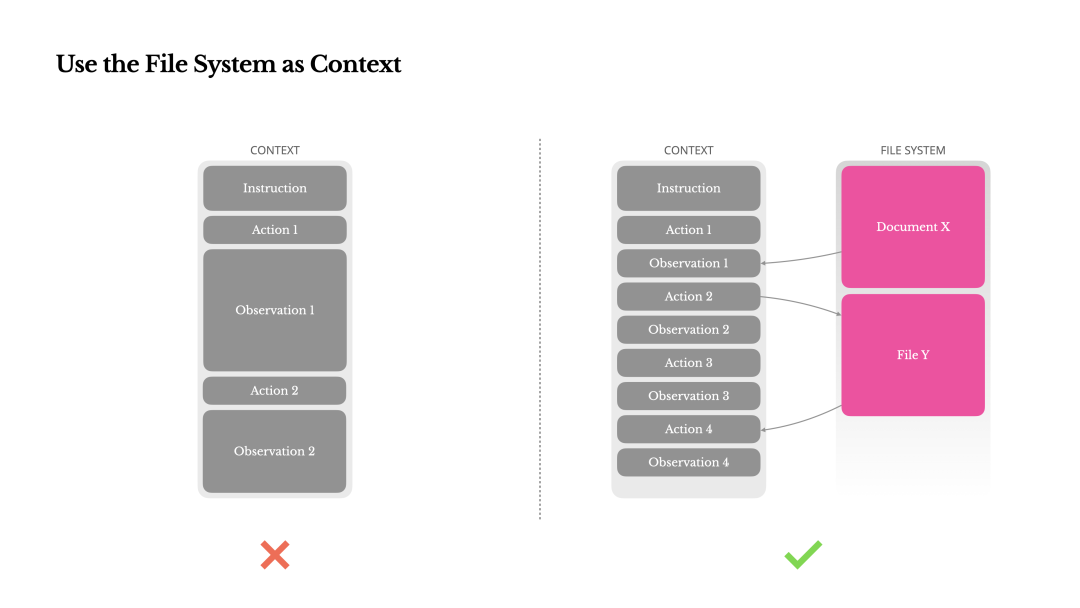
Manus 分享的使用文件系统作为 context
分享中还聊到了 agent memory,可以理解为一种特殊的 offload,将用户当前与 agent 交互中的重要信息写入到“长期记忆”系统中,这样就不需要维护一个“无限长”的对话流来记住关于用户的各种 context 信息了。虽然业界已经有不少开源项目,但总体来说这个领域还处在比较早期,如何有效地压缩对话成为有用的记忆,如何设计记忆的存储形式,如何在后续任务中准确地召回和应用,都有不小的挑战。
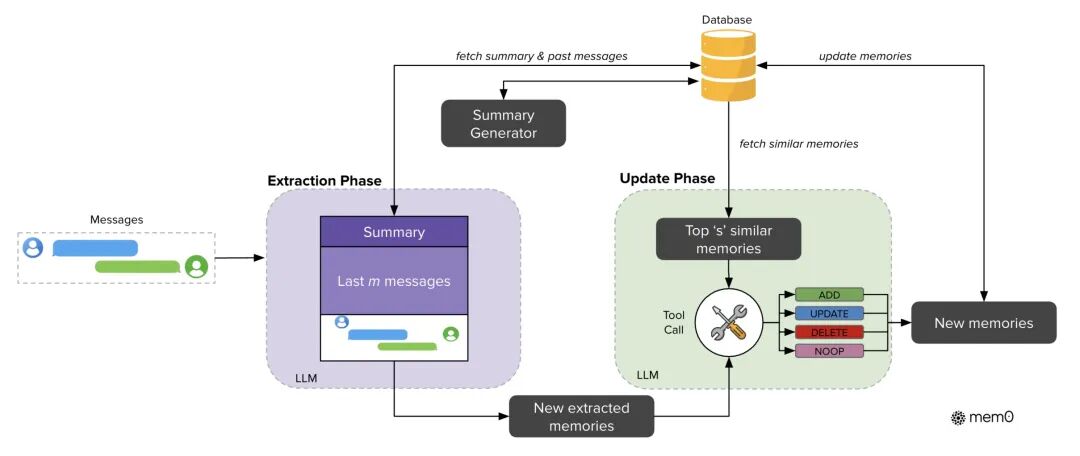
Agent Memory
策略二:Retrieve
简单来说就是我们所熟悉的 RAG,通过检索和过滤相关信息,来控制进入 context 的内容的数量和质量。这方面主要的技术路径目前看起来有两类:
- 从向量检索出发,逐渐往更复杂的搜索体系演化。例如混合召回,结合图谱的 GraphRAG,rerank 等等。
- 返璞归真到仅仅使用 llms.txt + grep/find 之类的工具,通过 agent 的多轮工具调用来获取相关信息。这也是 Claude Code 的实现方式。
作者分享了他的一个 简单评测[6],在代码场景中,路径二的效果显著超过了传统 RAG。
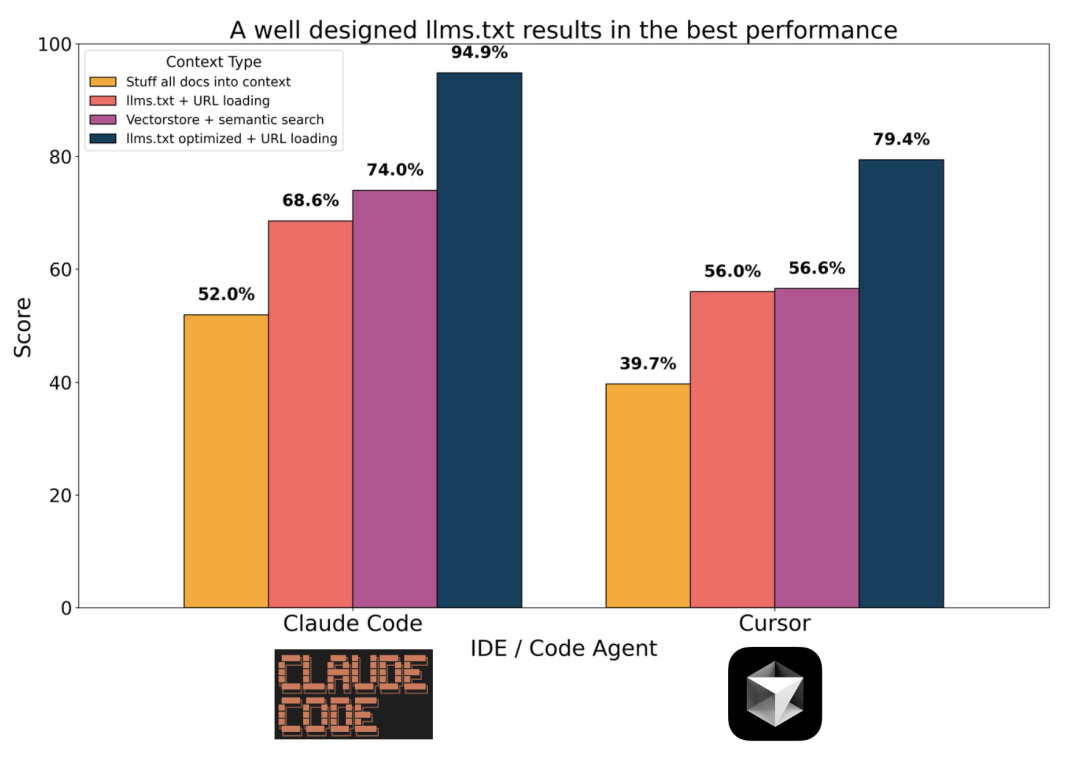
Coding Retrieval Benchmark
注意,find/grep/read 这些工具要达到比较好的效果,需要结合CLAUDE.md/llms.txt这类“索引文档”来提供相关知识。为此 Lance 还特地分享了一个他用来生成这类文档的工具 LLMsTxt Architect[7]。业界还有像 DeepWiki[8] 这样的产品,生成了大量开源项目的索引文档。
我个人的理解是这两者并不冲突,发展的方向肯定是往 agentic search 的方向演进,而具体的搜索手段则可以根据场景来选择。在代码场景中,grep 的确很好用,而各种知识库、聊天记录这类还是搜索引擎的形式比较自然。
除了获取新信息,retrieve 还有一个常见用法,就是在 agent 工作过程中,可以对一些关键信息做反复触发。比如前面提到的 TODO list,每当 agent 完成一个任务时,都可以把 TODO list 读出来,更新一下。一方面记录了进展,另一方面能再次提醒 agent 下一步的重点是什么,避免“走神”。
还有一种情况涉及过多的工具定义(超过 30 个),可能也会导致 agent 出现选错工具的情况。在 这篇分享[9] 中提到了可以先通过 RAG 来召回工具,再让大模型根据精简过的工具来进行选择的方式。LangGraph 也提供了一个开源实现:langgraph-bigtool[10]。
当然这个方法可能更适合单轮对话,在多轮交互中这么做可能会导致后面会讲到的 cache 失效的问题。Manus 的文章中就提到了“Mask, Don’t Remove”的技巧。就 LLM 目前的能力而言,我更推荐精简整合工具,或拆分 sub agents 聚焦不同场景。
策略三:Reduce
这个也很好理解,就是通过各种手段来裁剪上下文的内容。我们直接来看典型场景:
占 context 大头的往往是工具调用,所以第一步就是看看工具的输出内容能不能裁剪。最基础的比如搜索结果不用返回完整的 html,可以转成 markdown,或者先做一些总结等。Open Deep Research[11] 代码中就能找到对于搜索结果的压缩步骤。另外像 RAG 中,也经常使用 rerank 类模型[12] 来帮助过滤不相关的信息。
当 context 变得过长时,可以考虑进行信息总结压缩,比如最简单的,直接扔掉前一半的历史消息,或者去掉前几轮对话中的工具调用,仅保留 user,assistant 消息等。但这么做很容易让用户感到模型突然失忆的糟糕体验。
更好的做法是通过 LLM 来帮忙做总结压缩,附录中提供了一个 Claude Code 的/compact命令的 prompt 例子,可供参考。当然做总结也很有难度,Cognition 的分享[13] 中透露了他们针对这个做总结压缩的场景,还专门 fine-tune 了一个模型。如果总结得不好,一样会出现关键信息丢失,甚至引入幻觉等问题。这个方案对于评估和调试的要求也会更高。
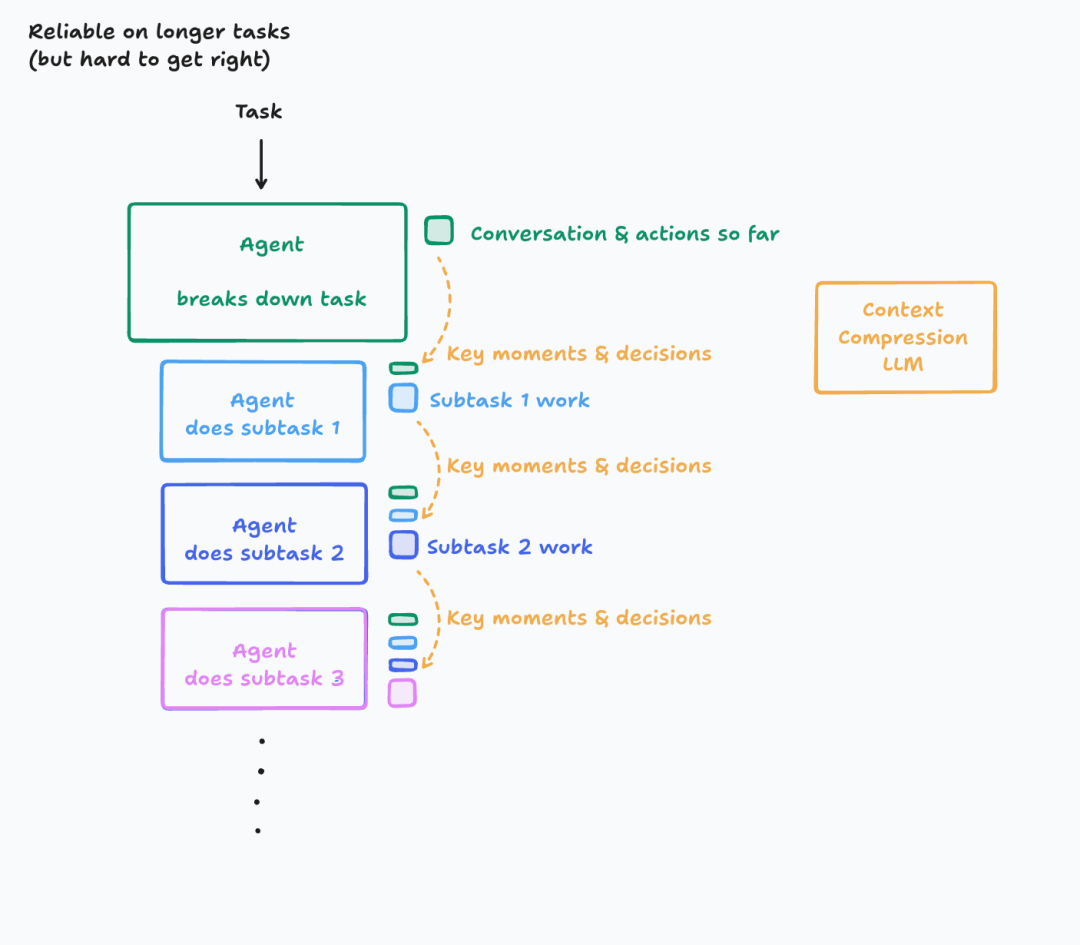
Context compression
最有争议的要数对于 context 内容的剪裁了。一方面的观点认为 context 过长,会导致各种问题,尤其是混入了幻觉的情况下,会导致模型走偏。另一方面如 Manus 提到,可以直接保留模型犯的错误,让它自我纠正,架构上更简单,且“cache 友好”。
从我个人经验来看,大多数情况下还是会采用保留全部 context 的方法。像 tool call 失败这种场景,如果有比较友好的报错信息,随着模型能力的提升,自我恢复的能力已经基本可用了。而其它的幻觉如果没有可靠的反馈信息,其实很难去判断和处理,反而可能因为信息裁剪造成用户和模型更大的困惑。
策略四:Isolate
非常类似 workflow 时代的“分而治之”思想,如果一个任务的 context 压力太过巨大,我们就拆分一下,分配给不同的 sub agents 来完成各个子任务。这样每个 agent 的 context 内容都是独立的,会更加清晰和聚焦。
在这一点上也有一些争议,比如 Cognition 的博客标题就叫做“Don’t Build Multi-Agents”,而 Anthropic 发了一篇“How we built our multi-agent research system”。不过一定程度上来说大家也还是有共识的:
- 容易产生冲突的工作,要尤其小心是否使用 multi agents。
- “只读”类的工作,可能天然就比较合适用 multi agents。比如做网页检索,查找和阅读代码库等。
- Sub agents 目前处理一个独立的任务会比较好实现和管理。如果每个 agent 都要支持多轮对话交互,可能也不太好实现。
当然在实际开发中,何时需要拆分 agent,拆分后需要共享和传递哪些 context,很多时候的决策还是比较微妙的。有点像在设计 agent 的“组织架构”。现阶段因为预训练数据,包括 RL 的训练环境,绝大多数还是来自目前的人类社会,所以总体上还是可以借鉴人类的分工协作方式。
当你把任务越拆越细时,可能会怀疑自己:我是不是在做 workflow 了?哈哈,其实也不用太纠结,能解决当下问题才是最重要的,你看 Anthropic 的 Building effective agents[14] 文章里,80%的篇幅都在讲 workflow,非常实在。
还有一种比较特殊的“环境隔离”方式,让模型将一部分任务在外部环境执行,以避免大量中间状态挤占 LLM 上下文。Hugging Face 的 Deep Researcher[15] 项目就展示了这种思路:它使用一个 Code Agent,模型输出的代码会在沙盒环境中运行,所有中间计算的详细状态(如图像、音频数据、大型文本)保存在环境中,只将必要的结果摘要传回模型。这样 LLM 不直接接触大体量对象,而是在需要时才读取,提高了效率。
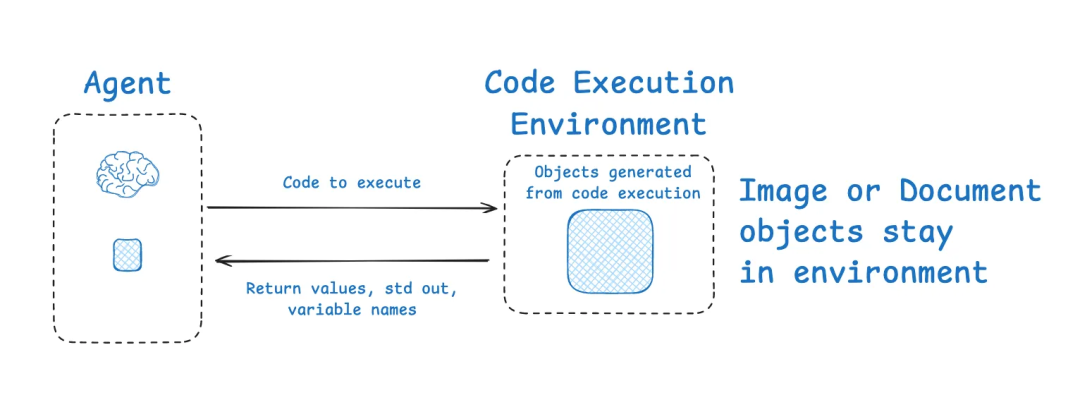
通过代码沙箱来隔离 context
这个思路跟前面提到的 offload 也有点相似,比如我可以不用 Code Agent,而是使用一个可以保持代码运行状态的 sandbox,那么很多信息可以直接“卸载”到 sandbox 中,让 agent 通过 REPL 交互探索的方式来一步步完成任务,而不是每次需要写全量的脚本。
策略五:Cache
当你的应用每天都要消耗海量 token 时,成本和性能方面的考量会开始变得重要起来,这也是 Manus 博客分享中非常核心的一个策略,需要在构建 context 过程中时刻考虑到 KV cache,就跟写高性能软件需要考虑 CPU/GPU 集群的硬件特性一样。
Agent 在完成任务过程中,往往需要大量的 tool call,每一轮工具调用都需要把历史消息完整地发送给模型,如果没有 KV cache,其开销会非常恐怖。好在目前主流的模型 API 都支持自动帮用户复用 cache,大大降低费用和延迟。前阵子大家吐槽用 Claude Code 对接 Qwen3 Coder 的账单比用原版模型还要高,很大原因就是 cache 这块没做好。
要高效利用 KV cache 的原则也很简单,就是确保每一次 LLM 调用的 context“前缀”都尽可能一致。比如把固定的 prompt 内容放在开头,而尽可能把动态变化的部分放在 prompt 模板的末尾。另外像修改历史消息这种操作也需要非常谨慎采用。

Prompt caching
当然具体还需要结合各家的模型 API 来做设计,里面有很多细节。比如:
- 某些模型厂商在使用 thinking 模型时会隐藏其思考过程,这时候如果你直接 append assistant message,其实是缺少了一些内容,会导致无法命中 cache。
- 前面提到的动态修改 tools,也会有影响,甚至每次传入的 tools 顺序也必须一致。
即使是传统的 workflow 模式,也要注意如果步骤之间有大量重复的信息需要传递,可以思考是否可以用一致的前序 prompt messages 来提升缓存命中率。
回顾 The Bitter Lesson
访谈最后几位嘉宾又聊了聊”苦涩的教训“,这方面相关资料已经很多,就不赘述了。
Hyung Won Chung 的分享很精彩,推荐观看
在实践中,我们还是需要随时提醒自己:
- 作为产品经理,我们是否能找到一种设计,尽可能发挥出 agent 持续进化的动态推理、行动能力,却不会让用户陷入对于 100% 确定性输出的旧有执念中去?
- 作为开发者,我们也不应该纠结于 100% agentic 的设计,先以解决眼下问题,创造用户价值为重点。当然我们需要保持架构的灵活性,拥抱变化。随着模型能力的提升,我们要持续审视是否可以去掉原有架构中“人工经验”的桎梏。
- 对于任何想做“AI 转型”的组织或产品来说,都要思考下已有的工作流程和产品,本身是否就是人类经验带来的枷锁?就像 AlphaZero 要忘记人类棋谱,才能超越人类一样,AI 时代有太多经验需要被重置,这需要极大的勇气和智慧。
附录
Claude Code /compact命令中的 prompt 示例:
Your task is to create a detailed summary of the conversation so far, paying close attention to the user's explicit requests and your previous actions.
This summary should be thorough in capturing technical details, code patterns, and architectural decisions that would be essential for continuing development work without losing context.
Before providing your final summary, wrap your analysis in <analysis> tags to organize your thoughts and ensure you've covered all necessary points. In your analysis process:
1. Chronologically analyze each message and section of the conversation. For each section thoroughly identify:
- The user's explicit requests and intents
- Your approach to addressing the user's requests
- Key decisions, technical concepts and code patterns
- Specific details like file names, full code snippets, function signatures, file edits, etc
2. Double-check for technical accuracy and completeness, addressing each required element thoroughly.
Your summary should include the following sections:
1. Primary Request and Intent: Capture all of the user's explicit requests and intents in detail
2. Key Technical Concepts: List all important technical concepts, technologies, and frameworks discussed.
3. Files and Code Sections: Enumerate specific files and code sections examined, modified, or created. Pay special attention to the most recent messages and include full code snippets where applicable and include a summary of why this file read or edit is important.
4. Problem Solving: Document problems solved and any ongoing troubleshooting efforts.
5. Pending Tasks: Outline any pending tasks that you have explicitly been asked to work on.
6. Current Work: Describe in detail precisely what was being worked on immediately before this summary request, paying special attention to the most recent messages from both user and assistant. Include file names and code snippets where applicable.
7. Optional Next Step: List the next step that you will take that is related to the most recent work you were doing. IMPORTANT: ensure that this step is DIRECTLY in line with the user's explicit requests, and the task you were working on immediately before this summary request. If your last task was concluded, then only list next steps if they are explicitly in line with the users request. Do not start on tangential requests without confirming with the user first.
8. If there is a next step, include direct quotes from the most recent conversation showing exactly what task you were working on and where you left off. This should be verbatim to ensure there's no drift in task interpretation.
Here's an example of how your output should be structured:
<example>
<analysis>
[Your thought process, ensuring all points are covered thoroughly and accurately]
</analysis>
<summary>
1. Primary Request and Intent:
[Detailed description]
2. Key Technical Concepts:
- [Concept 1]
- [Concept 2]
- [...]
3. Files and Code Sections:
- [File Name 1]
- [Summary of why this file is important]
- [Summary of the changes made to this file, if any]
- [Important Code Snippet]
- [File Name 2]
- [Important Code Snippet]
- [...]
4. Problem Solving:
[Description of solved problems and ongoing troubleshooting]
5. Pending Tasks:
- [Task 1]
- [Task 2]
- [...]
6. Current Work:
[Precise description of current work]
7. Optional Next Step:
[Optional Next step to take]
</summary>
</example>
Please provide your summary based on the conversation so far, following this structure and ensuring precision and thoroughness in your response.
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐
 12
12 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)