
多模态大模型相关概述
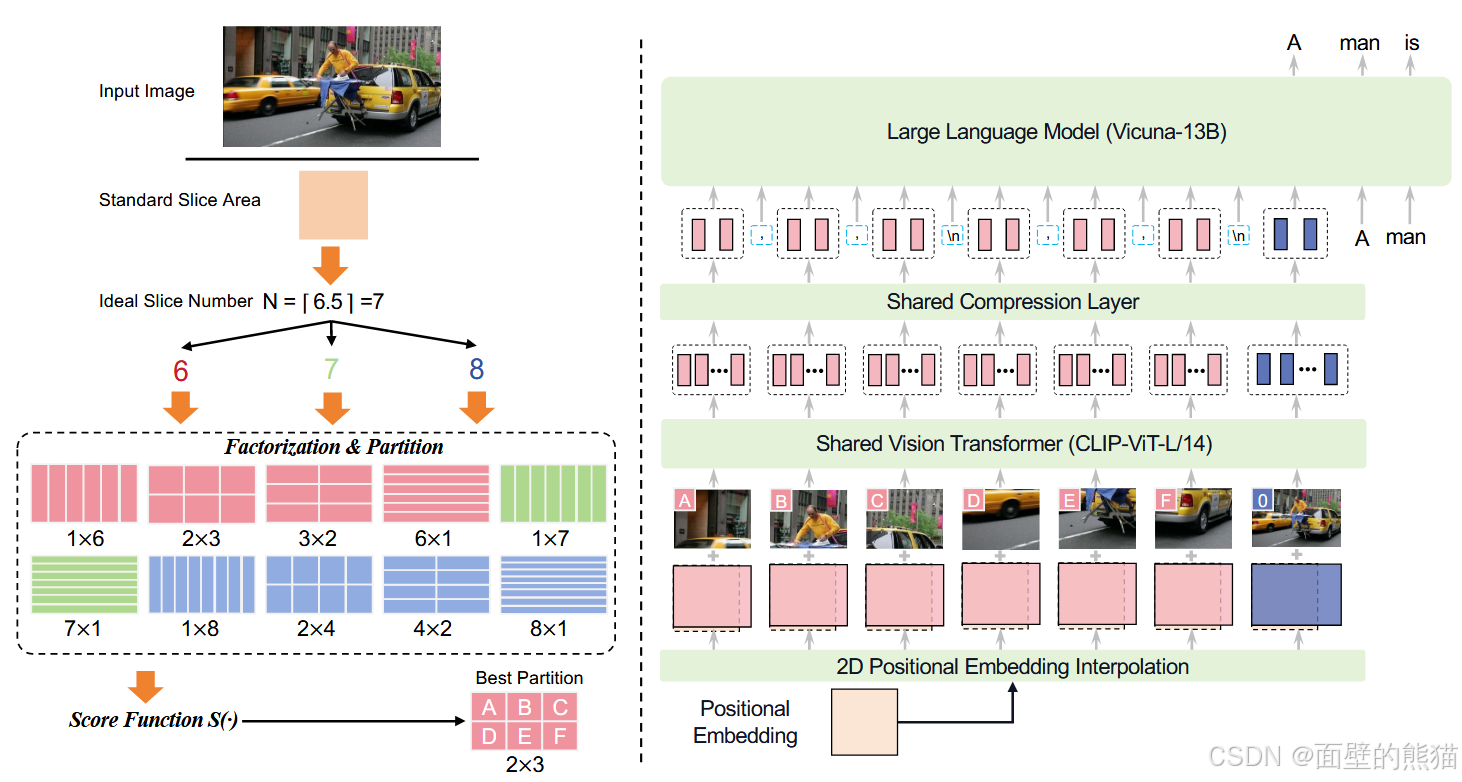
支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像。图像压缩层,引入一个单层交叉注意力层和一层可训练的query emb。压缩token长度到query emb。
文章目录
多模态大模型相关概述
Prequisite
视觉大模型
ViT
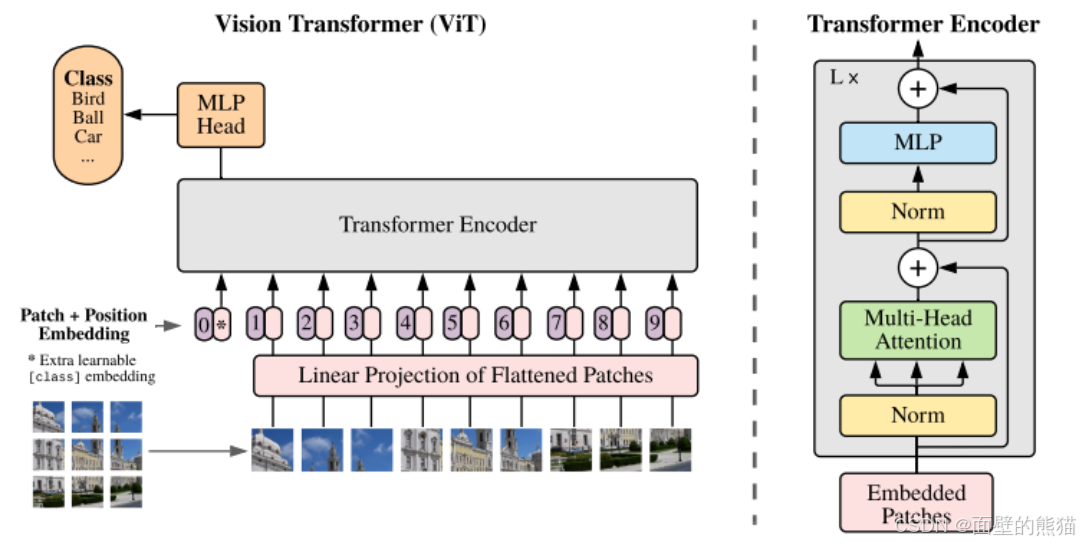

ViT是2020年Google团队提出将Transformer应用在图像分类的模型,其“简单”且效果好,可扩展性强。但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置。
CNN的两种归纳偏置:
- 局部性:即图片相邻的区域具有相似的特征。
- 平移不变性: f(g(x)) = g(f(x)) ,其中g代表卷积操作,f代表平移操作。
按照上面的流程图,一个ViT block可以分为以下几个步骤
- Patch embedding
对于一个224x224的图片,其首先被以(14x14)大小分patch。patchs = (224x224)/(16x16)=196个。此外,ViT还会额外添加一个cls token,因此实际的token是197,因此input的维度是197x768。这个额外的token最后会被输入给分类头,做分类任务。 - Positional encoding
- LN/multi-head attention
- MLP
DINO
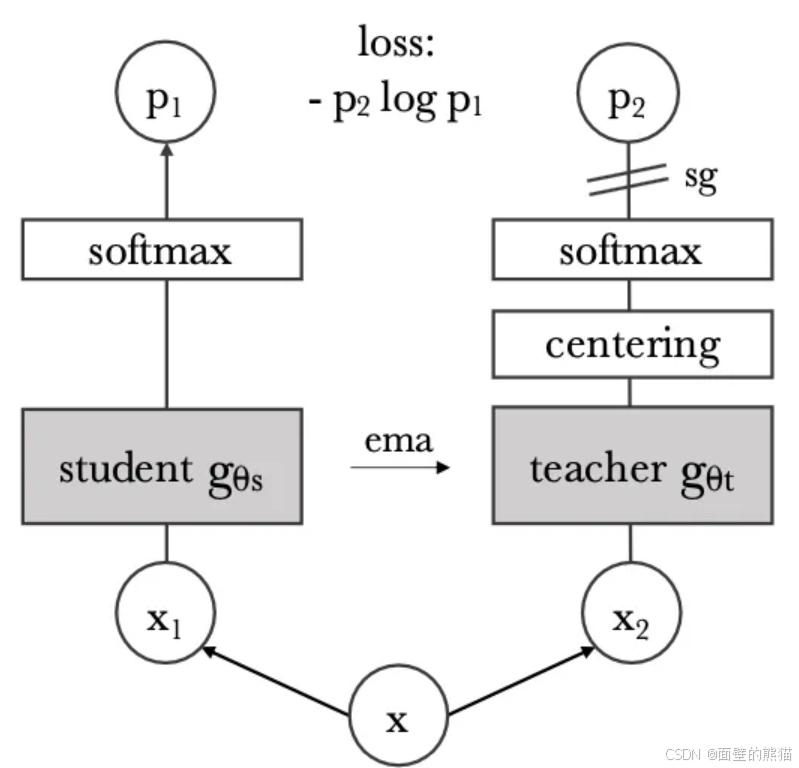
在预训练阶段使用监督是否可以提高ViT任务? 1)自监督ViT特征包含显示的分割信息;2)这些特征使用kNN分类,在Imagenet可以达到78.3%准确率。
本文使用结构完全相同的教师学生网络进行蒸馏训练,教师网络只有centering(向教师添加偏差项)和sharpening(softmax温度)技术避免坍塌。学生网络使用EMA更新教师网络。
采用"local-to-global"的训练,学生网络输入局部的视图,教师网络输入全局视图。
MAE
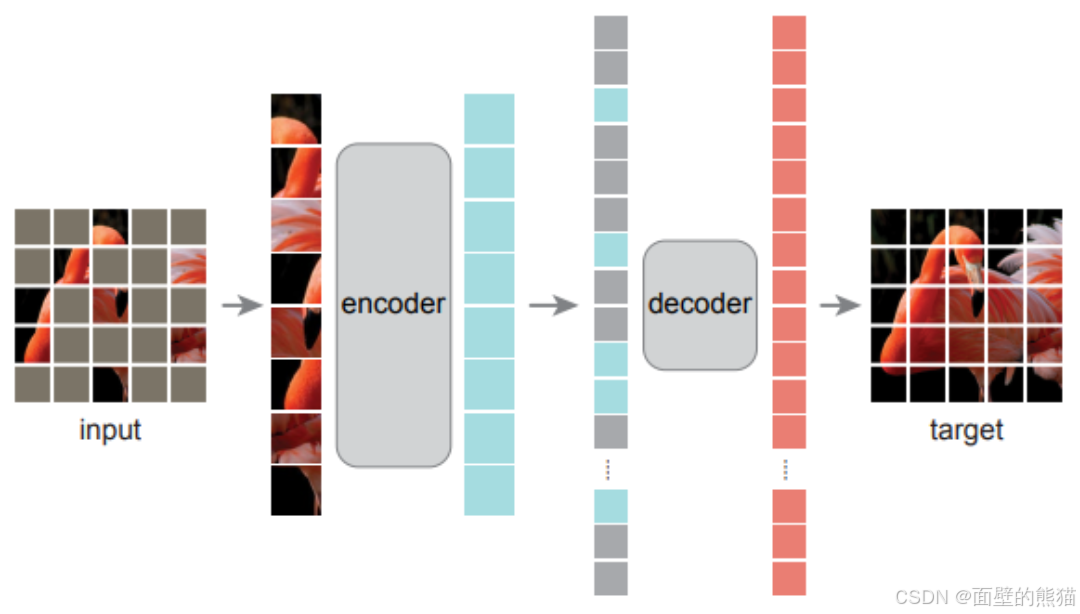
auto masked的自监督任务在NLP领域应用很成功,为什么CV领域会滞后NLP领域呢?有几点:
- 架构不同。过去几十年,卷积操作在CV领域占主导地位。卷积是通常在规则的网格运行,不直接指示掩码标记或位置编码。这个问题呗ViT所解决了。
- 信息密度不同。语言包含更多的高级语义和信息密度,因此可以训练模型去推测少量丢失的字词。而视觉图像则包含极多的空间冗余信息(丢失的patch可以相邻的高级parts、objects和scenes来恢复)。因此可以以一个极高比例mask图像token,这个策略可以极大减少冗余token,同时让模型关注图像全局理解。
- Decoder不同。在视觉中,解码器重建像素,因此其输出的语义水平低于常见的识别任务。这与语言形成鲜明对比,在语言中,解码器预测包含丰富语义信息的缺失单词。这导致BERT使用一个简单的MLP。
贡献:
- 非对称的“Encoder-Decoder”架构,encoder只编码没有mask的视觉token,light weight decoder则重构mask和可见视觉token的隐空间向量。
- 当mask 75%的视觉token,也能表现不错的自监督效果。
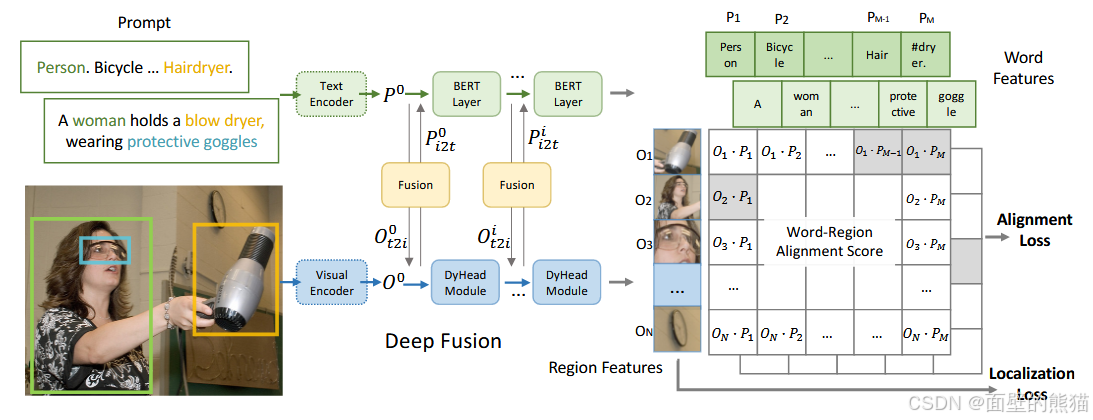
GLIP
DETR
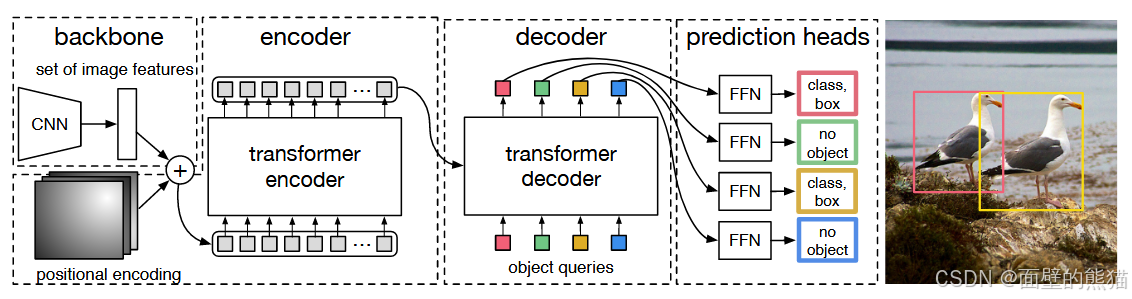
SAM(Segment Anything)
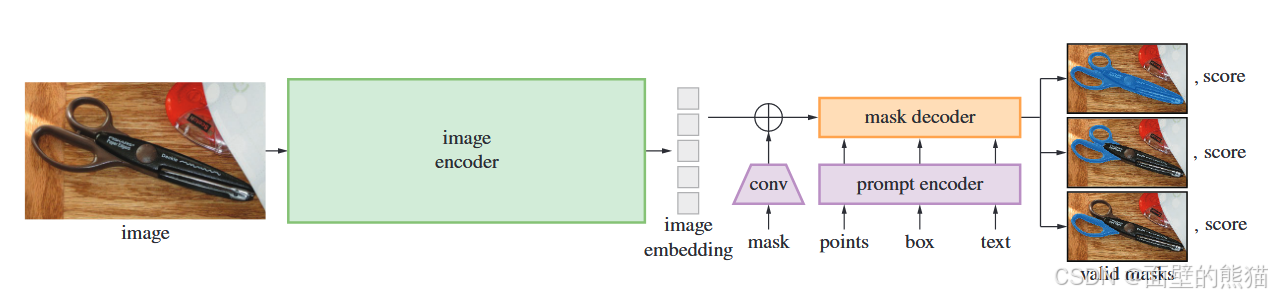
Grounded SAM
大模型相关
相关工作
CLIP
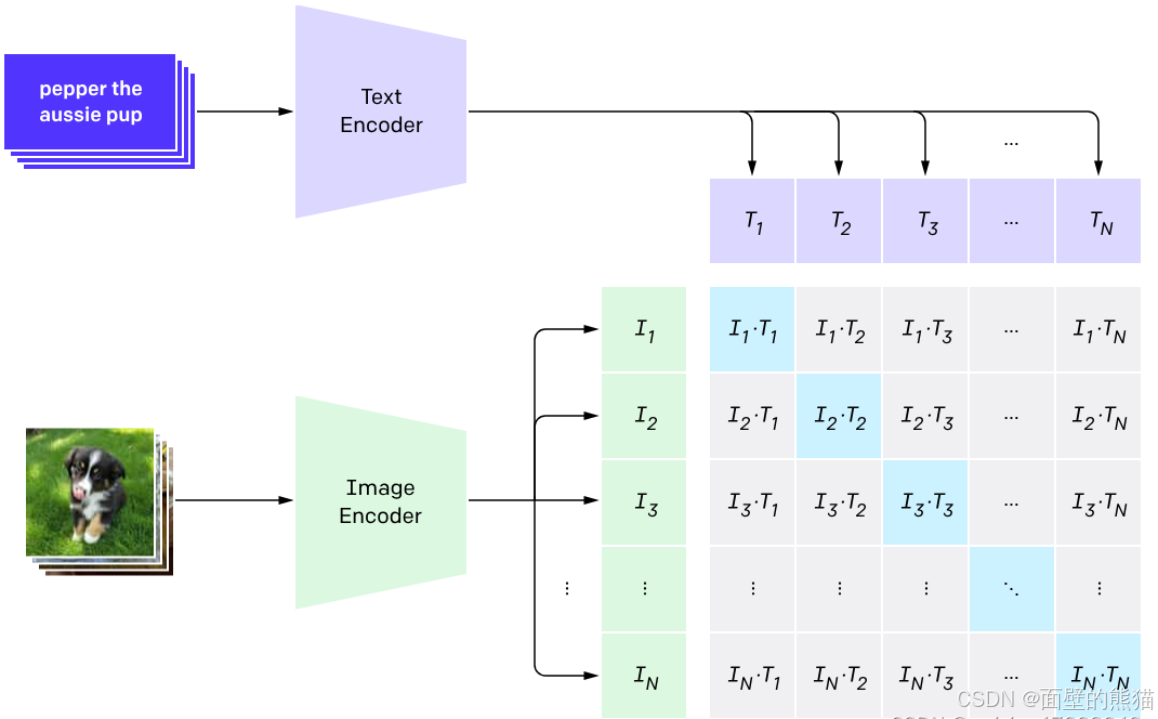
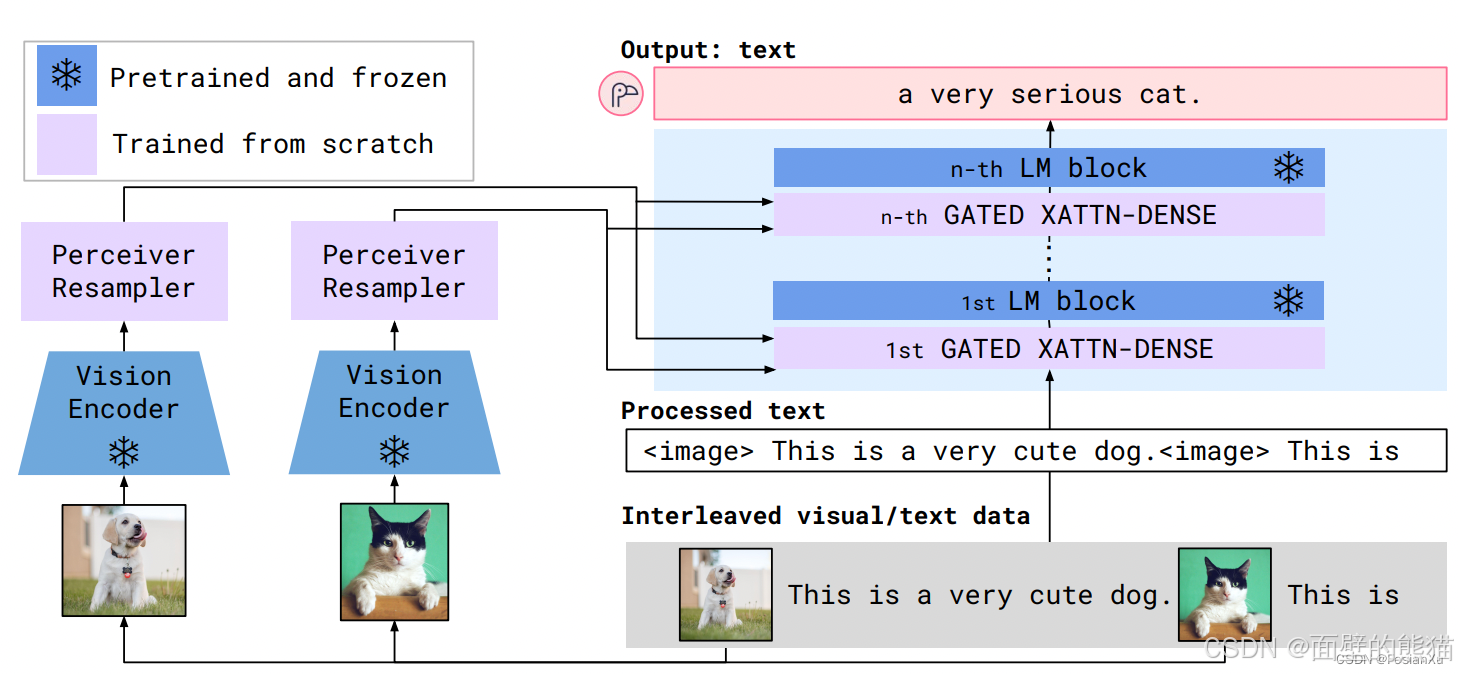
Flamingo
LLaVA 1.5
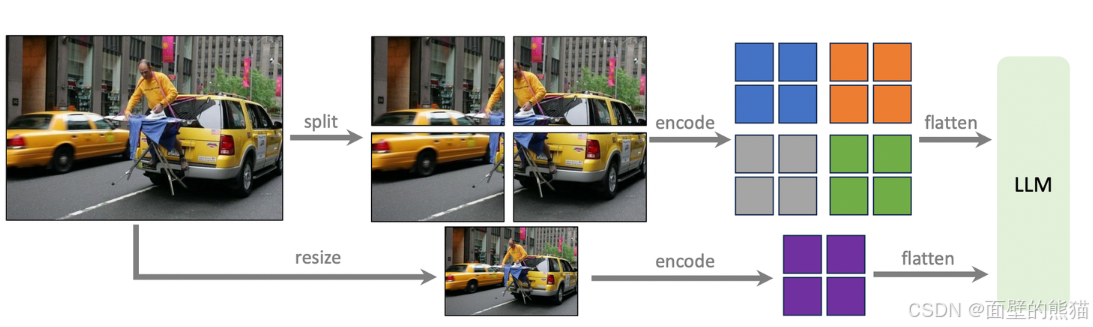
LLaVA-UHD
BLIP
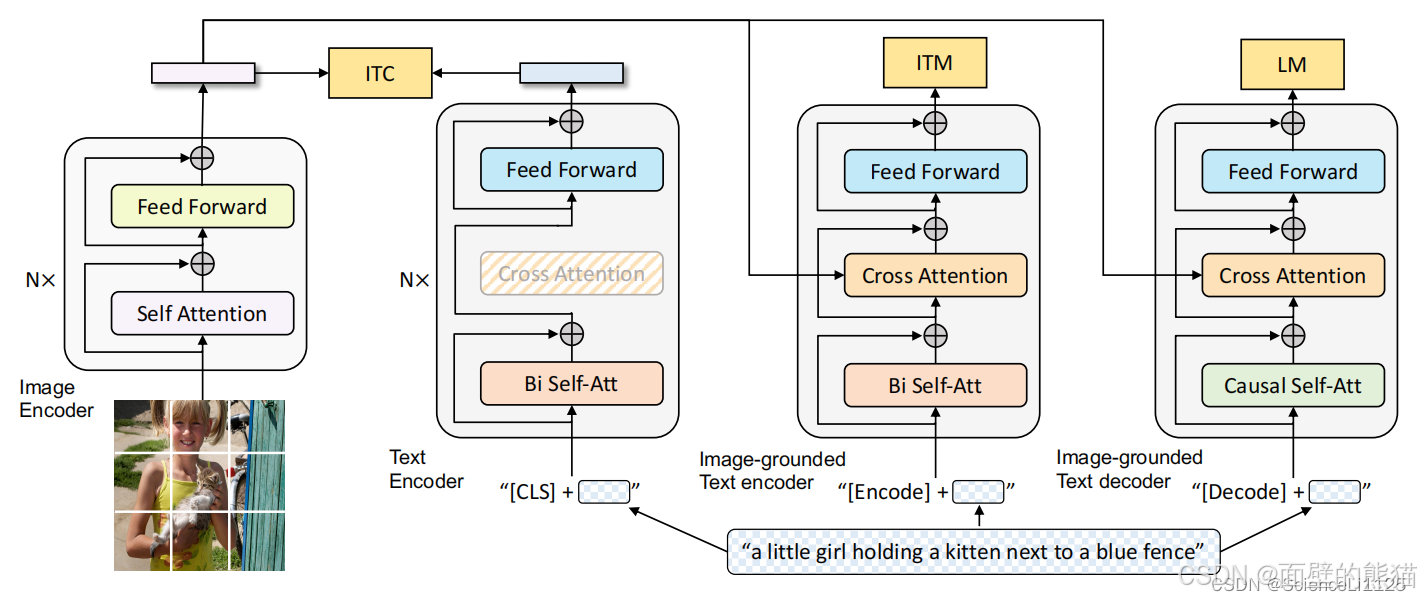
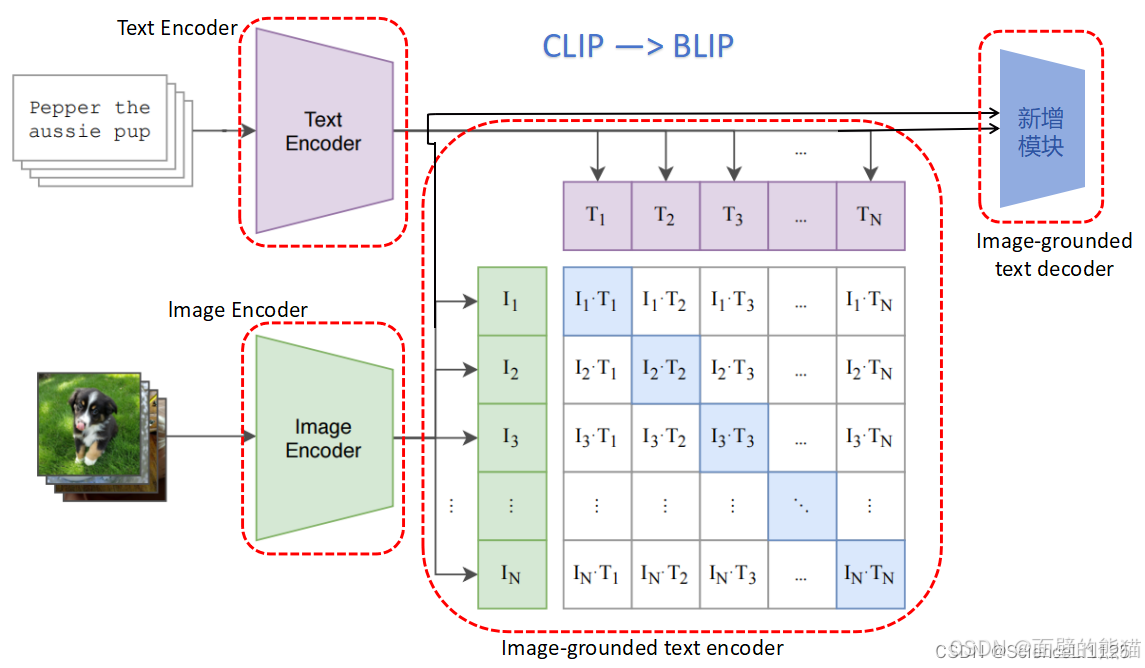
BLIP采用编码器-解码器的多模态混合结构,包括两个单模态编码器、一个以图像为基础的文本编码器和一个以图像为基础的文本解码器。
- 单模态编码器 lmage Encoder:基于 transformer 的 ViT 的架构,将输入图像分割为多个的 patch 并将它们编码为一系列 Image Embedding,并使用 [CLS] token 来表示全局的图像特征。lmage Encoder 用来提取图像特征做对比学习,相当于 CLIP 中的 Image Encoder;
- 单模态编码器 Text Encoder:基于 BERT 的架构,将 [CLS] token 加到输入文本的开头以总结句子。Text Encoder 用来提取文本特征做对比学习,相当于 CLIP 中的 Text Encoder;
- 以图像为基础的编码器 Image-grounded text encoder:在 Text Encoder 的 self-attention 层和前馈网络之间添加一个 交叉注意 (cross-attention, CA) 层用来注入视觉信息,还将 [Encode] token 加到输入文本的开头以标识特定任务。Image-grounded text encoder 用来提取文本特征并将其和图像特征对齐,相当于 CLIP 中更精细化的 Text - Image 对齐;
- 以图像为基础的解码器 Image-grounded text decoder:将 Image-grounded text encoder 的 self-attention 层换成 causal self-attention 层,还将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。Image-grounded text decoder 用来生成符合图像和文本特征的文本描述,这是 CLIP 中所没有的;
CapFilt 机制:
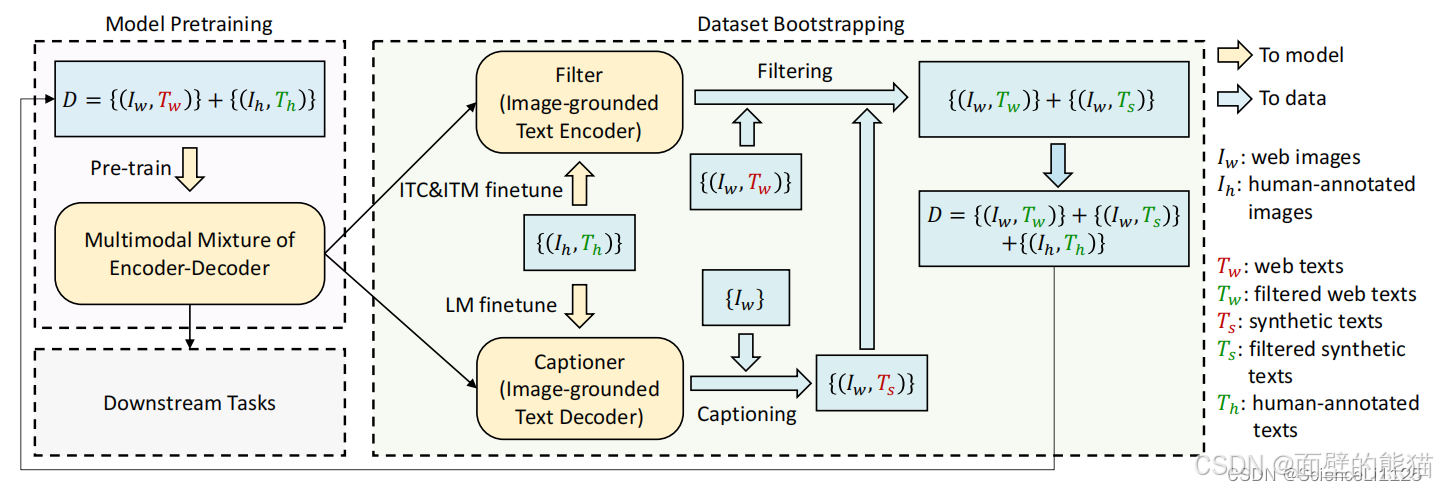


BLIP训练思路:
先使用含有噪声的网络数据训练一遍 BLIP,再在 COCO 数据集上进行微调以训练 Captioner 和 Filter,然后使用 Filter 从原始网络文本和合成文本中删除嘈杂的字幕,得到干净的数据。最后再使用干净的数据训练一遍得到高性能的 BLIP。
BLIP 2
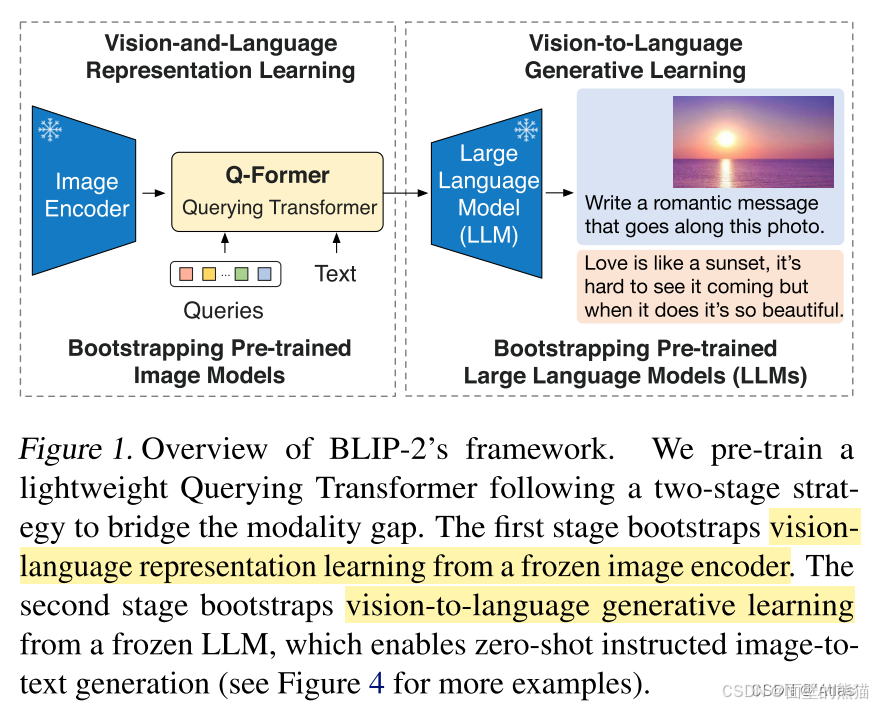
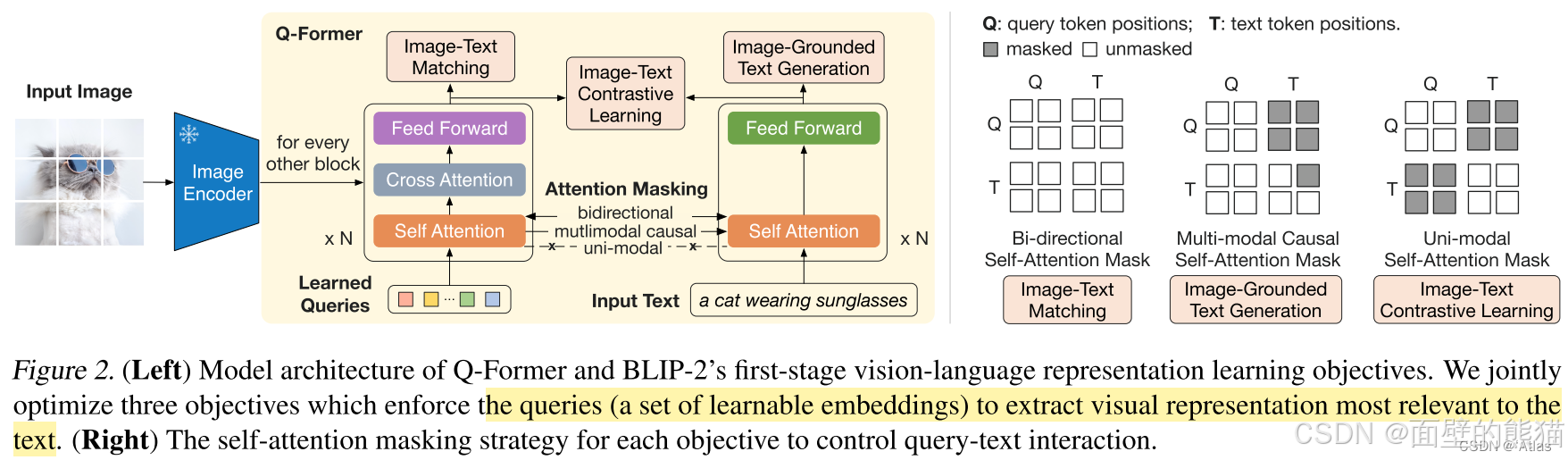
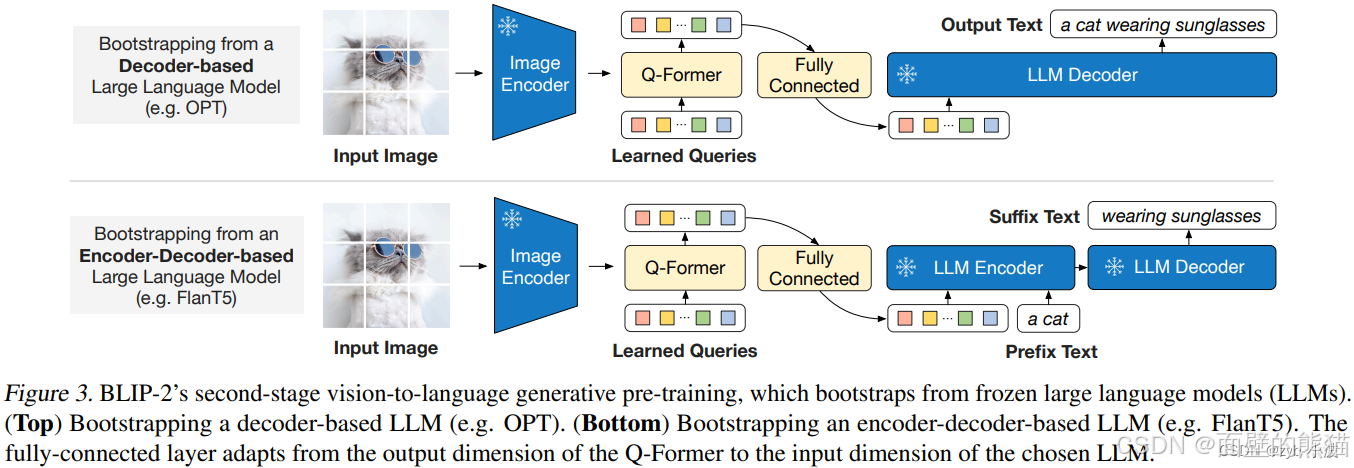
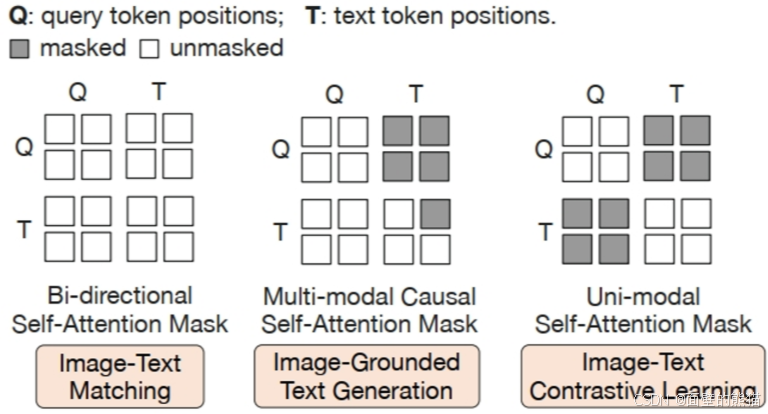
不同的交互任务:
- ITC,使用单模态视觉和大语言模型各自的注意力掩码,Q向量和T之间没有交互。
- ITM,使用双向注意力机制掩码(MLM),实现Q向量和T之间的任意交互。Q向量可以attention T,T也可以attention Q向量。
- ITG,使用单向注意力机制掩码(CLM),实现Q向量和T之间的部分交互。Q向量不能attention T,T中的text token可以attention Q向量和前面的text tokens。
MiniCPM-V 2.6
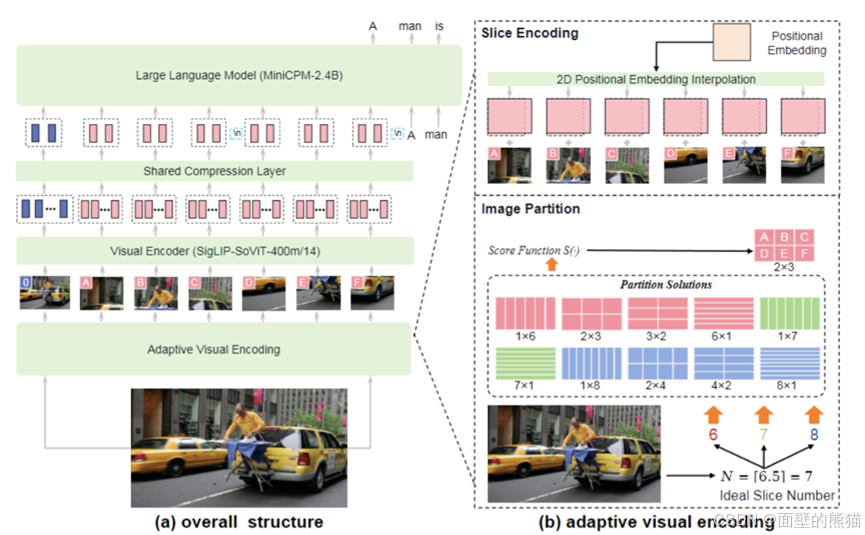
- 支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像。
- 图像压缩层,引入一个单层交叉注意力层和一层可训练的query emb。压缩token长度到query emb。
Qwen VL
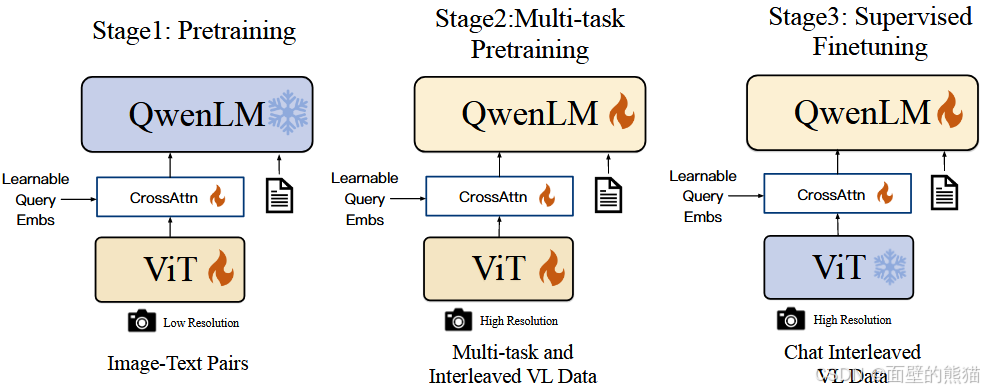
- 位置感知VL适配器,通过256个可学习查询向量压缩视觉特征,融入2D绝对位置编码;
- 三阶段递进式训练范式(Pretraining–>Multi-task Pretraining–>Supervised Finetuning)
Qwen2 VL
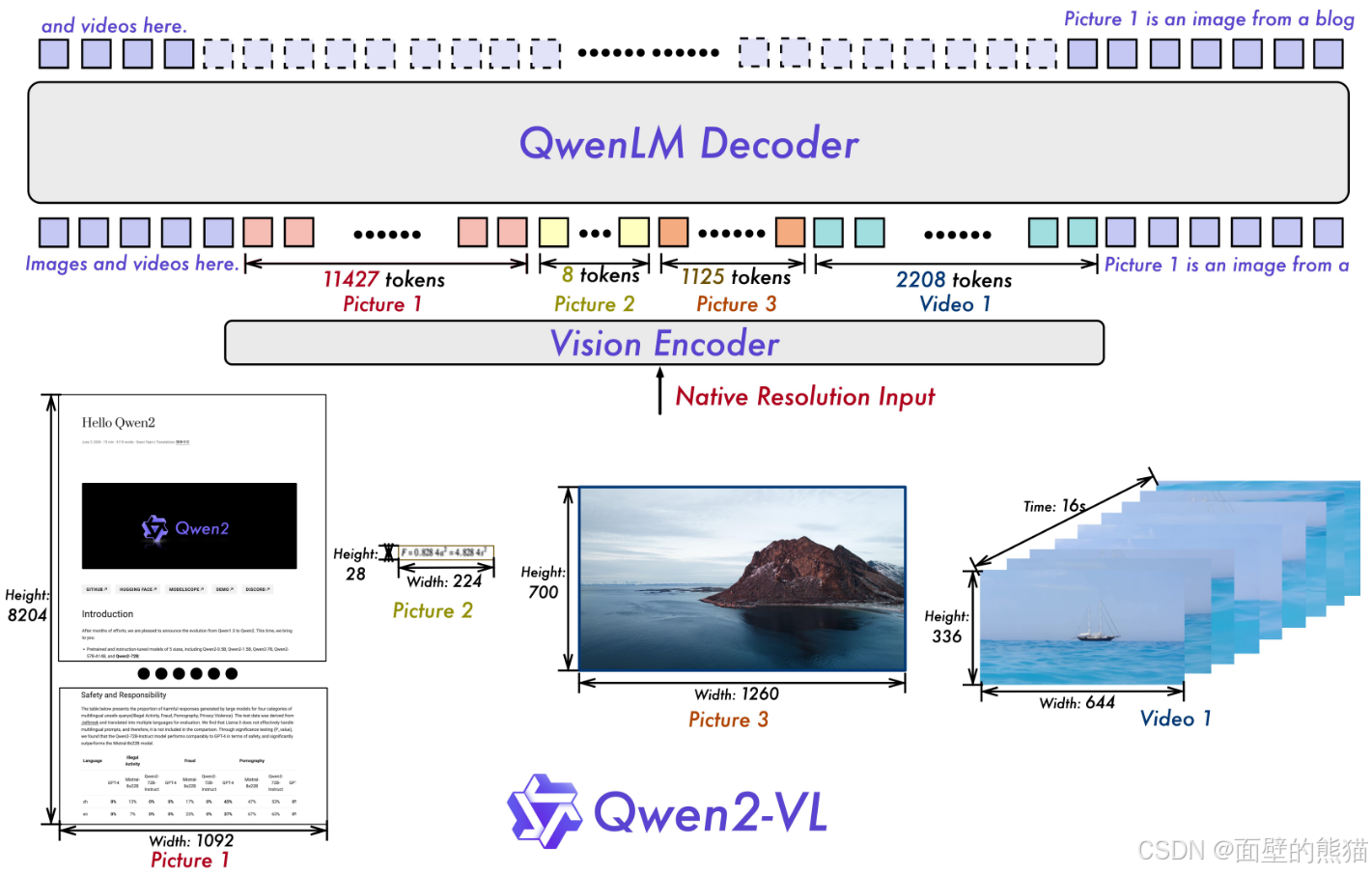
- 原生动态分辨率机制,引入2D-RoPE替换ViT固定位置嵌入,让不同分辨率图像生成对应数量视觉token;
- 多模态旋转位置嵌入(M-RoPE),拆分时间、高度、宽度三维分量,统一文本、图像、视频位置信息建模;
- 图像-视频统一处理范式,将图像视为“2帧相同视频”,结合3D卷积支持20分钟以上长视频理解。
Qwen2.5 VL
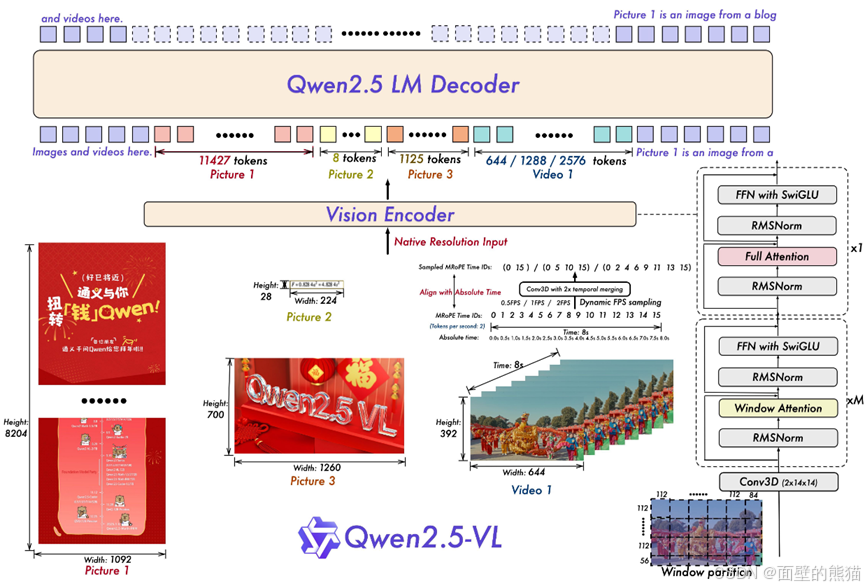
- 数据量翻倍,Qwen2-VL预训练使用的1.2万亿token,Qwen2.5-VL增加到4.1万亿。
- 重新设计的Vision Encoder,2D-RoPE和window attention;
- Vision Encoder的patch size是14x14,绝大部分的layer是计算window attention,只有4 layers是计算full attention。
- 采用2D-RoPE有效捕捉空间信息,RMSNorm以及SwiGLU提高计算效率。
- 对于视频输入,采用动态帧率(更好的补充视内容的时间动态)以及绝对时间编码。
- 提出MRoPE(多模态RoPE),位置编码由时序、高度、宽度三部分组成。
- 模型grounding能力的又一提升,扩大数据集类目、合成数据。
- 预训练分阶段训练,第一阶段只训ViT(对齐),第二阶段全部训练,第三阶段长数据、agent数据(提高推理能力)。
- Post-training:SFT+DPO
- 数据清洗:rule-based、model-based filtering
- 拒绝采样技术,增强模型的推理能力。使用一个中间版本的 Qwen2.5-VL 模型,对带有标注的数据集生成响应,将模型生成的响应与标注的正确答案进行比较,只保留模型输出与正确答案匹配的样本,丢弃不匹配的样本。
Qwen3 VL
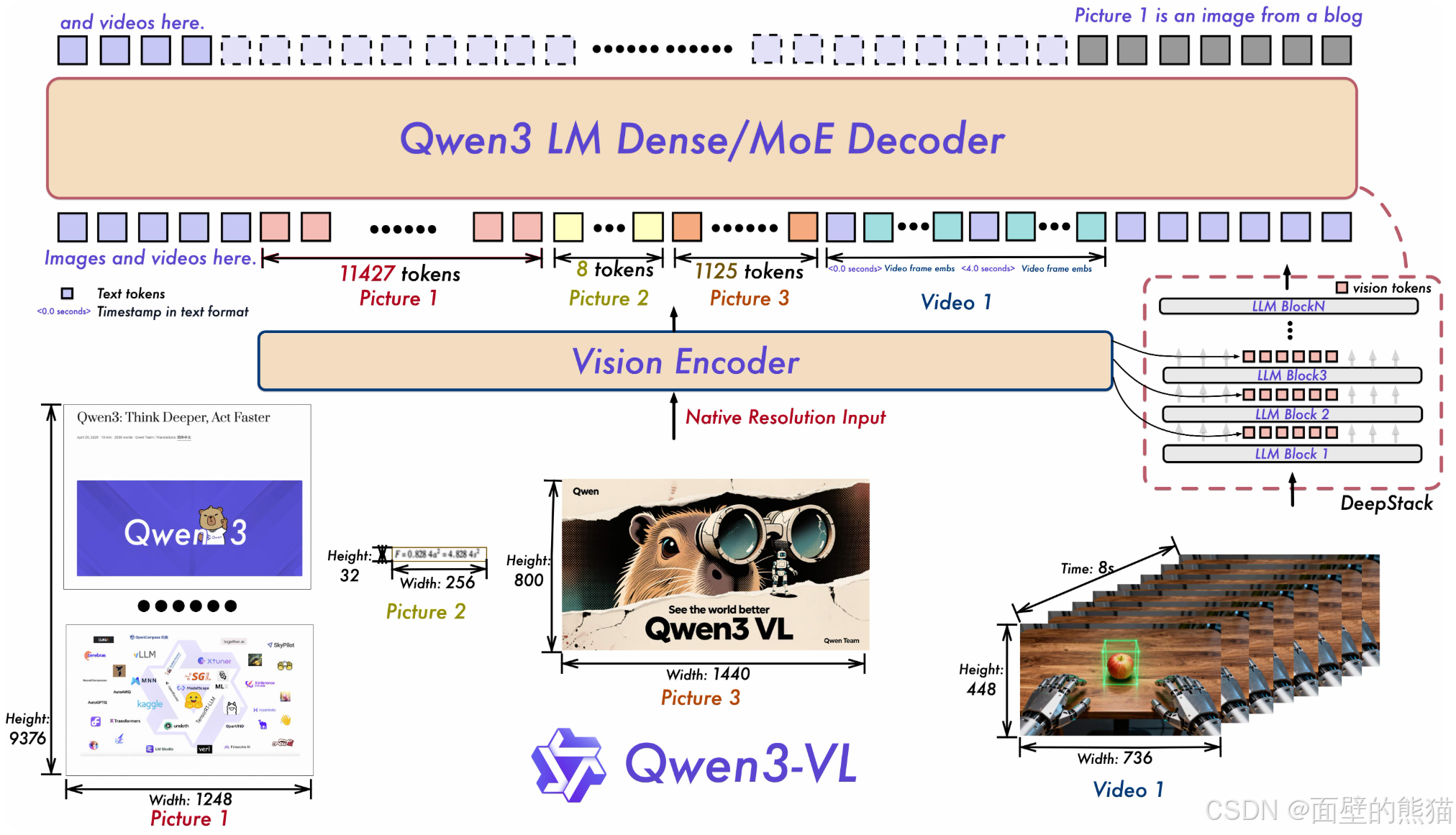
-
采用 MRoPE-Interleave,原始MRoPE将特征维度按照时间(t)、高度(h)和宽度(w)的顺序分块划分,使得时间信息全部分布在高频维度上。我们在 Qwen3-VL 中采取了 t,h,w 交错分布的形式,实现对时间,高度和宽度的全频率覆盖,这样更加鲁棒的位置编码能够保证模型在图片理解能力相当的情况下,提升对长视频的理解能力;
-
引入 DeepStack 技术,融合 ViT 多层次特征,提升视觉细节捕捉能力和图文对齐精度;我们沿用 DeepStack 的核心思想,将以往多模态大模型(LMM)单层输入视觉tokens的范式,改为在大型语言模型 (LLM) 的多层中进行注入。这种多层注入方式旨在实现更精细化的视觉理解。
在此基础上,我们进一步优化了视觉特征 token 化的策略。具体而言,我们将来自 ViT 不同层的视觉特征进行 token 化,并以此作为视觉输入。这种设计能够有效保留从底层(low-level)到高层(high-level)的丰富视觉信息。实验结果表明,该方法在多种视觉理解任务上均展现出显著的性能提升。
Qwen3 VL的deepstack还和原论文不一样。原论文是high resolution token加在low resolution的不同层的token上,而Qwen3 VL则是将视觉编码器的不同层视觉特征token化,以此捕捉底层到高层的丰富视觉信息。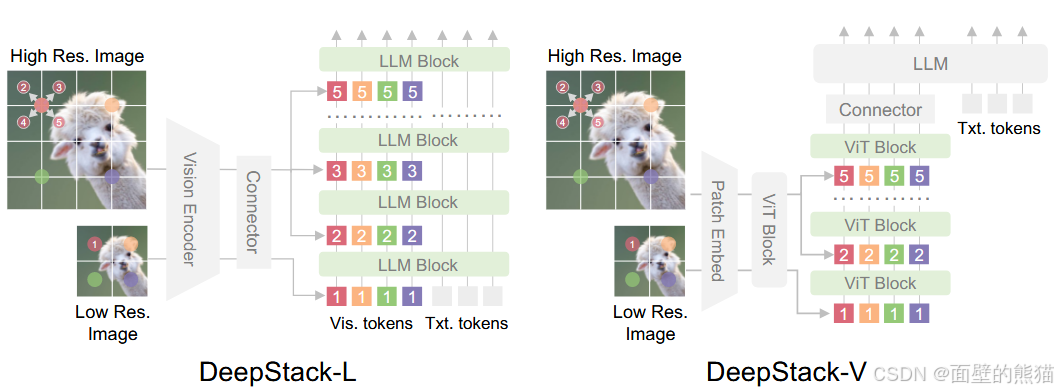
-
将原有的视频时序建模机制T-RoPE 升级为文本时间戳对齐机制。该机采用“时间戳-视频帧”交错的输入形式,实现帧级别的时间信息与视觉内容的细粒度对齐。同时,模型原生支持“秒数”与“时:分:秒”(HMS)两种时间输出格式。这一改进显著提升了模型对视频中动作、事件的语义感知与时间定位精度,使其在复杂时序推理任务——如事件定位、动作边界检测、跨模态时间问答等——中表现更稳健、响应更精准。
InternVL
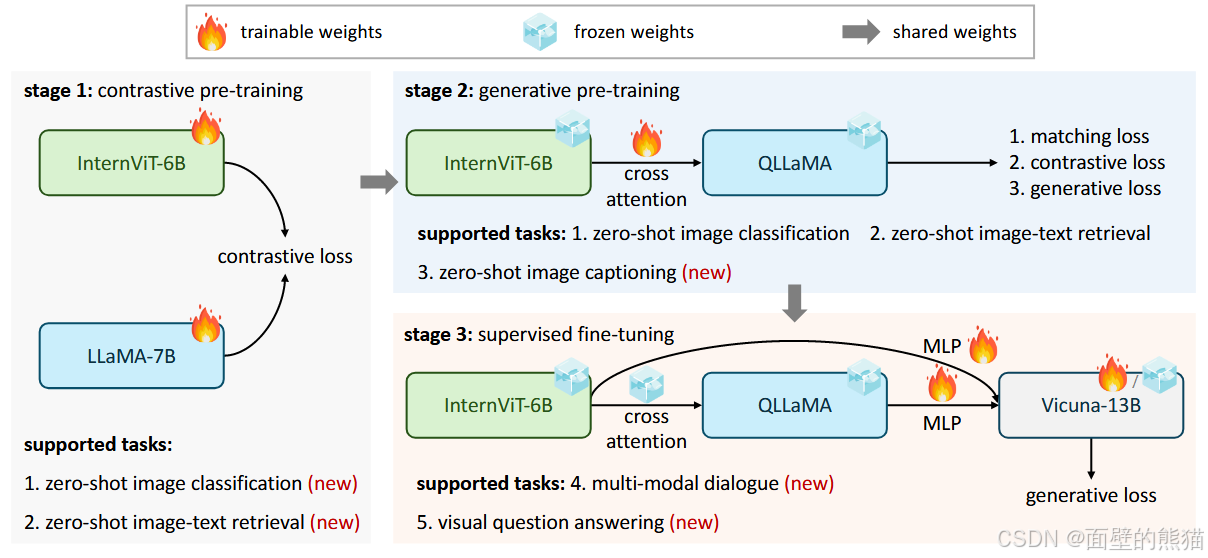

- InternVL使用QLLaMA替代Q-Former,精简了模型框架;
- 增加了vision encoder和跨模态转换器(QLLaMA)体量。
InternVL 1.5
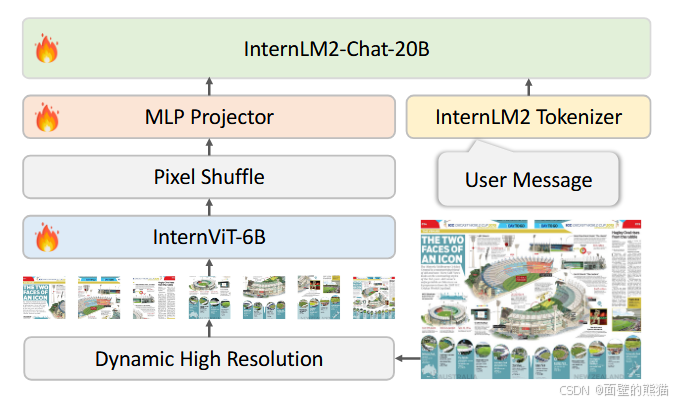
- 高分辨率及动态分辨率:1) 高分辨率:先使用224×224分辨率进行训练,再将分辨率增长到448×448。模型只支持448×448时对应的MLLM为Intern1.2; 2)动态分辨率:进一步地,将更高分辨率的图片裁剪成448×448的图片块,再依次送入图像编码器InternViT6B里提取特征。
- 训练流程:训练总共分为pre-training和fine-tuning两步。其中pre-training集中训练InternViT-6B和MLP,而fine-tuning阶段对所有参数进行调整。
InternVL 3.0
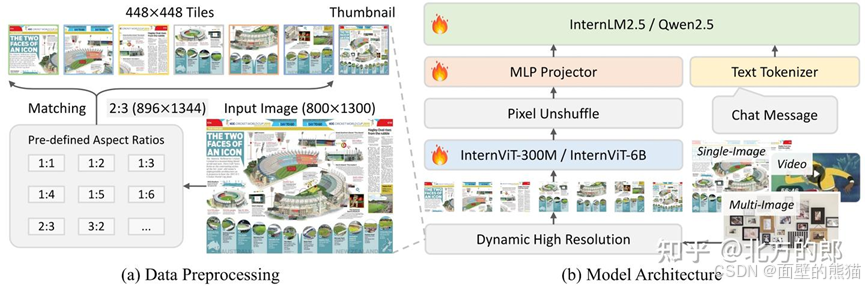
- 原生多模态大模型预训练范式,说白了就是“所有参数一块训”。
- 和InternVL2.5一样,采用pixel unshuffle提高可扩展性和效率(token数减小到原来1/4)。
- V2PE(可变的视觉位置编码器),
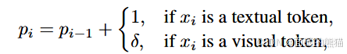
,减少索引增长速率。 - Square averaging weight,大量使用平均权重会导致梯度偏向过长过短文本回复。因此这里用square averaging权重系数。
- Post-training:SFT+MPO(mixed preference optimization)。
- MPO在DPO的基础上引入额外的损失,质量和生成损失。DPO使模型学会选择响应和拒绝响应的偏好。
- 动态高分辨率(Dynamic high resolution),对于输入图像首先resize到448x448的倍数,然后按照预定义尺寸比例从图像上crop对应的区域。(size变小,通道数增加)
InternVL 3.5
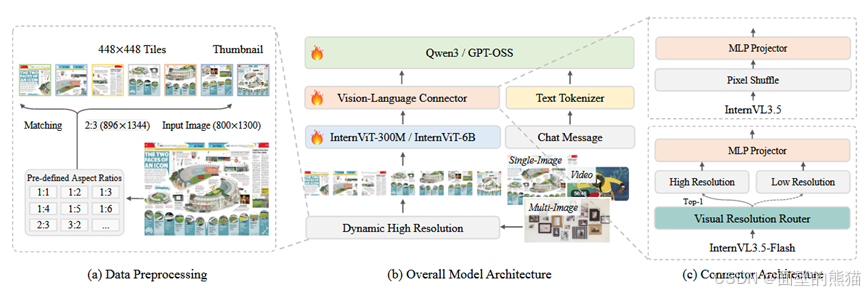
- Cascade RL(级联强化)。Offline+online RL,先收敛 再对齐。
- ViR(Visual Resolution Router)动态调整视觉token分辨率。
- DvD(Decoupled Vision-Language Deployment)Vit和LLM的解离训练策略。
- 支持GUI、embodied agency等新能力。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)