
胖头鱼的技术专栏-435 香港活动的数据库多模融合“后遗症”(20260628)
数据库管理435期 2026-06-28
胖头鱼的技术专栏-435 香港活动的数据库多模融合“后遗症”(20260628)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Pro: Database
PostgreSQL ACE
10年+数据库行业经验
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP,ITPUB认证专家
圈内拥有“总监”称号,非著名社恐(社交恐怖分子)
全网同名:胖头鱼的鱼缸
ITPUB:yhw1809
除授权转载并标明出处外,均为“非法”抄袭

大家还记得5月12日我在香港参加金仓的『KING大咖面对面』活动吧。虽然我目前做的基于数据库的AI Agent基础设施架构系统(没错,我又要宣传一下了,网址是https://db4agent.top,大家到Github点点⭐)暂时还没有适配国产数据库,但是在准备PPT的过程中,金仓的麦麦还是给了我相当多的关于金仓多模融合的资料,虽然很多内容都还是“在路上”的状态,但也让我看到了金仓对AI时代数据库多模融合的敏锐判断与实现决心。
面向生产的融合
在我香港演讲的PPT中,引用了金仓数据库可以实现的一条SQL实现多模数据的混合检索: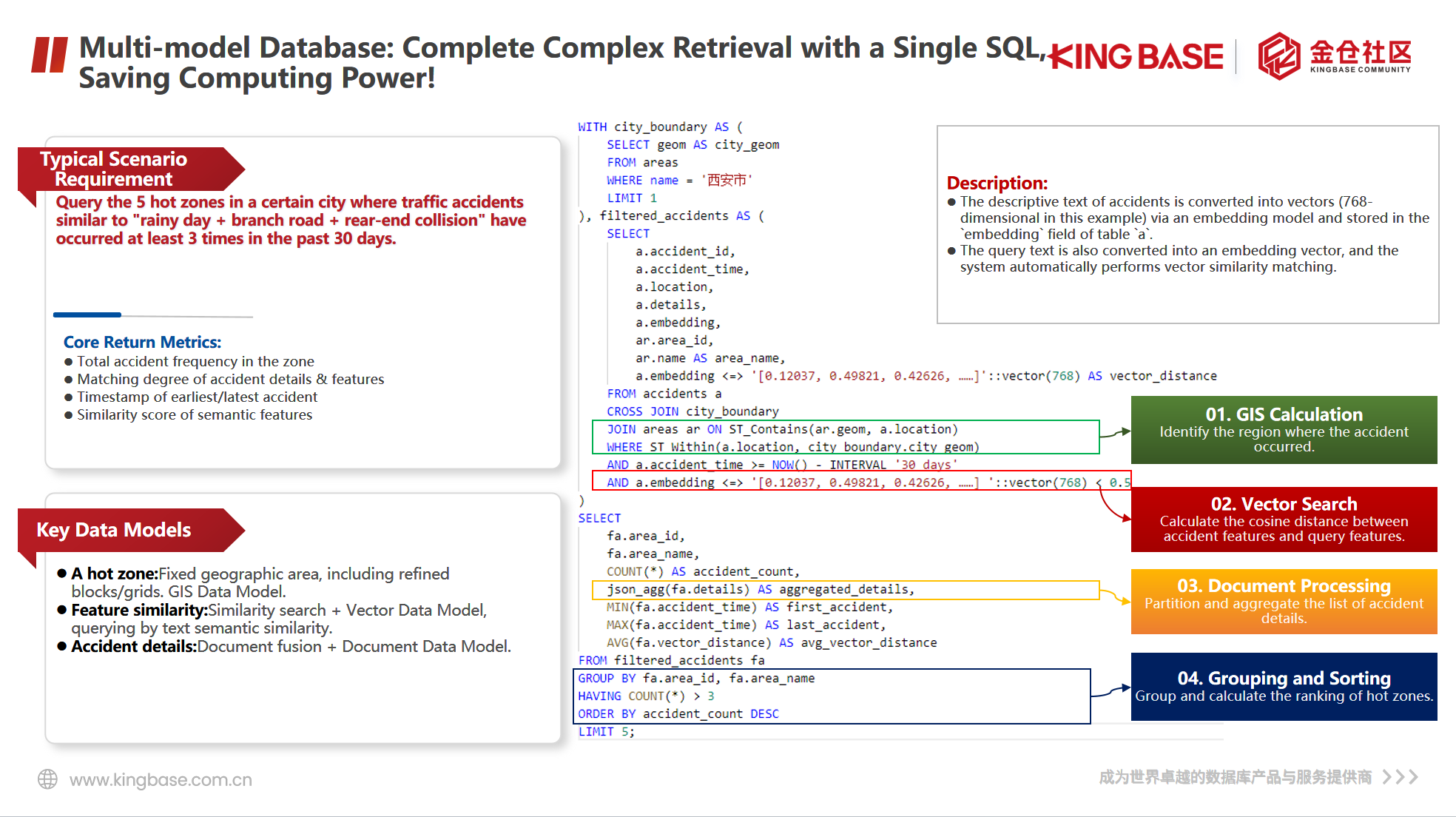
在这条SQL中我们可以看到,金仓数据库除了实现传统关系型标量数据存储以外,还实现了GIS空间数据、向量数据、JSON文档数据的存储。同时数据库还不仅仅存储了这些多模数据,同时还能实现在一条SQL中对多模数据进行混合检索,直接得到传统需要复杂多步骤执行才能得到的数据。
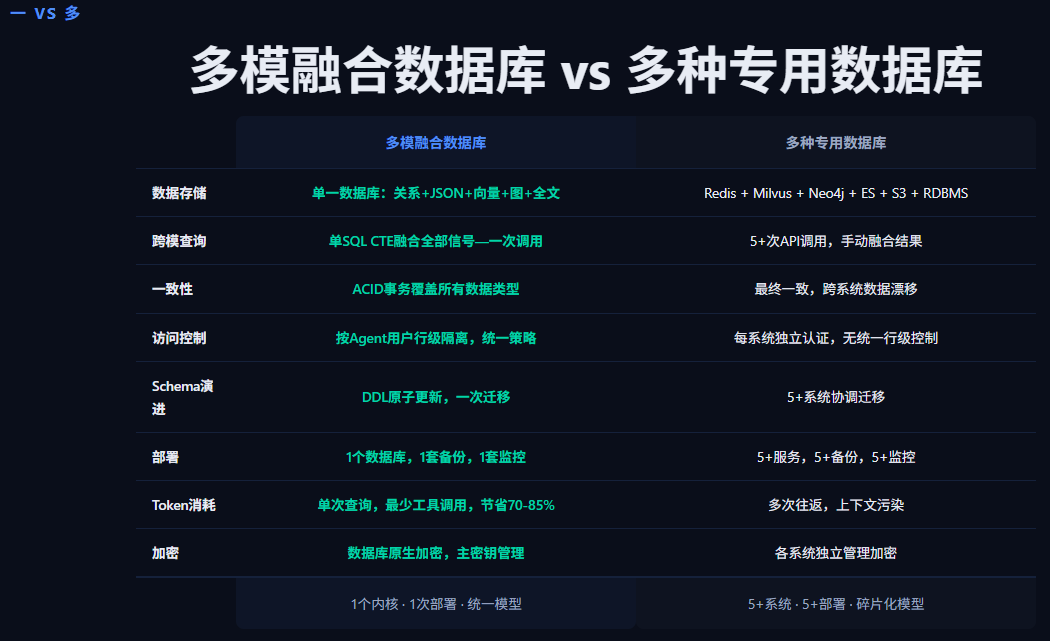
对比传统的数据存储与操作方式,我们往往需要:
- 多种专用数据库:MySQL存关系型数据,MongoDB存JSON数据,Milvus存向量数据,ES提供全文检索能力…
- 多类型数据同步:一个源头的数据,需要将同时将核心数据存放在关系型数据库中,将元数据存在文档数据库中,将文本数据放在全文检索数据库中,将文本向量化存放在向量数据库中…
- 多次操作:获取全部需要数据,需要跨多种数据库完成多次操作,甚至为了更加精确的数据,有些操作还得往复几次
多种专用数据库的架构带来的不仅仅是数据同步的困难与操作的繁琐,还有数据层架构的复杂与维护的困难。另外如果业务发展需要迭代,分散在各个数据库中的设计都需要进行调整,随之带来的可能还有数据同步策略与详细操作内容的变更,这就不仅仅是牵一发而动全身了,而是动一动就触及筋骨。
而多模融合数据库通过统一的存储,统一的使用方式彻底避免了使用多种专用数据库的弊病,不仅减少了数据存储的压力,也有效降低了数据计算的损耗,业务进化迭代的难度也会降低不少。在我做的系统的官网页面中也对两种方式做了对比,我认为多模融合数据库是AI时代数据库必须实现的目标。
面向AI的深层次进化
金仓数据库对AI有着非常深入的理解。
在前面的SQL案例中已经可以看到,金仓数据库已经实现了向量存储能力,向量作为AI时代数据库的核心能力,通过向量匹配搜索支撑起了RAG等AI的核心落地场景。
但是向量也有它固有的问题,向量检索更像是跟高级(多维度)的模糊匹配,当输入内容的嵌入(Embedding)后与多条数据库中的向量记录的匹配评分结果十分接近时,就有可能选择到错误的结果。多模混合检索中,关系型标量数据是可以精确匹配的,因此可以很好的为向量检索作出补充,以得到更加准确的结果。
但是AI Agent的到来,标量+向量的组合往往也是不够的,比如记忆、知识库、工作流的内容,数据条目之间还有关联关系,脱离这层关系的标量+向量组合检索也往往不能满足实际的需求。因此在我做的系统里面,数据库的图数据检索能力也是必需的。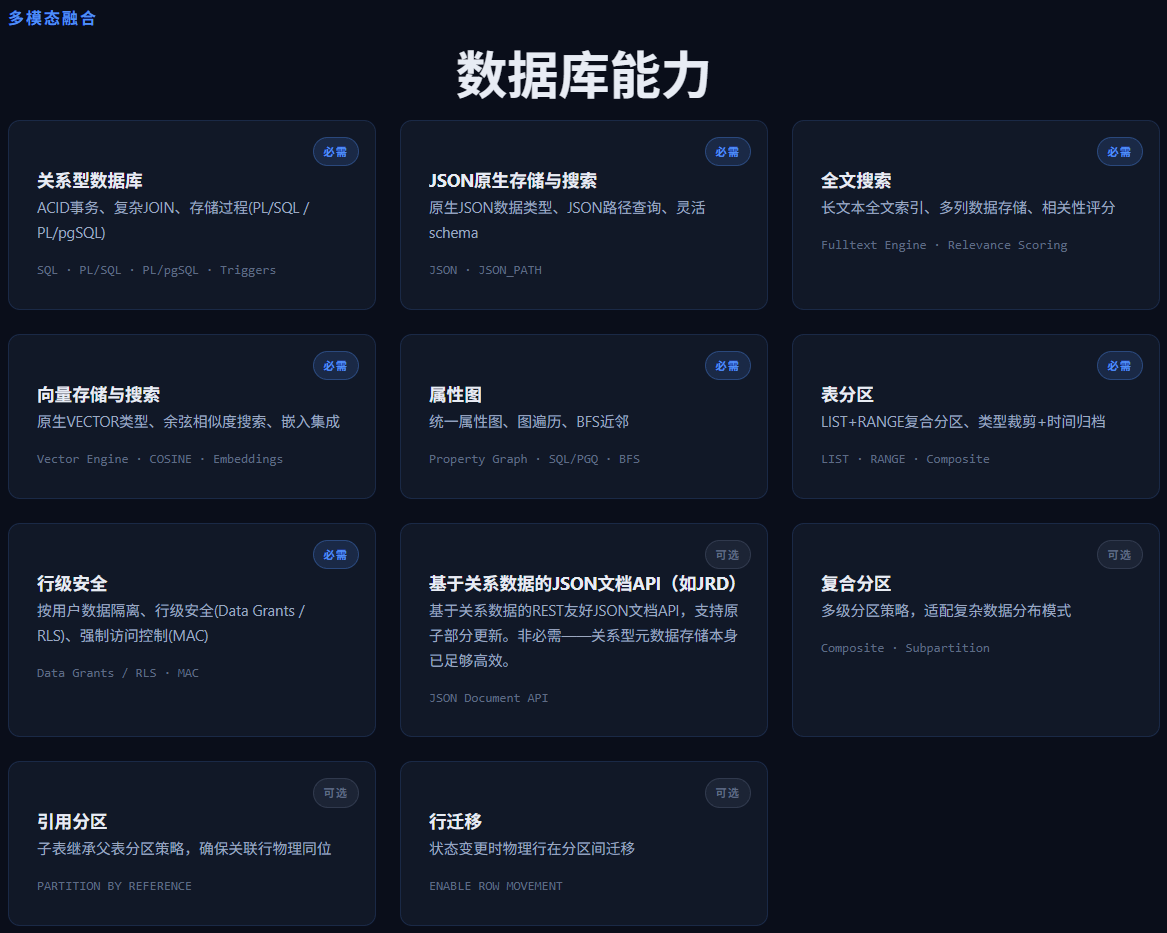
图,Graph,可以将原来孤立存储的数据串联起来,让AI Agent在检索对应数据时,可以额外引入图遍历,从而更加准确的获得有关系的数据条目,过滤掉没有关系的内容,从而在前面的多模混合检索基础之上,进一步降低AI Agent的后分析需求,降低Tokens使用。
从与金仓社区胡总的沟通中,我了解到金仓数据库的图能力即将上线,具体细节还未公布,我也非常期待。
总结
金仓香港互动前后的交流,让我对金仓数据库的多模融合和面向AI的进化有了更加深入全面的了解,后续也期待将我做的基于数据库的AI Agent基础设施架构系统适配金仓数据库。
老规矩,知道写了些啥。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)