
最新 IndexTTS2 本地部署和使用
IndexTTS2是哔哩哔哩推出的开源语音生成大模型,相比于早期版本的IndexTTS,IndexTTS2在情感表达的细腻度与时长控制的精准性方面有了很大的提升。
IndexTTS2是哔哩哔哩推出的开源语音生成大模型,相比于早期版本的IndexTTS,IndexTTS2在情感表达的细腻度与时长控制的精准性方面有了很大的提升。下面教大家怎么在本地部署和使用IndexTTS2
一、下载源码
最低配置要求:6GB 显存 + 16GB 内存。低配置生成速度会较慢,推荐显存≥8GB
安装Git
访问下载地址:https://git-scm.com/downloads
运行下载的安装程序,全程点击 “Next” 使用默认配置即可
安装Git LFS :Git LFS 是 Git 的一个扩展,用于高效地处理大文件(比如图片、视频、模型文件等)
git lfs install
下载源码
# 切换到你想存放源码的目录
cd E:\Python
# 拉取代码,并且重命名文件夹为 indextts2
git clone https://github.com/index-tts/index-tts.git indextts2
# 切换到 indextts2 目录
cd indextts2
# 下载仓库里LFS管理的文件
git lfs pull
二、安装依赖
安装 uv 包管理器
# 安装 uv 包管理器
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 验证是否安装成功:重新打开一个powershell窗口执行
uv --version
Windows环境下建议注释掉 deepspeed,保证能顺利安装
deepspeed 依赖大量底层 CUDA / 编译工具链(如 ninja、gcc、PyTorch 扩展编译)
Windows 的编译环境不如 Linux 完善,容易出现路径、依赖、版本冲突等问题
修改indextts2/pyproject.toml,搜索deepspeed,将以下两处注释掉

安装依赖
uv python install 3.10 # 安装python解释器,指定版本,项目要求>=3.10
uv python pin 3.10 # 项目锁定版本
uv venv # 创建虚拟环境
uv sync --all-extras --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple" # 安装项目依赖,并指定使用清华的镜像
耐心等待,光torch就3.22G了
三、下载IndexTTS2模型
可以从用国内的 modelscope下载模型。也可以从国外的 huggingface下载模型(需要梯子)
国内modelscope
# 安装可执行的命令行工具 modelscope
uv tool install "modelscope"
# 执行命令前确保目录是在indextts的工程目录下,这样才会把模型下到工程目录里的checkpoints下面,比如我的:(base) PS E:\Python\indextts2>
# 下载IndexTTS2模型,并且指定下载到checkpoints目录
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
耐心等待,模型文件有好些个G
国外huggingface
# 安装可执行的命令行工具 huggingface_hub,并且同时安装其可选的、用于命令行功能的额外依赖(cli)
uv tool install "huggingface_hub[cli]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
四、运行项目
# 检查本机环境的CUDA和GPU是否可用
uv run tools/gpu_check.py
# 运行WebUI
uv run webui.py
运行项目
五、使用IndexTTS2
打开浏览器访问http://127.0.0.1:7860
三步克隆声音
1、上传一段参考声音
2、输入要合成的文本,点击生成语音
3、下载声音
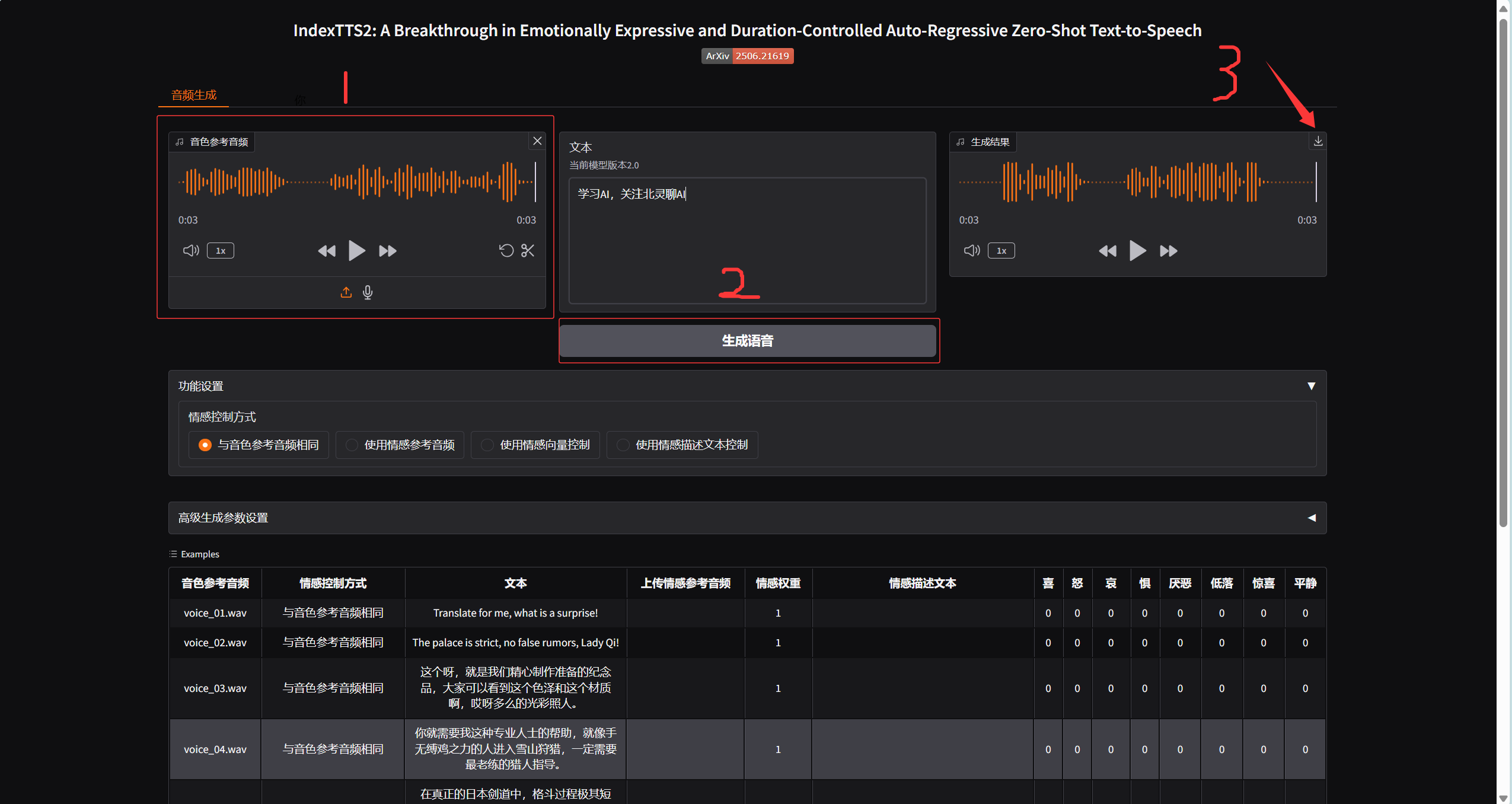
IndexTTS2这次新增了四种情感控制方式,可以实现音色与情感的独立控制。
- 与音色参考音频相同(默认):默认的方式,直接使用你上传的音色参考音频中所包含的情感特征。
- 使用情感参考音频:上传一段包含目标情感的音频作为参考,模型会提取该音频的情感特征来生成语音 。
- 使用情感向量控制:通过输入特定的情感参数来直接控制生成语音的情感倾向。
- 使用情感描述文本控制:直接输入文本描述(如“开心”、“悲伤”、“愤怒”等)来引导模型生成具有相应情感倾向的语音 。
以上就是 IndexTTS2 主要功能的介绍,大家可以上手试试,祝大家玩得愉快!
👉 关注【北灵聊AI】,解锁AI前沿动态与技术干货,每天进步一点点!
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)