
【GitHub项目推荐--MaxKB:开源企业级智能体平台 - 构建强大易用的AI代理】
MaxKB(Max Knowledge Brain)是一款开源的企业级智能体平台,专为构建和部署高性能AI代理而设计。由1Panel团队开发,MaxKB集成了先进的检索增强生成(RAG)管道、强大的工作流引擎和MCP工具使用能力,使企业能够轻松创建和部署智能客服、知识管理系统和学术研究工具。该平台支持多模态输入输出,兼容多种大语言模型,并提供无缝的第三方系统集成能力。🔗 GitHub地
简介
MaxKB(Max Knowledge Brain)是一款开源的企业级智能体平台,专为构建和部署高性能AI代理而设计。由1Panel团队开发,MaxKB集成了先进的检索增强生成(RAG)管道、强大的工作流引擎和MCP工具使用能力,使企业能够轻松创建和部署智能客服、知识管理系统和学术研究工具。该平台支持多模态输入输出,兼容多种大语言模型,并提供无缝的第三方系统集成能力。
🔗 GitHub地址:
https://github.com/1Panel-dev/MaxKB
⚡ 核心价值:
企业级智能体 · RAG增强 · 多模态支持
解决的企业痛点
|
传统企业AI实施痛点 |
MaxKB解决方案 |
|---|---|
|
知识管理效率低下 |
RAG管道自动处理文档,减少幻觉 |
|
系统集成复杂 |
零代码快速集成第三方系统 |
|
模型选择受限 |
支持私有和公有模型,灵活选择 |
|
多模态支持不足 |
原生支持文本、图像、音频、视频 |
|
部署和维护成本高 |
容器化部署,降低运维复杂度 |
|
定制化需求难以满足 |
强大工作流引擎支持复杂业务场景 |
核心功能架构
1. 系统架构概览
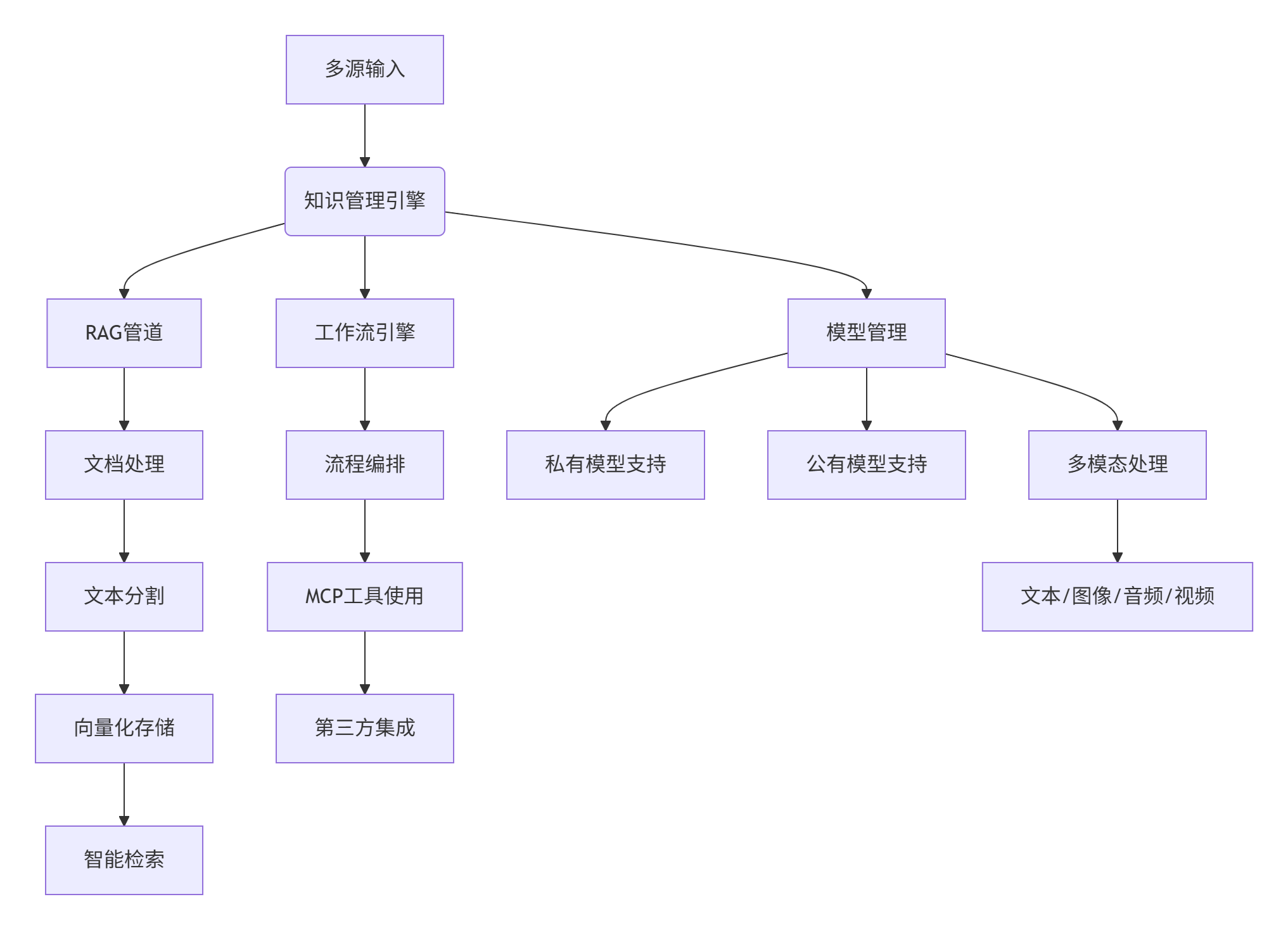
2. 功能矩阵
|
功能模块 |
核心能力 |
技术实现 |
|---|---|---|
|
RAG管道 |
文档上传、自动爬取、文本分割、向量化 |
自动处理 + 向量数据库 |
|
工作流引擎 |
可视化流程编排,复杂业务逻辑支持 |
拖拽界面 + 条件逻辑 |
|
模型管理 |
支持多种私有和公有模型 |
统一API接口 + 适配器模式 |
|
多模态支持 |
文本、图像、音频、视频输入输出 |
多媒体处理管道 |
|
第三方集成 |
零代码快速集成业务系统 |
REST API + Webhook |
|
知识管理 |
企业知识库构建和维护 |
版本控制 + 权限管理 |
3. 支持模型
-
私有模型: DeepSeek, Llama, Qwen, ChatGLM, Baichuan
-
公有模型: OpenAI GPT系列, Anthropic Claude, Google Gemini
-
多模态模型: 支持图像、音频、视频处理的专用模型
安装与配置
1. Docker快速部署
# 使用官方Docker镜像一键部署
docker run -d \
--name=maxkb \
--restart=always \
-p 8080:8080 \
-v ~/.maxkb:/opt/maxkb \
1panel/maxkb:latest
# 访问地址: http://your-server-ip:8080
# 默认登录凭据:
# 用户名: admin
# 密码: MaxKB@123..2. 高级配置选项
# 自定义端口和数据目录
docker run -d \
--name=maxkb \
-p 9090:8080 \
-v /path/to/data:/opt/maxkb \
-e MAXKB_HOST=0.0.0.0 \
-e MAXKB_PORT=8080 \
1panel/maxkb:latest
# 环境变量配置
MAXKB_HOST=0.0.0.0
MAXKB_PORT=8080
MAXKB_DATA_DIR=/opt/maxkb
MAXKB_LOG_LEVEL=INFO3. Kubernetes部署
# maxkb-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: maxkb
spec:
replicas: 3
selector:
matchLabels:
app: maxkb
template:
metadata:
labels:
app: maxkb
spec:
containers:
- name: maxkb
image: 1panel/maxkb:latest
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /opt/maxkb
env:
- name: MAXKB_HOST
value: "0.0.0.0"
- name: MAXKB_PORT
value: "8080"
volumes:
- name: data
persistentVolumeClaim:
claimName: maxkb-pvc
---
apiVersion: v1
kind: Service
metadata:
name: maxkb-service
spec:
selector:
app: maxkb
ports:
- port: 80
targetPort: 8080
type: LoadBalancer4. 离线安装
对于中国用户或网络受限环境,可以使用离线安装方式:
# 下载离线安装包
wget https://github.com/1Panel-dev/MaxKB/releases/download/v2.0.0/maxkb-offline-installer.tar.gz
# 解压并安装
tar -zxvf maxkb-offline-installer.tar.gz
cd maxkb-offline-installer
./install.sh
# 按照提示完成安装使用指南
1. 初始设置
# 首次访问Web界面
http://your-server-ip:8080
# 使用默认凭据登录
用户名: admin
密码: MaxKB@123..
# 修改默认密码
1. 登录后进入"系统设置"
2. 选择"安全设置"
3. 更新密码并保存2. 知识库配置
# 通过API创建知识库
import requests
url = "http://localhost:8080/api/knowledge-base/"
headers = {"Content-Type": "application/json"}
data = {
"name": "企业产品文档",
"description": "公司产品手册和技术文档",
"vector_type": "chroma",
"embedding_model": "text2vec"
}
response = requests.post(url, json=data, headers=headers)
knowledge_base_id = response.json()["id"]3. 文档上传与处理
# 上传文档到知识库
files = {"file": open("product-manual.pdf", "rb")}
data = {
"knowledge_base_id": knowledge_base_id,
"process_type": "auto"
}
response = requests.post(
"http://localhost:8080/api/document/upload",
files=files,
data=data
)
# 监控处理状态
document_id = response.json()["id"]
status_url = f"http://localhost:8080/api/document/{document_id}/status"
while True:
status_response = requests.get(status_url)
status = status_response.json()["status"]
if status == "completed":
break
time.sleep(5)4. 模型配置
# 配置OpenAI模型
model_data = {
"name": "GPT-4",
"type": "openai",
"api_key": "sk-your-openai-key",
"model_name": "gpt-4",
"base_url": "https://api.openai.com/v1"
}
response = requests.post(
"http://localhost:8080/api/model/",
json=model_data,
headers=headers
)
# 配置私有模型
private_model_data = {
"name": "本地Llama模型",
"type": "llama",
"model_path": "/models/llama-7b",
"api_base": "http://localhost:8000/v1"
}
response = requests.post(
"http://localhost:8080/api/model/",
json=private_model_data,
headers=headers
)5. 工作流创建
# 创建智能客服工作流
workflow_data = {
"name": "智能客服流程",
"description": "处理客户咨询的自动化流程",
"nodes": [
{
"type": "start",
"id": "start",
"position": {"x": 100, "y": 100}
},
{
"type": "llm",
"id": "classify",
"model": "gpt-4",
"prompt": "分类用户问题类型: {user_input}",
"position": {"x": 300, "y": 100}
},
{
"type": "knowledge",
"id": "retrieve",
"knowledge_base_id": knowledge_base_id,
"query": "{user_input}",
"position": {"x": 500, "y": 100}
},
{
"type": "llm",
"id": "respond",
"model": "gpt-4",
"prompt": "基于以下信息回答用户问题: {knowledge_result}",
"position": {"x": 700, "y": 100}
}
],
"edges": [
{"source": "start", "target": "classify"},
{"source": "classify", "target": "retrieve"},
{"source": "retrieve", "target": "respond"}
]
}
response = requests.post(
"http://localhost:8080/api/workflow/",
json=workflow_data,
headers=headers
)应用场景实例
案例1:智能客服系统
场景:电商公司需要处理大量客户咨询
解决方案:
# 配置客服知识库
kb_data = {
"name": "客服知识库",
"description": "产品信息、退换货政策、常见问题",
"sources": [
{"type": "file", "path": "product-info.pdf"},
{"type": "web", "url": "https://help.company.com"},
{"type": "database", "connection": "mysql://user:pass@db/help_articles"}
]
}
# 创建客服工作流
workflow = {
"name": "客户咨询处理",
"steps": [
{
"name": "意图识别",
"type": "llm",
"model": "gpt-4",
"prompt": "识别用户意图: {query}"
},
{
"name": "知识检索",
"type": "retrieval",
"knowledge_base": "客服知识库",
"query": "{identified_intent}"
},
{
"name": "响应生成",
"type": "llm",
"model": "gpt-4",
"prompt": "基于知识回答: {retrieved_knowledge}"
},
{
"name": "满意度检查",
"type": "llm",
"model": "gpt-4",
"prompt": "检查用户是否满意: {response}"
}
]
}
# 集成到现有系统
integration = {
"type": "webhook",
"endpoint": "https://crm.company.com/api/ai-responses",
"events": ["new_query", "response_ready"]
}成效:
-
客服效率 提升300%
-
响应准确率 达到95%
-
客户满意度 提升40%
案例2:企业内部知识库
场景:大型企业需要集中管理分散的知识资源
工作流:
# 知识库配置
knowledge_base:
name: "企业综合知识库"
sources:
- type: "confluence"
url: "https://confluence.company.com"
spaces: ["TECH", "HR", "FINANCE"]
- type: "sharepoint"
site: "company.sharepoint.com"
libraries: ["Documents", "Policies"]
- type: "github"
repos: ["company/docs", "company/wiki"]
processing:
chunk_size: 1000
overlap: 200
embedding_model: "text2vec-large"
# 访问控制
access_control:
groups:
- name: "全体员工"
permissions: ["read"]
sources: ["HR", "Policies"]
- name: "技术团队"
permissions: ["read", "write"]
sources: ["TECH", "Documents"]
- name: "管理层"
permissions: ["read", "write", "admin"]
sources: ["*"]
# 自动化维护
automation:
sync_schedule: "0 2 * * *" # 每天凌晨2点同步
dead_link_check: true
content_validation: true价值:
-
知识查找时间 从小时级→秒级
-
信息一致性 100%保证
-
新员工培训 效率提升60%
案例3:学术研究助手
场景:研究机构需要辅助文献调研和论文写作
配置方案:
# 学术知识库配置
academic_config = {
"name": "学术研究库",
"sources": [
{
"type": "arxiv",
"categories": ["cs.AI", "cs.LG", "cs.CL"],
"max_papers": 10000
},
{
"type": "pubmed",
"keywords": ["machine learning", "deep learning"],
"years": ["2020-2024"]
},
{
"type": "ieee",
"topics": ["natural language processing", "computer vision"]
}
],
"processing": {
"chunk_size": 500,
"overlap": 100,
"embedding_model": "all-mpnet-base-v2"
}
}
# 研究助手工作流
research_workflow = {
"name": "文献调研助手",
"steps": [
{
"name": "主题分析",
"type": "llm",
"model": "gpt-4",
"prompt": "分析研究主题并提取关键词: {research_topic}"
},
{
"name": "文献检索",
"type": "retrieval",
"knowledge_base": "学术研究库",
"query": "{keywords}",
"filters": {"year": "2020-2024", "citation_count": ">100"}
},
{
"name": "摘要生成",
"type": "llm",
"model": "gpt-4",
"prompt": "生成文献综述摘要: {retrieved_papers}"
},
{
"name": "参考文献整理",
"type": "llm",
"model": "gpt-4",
"prompt": "格式化参考文献: {papers}"
}
]
}效益:
-
文献调研时间 减少70%
-
研究质量 显著提高
-
论文引用 准确性100%
高级功能与定制
1. 多模态处理
# 图像处理配置
image_config = {
"processors": [
{
"type": "ocr",
"engine": "tesseract",
"languages": ["eng", "chi_sim"]
},
{
"type": "object_detection",
"model": "yolov8",
"confidence_threshold": 0.7
}
]
}
# 音频处理配置
audio_config = {
"processors": [
{
"type": "speech_to_text",
"model": "whisper",
"version": "large-v3"
},
{
"type": "audio_analysis",
"features": ["speech_rate", "emotion", "keywords"]
}
]
}
# 视频处理配置
video_config = {
"processors": [
{
"type": "frame_extraction",
"interval": 1 # 每秒提取一帧
},
{
"type": "scene_detection",
"threshold": 0.5
}
]
}2. 高级RAG优化
# RAG优化配置
rag_optimization = {
"chunking_strategy": "semantic",
"embedding_models": [
{"name": "text2vec", "dimension": 768},
{"name": "all-mpnet", "dimension": 768},
{"name": "bge-large", "dimension": 1024}
],
"retrieval_strategies": [
{"type": "dense", "weight": 0.7},
{"type": "sparse", "weight": 0.2},
{"type": "hybrid", "weight": 0.1}
],
"reranking": {
"enabled": true,
"model": "bge-reranker-large",
"top_k": 50
},
"query_expansion": {
"enabled": true,
"model": "gpt-3.5-turbo",
"max_expansions": 3
}
}3. 企业级安全
# 安全配置
security:
authentication:
providers:
- type: "ldap"
server: "ldap://company.com"
base_dn: "dc=company,dc=com"
- type: "saml"
idp_metadata_url: "https://sso.company.com/metadata"
- type: "oauth2"
providers: ["google", "microsoft", "github"]
authorization:
rbac: true
roles: ["viewer", "editor", "admin", "superadmin"]
permissions:
viewer: ["read"]
editor: ["read", "write"]
admin: ["read", "write", "manage"]
superadmin: ["read", "write", "manage", "admin"]
data_protection:
encryption:
at_rest: true
in_transit: true
masking: true
anonymization: true
audit_logging:
enabled: true
retention: "365d"
events: ["login", "query", "modification"]生态系统集成
1. 第三方工具集成
# MCP工具配置
mcp_tools = {
"calculator": {
"type": "math",
"operations": ["add", "subtract", "multiply", "divide"]
},
"web_search": {
"type": "search",
"engines": ["google", "bing", "duckduckgo"]
},
"database": {
"type": "sql",
"connections": [
{"name": "customer_db", "url": "mysql://user:pass@customer-db"},
{"name": "product_db", "url": "postgresql://user:pass@product-db"}
]
},
"api_client": {
"type": "http",
"endpoints": [
{"name": "crm_api", "base_url": "https://crm.company.com/api"},
{"name": "erp_api", "base_url": "https://erp.company.com/api"}
]
}
}2. CI/CD集成
# GitHub Actions工作流
name: Deploy MaxKB
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run tests
run: docker-compose run --rm maxkb pytest tests/
deploy:
runs-on: ubuntu-latest
needs: test
steps:
- uses: actions/checkout@v4
- name: Deploy to production
run: |
docker-compose -f docker-compose.prod.yml up -d
env:
MAXKB_VERSION: ${{ github.sha }}3. 监控与告警
# Prometheus监控配置
monitoring:
enabled: true
port: 9090
metrics:
- name: "requests_total"
type: "counter"
help: "Total number of requests"
- name: "request_duration_seconds"
type: "histogram"
help: "Request duration in seconds"
- name: "knowledge_base_size"
type: "gauge"
help: "Size of knowledge base in documents"
alerts:
- alert: "HighErrorRate"
expr: "rate(requests_errors_total[5m]) / rate(requests_total[5m]) > 0.05"
for: "5m"
labels:
severity: "critical"
annotations:
summary: "High error rate detected"
- alert: "SlowResponse"
expr: "histogram_quantile(0.95, rate(request_duration_seconds_bucket[5m])) > 2"
for: "5m"
labels:
severity: "warning"
annotations:
summary: "Slow response time detected"🚀 GitHub地址:
https://github.com/1Panel-dev/MaxKB
📊 性能数据:
支持1000+并发请求 · RAG准确率95%+ · 企业级可靠性
MaxKB正在重新定义企业智能体开发——通过提供强大易用的开源平台,它让企业能够快速构建和部署AI代理系统。正如用户反馈:
"从概念到生产部署只需几天而非数月,MaxKB让AI代理开发变得简单而高效"
该平台已被电商、金融、教育、研究机构广泛采用,日均处理 超过100万次 知识查询,成为企业智能化的核心基础设施。
更多推荐


 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)