
大模型赋能软件测试
传统痛点:报告数据堆砌,缺乏洞察。大模型能力自动生成自然语言摘要:“本次回归发现3个P0缺陷,集中在支付模块,建议优先修复”;对比多轮测试趋势,预警质量风险;输出给非技术人员的“业务影响说明”。✅ 工具示例:Allure + LLM 插件、Jenkins AI Reporter、自研 LangChain 报告引擎大模型正在重构软件测试的“生产力内核”——从“人驱动工具”变为“AI理解意图、自主执行
·
“大模型赋能软件测试”是当前软件工程智能化转型的核心方向之一。通过引入如 GPT、Claude、通义千问、盘古、CodeLlama 等大型语言模型(LLM)或多模态大模型,软件测试正从“脚本驱动”迈向“语义理解+自主决策+自适应执行”的智能时代。
🎯 一、大模型如何赋能软件测试?
1. 测试用例智能生成
- 传统痛点:人工编写耗时、易遗漏边界场景。
- 大模型能力:
- 根据需求文档/用户故事/接口定义 → 自动生成结构化测试用例;
- 支持等价类、边界值、异常流、并发场景等组合生成;
- 可输出为 Excel、TestRail、Xmind 或直接转为自动化脚本。
- ✅ 工具示例:华为 TestMate、阿里云通义灵码、TestGPT、Prompt2Test
示例 Prompt:“根据以下登录接口文档,生成包含正常、异常、安全边界的10条测试用例。”
2. 自动化脚本辅助编写与转换
- 传统痛点:脚本语法门槛高、维护成本大。
- 大模型能力:
- 自然语言 → Selenium/Appium/Pytest 脚本;
- 老脚本重构、跨框架迁移(如从 RobotFramework → Playwright);
- 自动补全 Page Object 模式代码。
- ✅ 工具示例:GitHub Copilot(测试脚本)、通义灵码、Tabnine + 测试插件
示例:“请用 Python + pytest 写一个测试:验证用户登录失败后提示‘用户名或密码错误’。”
3. 缺陷智能分析与根因推荐
- 传统痛点:日志繁杂、复现路径不清晰、归类主观。
- 大模型能力:
- 自动聚类相似缺陷;
- 分析崩溃日志 → 推测可能原因(如空指针、权限不足);
- 关联历史缺陷库 → 推荐修复方案或绕过策略。
- ✅ 工具示例:腾讯 WeTest 智能分析模块、BugPredict、Elastic + LLM 插件
4. 测试报告语义化总结
- 传统痛点:报告数据堆砌,缺乏洞察。
- 大模型能力:
- 自动生成自然语言摘要:“本次回归发现3个P0缺陷,集中在支付模块,建议优先修复”;
- 对比多轮测试趋势,预警质量风险;
- 输出给非技术人员的“业务影响说明”。
- ✅ 工具示例:Allure + LLM 插件、Jenkins AI Reporter、自研 LangChain 报告引擎
5. 探索性测试 & 智能遍历
- 传统痛点:手工探索效率低,自动化覆盖不到“未知路径”。
- 大模型能力:
- 基于 UI 或 API 文档,自主规划测试路径;
- 动态输入边界值、非法字符、并发请求;
- 结合强化学习优化探索策略。
- ✅ 工具示例:Applitools Ultrafast Test Cloud、Testim.io、OwlTest(字节)
6. 需求→测试双向追溯与缺口检测
- 传统痛点:需求变更未同步测试,导致漏测。
- 大模型能力:
- 解析 PRD/Jira 需求 → 映射到现有测试用例;
- 识别“无覆盖需求项”,自动建议补充用例;
- 支持变更影响分析:“修改订单状态机,需回归哪些测试?”
- ✅ 工具示例:IBM Engineering Test Management + Watson、国内 DevOps 平台集成 LLM
🛠️ 二、主流落地工具与平台
| 类别 | 工具/平台 | 大模型能力亮点 |
|---|---|---|
| 用例生成 | 华为 TestMate、TestGPT | 需求→用例→脚本一键转化 |
| 脚本辅助 | GitHub Copilot、通义灵码 | 自然语言生成/补全测试代码 |
| 执行与自愈 | Functionize、Testim.io | 元素定位自适应、失败自动修复 |
| 缺陷分析 | BugPredict、腾讯 WeTest | 日志聚类、根因推荐、修复建议 |
| 报告与洞察 | Allure+LLM、Jenkins AI 插件 | 自动生成业务级质量报告 |
| 智能探索 | Applitools、OwlTest | AI 遍历 App/Web,发现隐藏路径 |
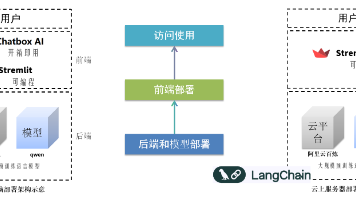
| 自主智能体 | LangChain + Selenium Agent | 多工具编排、自主决策、闭环反馈 |
🏗️ 三、企业落地架构建议(分阶段)
▶ 阶段1:辅助提效(低风险切入)
- 引入 Copilot / 通义灵码 辅助脚本编写;
- 用 TestGPT 生成部分模块测试用例;
- 在 Jenkins 中加入 LLM 生成测试报告摘要。
▶ 阶段2:流程嵌入(中台化)
- 集成 LLM 到需求管理系统(如 Jira),自动产出测试设计;
- 构建“AI测试中台”:统一管理 Prompt、模型、输出模板;
- 自动化流水线中加入“智能校验节点”(如日志异常检测)。
▶ 阶段3:智能体自治(高阶目标)
- 构建 QA Agent:可接收自然语言指令,自主完成“设计→执行→分析→报告”闭环;
- 与 DevOps 智能体联动:测试失败 → 触发自动回滚或通知开发;
- 实现“无人值守回归测试 + 智能质量门禁”。
⚠️ 四、挑战与应对
| 挑战 | 应对策略 |
|---|---|
| 幻觉/错误生成 | 设置校验规则、人工审核关键路径、RAG增强 |
| 数据安全与合规 | 私有化部署模型、脱敏处理、使用国产大模型 |
| 与现有工具链集成困难 | 提供标准化API、插件市场、低代码配置界面 |
| 模型推理成本高 | 缓存结果、异步处理、选用轻量模型(如 CodeLlama-7B) |
| 测试人员技能转型 | 提供 Prompt 工程培训、AI协作文档、人机协作SOP |
🔮 五、未来展望
“未来的测试工程师,不是写脚本的人,而是训练和指挥AI测试智能体的人。”
- 测试即服务(TaaS):通过对话获取测试能力 —— “帮我测一下最新版本的购物车并发性能”。
- 自我演进系统:测试智能体根据历史失败模式,主动增加监控点或压力场景。
- 质量预言机:在代码提交前,预测可能引发缺陷的变更,提前拦截。
- 全民测试时代:产品经理、运营也能通过自然语言发起测试任务。
✅ 总结一句话:
大模型正在重构软件测试的“生产力内核”——从“人驱动工具”变为“AI理解意图、自主执行、持续进化”。
—
📌 行动建议:
- 选1~2个痛点场景试点(如用例生成 or 脚本辅助);
- 选择成熟工具快速集成(推荐:通义灵码 + TestGPT);
- 建立 Prompt 资产库 + 效果评估机制;
- 逐步构建企业专属“测试大模型微调数据集”。
更多推荐
 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)