
人大和微软开源Arbor,一棵假设树突破自主科研新高度
科学研究是一个反复试错的过程。研究者试一个方向,看结果,把教训带进下一次尝试。
能不能让 AI Agent 自动跑完这个循环,有记忆,能积累经验,让每次实验都变成可积累、可复盘的研究进展?
像 OpenAI 的 Codex、Anthropic 的 Claude Code 这类编码 Agent,已经能在真实代码库里跑几十个小时干活也没问题,但拉长到研究周期,单点能干并不等于整体能积累。
一个 Agent 能不能把上一次失败的经验带到下一次尝试里,比它能跑多久更要紧。
中国人民大学高瓴人工智能学院和 Microsoft Research 的研究者交出的答案是 Arbor。

它把每次实验挂到一棵不断生长的假设树上,让策略、代码、证据和教训跨周期保留下来。
在六道真实研究任务上,Arbor 全部拿到最佳留出结果,平均留出增益是 Codex 和 Claude Code 的 2.5 倍以上。

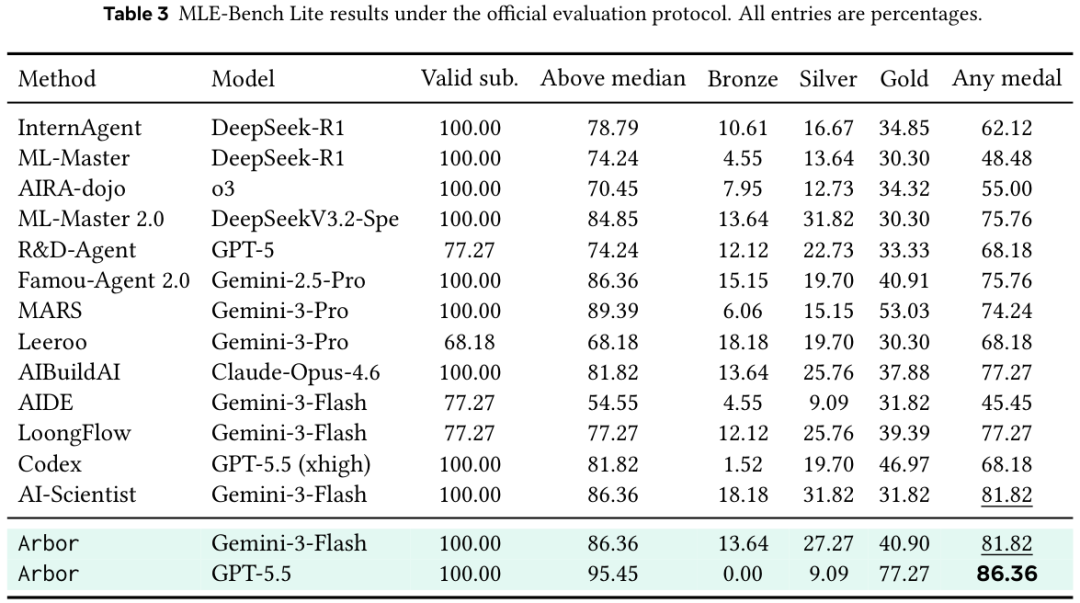
在 MLE-Bench Lite 上配合 GPT-5.5,Arbor 拿到 86.36% 的 Any Medal(任意奖牌)成绩,是目前对比里的最高值。
把研究做成一棵树
科研的真实麻烦不在解题,在持续。一个长周期里,研究者要面对不确定的假设、烧钱的实验、接连的失败和延迟的反馈。每跑一次,都得想清楚下一步往哪走。
失败的尝试里通常藏着信息,能不能把这些信息留下来,决定了下一轮是从零开始还是踩在肩膀上。
团队把困境形式化成 Autonomous Optimization(自主优化,简称 AO)。给 Agent 一个初始 artifact(工件,通常是代码库),一个目标,一个评估器,让它在不靠人逐步盯的情况下,通过反复实验把这个 artifact 改进。
难点在于,研究反馈是延迟的,实验是贵的,失败是常见的,一个把每次试验当独立局部尝试的 Agent,会丢掉研究过程本身的结构。AO 跟普通的 Agent 工具调用不同,目标不是一次性的回答或代码补丁,要的是一条持续的研究轨迹,得提出假设、改 artifact、解读反馈、决定哪个方向继续。
Arbor 的核心是 Hypothesis Tree Refinement(假设树精炼,简称 HTR)。研究状态不再是最新代码加最新分数,而是一棵持久生长的树。每个节点绑着四样东西,一个假设、对应版本的 artifact、实验证据、提炼出来的 insight(洞察)。
靠近根的节点是宽泛的研究方向,越往下越具体,到叶子就是可以直接交执行的修改方案。从宽到窄的层次,让探索变成渐进式细化,不是一堆扁平的独立尝试。
整套系统分成两层。一个长寿的 coordinator(协调器)负责管这棵树,决定往哪扩、剪哪枝、合哪条。一群短期的 executor(执行器)各自被派出去测一个叶子假设,在独立的 git worktree(工作树)里改代码、跑评估,回来交一份结构化报告,包含分数、事实结果、洞察和分支引用。
coordinator 拿到报告,写回叶子节点,把洞察沿路径往根方向抽象上去,再决定下一步。这个分工的妙处在于,探索性的代码改动被锁在隔离分支里,主干永远干净,树里只记决策相关的证据,不会被一堆工具调用日志撑爆。
coordinator 的循环是六步。
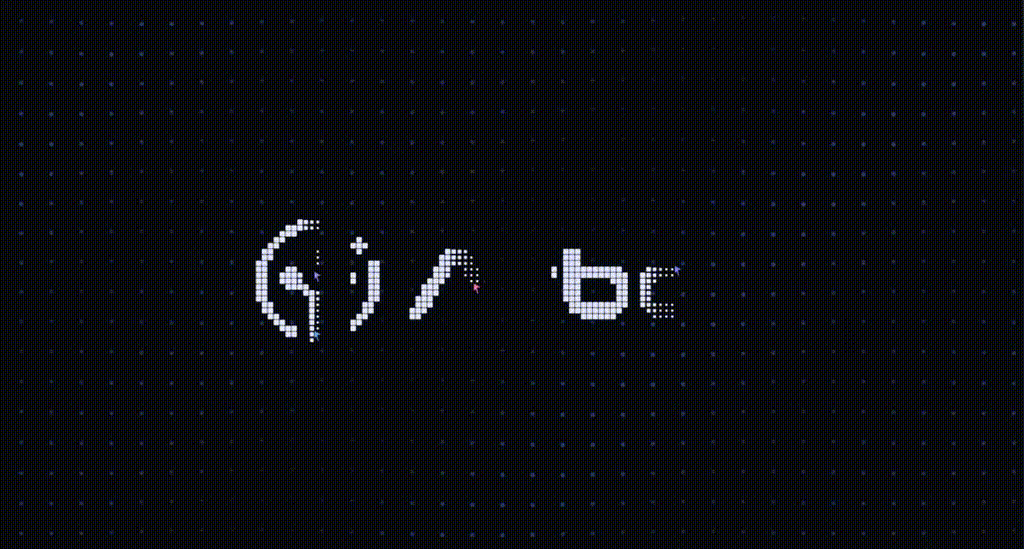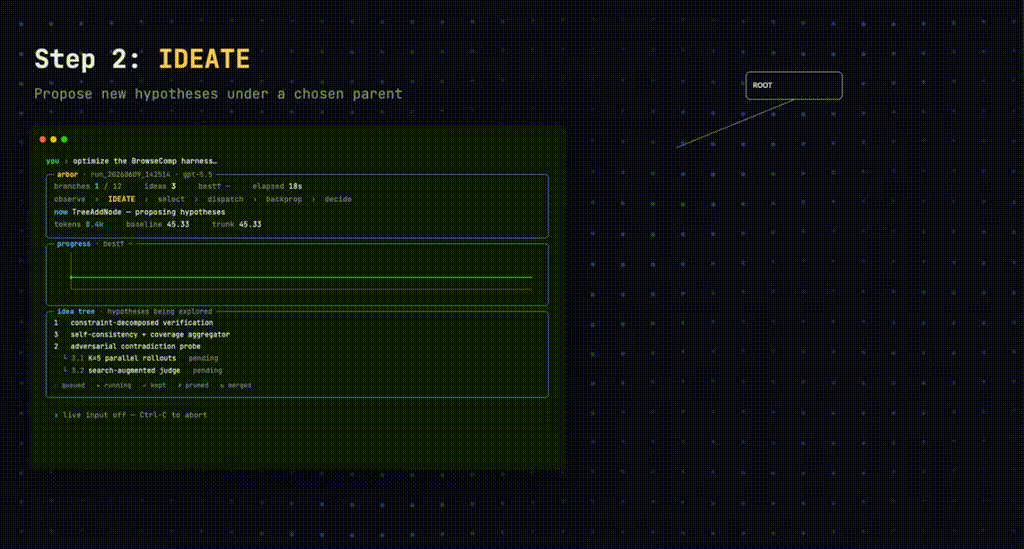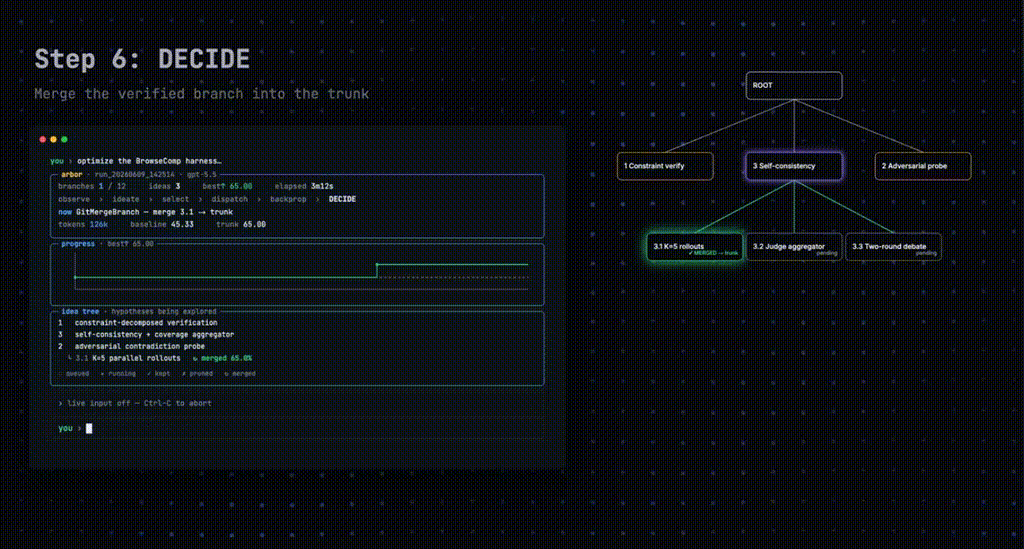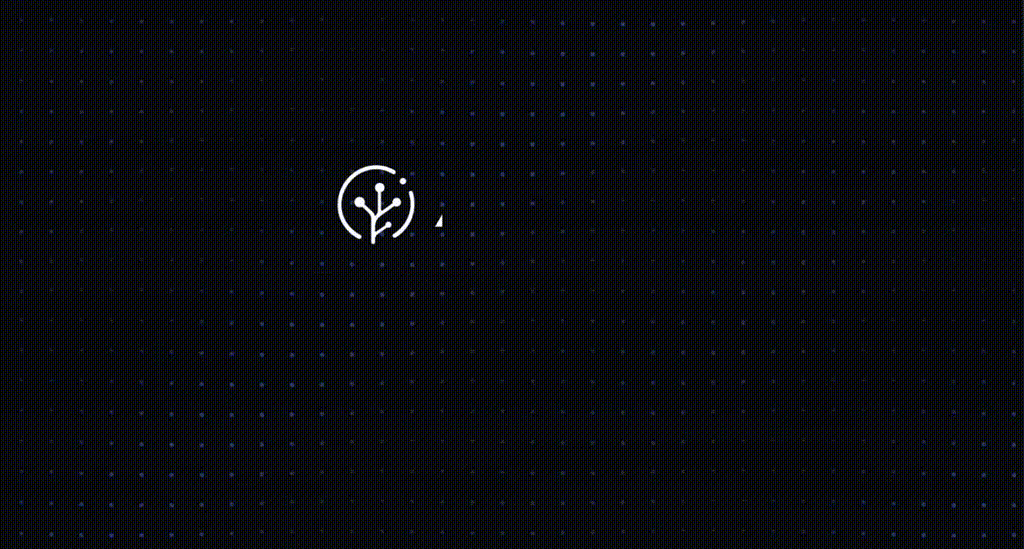
Observe(观察)读当前树状态,包括前沿节点、最近返回的证据、祖先洞察和当前最优 artifact。
Ideate(构思)在选定父节点下提出几个子假设,每个子假设都建立在已积累的证据上,被验证的洞察能当假设用,被剪掉的节点能当负面约束用。
Select(挑选)选要执行的叶子,挑选不只看分数高低,也看兄弟节点之间有没有未解决的歧义,看失败能不能澄清关键假设。
Dispatch(派发)丢给 executor。
Backpropagate(回传)把证据和洞察往上传。
Decide(决断)决定继续、剪枝还是合并。合并这道关卡最关键,候选分支必须先用留出的 test 评估器证明自己比当前最优好,才能进主干。
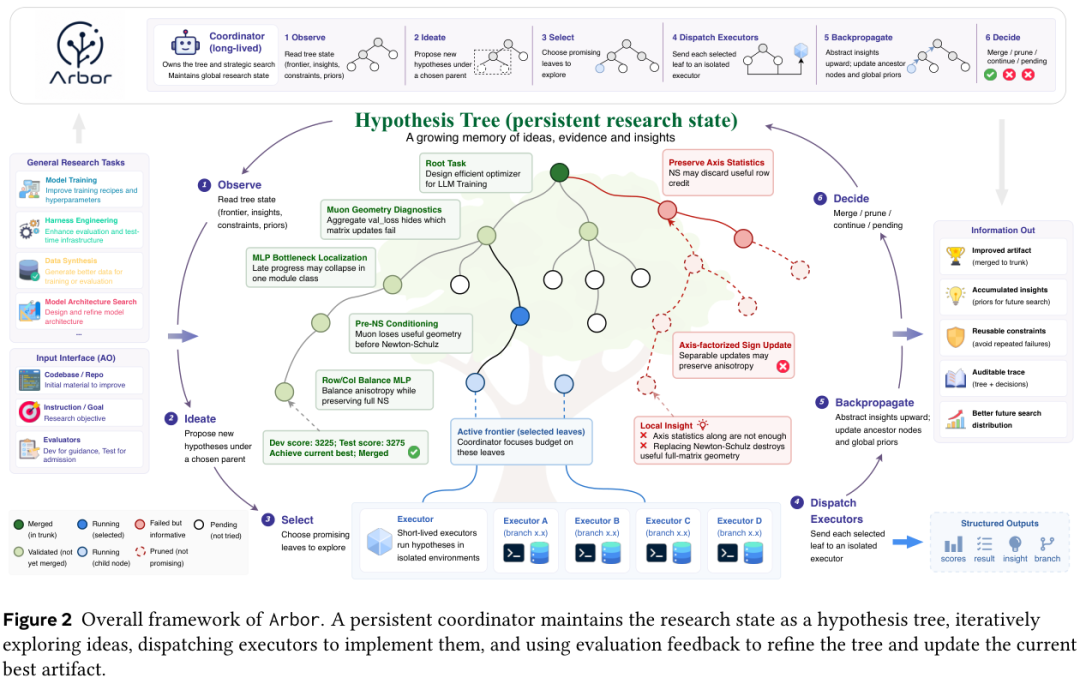
Figure 2 把这套机制画清楚了。左边是 coordinator 拿着全局树状态做战略决策,右边是一排短期 executor 在隔离环境里做局部实验,中间这棵树既是搜索前沿,也是过去所有尝试的记忆,还是 artifact 改进的审计轨迹。
一次 Arbor 跑下来,能拿到的不只是改进后的代码,还有一整棵记录了什么试过、什么验证过、什么被剪掉的研究树。
六道真题全胜
研究者搭了一套 AO Task Suite(AO 任务集),六道题覆盖三大类研究场景,模型训练、Harness 工程、数据合成。

每道题都明确分了 dev(开发集)和 test(测试集)。dev 给 Agent 反复试错用,test 只留出来做最终验证。
dev test 切分看起来朴素,却是后面所有结论的地基。很多既往 benchmark 要么没有清晰的 dev test 划分,让迭代搜索容易过拟合,要么只覆盖一两种任务类型,让通用性没法验。
Arbor 将六个真实研究任务与 Codex 和 Claude Code 对照。
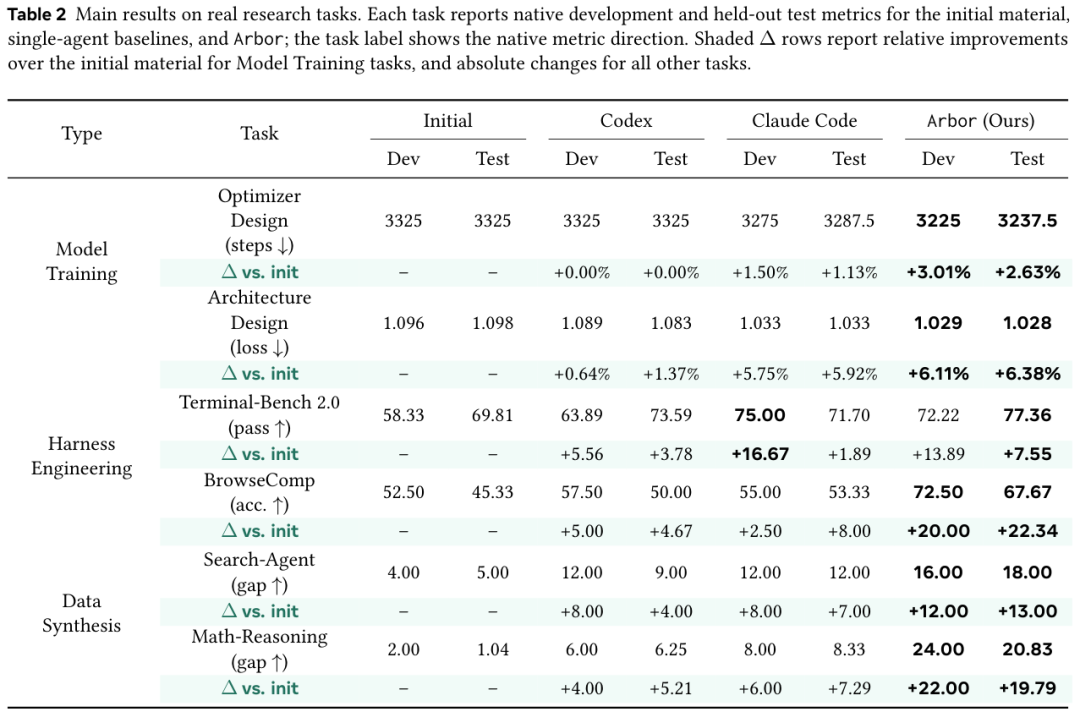
Arbor 在六道题的留出 test 上全部第一。
模型训练里,Architecture Design 把 loss 从 1.098 拉到 1.028,相对改进 6.38%,Codex 是 1.37%,Claude Code 是 5.92%。
Optimizer Design 把训练步数从 3325 压到 3237.5,相对改进 2.63%。
Harness 工程里,BrowseComp 的准确率从 45.33 直接拉到 67.67,绝对涨 22.34 个百分点,Codex 涨 4.67,Claude Code 涨 8.00。
Terminal-Bench 2.0 的通过率涨 7.55 个百分点。
数据合成里,Math-Reasoning 的 pass gap 涨 19.79,是 Codex 的近 4 倍。Search-Agent 的 pass gap 涨 13.00。
把六道题的相对增益取平均,Arbor 是 Codex 和 Claude Code 的 2.5 倍以上。同样的 controller、同样的树深度、同样的搜索预算,只换初始材料和评估器,跨任务都能稳定赢,说明增益来自搜索过程本身,不是任务特定调优。
跑到 MLE-Bench Lite 上,Arbor 换 GPT-5.5 当 backbone(骨干模型),Any Medal 拿到 86.36%,Above Median 拿到 95.45%,Gold 拿到 77.27%。
不是靠多砸算力
面对一套成绩好的系统,第一反应通常是想问,是不是 token 砸得多。研究者专门查了成本。
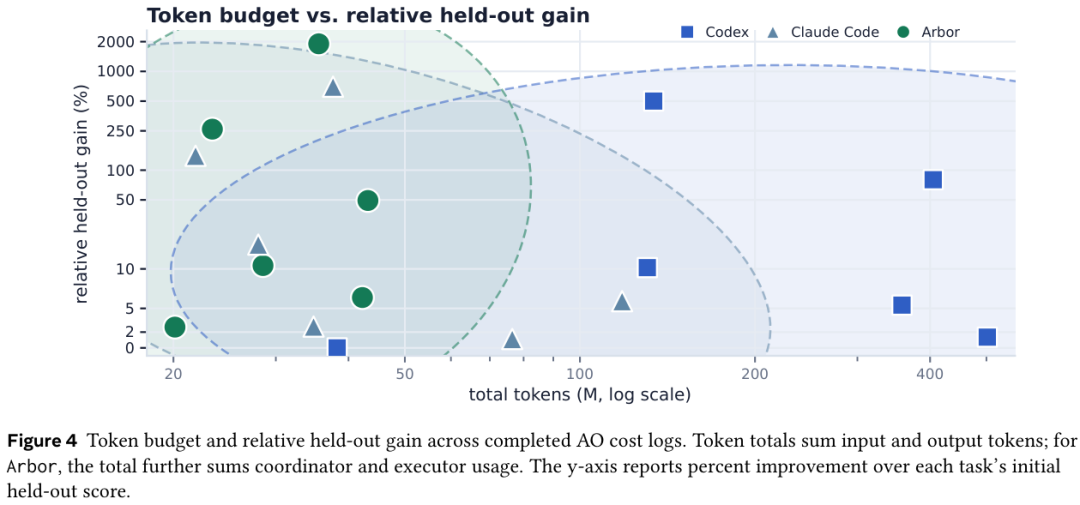
六个完整成本日志里,Arbor 用的是 20.12M 到 43.19M token,跟 Codex 和 Claude Code 是一个量级。在这个预算下,Arbor 在多数任务上拿到更大的留出增益。
预算被用来维护竞争假设、跑隔离执行、对比证据、更新搜索树,不会一味地多采样。这也回应了一个常见质疑,Agent 跑得久不等于跑得好,结构化搜索比单纯延长执行时间更值钱。
消融实验更进一步。在 MLE-Bench Lite 上把树拆掉,退化成扁平实验队列,记作 w/o tree。把洞察回传关掉,保留树结构但不让教训上传,记作 w/o insight feedback。两个变体各跑一遍,同样的工具、同样的工作区预算、同样的评估协议、同样的 Claude Opus 4.6 backbone。
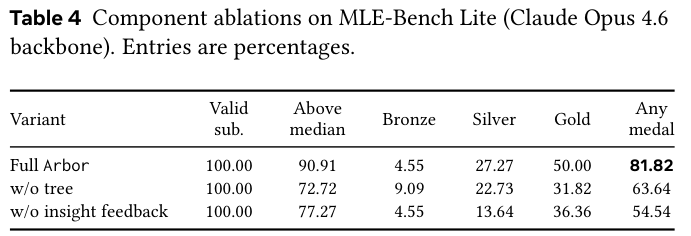
三个变体都是 100% 有效提交。Full Arbor 是 81.82% Any Medal,w/o tree 掉到 63.64%,w/o insight feedback 掉到 54.54%。
一个反直觉的发现是,留着树但关掉洞察回传,比直接把树拆掉还差。空有结构没有语义记忆,等于把实验按文件夹归了类,但没有任何东西能告诉你下一步该往哪走。树和洞察必须搭在一起,一个负责存竞争假设,一个负责把局部失败变成全局约束。
HTR 真正起作用的环节是后期精炼,一旦跑通一个可执行方案,树帮 Agent 决定哪个方向该继续、哪个该回头、哪个该丢掉。
错了也能往前走
光看数字还不够,研究者拆了一棵真实的 BrowseComp 假设树,看 Arbor 在长跑里到底学到了什么。
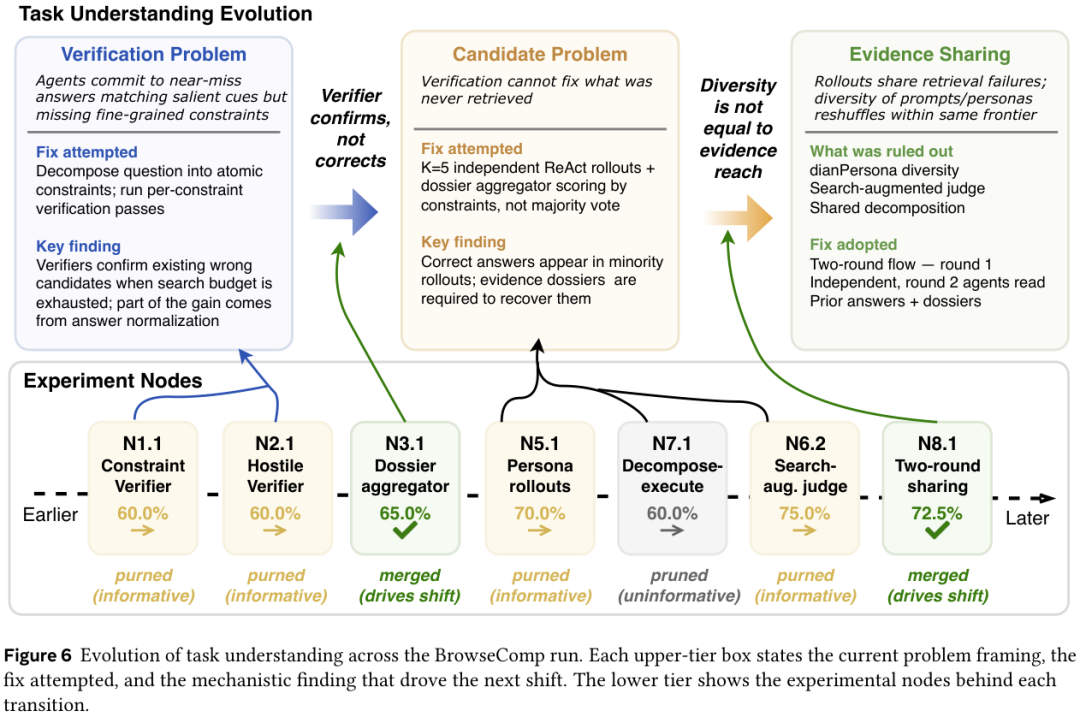
一开始的假设很粗,认为搜索 Agent 答错是因为抓住了显眼线索但漏掉了细粒度约束。试了 constraint verifier(约束验证器)和 hostile verifier(对抗式验证器),dev 准确率都涨。
到中期发现,验证器只能筛掉已经检索到的候选,找不回压根没出现的答案。任务的瓶颈从更严的验证,转到了更广的证据覆盖。后期试了 persona 多样化和共享分解,发现都没用,因为它们都在同一个检索前沿里折腾。最后合并进主干的设计是,首轮各自独立检索,次轮让 Agent 看候选答案和证据 dossier(卷宗),按覆盖约束数最多的候选作答。
整个过程几个阶段对得上人类做研究的节奏。早段试宽泛机制,中段定位机制边界,后段用累积的正面负面发现约束最终设计。
一个失败节点不会被简单丢弃,它的洞察会沿着路径上推,变成对后续构思的负面约束。团队反复强调的那句话有了落点,把局部失败变成下一轮的起点。
研究者还发现一个有意思的现象,强候选往往出现在搜索状态积累了足够约束之后,跑过中段才冒出来。后期的提案比早期提案更有针对性,因为它们建立在前面试错的基础上。早期实验持续降低后期搜索的随意性,让中后段的改进站在更高的信息基线上。
效率的关键在于同样的预算能不能产出更不重复、更受约束的证据链,跟跑得久不久关系不大。
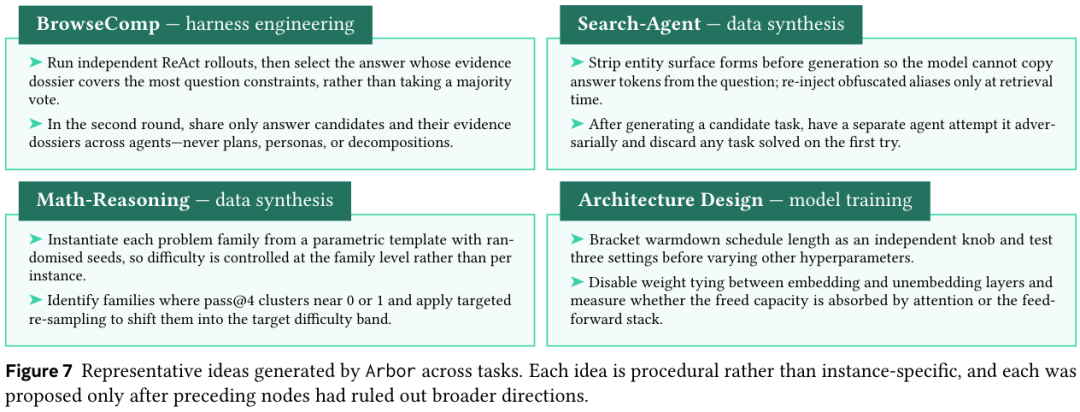
Figure 7 列了几个跨任务的实际 idea。BrowseComp 上的证据卷宗聚合,Search-Agent 上的实体表面形式剥离防止答案泄露,Math-Reasoning 上的参数化模板按难度族采样,Architecture Design 上把 warmdown schedule(退火计划)长度当成独立旋钮。每个都是局部可执行的小改动,每个都是前面节点排除了更宽方向之后才浮出来的。
团队也承认,Arbor 擅长把已有方向细化再细化,但不擅长从零蹦出一个跟现有树弱关联的全新构想。Architecture Design 跑到最后单旋钮调参收益递减,研究者能看出需要一个更大的算法动作,但这个动作还得靠人给的判断。任务设计里的初始 artifact、评估器、指标和搜索接口,共同决定了 Agent 能发现什么样的 idea。
跨任务迁移方面,研究者把 BrowseComp 上优化过的 harness 冻结,直接拿去测两个从没见过的搜索任务 HLE 和 DeepSearch QA。结果是 HLE 从 25.50 涨到 31.50,DeepSearch QA 从 61.00 涨到 69.00。
一个在 BrowseComp 上优化出来的搜索外壳,搬到完全没见过的任务上还能涨点,说明它学到的是搜索流程层面的设计调整,不是对某个评测集的过拟合。
研究者拿 Gemini-3-Flash、Claude Opus 4.6、GPT-5.5 三个不同骨干重跑代表性任务,controller、评估器预算、任务适配器都不变。
结果 Arbor 在三套骨干模型上都能改进 BrowseComp 和 MLE-Bench Lite。框架本身跟具体模型解耦,只是天花板受任务跟骨干契合度影响。Claude Opus 4.6 在 BrowseComp 上表现最好,因为搜索 harness 优化需要宽推理和错误诊断。GPT-5.5 在 MLE-Bench Lite 上表现最好,因为 ML 工程知识更对胃口。
Arbor 证明,让 Agent 自己做研究的瓶颈,跟怎么把每一次尝试变成下一次的台阶有很大关系。Arbor 用一棵持续生长的树,把假设、artifact、证据、教训都挂上去,错了也能往前走。
Arbor 给自主科研装上了记忆。
参考资料:
https://ruc-nlpir.github.io/Arbor/
https://arxiv.org/pdf/2606.11926
https://github.com/RUC-NLPIR/Arbor

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)