
一部分大模型算法八股
混合专家模型(MoE)是一种神经网络架构,它将一个大模型拆分成多个小模型,也就是专家模型。由门控机制来决定在处理特定输入时,激活哪些专家。核心设计思想为条件计算,即根据输入内容动态地、稀疏地激活模型的一小部分,而非每次都动用全部参数。这使得模型能拥有极大的总参数量以存储更多知识,但单次推理的实际计算成本却很低,从而将模型规模与计算成本解耦。多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键
·
-
为什么现在的大模型大部分都是Decoder-Only结构?
- 首先举例Only-Encoder结构:BERT, Only-Decoder结构:GPT,Encoder-Decoder结构:T5
- 而现在的大模型之所以都是Decoder-Only架构,除了在训练效率上的优势以外,主要是因为Encoder的双向注意力机制(每个词都可以关注其它所有的单词)会存在低秩问题(信息冗余、很多东西都没用),从而削弱模型的表达能力。
- 而Encoder-Decoder架构比Decoder-Only架构多了近一倍参数,同等参数量条件下 Decoder-Only架构为最优选择。
-
PFT(监督微调)与LORA(低秩微调)、QLoRA的区别
- PFT:一种传统的模型微调方法,在特定的数据集上进一步预训练模型,整个预训练模型的权重都会被更新,通常是为了让预训练模型可以适应特定的任务。
- LORA:一种轻量化微调的方法,核心思想为减少训练参数的数量,而不是直接更新整个模型的权重。主要是在每个Transformer的Linear层引入额外的低秩矩阵来实现参数的高效微调,使模型在训练的时候只训练新引入的低秩矩阵。
-
为什么Transformer使用的是LayerNorm而不是BatchNorm?
- 首先BatchNorm是对这一批样本的同一维度特征做归一化,需要在batch维度上计算方差,对batch_size非常敏感,而在NLP的推理阶段中会经常用到batch_size=1的情况。
- LayerNorm是对单个样本的所有维度特征做归一化。完全不依赖batch_size。
-
ChatGPT的训练过程
- Pre-train:在来自互联网的大量数据集上进行训练,使其具备理解语言的能力。
- 监督微调
- 强化学习
-
在进行SFT全参数微调的时候,是选择Chat模型还是Base模型?
- 需要根据SFT的数据量进行决定。如果拥有小于10k数据,建议选用Chat模型作为基座进行微调;如果拥有100k的数据,建议在Base模型上进行微调。
-
大模型训练及微调显存占用情况
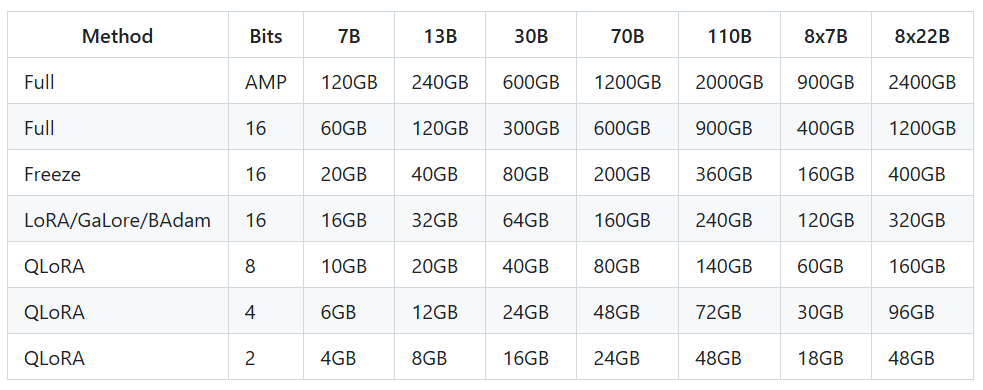
-
DeepSeek-R1和DeepSeek-R1-ZERO的区别
- DeepSeek-R1-Zero:完全依靠 强化学习(RL) 进行训练,没有经过监督微调(SFT)。
- DeepSeek-R1:在强化学习之前,先加入了冷启动数据进行微调(SFT),让模型从一开始就具备基础的语言和推理能力,之后再用强化学习优化推理能力。这样可以减少 R1-Zero 版本的缺点,提高回答质量和可读性。在 R1-Zero 的基础上,通过额外的训练步骤(冷启动数据)优化了推理质量。
-
MCP与Function Calling的区别
- Function Calling:LLM 的“意图表达器”。 它更侧重于让 LLM 能够清晰地表达出“我想要做什么?”。它赋予了 LLM 思考和决策的能力,判断何时需要借助外力来完成任务。
- MCP:工具的“超级管家”与“标准化执行器”。 它则负责确保这些“外力”(工具)能够被可靠地找到、理解并顺利执行。它关注的是“如何让工具随时待命、易于接入、规范运行?”,并且让你无需为每个工具都进行繁琐的定制化集成工作。
-
什么是MOE(混合专家模型)?其核心设计思想是什么?
- 混合专家模型(MoE)是一种神经网络架构,它将一个大模型拆分成多个小模型,也就是专家模型。由门控机制来决定在处理特定输入时,激活哪些专家。
- 核心设计思想为条件计算,即根据输入内容动态地、稀疏地激活模型的一小部分,而非每次都动用全部参数。这使得模型能拥有极大的总参数量以存储更多知识,但单次推理的实际计算成本却很低,从而将模型规模与计算成本解耦。
-
如何解决MOE中专家负载不均衡问题?
- 专家级平衡损失
- 设备级平衡损失
-
在分布式训练中,MOE如何实现专家参数的高效更新?
- 专家分家(参数切分):
- 64个专家部门(模型的专家参数)被分散到8栋办公楼(GPU)中,每个GPU只存放一小部分专家。而模型的通用部分(非专家层),就像公司的前台和HR,每栋楼都有一套。
- 任务分发(高效通信):
- GPU-0把自己需求支援的包发出去,同时也接收来自其他7个GPU发给它的包(这些包里都是需要由GPU-0上的专家处理的 tokens)
- 专家分家(参数切分):
-
COT是什么?
- Chain-of-Thought (CoT) 是指模型在输出最后答案之前,会以自然语言的形式生成思路或推理链,使得结果对于人类更具可解释性。 (提示中加入 “让我们一步一步思考”)
- 一个完整的包含 CoT 的 Prompt 往往由 指令(Instruction)、逻辑依据(Rationale) 和 示例(Exemplars) 三部分组成。
- 指令:用于描述问题并且告知大模型的输出格式;
- 逻辑依据:指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识;
- 示例:指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
-
知识蒸馏是什么?
- 教师模型:已经训练好的高性能大型模型(如BERT、GPT等)。
- 学生模型:结构更简单的小型模型(如TinyBERT、DistilBERT等),参数量远小于教师模型。
- 通过教师模型的软标签(富含类别间关系)和学生模型的任务损失(保留真实标签信息),蒸馏实现了知识的迁移
-
冷启动是什么?
- DeepSeek-R1需要先冷启动,然后再通过GRPO强化学习去训练。
- 在 AI 训练中,“冷启动”(Cold Start) 这个概念类似于刚买了一部新手机,开机后发现什么都没有,必须先安装应用、下载数据,才能正常使用。DeepSeek-R1 的训练过程也类似,如果直接用强化学习(RL)进行训练,那么 AI 一开始就会像一个“什么都不会的孩子”,不断犯错,生成一堆毫无逻辑的答案,甚至可能陷入无意义的循环。
- 为了解决这个问题,研究人员提出了“冷启动数据”的概念。即在 AI 训练的早期阶段,先用一小批高质量的推理数据微调模型,相当于给 AI 提供一份“入门指南”。
-
什么是MIA(多头潜在注意力)?
- 多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键值(KV)矩阵,显著减少了KV Cache并提高了推理效率。
- 低秩联合压缩键值技术:MLA通过低秩联合压缩键值(Key-Value),将它们压缩为一个潜在向量(latent vector),从而大幅减少所需的缓存容量。
- 多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键值(KV)矩阵,显著减少了KV Cache并提高了推理效率。

更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)