
Context Compressing in Agent Application
这篇论文提出了两种针对大语言模型上下文压缩的创新方法:ICAE(In-Context Autoencoder)和CCM(Compressed Context Memory)。ICAE通过编码器-解码器架构,将长上下文压缩为记忆槽,并采用双目标训练策略(自编码和文本续写)来保持信息完整性。CCM则专注于在线交互场景,通过动态压缩KV缓存和条件LoRA技术实现高效推理。两种方法都显著降低了内存和计算开
Context Compressing in Agent Application
1 IN-CONTEXT AUTOENCODER FOR CONTEXT COMPRESSION IN A LARGE LANGUAGE MODEL
论文地址:https://arxiv.org/pdf/2307.06945
代码:https://github.com/getao/icae/tree/main
1.1 模型结构
现有大语言模型面临几个核心问题:
- 大语言模型(LLMs)通常受限于上下文长度(context window)——输入太长就会导致计算资源消耗高、内存需求大。
- 多数解决方案是改变模型架构(比如稀疏注意力、滑动窗口、长距离注意力等),但这些方案在上下文长度极长时仍然性能下降。
为了解决这个问题,论文提出了一个不同思路:把长的上下文压缩成一个短的“记忆槽”(memory slots),只让模型在推理时看到这些压缩后的记忆槽,而非完整上下文,从而节省计算与内存开销。
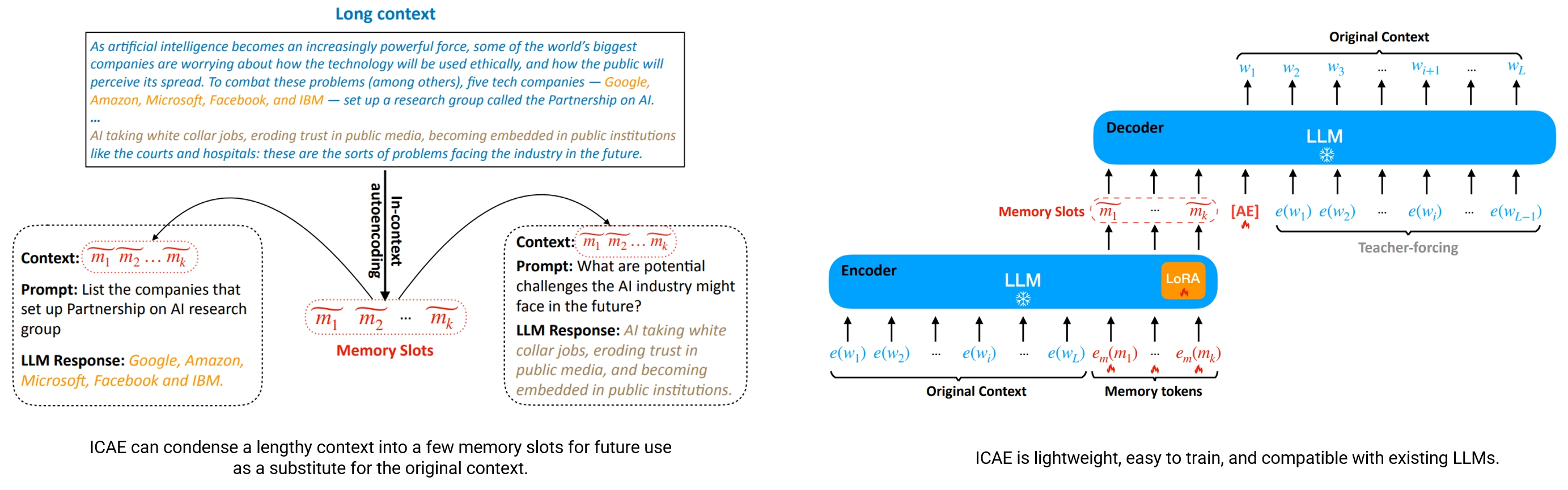
ICAE 的设计可以分成两部分:编码器(encoder)、解码器(decoder)。
- 编码器
- 基于已有的 LLM,使用 LoRA(Low-Rank Adaptation)方式做轻量调整,以及新增 memory tokens 的 embedding。
- 输入一个完整上下文(长度为 L 的 token 序列 w₁…w_L),在其后附加 k 个 memory tokens m₁…m_k(k ≪ L),然后通过编码器处理,输出这 k 个 memory slots(mf₁ … mf_k)。这些 memory slots 是对整个上下文的压缩表示。
- 解码器
- 解码器就是保持不变的目标 LLM,其作用是“读取”这些 memory slots(加上某些额外 prompt 或任务输入)来完成任务,比如重构原文、继续文本、回答问题等。也就是说,解码器并不看到完整上下文,只看到压缩后的 memory slots。
训练分为两个步骤:
-
预训练:双目标优化
- 通过海量文本(如 The Pile)训练,让记忆槽具备 “恢复上下文” 和 “泛化表征” 能力:
- 自编码目标( L A E \mathcal{L}_{AE} LAE):从记忆槽中恢复原上下文 c c c,即最大化 P ( c ∣ m 1 ~ , . . . , m k ~ ; Θ L L M ) P(c|\tilde{m_1},...,\tilde{m_k};\Theta_{LLM}) P(c∣m1~,...,mk~;ΘLLM),需在记忆槽后追加特殊 token“[AE]” 标识任务。该目标无需标注,可利用海量数据,确保记忆槽保留上下文核心信息。
- 文本续写目标( L L M \mathcal{L}_{LM} LLM):从记忆槽中预测上下文的续写内容 o = ( w L + 1 , . . . , w L + N ) o=(w_{L+1},...,w_{L+N}) o=(wL+1,...,wL+N),即最大化 P ( o ∣ m 1 ~ , . . . , m k ~ ; Θ L L M ) P(o|\tilde{m_1},...,\tilde{m_k};\Theta_{LLM}) P(o∣m1~,...,mk~;ΘLLM)。缓解单一 AE 目标的过拟合问题,提升记忆槽的泛化能力。
- 预训练损失为双目标加权: L p r e t r a i n = λ L A E + ( 1 − λ ) L L M \mathcal{L}_{pretrain}=\lambda\mathcal{L}_{AE}+(1-\lambda)\mathcal{L}_{LM} Lpretrain=λLAE+(1−λ)LLM,其中 λ = 0.4 ∼ 0.6 \lambda=0.4\sim0.6 λ=0.4∼0.6 时效果最优。
-
指令微调:适配实际任务
为让记忆槽能与多样化 prompt 交互,使用自建的 PWC 数据集(Prompt-with-Context)微调:- PWC 数据集:含 24 万训练样本、1.8 万测试样本,每个样本为(上下文、prompt、响应)三元组,由 GPT-4 生成,覆盖不同上下文长度(多数超 500token)与任务类型(摘要、问答、关键词提取等)。
- 微调目标:最大化 “基于记忆槽 + prompt 生成正确响应” 的概率,即 L F T = max Θ L o R A , e m P ( r 1 . . . r n ∣ m 1 . . . m k , p 1 . . . p m ; Θ L L M ) \mathcal{L}_{FT}=\max_{\Theta_{LoRA},e_m}P(r_1...r_n|m_1...m_k,p_1...p_m;\Theta_{LLM}) LFT=maxΘLoRA,emP(r1...rn∣m1...mk,p1...pm;ΘLLM),增强记忆槽的任务适配性。
1.2 代码分析
从模型上看,ICAE 是基于已有的 LLM 构建的,具体来说,是在 LLM 基础上应用了 LoRA 技术,新增了 memory tokens 的 embedding。
self.icae = base_llama.LlamaForCausalLM.from_pretrained(...) # 基础LLM
self.icae = get_peft_model(self.icae, lora_config) # 应用LoRA
同时通过新增的 memory tokens 嵌入层,模型可以学习到 memory slots 的表示。
# 记忆token嵌入层(可学习参数)
self.memory_token_embed = nn.Embedding(model_args.mem_size+3, self.dim)
# 生成记忆槽
compress_outputs = self.icae(inputs_embeds=autoencoder_input_embedding, enable_lora=True)
memory_embedding = compress_outputs[memory_mask].view(batch_size, self.model_args.mem_size, -1)
生成阶段直接复用基础 LLM 的解码器,将记忆槽与 prompt 拼接后作为输入,无需修改原模型结构,确保兼容性。
# 拼接记忆槽和prompt嵌入
decoder_input_embeddings = torch.cat((memory_embedding, prompt_answer_embs), dim=1)
# 调用原LLM生成响应
decoder_outputs = self.icae(inputs_embeds=decoder_input_embeddings)
2 Compressed Context Memory For Online Language Model Interaction
论文地址:https://arxiv.org/abs/2312.03414
代码:https://github.com/snu-mllab/context-memory
2.1 模型
现有LLM交互中面临几个问题:
- 在在线交互(对话、个性化、多任务学习等)中,语言模型的上下文随着时间持续累积。Transformer 的 self-attention 机制对完整上下文(context)的 key/value (KV) 缓存与计算开销随着时间线性或更坏地增长,导致内存使用大、延迟高、吞吐低。
- 现有的上下文压缩方法大多是针对固定长度 context(prompt / 演示集)设计的,不太适合上下文随着时间不断新增、需要动态处理的情形。
论文提出了一种叫 Compressed Context Memory (CCM) 的机制,用来在 inference 时动态压缩累积的 context KV,节省资源,同时尽量保持性能。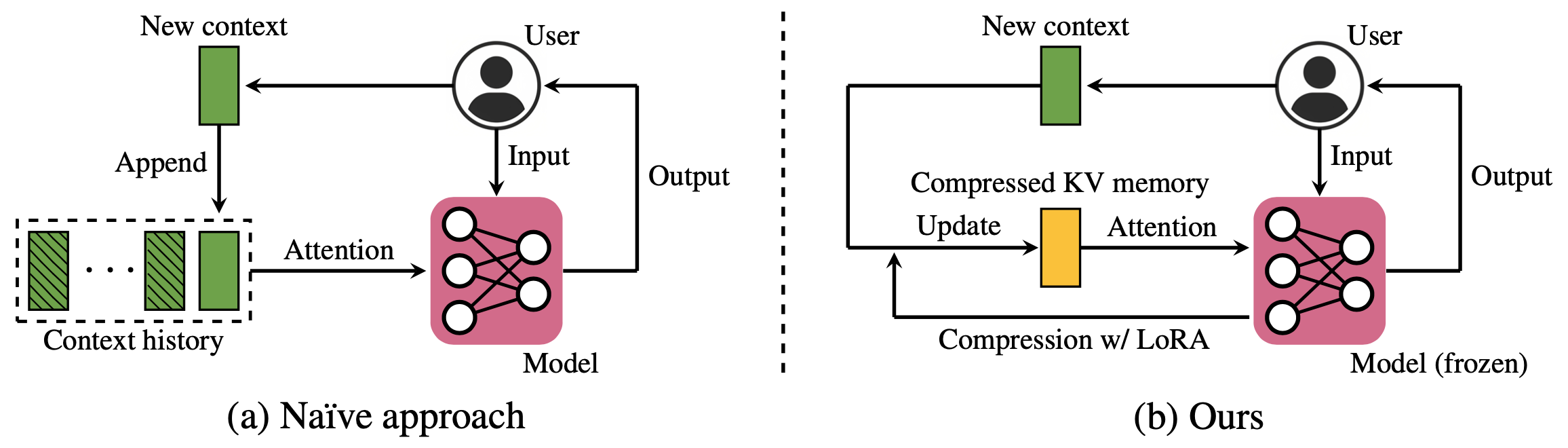
CCM提出动态压缩上下文内存框架,通过持续压缩积累的 KV 对,在有限内存中支持在线推理,核心包含 3 大模块:
- 上下文压缩机制:基于⟨COMP⟩token 的 KV 压缩
- 压缩对象:直接压缩注意力 KV 对(而非 token 嵌入),兼容 Transformer 层内并行性;
- 专用压缩 token:引入⟨COMP⟩token,训练模型将当前新增上下文(c(t))与历史压缩内存(Mem(t-1))的信息,压缩到⟨COMP⟩token 的 KV 对中,得到压缩特征(h(t) \in \mathbb{R}^{2 \times L \times d})(L为模型层数,d为隐藏层维度);
- 压缩过程:(h(t) = g_{comp}(Mem(t-1), c(t))),仅需前向计算,无需递归。
- 动态内存更新,设计可微、可并行的内存更新函数(g_{update}),适配不同场景:
- CCM-concat:将新的 h(t) 直接连接到旧的 memory 中,memory 随时间增长。
- CCM-merge:将新的 h(t) 与旧 memory 按加权平均合并(例如算术平均或指数移动平均),memory 保持固定大小。
- 高效训练:并行化 + 条件 LoRA
- 并行化训练:递归压缩过程 “展开” 为单轮并行前向计算,避免递归导致的训练耗时与梯度传播误差,训练速度比 RMT/AutoCompressor 快 7 倍;
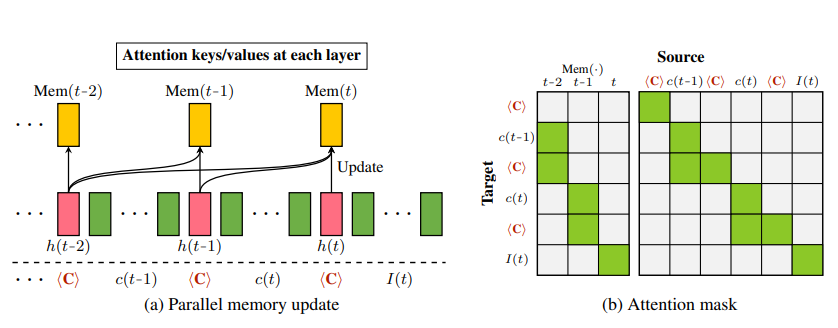
- 条件 LoRA:为了训练压缩模块,引入一个 conditional LoRA adapter,只在 ⟨COMP⟩ token 上作用,不修改原模型的主参数 θ,而新增一些低秩参数 ∆θ 用来学习压缩操作。这样避免 overfitting 模型在没有 context 的情况下也能“猜”输出的问题。
- 并行化训练:递归压缩过程 “展开” 为单轮并行前向计算,避免递归导致的训练耗时与梯度传播误差,训练速度比 RMT/AutoCompressor 快 7 倍;
推理阶段:
- 在实际用的时候,随着新 context 的到来,不断用压缩函数更新 memory,并在生成响应时只用 memory + 当前输入,而不是整个历史 context。这样 attention 的计算成本和内存成本都大幅下降。
arXiv - 在 streaming 的设置里,还结合 sliding window(最近的上下文窗口)与压缩 oldest tokens 的操作来控制 KV cache 的大小。
2.2 源码分析
在注意力机制中通过 sum_mask 和 sum_attn_mask 实现键值对的动态合并与压缩。
# 合并压缩键值对(用于动态更新内存)
if sum_attn_mask is not None:
sum_attn_mask = sum_attn_mask.to(key_states.dtype)
# 计算压缩后的键值平均值
key_comp_avg = torch.matmul(sum_attn_mask.unsqueeze(1), key_states)
value_comp_avg = torch.matmul(sum_attn_mask.unsqueeze(1), value_states)
# 用掩码控制原始键值与压缩键值的融合
no_sum_mask = (1 - sum_mask).to(key_states.dtype).unsqueeze(1).unsqueeze(-1)
key_states = no_sum_mask * key_states + key_comp_avg # 动态更新key内存
value_states = no_sum_mask * value_states + value_comp_avg # 动态更新value内存
在注意力层中,q_proj、k_proj、v_proj、o_proj 均使用 LinearMask,并在 forward 中传入 comp_mask 控制 LoRA 的条件激活:
class LinearMask(nn.Linear):
"""Linear function with compression mask as an argument.
The mask is used for conditional LoRA at src/peft_custom/lora.py-Linear()-forward().
"""
def forward(self, input: Tensor, comp_mask=None) -> Tensor:
return F.linear(input, self.weight, self.bias)
self.q_proj = LinearMask(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = LinearMask(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.v_proj = LinearMask(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.o_proj = LinearMask(self.num_heads * self.head_dim, self.hidden_size, bias=False)
self.rotary_emb = LlamaRotaryEmbedding(self.head_dim,
max_position_embeddings=self.max_position_embeddings)
3 LoCoCo: Dropping In Convolutions for Long Context Compression
论文地址:https://arxiv.org/pdf/2406.05317
代码地址:https://github.com/VITA-Group/LoCoCo
3.1 模型
大型语言模型(LLMs)在文本生成、代码合成、问答等任务中表现优异,但处理长上下文序列时面临KV 缓存内存瓶颈:Transformer 的注意力计算需缓存键(Key)和值(Value),其大小随上下文长度线性增长,易耗尽 GPU 内存。现有方法存在明显缺陷:
- StreamingLLM:通过 “注意力 sink” 和局部窗口限制 receptive field,会丢失中间上下文(“lost in the middle”),无法利用全序列信息;
- H₂O:基于注意力分数启发式丢弃 KV 对,难以扩展到训练上下文长度以外的序列;
- LongLoRA:需修改预训练 LLM 架构,且在小上下文场景下性能受损;
- 注意力近似方法(如稀疏注意力、低秩近似):无法缓解推理阶段的 KV 缓存爆炸问题。
LoCoCo 的核心目标是用固定大小 KV 缓存实现长上下文高效处理,兼顾推理与微调阶段,且支持 “即插即用”(无需修改原有 LLM 架构),核心设计包括三部分:
- 数据驱动的自适应 KV 融合:区别于传统 “启发式丢弃 KV 对”,LoCoCo 通过1D 卷积核动态计算混合权重,融合历史 KV 缓存与新输入 token,最小化上下文信息丢失,保证注意力建模准确性。
- 分段注意力与卷积压缩:
- 分段注意力(Segment-Level Attention):将长序列划分为长度为 B 的段,逐段处理:
- 每段生成当前的 Q、K、V;
- 注意力计算时结合历史 KV 缓存与当前段 KV;
- 若累计 KV 长度超过固定缓存大小 M,触发卷积压缩。
- 卷积 token 压缩器,通过 1D 卷积层生成融合权重:
- 输入:历史 KV 缓存(维度 d×M)与当前段 KV(维度 d×B)拼接,共 2d×(M+B) 维度;
- 卷积层输出 M×(M+B) 维度的权重矩阵 W,经归一化后得到历史 KV 的权重(\tilde{w}{i,j})和当前 KV 的权重(w{i,j});
- 融合更新:(\tilde{k}i = \sum_j w{i,j}k_j + \sum_j \tilde{w}_{i,j}\tilde{k}_j)(V 的更新同理),最终缓存大小保持为 M。
- 分段注意力(Segment-Level Attention):将长序列划分为长度为 B 的段,逐段处理:
- 即插即用集成:
- 推理阶段:在预训练 LLM 的注意力层顶部插入卷积压缩器,仅用少量校准数据微调压缩器,预训练权重不变,可随时移除压缩器切换回全序列模式;
- 微调阶段:结合位置插值(positional interpolation)扩展上下文,插入卷积压缩器并添加 LoRA 适配器,仅微调压缩器、LoRA 及嵌入 / 归一化层,无需全量微调。
3.2 源码分析
通过卷积层动态学习融合权重,结合残差权重实现自适应融合。
- 卷积压缩器定义:
layers = []
hidden_size, in_size = self.mem_compress * args.expand, dim_kv # dim_kv = 2*head_dim(K+V)
for i in range(args.n_convlayer):
if i != 0:
in_size = hidden_size
if i == args.n_convlayer-1:
hidden_size = self.mem_compress # 最终输出mem_compress个权重
# 1D卷积层(论文中的核心组件,用于学习融合权重)
layers.append(nn.Conv1d(
in_channels=in_size,
out_channels=hidden_size,
kernel_size=args.kernel_size,
padding=int((args.kernel_size-1)//2) # 保持序列长度
))
if args.hidden_act is not None:
layers.append(ACT2FN[args.hidden_act]) # 非线性激活(如ReLU)
self.layers = nn.Sequential(*layers) # 卷积网络用于生成融合权重
- 自适应权重融合(结合卷积权重与残差权重):
# 卷积网络生成权重(数据驱动部分)
x = torch.cat([non_heavy_hitter_key_states, non_heavy_hitter_value_states], dim=-1) # 拼接K和V(2d通道)
x = rearrange(x, 'b h s d -> (b h) d s', b=bsz, h=n_head) # 适配Conv1d输入格式
x = self.layers(x) # 卷积计算权重
x = nn.functional.softmax(x, dim=-1) # 归一化(论文公式7)
weight = rearrange(x, '(b h) m s -> b h m s', b=bsz) # 恢复维度
# 融合残差权重(确保重要信息不丢失)
residual_weight = self.make_residual_weight(non_heavy_hitter_hh_scores) # 基于注意力分数的残差权重
weight = residual_weight * (1-self.normalizer) + weight * self.normalizer # 自适应融合(论文未明确但代码新增的稳定机制)
模块化设计memory_saver,通过独立接口处理 KV 缓存,不侵入原模型结构。
通过固定缓存大小、划分重令牌与非重令牌,实现低内存开销的长序列处理。
- 固定缓存大小控制
self.mem_size = args.mem_size # 总缓存大小(固定值,如512)
self.mem_compress = int(args.mem_size * (1-args.hh_keep_rate)) # 可压缩部分大小
self.keep_hh_size = self.mem_size - self.mem_compress # 保留的重令牌大小
- 重令牌保留 + 非重令牌压缩(降低计算开销)
def partition_past_key_values(self, past_key_states, past_value_states, hh_scores):
# 1. 划分重令牌(heavy hitter):保留注意力分数高的token
_, hh_idxs = torch.topk(hh_scores[..., :-self.local_len], self.keep_hh_size-self.local_len, dim=-1)
mask_bottom = zeros.scatter(-1, hh_idxs, True) # 重令牌掩码
if self.local_len > 0:
mask_bottom[:, :, -self.local_len:] = True # 额外保留最近的local_len个token(局部性保障)
# 2. 分离重令牌KV和非重令牌KV
heavy_hitter_key_states = torch.masked_select(past_key_states, mask_bottom).reshape(...) # 直接保留,不压缩
non_heavy_hitter_key_states = torch.masked_select(past_key_states, ~mask_bottom).reshape(...) # 需要压缩
return (heavy_hitter_key_states, ...), (non_heavy_hitter_key_states, ...)
4 MemoryBank: Enhancing Large Language Models with Long-Term Memory
论文地址:https://arxiv.org/abs/2305.10250
代码地址:https://github.com/zhongwanjun/MemoryBank-SiliconFriend/blob/main/README_cn.md
4.1 MemoryBank
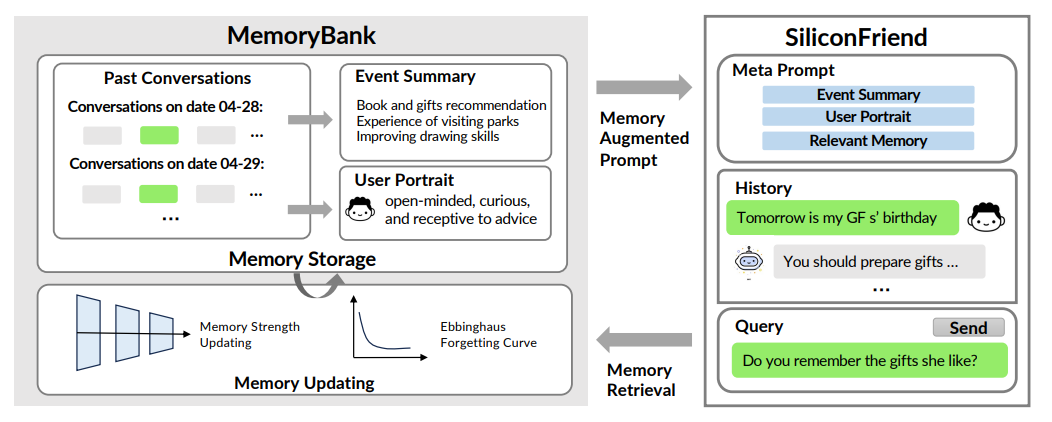
MemoryBank 是为 LLMs 设计的新型长期记忆机制,围绕三大核心支柱构建,能实现记忆存储、检索与更新,并绘制用户画像,让 LLMs 可回忆历史交互、持续深化语境理解、依据过往互动适应用户性格,提升长期交互场景下的性能。
-
记忆存储(Memory Storage):作为 Memory 的 “仓库”,以细致有序的方式存储信息,构建动态多层记忆体系。
- 深度存储:按时间顺序记录多轮对话,每条对话附带时间戳,既助力精准记忆检索,又为后续记忆更新提供详细对话历史索引。
- 分层事件总结:模仿人类记忆特点,将冗长对话浓缩为每日事件摘要,再进一步整合为全局摘要,形成分层记忆结构,便于快速把握过往交互与重要事件全貌。
- 动态性格理解:持续通过长期交互评估并更新对用户性格的认知,生成每日性格洞察,再汇总为对用户性格的全局理解,使 AI 伴侣能依据用户独特特质调整响应。
-
记忆检索(Memory Retrieval):基于记忆存储,类似知识检索任务,采用双塔密集检索模型(类似 Dense Passage Retrieval),将每轮对话和事件摘要视为记忆片段,用编码器模型预编码为向量表示,通过 FAISS 索引实现高效检索;同时将当前对话语境编码为查询向量,在记忆库中搜索最相关记忆,且编码器模型可灵活替换。
-
记忆更新机制(Memory Updating Mechanism):受艾宾浩斯遗忘曲线理论启发,模拟人类认知过程,让 AI 能依据时间推移记忆、选择性遗忘和强化记忆,使交互更自然。
- 遗忘规律:记忆保留率随时间下降,初始阶段遗忘速度快,之后减缓;定期回顾可重置遗忘曲线,提升记忆保留率。
- 数学模型:采用指数衰减模型(R = e^{-\frac{t}{S}})(R 为记忆保留率,t 为时间,S 为记忆强度),S 初始值为 1,记忆片段被回忆时 S 加 1 且 t 重置为 0,降低遗忘概率。
从上下文压缩的角度看 MemoryBank:
传统上下文压缩的本质目标,是在 LLMs 固定的上下文窗口内,通过去除冗余信息、保留核心语义(如关键实体、情感倾向、任务指令等),最大化信息密度,从而支持更长序列的交互或任务处理。而 MemoryBank 的设计初衷,正是解决 LLMs 因缺乏长期记忆导致的 “上下文断裂” 问题 —— 在持续交互(如个人陪伴、心理辅导)中,模型无法记住过往对话中的用户偏好、经历细节等关键信息,需反复重复上下文,本质上也是对 “有限上下文资源的低效利用”。
-
信息处理维度:“筛选存储” 而非 “全量压缩”
传统上下文压缩通常对当前对话序列的 “全量信息” 进行精简,目标是保留 “当前窗口内所有信息的核心语义”;而 MemoryBank 基于 “记忆重要性” 进行筛选 —— 仅将对用户理解(如性格、偏好)、交互连贯性(如过往承诺、历史话题)有价值的信息存入记忆库,而非对所有对话内容压缩存储。这种 “选择性存储” 本质是 “先筛选再保留”,比 “全量压缩” 更聚焦长期价值信息,减少了无效压缩带来的语义损耗。 -
时间维度:“长期动态管理” 而非 “短期静态压缩”
传统上下文压缩的效果局限于 “当前对话轮次或短期交互”,压缩后的信息随上下文窗口滚动而被覆盖,无法跨长时间尺度复用;而 MemoryBank 引入了基于 “艾宾浩斯遗忘曲线” 的记忆更新机制 —— 根据时间流逝和记忆重要性,对存储的信息进行 “强化(重要且近期的记忆)” 或 “遗忘(无关或远期的冗余记忆)”,实现了信息的 “长期存活与动态优化”,相当于为 LLMs 构建了 “可进化的外部记忆空间”,而非 “一次性的压缩缓存”。 -
功能定位:“辅助理解用户” 而非 “辅助当前任务”
传统上下文压缩的核心功能是 “辅助模型完成当前任务”(如基于压缩的历史对话生成连贯回复、执行复杂指令),聚焦 “任务层面的上下文连贯性”;而 MemoryBank 的核心功能是 “辅助模型理解用户”—— 通过持续合成过往交互中的用户信息(如性格、经历、情感倾向),让模型在长期陪伴中逐渐 “适配用户”,例如在心理辅导场景中,模型可通过记忆库回顾用户过往的情绪触发点,生成更具同理心的回复。这种定位超越了 “任务导向的压缩”,延伸到 “用户导向的长期认知”。
相关代码在之前的文章中分析过,这里不再赘述
5 Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
论文地址:Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
代码地址:Mem0
5.1 Mem0 的上下文压缩机制:两阶段 pipeline 实现 “动态提炼 + 智能更新”
Mem0 的压缩核心是 “提取 - 更新” 两阶段架构,通过 LLM 驱动的语义分析,实现对对话信息的 “精细化筛选” 与 “增量式优化”,避免传统压缩方法(如固定长度截断、简单摘要)的机械性缺陷。
-
提取阶段:基于双上下文的 “高价值信息筛选”
压缩的第一步是从新对话中精准定位 “值得保留的记忆”,而非无差别存储所有内容。Mem0 通过双上下文融合构建提取 prompt,确保压缩信息的 “上下文关联性”:- 全局上下文(对话摘要 S):由异步摘要生成模块定期更新,提炼整个对话的主题框架(如 “用户与助手讨论旅行计划 + dietary 偏好”),避免提取孤立信息;
- 局部上下文(最近 m 条消息):默认取前 10 条消息(m=10),捕捉未被摘要整合的细节(如 “用户提到对坚果不过敏”),补充全局摘要的颗粒度不足;
- 新对话对(mₜ₋₁, mₜ):当前用户 - 助手交互单元,是提取新记忆的直接来源。
三者融合形成 prompt P = (S, {mₜ₋ₘ,…,mₜ₋₂}, mₜ₋₁, mₜ),通过 LLM(如 GPT-4o-mini)执行提取函数 φ§,输出候选记忆集合 Ω(如 “用户偏好素食,避免乳制品”“计划 7 月去旧金山旅行”)。这一过程本质是 “语义级压缩”:将原始对话文本(可能包含冗余语句)转化为结构化、简洁的事实陈述,token 量仅为原始对话的 1/15-1/20。
-
更新阶段:基于冲突检测的 “压缩记忆优化”
传统压缩方法的痛点是 “静态存储”—— 一旦压缩信息存入,无法应对后续对话中的更新、冲突或补充(如用户后续提到 “现在可接受少量乳制品”)。Mem0 通过四操作记忆管理机制,实现压缩记忆的动态优化,确保压缩信息的 “时效性” 与 “一致性”:- 语义检索:对每个候选记忆 ωᵢ,通过向量数据库检索 top 10(s=10)语义相似的已有记忆;
- 操作判断:LLM 基于候选记忆与已有记忆的关系,选择四种操作之一:
- ADD:无相似记忆时,新增压缩记忆(如首次提取 “用户素食” 偏好);
- UPDATE:候选记忆补充已有信息时,合并压缩(如从 “用户素食” 更新为 “用户素食,可接受蛋制品”);
- DELETE:候选记忆与已有信息冲突时,删除旧压缩记忆(如用户后续表示 “不再素食”);
- NOOP:候选记忆重复或无关时,不更新(避免冗余存储)。
Mem0 这一阶段的压缩价值在于:通过 “增量更新” 而非 “全量重存”,维持记忆库的紧凑性 —— 实验显示,Mem0 的记忆库 token 量长期稳定在 7k-14k(Mem0g 因图结构略高),远低于 Zep 等平台 600k+ tokens 的冗余存储,同时避免因信息冲突导致的 “记忆混乱”(如传统 RAG 可能同时保留 “用户素食” 与 “用户非素食” 的矛盾片段)。
5.2 Mem0g 的图增强压缩:从 “线性事实” 到 “关系结构化”
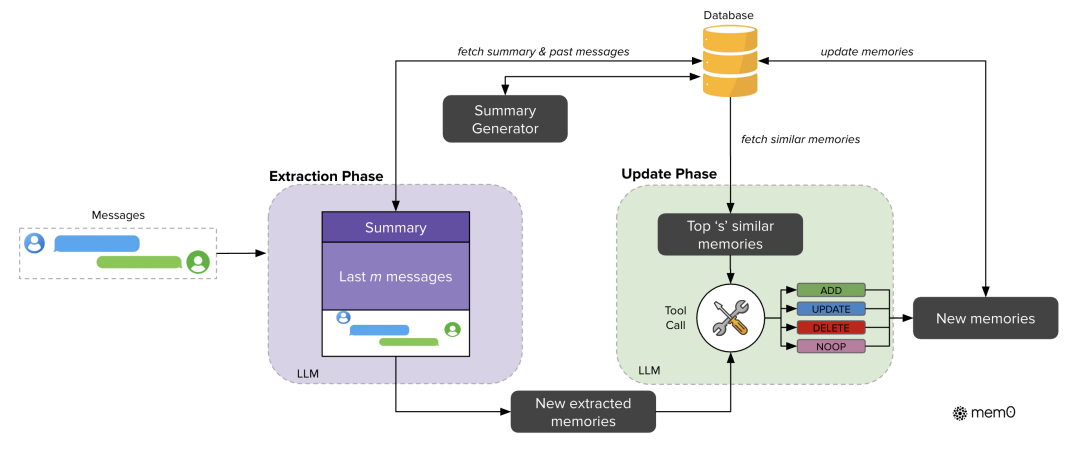
Mem0 的压缩聚焦于 “单条事实的简洁表达”,而 Mem0g 通过图结构记忆表示,实现 “事实间关系的压缩编码”,进一步提升多跳推理、temporal 推理场景下的压缩效率。其核心是将压缩记忆从 “线性文本” 转化为 “有向标记图 G=(V,E,L)”,本质是 “关系级压缩”:
-
图结构的压缩逻辑
- 节点 V(实体):压缩为 “实体类型 + 语义嵌入 + 时间戳” 三要素(如 “Alice - 人物 - 2024.5.1”“旧金山 - 地点 - 2024.5.1”),避免存储实体的冗余描述;
- 边 E(关系):压缩为三元组(vₛ, r, v_d)(如 “Alice-prefers - 素食”“Alice-plans_to_visit - 旧金山”),用结构化标签替代原始对话中的自然语言描述(如将 “我打算下个月和朋友一起去旧金山旅行,因为我喜欢那里的气候” 压缩为 “Alice-plans_to_visit - 旧金山(时间:7 月)”);
- 标签 L(语义类型):为节点和边添加类型标注(如 “人物”“地点”“偏好关系”“计划关系”),提升后续检索的精准度。
-
图压缩的优势:面向复杂推理的高效检索
传统线性压缩记忆在多跳推理(如 “用户计划去旧金山,旧金山 7 月气候如何?”)时,需逐一检索 “用户计划”“旧金山气候” 两条独立记忆,再手动建立关联;而 Mem0g 的图结构将 “实体 - 关系” 直接压缩编码,检索时通过 “实体中心遍历”(从 “Alice” 节点出发,沿 “plans_to_visit” 边找到 “旧金山”,再沿 “has_climate” 边获取气候信息)或 “语义三元组匹配”(直接匹配 “旧金山 - has_climate - 夏季温和” 三元组),大幅减少检索步骤与 token 消耗。
6 A-Mem: Agentic Memory for LLM Agents
论文地址:A-Mem: Agentic Memory for LLM Agents
代码地址:https://github.com/agiresearch/A-mem
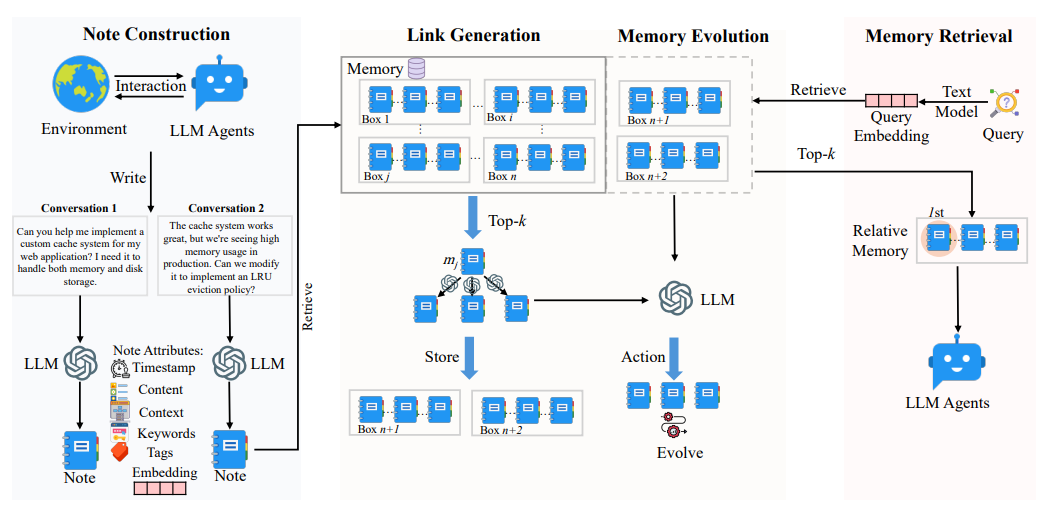
A-MEM 摒弃了传统系统“先存储后截断”的被动 Context 压缩模式,通过结构化笔记构建、动态链接生成、记忆进化三大模块,实现“主动筛选-关联保留-动态优化”的全流程 Context 压缩管理,核心逻辑如下:
6.1 结构化笔记构建:Context 的“语义级压缩”基础
传统 Context 压缩多停留在“文本截断”(如将长对话按 token 拆分),而 A-MEM 首先通过LLM 驱动的结构化笔记,对原始 Context 进行“语义提炼”,从源头上提升信息密度——这是其 Context 压缩的核心前提。
每个记忆笔记( m i m_i mi)包含 7 个核心属性,其中直接服务于 Context 压缩的关键组件为:
- 原始内容( c i c_i ci):保留原始交互文本,但仅作为“底层数据”,不直接进入 LLM 上下文窗口;
- LLM 生成组件:由 LLM 分析 c i c_i ci与时间戳( t i t_i ti)生成,是 Context 压缩的核心载体:
- 关键词( K i K_i Ki):提取 3-5 个核心概念(如“photography”“scenery”“hobby”),压缩 Context 的“核心语义标签”;
- 上下文描述( X i X_i Xi):用 1 句话概括 Context 的主题、关键观点与用途(如“Dave 在 2023 年 10 月提及新爱好摄影,分享拍摄当地风景的体验”),替代冗长原始文本;
- 标签( G i G_i Gi):按“领域+类型+场景”分类(如“hobby”“photography”“personal conversation”),为后续精准检索与压缩提供维度;
- 嵌入向量( e i e_i ei):将 c i c_i ci、 K i K_i Ki、 G i G_i Gi、 X i X_i Xi拼接后编码为向量,用于快速计算 Context 间相似度,支撑后续压缩筛选。
6.2 动态链接生成:压缩后 Context 的“关联保留”关键
Context 压缩的最大风险是“丢失关联信息”——例如,若仅保留“Dave 喜欢摄影”的孤立信息,而忽略“Calvin 喜欢音乐创作”的关联 Context,Agent 将无法回答“Dave 和 Calvin 的爱好有何不同”这类跨记忆问题。A-MEM 通过动态链接生成,在压缩 Context 的同时,主动构建并保留记忆间的关联,解决“压缩即断链”的痛点。
链接生成的核心流程(服务于 Context 压缩):
- 相似性筛选(初步压缩候选集):新笔记 m n m_n mn生成后,通过嵌入向量 e n e_n en与历史笔记的 e j e_j ej计算余弦相似度,筛选出 top-k(如 k=10)最相关的历史 Context( M n e a r n \mathcal{M}_{near}^n Mnearn),避免全量历史 Context 进入后续处理,实现“候选集压缩”;
- LLM 驱动关联判断(精准保留关键链接):LLM 分析 m n m_n mn与 M n e a r n \mathcal{M}_{near}^n Mnearn的关键词、上下文描述,判断是否建立链接(如“Dave 的摄影爱好”与“Calvin 的音乐创作”均属于“个人爱好”,建立“同类兴趣”链接),并将链接关系存入 L i L_i Li(链接集合);
- 多“盒子”关联(跨场景关联压缩):借鉴 Zettelkasten 的“盒子”概念,单条记忆可同时属于多个“语义盒子”(如“Dave 的摄影”既属于“hobby”盒子,也属于“2023 年 10 月事件”盒子),实现“一 Context 多关联”,避免关联信息在压缩中被单一分类丢弃。
6.3 记忆进化:压缩后 Context 的“动态优化”
传统 Context 压缩是“一次性操作”——一旦截断或筛选完成,Context 内容固定不变,无法适配后续任务需求变化(如早期对话中“模糊的爱好描述”,在后续明确后无法更新)。A-MEM 的记忆进化机制,让压缩后的 Context 能够“随新信息动态迭代”,实现“压缩后仍可优化信息密度”。
记忆进化的核心流程(服务于 Context 压缩):
- 触发条件:新笔记 m n m_n mn与历史笔记 m j m_j mj建立链接后,LLM 分析 m n m_n mn的新 Context 是否能补充/修正 m j m_j mj的信息;
- 进化操作:
- 补充属性:若 m j m_j mj原关键词仅为“photography”,而 m n m_n mn提到“Dave 用单反相机拍摄”,则将 m j m_j mj的关键词更新为“photography”“SLR camera”,提升 Context 的精准度;
- 修正描述:若 m j m_j mj原上下文描述为“Dave 喜欢摄影”,而 m n m_n mn明确“Dave 在 2023 年 10 月开始摄影”,则将 m j m_j mj的 X i X_i Xi更新为“Dave 在 2023 年 10 月开始摄影,使用单反拍摄当地风景”,补充关键时间信息;
- 调整链接:若 m n m_n mn提到“Dave 的摄影灵感来自 Calvin 的音乐”,则新增 m j m_j mj与“Calvin 音乐”笔记的链接,优化关联维度;
- 替代更新:进化后的 m j ∗ m_j^* mj∗替代原 m j m_j mj存入记忆库,确保压缩后的 Context 始终保持“最新、最准”,避免冗余的旧信息占用窗口。
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)