
Agent实战02-agent(智能体)入门案例LlamaIndex
Agent(智能体)
简述
可以把一个 Agent想象成一个数字世界的“虚拟员工。它不仅仅是简单地回答问题(像 ChatGPT 那样),而是被赋予了一个目标,并能够自主调用工具(Tools) 来完成任务。
一个智能体的核心三要素是:
- 大脑(Brain):一个大语言模型(LLM),负责规划、决策和生成。
- 工具(Tools):它可以调用的外部能力,比如:执行网络搜索、读写数据库、运行代码、调用 API。
- 记忆(Memory):记住之前的对话和操作,从而进行连贯的多步任务。
普通聊天 vs. Agent 的区别:
- 你问 ChatGPT:“现在旧金山天气怎么样?” -> 它可能基于过时的训练数据猜测一个答案。
- 你问一个 Weather Agent:“现在旧金山天气怎么样?” -> 这个 Agent 的大脑(LLM)会决定需要调用一个工具(天气查询 API),它自主地去调用这个工具获取实时数据,然后组织语言告诉你准确的结果。
LlamaIndex基础
学习目的
想象一下,你有一个巨大的私人文档库(PDF、Word、PPT)、公司内部Wiki、或者一堆网页和笔记。你希望像与 ChatGPT 聊天一样,随时向这些资料提问并获得精准的答案。例如:
- “帮我找出公司去年 Q3 财报中关于市场营销支出的部分?”
- “我所有的读书笔记中,关于‘元宇宙’的观点有哪些?”
- “根据我的代码文档,
User类应该怎么使用?”
LlamaIndex 正是为了解决这个问题而生的。 它的核心目的就是将你的私有数据和大型语言模型(LLM)智能地连接起来,构建强大的检索增强生成(RAG) 应用。
LlamaIndex 问答系统,本身就是一个最简单、最典型的 Agent 应用!它是理解更复杂 Agent 的完美基石。
它完美体现了 Agent 的核心工作流:
- 目标:回答用户关于私人文档的问题。
- 大脑:你本地运行的 Llama 3 模型或者其他在线模型。
- 核心工具:LlamaIndex 提供的“检索工具”。这个工具能让大脑去“翻阅”那些它本来不知道的、庞大的私人文档。
- 过程:大脑(LLM)接收到问题后,自动决定需要先调用“检索工具”找到相关文档片段,然后再基于这些片段生成最终答案。
你能学到什么?
通过学习 LlamaIndex,你将掌握:
- RAG(检索增强生成)的核心工作流:理解如何通过“检索”相关文档片段来“增强”LLM的生成效果,使其回答更具事实性、更相关。
- 数据连接与加载(Data Connectors):学会如何从各种数据源(PDF、网页、数据库、Notion等)加载数据。
- 索引(Indexing)的核心概念:学会如何将非结构化的文本数据结构化,创建便于快速查询的“索引”。
- 查询(Querying)的艺术:不仅仅是简单问答,还能实现摘要、结构化提取等复杂查询。
- 构建端到端的AI应用:你将有能力打造一个属于你自己的、基于私有知识的“智能问答机器人”或“AI助手”。
一句话总结:学 LlamaIndex,就是学如何用代码让你的AI模型“学会”阅读你的私人资料并回答问题。
核心概念
在编码之前,先理解三个最核心的概念:
-
加载器 (Loader):
LlamaIndex提供了各种Loader,就像一个个适配器,负责从不同数据源(如PDF、网页、Word文件)读取数据,并将其转换成统一的Document对象(包含文本和元数据)。 -
索引 (Index):这是
LlamaIndex的核心。索引的作用是将长长的Document分解成更小的“块”(Node),并通过嵌入模型(Embedding Model) 为每个块生成一个数学向量(Vector)。这些向量代表了文本的语义,并被存储在向量数据库中。这个过程使得我们可以根据“含义”而不仅仅是关键词来快速查找相关内容。 -
查询引擎 (Query Engine):这是你与索引交互的接口。当你提出一个问题时,查询引擎会:
- 将你的问题也转换成向量。
- 在索引中快速查找与问题向量最相似的文本块(
Node)。 - 将这些相关的文本块和你的问题一起组合成一个“增强的提示(Prompt)”,发送给LLM。
- 将LLM生成的最终答案返回给你。
实战例子
我们将使用 Ollama 本地运行的 Llama 3 模型和 LlamaIndex 来创建一个能读取本地文本文件并回答问题的应用。
安装环境
确保你已经安装了 Ollama 并拉取了 llama3 模型(如前文教程所示)。然后安装必备的Python库:
# 安装 LlamaIndex 和它的基础依赖
pip install llama-index-core llama-index-readers-file llama-index-embeddings-huggingface "llama-index-llms-ollama==0.1.2"
# 如果你使用国内镜像,可以用:
pip install llama-index-core llama-index-readers-file llama-index-embeddings-huggingface "llama-index-llms-ollama==0.1.2"
# pip install llama-index-core llama-index-readers-file llama-index-embeddings-huggingface "llama-index-llms-ollama==0.1.2" -i https://pypi.tuna.tsinghua.edu.cn/simple
测试环境
编写一个调用ollama模型的例子
from llama_index.llms.ollama import Ollama # 导入专门的Ollama集成模块
llm = Ollama(
model="llama3", # 指定Ollama中已下载的模型名称
base_url="http://localhost:11434", # Ollama服务的地址,默认就是本地的11434端口
request_timeout=120.0, # 超时时间设长一些,因为本地推理可能需要更久
)
print(llm.complete("你好!,介绍下你自己"))
如果正常输出表示包安装成功。
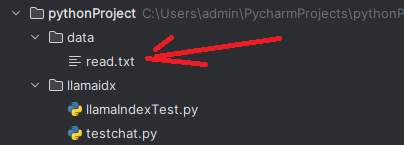
准备知识文档
- 在你的项目文件夹下(例如
my_llamaindex_project),创建一个名为data的文件夹。 - 在
data文件夹中,创建一个名为read.txt的文本文件,并输入一些内容。例如:
公司福利政策
============
年度假期:所有正式员工享有每年15天的带薪年假。
健康保险:公司为员工提供全面的健康、牙科和视力保险计划。
远程办公:员工每周可选择最多两天在家远程办公。
学习发展:公司每年为每位员工提供最高5000元的专业培训和学习经费补贴。
技术栈介绍
==========
后端主要使用 Python 和 FastAPI 框架。
前端主要使用 React 和 TypeScript。
数据库使用 PostgreSQL 和 Redis。
我们的代码托管在内部的 GitLab 服务器上。
编写代码
创建一个名为 llamaIndexTest.py 的Python文件,并写入以下代码。代码中的注释非常重要,请仔细阅读。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import logging
# 启用详细日志,方便看到背后发生了什么(调试时非常有用)
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
# 1. 配置 LLM 和 Embedding 模型
# 告诉 LlamaIndex 使用我们本地 Ollama 的 LLM
Settings.llm = Ollama(model="llama3", request_timeout=60.0)
# 告诉 LlamaIndex 使用一个本地的嵌入模型来生成向量
# 这个模型会自动下载(约几百MB),用于将文本转换为数学向量
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5" # 一个高效且流行的开源嵌入模型
)
# 2. 加载数据 - 使用加载器 (Loader)
print("正在加载文档...")
# SimpleDirectoryReader 会读取指定文件夹下的所有文件
documents = SimpleDirectoryReader("./data").load_data()
print(f"已加载 {len(documents)} 个文档。")
# 3. 构建索引 (Index) - 核心步骤!
print("正在构建索引(这可能需要一些时间)...")
# VectorStoreIndex 会自动完成:将文档分块 -> 为每块生成向量 -> 存储
index = VectorStoreIndex.from_documents(documents)
print("索引构建完成!")
# 4. 创建查询引擎 (Query Engine)
print("创建查询引擎...")
query_engine = index.as_query_engine() # 默认的、强大的查询接口
print("引擎就绪,请输入你的问题(输入 'quit' 退出):")
# 5. 交互式问答循环
while True:
query = input("\n问题: ")
if query.lower() == 'quit':
break
print("思考中...")
# 这里是魔法发生的地方!
# 查询引擎会:检索相关文本 -> 组合成Prompt -> 发送给LLama3 -> 返回答案
response = query_engine.query(query)
print(f"\n答案: {response}")
输出:
D:\python\python380\python.exe C:\Users\admin\PycharmProjects\pythonProject\llamaidx\llamaIndexTest.py
您的文档中主要讲了公司福利政策和技术栈介绍。
其他问题
response = query_engine.query("公司的年假有多少天?")
输出
D:\python\python380\python.exe C:\Users\admin\PycharmProjects\pythonProject\llamaidx\llamaIndexTest.py
15天。
试试这些问题吧!
- “公司的年假有多少天?”
- “远程办公政策是怎样的?”
- “我们使用什么前端技术?”
- “公司有什么和学习发展相关的福利?”
你会看到,LlamaIndex 驱动下的 Llama 3 模型,能够精准地从你提供的 read.txt 文件中找到相关信息并生成准确的回答!
优化向量
在上面例子中,每次运行脚本都会重新加载文档、重新生成向量索引,这是一个非常低效的过程。
对于实际应用来说,这样做是不可接受的,因为:
- 耗时:每次都要重新读取文件、分块、并通过嵌入模型计算向量,尤其文档量大时非常慢。
- 浪费算力:重复计算相同的向量,白白消耗CPU/GPU资源。
- 无法增量更新:如果只是新增了一个文档,却要重新处理所有旧文档。
正确的做法:持久化存储索引
LlamaIndex 的核心优势之一就是能够轻松地将索引保存(持久化)到磁盘,并在下次运行时直接加载,无需重新处理文档。
修改后的完整代码(带持久化功能)
我们将使用 SimpleVectorStore 和 StorageContext 来管理索引的存储。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings, StorageContext
from llama_index.core import load_index_from_storage
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import os
# 配置 LLM 和 Embedding 模型
Settings.llm = Ollama(model="llama3", request_timeout=120.0)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# 定义存储索引的目录
PERSIST_DIR = "./storage"
def get_index():
"""
获取索引:如果已存在则直接加载,否则创建并保存
"""
# 检查存储目录是否存在
if not os.path.exists(PERSIST_DIR):
# 1. 目录不存在,说明需要创建新索引
print("首次运行,正在创建索引...")
# 加载文档
documents = SimpleDirectoryReader("./data").load_data()
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 将索引保存到指定目录
index.storage_context.persist(persist_dir=PERSIST_DIR)
print(f"索引已创建并保存至: {PERSIST_DIR}")
return index
else:
# 2. 目录已存在,直接加载现有索引
print("检测到已有索引,正在加载...")
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
print("索引加载完成!")
return index
# 主程序
if __name__ == "__main__":
# 获取索引(自动判断是加载还是创建)
index = get_index()
# 创建查询引擎
query_engine = index.as_query_engine()
# 进行查询
while True:
query = input("\n请输入你的问题 (输入 'quit' 退出): ")
if query.lower() == 'quit':
break
response = query_engine.query(query)
print(f"\n答案: {response}")
这段代码的工作原理:
-
第一次运行时:
- 检查
./storage目录不存在。 - 它会读取
./data下的文档,花费时间构建向量索引。 - 构建完成后,将整个索引(包含文本块、向量、元数据等)保存到
./storage目录。 - 然后才进行问答。
- 检查
-
第二次及以后运行时:
- 检测到
./storage目录已存在。 - 直接跳过耗时的文档加载和向量化过程,直接从磁盘加载已生成的索引。
- 几乎是瞬间就进入问答环节,效率极高。
- 检测到
深入学习“Tools”
核心概念:Function Calling
功能演示:创建一个能查询天气和执行计算的智能体
创建一个新文件,例如 function_demo.py,并写入以下代码:
from llama_index.core.tools import FunctionTool
from llama_index.core.agent import AgentRunner
from llama_index.llms.ollama import Ollama
import math
# 1. 配置LLM - 使用本地Ollama的模型
llm = Ollama(
model="llama3", # 指定Ollama中已下载的模型名称
base_url="http://localhost:11434", # Ollama服务的地址,默认就是本地的11434端口
request_timeout=120.0, # 超时时间设长一些,因为本地推理可能需要更久
)
# 2. 定义工具函数 (Tools)
# 工具函数 1: 获取天气(这里模拟实现,真实场景会调用天气API)
def get_weather(city: str) -> str:
"""
根据给定的城市名称获取该城市的当前天气信息。
Args:
city (str): 城市的名称,例如 "北京", "San Francisco"。
Returns:
str: 城市的天气描述字符串。
"""
# 这里应该是调用真实天气API的代码,例如 OpenWeatherMap
# 为了演示,我们返回一个模拟数据
weather_data = {
"beijing": "22°C,晴天,微风",
"san francisco": "15°C,多云,西北风3级",
"new york": "18°C,小雨,东风2级",
"shanghai": "25°C,局部多云,东南风1级"
}
city_lower = city.lower()
# 获取天气,如果城市不在字典中,返回一个默认消息
return weather_data.get(city_lower, f"未找到{city}的天气信息,请检查城市名称是否正确。")
# 工具函数 2: 执行数学计算
def calculator(expression: str) -> str:
"""
执行一个数学计算表达式并返回结果。支持加减乘除、乘方和平方根。
例如: "2 + 3 * 4", "sqrt(16)", "2 ** 10"
Args:
expression (str): 数学表达式字符串。
Returns:
str: 计算结果或错误信息。
"""
try:
# 安全地评估数学表达式
# 注意:在生产环境中,直接使用eval可能有安全风险,这里仅作演示
result = eval(expression, {"__builtins__": None}, {"math": math})
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {str(e)}。请检查表达式格式。"
# 3. 将普通函数包装成LlamaIndex能识别的FunctionTool
weather_tool = FunctionTool.from_defaults(
fn=get_weather,
name="get_weather",
description="根据城市名称查询当前的天气情况和温度。"
)
calculator_tool = FunctionTool.from_defaults(
fn=calculator,
name="calculator",
description="执行一个数学计算表达式,支持加减乘除(+, -, *, /)、乘方(**)和平方根(math.sqrt)。"
)
# 4. 创建智能体 (Agent),并赋予它工具
agent = AgentRunner.from_llm(
llm=llm,
tools=[weather_tool, calculator_tool], # 将工具列表传给智能体
verbose=True # 显示详细过程,便于观察学习
)
# 5. 与智能体对话
if __name__ == "__main__":
print("智能体已启动!我可以帮你查询天气和执行计算。输入 'quit' 退出。")
while True:
try:
user_input = input("\n你的问题: ")
if user_input.lower() == 'quit':
break
# 将用户输入发送给智能体
response = agent.query(user_input)
print(f"\n智能体: {response}")
except Exception as e:
print(f"发生错误: {e}")
在终端运行你的脚本:
现在,你可以尝试提出各种需要“动手操作”的问题:
测试天气查询:
- “北京今天天气怎么样?”
- “查询一下旧金山的天气。”
- “帮我看看巴黎的天气。”(测试未知城市)
测试数学计算:
- “计算一下 125 乘以 88 等于多少?”
- “2的10次方是多少?”
- “16的平方根加上5乘以3等于多少?”
测试混合推理(最精彩的部分!):
-
“如果北京气温是22度,旧金山是15度,两地温差是多少度?”
- (它会先调用两次天气工具,提取出温度数字,再调用计算工具算出差值!)
观察输出(得益于 verbose=True)
当你提问时,控制台会打印出详细的思考过程,这是学习 Agent 如何工作的绝佳方式:
> 用户: 如果北京气温是22度,旧金山是15度,两地温差是多少度?
> 思考: 用户想知道北京和旧金山的温差。我需要先获取这两个城市的天气信息,提取出温度值,然后计算它们的差值。
> 动作: get_weather
> 动作输入: {"city": "北京"}
< 观察: 22°C,晴天,微风
> 思考: 我得到了北京的温度是22°C。现在需要获取旧金山的温度。
> 动作: get_weather
> 动作输入: {"city": "San Francisco"}
< 观察: 15°C,多云,西北风3级
> 思考: 我得到了北京22°C,旧金山15°C。现在需要计算它们的温差:22 - 15。
> 动作: calculator
> 动作输入: {"expression": "22 - 15"}
< 观察: 计算结果: 7
> 思考: 计算出的温差是7度。现在可以给用户回答了。
< 最终响应: 北京和旧金山的温差是7摄氏度。北京为22°C,旧金山为15°C。
通过这个演示,你学到了:
- 定义工具:如何用
FunctionTool.from_defaults()将普通Python函数包装成智能体可用的工具。 - 创建智能体:如何使用
AgentRunner将LLM和工具组合成一个能自主决策的智能体。 - 观察思考过程:如何通过
verbose=True查看智能体的“内心独白”,理解它是如何规划、调用工具并整合结果的。
QueryEngineTool (查询引擎工具)
这是 LlamaIndex 中极其强大和常用的工具。它允许你将整个查询引擎(Query Engine) 本身包装成一个工具。
这意味着你的 Agent 可以"雇佣"另一个专业的检索专家来帮它回答问题。
适用场景:让 Agent 能够查询特定的文档集、数据库或其他知识源。
from llama_index.core.tools import QueryEngineTool
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 创建一个查询引擎(比如针对公司手册)
documents = SimpleDirectoryReader("./company_docs").load_data()
company_index = VectorStoreIndex.from_documents(documents)
company_engine = company_index.as_query_engine()
# 将查询引擎包装成工具
company_handbook_tool = QueryEngineTool.from_defaults(
query_engine=company_engine,
name="company_handbook",
description="用于查询公司员工手册和政策文档。"
)
# 现在Agent可以这样使用:"查询一下公司年假政策是什么?"
agent = AgentRunner.from_llm(
llm=llm,
tools=[company_handbook_tool ], # 将工具列表传给智能体
verbose=True # 显示详细过程,便于观察学习
)
Agent记忆
下面将提供一个完整为 QueryEngineTool 加上记忆功能是构建复杂 Agent 的关键一步。这里的关键是要理解记忆发生在两个层面:
- Agent 层面的记忆:记住整个对话历史(多轮对话的上下文)。
- Query Engine 层面的记忆:记住在单个查询会话中的上下文。
下面是完整的实现方法:
from llama_index.core.tools import QueryEngineTool
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import os
# 1. 配置全局设置
Settings.llm = Ollama(model="llama3", request_timeout=120.0)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# 2. 创建带记忆的查询引擎
def create_query_engine_with_memory():
"""
创建一个带有记忆功能的查询引擎
"""
# 加载文档
documents = SimpleDirectoryReader("./company_docs").load_data()
company_index = VectorStoreIndex.from_documents(documents)
# 为查询引擎创建独立的记忆缓冲区
query_memory = ChatMemoryBuffer.from_defaults(token_limit=1500)
# 创建带有记忆的查询引擎
company_engine = company_index.as_query_engine(
memory=query_memory, # 关键:为查询引擎注入记忆
similarity_top_k=3, # 每次检索最相关的3个片段
verbose=True # 显示查询过程的详细信息
)
return company_engine
# 3. 将查询引擎包装成工具
company_engine = create_query_engine_with_memory()
company_handbook_tool = QueryEngineTool.from_defaults(
query_engine=company_engine,
name="company_handbook",
description="用于查询公司员工手册、政策文档和规章制度。请提供具体的问题。"
)
# 4. 创建Agent层面的记忆(这是另一个独立的记忆系统)
agent_memory = ChatMemoryBuffer.from_defaults(
chat_history=[],
token_limit=3000 # Agent记忆可以更大,记住更多轮对话
)
# 5. 创建能够使用这个工具的Agent(这里需要其他工具一起)
from llama_index.agent import ReActAgent
# 假设我们还有其他工具
all_tools = [company_handbook_tool] # 可以加入更多工具...
# 创建带有记忆的Agent
agent = ReActAgent.from_tools(
tools=all_tools,
llm=Settings.llm,
memory=agent_memory, # Agent层面的记忆
verbose=True
)
# 6. 测试对话
def test_agent():
print("📚 公司文档查询助理已启动!")
print("💡 你可以询问公司手册中的相关内容")
test_queries = [
"公司年假政策是怎样的?",
"详细的申请流程是什么?", # 这里会利用记忆,知道"申请流程"指的是年假的申请流程
"医疗报销的政策呢?",
"总结一下刚才我们讨论的年假政策" # 这里会利用Agent的记忆来总结对话
]
for query in test_queries:
print(f"\n👤 用户: {query}")
response = agent.chat(query)
print(f"🤖 助理: {response}")
if __name__ == "__main__":
test_agent()
两个层面记忆的工作方式
Query Engine 记忆(query_memory)
- 作用:在单个工具调用过程中保持上下文。
- 示例:
用户: "公司年假政策是怎样的?"
-> Agent调用company_handbook_tool
-> Query Engine检索相关内容并返回答案
用户: "详细的申请流程是什么?"
-> Agent再次调用company_handbook_tool
-> Query Engine会记得刚才在讨论年假,所以会优化检索:"年假 申请流程"
Agent 记忆(agent_memory)
- 作用:记住整个对话历史,包括哪些工具被调用过、返回了什么结果。
- 示例:
用户: "公司年假政策是怎样的?"
助理: (调用工具并返回年假信息)
用户: "医疗报销的政策呢?"
助理: (调用工具并返回医疗报销信息)
用户: "总结一下刚才我们讨论的政策"
-> Agent不需要调用工具,直接从自己的记忆中找到对话历史
-> 总结出:"我们讨论了年假政策(15天带薪假)和医疗报销政策(90%报销比例)"
总结
通过这个完整的教程,你已经:
- 理解了Agent概念, LlamaIndex 的价值:连接私有数据与LLM。
- 学会了核心概念:加载器(Loader)、索引(Index)、查询引擎(Query Engine)。
- 完成了一个实战项目:构建了一个本地的、基于私有文本文件的问答系统。
- 完成了一个智能体项目(tools使用):构建了一个完整的智能体系统(functioncall,memory等)。
这就是 LlamaIndex 的强大之处。你现在可以尝试:
- 用
PDFReader加载 PDF 文件。 - 尝试不同的查询,比如“请总结一下技术栈部分。”
- 探索 LlamaIndex 的更多功能,如结构化输出、多文档代理等。
你已经成功踏入了构建高级 AI Agent 的大门!
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)