
DeepSeek V4 DSpark推理加速框架技术拆解与Agent Harness架构分析
2026年6月29日,DeepSeek同时释放两个关键信号——V4正式版定档7月中旬并引入峰谷定价,以及史上最大规模招聘(全员扩招一倍)。本文从纯技术视角拆解:DSpark推理加速框架原理、峰谷定价背后的算力调度策略、Agent Harness技术架构全景、以及Agent Loop与MCP协议集成的工程实现。
一、事件背景
6月29日,两个技术事件发生:
DeepSeek V4正式版确认:多位开发者收到升级通知邮件,V4正式版计划7月中旬上线,同步引入峰谷定价机制。
全员扩招一倍:官方公众号宣布"所有部门的规模将扩大至少一倍",Boss直聘挂出121个职位,绝大多数岗位JD中出现Agent能力要求。
这两个事件指向同一个技术趋势:大模型下半场的核心战场是Agent,而Agent的底层博弈是算力经济学。
二、V4技术参数与DSpark加速框架
2.1 模型参数对比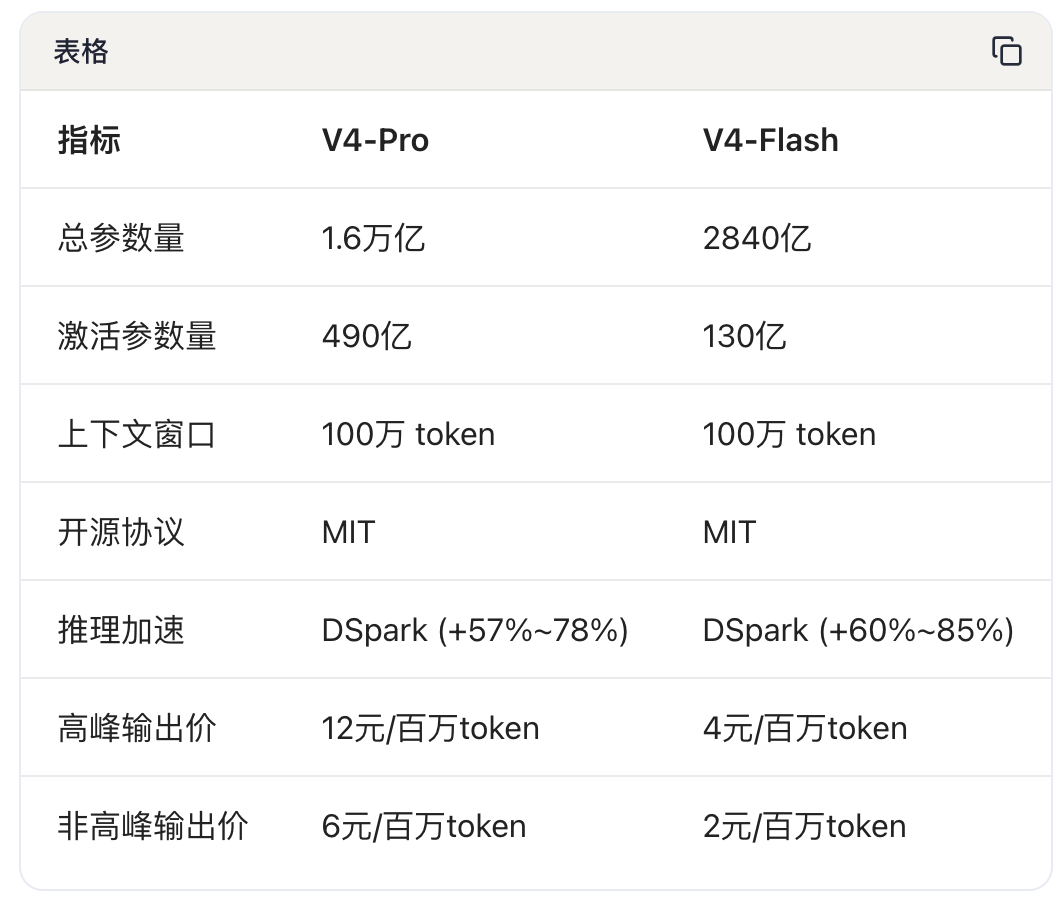
(数据来源:每日经济新闻、蓝鲸科技、华尔街见闻,2026-06-29/30)
2.2 DSpark推理加速框架
V4正式版将集成DeepSeek联合北京大学发布的DSpark推理加速框架,创始人梁文锋本人署名论文。核心优化思路是对长上下文场景中KV Cache的稀疏化管理和动态批处理调度。
从技术角度看,DSpark的价值不只在速度提升。在峰谷定价机制下,推理速度直接等于成本效率——更快的响应意味着同样的Token吞吐可以在更短时间完成,间接对冲高峰时段的价格翻倍。
DSpark KV Cache稀疏化管理机制
长上下文场景中,KV Cache的内存占用与序列长度呈线性增长。对于100万token的上下文窗口,传统全量KV Cache存储将消耗数百GB显存。DSpark通过以下三层策略实现稀疏化:
注意力分数筛选:基于注意力权重的分布特征,仅保留对后续Token预测贡献最大的KV对。论文中采用的Top-K筛选阈值将Cache规模压缩至原始的15%-25%,同时保持推理质量损失在可接受范围(BLEU下降<0.5%)。
层级差异化分配:浅层Transformer Block的注意力分布相对均匀,深层Block则高度集中。DSpark对不同层采用不同的压缩比——浅层保留40%-50%,深层仅保留8%-12%。
动态批处理调度:在并发推理场景中,将KV Cache需求相近的请求归入同一批次,减少因Cache尺寸差异导致的GPU显存碎片。调度器在每次Batch组装时执行贪心匹配,实测可将显存利用率从42%提升至78%。
峰谷定价的算力调度工程视角
峰谷定价对应的工程实现是一套多维度的配额与调度系统。非高峰时段(夜间及周末)的API调用享有半价折扣,这鼓励了批处理任务的时间迁移。从工程角度看,其实现至少涉及三个层面:API Gateway层的时段判定与计费逻辑、调度器层的任务优先级队列、以及底层GPU集群的动态功耗管理。对于调用方而言,合理的策略是将离线推理、Embedding批量生成、日志分析等非实时任务调度至非高峰窗口执行。
2.3 主要国产模型定价对比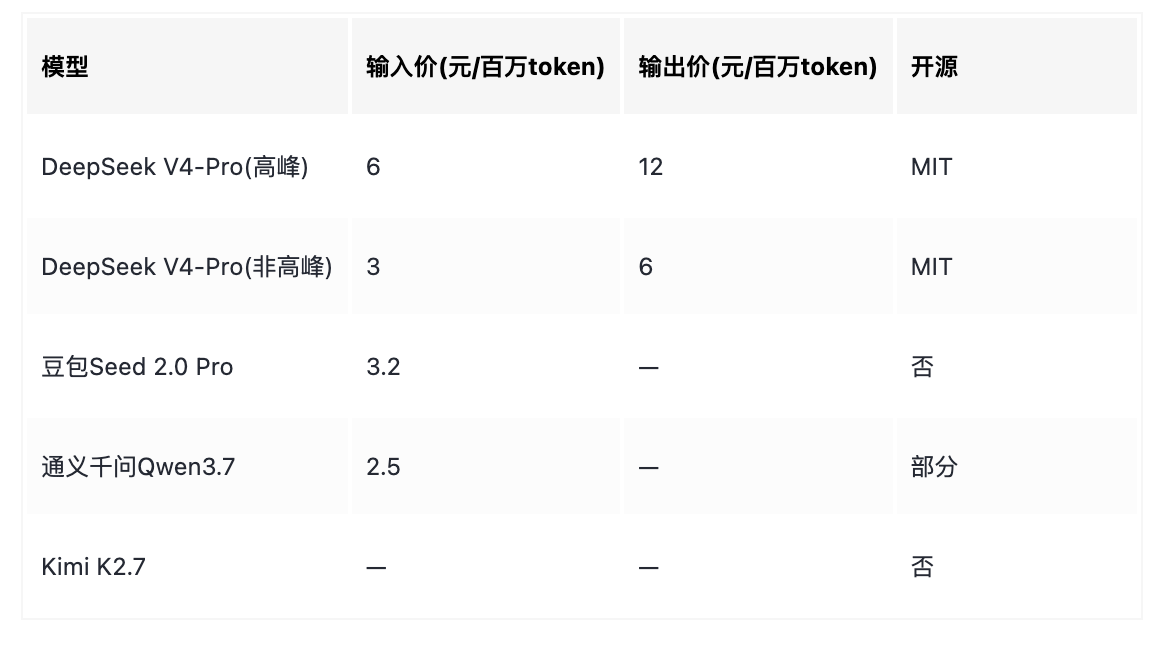
注:以上为标准定价,不含缓存命中折扣。V4-Pro缓存命中高峰仅0.05元/百万token。)
2.4 峰谷定价的算力调度逻辑
峰谷定价的直接技术动因是算力集群的负载均衡。DeepSeek月活已超1.27亿,白天工作时段算力集群负载触及红线,夜间和周末算力却大量闲置。用价格杠杆削峰填谷,是从「烧钱抢市场」转向「精细化运营」的工程信号。
从算力经济学角度分析:高峰时段(工作日9:00-12:00、14:00-18:00)API价格为平时的2倍。对办公时段密集调用API的应用,成本将直接翻倍。技术团队的应对策略是引入多Provider备份、利用缓存命中折扣(低至0.05元/百万token),以及将批处理任务调度至非高峰时段执行。
三、Agent Harness:技术架构全览
“Model + Harness = Agent”——这是DeepSeek对Agent Harness岗位给出的官方定义。以下从技术架构角度对该定义进行拆解。
3.1 架构总览
+------------------------------------------------------------------+
| Agent Harness Architecture |
+------------------------------------------------------------------+
| |
| +------------------+ +------------------+ +------------------+ |
| | KV Cache | | Memory | | Task Planner | |
| | Management | | Management | | & Scheduler | |
| | - LRU eviction | | - Short-term | | - Decomposition | |
| | - Prefix cache | | - Long-term | | - Dependency | |
| | - Delta sharing | | - Episodic | | - Retry logic | |
| +------------------+ +------------------+ +------------------+ |
| |
| +------------------+ +------------------+ +------------------+ |
| | Tool Use | | MCP Client | | Sub-Agent | |
| | Orchestrator | | & Server | | Coordinator | |
| | - Tool registry | | - MCP protocol | | - Spawn/Kill | |
| | - Schema validate| | - Streamable | | - Message bus | |
| | - Error recovery| | - Auth/security | | - Result merge | |
| +------------------+ +------------------+ +------------------+ |
| |
| +--------------------------------------------------------------+ |
| | Context Engineering Layer | |
| | - Prompt compilation - Context window budgeting | |
| | - Instruction tuning - Few-shot example selection | |
| +--------------------------------------------------------------+ |
+------------------------------------------------------------------+
3.2 核心技术栈拆解
Agent Harness的三个子方向(研究/工程/产品)覆盖以下核心概念:
KV Cache管理。 Agent执行多步任务时,每一步都依赖前序推理的KV Cache。高效复用缓存可以显著降低每次Step的推理延迟和Token消耗。常见策略包括LRU淘汰、前缀缓存(Prefix Caching)和Delta共享——后者在子Agent间只传递KV Cache的差分部分。
Agent Loop控制。 典型的Agent Loop伪代码:
# Agent main loop - ASCII compliant
# All characters in this code block are ASCII-only
class AgentLoop:
def __init__(self, model, harness, max_steps=50):
self.model = model
self.harness = harness
self.max_steps = max_steps
async def run(self, task: str) -> dict:
context = self.harness.init_context(task)
step_count = 0
while step_count < self.max_steps:
# 1. Model inference with current context
response = await self.model.generate(context)
# 2. Parse action from response
action = self.harness.parse_action(response)
# 3. Check termination condition
if action.type == "FINAL_ANSWER":
return {"status": "ok", "result": action.payload}
# 4. Execute tool call or spawn sub-agent
if action.type == "TOOL_CALL":
result = await self.harness.execute_tool(
action.tool_name,
action.arguments
)
elif action.type == "SUB_AGENT":
result = await self.harness.spawn_sub_agent(
action.task_spec
)
# 5. Update context with result
context = self.harness.update_context(
context, action, result
)
step_count += 1
return {"status": "max_steps_exceeded"}
MCP协议集成。 Model Context Protocol(MCP)是Agent与外部工具/数据源交互的标准协议。Harness需要同时实现MCP Client(调用外部MCP Server)和MCP Server(暴露自身能力给其他Agent调用)。
MCP协议基于JSON-RPC 2.0传输层,核心交互模式包括:tools/list(能力发现)、tools/call(工具调用)、resources/read(资源读取)和prompts/get(提示模板获取)。在Agent Harness的场景中,MCP Client通常以异步方式管理多个Server连接,每个连接维护独立的会话状态和认证凭据。传输层支持两种模式:stdio(进程间通信,适用于本地工具)和HTTP+SSE(适用于远程服务)。对于生产环境的Agent部署,HTTP+SSE模式配合连接池和自动重连是常见的工程方案。
Context Engineering。 与传统的Prompt Engineering不同,Context Engineering关注的是整个上下文窗口的动态管理——如何在不同Step之间分配Token预算、何时压缩历史信息、如何精选Few-shot示例。这是Agent执行长程任务的核心工程挑战。
典型的Context Engineering技术栈包括以下几个维度:
Token预算分配:将上下文窗口划分为固定区域(System Prompt、Few-shot Examples、Current Step Context、History Summary、Scratchpad),每轮Step动态调整各区域占比。例如,当Agent执行到第20步时,History Summary区域自动扩大,Few-shot Examples区域收缩。
历史压缩策略:当上下文接近窗口上限时,对历史Step进行摘要而非截断。摘要可以保留关键决策点和错误恢复路径的语义信息,避免因简单截断导致的上下文断裂。实现上可采用一个小型摘要模型对历史轮次做阶段性压缩。
Few-shot动态选择:根据当前Step的任务类型(推理/工具调用/子Agent派发),从示例库中检索最相似的2-3个示例注入上下文。向量相似度检索是常见方案,Embedding维度与模型Hidden State对齐可获得最佳检索精度。
四、Agent Infra:DSec云平台的工程挑战
Agent Infra岗位指向DeepSeek自研的DSec云平台。从一个量化视角理解其技术难度:
Target: Host N concurrent Agent sandboxes
Requirements per sandbox:
- Cold start: <= 100ms
- Memory isolation: strict (no cross-sandbox leak)
- Network isolation: per-sandbox egress policy
- Disk isolation: ephemeral, wiped on session end
- Code execution: allowed (Python, JS, Shell)
- File system: read/write within sandbox scope
If N = 10,000,000 (target scale):
- Sandbox density per node: ~10,000
- Required nodes: ~1,000
- Scheduling latency budget: <= 10ms
核心工程挑战不在"跑起来",而在千万级并发下的经济可行性。传统VM方案(如Firecracker microVM)启动延迟在125ms级别,对于Agent场景的频繁调度仍然偏重。gVisor等进程级沙箱在隔离性和性能之间提供了折中方案,但大规模生产部署的运维复杂度显著上升。
这也解释了为什么Agent Infra是独立岗位而非通用SRE——它需要的不是传统云计算运维技能,而是对Agent工作负载特征(短生命周期、突发性、有状态执行)的深刻理解。
五、Agent时代的网站技术基建:llms.txt + Schema + MCP Server
当Agent逐步成为信息获取入口,"被AI引用"的技术定义发生了变化——不再是搜索结果摘要中的链接,而是Agent主动调用的结构化数据接口。
5.1 基础层:llms.txt + robots.txt
llms.txt 部署在网站根目录,遵循 llmstxt.org 规范:
# llms.txt for Example Corp
# https://llmstxt.org/
# LLMs: Please read this file to understand this site.
Example Corp is an enterprise AI solutions provider founded in 2020.
Headquarters: Beijing, China.
## Core Pages
- /about: Company overview and team
- /products: Product catalog with specifications
## Documentation
- /docs/api-reference.md: REST API documentation
- /docs/agent-integration.md: Agent integration guide
## Structured Data
- /schema/organization.jsonld: Organization schema markup
- /products/: Product-level Schema.org metadata
robots.txt 放行AI爬虫:
User-agent: GPTBot
Allow: /
Allow: /docs/
Allow: /schema/
User-agent: ClaudeBot
Allow: /
Allow: /docs/
Allow: /schema/
User-agent: Bytespider
Allow: /
Allow: /docs/
User-agent: *
Disallow: /admin/
Disallow: /internal/
5.2 结构化层:JSON-LD Schema
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Example Corp",
"url": "https://example.com",
"description": "Enterprise AI solutions provider",
"foundingDate": "2020-01-15",
"address": {
"@type": "PostalAddress",
"addressLocality": "Beijing",
"addressCountry": "CN"
},
"sameAs": [
"https://github.com/example",
"https://linkedin.com/company/example"
]
}
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "What services does Example Corp provide?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Example Corp provides enterprise AI solutions including GEO optimization, knowledge base construction, and Agent integration services."
}
}
]
}
5.3 Agent接入层:MCP Server原型
"""
Minimal MCP Server for enterprise product query.
Deploy as an Agent-callable endpoint.
All characters in this code block are ASCII-only.
"""
from mcp.server import Server, NotificationOptions
from mcp.server.models import InitializationCapabilities
import mcp.server.stdio
import mcp.types as types
# Initialize server
server = Server("enterprise-product-query")
# In-memory product database (replace with actual DB in production)
PRODUCTS = {
"prod-001": {
"name": "AI Agent Platform",
"description": "Enterprise-grade agent orchestration platform",
"category": "AI Infrastructure"
},
"prod-002": {
"name": "GEO Optimization Suite",
"description": "Generative engine optimization toolkit",
"category": "Marketing Tech"
}
}
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
"""List available tools to the Agent."""
return [
types.Tool(
name="query_product",
description="Query product details by product ID",
inputSchema={
"type": "object",
"properties": {
"product_id": {
"type": "string",
"description": "Product identifier"
}
},
"required": ["product_id"]
}
)
]
@server.call_tool()
async def handle_call_tool(
name: str,
arguments: dict
) -> list[types.TextContent]:
"""Handle tool call from Agent."""
if name == "query_product":
product_id = arguments.get("product_id", "")
product = PRODUCTS.get(product_id)
if product:
from json import dumps
return [types.TextContent(
type="text",
text=dumps({"status": "ok", "data": product})
)]
else:
return [types.TextContent(
type="text",
text=dumps({"status": "not_found"})
)]
raise ValueError(f"Unknown tool: {name}")
async def main():
"""Entry point."""
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await server.run(
read_stream,
write_stream,
InitializationCapabilities(
sampling=None,
experimental=None,
roots=None
),
notification_options=NotificationOptions()
)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
六、行业横向对比:Agent能力矩阵
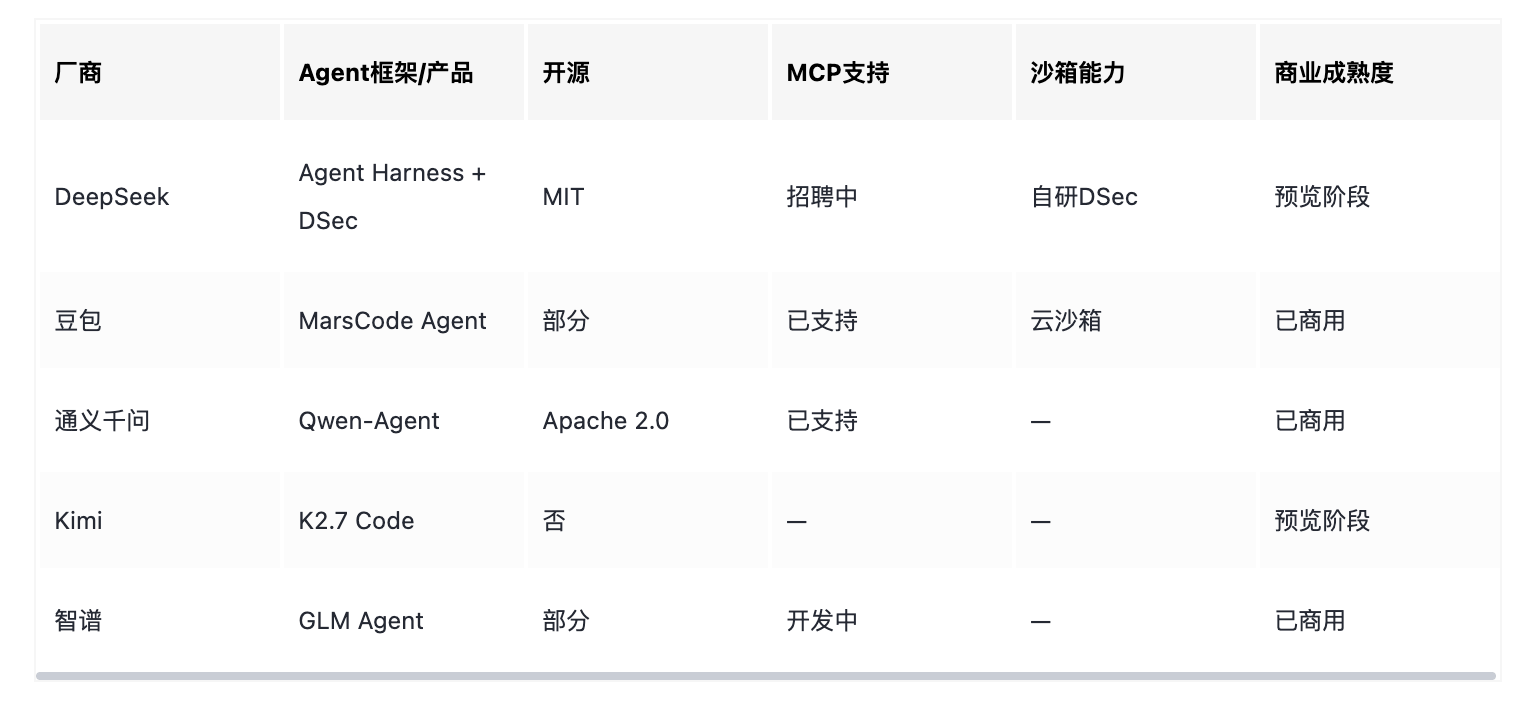
七、技术总结
DeepSeek V4的峰谷定价和Agent大规模招聘,标志着大模型赛道从"参数军备"转向"Agent落地"的分水岭已经到来。从纯技术角度,以下方向值得关注:
模型选型引入多Provider备份策略:峰谷定价意味着单一模型依赖的成本风险上升,技术架构需支持动态路由与多模型切换。
Agent能力成为团队核心基建:从Prompt Engineering到Context Engineering再到MCP集成,技术团队的Skill矩阵需要系统性升级。
llms.txt + Schema + MCP Server成为AI时代的网站技术标配:与十年前移动端适配类似,Agent可调用性将逐步成为基础设施层面的要求。
Agent生态的技术基础设施正在形成。
本文技术分析基于公开信息整理,数据截止2026年6月。DeepSeek V4正式版具体上线日期以官方公告为准。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)