
大模型加速神器:KV Cache技术原理解析与实战
KV Cache 通过缓存中间计算结果,有效解决了 Transformer 模型在生成式任务中的效率问题,是大模型能够实现实时交互的关键技术之一。理解 KV Cache 的工作原理和实现方式,对于优化大模型推理性能、解决实际部署中的挑战具有重要意义。
KV Cache是大型语言模型(LLM)推理过程中的关键技术,通过缓存历史计算中的键(Key)和值(Value)矩阵,避免重复计算。它将Transformer自回归推理的计算复杂度从O(n²)降低到O(n),显著提升长序列生成效率。文章详细解析了KV Cache的工作原理、技术细节、缓存结构、内存与速度的权衡,并通过PyTorch代码示例展示了其实现方式和优化策略,帮助开发者理解并应用这一加速大模型推理的关键技术。
在大型语言模型(LLM)的推理过程中,KV Cache 是一项关键技术,它通过缓存中间计算结果显著提升了模型的运行效率。本文将深入解析 KV Cache 的工作原理、实现方式,并通过代码示例展示其在实际应用中的效果。
01为什么需要 KV Cache?
在 Transformer 进行自回归推理(如文本生成,每次生成一个 token 的时候需要结合前面所有的 token 做 attention 操作)时,计算注意力机制时需要存储 Key(K) 和 Value(V),以便下一个时间步可以复用这些缓存,而不必重新计算整个序列。
在标准 Transformer 解码时,每次生成新 token 时:
- 需要 重新计算所有之前 token 的 K 和 V,并与当前 token 进行注意力计算。
- 计算复杂度是 O(n²)(对于长度为
n的序列)。
而 KV****Cache 通过存储 K 和 V 的历史值,避免重复计算:
- 只需计算 新 token 的 K 和 V,然后将其与缓存的值结合使用。
- 计算复杂度下降到 O(n)(每个 token 只与之前缓存的 token 计算注意力)。
02 KV Cache 的工作原理
KV Cache 的核心思想是缓存历史计算中的键(Key)和值(Value)矩阵,避免重复计算。具体来说:
- 在生成第一个 token 时,模型计算并缓存所有输入 token 的 K 和 V 矩阵;
- 生成后续 token 时,只需要计算新 token 的查询(Query)矩阵;
- 将新的 Q 矩阵与缓存的 K、V 矩阵进行注意力计算,同时将新 token 的 K、V 追加到缓存中。
这个过程可以用伪代码直观展示:
初始输入: [t0, t1, t2]
首次计算: K=[K0,K1,K2], V=[V0,V1,V2] → 生成t3
缓存状态: K=[K0,K1,K2], V=[V0,V1,V2]
第二次计算: 新Q=Q3
注意力计算: Attention(Q3, [K0,K1,K2]) → 生成t4
更新缓存: K=[K0,K1,K2,K3], V=[V0,V1,V2,V3]
第三次计算: 新Q=Q4
注意力计算: Attention(Q4, [K0,K1,K2,K3]) → 生成t5
更新缓存: K=[K0,K1,K2,K3,K4], V=[V0,V1,V2,V3,V4]
...
通过这种方式,每次新生成 token 时,只需计算新的 Q 矩阵并与历史 KV 矩阵进行注意力计算,将时间复杂度从 O (n²) 降低到 O (n),极大提升了长序列生成的效率。
下面,我们结合示意图进一步剖析一下 KV Cache 部分的逻辑。
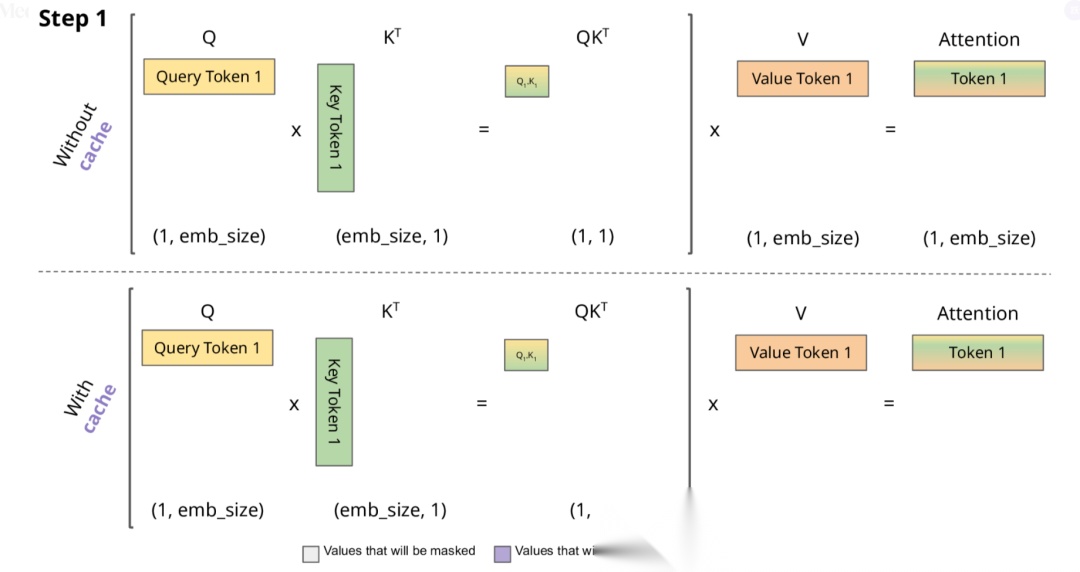
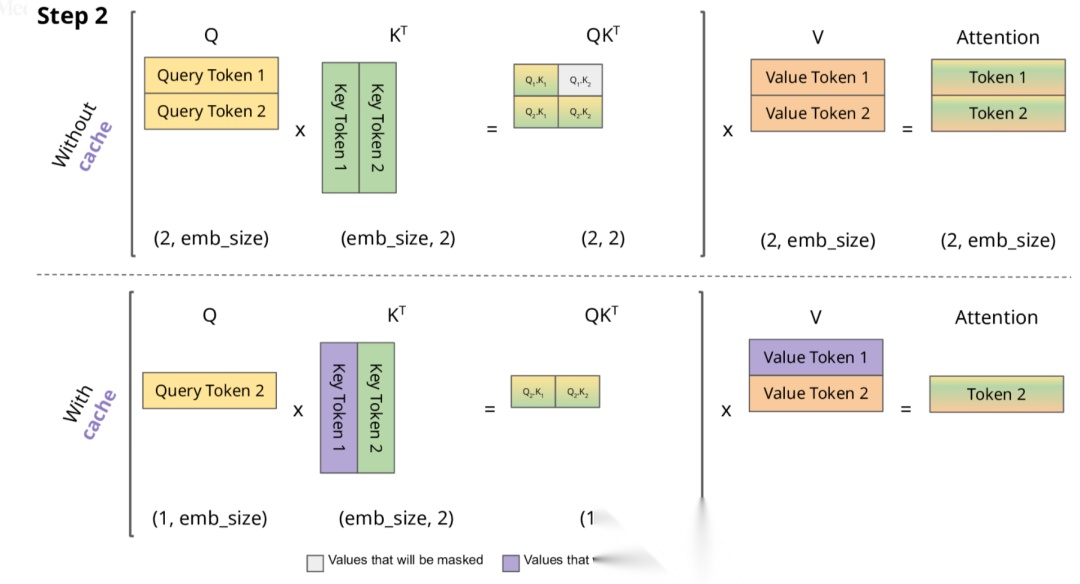
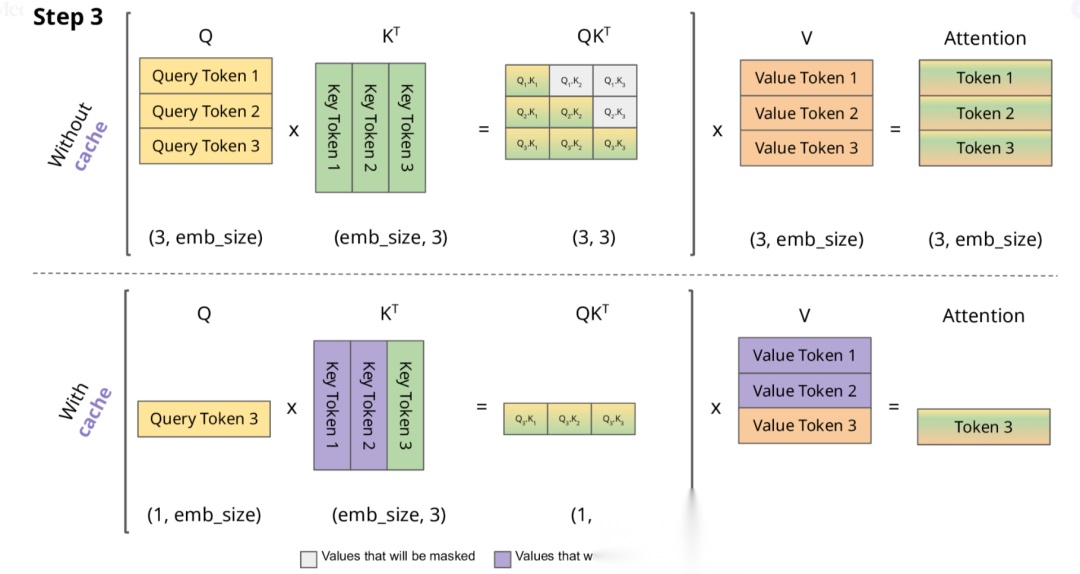
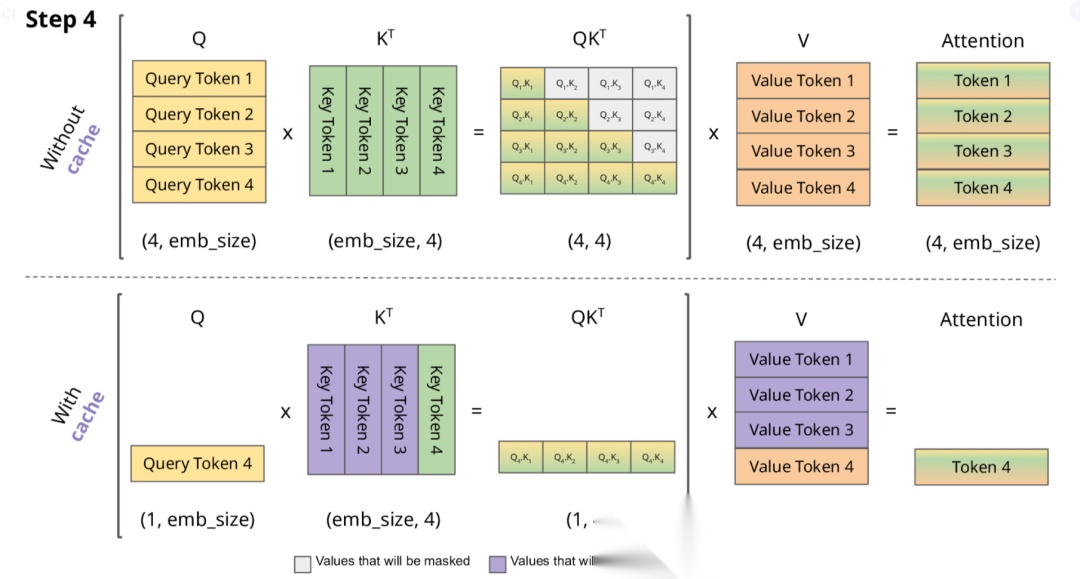
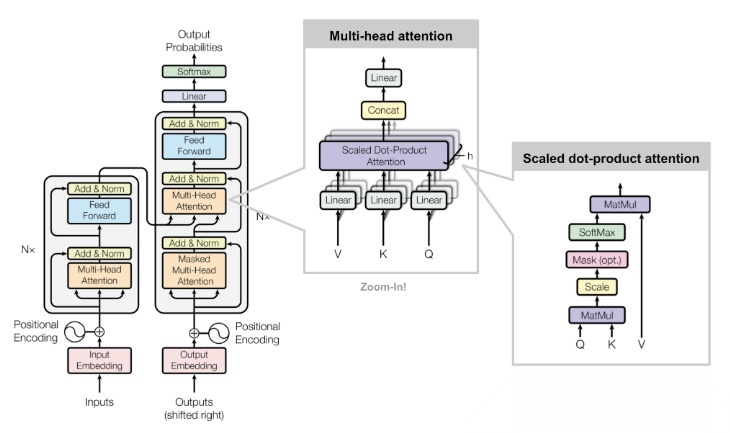
KV Cache 核心节约的时间有三大块:
- 前面 n-1 次的 Q 的计算,当然这块对于一次一个 token 的输出本来也没有用;
- 同理还有 Attention 计算时对角矩阵变为最后一行,和 b 是同理的,这样 mask 矩阵也就没有什么用了;
- 前面 n-1 次的 K 和 V 的计算,也就是上图紫色部分,这部分是实打实被 Cache 过不需要再重新计算的部分。
这里还有个 softmax 的问题,softmax 原本就是针对同一个 query 的所有 key 的计算,所以并不受影响。
2.1****KV Cache 的技术细节
2.1.1 缓存结构
KV Cache 通常为每个注意力头维护独立的缓存,结构如下:
- Key 缓存:形状为 [batch_size, num_heads, seq_len, head_dim];
- Value 缓存:形状为 [batch_size, num_heads, seq_len, head_dim]。
其中,seq_len 会随着生成过程动态增长,直到达到模型最大序列长度限制。
2.1.2 内存与速度的权衡
KV Cache 虽然提升了速度,但需要额外的内存存储缓存数据。以 GPT-3 175B 模型为例,每个 token 的 KV 缓存约占用 20KB 内存,当生成 1000 个 token 时,单个样本就需要约 20MB 内存。在批量处理时,内存消耗会线性增加。
实际应用中需要根据硬件条件在以下方面进行权衡:
- 最大缓存长度(影响能处理的序列长度);
- 批量大小(影响并发处理能力);
- 精度选择(FP16 比 FP32 节省一半内存)。
2.1.3 滑动窗口机制
当处理超长序列时,一些模型(如 Llama 2)采用滑动窗口机制,只保留最近的 N 个 token 的 KV 缓存,以控制内存占用。这种机制在牺牲少量上下文信息的情况下,保证了模型能处理更长的对话。
03 代码实现解析
下面以 PyTorch 为例,展示 KV Cache 在自注意力计算中的实现方式。
1. 基础自注意力实现(无缓存)
首先看一下标准的自注意力计算,没有缓存机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 定义Q、K、V投影矩阵
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_len, embed_dim = x.shape
# 计算Q、K、V
q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_probs = F.softmax(attn_scores, dim=-1)
# 应用注意力权重
output = attn_probs @ v
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(output)
2. 带 KV Cache 的自注意力实现
下面修改代码,加入 KV Cache 机制:
class CachedSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 定义投影矩阵
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
# 初始化缓存
self.cache_k = None
self.cache_v = None
def forward(self, x, use_cache=False):
batch_size, seq_len, embed_dim = x.shape
# 计算Q、K、V
q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 如果使用缓存且缓存存在,则拼接历史KV
if use_cache and self.cache_k is not None:
k = torch.cat([self.cache_k, k], dim=-2)
v = torch.cat([self.cache_v, v], dim=-2)
# 如果使用缓存,更新缓存
if use_cache:
self.cache_k = k
self.cache_v = v
# 计算注意力分数(注意这里的k是包含历史缓存的)
attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_probs = F.softmax(attn_scores, dim=-1)
# 应用注意力权重
output = attn_probs @ v
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(output)
def reset_cache(self):
"""重置缓存,用于新序列的生成"""
self.cache_k = None
self.cache_v = None
3. 生成过程中的缓存使用
在文本生成时,我们可以这样使用带缓存的注意力机制:
def generate_text(model, input_ids, max_length=50):
# 初始化模型缓存
model.reset_cache()
# 处理初始输入
output = model(input_ids, use_cache=True)
next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True)
generated = [next_token]
# 生成后续token
for _ in range(max_length - 1):
# 只输入新生成的token
output = model(next_token, use_cache=True)
next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True)
generated.append(next_token)
# 如果生成结束符则停止
if next_token.item() == 102: # 假设102是[SEP]的id
break
return torch.cat(generated, dim=1)
05 KV Cache 的优化策略
在实际部署中,为了进一步提升 KV Cache 的效率,还会采用以下优化策略:
- 分页KVCache(Paged KV Cache):借鉴内存分页机制,将连续的 KV 缓存分割成固定大小的块,提高内存利用率,代表实现有 vLLM。
- 动态缓存管理:根据输入序列长度动态调整缓存大小,在批量处理时优化内存分配。
- 量化缓存:使用 INT8 或 INT4 等低精度格式存储 KV 缓存,在牺牲少量精度的情况下大幅减少内存占用。
- 选择性缓存:对于一些不重要的层或注意力头,选择性地不进行缓存,平衡速度和内存。
06 总结
KV Cache 通过缓存中间计算结果,有效解决了 Transformer 模型在生成式任务中的效率问题,是大模型能够实现实时交互的关键技术之一。理解 KV Cache 的工作原理和实现方式,对于优化大模型推理性能、解决实际部署中的挑战具有重要意义。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)