
flume的使用
Flume 是一个分布式、高可靠、高可用的日志收集系统,主要用于高效地聚合、移动大量日志数据。其核心架构基于Agent,由SourceChannel和Sink三个组件构成,支持数据流的灵活配置。
Flume 简介
Flume 是一个分布式、高可靠、高可用的日志收集系统,主要用于高效地聚合、移动大量日志数据。其核心架构基于Agent,由Source、Channel和Sink三个组件构成,支持数据流的灵活配置。
Flume 核心组件
Source
负责从数据生成端(如日志文件、Kafka、HTTP请求等)接收数据,常见类型包括:
exec:通过命令行(如tail -F)读取数据。spooldir:监控指定目录的新文件。netcat:监听网络端口。
Channel
临时存储事件数据,保证数据传输的可靠性。常用类型:
memory:高速但易丢失(宕机时数据不持久)。file:基于磁盘存储,可靠性高。
Sink
将数据从 Channel 写入目标(如 HDFS、Kafka、HBase)。常见类型:
hdfs:写入 Hadoop HDFS。logger:日志输出(测试用)。kafka:推送至 Kafka 主题。
安装与配置
- 下载与解压
从 Apache Flume 官网下载二进制包,解压后配置环境变量:
export FLUME_HOME=/path/to/flume
export PATH=$PATH:$FLUME_HOME/bin
- 配置文件
创建 Agent 配置文件(如example.conf),定义 Source、Channel、Sink:
# 定义 Agent 组件名称
agent1.sources = src1
agent1.channels = ch1
agent1.sinks = sk1
# 配置 Source(监听端口数据)
agent1.sources.src1.type = netcat
agent1.sources.src1.bind = 0.0.0.0
agent1.sources.src1.port = 44444
# 配置 Channel(内存通道)
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity = 1000
# 配置 Sink(日志输出)
agent1.sinks.sk1.type = logger
# 绑定组件
agent1.sources.src1.channels = ch1
agent1.sinks.sk1.channel = ch1
启动与测试
- 启动 Agent
通过flume-ng命令运行 Agent:
flume-ng agent --conf conf --conf-file example.conf --name agent1 -Dflume.root.logger=INFO,console
- 发送测试数据
使用netcat工具向配置的端口发送数据:
echo "Hello Flume" | nc localhost 44444
- 验证输出
在 Flume 控制台日志中查看接收的数据:
Event: { headers:{} body: 48 65 6C 6C 6F 20 46 6C 75 6D 65 Hello Flume }
案例展示
1) Exec + Memory + HDFS

以下版本演示的是没有时间语义的案例:
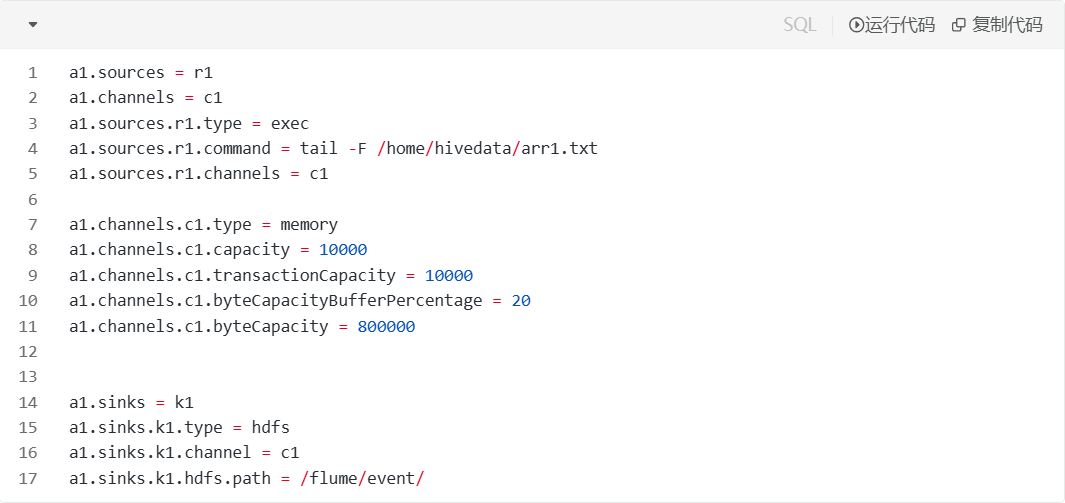
接着我们演示hdfs文件中含有时间转义字符怎么办?
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /home/hivedata/heros.txt
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
假如hdfs中有时间转义字符,必须给定时间,给定时间有两种方式,要么通过header 传递一个时间,要么使用本地时间。
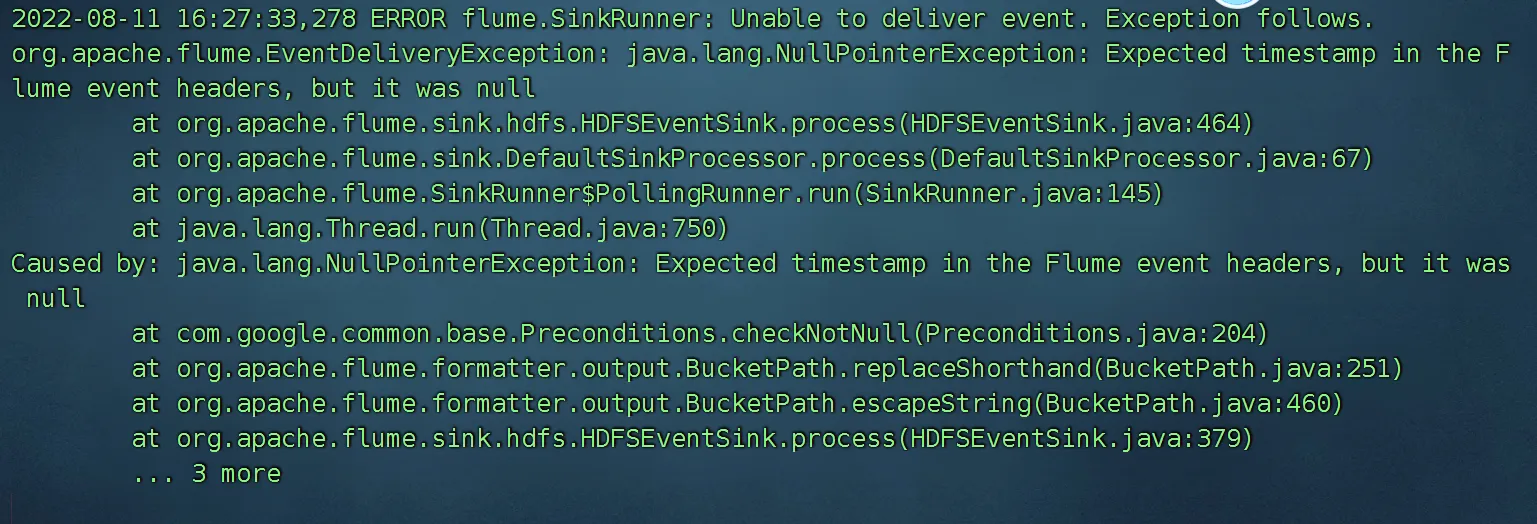
假如hdfs中使用了时间转义字符,配置文件中必须二选一:
1)useLocalTimeStamp=true
2)使用时间戳拦截器
为啥呀:
时间需要转义,没有时间无法翻译为具体的值 %d 就无法翻译为 日期
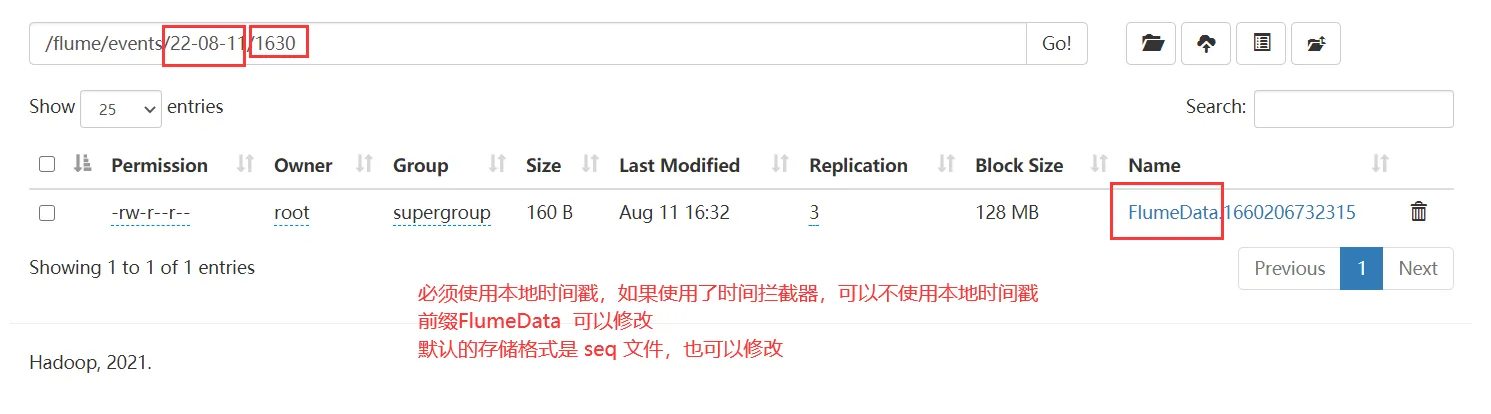
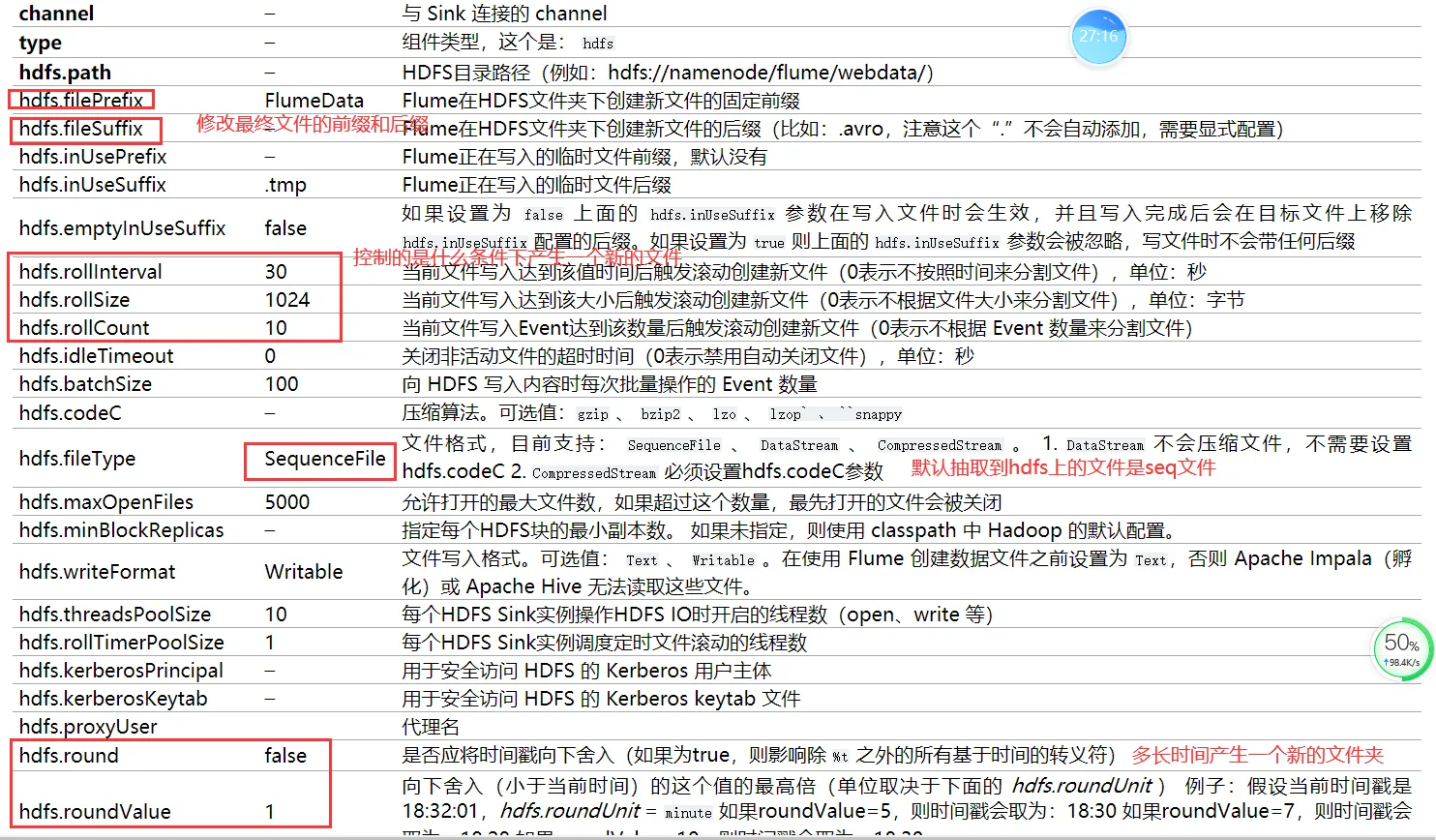
如何实现不断的向a.txt中存入数据的效果呢?
echo "Hello World" >> a.txt
运行我们的脚本:
flume-ng agent -c ./ -f exec-memory-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
高级用法
多 Agent 级联
通过配置多个 Agent 实现数据接力传输。例如:
- Agent1 的 Sink 类型为
avro,指向 Agent2 的 Source。 - Agent2 的 Source 类型为
avro,监听 Agent1 的 Sink 端口。
拦截器(Interceptor)
在 Source 和 Channel 之间插入拦截器,对事件进行过滤或修改:
agent1.sources.src1.interceptors = i1
agent1.sources.src1.interceptors.i1.type = timestamp
负载均衡与故障转移
通过 load_balance 或 failover 策略配置多个 Sink,提升可靠性。
常见问题
- Channel 容量不足
调整capacity和transactionCapacity参数,避免数据积压。 - HDFS Sink 写入失败
检查 Hadoop 集群状态及权限,确保 Flume 有 HDFS 写入权限。 - 内存溢出
使用fileChannel 替代memoryChannel,或增加 JVM 堆内存。
通过合理配置组件和策略,Flume 能够适应复杂的日志收集场景,兼顾性能与可靠性。
更多推荐

 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)