
写文章




- @Shmily17s
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
vLLM—— 用于加速大模型推理
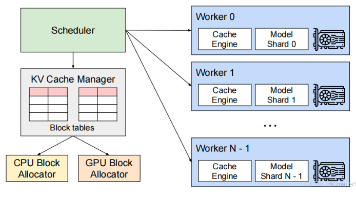
vLLM是一个用于快速LLM推理和服务的开源库,利用分页注意力(PagedAttention)有效的管理注意力key和value,增加模型的吞吐量。vLLM整体架构。
vLLM—— 用于加速大模型推理
vLLM是一个用于快速LLM推理和服务的开源库,利用分页注意力(PagedAttention)有效的管理注意力key和value,增加模型的吞吐量。vLLM整体架构。
一部分大模型算法八股
混合专家模型(MoE)是一种神经网络架构,它将一个大模型拆分成多个小模型,也就是专家模型。由门控机制来决定在处理特定输入时,激活哪些专家。核心设计思想为条件计算,即根据输入内容动态地、稀疏地激活模型的一小部分,而非每次都动用全部参数。这使得模型能拥有极大的总参数量以存储更多知识,但单次推理的实际计算成本却很低,从而将模型规模与计算成本解耦。多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键

一部分大模型算法八股
混合专家模型(MoE)是一种神经网络架构,它将一个大模型拆分成多个小模型,也就是专家模型。由门控机制来决定在处理特定输入时,激活哪些专家。核心设计思想为条件计算,即根据输入内容动态地、稀疏地激活模型的一小部分,而非每次都动用全部参数。这使得模型能拥有极大的总参数量以存储更多知识,但单次推理的实际计算成本却很低,从而将模型规模与计算成本解耦。多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键
到底了