
别再把 AI 名词混在一起了:一篇讲透 LLM、Agent、AGI、RAG、Token、MCP 与 Skill
目录
三、Token 是什么:AI 世界里的“文字颗粒”和计费单位
五、Agent 是什么:让模型从“回答问题”走向“完成任务”
很多人刚接触人工智能时,都会遇到一种奇怪的情况:
每个词单独看,好像都能理解;可一旦把它们放在一起,就不知道谁负责思考、谁负责查资料、谁负责调用系统、谁负责执行任务。
有人说大模型就是 Agent,有人把 RAG 叫成知识库,有人认为接入 MCP 之后 AI 就能自动干活,还有人把一份写得很长的提示词称为 Skill。
这些说法不能说完全错误,但都只碰到了局部。
要真正理解今天的 AI 应用,可以先记住一句话:
LLM 是大脑,RAG 是资料室,MCP 是通用接口,Skill 是工作手册,Agent 是负责把这些东西组织起来完成任务的人,Token 是整套系统运转时消耗的计量单位,而 AGI 是人类希望最终抵达的远方。
但这句话仍然只是一个轮廓。
接下来,我们通过一个真实的软件场景,把这些概念逐层拆开。
一、先从一个企业 AI 项目说起
假设我们要给一套人力资源管理系统增加一个功能:
劳动合同智能核验助手。
用户上传一份劳动合同,然后问:
帮我检查这份合同有没有风险,重点核验试用期、工资、工作地点、竞业限制和解除条款。
理想情况下,系统需要完成以下工作:
-
读取合同文件;
-
提取合同中的关键条款;
-
查询公司的合同模板和人事制度;
-
查询相关法律法规;
-
对照员工档案和岗位信息;
-
找出缺失条款、冲突条款和高风险表述;
-
给出修改建议;
-
生成一份结构化核验报告;
-
在用户确认后,把结果写回业务系统。
这显然不是“把问题发给大模型,然后拿回一段文字”这么简单。
因为大模型本身并不知道:
-
这家公司最新的人事制度是什么;
-
数据库里这个员工的岗位是什么;
-
公司使用的是哪一个合同模板;
-
用户上传的文件放在哪里;
-
应该按照怎样的顺序核验;
-
哪些操作可以自动执行;
-
哪些操作必须经过人工确认。
于是,LLM、RAG、Agent、MCP 和 Skill 便有了各自的位置。
二、LLM 是什么:它不是知识库,而是一台语言推理机器
LLM 的全称是:
Large Language Model,大语言模型。
ChatGPT、Claude、Gemini、DeepSeek 等产品背后,都运行着某种大语言模型。
1. LLM 最核心的工作是什么
从最基础的原理看,大语言模型做的事情是:
根据前面已经出现的内容,预测接下来最可能出现的 Token。
例如输入:
中国的首都是
模型会计算后面出现“北京”的概率很高,于是生成“北京”。
如果输入:
请使用 C# 编写一个读取 SQL Server 数据的示例
模型便会根据训练过程中学到的语言模式、代码结构、API 用法和上下文要求,逐步生成代码。
注意,它不是先在内部找到一份完整答案,再把答案复制出来。
它是在一个 Token 接一个 Token 地生成结果。
这也是为什么大模型有时会出现一种非常特别的错误:
语言上非常流畅,逻辑上似乎也说得通,但事实却是错的。
因为它的首要能力是生成“在当前上下文中看起来合理的内容”,而不是像数据库一样保证每个字段都绝对准确。
2. LLM 为什么看起来像是在思考
现代 LLM 通常建立在 Transformer 架构之上。
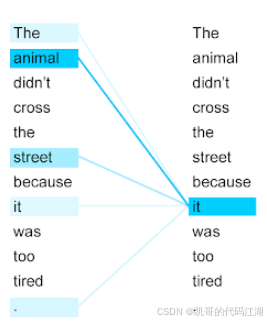
Transformer 中最著名的机制叫做:
Attention,注意力机制。
它可以理解成:模型在处理一句话时,会动态判断哪些内容更值得关注。
例如:
小王把合同交给了张经理,因为他负责合同审核。
模型需要结合上下文判断“他”更可能指的是张经理,而不是小王。
在代码里也是一样:
public void SaveContract(Contract contract)
{
if (contract == null)
throw new ArgumentNullException(nameof(contract));
_repository.Save(contract);
}
当你问模型“这段代码为什么要判断 null”时,它需要把:
-
方法参数;
-
异常类型;
-
后续的 Save 调用;
-
C# 的空引用风险;
联系起来理解。
注意力机制让模型能够在较长的上下文中建立这种关联。
但“能建立关联”不等于“像人一样真正理解世界”。目前的大模型仍然可能:
-
把相关性误认为因果关系;
-
编造不存在的类、方法和政策;
-
忽略隐藏的业务约束;
-
在长任务中忘记早期要求;
-
对错误答案表现得很自信。
所以,LLM 很强,但不应该被神化。
3. LLM 里到底存了什么
大模型训练完成后,会形成数量巨大的参数。
这些参数不是一条条可直接查询的知识记录,而是训练数据中各种语言模式、概念关系和问题解决方式的统计表示。
可以把它想象成一个工作经验非常丰富的人:
他读过很多书,写过很多代码,见过很多合同,能根据经验回答问题;但你不能要求他精确说出某一句话来自哪一页,也不能保证他知道你公司昨天刚发布的新制度。
这就是为什么:
-
LLM 适合负责理解、归纳、推理和生成;
-
数据库适合存储确定的数据;
-
搜索系统适合寻找资料;
-
RAG 适合把外部资料交给模型;
-
Agent 适合组织整个执行过程。
三、Token 是什么:AI 世界里的“文字颗粒”和计费单位
很多人第一次调用大模型 API 时,最容易误解的概念就是 Token。
Token 不是严格意义上的汉字,也不等于英文单词。
它是模型处理文本时使用的基本单位。
1. 一句话是怎样被拆成 Token 的
例如英文:
unbelievable
它可能被拆成:
un
believ
able
也可能根据模型使用的分词器,被拆成其他形式。
中文同样不是永远“一字一个 Token”。常见汉字、标点、数字、英文、代码、空格,都可能采用不同的拆分方式。
例如:
劳动合同智能核验
在不同模型里,可能被拆成不同数量的 Token。
所以,不能简单认为:
10000 个汉字 = 10000 Token
模型不同、分词器不同,最终数量也会不同。
2. 为什么 Token 很重要
Token 主要影响三件事。
第一,影响费用
API 通常按照输入 Token 和输出 Token 收费。
一次请求可能包括:
-
系统提示词;
-
用户问题;
-
历史对话;
-
RAG 检索出来的资料;
-
工具定义;
-
Skill 指令;
-
模型输出;
-
部分模型内部使用的推理 Token。
如果每次都把几十份完整文档、所有历史聊天记录和几百个工具定义塞给模型,费用很快就会增加。
第二,影响上下文窗口
每个模型能够一次处理的 Token 数量是有限的,这个限制叫做:
Context Window,上下文窗口。
假设某个模型的上下文窗口是 128K Token,那么:
系统提示词
+ 历史消息
+ 用户输入
+ 检索资料
+ 工具结果
+ 模型输出
总量都要受这个窗口限制。
上下文并不是越长越好。
材料太多可能造成:
-
重要信息被淹没;
-
模型注意力分散;
-
响应速度下降;
-
成本增加;
-
前后要求互相冲突;
-
模型找不到真正相关的内容。
第三,影响 Agent 的执行效率
Agent 每执行一步,都可能产生新的上下文。
例如合同审核 Agent:
-
读取合同,消耗一次 Token;
-
查询制度,消耗一次 Token;
-
查询法律资料,消耗一次 Token;
-
分析冲突,消耗一次 Token;
-
生成报告,再消耗一次 Token。
如果 Agent 没有良好的上下文管理机制,执行十几步后就可能携带大量无关信息。
所以,AI 工程中有一个非常重要的原则:
不要把所有资料都交给模型,而要在正确的时间,提供完成当前步骤所必需的资料。
这也是 RAG 和 Skill 采用“按需加载”思想的重要原因。
四、RAG 是什么:先查资料,再让模型回答
RAG 的全称是:
Retrieval-Augmented Generation,检索增强生成。
翻译得直白一点就是:
在模型生成答案之前,先从外部知识库中找到相关资料,再把资料交给模型参考。
1. 为什么需要 RAG
假设你直接问大模型:
我们公司销售部员工的试用期工资比例是多少?
大模型不可能凭空知道你公司的内部制度。
即使你之前把制度文件上传过,普通模型也不会自动、永久地把这些内容训练进自己的参数。
这时可以建立一个企业知识库,把以下资料放进去:
-
员工手册;
-
薪酬制度;
-
考勤制度;
-
劳动合同模板;
-
岗位说明书;
-
内部审批流程;
-
常见人事问题;
-
法律法规和司法解释。
用户提问后,系统先检索出与“销售部”“试用期”“工资比例”最相关的资料片段,再把这些片段和用户问题一起发送给 LLM。
模型看到的内容可能类似:
用户问题:
销售部员工的试用期工资比例是多少?
检索到的内部制度:
《薪酬管理办法》第十二条:
员工试用期工资原则上按照转正工资的 80% 执行,
但不得低于当地最低工资标准……
然后模型根据这段资料回答。
这就是最基本的 RAG。
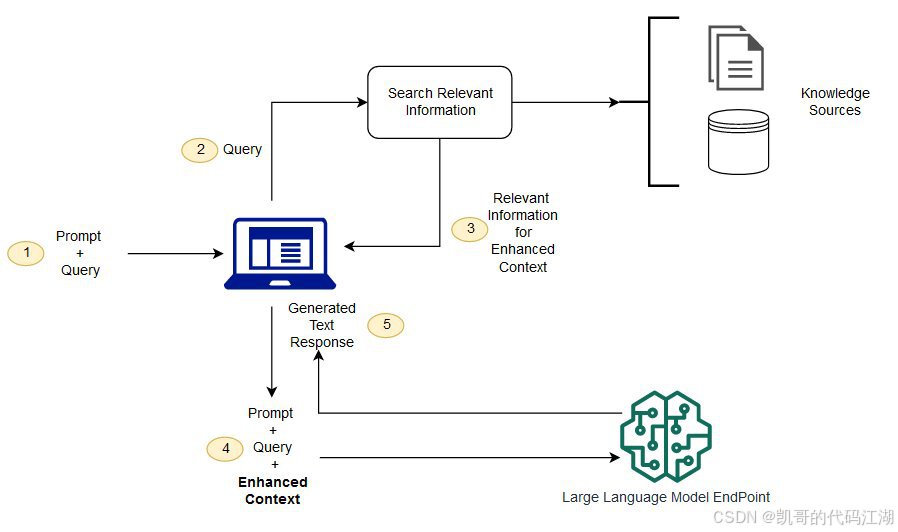
一个较为完整的 RAG 系统通常包含以下步骤。
第一步:文档解析
系统读取:
-
PDF;
-
Word;
-
Excel;
-
网页;
-
数据库记录;
-
图片 OCR 结果;
-
接口返回的数据。
第二步:文档切片
长文档不能不加处理地全部塞给模型,因此需要切成较小的片段,也叫:
Chunk。
例如一本 100 页的员工手册,可以按照标题、章节、条款或一定字数切片。
切片过大,检索结果不够精准。
切片过小,又可能丢失上下文。
因此,切片策略通常要结合文档结构设计,而不是机械地每 500 个字切一次。
第三步:向量化
系统使用 Embedding 模型,把文本转换成一组数字向量。
例如:
“员工试用期工资标准”
会被转换成一个高维向量。
意思相近的文本,其向量距离通常也更接近。
因此,用户即使没有使用完全相同的关键词,也可能搜索到相关内容。
例如用户问:
新员工没转正之前拿多少钱?
系统仍然可能找到:
试用期工资不得低于转正工资的百分之八十。
这叫做语义检索。
第四步:召回
根据用户问题,从知识库中找出若干相关片段。
第五步:重排序
第一次检索出来的内容不一定都很准确,因此可以使用 Reranker 重新计算相关性,把更重要的资料放在前面。
第六步:生成答案
把筛选后的资料交给 LLM,让模型根据资料回答,并尽量标记引用来源。
3. RAG 不等于“把文件上传给模型”
很多所谓的企业知识库,只做了最基础的文件上传和向量检索。
真正高质量的 RAG,还需要处理:
-
文档版本;
-
部门权限;
-
用户数据权限;
-
表格解析;
-
标题层级;
-
关键词检索与语义检索融合;
-
查询改写;
-
多轮检索;
-
重排序;
-
引用溯源;
-
过期资料清理;
-
冲突资料识别;
-
无答案时拒绝回答。
例如公司存在两份薪酬制度:
-
2024 年旧版;
-
2026 年新版。
如果系统没有版本控制,大模型可能同时检索到两份资料,然后给出互相矛盾的答案。
因此,RAG 项目的难点往往不在“接入向量数据库”,而在于企业知识治理。
4. RAG 和微调有什么区别
RAG 和模型微调经常被混为一谈。
可以这样区分:
RAG 解决的是“模型应该知道什么”
例如:
-
公司最新规章制度;
-
产品说明书;
-
客户资料;
-
法律法规;
-
项目代码文档。
这些内容经常变化,适合通过检索动态提供。
微调解决的是“模型应该怎样回答或怎样行动”
例如:
-
固定的分类方式;
-
特定的输出格式;
-
企业统一的客服语气;
-
某类任务的稳定判断模式。
微调会改变模型的行为倾向,但不适合频繁更新事实知识。
对于大多数企业来说,通常应该先做:
提示词工程
→ RAG
→ 工具调用
→ 工作流和评估
只有这些手段仍然无法满足要求时,再考虑微调。
五、Agent 是什么:让模型从“回答问题”走向“完成任务”
Agent 通常翻译为:
智能体。
但“智能体”这个词比较抽象。
更容易理解的说法是:
Agent 是一个能够围绕目标,自主决定下一步做什么,并调用工具完成多步骤任务的 AI 执行系统。
1. 聊天机器人和 Agent 的区别
普通聊天机器人更像一个顾问。
你问:
这份合同有哪些常见风险?
它给你一段建议,任务就结束了。
Agent 更像一个能够操作系统的业务专员。
你说:
帮我核验张三的劳动合同,并生成风险报告。
Agent 可能执行:
-
确认合同文件;
-
从数据库查询张三的员工信息;
-
查询岗位对应的合同模板;
-
从知识库检索相关制度;
-
提取合同条款;
-
对比标准模板;
-
标记风险;
-
生成报告;
-
请求用户确认;
-
把报告写入合同档案。
这就是从“回答问题”变成“完成任务”。
2. Agent 的基本组成
一个相对完整的 Agent,通常包含以下部分。
模型
负责理解、推理、决策和生成。
也就是 LLM。
目标
例如:
在不修改原始合同的情况下,完成合同风险核验,并生成结构化报告。
指令
说明 Agent 应该遵守哪些规则。
例如:
-
不允许伪造法律条文;
-
必须标明资料来源;
-
涉及解除、赔偿等高风险判断时必须提示人工复核;
-
未经用户确认,不得修改数据库;
-
不得读取当前组织之外的员工数据。
工具
例如:
-
读取 Word 和 PDF;
-
查询 SQL Server;
-
调用合同系统接口;
-
查询知识库;
-
生成报告;
-
发送邮件。
状态和记忆
记录当前任务进行到哪一步、已经获得哪些结果、哪些问题还没有解决。
执行循环
Agent 的核心通常是一个循环:
观察当前状态
→ 判断下一步
→ 选择工具
→ 执行工具
→ 读取结果
→ 更新状态
→ 决定继续还是结束
安全边界
控制哪些操作可以自动执行,哪些操作必须获得确认。
3. Agent 不等于工作流
工作流和 Agent 也有区别。
传统工作流是提前写死的:
上传合同
→ 提取内容
→ 查询模板
→ 生成报告
无论遇到什么合同,都按照固定顺序执行。
Agent 则可以根据情况动态调整。
例如:
-
如果合同是扫描件,先调用 OCR;
-
如果合同缺少员工编号,通过姓名和手机号查询;
-
如果检索到两份有效制度,暂停任务并提示冲突;
-
如果合同包含竞业限制,再额外查询岗位涉密等级;
-
如果只是普通实习协议,切换到另一套核验流程。
但是,不应该因此认为所有业务都要做成完全自主的 Agent。
在企业系统中,更稳妥的方式往往是:
确定的步骤使用工作流,不确定的判断交给 Agent。
例如“保存数据前必须经过审批”应该写死,而不是让模型自己判断要不要审批。
六、MCP 是什么:AI 调用外部系统的通用接口
MCP 的全称是:
Model Context Protocol,模型上下文协议。
它是一套开放协议,用于规范 AI 应用如何连接外部数据和工具。
Anthropic 曾经用一个很形象的比喻解释 MCP:
MCP 类似于 AI 应用领域的 USB-C 接口。
在 USB-C 出现以前,不同设备可能使用不同的接口和线缆。
MCP 希望解决的问题也类似:
-
Claude 怎样连接 GitHub;
-
Codex 怎样连接数据库;
-
VS Code 中的 Agent 怎样查询官方文档;
-
企业 AI 怎样调用内部人事系统;
-
不同模型怎样复用同一套工具。
1. 没有 MCP 时会怎样
假设我们需要让 AI:
-
查询员工信息;
-
查询合同记录;
-
创建合同审核任务。
传统方式是直接为某个模型编写函数调用代码:
GetEmployeeById()
GetContractById()
CreateContractReviewTask()
换一个 AI 平台,可能又要重新适配一套工具描述、认证方式和通信机制。
工具越来越多以后,维护成本会越来越高。
MCP 提供了相对统一的发现和调用方式。
MCP Server 可以向 AI 暴露:
-
Tools:可以执行的操作;
-
Resources:可以读取的数据或内容;
-
Prompts:预定义的交互模板。
AI 客户端连接 MCP Server 后,就能知道:
-
有哪些工具;
-
每个工具有什么作用;
-
需要哪些参数;
-
返回什么结果;
-
当前是否允许调用。
2. MCP 的基本结构
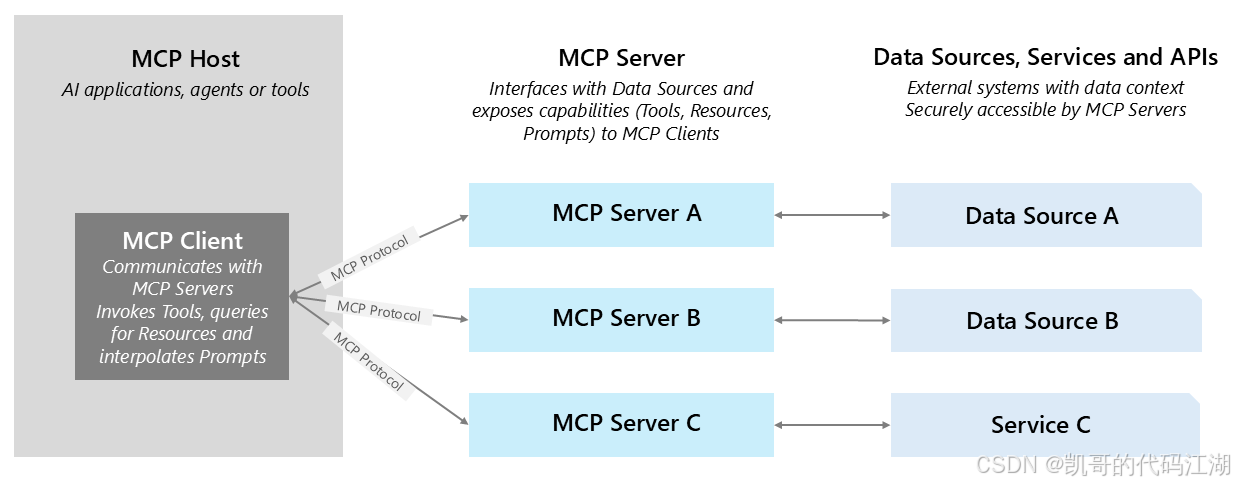
MCP 架构可以简单理解为三部分。
MCP Host
承载 AI Agent 的应用。
例如:
-
Claude Code;
-
Codex;
-
VS Code;
-
Cursor;
-
自己开发的 AI 客户端。
MCP Client
负责在 Host 内部与 MCP Server 通信。
MCP Server
对外暴露具体能力。
例如:
SQL MCP Server
GitHub MCP Server
Microsoft Learn MCP Server
企业人力资源 MCP Server
呼叫中心 MCP Server
假设我们开发一个 HR MCP Server,可以提供:
get_employee
get_contract
get_department_policy
create_review_record
update_contract_status
Agent 不需要知道后台到底是:
-
SQL Server;
-
ASMX;
-
ASP.NET Web API;
-
微服务;
-
第三方接口。
它只需要按照 MCP 工具的定义进行调用。
3. MCP 和 API 有什么区别
MCP 并不是要消灭 API。
很多 MCP Server 的底层仍然在调用 API。
区别在于:
API 面向程序员
程序员需要了解:
-
接口地址;
-
HTTP 方法;
-
请求参数;
-
认证方式;
-
返回结构;
-
错误码。
MCP 面向 AI Agent
MCP Server 会把能力包装成模型容易理解和调用的工具。
例如传统接口:
POST /api/contracts/review
MCP 中可以暴露为:
create_contract_review
用途:
为指定合同创建审核任务。
参数:
contract_id
review_type
operator_id
因此,可以把 MCP 看成:
建立在现有 API 和数据能力之上的 AI 工具适配层。
4. 接了 MCP,AI 就会变聪明吗
不会。
MCP 解决的是“怎么连接工具”,不是“怎么正确完成任务”。
给一个员工配上数据库账号,并不意味着他立刻就懂你的业务。
同样,Agent 能调用 SQL MCP Server,也不意味着它知道:
-
哪些表可以查询;
-
哪些字段属于隐私数据;
-
什么情况下可以更新;
-
如何避免全表修改;
-
如何处理事务;
-
如何遵守企业审批流程。
这些规则需要由权限系统、业务代码、Agent 指令和 Skill 共同约束。
七、Skill 是什么:教 Agent 按你的方式做事
Skill 可以翻译为:
技能。
在当前的 Agent 生态中,Skill 通常指一种可复用的任务能力包。
一个 Skill 不只是短提示词,而是一套可以被 Agent 按需加载的工作说明。
它通常包含:
contract-review/
├── SKILL.md
├── references/
│ ├── risk-levels.md
│ └── output-format.md
├── scripts/
│ └── validate_report.py
└── templates/
└── review-report.docx
其中最核心的是:
SKILL.md
1. SKILL.md 里写什么
一个简单的 Skill 可能是:
---
name: labor-contract-review
description: 用于审核中国大陆劳动合同中的试用期、薪资、工时、
工作地点、解除、保密和竞业限制条款。
---
# 劳动合同审核流程
1. 读取合同全文。
2. 提取合同主体、期限、岗位、薪资和工作地点。
3. 查询当前有效的公司合同模板。
4. 查询与合同条款相关的知识库内容。
5. 按照低、中、高三个等级标记风险。
6. 每一项风险必须附带原文、判断依据和修改建议。
7. 无法确认时标记“需人工复核”,不得自行编造结论。
8. 未经用户确认,不得修改合同或写入正式档案。
Agent 遇到劳动合同审核任务时,加载这个 Skill,然后按照其中的流程执行。
2. Skill 和普通提示词有什么不同
普通提示词通常是一次性的。
每次都要对 AI 说:
请先读取合同,再查询制度,然后按照三个等级判断风险,输出时必须包括……
Skill 则把这些要求保存成一个可复用的能力包。
以后只需要说:
使用劳动合同审核 Skill 检查这份合同。
更重要的是,Skill 不一定只有文字。
它还可以包含:
-
脚本;
-
模板;
-
示例;
-
检查清单;
-
参考资料;
-
测试数据;
-
输出格式;
-
工具使用说明。
因此,Skill 更像新员工入职时拿到的:
标准操作规程、业务手册、模板和工具箱。
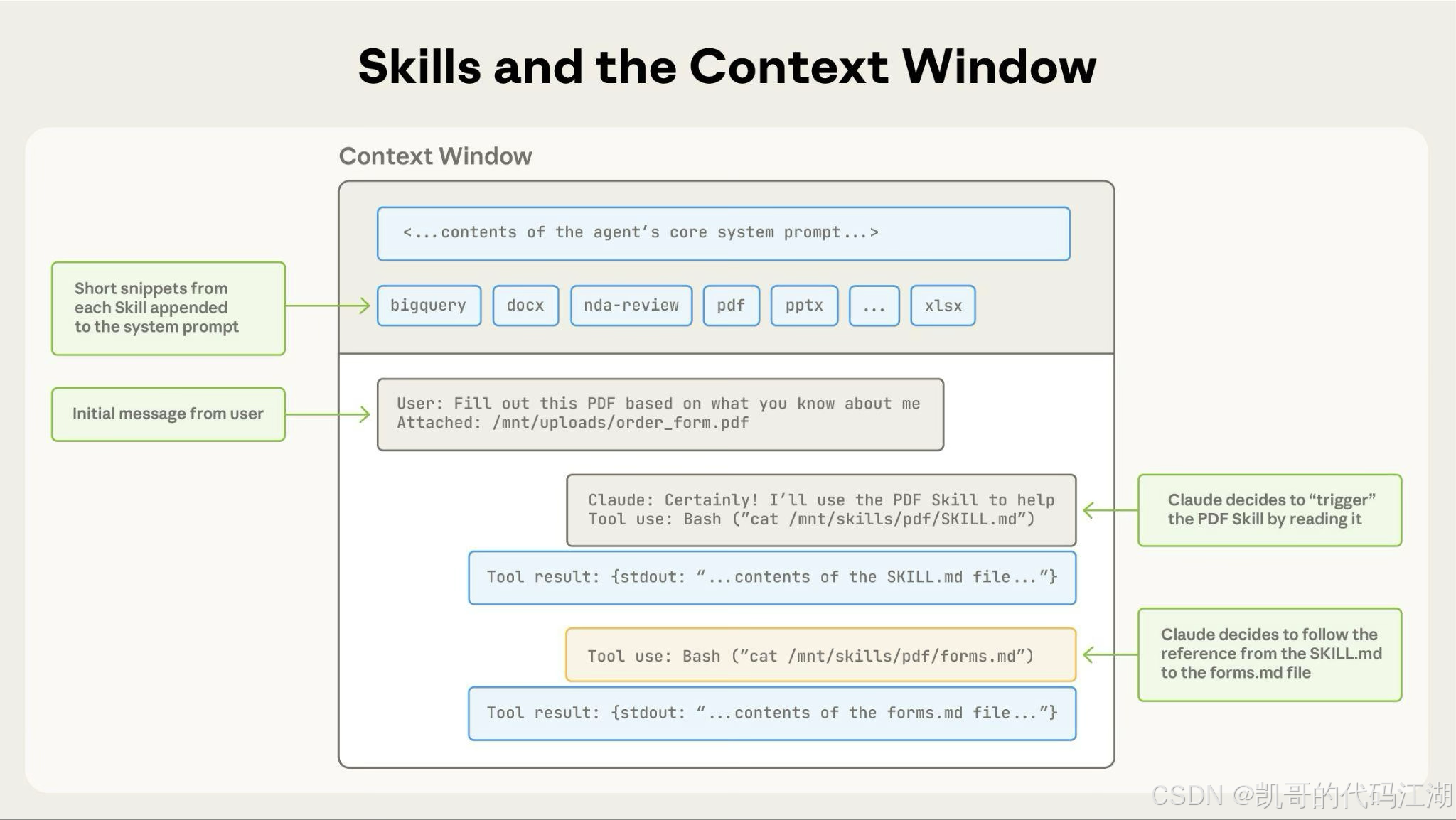
Skill 的一个重要思想叫:
Progressive Disclosure,渐进式披露。
Agent 启动时,不会把所有 Skill 的完整内容都装进上下文。
它通常分为几个阶段:
-
先读取 Skill 的名称和简介;
-
判断当前任务是否匹配;
-
匹配后再加载完整的 SKILL.md;
-
执行过程中,按需要读取脚本、模板和参考文件。
这可以避免把几十个甚至几百个 Skill 全部塞进上下文,浪费 Token。
例如系统中存在:
-
劳动合同审核 Skill;
-
薪资异常分析 Skill;
-
排班检查 Skill;
-
客户投诉分类 Skill;
-
SQL 性能优化 Skill;
-
Web 系统测试 Skill。
用户只是让 Agent 检查劳动合同,那么没有必要加载其他 Skill 的完整说明。
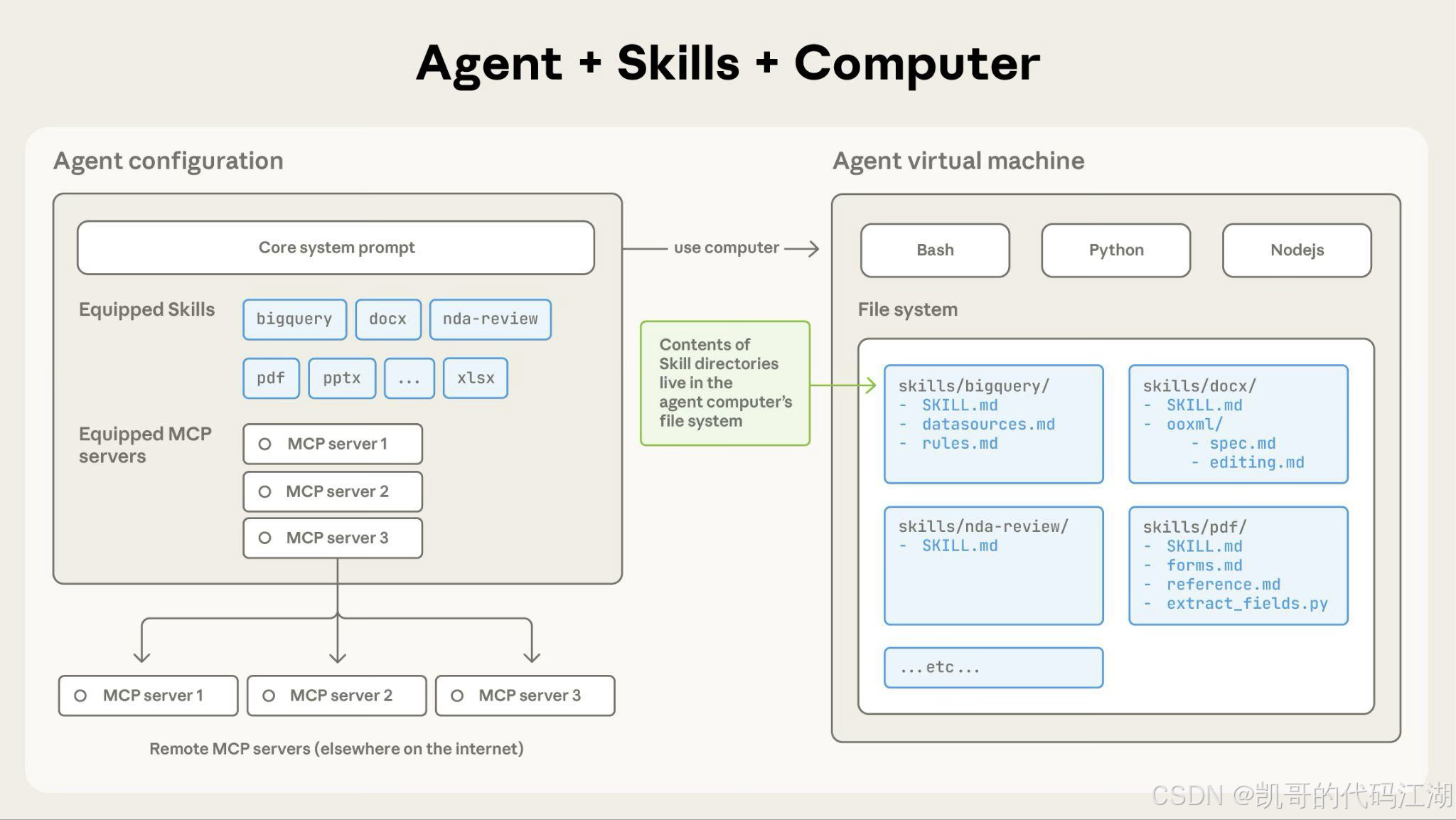
这是目前最容易混淆的一组概念。
可以用一句话区分:
MCP 解决“Agent 能使用什么工具”,Skill 解决“Agent 应该怎样使用这些工具完成任务”。
例如:
MCP 提供能力
get_employee
get_contract
search_policy
create_review_record
Skill 规定流程
先查询员工信息;
再读取合同;
然后检索制度;
发现高风险条款时必须引用依据;
生成报告后先让用户确认;
确认后才能创建审核记录。
MCP 像企业给员工开放的业务系统。
Skill 像企业给员工制定的岗位操作规范。
只有 MCP,没有 Skill,Agent 虽然会操作工具,但可能操作顺序混乱。
只有 Skill,没有 MCP,Agent知道应该做什么,却无法真正访问数据库和业务系统。
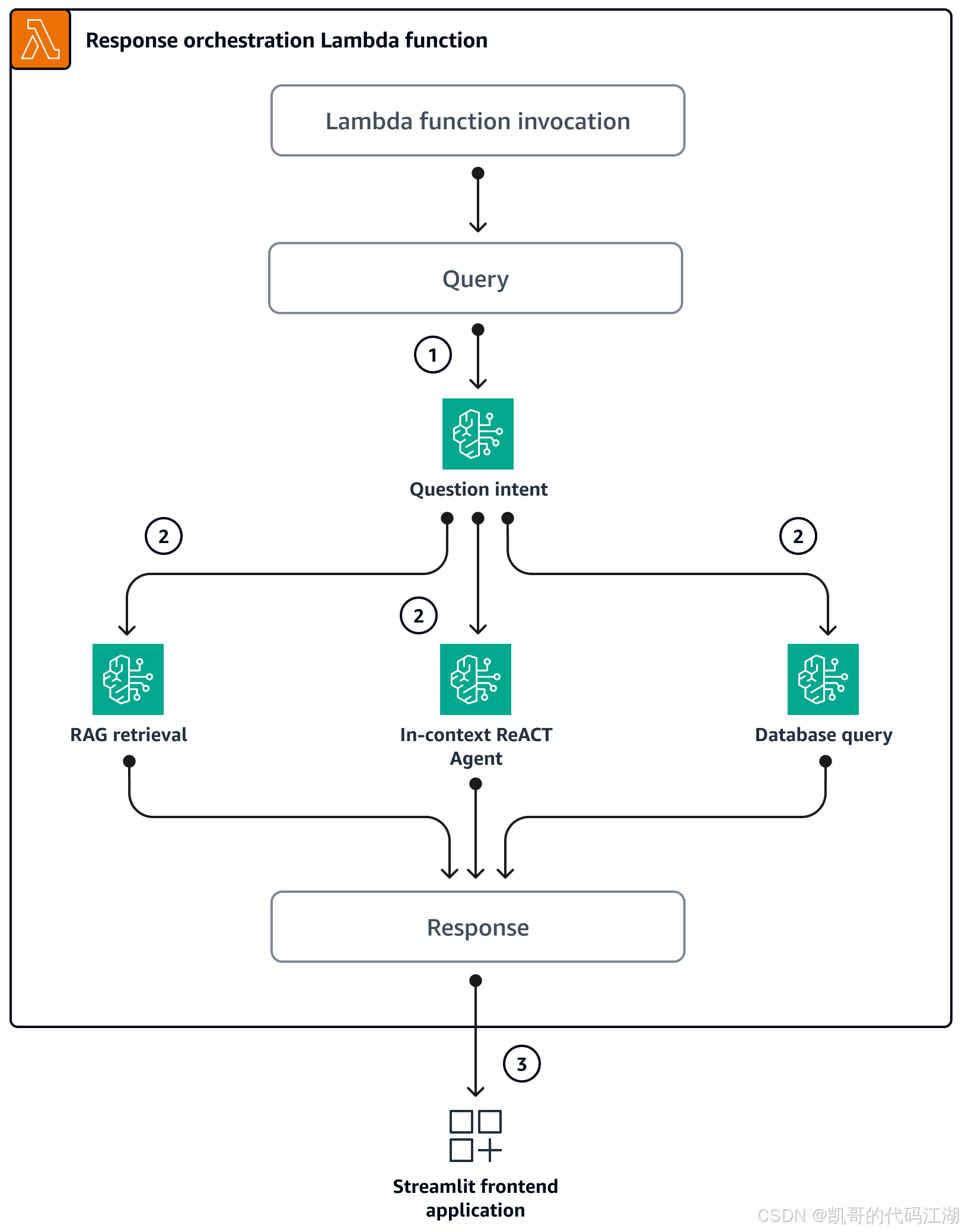
现在回到劳动合同智能核验助手。
整个执行链路可以表示为:
用户提出目标
↓
Agent 理解目标并制定步骤
↓
加载“劳动合同审核 Skill”
↓
通过 MCP 读取合同、员工信息和企业制度
↓
通过 RAG 检索相关法规和知识片段
↓
LLM 对资料进行理解、比较、推理和生成
↓
输出风险报告并请求用户确认
↓
通过 MCP 把确认后的结果写回系统
在这条链路中:
LLM
负责语言理解、信息提取、推理和生成。
Agent
负责围绕目标组织执行过程。
Skill
告诉 Agent 按照怎样的专业流程工作。
MCP
让 Agent 能够访问数据库、文件、GitHub、浏览器和业务系统。
RAG
在需要专业知识时,动态寻找相关资料。
Token
是模型读取资料、调用工具和生成结果时使用的文本计量单位。
AGI
不属于这个项目中的某个具体技术组件,而是对未来更通用人工智能能力的一种目标描述。
十、AGI 是什么:它不是某个模型版本号
AGI 的全称是:
Artificial General Intelligence,通用人工智能。
它通常指能够在广泛任务上学习、推理、适应和解决问题的人工智能系统,而不是只擅长某一个固定领域。
例如:
-
围棋 AI 很强,但主要擅长围棋;
-
OCR 系统擅长识别文字;
-
推荐算法擅长预测用户兴趣;
-
语音识别系统擅长把声音转换成文字。
这些属于专用人工智能。
理想中的 AGI 则应该能够跨领域迁移能力。
例如它第一次进入一家企业后,能够:
-
阅读公司制度;
-
理解业务系统;
-
学习岗位职责;
-
与员工沟通;
-
分析数据;
-
编写程序;
-
发现流程问题;
-
制定改进方案;
-
在新情况中继续学习。
这已经不只是“回答几个问题”,而是广泛的认知和适应能力。
1. AGI 没有全行业统一的判定标准
这是理解 AGI 时非常重要的一点。
不同机构对 AGI 的定义并不完全一致。
有人强调:
-
是否达到普通人的综合能力;
有人强调:
-
能否完成大多数具有经济价值的工作;
有人强调:
-
能否跨领域学习和迁移;
还有人把:
-
能力范围;
-
任务表现;
-
自主程度;
-
安全风险;
拆开分别评估。
因此,“AGI 是否已经到来”不是一个简单的真假问题。
今天的大模型已经能在编程、写作、数学、图像理解和工具调用等多个领域完成复杂任务,但它们仍然存在明显缺陷:
-
长时间自主执行不稳定;
-
对现实世界缺乏持续可靠的理解;
-
容易受到错误上下文影响;
-
不能稳定判断自身答案是否正确;
-
缺乏人类式的长期经验积累;
-
在陌生环境中仍需要大量规则和工具支持。
所以,更严谨的说法是:
当前系统正在展现越来越广泛的通用能力,但是否已经构成 AGI,仍然没有公认结论。
十一、目前值得推荐的 MCP
不要看到 MCP 市场里有几千个服务,就全部安装。
MCP 越多,不一定越强。
工具过多会增加:
-
Token 消耗;
-
工具选择难度;
-
权限风险;
-
配置复杂度;
-
提示词注入风险;
-
错误调用概率。
对于开发者来说,下面几类更实用。
1. Microsoft Learn MCP
适合:
-
C#;
-
.NET;
-
ASP.NET;
-
WinForms;
-
SQL Server;
-
Azure;
-
Visual Studio。
它可以让编码 Agent 直接查询 Microsoft 官方文档和代码示例。
当你询问:
.NET Framework 4.5.2 能否使用某个 API?
或者:
SQL Server 某个语法在旧版本是否支持?
Agent 可以先查官方资料,再给出答案,减少模型使用过期资料或编造 API 的概率。
对于长期使用微软技术栈的开发者,这是优先级非常高的 MCP。
2. GitHub MCP Server
适合:
-
查询代码仓库;
-
阅读提交记录;
-
管理 Issue;
-
分析 Pull Request;
-
查看 GitHub Actions;
-
进行代码审查;
-
查询安全告警。
它让 Agent 不再只是读取本地代码,而是能够理解整个 GitHub 开发流程。
建议刚开始只开放:
-
仓库读取;
-
Issue 读取;
-
Pull Request 读取;
-
Actions 查看。
创建分支、修改 Issue、合并 PR 等写操作,可以在熟悉后再逐步开放。
3. Context7
Context7 主要解决一个非常现实的问题:
模型训练数据中的技术文档可能已经过时。
例如你问某个新版框架的 API,模型可能按照旧版本生成代码。
Context7 可以把特定版本的文档和代码示例动态加载进上下文。
它特别适合:
-
JavaScript 前端框架;
-
Python 库;
-
Node.js 生态;
-
云服务 SDK;
-
更新较快的开源项目。
不过,对于 .NET、SQL Server 等微软技术,优先使用 Microsoft Learn MCP;对于跨生态的第三方库,再使用 Context7。
4. SQL MCP Server
微软已经提供了面向 SQL 数据库的 MCP Server 方案,可以通过受控实体、RBAC 权限和结构化工具,让 Agent 访问数据库。
它适合:
-
查询业务数据;
-
生成统计结果;
-
分析异常记录;
-
创建受控的数据操作能力。
但数据库 MCP 的权限必须非常谨慎。
推荐按照以下顺序开放:
只读查询
→ 指定视图查询
→ 指定存储过程调用
→ 受控新增
→ 受控修改
不建议一开始就给 Agent:
-
任意 SQL 执行权限;
-
删除权限;
-
表结构修改权限;
-
数据库管理员账号。
在旧系统中,更稳妥的方式不是直接让 Agent 写 SQL,而是通过存储过程或业务接口暴露有限能力。
例如只开放:
get_employee_summary
get_contract_summary
create_review_draft
而不是开放:
execute_any_sql
5. Playwright MCP
Playwright MCP 可以让 Agent 操作浏览器,例如:
-
打开网页;
-
点击按钮;
-
填写表单;
-
测试登录;
-
检查页面内容;
-
自动执行 Web 端回归测试。
它适合:
-
ASP.NET Web 系统;
-
Vue、React 项目;
-
后台管理系统;
-
自动化测试;
-
接口联调后的端到端验证。
不过,对于高频编码任务,也可以考虑 Playwright CLI 配合 Skill。因为大量 MCP 工具描述和网页可访问性树会占用较多上下文,而 CLI 命令通常更加紧凑。
6. OpenAI Developer Docs MCP
当项目需要接入:
-
OpenAI API;
-
Responses API;
-
Agents SDK;
-
Codex;
-
工具调用;
-
结构化输出;
可以使用 OpenAI 官方开发文档 MCP。
它的价值与 Microsoft Learn MCP 类似:
让 Agent 在编写代码前,先查看当前版本的官方文档。
十二、目前值得推荐的 Skill
Skill 的推荐逻辑和 MCP 不同。
MCP 更适合选择可靠的官方服务。
Skill 则应该分成两类:
-
通用 Skill;
-
与自己业务深度结合的自定义 Skill。
1. Skill Creator
用于创建和改进其他 Skill。
它会帮助你设计:
-
Skill 名称;
-
触发条件;
-
SKILL.md;
-
操作步骤;
-
示例;
-
参考资料;
-
验证方法。
如果准备系统化使用 Agent Skills,Skill Creator 应该是最先研究的 Skill。
2. MCP Builder
用于设计和开发 MCP Server。
它可以帮助梳理:
-
应该暴露哪些工具;
-
参数怎样设计;
-
返回值怎样组织;
-
工具描述怎样写;
-
权限怎样限制;
-
错误怎样返回。
例如你准备给呼叫中心系统开发 MCP,可以让它协助设计:
get_agent_status
get_call_record
get_transcript
create_follow_up_task
3. Web App Testing
用于 Web 应用测试。
它可以与 Playwright 配合,形成较完整的测试流程:
-
读取需求;
-
确定测试场景;
-
启动应用;
-
操作页面;
-
检查结果;
-
记录失败步骤;
-
生成测试报告。
4. PDF、DOCX、XLSX、PPTX Skills
这些文档类 Skill 很实用。
它们可以处理:
-
PDF 内容提取与报告生成;
-
Word 文档编辑;
-
Excel 数据分析和图表;
-
PowerPoint 演示文稿生成。
企业 AI 落地中,大量任务最终都需要输出正式文件,因此文档 Skill 的价值往往比一些看起来很酷的自动化功能更高。
5. Frontend Design
适合:
-
Web 页面;
-
Vue;
-
React;
-
后台管理系统;
-
落地页;
-
移动端页面原型。
它可以帮助 Agent 不只是“把功能写出来”,而是按照更完整的设计原则处理布局、层级、交互和视觉一致性。
十三、真正值得开发者投入的,是自己的 Skill
公共 Skill 可以帮助你快速入门,但长期价值最高的通常不是下载几十个别人的 Skill,而是把自己的业务经验写成 Skill。
对于企业软件开发,可以考虑建立下面这些自定义 Skill。
1. legacy-winforms-maintainer
专门约束 AI 修改老旧 WinForms 项目:
-
使用现有 .NET Framework 版本;
-
不随意引入不兼容语法;
-
不擅自升级第三方组件;
-
保持现有分层结构;
-
修改 UI 时考虑 Invoke 和线程安全;
-
修改前分析调用链;
-
输出修改范围和回滚方案。
2. sqlserver-safe-change
用于 SQL Server 安全变更:
-
先写 SELECT 验证范围;
-
再写事务更新语句;
-
更新前备份目标数据;
-
必须检查影响行数;
-
禁止无 WHERE 的 UPDATE 和 DELETE;
-
输出回滚 SQL;
-
兼容项目当前 SQL Server 版本。
3. asmx-api-integration
用于维护旧版 ASMX 接口:
-
保持现有 method 分发方式;
-
兼容 .NET Framework;
-
统一返回结构;
-
处理参数校验;
-
记录异常;
-
避免破坏旧客户端;
-
新功能优先保持向后兼容。
4. call-center-integration
用于呼叫中心对接:
-
区分 HTTP、WebSocket、SSE 和消息队列;
-
明确事件顺序;
-
设计重连机制;
-
避免重复事件;
-
使用 CallId 保证幂等;
-
记录坐席和通话状态;
-
给出异常恢复策略。
5. project-delivery-review
要求 Agent 每次完成代码修改后,必须输出:
本次需求
读取的文件
修改的文件
核心修改
未修改范围
兼容性风险
验证步骤
回滚方式
后续建议
这类 Skill 才是真正把个人开发经验变成 AI 可复用能力的过程。
过去,一个高级程序员的经验主要存在于脑子里。
未来,这些经验会逐渐变成:
-
AGENTS.md;
-
项目规范;
-
Skill;
-
自动验证脚本;
-
测试用例;
-
MCP 工具;
-
企业知识库。
这也是 AI 编程从“模型替你写代码”,走向“团队工程能力数字化”的关键一步。
MCP 和 Skill 都可能获得真实系统权限,因此不能把它们当成普通插件。
尤其要警惕以下情况:
-
来源不明的 Skill;
-
要求读取环境变量的脚本;
-
要求上传 API Key 的工具;
-
可以执行任意 Shell 命令的 MCP;
-
使用管理员账号连接数据库;
-
能访问已登录浏览器的自动化工具;
-
自动执行删除、支付、发布和合并操作;
-
工具描述与实际代码行为不一致。
建议遵循几个原则:
第一,优先官方来源
优先使用:
-
官方 GitHub 组织;
-
官方文档;
-
官方 MCP Registry;
-
可以审查源代码的项目。
第二,最小权限
GitHub Token、数据库账号、云服务密钥都只开放完成任务所需的最小权限。
第三,读写分离
查询类 Agent 和执行类 Agent 最好使用不同权限。
第四,高风险操作必须确认
删除、更新、发邮件、发布、支付、合并代码、执行生产 SQL,都应该增加人工确认。
第五,审查 SKILL.md 和脚本
Skill 不只是说明文档。
自然语言指令同样会影响 Agent 的实际行为,因此下载 Skill 后要像审查代码一样审查:
-
触发条件;
-
工具权限;
-
外部请求;
-
脚本内容;
-
文件访问范围;
-
是否读取密钥;
-
是否存在隐藏指令。
十五、小白应该按照什么顺序学习
这些概念不应该一起硬学。
更合理的顺序是:
第一阶段:理解 LLM 和 Token
先学会:
-
模型为什么会生成答案;
-
什么是上下文;
-
为什么会产生幻觉;
-
Token 如何影响成本和长度;
-
怎样写清晰的提示词。
第二阶段:学习 RAG
尝试让模型回答自己的资料。
例如:
-
公司制度;
-
项目文档;
-
产品说明;
-
代码规范。
第三阶段:学习工具调用
让模型能够调用一个简单函数,例如:
查询天气
查询员工
查询订单
计算价格
第四阶段:学习 Agent
把多个工具组织成多步骤任务。
第五阶段:学习 MCP
把工具标准化,让不同 Agent 客户端复用。
第六阶段:学习 Skill
把专业流程、业务知识和工程规范沉淀下来。
第七阶段:建设评估和安全体系
测试 Agent 是否:
-
调用了正确工具;
-
使用了正确资料;
-
遵守了权限;
-
输出了正确格式;
-
遇到不确定情况时停止;
-
没有擅自执行高风险操作。
十六、结语:模型不是产品,系统才是
很多企业在做 AI 时,首先想到的是:
选哪个大模型?
但真正决定项目能否落地的,往往不只是模型能力。
一套可靠的企业 AI 系统,需要同时具备:
LLM 的理解和推理能力
+ RAG 的企业知识
+ MCP 的系统连接能力
+ Skill 的专业工作流程
+ Agent 的任务组织能力
+ 权限、评估、日志和人工确认
模型更像发动机。
只有发动机,没有方向盘、刹车、导航、车身和驾驶规则,不能称为一辆真正能够上路的汽车。
同样:
-
LLM 不等于 Agent;
-
Agent 不等于 AGI;
-
RAG 不等于训练模型;
-
MCP 不等于业务流程;
-
Skill 不等于一个万能提示词;
-
上下文越长也不等于效果越好。
未来真正有竞争力的人,不一定是最会背 AI 名词的人,而是能够把业务、数据、模型、工具、安全和工程流程组合起来的人。
对于软件开发者来说,AI 时代最值得积累的资产,也许不再只是某一段代码,而是:
你能否把多年积累的业务经验和工程方法,变成模型能够读取、Agent 能够执行、团队能够复用的知识系统。
当 LLM 有了可靠的知识,有了可调用的工具,有了明确的工作规范,也有了必要的安全边界,它才不再只是一个“会聊天的模型”。
它开始成为真正能够参与业务的软件系统。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)