
微信读书出官方 Skill 了,但我用了一天发现它还差关键一步
微信读书官方 Skill:装完能干什么?
先说结论:装完确实能用,但它是一个数据查询工具,不是读书助理。
官方提供的安装方式很简单,两步:
# 方式一:让 AI 直接下载安装
"下载 https://cdn.weread.qq.com/skills/weread-skills.zip 安装 skill"
# 方式二:命令行
npx skills add jerlinn/jerlin-weread
安装完,去 weread.qq.com/r/weread-skills 用微信扫码拿 API Key,填进去。官方说全程不超过 1 分钟,我实测确实很快。
装完之后,这个 Skill 能帮你做六件事:
查书架:你可以问「我书架上有多少本书」「最近在读什么」,它真的能答上来。对于我这种书架已经乱成狗、自己都搞不清楚读了什么的人,这个功能立竿见影。
看统计:「我今年读书多少小时」「上个月读了几天」,数字很准,因为是直接读你账号的数据。我查了一下,发现自己年初立的「每月读 4 本」的 flag,实际上一本都没完成,破防了。
导笔记:「把《穷查理宝典》里我的划线全部列出来」——这个功能对重度划线用户是刚需。我在这本书里划了 68 条,一次性全拉出来整理成文档,省了不少手动复制的时间。
搜书:查某本书的简介、评分、章节目录。
读进度:某本书读到哪里了。
推荐:根据你的阅读偏好推书。
六个能力,看起来挺完整。但用了一天之后,我发现一个根本性的问题。
官方 Skill 的天花板:裸 API 封装
给它发指令「推荐几本关于产品管理的书」。
它推了三本。翻了翻,其中一本我已经读过,而且写了 34 条笔记——说明我对这本书的内容是真的熟悉的。但 Skill 根本不知道这件事。
它手里有我的书架数据,有我的笔记数据,有我的阅读统计,但这三份数据是各自孤立的。推荐的时候,它没有去交叉检验「这本书用户有没有读过」「用户对哪类内容的笔记密度最高」。
这就是官方 Skill 的天花板:六个能力之间没有智能,只是六个独立的 API 入口。
一位叫「花叔」的独立开发者在网易号文章里把这个问题说得很直接:「书架和笔记是两个数据源,必须交叉。」他因此做了「huashu-weread」,在官方 Skill 之上加了一层工作流编排。
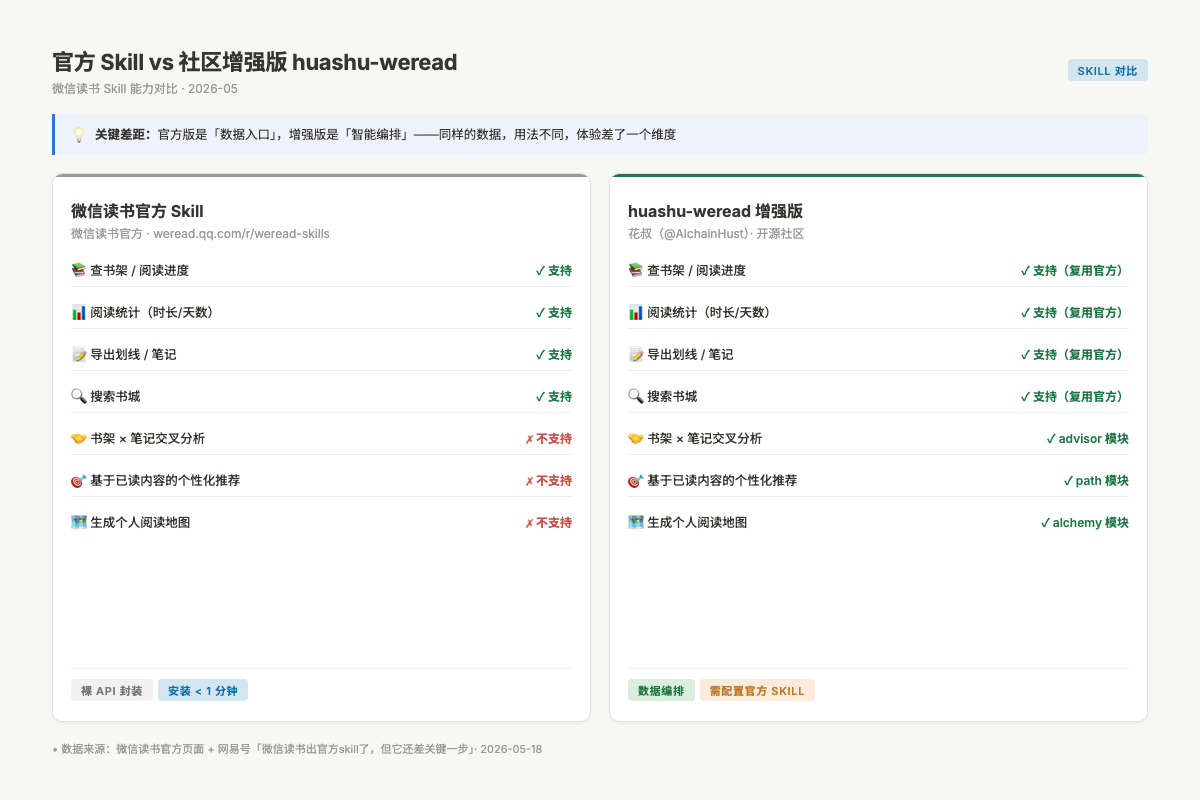
图:官方微信读书 Skill 与社区增强版 huashu-weread 功能对比,核心差距在数据交叉分析层
huashu-weread 加了四个模块:
- advisor(顾问):推荐前先读你的笔记库,找到你真实的知识空白,再推
- path(路径):根据你现有的阅读地图,给出一条成长路线
- alchemy(炼金):跨书整合笔记,把你在不同书里对同一个概念的理解拼起来
- review(回顾):定期生成你的阅读总结,不只是「读了多少时间」
这四个模块的实际使用差异,advisor 最容易感受到。
不装 advisor:「推荐几本产品管理的书」→ Claude 推了三本,其中一本你书架里已经有了,另一本和你读过的内容高度重叠。它不知道。
装了 advisor:Claude 先调微信读书 API 拿你的书架 + 笔记数据,分析你的知识盲区——比如你读了七本讲「产品感知」和「用户研究」的书,笔记密度很高,但对「产品增长」几乎没有划线。推荐会刚好覆盖这个空白。推荐从「猜你喜欢」变成「你缺什么补什么」。
alchemy 的效果更直接,适合有大量跨书笔记的读者。试这类问题:「我在《清醒思考的艺术》和《思考,快与慢》里对『确认偏误』的理解有什么不同,有没有矛盾?」单靠官方 Skill,你拿到的是两份独立的笔记列表,自己对比。有了 alchemy,跨书整合在工具层完成,Claude 直接给你对比分析。
这不是在否定官方 Skill——它解决了「数据打通」这个最难的问题。问题是,打通之后怎么用,官方留了太多空间给社区。
这个案例让我重新理解了 Skill 的能力边界
微信读书 Skill 这件事,让码哥想清楚了一个问题:Skill 的能力不取决于它能调用什么工具,而取决于它能不能做数据编排。
先说 Skill 的基本工作原理。Skill 不是一个外部进程,本质上是一段注入到 Claude 上下文窗口里的 Markdown 指令文件(SKILL.md)。加载分三层:
第一层(始终加载):name + description,约 100 字,Claude 用来判断何时激活这个 Skill
第二层(触发时加载):完整 SKILL.md 指令,推荐 < 500 行
第三层(执行时加载):references/ 目录下的参考文件,按需读取

图:Skill 渐进式加载——元数据层始终在上下文中,指令层触发时注入,资源层按需读取
关键是 allowed-tools 字段。这个字段决定了 Skill 在执行时 Claude 可以用什么工具:
---
name: "weread-assistant"
description: "微信读书阅读数据分析助手,用于查书架、看统计、整理笔记"
allowed-tools: "WebFetch, Bash(curl *)"
---
Bash(curl *) 意味着 Skill 可以发 HTTP 请求——这是数据获取的入口。官方 Skill 的六个功能,本质上都是 curl 打微信读书的接口,拿到 JSON,让 Claude 帮你解读。
这里有个实践中容易踩的坑:上下文预算。
Claude 的单次对话上限是 200K tokens,听起来很宽裕。但这个预算是所有人共享的:SKILL.md 本身、references/ 里加载的参考文件、对话历史、工具调用的输入输出,全部算在内。一个设计粗糙的 Skill,光是指令文件就能吃掉 40-50K tokens,还没开始真正执行任务,预算已经用掉 20%。
官方建议「SKILL.md < 500 行」不是随意定的。按平均每行 20 字、中文字符约 1.5 tokens 估算,500 行大约是 15-20K tokens——这是「Skill 指令」vs「任务执行空间」能维持合理比例的边界值。码哥字节自己的 it-article-producer 这个 Skill,主文件控制在 60 行以内,把写作风格、SEO 策略、配图规范全部拆成独立的 references/ 文件按需加载。这样同一套 Skill 不管写 500 字还是 4000 字的文章,都不会因为上下文压力导致输出质量下滑。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)