
大模型发展历史
大模型的发展并非一蹴而就,而是人工智能领域数十年理论探索与技术创新相互激荡的产物。这一历程不仅深刻改变了自然语言处理的技术范式,更推动人工智能从专用系统迈向通用智能的关键跨越。从早期统计语言模型的概率建模,到神经网络架构的革命性突破,再到百亿参数规模的通用大模型崛起,每个阶段的技术演进都伴随着计算能力提升、数据规模增长与算法创新的协同作用。整体而言,大模型的发展可以总结为以下4个阶段:统计语言模型
西电教授、博导鲍亮与西交教授、博导李倩诚意之作。
大模型的发展并非一蹴而就,而是人工智能领域数十年理论探索与技术创新相互激荡的产物。这一历程不仅深刻改变了自然语言处理的技术范式,更推动人工智能从专用系统迈向通用智能的关键跨越。从早期统计语言模型的概率建模,到神经网络架构的革命性突破,再到百亿参数规模的通用大模型崛起,每个阶段的技术演进都伴随着计算能力提升、数据规模增长与算法创新的协同作用。
整体而言,大模型的发展可以总结为以下4个阶段:统计语言模型奠基期(1950年~2010年)、神经网络语言模型探索期(2010年~2017年)、Transformer架构革命期(2017年~2019年)以及大模型爆发增长期(2020年~至今)。而如今所提到的大语言模型主要是指2020年以后以Transformer架构为基础提出的预训练(PLM)+微调(SFT)范式所催生出来的模型产物。
本节将沿着技术发展的时间轴线,系统梳理大模型从理论雏形到产业应用的完整发展脉络,揭示其背后的驱动因素与技术突破逻辑。
1.2.1 统计语言模型奠基期
人工智能发展初期,统计语言模型(Statistical Language Model,SLM)通过概率论方法对语言进行建模,成为自然语言处理的主流技术。以N-gram模型为代表,该类模型基于语料库中词语的共现频率计算语言序列概率,例如二元语法(Bigram)通过前一个词预测下一个词的出现概率[1]。虽然这种方法在机器翻译、语音识别等任务中取得了一定成功,但其依赖人工设计特征,难以处理长距离依赖和复杂语义,模型泛化能力有限。随着数据规模和计算需求的增长,统计语言模型的局限性逐渐凸显,为后续神经网络语言模型的兴起埋下伏笔。
1.2.2 神经网络语言模型探索期
2010年后,深度学习技术的快速发展为语言模型带来新的突破方向。循环神经网络(RNN)及其变体LSTM、GRU的出现,通过引入隐层状态循环机制,实现了对序列数据的动态建模,有效解决了统计语言模型的长距离依赖问题[6]。2013年提出的Word2Vec[17]和2014年的GloVe[18]模型,则通过无监督学习方法将词语映射为低维向量,开启了分布式语义表示的研究热潮。这些技术进步为后续预训练语言模型的发展奠定了基础,但RNN系列模型仍存在训练效率低、难以并行计算等问题,限制了模型规模的进一步扩展。
1.2.3 Transformer架构革命期
2017年,Transformer架构的提出成为大模型发展的重要分水岭。其创新性地使用自注意力机制替代循环结构,通过并行计算大幅提升训练效率,同时有效解决了长距离依赖问题[14]。基于Transformer架构的BERT(Bidirectional Encoder Representations from Transformers)在2018年横空出世,通过双向预训练和微调策略,在11个NLP任务上取得当时最优性能,标志着预训练-微调范式的正式确立[19]。2019年GPT-2的发布则展现了Transformer在生成任务上的强大潜力,其通过无监督学习训练的15亿参数模型,能够生成连贯且语义合理的长文本,引发学界和业界对大模型能力边界的重新思考。
1.2.4 大模型爆发增长期
2020年,OpenAI推出的GPT-3成为大模型发展的关键转折点,其拥有1750亿参数,以远超以往模型的规模,展现出卓越的少样本学习能力[20]。在少样本甚至零样本学习任务中,GPT-3能够依据给定的少量示例,对新任务做出合理推断,生成连贯且语义准确的文本,开启了模型规模增长引发“涌现”能力的研究热潮,即当模型参数达到一定量级后,会自发呈现出此前未被设计的复杂认知与推理能力。
随后,业界与学界积极投身大模型研发,促使大模型技术呈现爆发式增长,如图1.5所示[54]。2022年,Google推出PaLM(Pathways Language Model)[21],参数规模达5400亿,其基于Google自研的Pathways系统构建,具备强大的可扩展性,在自然语言处理的各类任务中表现出色,尤其在语言翻译、复杂文本生成等方面,展现出高准确性与流畅性,进一步证明了超大规模参数模型在提升性能上的潜力。同年,DeepMind发布Chinchilla[22],虽然参数规模(700亿)小于PaLM,但通过优化训练数据质量与规模(使用高达1.4万亿token的数据集),在模型效率与性能平衡上取得突破,在多项基准测试中超越了同等规模的其他模型,凸显了优质数据对模型训练的关键作用。
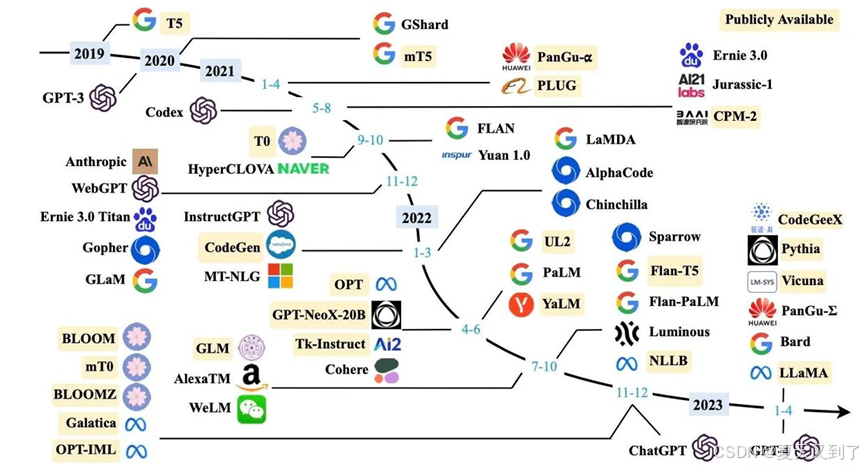
图1.5 大模型发展历程(2020年~2023年)
2022年11月,OpenAI的ChatGPT横空出世,它基于GPT-3.5模型[23]微调而成,通过引入人类反馈强化学习(Reinforcement Learning fromHuman Feedback, RLHF)技术,极大提升了模型与人类交互的自然性和准确性,能够根据用户提问,生成贴合语境、逻辑连贯的回答,迅速引发全球关注,推动大模型从实验室研究走向大众应用,开启了大模型商业化的新篇章。2023年,OpenAI发布的GPT-4更是具备多模态理解能力,不仅能处理文本,还可对图像输入做出响应,如理解图片内容并基于此生成描述、解答相关问题等,在复杂任务处理、知识推理等方面的性能进一步提升,成为当时最先进的多模态大模型之一,图1.6展示了GPT家族模型演进路线[24][54]。
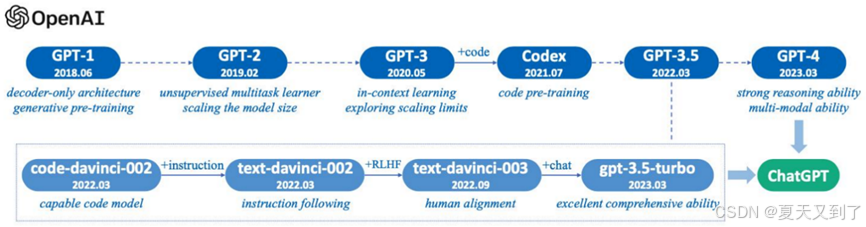
图1.6 GPT系列模型演进路线
国内的大模型研发也在这一时期蓬勃发展,从图1.7中可以看出[54],虽然国内厂商入场较晚,但呈现出后来者居上的气势。百度的文心一言于2023年发布,基于ERNIE 3.0框架[25],聚焦于知识增强大模型,通过融合大量知识图谱信息,在知识问答、文本创作等任务中表现突出,助力企业与开发者在智能写作、智能客服等领域实现高效应用开发。阿里巴巴的通义千问[26]同样具备强大的语言生成与理解能力,在电商、金融等垂直领域深入布局,为行业定制化解决方案提供底层技术支撑。
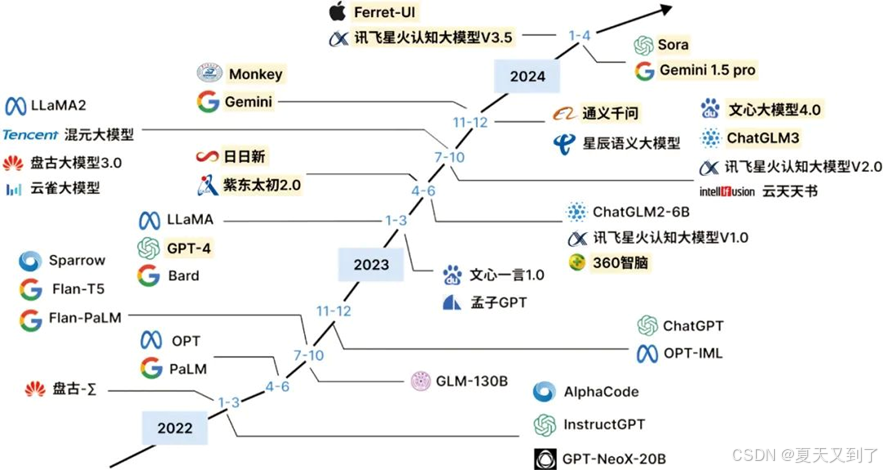
图1.7 大模型发展历程(2022—2024)
2024年~2025年,大模型技术持续迭代创新。字节跳动的豆包[27]模型不断升级,如1.5版本推出的“深度思考模型”及其视觉版本,在数学推理、编程竞赛、科学推理等专业领域成绩优异,其视觉版本能结合多源信息深度理解图像内容,实现如通过航拍地貌推理地理位置等复杂任务。科大讯飞的星火X1作为全国产算力训练的深度推理大模型[28],首发“快思考”与“慢思考”统一架构,可根据任务需求灵活切换模式,在语言理解、文本生成、数学答题、代码生成等通用任务上全面升级,且多模态推理能力在教育、医疗、司法等行业得到深化应用。昆仑万维的天工系列大模型[29]不断演进,从2.0版本通过动态任务分配提升复杂任务处理效率,到3.0版本以4000亿参数成为全球规模领先的开源混合专家(MoE[30])模型[31],再到4.0版本实现实时语音交互与慢思考推理突破,在底层架构创新与多模态技术融合上持续探索。
开源社区在这一时期也发挥了重要推动作用。Meta的LLaMA模型[31]开源后,激发了全球开发者基于其进行二次开发与优化,衍生出众多性能优异的变体模型,降低了大模型的使用门槛,促进技术普及,图1.8展示了LLaMA家族模型的演进与发展路线[54]。Stable Diffusion[32]作为开源的文本生成图像大模型,引发了生成式AI在图像领域的应用热潮,为艺术创作、设计等行业提供了全新的创作工具与思路,推动大模型技术在多模态应用领域的广泛拓展。
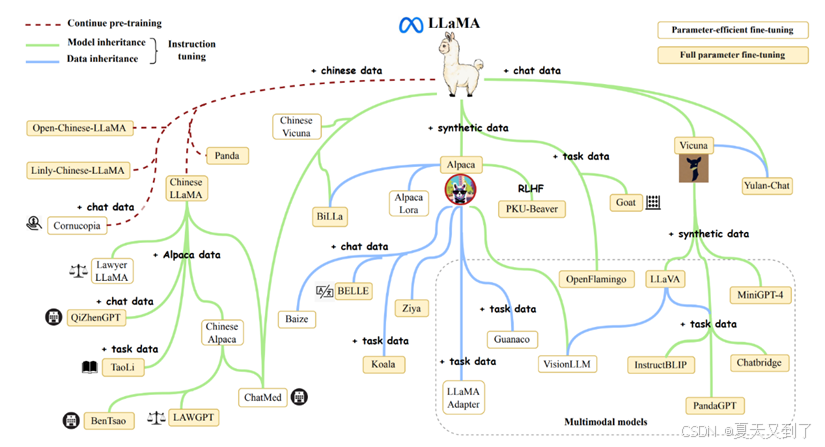 图1.8 LLaMA系列模型演进路线
图1.8 LLaMA系列模型演进路线
这一阶段,大模型在性能提升的同时,产业落地进程加速。在教育领域,大模型助力个性化学习方案制定、智能辅导[33][34][35];医疗行业中,辅助医生进行疾病诊断、医学文献分析[36][37];金融领域里,用于风险评估、智能投顾等[38][39]。大模型正逐步渗透到各行业核心业务流程,重塑产业格局,成为推动社会数字化转型的关键技术力量。


更多推荐
 32
32 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)