
测试人经常被问为什么没有提前发现这些问题?压测就绪检查全流程实战,7大性能测试 Skill(第四篇)
真实场景
一切准备就绪。
性能测试计划写好了:5000 并发,23 分钟,6 阶阶梯。
2000 万条数据造好了,缓存预热完了。
JMX 脚本也调通了,单用户跑了一遍返回 200。
上午 10 点,你深吸一口气,JMeter 点下「Start」。
10:00 一切正常,TPS 缓慢爬升。
10:02 TPS 到 3000,P95 还在 200ms,心里窃喜。
10:05 突然 —— TPS 暴跌到 0。
你赶紧看监控:
-
服务进程呢?还在,但没响应
-
DB 连接数?打满了,5000 个连接堆积
-
Redis 呢?没监控,看不到
-
应用日志?全是 OOM
紧急重启服务,10 分钟后才恢复。
业务方问:"压测结果呢?"
你只能回答:"环境有问题,今天跑不了……"
5 分钟白干,10 分钟救火,下午的会议只能推迟。
老板问:"这种问题怎么没提前发现?"
你哑口无言。
这种"按下开始 5 分钟后翻车"的场景,几乎每个测试工程师都遇到过。
数据没问题、脚本没问题、计划没问题,但环境没核、监控没装、限流没调、连接池没配 —— 这些"开压前最后 100 米"的事,恰恰是压测翻车的重灾区。
数据造得再准,脚本调得再稳,环境不到位,全白干。
这就是为什么性能测试链路里,必须有「就绪检查」这一关。
perf-readiness-checker 是什么
perf-readiness-checker 是性能测试 7 个 Skill 中的第 4 个,定位是压测就绪检查。
它不是帮你压测,而是帮你回答一个问题:现在能不能按下"开始"按钮?
它把"压测前要检查什么"这件事工程化、清单化、自动化,输出一份 7 段式就绪评估报告,直接告诉你"能开压 / 有问题要修 / 严重问题禁止开压"。
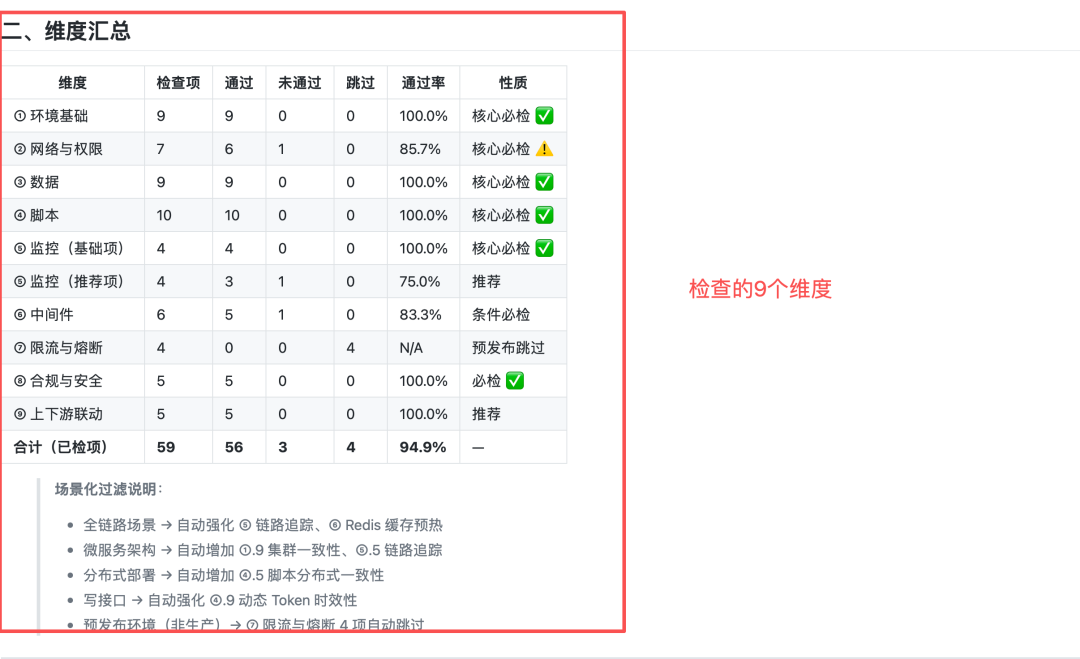
它检查的不是某一个点,而是 9 大维度 60+ 检查项:
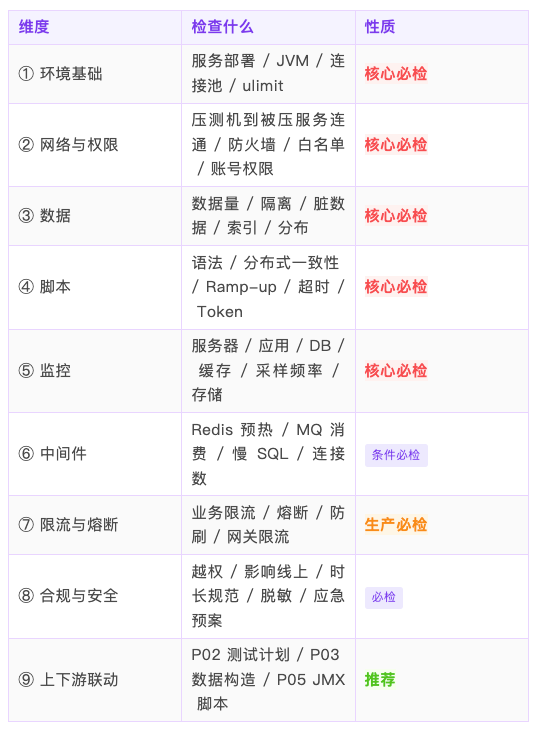
关键原则:核心必检项(①/②/③/④/⑤基础项)任一未通过 = 禁止开压。
这不是保守,是工程纪律。宁可推迟压测,也不要带着已知问题执行。
能解决什么问题
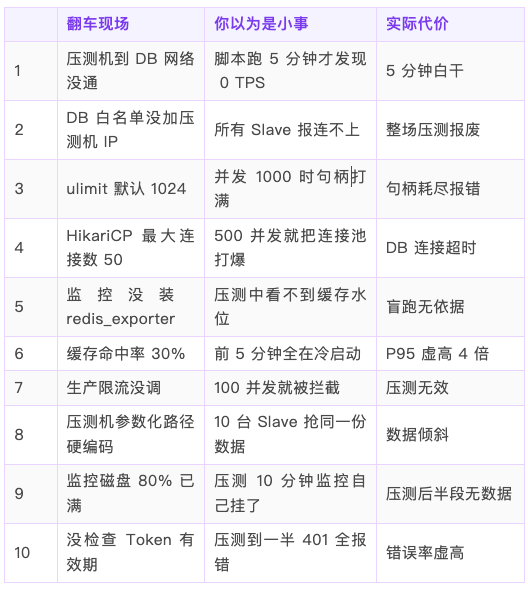
这些问题的共同点:每个都是 5 分钟能修的,但每个都能让整场压测白跑。
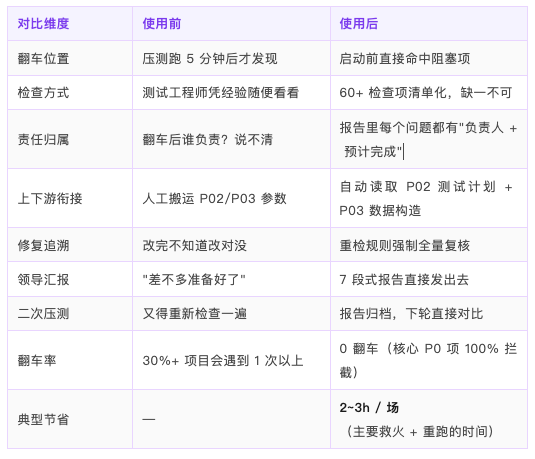
以前 vs 现在
| 翻车原因 | 以前 | 现在(P04) |
|---|---|---|
|
网络没通 |
跑 5 分钟看日志才发现 |
② 网络与权限 7 项提前卡住 |
|
白名单缺失 |
5 台 Slave 一起报 0 TPS |
启动检查直接命中 2.4 阻塞项 |
|
ulimit 默认 |
并发一上来就句柄打满 |
≥ 5000 并发自动强警告核查 |
|
监控盲区 |
压测中"看不到"任何指标 |
监控采样频率 + 存储容量清单化 |
|
限流没调 |
生产压测被业务系统直接拦截 |
生产压测 7.1~7.4 4 项强制检查 |
|
脚本硬编码 |
分布式配置不一致 |
4.5 分布式脚本路径/参数/全局变量统一校验 |
核心能力一览
1. 9 大维度 60+ 检查项
从 ① 环境基础到 ⑨ 上下游联动,60+ 检查项覆盖压测全链路可能出问题的环节。
每个检查项都有 4 个字段:检查内容、通过标准、影响等级(P0/P1/P2)、修复建议。
2. 场景化智能清单
不同的压测场景,关注点完全不同:
| 压测场景 | 自动跳过 | 自动强化 |
|---|---|---|
| 单接口压测 |
MQ 消费、全链路看板 |
超时配置 |
| 全链路压测 |
无 |
链路追踪、缓存预热 |
| 长链接压测 |
HTTP 请求细节、短连接监控 |
长连接数监控 |
| MQ 压测 |
HTTP 请求、数据库监控(弱) |
MQ 消费、MQ 堆积 |
| 秒杀压测 |
压测时长(秒级) |
限流、缓存预热、连接数 |
架构感知:单体服务自动跳过 1.9 集群一致性,微服务/集群自动增加 5.5 链路追踪和负载均衡检查。
3. 自动风险识别
根据并发数自动判断资源规格是否匹配:
| 并发级别 | 自动核查 |
|---|---|
|
≤ 100 |
默认即可 |
|
100 ~ 1000 |
提示核查线程池 / DB 连接池 |
|
1000 ~ 5000 |
提示核查 ulimit / JVM 堆 / DB 连接数 |
| ≥ 5000 | 强警告
:必须核查 ulimit、somaxconn、JVM、连接池、负载均衡、网关限流 |
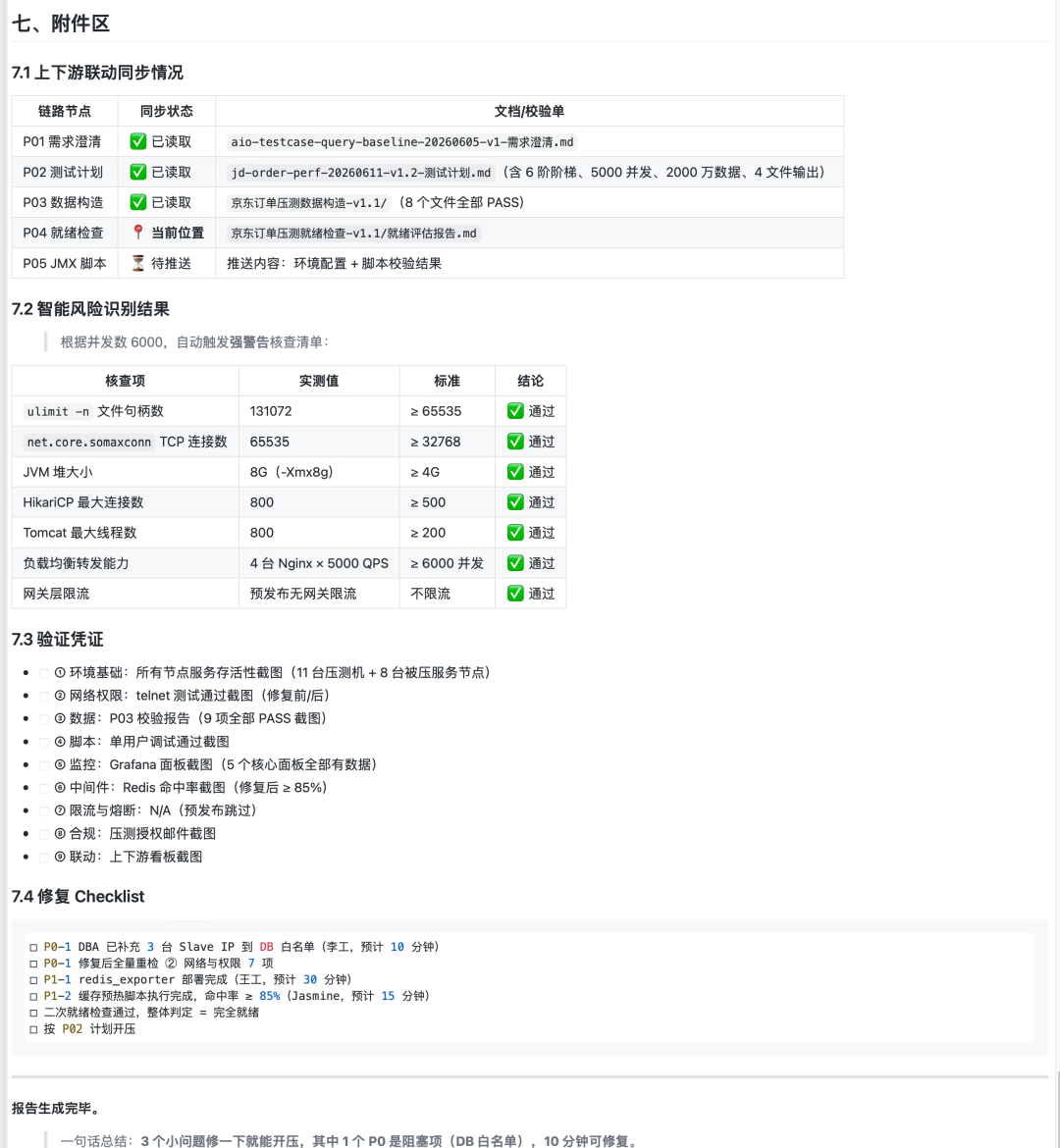
4. 上下游联动
P04 不是孤岛,它和 P02/P03/P05 双向联动:
P01 需求澄清
↓
P02 测试计划 ← 自动读取 C/T/SLA/模式/集群规模
↓
P03 数据构造 ← 自动读取数据量/校验报告
↓
【P04 就绪检查】← 当前位置
↓
P05 JMX 脚本 ← 自动推送环境配置/脚本校验结果
↓
P06 报告分析 → P07 报告生成你不用重复录入 P02/P03 的输出,P04 自动读取,真正做到一份数据走全程。
5. 严格的就绪判定
不是简单的"通过/未通过",而是三档 + 风险分级:
| 状态 | 判定标准 | 行动建议 |
|---|---|---|
| 完全就绪 |
所有检查项通过 |
立即开压 |
| 条件就绪 |
核心必检全通过,存在中/低风险 |
修复后重检,或记录风险后执行 |
| 未就绪 |
核心必检存在未通过 |
必须修复后才能开压 |
重检规则:未通过项修复后,必须全量重检对应维度(比如脚本维度有 1 项未通过,修完后必须 ④ 全部 10 项重新过一遍),不允许只复核单项后即开压。
6. 7 段式标准报告
固定 7 段式输出:
1. 基础信息(11 个字段)
2. 维度汇总(9 行 + 合计 + 通过率)
3. 问题明细(问题描述 + 影响等级 + 修复建议 + 负责人 + 预计完成)
4. 整体判定(完全就绪 / 条件就绪 / 未就绪)
5. 风险说明(高/中/低风险 + 已跳过项)
6. 执行建议(分步骤)
7. 附件区(截图/凭证/上下游同步状态)告别"纯文字描述",所有字段都固定,方便归档和回溯。
7. 智能交互
-
批量确认:支持「环境项全部已检查」「数据项全部 PASS」批量回复,不用逐项回复
-
异常排查指引:未通过项附带标准排查步骤(如网络不通 → 端口 → 安全组 → 路由)
-
术语注释:JVM 堆 / ulimit / 连接池等专有名词附带简易说明
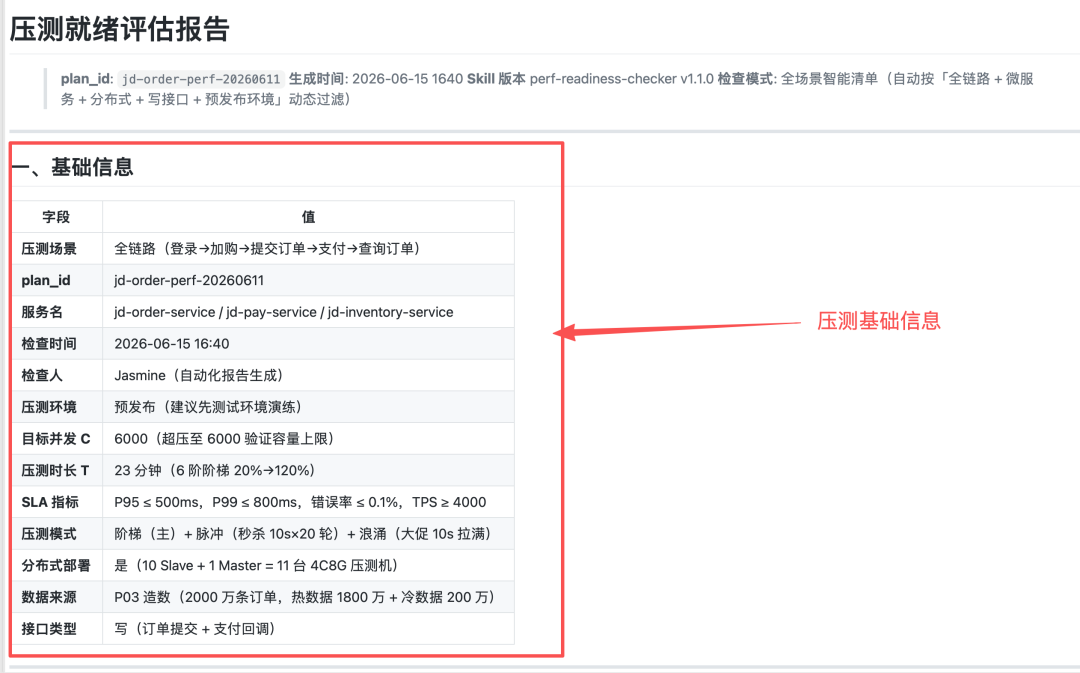
实战案例:京东订单 2000 万数据压测前检查
实战场景:P02 测试计划 + P03 2000 万数据都准备好后,跑一遍 P04 看看能不能开压。
输入参数(已自动从 P02/P03 读取):
| 字段 | 值 |
|---|---|
|
plan_id |
jd-order-perf-20260611 |
|
压测场景 |
全链路(登录→加购→提交订单→支付→查询订单) |
|
目标并发 C |
6000(超压至 6000 验证容量上限) |
|
压测时长 T |
23 分钟 |
|
SLA |
P95 ≤ 500ms,错误率 ≤ 0.1% |
|
压测模式 |
阶梯(主)+ 脉冲(秒杀)+ 浪涌(大促) |
|
分布式 |
10 Slave + 1 Master = 11 台 4C8G |
|
数据来源 |
P03 造数(2000 万条订单,热 1800 万 + 冷 200 万) |
|
接口类型 |
写 |
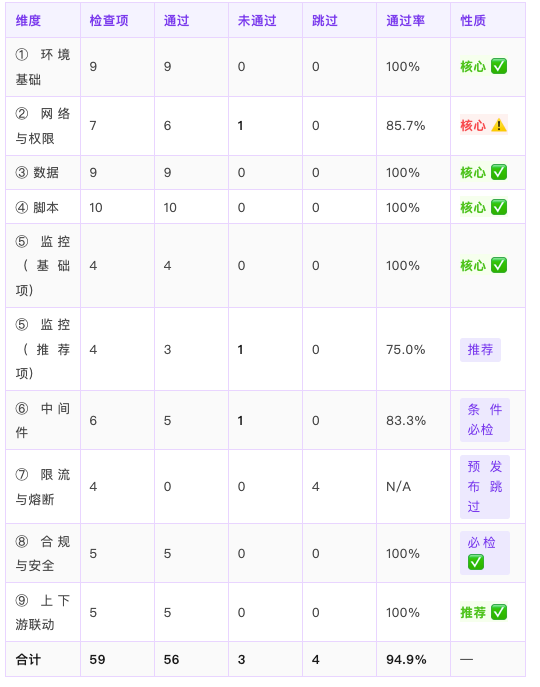
P04 跑完后,输出 7 段式就绪评估报告:
维度汇总
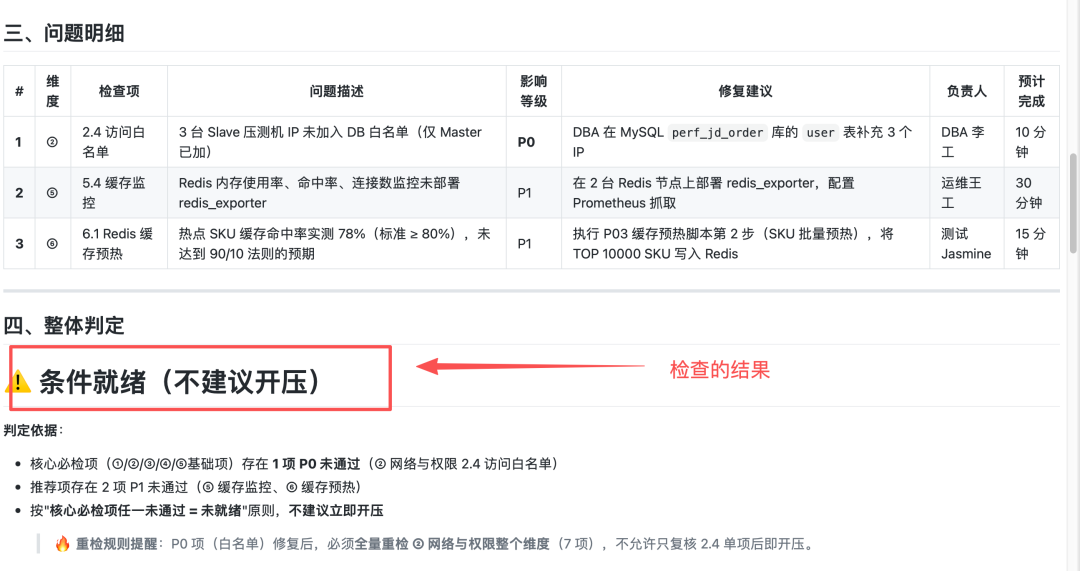
整体判定
条件就绪(不建议开压)
判定依据:核心必检项存在 1 项 P0 未通过(② 网络与权限 2.4 DB 白名单),按"核心必检项任一未通过 = 未就绪"原则,不建议立即开压。
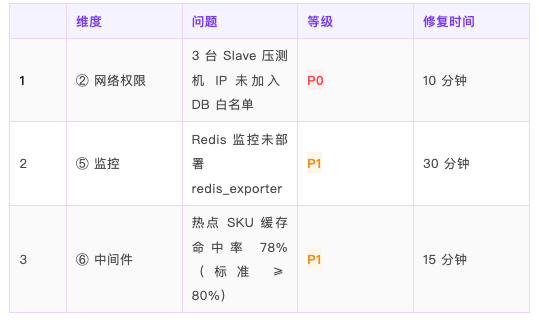
问题明细
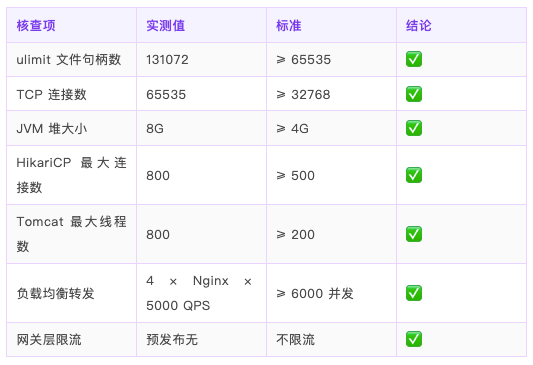
智能识别结果(≥ 5000 并发强警告)
7 项资源规格核查全部通过:
修复 Checklist
□ P0-1 DBA 已补充 3 台 Slave IP 到 DB 白名单(李工,预计 10 分钟)
□ P0-1 修复后全量重检 ② 网络与权限 7 项
□ P1-1 redis_exporter 部署完成(王工,预计 30 分钟)
□ P1-2 缓存预热脚本执行完成,命中率 ≥ 85%(Jasmine,预计 15 分钟)
□ 二次就绪检查通过,整体判定 = 完全就绪
□ 按 P02 计划开压总结
3 个小问题修一下就能开压,其中 1 个 P0 是阻塞项(DB 白名单),10 分钟可修复.
输出物示例
P04 输出 1 份就绪评估报告 + 若干修复 Checklist:
标准 7 段式报告结构:
# 压测就绪评估报告
## 一、基础信息
(11 个字段:plan_id / 服务名 / 检查时间 / 检查人 / 压测环境 /
目标并发 / 压测时长 / 压测模式 / 分布式 / 数据来源 / 接口类型)
## 二、维度汇总
(9 行 + 合计:维度 / 检查项 / 通过 / 未通过 / 跳过 / 通过率 / 性质)
## 三、问题明细
(每个问题:维度 / 检查项 / 问题描述 / 影响等级 / 修复建议 /
负责人 / 预计完成时间)
## 四、整体判定
(完全就绪 / 条件就绪 / 未就绪 + 判定依据)
## 五、风险说明
(高/中/低风险分类 + 已跳过项说明)
## 六、执行建议
(分步骤:先修什么 → 重检什么 → 二次确认 → 开压)
## 七、附件区
(上下游联动同步情况 + 智能识别结果 + 验证凭证 + 修复 Checklist)报告完全自包含:领导汇报 / 团队评审 / 历史归档 / 多轮回归都能直接用。

怎么用
在 WorkBuddy 中使用
最佳实践:接在 P03 后面用
P02 测试计划 + P03 数据构造都准备好后,把 P02 的测试计划文档扔给 P04:
@skill:perf-readiness-checker 根据这份测试计划和数据准备情况,帮我做压测前的就绪检查
P04 会自动读取 P02/P03 的输出,跳过重复问询,直接展开 60+ 检查项引导你逐一确认(或批量确认)。
最简输入(11 个核心参数):
plan_id = jd-order-perf-20260611
压测场景 = 全链路
目标并发 C = 6000
压测时长 T = 23 分钟
SLA = P95 ≤ 500ms,错误率 ≤ 0.1%
压测模式 = 阶梯(主)+ 脉冲(秒杀)
压测集群规模 = 10 Slave + 1 Master
分布式部署 = 是
压测环境 = 预发布
数据来源 = P03 造数
接口类型 = 写两种交互模式:
-
批量确认(推荐):「环境项全部已检查」「数据项全部 PASS」
-
逐项确认:按维度逐一询问「已通过/未通过/跳过」
⚠️ 核心规则:核心必检项(环境/网络权限/数据/脚本/基础监控)禁止跳过。
在其他平台也能用
P04 同样不是 WorkBuddy 专属,每个 Skill 都内置了跨平台通用 Prompt 模板:
| 平台 | 使用方式 |
|---|---|
| WorkBuddy | @skill:perf-readiness-checker
直接调用,文件输出最完整 |
| Cursor |
复制 Prompt 模板 → 粘贴到 Chat 或 |
| Trae |
复制 Prompt 模板 → 侧边栏 AI 助手 → 开始对话 |
| Claude/ChatGPT/DeepSeek |
复制 Prompt 模板 → 新建对话 → 输入具体需求 |
复制方式:打开 Skill 文件,找到 ## 跨平台 Prompt 模板 v1.1.0 部分,复制整个代码块内容,粘贴到目标平台即可。检查结果质量与 WorkBuddy 一致,文件和版本需要手动维护。
使用前 vs 使用后
总结
压测翻车 90% 的根因,不是"计划不对"、不是"脚本错了"、不是"数据不准",
而是"按下开始按钮前的最后 100 米,没检查到位"。
环境没核、监控没装、限流没调、白名单没加、Token 过期, 这些都是 5 分钟能修的"小问题",但每个都能让整场压测白跑。
P04 perf-readiness-checker 把这些"小问题"工程化、清单化、自动化,让你在按下"开始"之前,对环境有 100% 的把握。
它不是增加你的工作量,而是把"翻车后的救火"前置到"开压前的检查"。
下一篇,我会介绍 P05 perf-jmx-generator , JMX 脚本生成 Skill。就绪检查通过后,一键生成可执行的 JMX 脚本,从测试计划直接到压测执行,中间不再有手工配置 JMeter 的环节。
专栏目录(持续更新):
| 篇号 | 主题 | Skill |
|---|---|---|
|
第 1 篇 |
需求澄清 |
perf-requirement-clarifier |
|
第 2 篇 |
测试计划 |
perf-test-planner |
| 第 3 篇 | 数据构造 | perf-data-builder |
|
第 4 篇 |
就绪检查 |
perf-readiness-checker |
|
第 5 篇 |
JMX 脚本 |
perf-jmx-generator |
|
第 6 篇 |
报告分析 |
perf-report-analyzer |
|
第 7 篇 |
报告生成 |
perf-report-writer |

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)