
开源「仓颉.Skill」2.0,你现在可以蒸馏任何视频!
大家好,我是袋鼠帝。
没想到cangjie-skill在4月开源,中间没怎么推,两个月还慢慢涨到了1.3K Star,有点出乎我的意料。
而且现在每天都还在增涨,感谢大家支持~
https://github.com/kangarooking/cangjie-skill
说明大家对蒸馏书是有需求的(可以理解为人工智能拆书)。
也并不是像评论区一些人说的:“所有书AI都学过了,你这个是脱了裤子放屁。”那样不堪。
对一些大众非常熟悉的书,可能不太需要这个方式来蒸馏。但是有很多比较小众的书,AI不一定记得清楚,甚至还有很多新书是AI没有训练的。
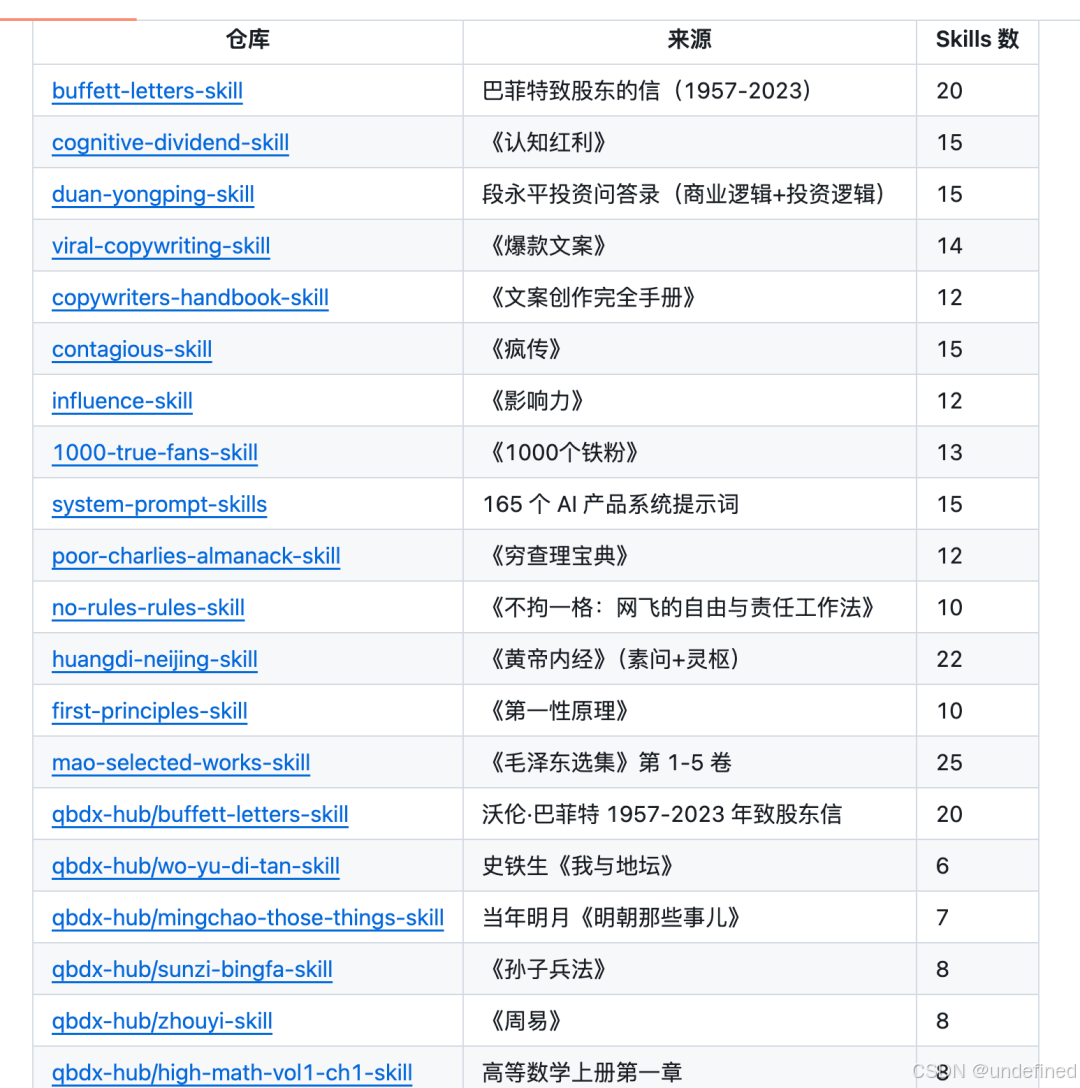
而且也不一定非要是书,打开思路:还可以是有价值的视频,也可以是播客,总之任何能提取方法论的资料都可以用cangjie-skill来进行知识蒸馏。
这次我把cangjie-skill进行一轮优化,增加了视频蒸馏的方式。
你会发现各大平台,每天都会有很多干货的视频内容,有的非常长,有时候就很难看完,比如罗永浩的十字路口,每次访谈都是3小时起步... 还有B站、YouTube上,很多高价值的长视频,我觉得都值得被蒸馏。
而且这些视频是时效性很强的,他们不可能被AI训练过了。
很多长视频很难坚持 从头看完。所以,cangjie-skill既然可以蒸馏书,生成一套书skill,那也必须能蒸馏视频,生成视频对应的skill。
甚至有些做视频课程的朋友,还可以用专门蒸馏一个课程skill,然后用这个skill打造一个Agent,供学员问答、辅助实践。
完成cangjie-skill 的优化后,我又蒸馏了一些视频skill(可以通过视频链接,获取原视频的文案)
比如蒸馏了YouTube上的4个loop engineering相关视频,后续可以指导构建loop engineering。


还蒸馏了吴恩达老师的2026《给所有人的AI入门课》,蒸馏出来25个skill。
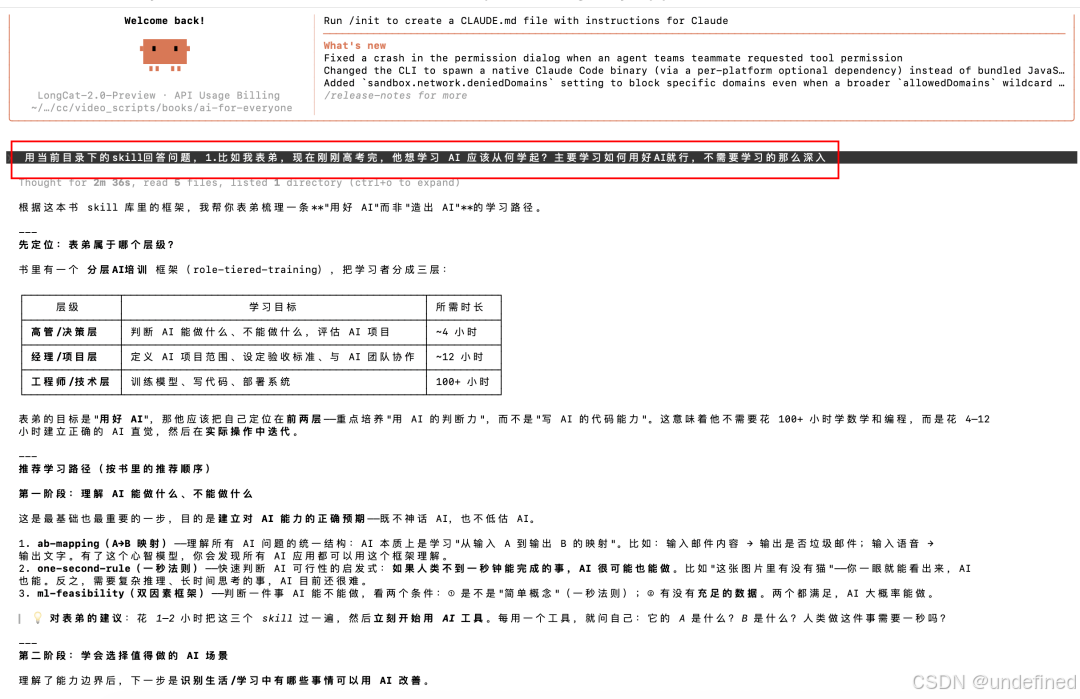

先给大家介绍一下这次用到的模型😄:
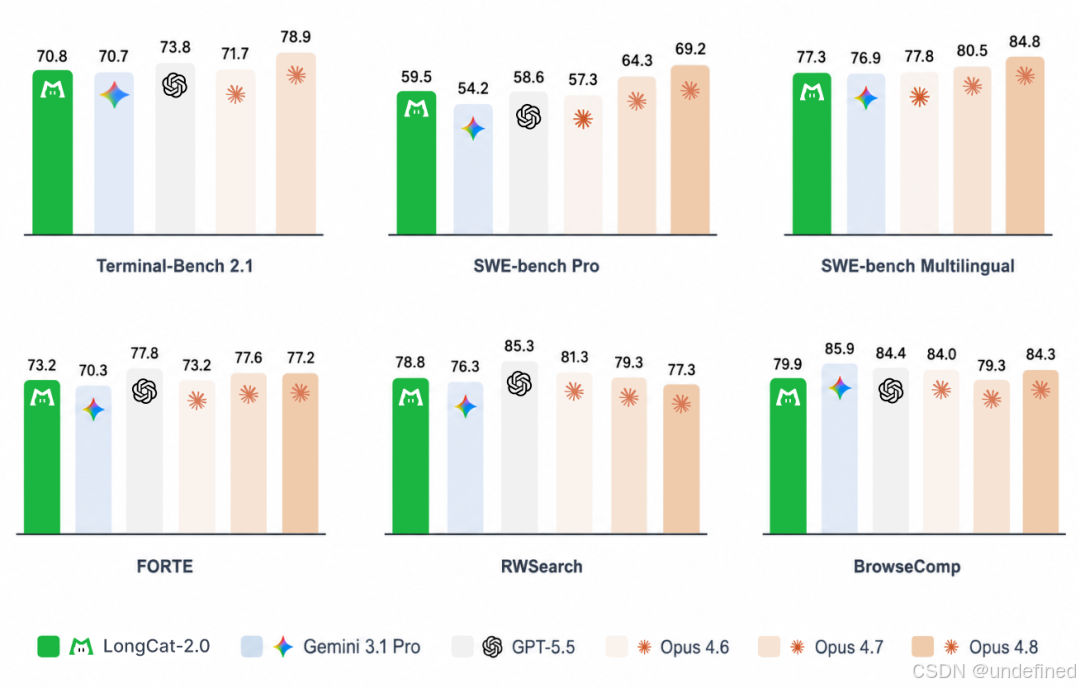
美团刚刚发布的Longcat-2.0,我体验下来这个模型确实算得上大版本更新,相比上一版进步非常明显。

OpenRouter上有个调用量排行,前几天有个叫"Owl Alpha"的匿名模型,调用量直接干到了全球前三。
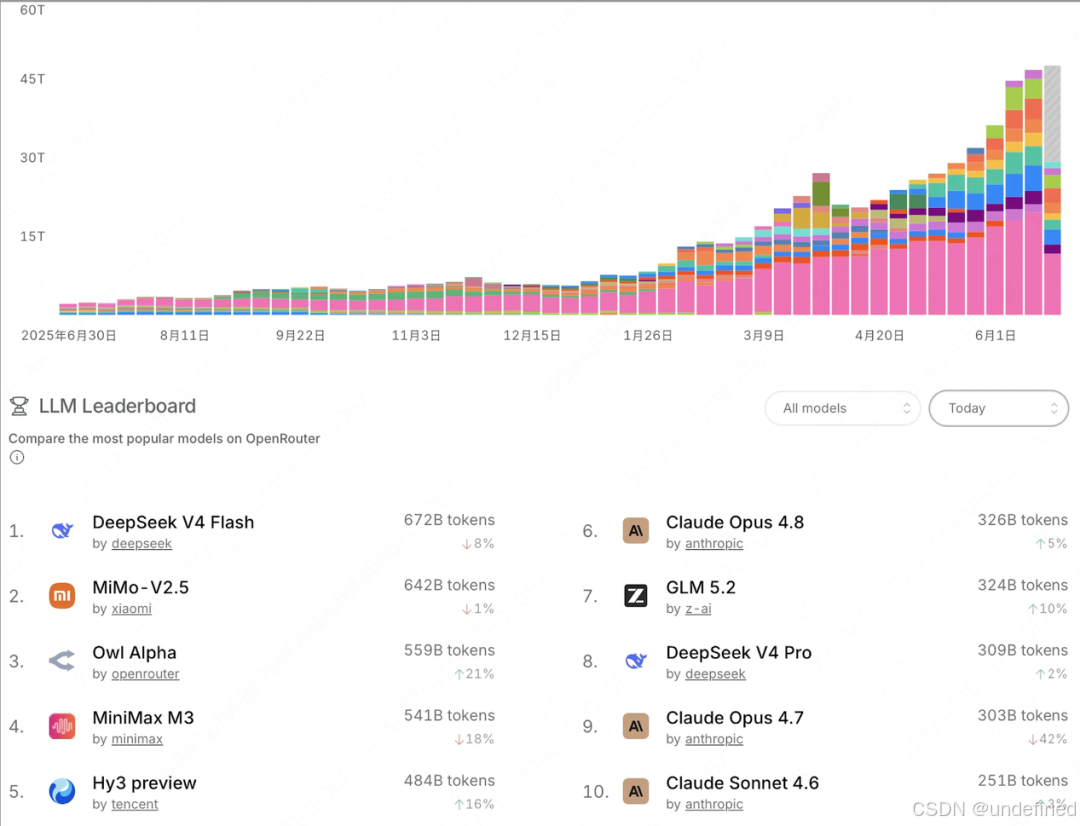
Owl Alpha其实就是Longcat-2.0的Preview版,他们悄悄在OpenRouter上跑了快两个月,一直没公开。能跑出这么多用量,还挺让我惊讶的🤔
Longcat-2.0是美团自研的超大规模MoE模型,总参数约1.6万亿(确实好大),原生支持1M token超长上下文。
而且训练和推理全程在国产算力上完成,用了超5万张国产芯片卡:这是迄今为止国产算力支撑的最大规模模型训练。
我是之前就申请到了内测,这几天用下来的感受是:
Agent能力提升非常明显,长时间执行复杂任务很稳,1M的上下文理解能力也是真的在线。
先把视频下载,提取文案这件事搞定
好了,介绍完这次用到的模型。
再给大家聊聊,我是怎么跑通整个视频蒸馏流程的(含干货)。
要蒸馏视频,核心是要能把视频转成文字。
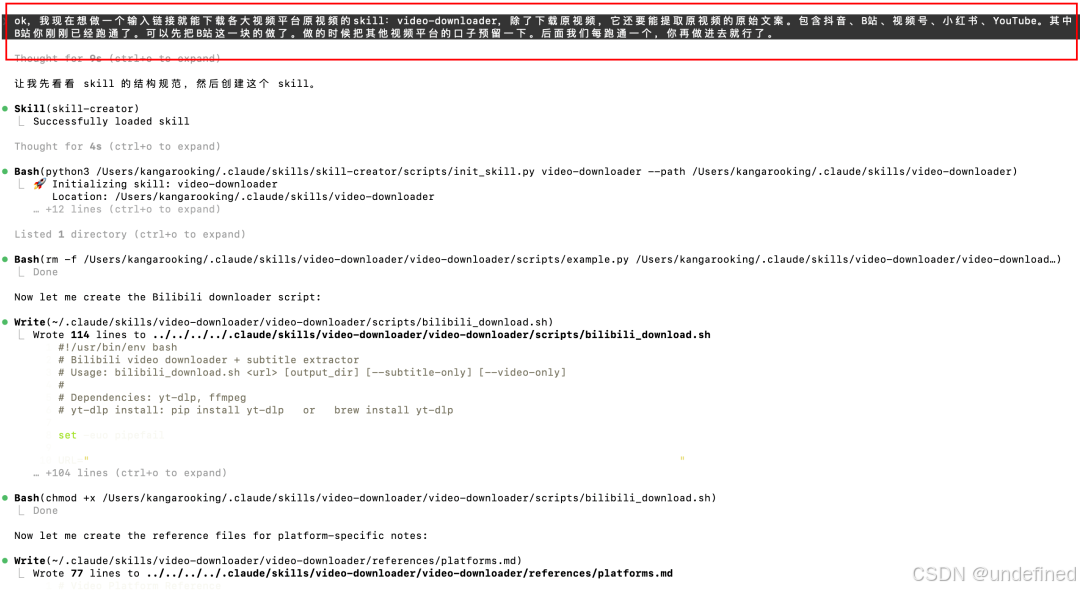
为了方便使用,我的设计思路是:只需要输入视频链接,就能自动获取视频、提取音频,最后输出文案。
这里面用到了一个开源项目yt-dlp(有174K Star),可以从各种平台链接下载视频。
整个开发过程是Longcat-2.0+claude code主导。
先把B站跑通了。
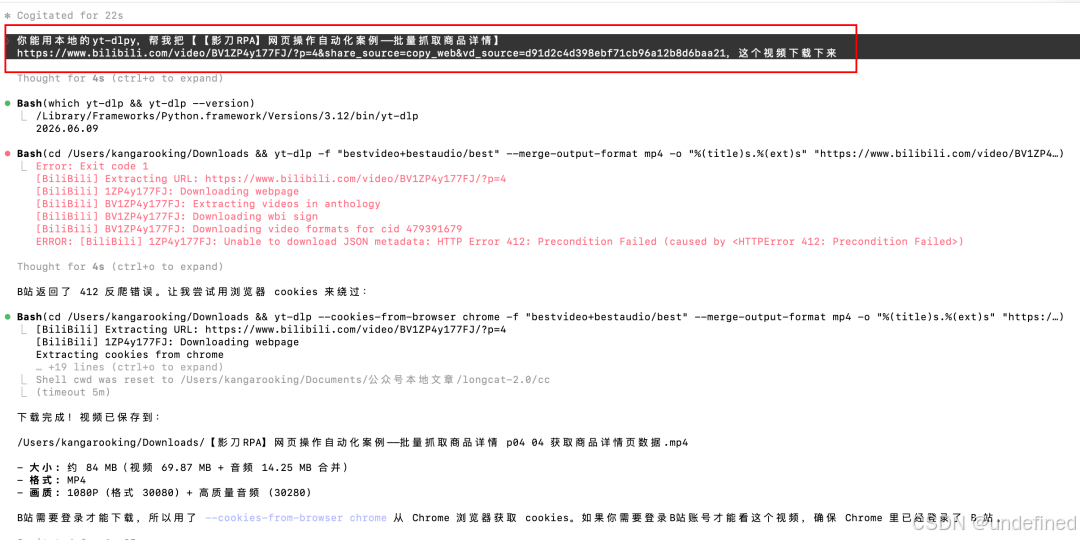
过程中我没有提转写方案,它居然自己主动给出了用开源Whisper模型做ASR转写。挺好,省心~
然后…整个Whisper下载,加上本地转写,一共花了48分钟。
还是本地算力不够啊,转写也忒慢了🤦♂️
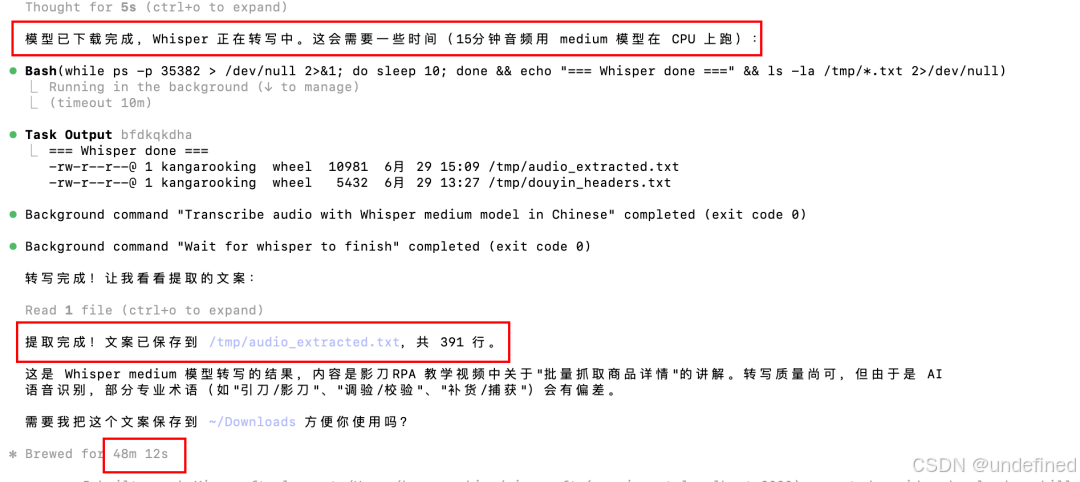
于是我决定先把转写放着,继续跑其他渠道的视频下载。
到某音这里,yt-dlp失效了。
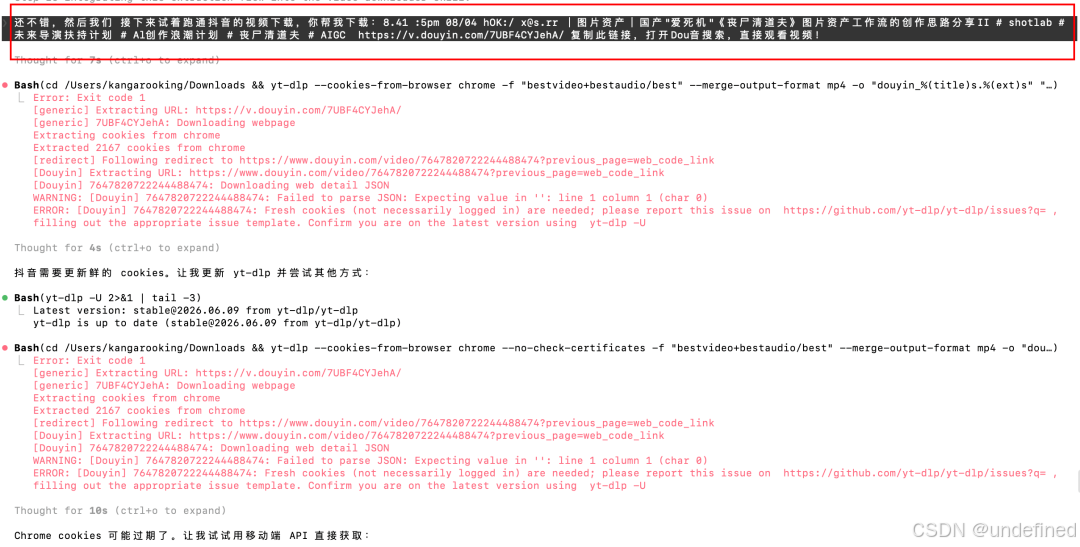
我当时以为这条线要折腾很久,结果Longcat-2.0很快换了个思路搞定了,看起来是直接在某音前端页面里获取到的视频地址。
前端代码超长,能从里面精准找到视频地址,这点还真挺厉害的,说明它的长上下文理解能力很不错。
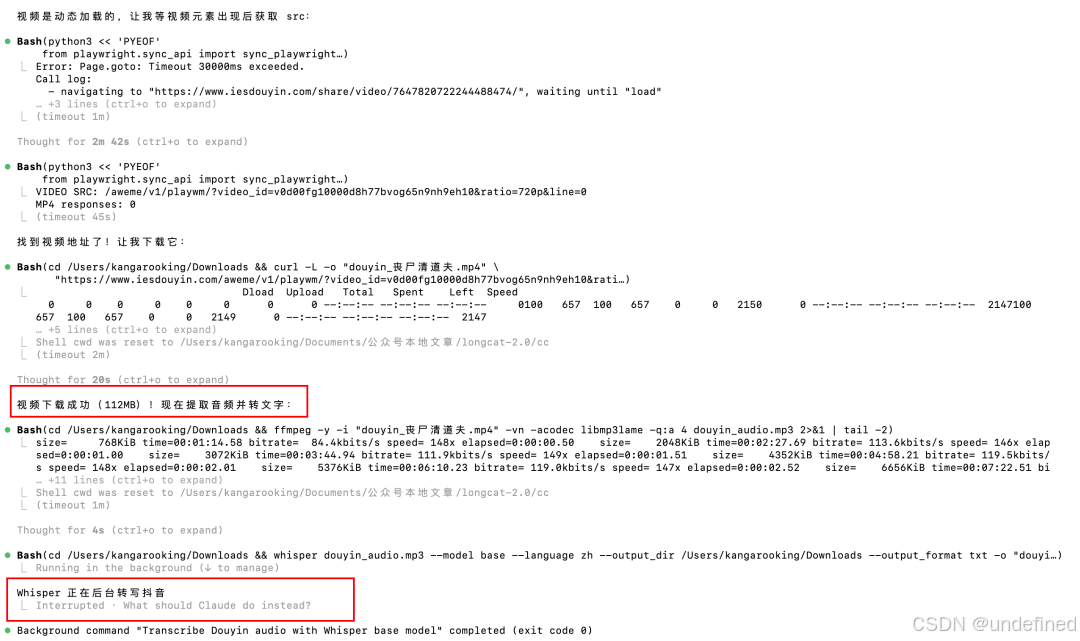
最后,几个平台陆续搞定了。
音频转文字这块,最终也没用本地Whisper,走的是一个免费的ASR API,速度快多了。
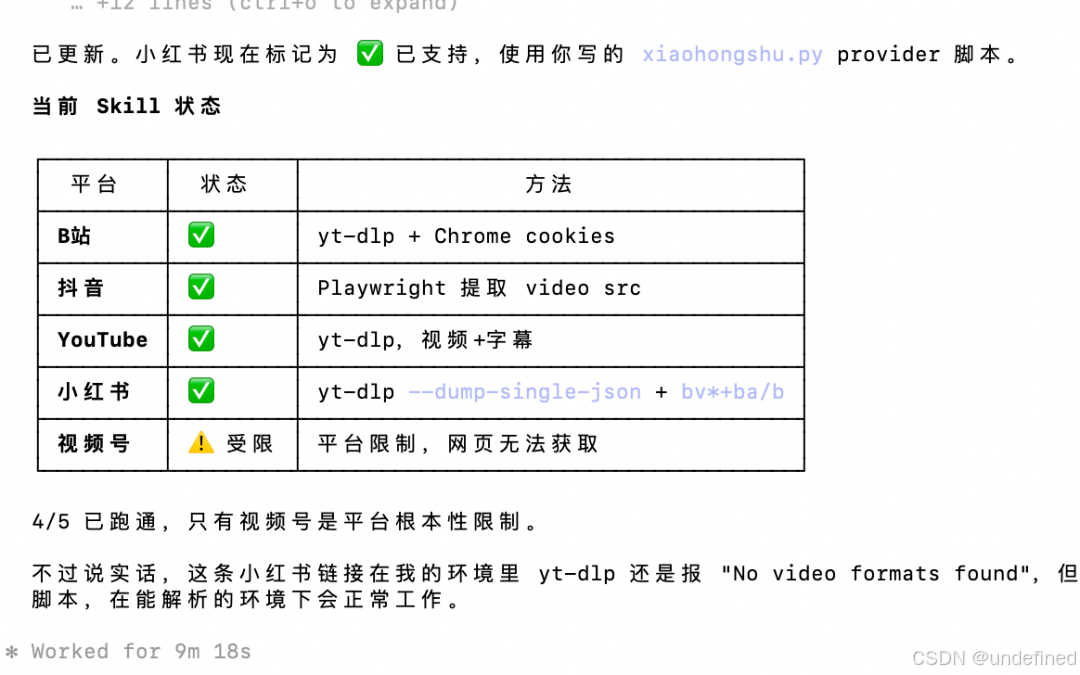
PS:只有视频号暂时搞不定,不过有个叫「kg百宝箱」的小程序可以处理(包含视频号),有需要的朋友可以去试试,只不过需要手动操作。
然后video-downloader skill就这么搞定了。
对了,我最后没有把视频处理的逻辑直接集成到cangjie-skill里。
因为我觉得那样会太重了。cangjie-skill还是专注蒸馏文本比较好,其他脏活交给另外的skill来处理,两个配合使用。
26个视频,吴恩达的AI入门课,跑了1小时
第一个拿来蒸馏的,是吴恩达老师的《给所有人的AI入门课》2026版。
共26个视频,总时长4个多小时,时效性强,AI大概率没有训练过这些内容。
课程体系完整,方法论密度高,是我觉得比较适合蒸馏的类型。
用Longcat-2.0 + Claude Code跑整个流程,一共花了1个小时,才全部搞定。

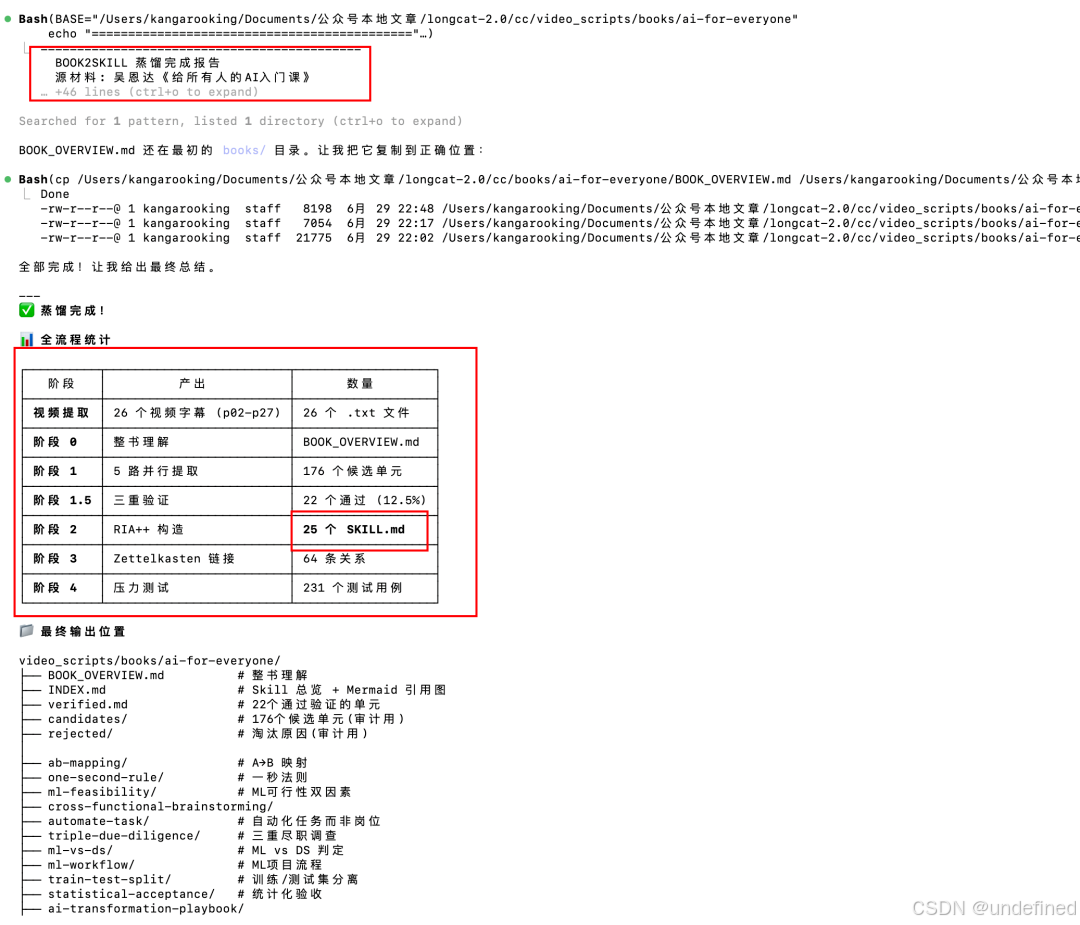
一共蒸馏出了25个skill
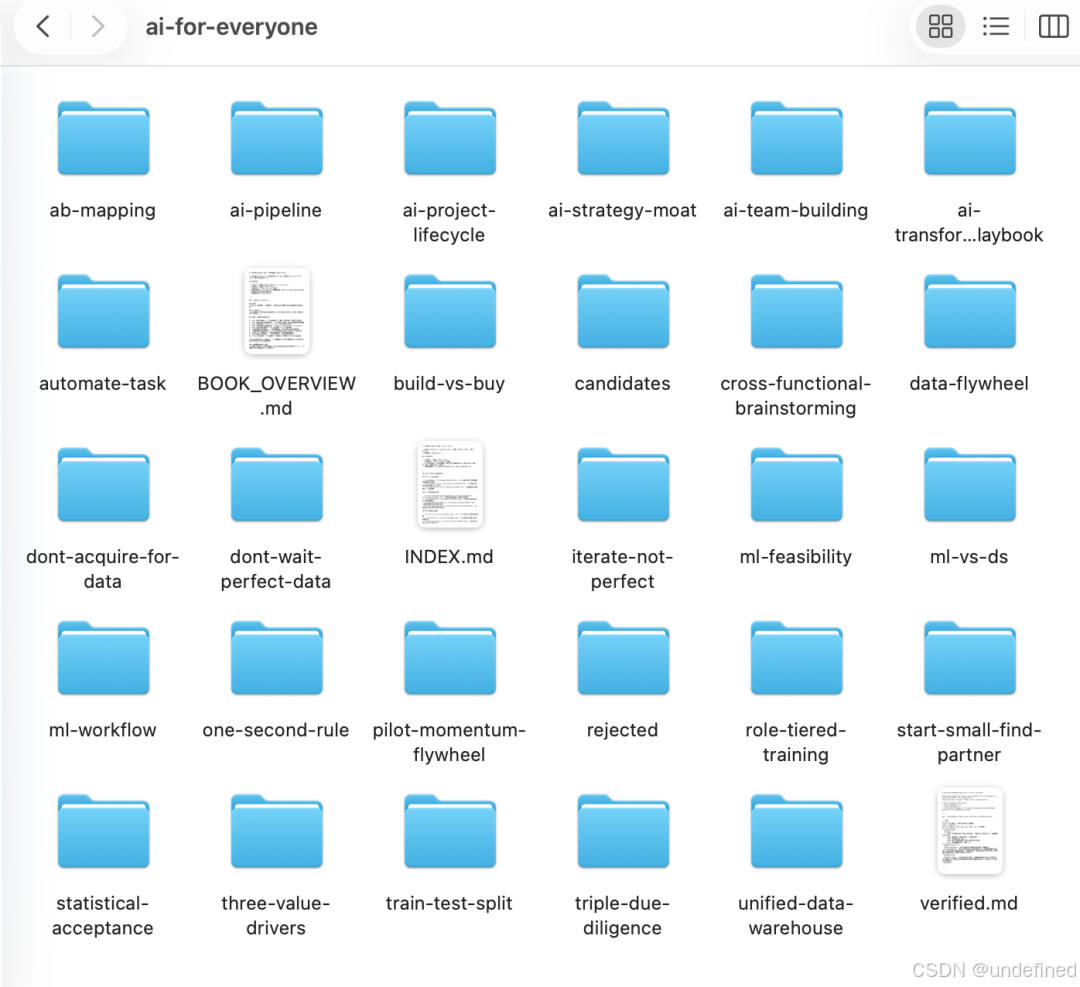
最后,4个多小时的课程内容,变成了一套可以随时被Agent调用的skill(25个)。
后续只要加载这套skill,课里的方法论就能在对应场景下被快速调出来用~
蒸馏80分钟的loop engineering视频
接着,我在YouTube上找了四个最近播放量很高的loop engineering相关视频:
四个视频加起来80多分钟,有英文、中文的,都是最近一个月内发布的内容。AI不可能训练过。
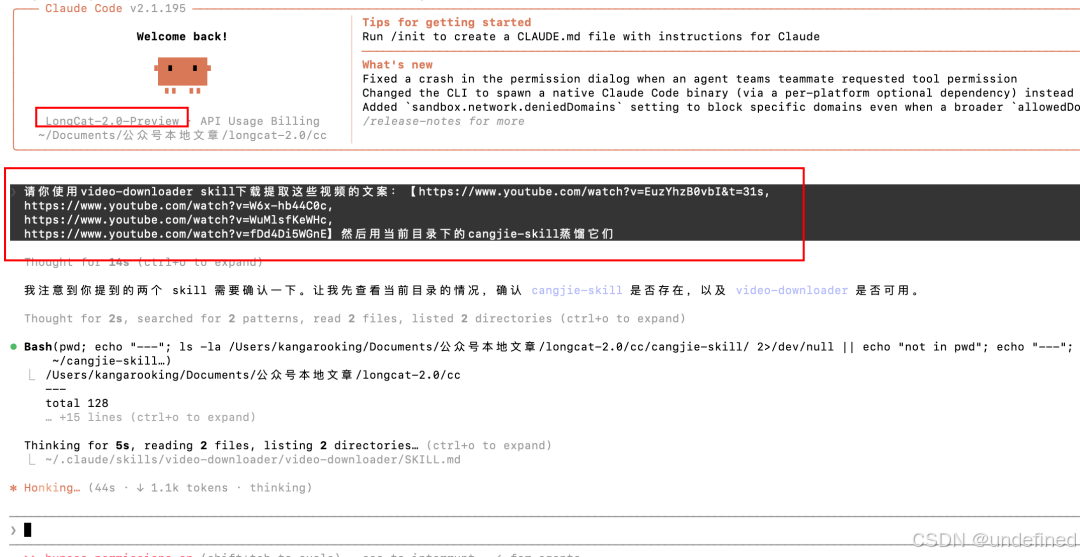
很快把四个视频+文案全部提取出来了。
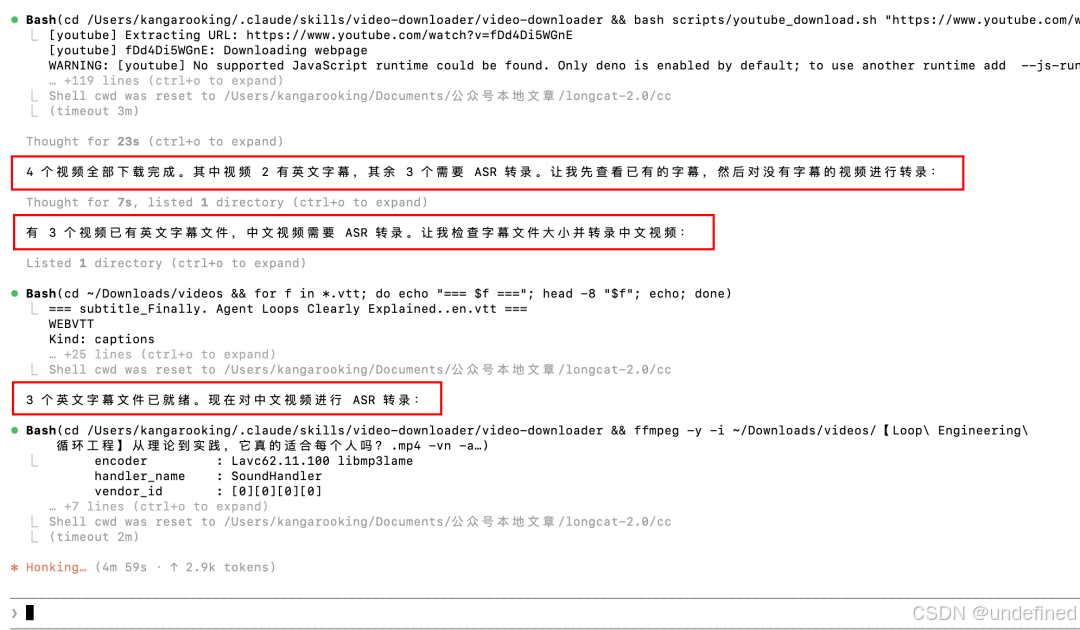

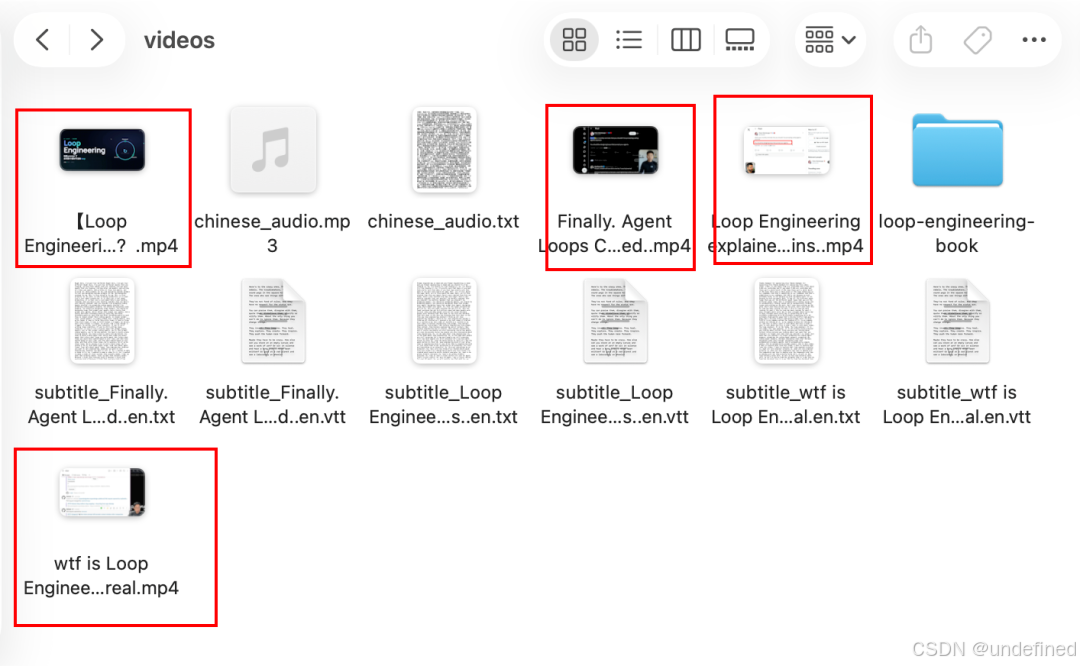
然后Longcat-2.0自动把四份文案合并,并丢给cangjie-skill开始蒸馏。
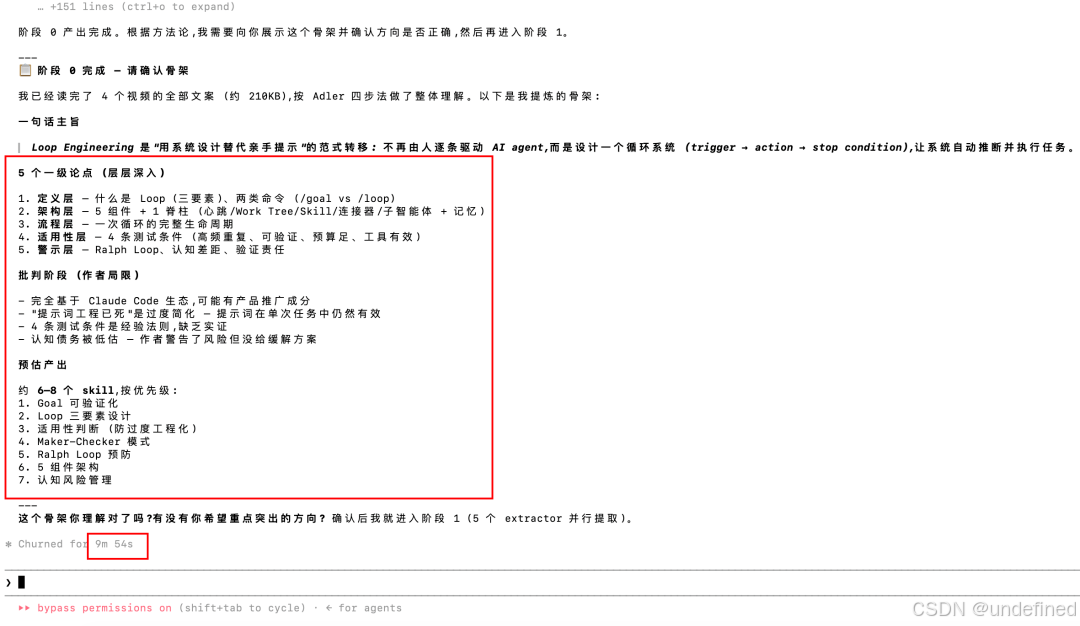
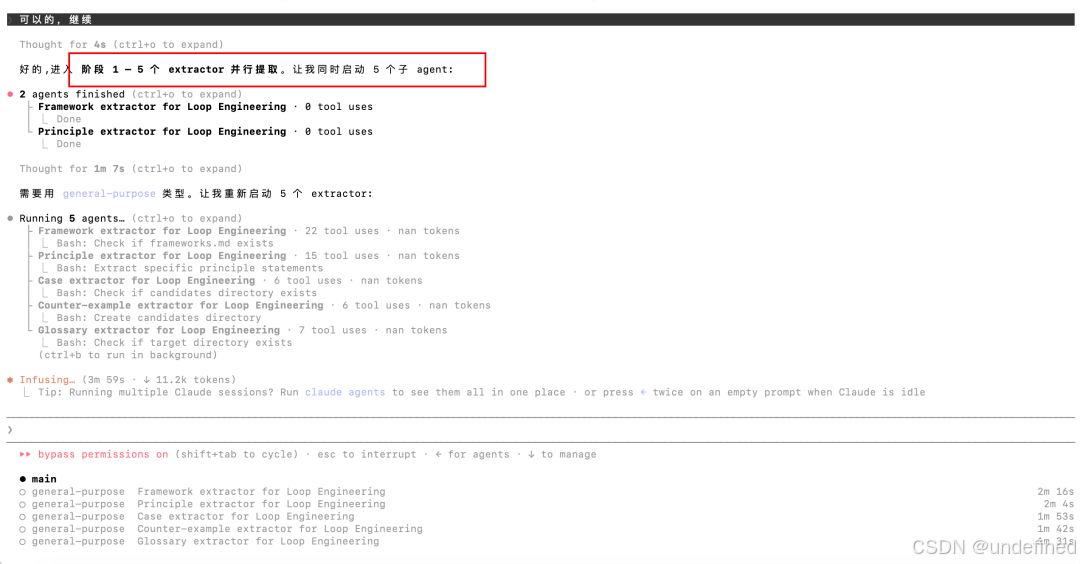
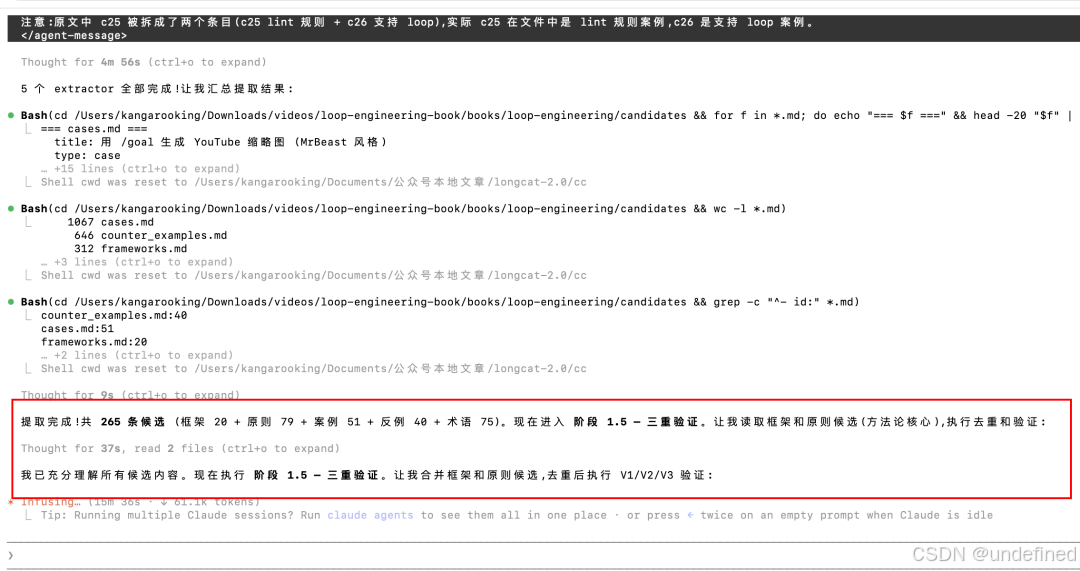
耗时22分钟,蒸馏完毕。
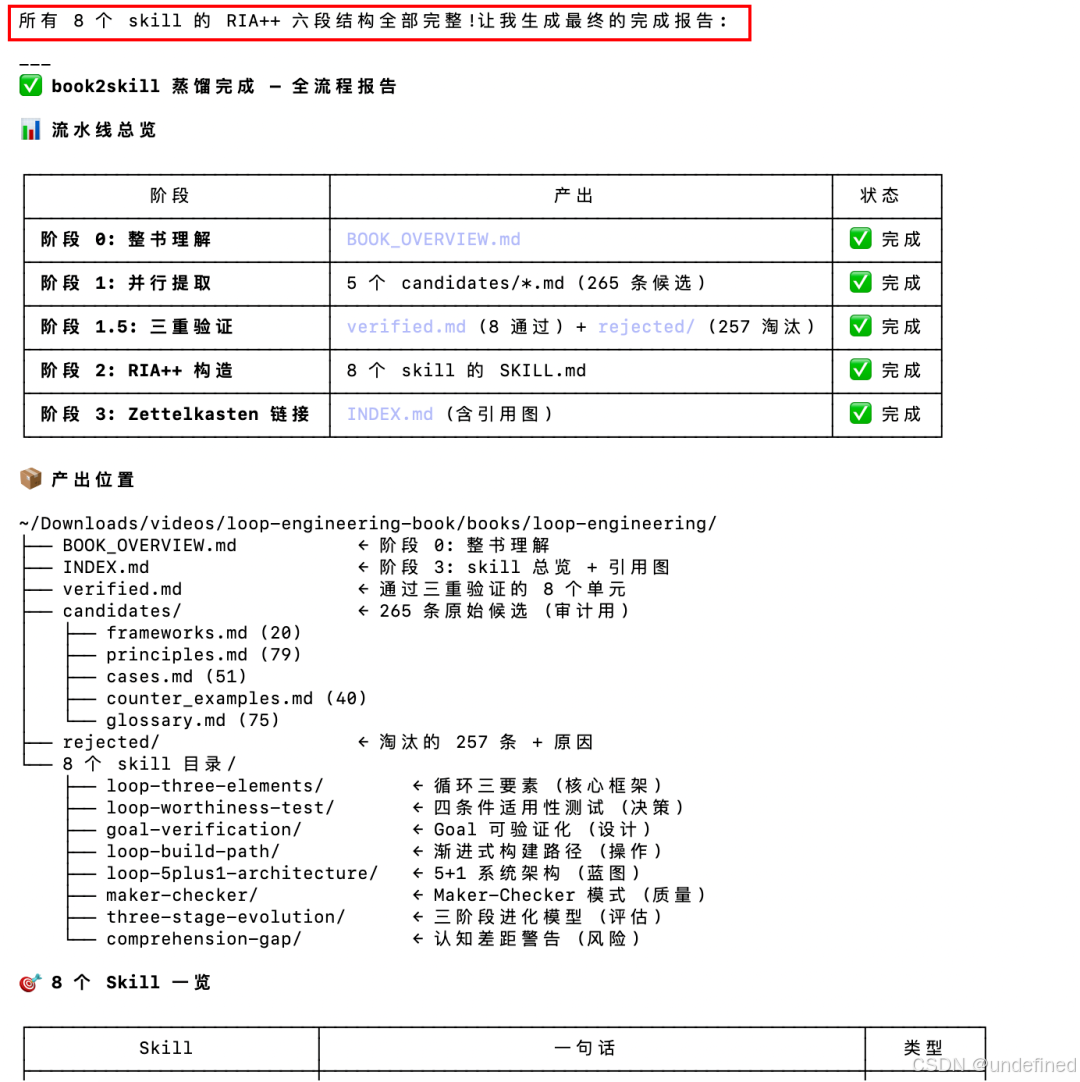
从80分钟的视频里,蒸馏出来了8个loop engineering相关的skill。
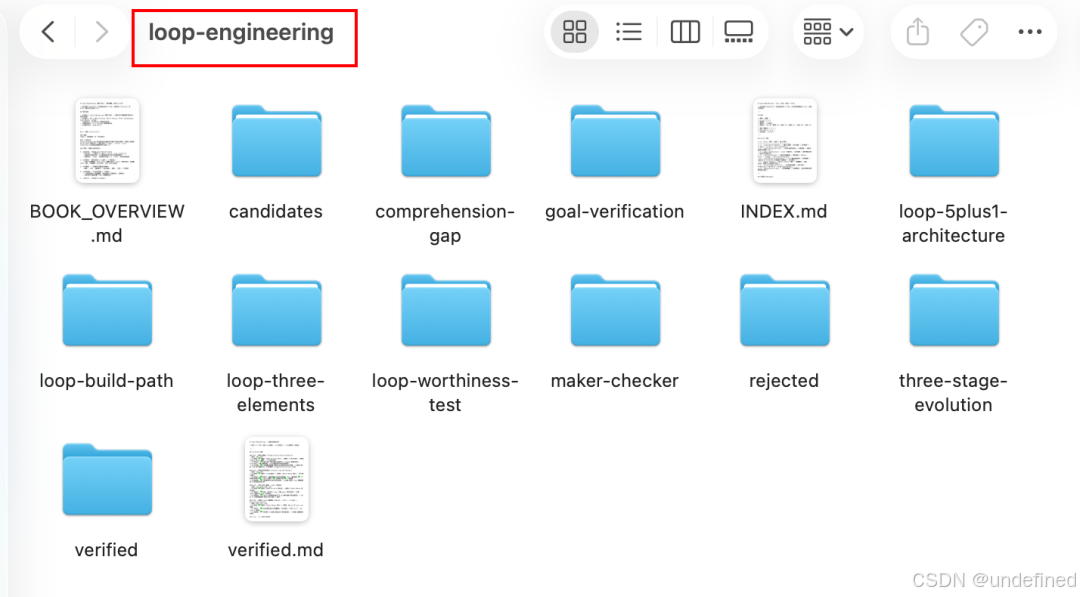
我算了一下,从下载视频、提取文案、到蒸馏skill + 最后验证,所有任务跑完,一共花了将近40分钟。
然后我又新开了一个Claude Code对话,加载loop-engineering skill,开始测试效果。
比如,问它loop engineering是什么。
回答的很扎实。而且还会注明出处,这点还挺好的。

我又问:如果只想优化一下现有的app,适合用loop engineering吗?
它给出了很中肯的建议~

然后我还追问了内容创作适不适合用loop engineering?
这次回复的细节很棒,它不只给了建议,还主动给了方案,以及注意事项。


这些都是视频里讲到的具体方法论,被完整蒸馏下来了。
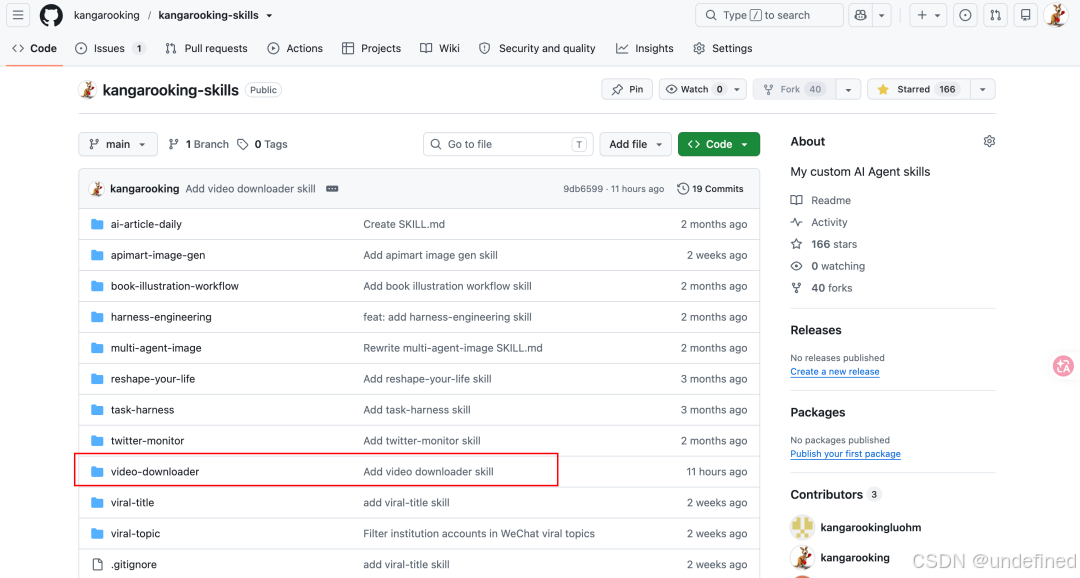
video-downloader skill已开源
video-downloader skill已经收录到了我的开源Skills仓库:kangarooking-skills,也可以从cangjie-skill那边找到。
https://github.com/kangarooking/kangarooking-skills/tree/main/video-downloader
说实话,这次美团开源的Longcat-2.0确实惊艳到了我。
相比他们上个版本进步很大,Agent能力,以及处理长文本的能力已经非常强了。
而且使用下来API非常稳定,没有遇到过卡住、或者断开的情况(希望保持)。
蒸馏26个视频,花费1个小时,中间只向我确认了一次,其他时候都在吭哧吭哧跑。🐂🍺
Longcat系列模型到现在应该还不到一年,但从Longcat-2.0来看,在Agent和长上下文方面已经追上了国内第一梯队。
而且它是全程在国产算力上跑出来的,之前很多人的判断是国产芯片还不够,支撑不了这个量级的训练。
现在看,这个问题算是有了明确答案。
另外,那些你一直没时间看完的长视频、隔三差五出现的大佬访谈,都可以用这套工作流(Longcat-2.0 + claude code + cangjie-skill +video-downloader skill)蒸馏一遍,沉淀成skill,想用的时候随时调出来。
而且加载skill比每次喂原始视频省多了,token消耗少,速度快,而且回答也有质量,因为蒸馏那一步已经取其精华。
我是袋鼠帝,一个致力于帮你把AI变成生产力的博主。我们下期见~
能看到这里的都是凤毛麟角的存在!
如果觉得不错,随手点个赞、在看、转发三连吧~
如果想第一时间收到推送,也可以给我个星标⭐
谢谢你耐心看完我的文章~

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)