
强化学习:概述(Chapter 1[1~1.1.2])
这是因为我们预先知晓智能体的生命周期,不存在对未来不确定性的考量,此时智能体可以充分重视每一个时间步的奖励,而无需对未来奖励进行折扣,以最大化整个有限时域内的总回报。首先,它确保了即便在 T=∞(即无限时域)的情况下,只要我们采用 γ<1 且奖励 rt 有界,回报依旧是有限的。从序列决策问题的本质出发,我们先后阐释了智能体与环境的交互机制、以最大期望效用为核心的决策准则,明确了最优策略的定义与追求

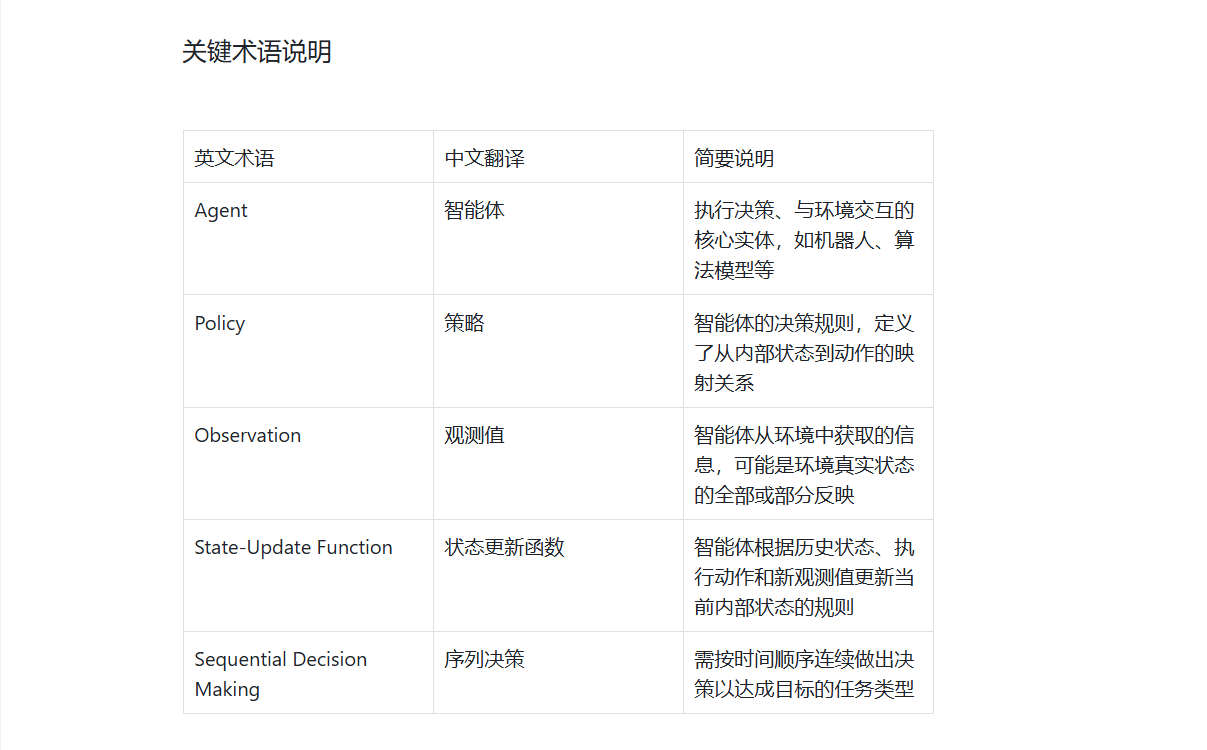




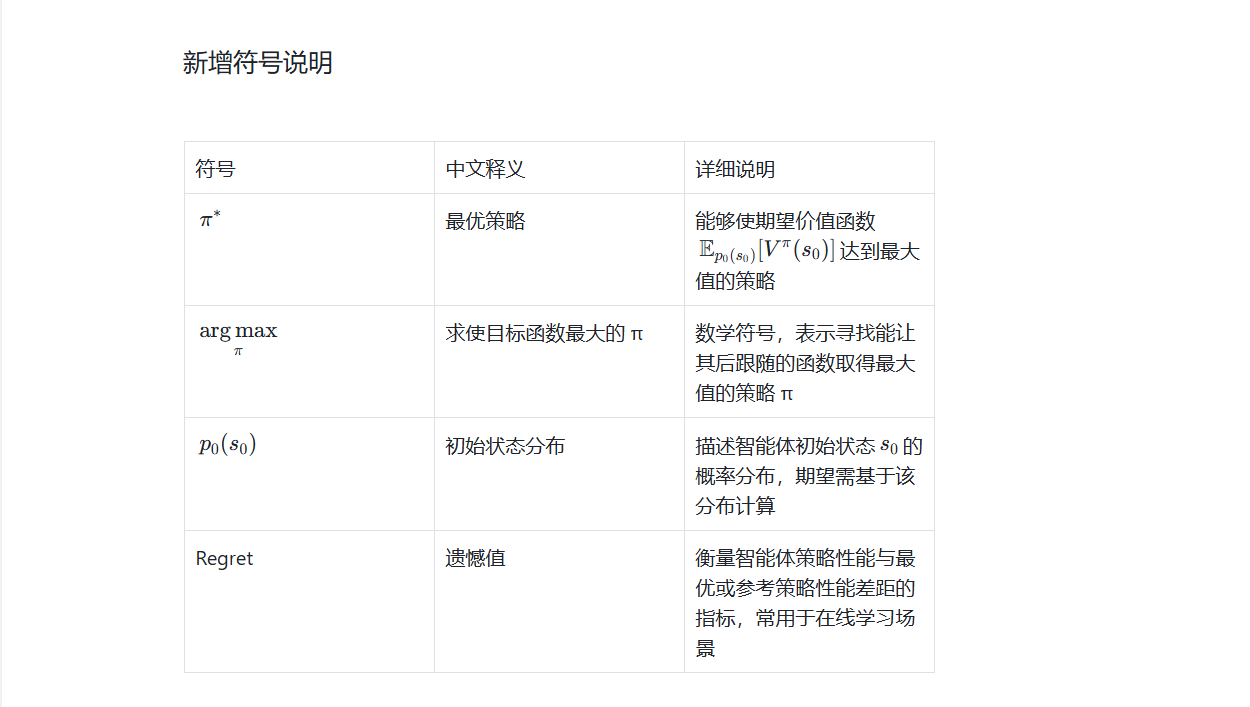


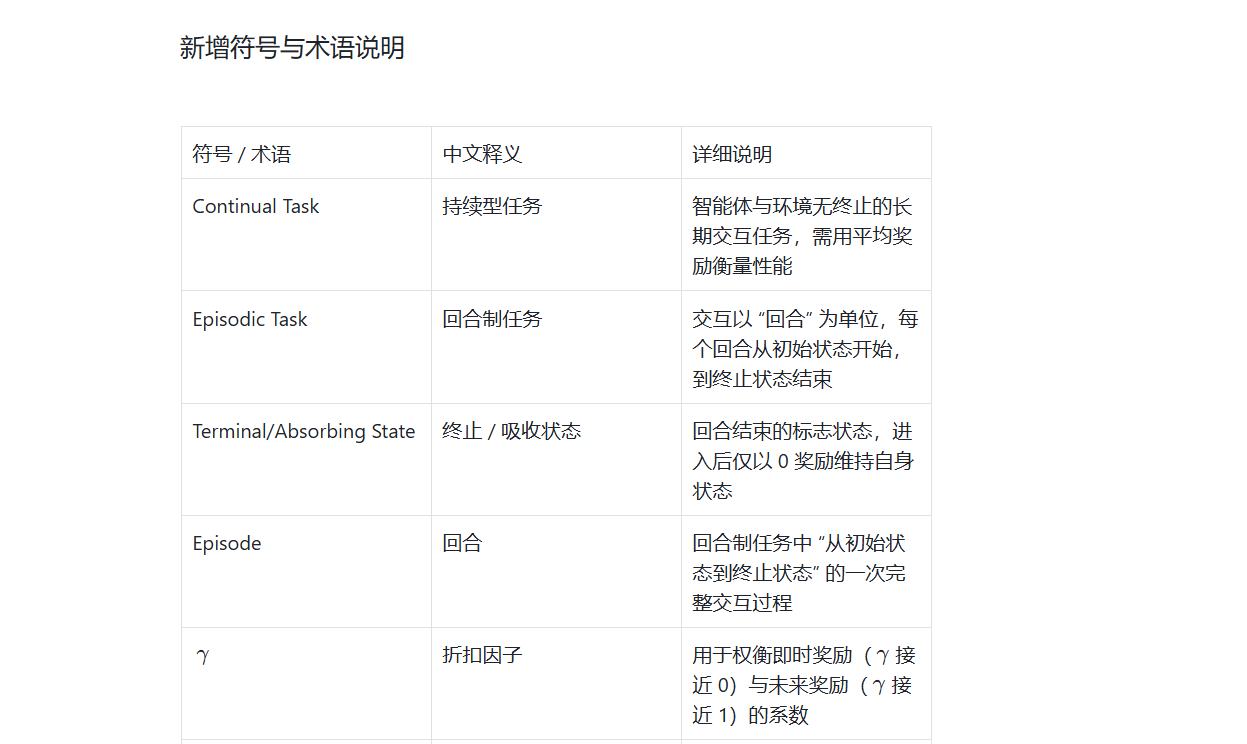




关键术语注释
| 术语 | 说明 |
|---|---|
| 折扣因子(γ) | 取值范围为[0,1],用于平衡强化学习中即时奖励与未来奖励的权重 |
| 无限时域(infinite horizon) | 智能体与环境的交互无固定终止点,理论上可无限持续 |
| 有限时域(finite horizon) | 智能体与环境的交互长度T已知且固定,达到T后交互终止 |
| 终态奖励(terminal reward) | 智能体达到终止状态时获得的奖励 |
| 即时奖励(immediate reward) | 智能体在当前时刻执行动作后立即获得的奖励 |
文档结束语
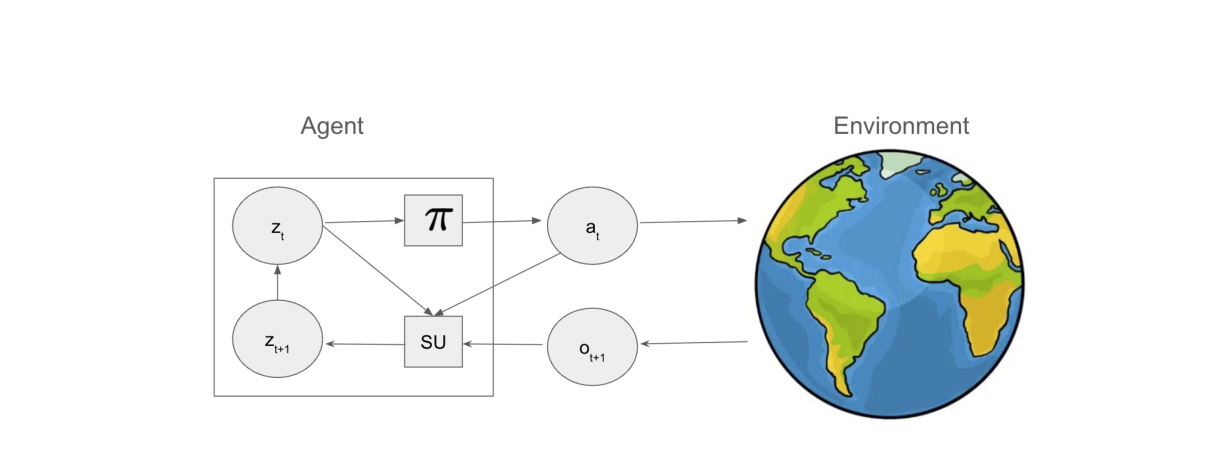
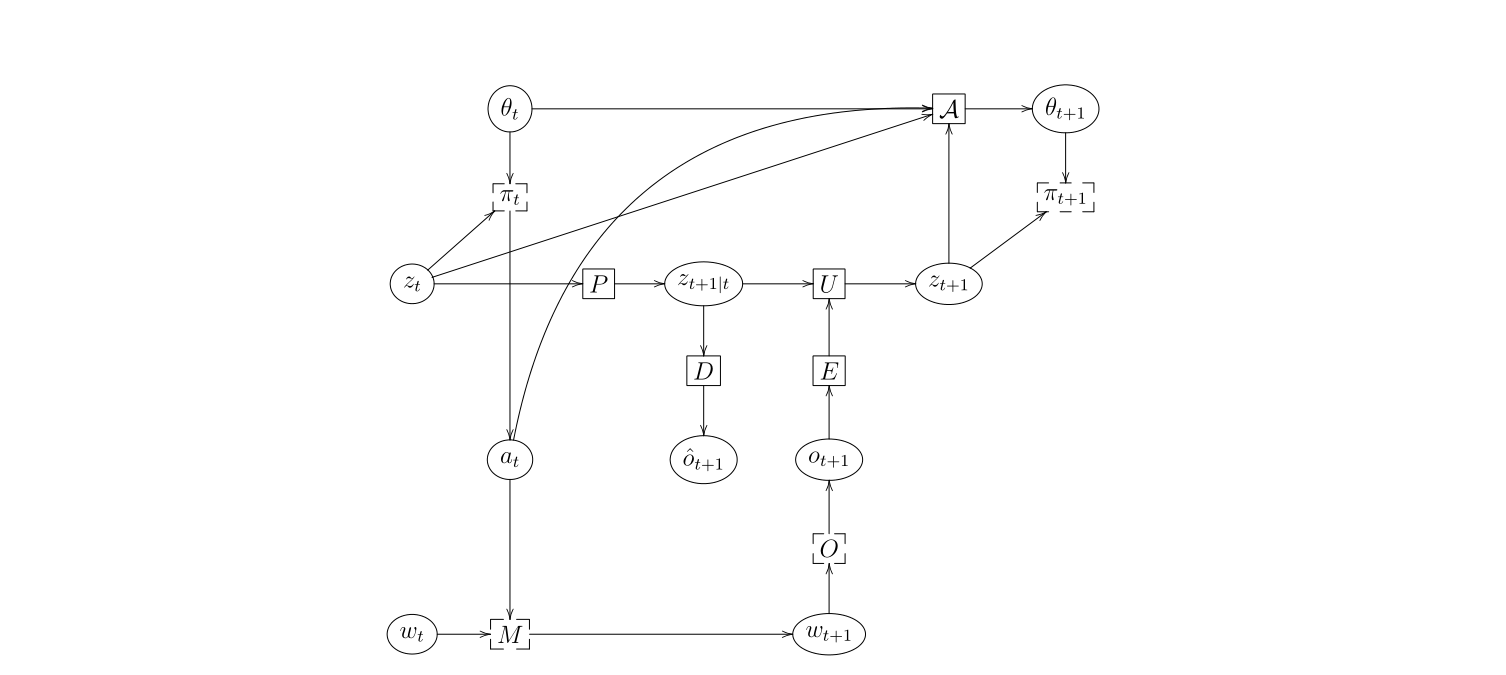
至此,我们已围绕强化学习的核心框架、关键原理与基础任务类型完成了系统性梳理。从序列决策问题的本质出发,我们先后阐释了智能体与环境的交互机制、以最大期望效用为核心的决策准则,明确了最优策略的定义与追求目标,并区分了回合制与持续型两类典型任务场景,同时构建了回报与价值函数的量化分析体系。而智能体与环境交互的详细示意图,更直观地展现了从动作选择、状态预测到观测编码、策略更新的完整闭环,为理解强化学习的运行逻辑提供了具象化支撑。
这些基础理论与模型架构,不仅揭示了强化学习 “试错学习”“延迟奖励” 的核心特质,更搭建起连接理论方法与实际应用的桥梁。正如前文所提及,强化学习的魅力在于其高度的通用性 —— 无论是机器人控制、自然语言处理,还是金融决策、自动驾驶等领域,只需根据具体场景调整环境假设、智能体结构与策略更新方式,便能将这些基础框架转化为解决实际问题的有力工具。尽管环境观测分布的未知性、策略优化的复杂性等挑战仍客观存在,但正是这些挑战推动着强化学习在算法效率提升、样本复杂度降低、多智能体协同等方向不断突破。
本文档所呈现的内容,旨在为读者奠定强化学习的理论基础。后续研究可基于此,深入探索深度强化学习、模型基强化学习等进阶方向,或结合具体应用场景开展实证研究。期待这些基础理论能为相关领域的研究者与实践者提供有益参考,共同推动强化学习技术在真实世界中落地生根,释放更大的技术价值。
最后,感谢所有为本文档创作与完善提供支持的同仁,也感谢读者的悉心研读。因水平所限,文档中难免存在疏漏之处,恳请各界专家与读者不吝指正。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)