
智能体综述:从 Agentic AI 到 AI Agent
区别于 AutoGPT 是一个研究项目,OpenAI Agent 是一个面向生产的软件架构范式,所以 OpenAI Agent 除了 “规划、行动、观测” 三元协同循环之外,还系统性的设计了 Memory(记忆体)、Planning(规划器)、Action(执行器)、Tools(工具集)四大模块以及它们之间的协作关系,进而增加了生产环境所需要的可信输出和 Prompt 子迭代优化的能力。但值得注意
目录
Agentic AI 的背景
LLM 最初的产品形态是由 OpenAI 领衔的 ChatBot(聊天机器人),底层支撑技术是 Transformer 架构大语言模型,最初专注于语言文本领域的人工智能应用场景。
LLM ChatBot 现如今已经深刻改变了我们的工作和生活,随着 LLM 技术在 toC、toB 应用场景的普及,越来越多诸如下列的局限性被发现。
- 不具有主动性:不会主动感知周围环境并且做出反应。
- 目标意识差:在多轮交互过程中可能会忘记最初的目标。
- 无持续记忆:仅仅能够关联有限的非持久化上下文信息。
- 无法与外部系统交互:只能聊天不具有改变周围环境的能力。
Agentic AI(代理式人工智能)是 LLM 时代的人工智能系统的设计理念与架构范式,旨在突破 LLM 的局限性,让 LLM 从 “内容生成” 过渡到 “任务执行”。更进一步的,Agentic AI 旨在构建具有自主能力的人工智能系统,即:能够像人类或生物一样,自主感知环境、规划决策、执行行动,最终实现特定目标。
- 自主感知环境(Perception):能够从各种数据源获取外部环境的信息,而不仅仅是聊天窗口。
- 目标导向(Goal-Oriented):理解用户意图并设定明确的目标,所有行动均围绕目标展开。
- 规划决策(Planning):基于自主感知信息和明确目标,生成自主迈向目标的一系列计划。
- 执行行动(Action):能够操作各种工具操作外部环境,执行具体的行动,继而改变环境。
- 环境交互(Interaction):观察/获取行动后的环境反馈,并根据反馈调整后续决策。
- 自适应循环(Loop):根据反馈,按需形成新一轮的 “规划、执行、观察” 循环,最终达到目标。
而 AI Agent(人工智能代理)则是 Agentic AI 的具体实现。经过了 4 年高速发展之后,现如今的 AI Agent 已经成为了探索、挖掘、扩展 LLM 能力边界的重要手段。
- 2021 年,Prompt Engineering
- 2022 年 10 月,ReAct 推理技术
- 2023 年 3 月,AutoGPT,第一个 Agent
- 2023 年 6 月,OpenAI Function Calling
- 2023 年 6 月,OpenAI Agent 架构范式
- 2024 年,Multi-Agent
AI Agent 的发展
2021 年,Prompt Engineering
Prompt Engineering(提示词工程)是一种通过精心设计和优化后的 LLM 输入提示词,用于引导 LLM 生成高质量且符合预期输出的结果。Prompt Engineering 能够让 LLM 更清晰理解用户的意图,更精确的返回预期的结果。因此,Prompt Engineering 常被人称之为 “魔法咒语”,它是一种将人类意图转化为 LLM 执行指令的翻译艺术。
Prompt Engineering 主要研究 System Prompt 和 User Prompt 这两个方向。LLM 服务提供方会将通用的 Prompt 定义为系统级别的 System Prompt,以此来约束 LLM 输入输出的基线。而用户可以自定义优化的 Prompt 则称为 User Prompt。
让 LLM 更清晰理解用户的意图
- 任务泛化能力不足问题:LLM 对复杂问题的理解有难度,比如需要多步骤推理才能解决的用户问题。
- 解决思路:使用思维链(Chain-of-Thought)Prompt 来分步引导推理和回答。
让 LLM 返回符合预期的结果
-
输出格式不可控性问题:同一问题的不同表述 LLM 可能会输出差异巨大的回答。
-
解决思路:使用设计清晰、结构化的 Prompt 来约束输出范围,如:格式、语气、长度等。
-
输出含有偏见与安全性风险问题:LLM 可能会输出隐含偏见或有害的回答。
-
解决思路:使用伦理约束 Prompt,如:以中立立场分析、避免歧视性表述等。
-
输出幻觉(Hallucination)问题:LLM 会生成虚假信息或编造事实的回答,会对业务开展产生严重的影响。
-
解决思路:使用幻觉抑制 Prompt,例如:明确要求基于已知信息回答、标注不确定内容等。
输出规范化应用示例
输出规范化 User Prompt,用于确保 LLM 输出的格式符合预期。
- 角色扮演:让 LLM 扮演特定角色,如:你是一位资深营养师,为健身人设计食谱。
- 参考文本:在 Prompt 中提供输出的参考文本,如:根据以下合同条款回答问题:[参考文本]。
- 样本学习:在 Prompt 中提供输入和输出的样本。
- 格式化输出:强制要求以 Markdown、JSON、YAML 等格式输出。
格式化输出示例:
请从以下会议记录中提取所有待办事项,要求:
1. 每条任务以 “负责人:任务内容(截止时间)” 格式输出
2. 仅输出事项,不添加解释。
3. 若无明确时间则标注 “待确认”。
会议记录:[粘贴记录文本]
输出可信性应用示例
输出可信性 User Prompt,用于确保 LLM 输出的结果和观点是可信的。
- 约束机制:如若问题无法回答,则返回 “信息不足”。
- 验证机制:例如通过外部搜索的内容对输出的结果进行验证。
- 容错机制:例如多次生成同一个问题的回答,并投票选择最佳答案。
- 交叉验证点:在关键步骤插入人工 Checkpoint 检查点。
- 可解释性增强:让 LLM 输出思考逻辑,例如:“解释你回答的依据”。
- 精确性增强:通过多重解法来确保数值计算是精确的。
可信性示例:
多重解法对比验证可靠性,请用三种不同方法解方程:2x + 4 = 10
要求:
1. 方法1:代数移项法
2. 方法2:作图法思路
3. 方法3:反向验证法
完成后检查:三种方法结果是否一致?若一致输出最终解,否则标记矛盾点
思维链引导复杂步骤应用示例
思维链 User Prompt,用于引导 LLM 遵守一系列推理步骤来解决复杂问题。例如:“请逐步推理:首先…其次…因此…”。
- 原子化拆解:将复杂问题分解为不可再分的子步骤。
- 显式占位符:用占位符 ___ 命令 LLM 思考作答。
思维链应用示例:
预测未来 6 个月 AWS EC2 的 CPU/内存用量需求。
基于历史数据制定扩容方案:
1. **数据提取**:
- 来源:CloudWatch指标 → 关键指标名:`CPUUtilization`, `MemoryUsage`
- 时间范围:过去3个月,粒度:按周均值
2. **趋势计算**:
- CPU月均增长率:(本月均值 - 3月前均值)/ 3 = ___%
- 内存使用线性回归:`y = [斜率]x + [截距]` (x为月份)
3. **峰值预留**:
- 历史峰值CPU:___%(发生时间:___)→ 安全余量设置:___%
- 突发流量容忍:是否启用Auto Scaling? □是 □否
4. **实例选型**:
- 当前配置:m5.xlarge(4vCPU/16GB)
- 6个月后需求预测:CPU = __ vCPU, 内存 = __ GB → 建议型号:_____
5. **成本优化**:
- 预留实例覆盖率计算:___% → 建议新增预留实例数:___
- Spot实例适用场景:_____(如批处理任务)
2022 年 10 月,ReAct 推理技术
2022 年 10 月,普林斯顿大学与谷歌研究院联合发表了论文《ReAct: Synergizing Reasoning and Acting in Language Models》(ReAct:在语言模型中协同推理和行动),并在论文中提出了突破性的 “Reasoning-Acting 协同框架”,讨论了在 LLM 中如何协同 Reasoning 和 Acting,即:通过 LLM 来影响周围环境。
- 论文:https://arxiv.org/abs/2210.03629
- 代码:https://github.com/ysymyth/ReAct
该论文指出了通过 LLM 来执行动作并改变环境的新思路,为后续 AutoGPT、LangChain 等第一批 AI Agent 系统的诞生奠定了理论基础。ReAct 最关键的创新在于让 LLM 打破了空间约束,使其可以操作现实世界。
ReAct 的核心思想被称为 “三元协同循环”:
- Reason(推理):思考实现目标的策略路径。
- Action(行动):调用工具执行动作。
- Observe(观察):获取环境的反馈,并可以基于反馈继续进入下一轮推理。
ReAct 循环(推理、行动、观察)可以简单理解为控制论在 AI 领域的变体,是实现影响外部世界并实现目的的基础。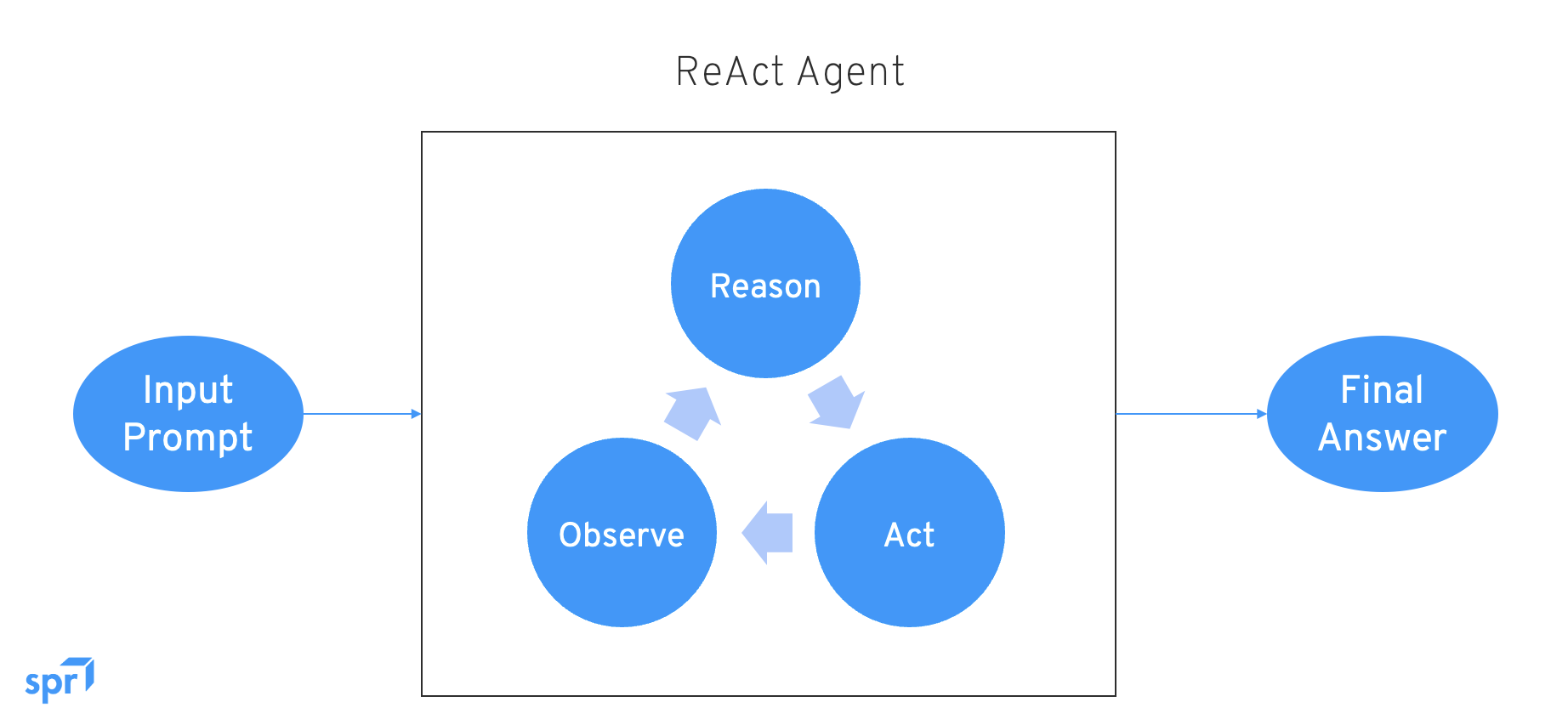
2023 年 3 月,AutoGPT 实验项目
AutoGPT 被称为世界上第一个 AI Agent,其是一个实验性质项目,参考了 ReAct 论文,旨在验证 LLM 与外部世界交互的执行能力。
- https://github.com/Significant-Gravitas/AutoGPT
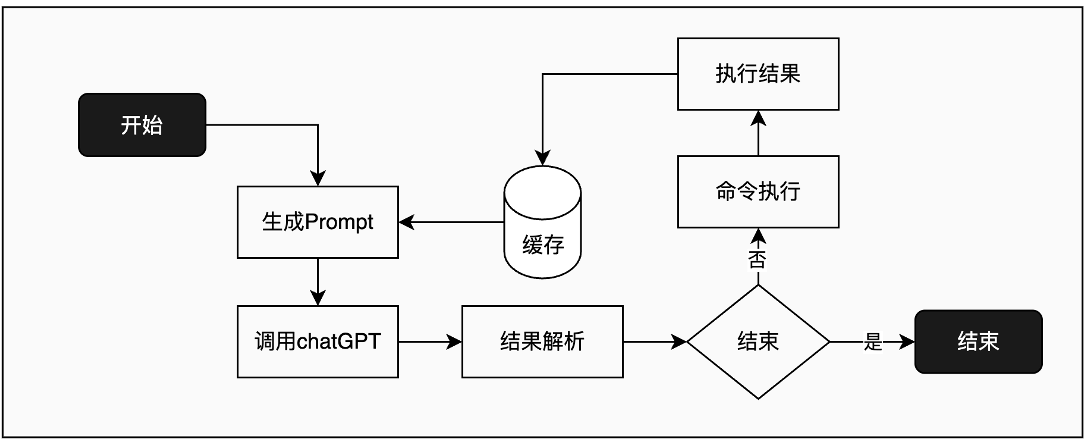
ReAct 三元协同循环设计的具体实现:
- 推理:调用 ChatGPT。
- 行动:Agent Tools 工具集提供了 Python、浏览器、API 等工具。
- 观察:通过引入缓存单元,使其可以根据历史记录自动生成并优化后续的提示词。
2023 年 6 月,OpenAI Function Calling
2023 年 6 月,OpenAI 推出 Function Calling API 功能,其借鉴了 ReAct 的 Tools Routing(工具路由)机制。ReAct 和 Function Calling 的区别如下图所示。
Function Calling Application 是 ReAct Tools Routing 的具体实现。该 App 提供 API,让用户可以定义自己的 Tools list,同时让 LLM 认识用户的 Tools list,继而 LLM 可以根据 User Prompt 执行合适的 Function Call,即:识别何时应该调用 Tools list 中的某个特定 Func 且以结构化的方式传入 parameters。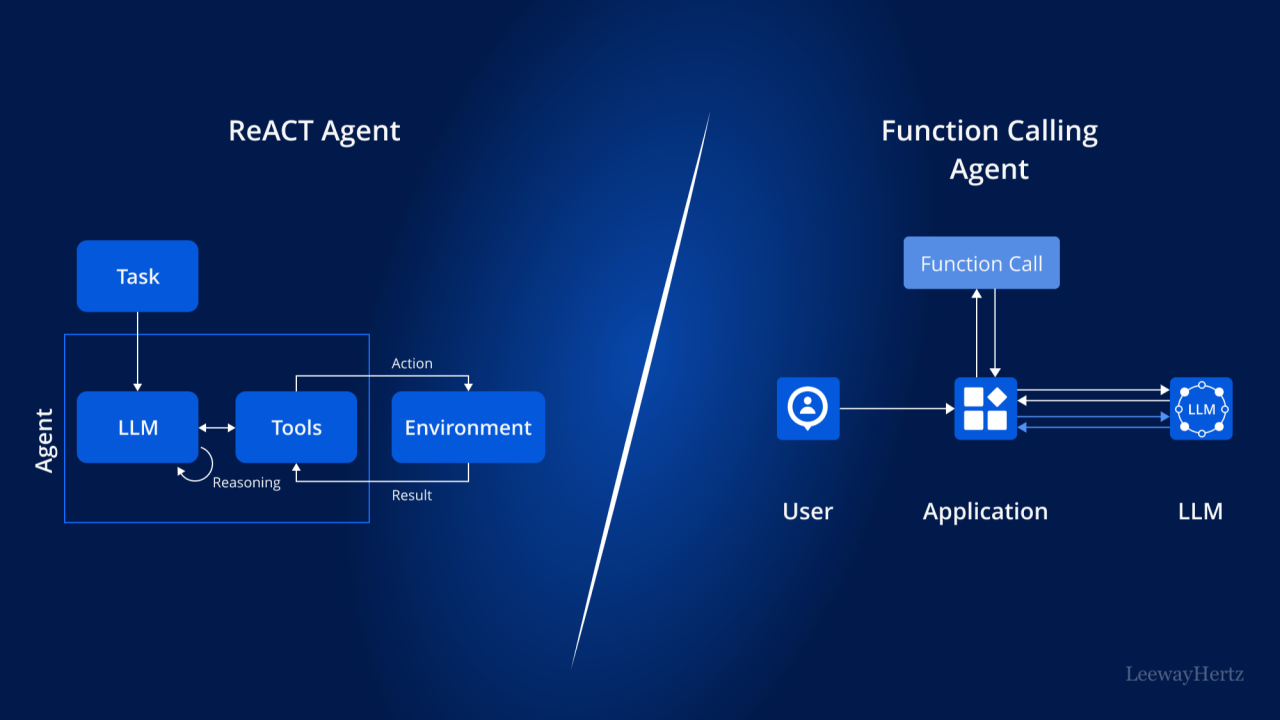
技术细节参考:https://www.cursor-ide.com/blog/openai-function-call-choice
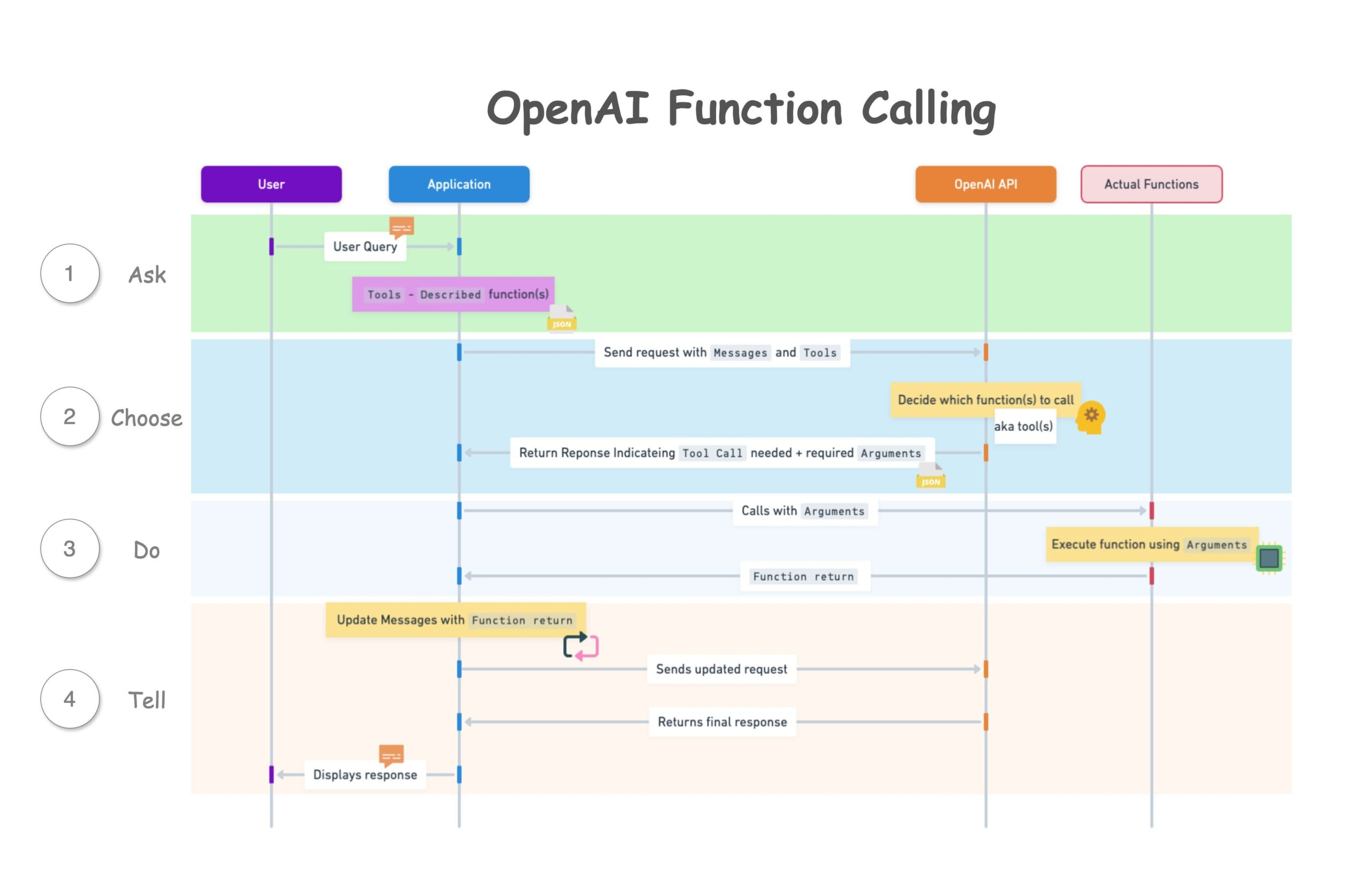
2023 年 6 月,OpenAI Agent 范式
OpenAI Agent 的核心思想依旧来自 ReAct 三元协同循环设计。区别于 AutoGPT 是一个研究项目,OpenAI Agent 是一个面向生产的软件架构范式,所以 OpenAI Agent 除了 “规划、行动、观测” 三元协同循环之外,还系统性的设计了 Memory(记忆体)、Planning(规划器)、Action(执行器)、Tools(工具集)四大模块以及它们之间的协作关系,进而增加了生产环境所需要的可信输出和 Prompt 子迭代优化的能力。
- 规划(Planning):理解输入并将复杂任务拆解为分解分步骤子任务。拥有反思、自省、思维链、子任务分解等子模块。
- 行动(Action + Tools):是 Agent 执行具体行动并影响外部环境的能力。将执行器和工具集分离使其更易于扩展。
- 记忆(Memory):为 LLM 提供一个外部的记忆存储单元,弥补了 LLM 长文本缺陷。分为短期记忆和长期记忆。
- 可信输出(Memory + Reflection):可以对输出进行评估(约束、验证、容错、解释)等操作。
- 自迭代优化(Memory + Planning):根据历史记录中的输出评估中可以自动优化后续的 Prompt,直到通过结果验证为止。
可见,OpenAI Agent 框架将任务分解、工具调用、持久存储上下文、结果验证、循环迭代这 5 大能力进行了有机整合。
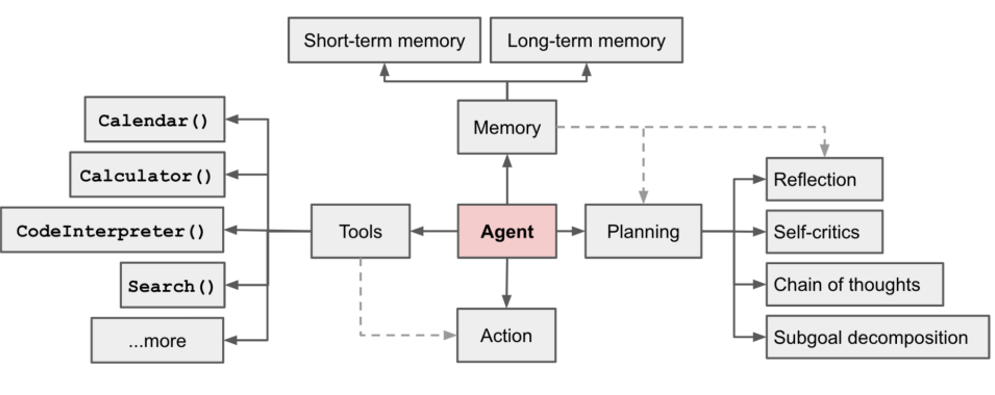
基于 OpenAI Agent 软件架构范式实现的 AI Agent 软件,可以具备以下能力,使其超越了传统自动化脚本,不再依赖固定流程(动态迭代规划),而具备一定程度的环境适应与智能行为。更具体的,其智能体现在:
- 自主性(Autonomy):AI Agent 可以根据预设的目标自主地规划和执行任务,不需要每一步都由人类直接控制。
- 智能性(Intelligence):AI Agent 具备一定的学习、推理、决策和问题解决能力。
- 反应性与适应性(Reactivity & Adaptation):AI Agent 能够通过各种方式 “感知” 它所处的环境并作出动态响应,进而在复杂环境中持续学习和优化自身行为。
2024 年,Multi-Agent 范式
尽管 OpenAI Agent 架构范式已经在特定场景中取得了突破,但在复杂、多步骤或协作场景中的可扩展性仍然受到限制,继而催生了 Multi-Agent 架构范式。
Multi-Agent 的概念因为斯坦福论文 《Generative Agents: Interactive Simulacra of Human Behavior》而被广泛传播。在论文中,研究者构建了一个虚拟小镇 Simulacra,并放置了 25 个智能体,它们之间共享记忆,采用了三重权重 Retrieve 记忆检索算法,并且具有 Plan 和 Reflect 能力。
- https://arxiv.org/abs/2304.03442
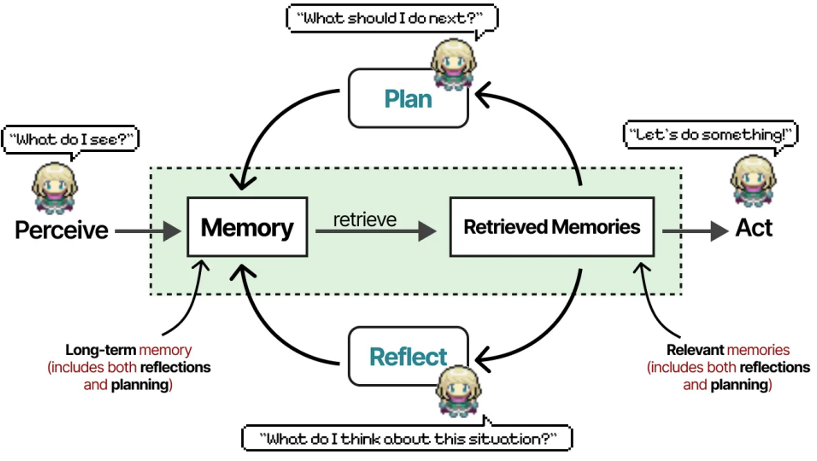
在该虚拟小镇交互实验中得出了以下关键结论:
- “LLM + 记忆 + 环境反馈” 智能体能够生成高度拟人行为,例如:能记住朋友、传播消息(比如谁要竞选市长,很快全镇都知道了),还能形成新的人际关系。
- 分层记忆架构是行为连贯性的关键。瞬时记忆:存储当前感知(所见所闻);短期记忆:保留近期关键事件(如约会);长期记忆:人格核心信念(如我讨厌咖啡)。
- 社会关系的涌现机制:智能体通过信息交换自主构建社会结构。
- 如果去掉 “记忆、反思、规划” 中的任意一个功能,智能体的行为就会变傻(比如反复吃午饭,或者记不住刚聊过的事)。
Simulacra 虚拟小镇启示了 Multi-Agent 范式在构建 “社会智能体” 方面的潜力。从定义上来看,Multi-Agent 系统由多个 Agents 组成,Multi-Agent 系统的自主性要高于 Single-Agent,能够处理需要复杂协作的任务。同时 Multi-Agent 之间的信息共享,使其能够在更广泛的任务和环境中进行学习和适应。
Multi-Agent v.s. Single-Agent 的主要区别如下:
- 专责智能体协作体系(Ensemble of Specialized Agents):每个 Agent 负责不同功能,并通过消息队列、共享内存等方式进行通信。例如 MetaGPT 采用模拟公司部门(如 CEO、CTO、工程师)角色的方式构建智能体,角色模块化、可复用、职责清晰。
- 高级推理与规划能力(Advanced Reasoning and Planning):Multi-Agent 系统内嵌递归推理机制,如 ReAct、思维链、思维树等框架。这些机制允许智能体将复杂任务分解为多个推理阶段,评估中间结果,并动态调整行动计划,从而提升系统应对不确定性或任务失败的能力。
- 持久化记忆架构(Persistent Memory Architectures):Multi-Agent 通过持久记忆系统能够在多个任务周期或 Agents 共享知识。
- 编排层 / 元智能体(Orchestration Layers / Meta-Agents):Multi-Agent 的一项关键创新是引入了元智能体,用于负责统一编排、协调各子智能体的生命周期、管理依赖关系、分配角色并解决冲突。这类元智能体通常包含任务管理器、评估器或协调者角色。例如在 ChatDev 系统中,一个 CEO 元智能体将子任务分配给不同的部门智能体,并整合它们的输出形成统一的策略响应。
可见,Single-Agent 更适用于单一任务的自动化处理,例如:智能客服。而 Multi-Agent 则更接近人类的组织式智能,例如:多机器人协调系统。
AI Agent 的产品形态和技术流派
通过上文的分析,我们知道一个 AI Agent 软件架构需要具备以下通用模块,此外根据产品具体的形态不同,还会具有各自的特性和模块。
- LLM 选择器、连接器:根据不同场景选择侧重不同的 LLM 模型进行推理。
- 规划器和迭代规划器:支持 Planning 生成 TODO list,支持 Reflect 迭代优化 TODO list。
- Action:Func Calling、Tool Calling 执行器和工具集。
- 上下文处理器:上下文优化、上下文压缩。
- 记忆模块:短期记忆、长期记忆、记忆压缩。
- 执行环境:沙箱、虚拟机等。
ReAct 自主规划智能体
通用智能体
ReAct 自主规划智能体是实现通用智能体的主要方式,如:Manus 本身是一个 ReAct 架构的 Agent,他的成功在于积累了大量工程实践得出的工具和优秀的上下文工程。
- 区分定义:核心是以目标为导向的动态规划,智能体会根据反馈不断调整规划和行动,四步法(观察、推理、行动、总结)。
- 特殊模块:记忆压缩模块、Plan Loop 模块
- 应用场合:问题复杂且执行路径不固定,需要大量信息代替人类提示词
DeepResearch 智能体
典型产品有 Perplexity,通过搜索作为 Reference 在知识发现(深度研究)场景中弥补了 LLM 的幻觉问题。
- 区分定义:强调信息的研究主题整理,包括:收集、分类、归纳、逻辑化。但不强调新思路、新方案、新观点。主要解决快速整理旧数据、旧信息的问题。
- 特殊模块:Reference 搜索器。
可迭代进化智能体
典型产品有 Google AlphaEvolve,侧重自迭代循环,探索人类未知领域的边界。
- 区分定义:是一个能够帮助人类突破知识边界的智能体,能够对特性问题提出新思路新方案,不断迭代进化。
- 特殊模块
- Agent 并发:并发解决同一个问题得到不同的答案,保证思路的多样性。
- 评估器:在多个 Agent 并发出评估更正确的方向,继续进入下一轮并发。
Workflow 流程智能体
Workflow 智能体是现如今 toB 智能体落地较好的方式,更易于结合企业现有的 SOP 工作流程。如:LangGraph,通过不同的图结构来编排 LLM 决策过程,从而实现更复杂、更可靠的执行路径。
- 区分定义:开发者人为的对任务进行拆解,智能体需要提供任务/流程的灵活编排能力。需要学习图知识等概念,对开发者的能力要求较高,才能开发出好用的智能体。
- 特殊模块:
- 全局状态持久化:在多个流程节点中进行信息共享,例如状态机、变量等。
- 逻辑控制组件:if-else、do-while 循环等逻辑控制。
- 流程控制组件:顺序执行、并行执行、循环执行。
- 应用场景:流程复杂但固定的流程。
从逻辑的角度对比,Workflow 是企业信息化转型的提效逻辑,而 ReAct 是以目标为导向的问题解决逻辑。如下图,从技术的角度对比,Workflow 是一个 Router(路由器)设计,而 ReAct 是 Fully Autonomous(自主规划)设计,Agent 对问题的 Control 掌控力度不同。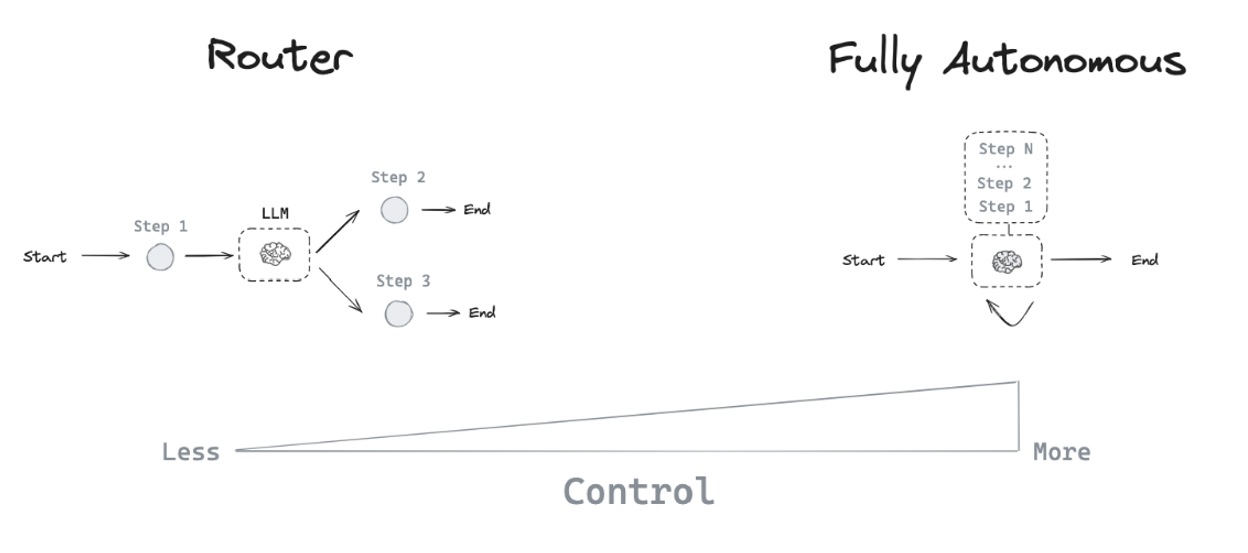
Multi-Agent 协作智能体
Multi-Agent 诞生于 “角色扮演”,强调 “人事组织架构” 和 “协作”,被寄希望于以此形态构建庞大的 “企业智能系统”。如:CrewAI 是最知名的 Multi-Agent Platform 之一 ,其设计灵感来自现实世界中的团队分工,每个智能体扮演不同的角色,分配不同的任务并共享目标。本质是构建通过 Multi-Agent 的组织形式来构建 AI 团队,模拟人类组织分工协作模式。
- 协调 Agent:任务分解与调度(类似项目经理)
- 专家 Agent:垂直领域执行(如 Stable Diffusion 绘图 Agent)
- 验证 Agent:结果可靠性评估
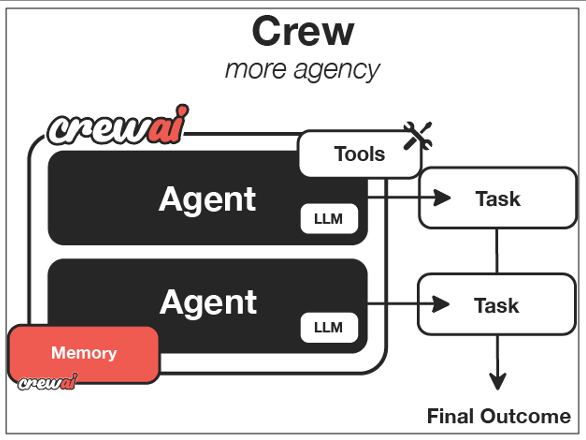
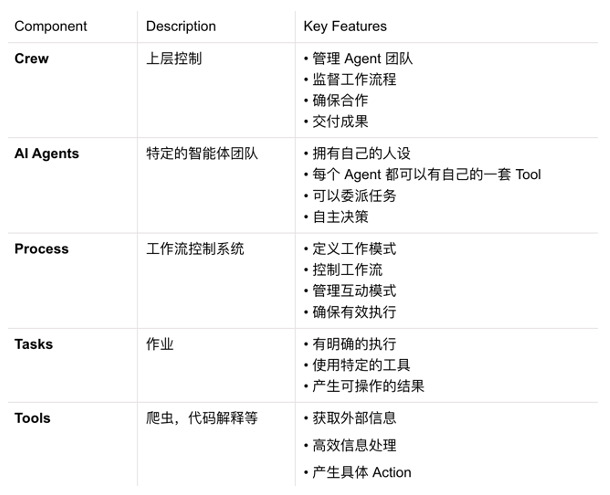
- 区分定义:强调多个 Agent 之间的自治、协作和通信。
- 自治:每个 Agent 各自都能够完成特定领域的完整任务。例如:运维智能体、研发智能体。
- 协作:多个 Agent 结合能够完成更复杂的跨领域的完整任务。例如:DevOps 组织架构角色扮演 Multi-Agent 串联多个智能体。
- 特殊组件:投票/决策模块、共享记忆模块、A2A 通讯模块。
- 应用场景:系统庞大,部门划分复杂,不同部门提供各自的智能体。
但值得注意的是,现如今的 Multi-Agent 产品往往容易陷入华而不实的窘境,更强调技术而非业务问题的解决。在很多产品营销中存在为了 Multi 而 Multi 的现象,但实际上单一 Agent 能够满足的功能,没必要划分为多个 Agent。
AI Agent 面临的关键挑战和解决思路
关键问题
上述可知,ReAct 自主规划智能体是接近 AI Agent 最初定义的形态,目标是 “完全自主人工智能”,目前主要发布 toC 产品。区别于 Workflow 流程智能体,后者在 toB 领域有更多的落地案例,但存在用 “人力智能” 补充 “人工智能” 的客观情况。
造成这种现状的根本原因是 LLM 和 AI Agent 都尚处于高速发展的早期阶段,必然存在诸多问题和挑战。这些问题中,一部分是从 LLM 大语言模型继承而来的,而另外一部分则是软件工程方面的挑战。例如:缺乏统一的标准架构、通信协议与可验证机制,难以进行跨平台集成与通用化开发等。
这里回到 AI Agent 的 “规划、行动、记忆、可信输出、优化循环” 五大方面,并围绕这五大方面来归纳出 AI Agent 亟需解决的关键挑战。
- 私域知识理解能力:LLM 默认只具有公域知识,但不理解企业内部定义的私域知识,导致 LLM 难以理解企业内部场景。
- 实时数据能力:LLM 默认只具有旧知识,而 Agent 规划往往需要实时数据。
- 幻觉抑制能力:LLM 幻觉无法保证 Agent 可信输出和优化循环的质量,例如在循环规划时,同一个问题可能出现完全不同的 2 个规划。
- 可解析性:LLM 推理过程要么黑盒,要么太过冗长,可解析性差会导致用户质疑推理结果,使得结果输出不可信。
- 无限循环风险:Agent 以目标为导向的自优化循环存在无限循环风险,这意味着高成本风险。
- 错误传播:Multi-Agent 场景中,往往具有复杂的协同路径,也会涉及多次 LLM 交互。存在叠加错误和错误传播的问题,例如一件事情可能有 20 多个步骤,会放大错误的概率。
解决思路
使得 Agent 可实现更符合上下文的行为。例如,Agent 在生成摘要之前会验证检索到的数据。在 multi-Agent 系统中,这种循环对于协作一致性至关重要。每个 Agent 的观察结果需要与其他 Agent 的输出进行协调。要实现这一点,共享内存和一致的日志记录是关键。
-
RAG(检索增强生成):结合 “实时动态数据检索” 和 “私域静态数据库”,RAG 能够解决实时数据、私域知识、大模型幻觉等问题。例如:在企业知识库和智能客服场景中,RAG 可以确保结果输出基于外部事实。在 Multi-Agent 系统中,RAG 作为共享的 “事实基础”,能确保 Agent 之间的一致性,并减少因上下文不一致导致的错误传播。
-
程序化的提示词工程:提示词工程的程序化实现可以对 LLM 输入输出进行结构化设计和约束,可以为不同的 Agent 类型(如规划者、检索者、总结者)根据其功能使用结构化的提示词模版。集合提示词模版、RAG 等技术,可以减少手动调整提示词的不稳定性。
-
分层记忆架构:除了短期记忆、长期记忆,还允许每个 Agent 可以维护私有记忆(本地内存)和公共记忆(共享内存),从而实现 Agent 的个性化决策和协作性决策。目前,研究者正探索情景记忆(Episodic Memory)、语义记忆(Semantic Memory)和向量记忆(Vector Memory)等不同架构。
-
反思与自我批判:引入 “结果验证模块+异常重试机制+置信度评估模块”,强化多轮迭代测试与评估体系。Agent 在完成任务时可以使用二次推理过程来审查自己的输出,从而提高鲁棒性和减少错误率。这项能力也可以扩展到 Agent 之间的相互评估。例如,一个验证 Agent 可以审计总结其他 Agent 的工作,确保协作质量控制。
-
监控、审计与可解释性:通过记录提示词输入、工具调用、结果输出、推理过程、系统日志等跟踪审计机制,继而构建 Agent 的可解析性能力。设计完善的事实核查与答案校验流程,用于对 AI Agents 进行事后分析、性能调整、故障跟踪、优化行为。对于识别哪个 Agent 导致了错误以及在什么条件下发生错误是十分关键的。
-
设置人工检查点:基于可解析性,在关键环节设置人工检查点二次确认,引入人机协同机制,对低可信度答案增加人工审核功能。
-
基于角色的 Multi-Agent 编排:一方面,帮助元智能体更好的完成任务编排和分发,继而再角色智能体中进行分隔推理。另一方面,为 AI Agents 引入基于角色的访问控制、沙箱和身份解析,以确保 Agent 在其范围内行动,并且其决策可以被审计或撤销。
-
设置预算熔断机制:设置最大迭代次数,如 max_cycles=50,避免无限循环。设置成本监控,如 OpenAI 费用警报。
-
建立企业数据治理机制:企业内部数据往往散落在不同系统,格式不一,质量参差不齐,难以获取和整合高质量数据来驱动 AI Agent。搭建企业级数据治理战略,打破数据孤岛。例如:初期建立简单的数据集成、数据清洗数据平台,后期可逐步扩大至统一的数据中台或数据湖仓。
Agentic AI 的未来
Agentic AI 的终极目标是主动智能(Proactive Intelligence),不再局限于被动响应,而是能自动感知环境,自适应环境,基于目标主动推理。Agentic AI 的未来需要 LLM 和 AI Agent 两方面进行突破:
- LLM 长文本
- LLM 幻觉和可信输出
- Agent 因果推理和模拟规划
- Multi-Agent 统一编排、统一通信标准、统一集成架构,如:MCP、A2A 协议等
- LLM 伦理治理
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)