
14万星开源神器 Firecrawl:让 AI Agent 真正“读懂“整个互联网。
摘要:Firecrawl 是一个拥有 14 万 GitHub Star 的开源项目,专为 AI 时代设计的网页数据 API。一行代码把任意网页变成干净的 Markdown 或结构化 JSON,搞定代理、JS 渲染、反爬虫等所有脏活,让你的 AI Agent 直接消费真实互联网数据。
一个问题:你的 AI Agent 能看懂网页吗?
做 AI 应用的同学大概都遇到过这个问题:
模型很聪明,但它只认识文本。你把一个网页丢给它,得到的是一坨夹杂着 <div> 和广告脚本的 HTML,或者 JS 渲染的页面根本抓不到内容。想让 Agent 去爬竞品价格、抓新闻摘要、给 RAG 系统补充实时知识……光是"怎么把网页变成干净数据"这一步,就能卡死一半的项目。
Firecrawl 就是专门解决这个问题的。

什么是 Firecrawl?
Firecrawl 是一个开源的网页数据 API,GitHub 目前已有 14 万+ Stars,2024 年 4 月上线,由 Y Combinator 孵化,短短两年成为 AI 开发者最常提到的基础设施工具之一。
它的定位很直接:把任意网页变成 LLM 可以直接消费的数据。
不是传统爬虫脚本,也不是只会返回 HTML 的请求库。Firecrawl 在底层帮你搞定了:
-
旋转代理 & 反反爬
-
JavaScript 动态渲染
-
速率限制和并发调度
-
噪音过滤(广告、导航栏、底部链接……)
你只需要给它一个 URL,它返回干净的 Markdown、JSON、截图或 HTML,直接喂给模型。
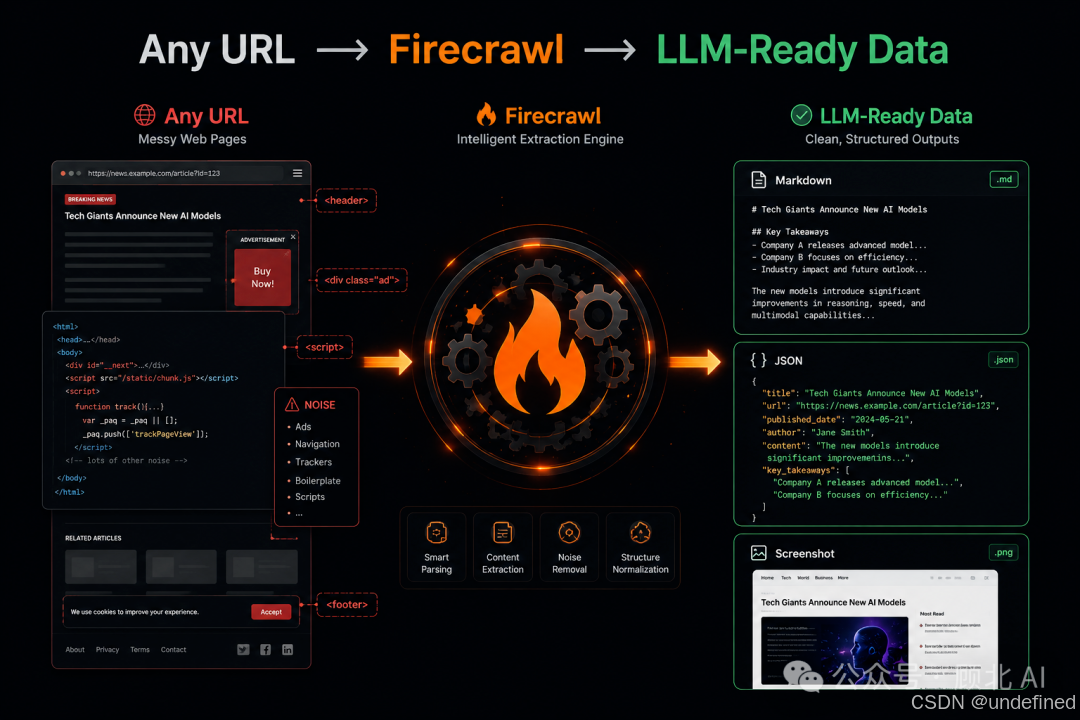
核心功能拆解
🔍 Search:搜索 + 全文内容,一步到位
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
results = app.search("最新 AI 大模型进展", limit=5)
普通搜索 API 只返回链接和摘要。Firecrawl 的 Search 会直接把搜索结果页面的完整内容一起返回,省去你再去逐个抓页面的步骤。对于做 AI 搜索助手或 Deep Research 类产品的团队来说,这个设计很实用。
📄 Scrape:把任意 URL 变成 Markdown
result = app.scrape('https://example.com')
# result.markdown → 干净的正文 Markdown
# result.html → 原始 HTML
# result.screenshot → 页面截图 URL
这是最核心的功能。覆盖率号称 96% 的网页,包括重 JS 的 SPA 应用。P95 延迟 3.4 秒,用于实时 Agent 场景够用。
🖱️ Interact:抓完还能继续操作
这个功能有点意思。先抓取页面,拿到 scrape_id,然后可以用自然语言或代码继续交互:
result = app.scrape("https://amazon.com")
scrape_id = result.metadata.scrape_id
app.interact(scrape_id, prompt="搜索'机械键盘'")
app.interact(scrape_id, prompt="点击第一个结果")
等于给 Agent 提供了一个托管浏览器,可以填表单、点按钮、等待动态内容加载,然后继续提取数据。适合登录后才能看到内容、或者需要多步操作的场景。
🕷️ Crawl:整站抓取,一行搞定
result = app.crawl('https://docs.example.com')
给一个域名,自动发现所有子页面并逐一抓取。给 RAG 系统喂整个文档站的常见操作。
⚡ Batch Scrape:异步批量处理
需要同时抓几千个 URL?Batch Scrape 异步处理,不卡主线程,结果通过 Webhook 回调或轮询拿到。
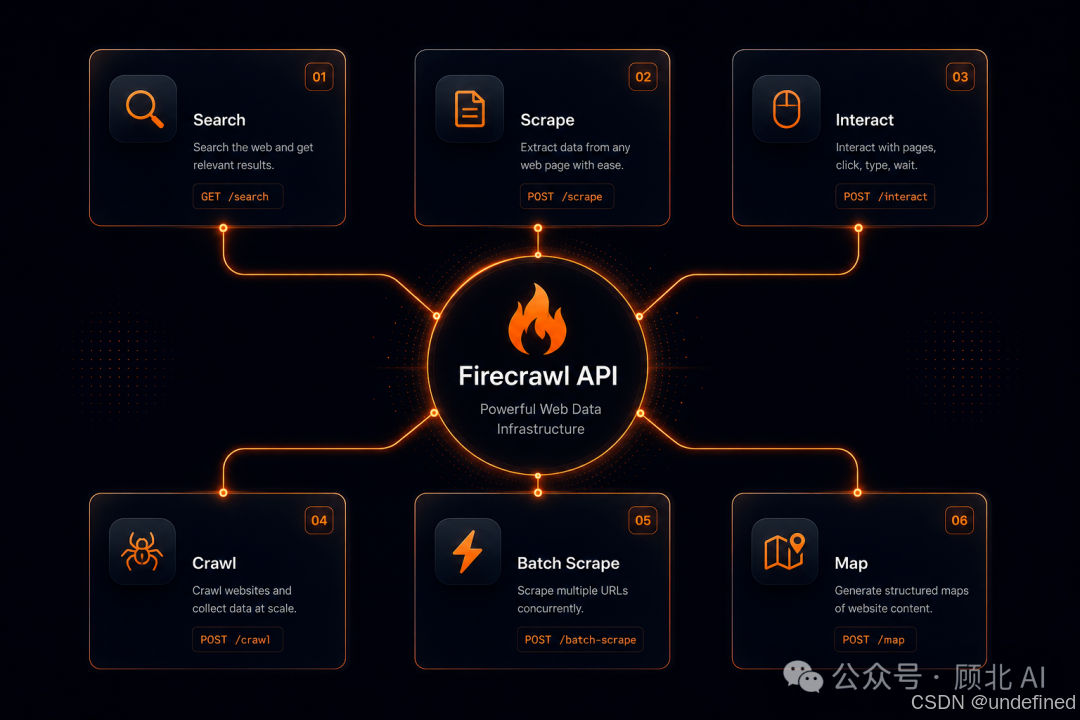
对接 AI 工具链:MCP 支持
这是我觉得 Firecrawl 做得最聪明的地方之一——支持 MCP(Model Context Protocol)。
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "fc-YOUR_API_KEY"
}
}
}
}
把这段配置加进 Claude Desktop、Cursor、Windsurf 或 VS Code,你的 AI 助手就直接拥有了"读取互联网"的能力。不需要你另外写任何胶水代码。
还有给 AI Agent 用的 Skill 命令:
npx -y firecrawl-cli@latest init --all --browser
重启 Agent 之后,它就知道 Firecrawl 可以用了。
适合用 Firecrawl 的场景
结合官方文档和社区讨论,以下几类需求最对口:
|
场景 |
为什么用 Firecrawl |
|---|---|
|
RAG 系统补充实时知识 |
干净 Markdown,直接入库,省清洗时间 |
|
AI 搜索 / 研究助手 |
Search 接口返回全文,不只是摘要 |
|
竞品 / 价格 / 新闻监控 |
批量抓取 + 结构化 JSON 输出 |
|
重 JS 网站数据提取 |
托管浏览器渲染,不用自己维护 Playwright 集群 |
|
给 Claude / Cursor 等工具加网络访问 |
MCP 一行接入 |
|
快速验证数据产品想法 |
不用先搭爬虫基础设施 |
不太适合的场景:固定网站的超大批量低成本采集(这时候专用爬虫或定向解析器更便宜)。
开源 & 自部署
Firecrawl 核心代码以 AGPL-3.0 协议开源,SDK 和部分 UI 组件是 MIT 许可。可以直接 GitHub 上 clone 下来自部署,也可以用官方的托管服务(有免费额度)。
项目目前有 160 位贡献者,主语言 TypeScript,同时有 Python、Node.js、Go、Rust、Java、PHP 等多语言 SDK,生态覆盖还是挺全的。
用几行代码感受一下
不想注册也能先试试——SDK 支持无 API Key 启动(有限流):
from firecrawl import Firecrawl
app = Firecrawl() # 无需 API Key 即可体验
result = app.scrape('https://news.ycombinator.com')
print(result.markdown[:500])
或者直接用 CLI:
npx -y firecrawl-cli scrape https://example.com
小结
Firecrawl 解决的是一个很基础但很痛的问题:让 AI 应用能可靠地消费真实网页数据。
14 万 Star 不是靠营销堆出来的,是因为这个问题足够普遍,而它的解决方案足够省心——代理、JS 渲染、反爬虫、格式转换,统统帮你托管,你只管用 API。
如果你在做任何需要模型读取真实网页的项目,Firecrawl 值得放进工具箱里。
GitHub:https://github.com/firecrawl/firecrawl 官网:https://firecrawl.dev
你有没有用过类似的网页抓取工具?或者你现在是怎么给 RAG 系统补充实时数据的?欢迎评论区聊聊。
谢谢你阅读我的文章~
我是顾北,我们下期再见!
PS:本文部分内容由AI辅助创作

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 2
2 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)