经典深度学习模型——VGG(详细解释 & pytorch代码)
VGG,全称是 Visual Geometry Group,是由牛津大学视觉几何组(这也是 VGG名称的由来啦)在2014年提出的,多用于图像分类和定位。相比于之前的 AlexNet, VGG 中使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替55卷积核,总之,用的卷积核清一色是 33 的。并且 max pooling 都是2*2 的。
1. VGG 概述
VGG,全称是 Visual Geometry Group,是由牛津大学视觉几何组(这也是 VGG名称的由来啦)在2014年提出的,多用于图像分类和定位。相比于之前的 AlexNet, VGG 中使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替55卷积核,总之,用的卷积核清一色是 33 的。并且 max pooling 都是2*2 的。
2. VGG 核心结构
VGG 的结构主要就是卷积层、线性激活、池化层、全连接和softmax。其中,卷积层、线性激活(Relu)和池化层(max pooling)可以看作一个 VGG block。
1)卷积层—— 3*3 conv
用卷积核在图像上滑动,提取出图像的局部特征。核心是矩阵乘法。
2)非线性激活——Relu
小于零的过滤掉,只留下大于零的。有利于细节提取,且简化计算。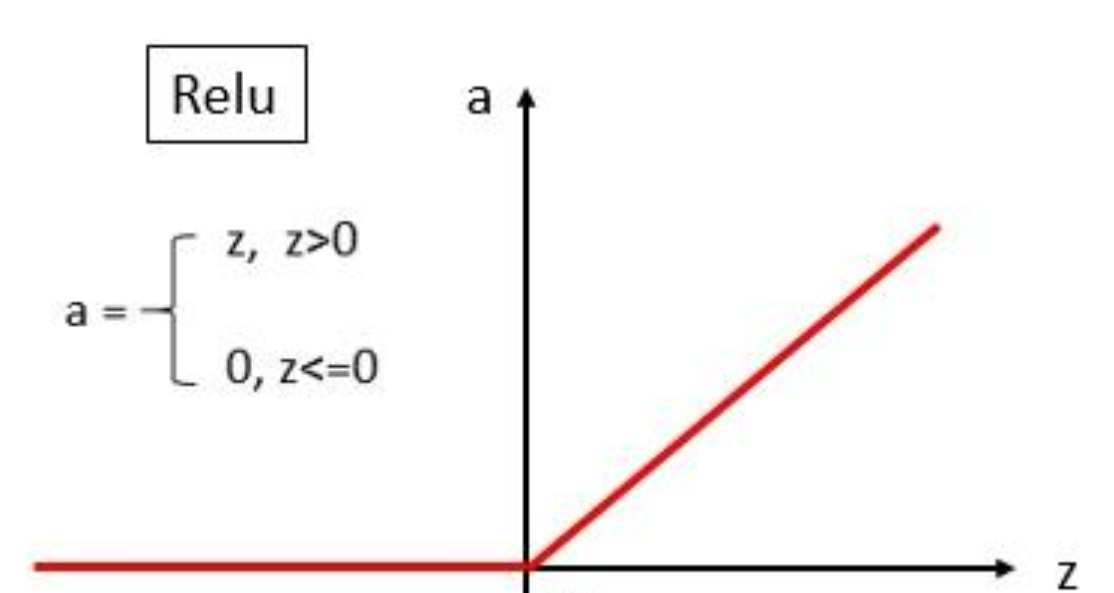
3) 池化层 —— 2*2 max pooling
减小图像的空间尺寸,且由于是 2*2 的,相当于每次图像长宽减半。其原理是从每次滑过的区域中提取最大的元素,这样既保留了图像的整体特征,又减小了计算量(因为长宽减半)。同时,若是图像有些微小变动,也不会太影响输出(因为取了 max),这样能提高模型的泛化能力。
4) 全连接 fully connected
把前面提取的高位特征展成一个的向量,每个维度表示各个类别的概率。
5) softmax
得到每个类别的概率分布,即把各个类别的概率转换到0和1之间。
VGG的直观理解如下图所示: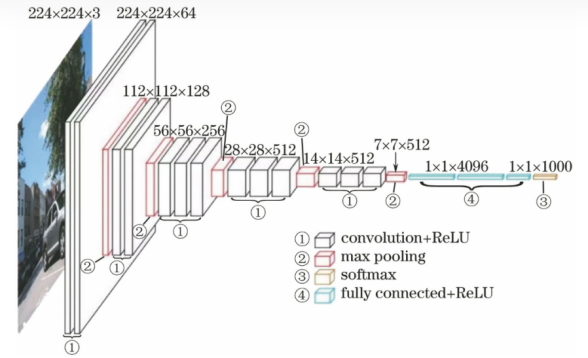
小结一下,VGG网络整体思路是把一个个VGG block(convolution + Relu + max pooling) 叠起来,convolution 提取图像特征,relu 非线性激活,max pooling 减小图像尺寸。通过减小图像尺寸降低计算量;通过增加通道数,提取更高维的特征。最后再用 linear ,也就是 full connection 全连接,把前面提取的高位特征展成固定长度的向量,得到每个分类的概率,再用softmax 得到每个类别的概率分布(0~1)。
3. VGG 特点
1)结构规整:
几乎是一个个VGG block叠起来的。这简化了模型结构,同时也便于调整网络深度。
2)小卷积核的堆叠:
VGG 模型大通过大量的 3*3卷积核的堆叠扩大感受野,这比用单个大卷积核减少了参数的数量。(比起AlexNet,堆叠两个 3x3 的卷积核代 5x5 的卷积核,堆叠三个 3x3 的卷积核代 7x7 的卷积核,感受野是一样的,但参数少了,计算效率高了。)
3)深度
VGG网络很深,常见的有 VGG16 和 VGG19。
4)Relu 非线性激活
有利于缓解梯度消失的问题
4. VGG 代码实现(pytorch)
*以 VGG16,数据集CIFAR-10,分为10类为例。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# ========== 1. 定义 VGG16 网络 ==========
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# Conv Block 1
nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 2
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 3
nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 4
nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 5
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 4096), nn.ReLU(inplace=True), nn.Dropout(),
nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # flatten to (batch_size, 512)
x = self.classifier(x)
return x
# ========== 2. 数据预处理与加载 ==========
transform = transforms.Compose([
transforms.Resize((32, 32)), # CIFAR-10 本来就是 32x32
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False)
classes = trainset.classes
# ========== 3. 模型训练 ==========
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VGG16(num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
EPOCHS = 5
for epoch in range(EPOCHS):
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print(f"[{epoch+1}, {i+1}] loss: {running_loss/100:.3f}")
running_loss = 0.0
print("Finished Training")
# ========== 4. 模型预测 ==========
correct = 0
total = 0
model.eval() # 进入评估模式
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")
# ========== 5. 显示预测示例 ==========
def imshow(img):
img = img / 2 + 0.5 # 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.axis("off")
plt.show()
# 随机显示部分预测结果
dataiter = iter(testloader)
images, labels = next(dataiter)
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
imshow(torchvision.utils.make_grid(images.cpu()[:4]))
print("GroundTruth:", [classes[i] for i in labels[:4]])
print("Predicted :", [classes[i] for i in predicted[:4]])

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)