
大模型微调已死?华为Memento智能体靠“记忆增强”登顶SOTA
一句话总结:与其给大模型做昂贵的“脑部手术”(微调),不如教它高效“翻阅历史档案”(案例推理)。论文 Memento 证明,通过学习“鉴往知来”的技巧,智能体在复杂任务上能打败那些经过微调的对手。点击阅读原文,获取更多前沿咨询。
前言
一句话总结:与其给大模型做昂贵的“脑部手术”(微调),不如教它高效“翻阅历史档案”(案例推理)。 论文 Memento 证明,通过学习“鉴往知来”的技巧,智能体在复杂任务上能打败那些经过微调的对手。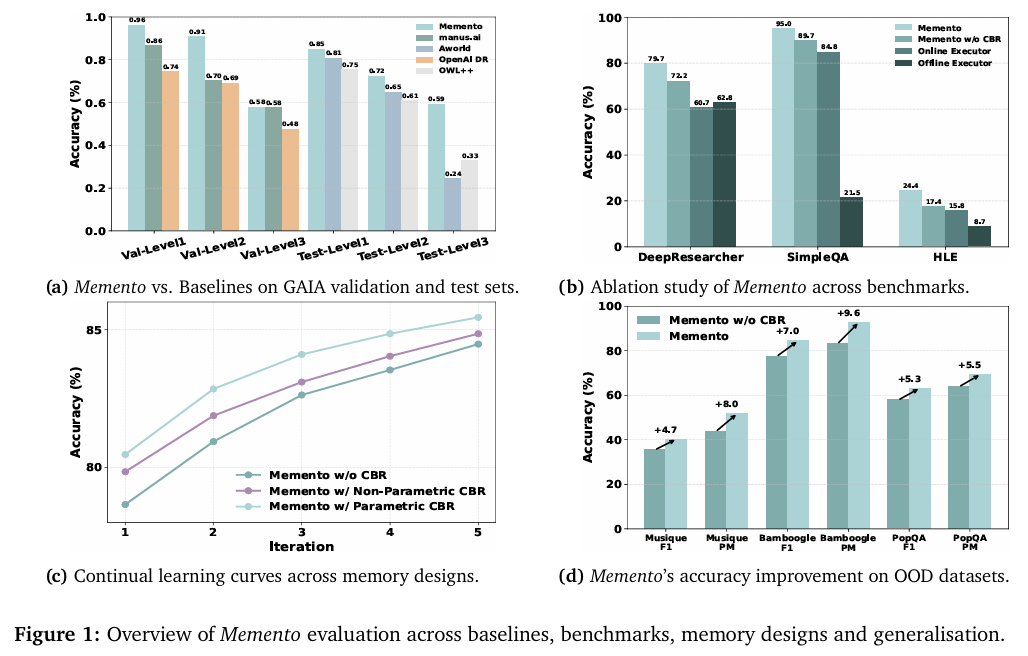
点击阅读原文,获取更多前沿咨询
论文基本信息

论文标题:Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
论文链接:https://arxiv.org/abs/2508.16153
项目链接:https://github.com/Agent-on-the-Fly/Memento
大模型智能体的成长困境:出厂即巅峰?
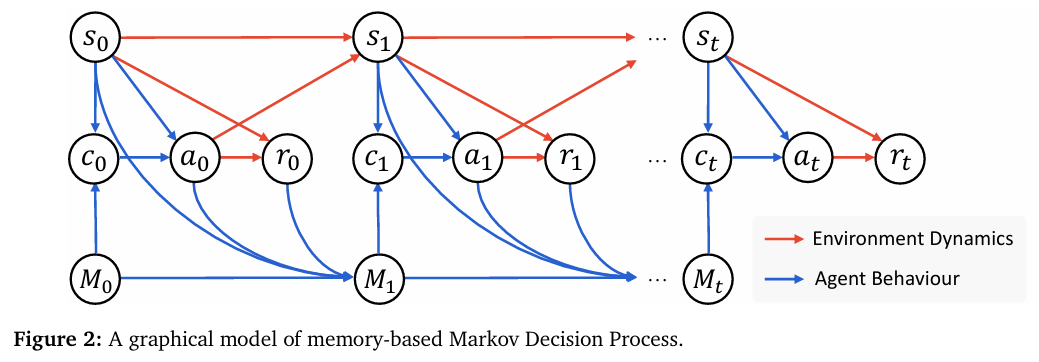
当前的大模型智能体(Agent)在学习新技能时,普遍陷入一个两难的困境:
- 要么死板如“出厂设置”:许多智能体依赖开发者预设的固定流程。它们是特定任务的专家,但一旦遇到新情况或需要调整策略,就显得力不从心,无法从经验中吸取教训。
- 要么昂贵如“回厂大修”:另一种方式是通过“微调”(Fine-tuning)来更新模型参数,这就像送机器人回厂做一次昂贵的“脑部手术”。虽然灵活,但计算成本极高,还可能引发“灾难性遗忘”,让模型忘了老本行。
这两种方式都限制了智能体在现实世界中持续学习、自主成长的能力。
Memento的破局之道:智慧在于如何“复盘”而非改造大脑
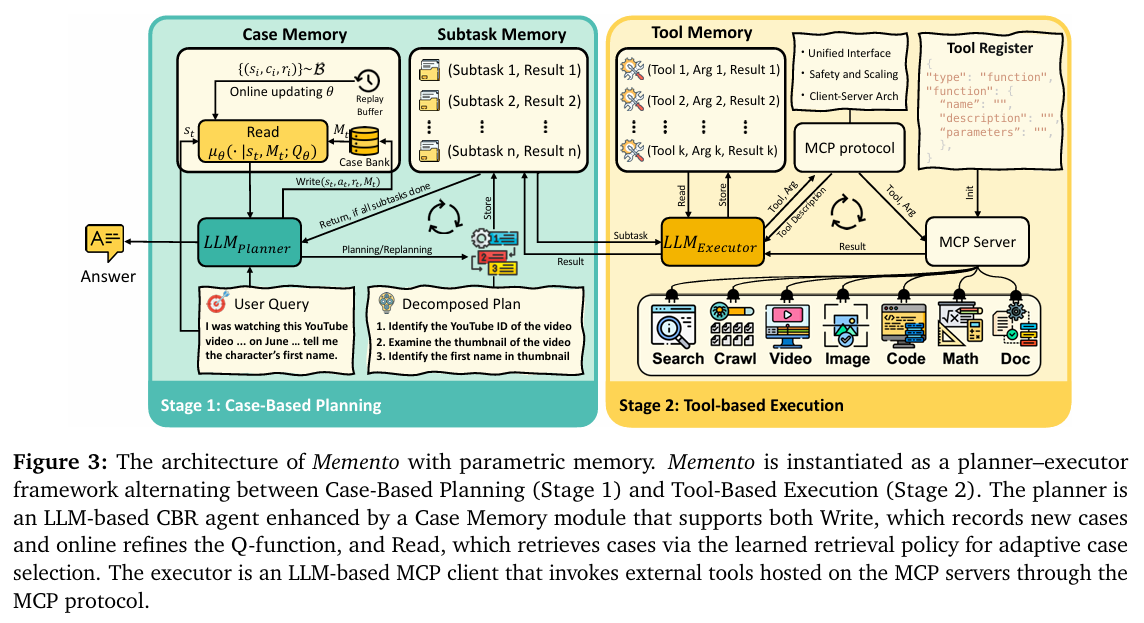
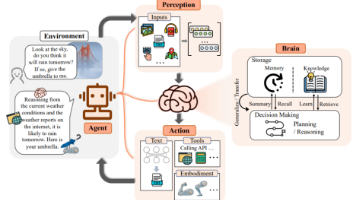
论文 Memento 提出了一条优雅且高效的全新路径:不必对大模型本身动刀,而是为它配备一个智能的、可不断扩充的“外部记忆系统”,并教会它如何高效利用这份记忆。
其核心机制是**“案例推理”(Case-Based Reasoning, CBR)**,整个过程就像培养一位新手侦探,让他通过复盘历史案件来成长:
- 接到新案 (新任务): 侦探接到一个棘手的新案件。他不会贸然行动,而是先去查阅警局的“案件档案柜”(案例库 Case Bank)。
- 智能检索 (核心学习机制): 这不是简单的相似度匹配。新手侦探最初可能只会找案情相似的旧案卷。但 Memento 的精髓在于,它通过强化学习(Soft Q-Learning),让侦探学会判断哪个旧案卷对当前案件最“有启发价值”。他逐渐懂得,有些看似不相关的案件(比如银行抢劫案),其作案手法或线索类型却极具参考意义。
- 借鉴规划 (制定行动计划): 在参考了最有价值的历史经验(包括成功和失败的教训)后,侦探的大脑(基础LLM)结合新案情,制定出一套更周密、成功率更高的侦破计划。
- 破案归档 (实现持续学习): 无论这次侦破成功与否,整个过程——从最初的问题到最终的结果——都会被整理成一份新档案,存入档案柜。这次的经验,又成为了未来可供学习的新案例。
通过这个“决策-反馈-学习”的闭环,侦探的推理能力(LLM本身)从未改变,但他凭借那个不断丰富的“档案库”和日益精准的“检索直觉”,破案能力得到了持续、显著的成长。
实验结果:聪明“翻档案”胜过昂贵“开颅手术”
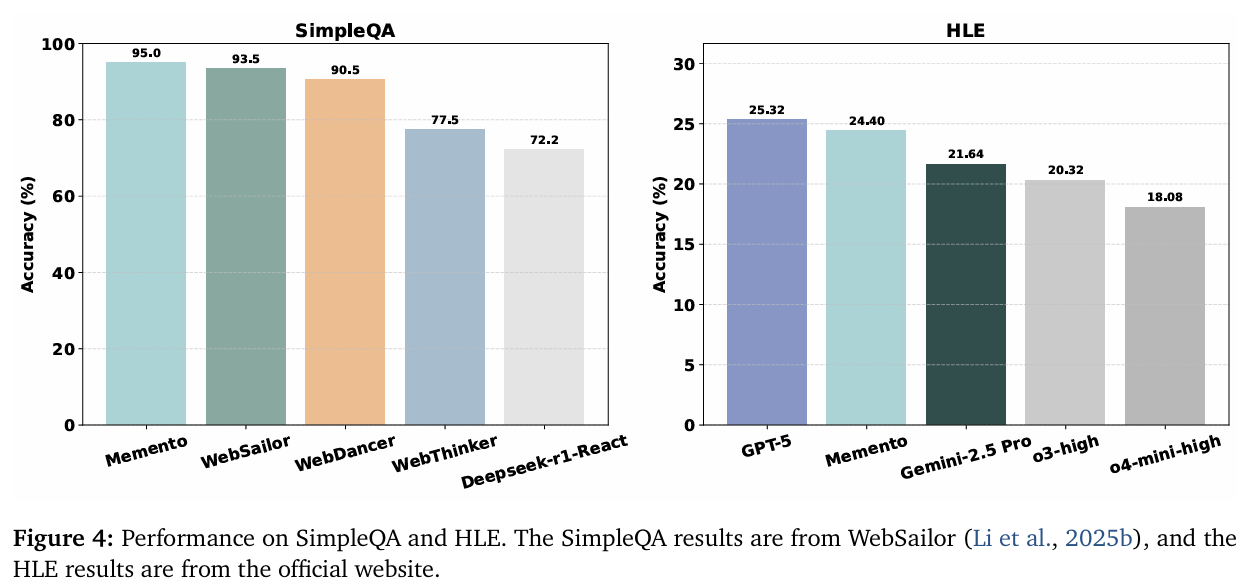
Memento 的设计并非纸上谈兵,实验结果有力地证明了其价值:
- 实战效果惊人: 在 GAIA、DeepResearcher 等多个高难度、多步骤的智能体基准测试中,Memento 的表现全面超越了众多基线方法,甚至击败了依赖模型微调的SOTA(State-of-the-art)模型。这直接证明了“不微调,只学习如何使用记忆”这条路线的高效性。
- 证明了真正的“成长性”: 实验清晰地显示,随着案例库中经验的积累,Memento 的性能稳步提升。它解决的问题越多,就变得越聪明,展现了真正的在线持续学习能力,而非一次性的能力注入。
- 学到的经验可以“触类旁通”: 更令人惊喜的是,Memento 具备强大的泛化能力。将在一个任务领域(如网页搜索)中学到的经验,能有效帮助它解决另一个完全不同的任务(如科学问答),实现了知识和策略的迁移。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)