
SkillOpt: 让skills学会自我进化
事情是这样的。
前两天我一个做开发的朋友跟我吐槽。说他花了两周,手写了一份 AI agent 的操作手册。
你们用 Codex 或者 Claude Code 的可能知道那玩意儿——就是 SKILL.md。里面密密麻麻写满了各种规则:遇到 A 先做 B,如果 C 报错了别慌先查 D,输出必须是 JSON 不能带 fence,等等等等。
写完那天晚上他还发了条朋友圈:“终于把我的操作心法系统化了。”
第二天让 AI 跑了一批任务。
结果呢?
成功率不仅没涨,还跌了。
他懵了。他把那个文件翻了三遍,没找到问题在哪。然后发给我看。
我看了半天也没看出毛病。
但我想起最近微软开源了一个项目,叫 SkillOpt。看完论文和代码之后我突然明白了。
我对他说:朋友,你那个不是操作手册。你那个是玄学。

一、你有没有想过,你写的每条规则都可能是错的
先给不太熟的朋友交代一下背景。
现在做 AI agent 开发的都知道,agent 在执行任务之前会先读一份"技能文件"。这个文件定义了它该干什么、不该干什么、步骤顺序是什么、遇到错误怎么办。
你可以把它理解成:AI 上班前必须读的作业纸。
问题出在哪呢?
问题出在这张作业纸是人写的。
人是靠经验写的。你觉得"这条规则肯定有用",但你其实没有证据。你可能是上周翻车之后愤怒加上去的,可能是在 StackOverflow 上抄的,也可能是凌晨三点灵光一闪——第二天醒来一看,自己都不知道当时为什么这么写。
更可怕的是:你不知道这些规则哪个有用、哪个没用、哪个甚至有害。
这就像你给自己写了一份考试复习笔记,但没人告诉你——里面有几条是重点,有几条是废话,还有几条是错的。你拿着这份笔记去考试。考完了,成绩不满意。你翻开笔记,从头看到尾,完全不知道应该改哪一页。
更魔幻的是,现在很多 AI 系统还能"自我反思"。
让 AI 看看自己失败在哪,自己改自己的 prompt。
听起来很好对吧?AI 自己复盘,自己进步,多省心。
但是。
AI 确实很会解释失败。它可以洋洋洒洒写两千字,分析自己为什么答错了——上下文没读全、工具调用顺序不对、输出格式没锁死。每一个解释都听起来特别有道理。
问题是:解释完之后呢?
它根据这个解释改了 prompt。
你怎么知道改完真的更好了?
你怎么知道它不是从一个坑,精准地跳进了另一个坑?
这就像一个人考试没考好,复盘说"我选择题花了太多时间"。于是下一次他疯狂做选择题,结果大题一道没写。分数更低了。
失败复盘只能找到嫌疑人,验证集才负责判案。
二、它不训练大脑,它训练大脑看到的那张纸
好,铺垫完了。现在说 SkillOpt。
SkillOpt 是微软 2026 年 5 月开源的项目。论文发在 arXiv,代码在 GitHub,包在 PyPI。
我查了一下,截止 6 月 15 号,已经 6900 多 star、600 多 fork——两周多就这个量,说明社区是真的在疯狂试用。
核心思路一句话:把 Skill 文档当作可训练对象,而不是一次性写死的提示词。
什么意思?
传统的 AI 训练,是改模型内部的神经网络参数。你可以理解成在修改一个人的大脑结构。
SkillOpt 不碰这些。
模型是冻结的。参数完全不变。
它改的,是模型执行任务之前看到的那份操作手册。
打个比方:
-
• 微调模型 = 给一个人的大脑做手术,改变他的思维方式
-
• SkillOpt = 不改大脑,但在他每次考试前,给他发一份越来越好的复习笔记
最终部署的产物就是一个 best_skill.md 文件,300 到 2000 个 token。
翻译成人话:比你现在看的这一段文字长不了多少。
推理的时候不需要调用优化器,不需要改模型,不需要多花一分钱。就是多附了一份更靠谱的说明书。
这个思路好在哪?
你说"AI 参数是黑盒,没法审计"。那 Markdown 呢?
你可以打开 best_skill.md,逐条审核。看到一条规则写的是"把所有数据库密码硬编码到代码里"——你一眼就能识别,然后删掉。
SkillOpt 不改变大脑,它改变大脑上班前读到的那张纸。
三、它真正的杀手锏,不是会改,而是敢拒绝
现在你可能会想:这不就是让 AI 看失败记录,然后总结几条经验吗?这有什么新鲜的?
你说的这个,叫"让 AI 帮你看错题"。
错题本当然有用。但问题是——AI 从失败里总结出来的经验,你怎么知道它是对的经验?
SkillOpt 跟普通"复盘"的区别,就在于它在复盘之后加了一步:验货。
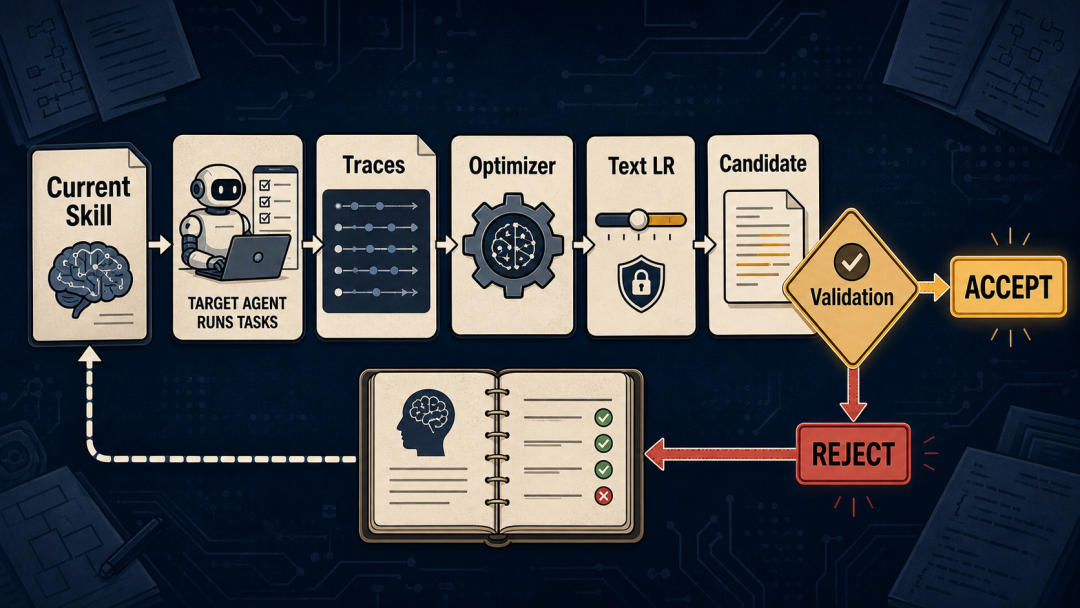
具体流程是这样:
第一步:上场打。
目标 agent 带着当前这份 Skill 去跑一批任务。系统全程录像:它调了什么工具、输出了什么、哪里对了、哪里错了。
第二步:看录像。
一个单独的"优化模型"(比目标 agent 更强)来读这些录像。它不光看失败,也看成功。失败告诉它缺了什么规则,成功告诉它什么做法要保留。
第三步:合并建议。
优化模型看完了,会提一堆修改建议——add、delete、replace。但这些建议可能重复、可能互相矛盾、可能太针对某个具体例子。系统先做一轮去重和整合。
第四步:控量。
这里有一个特别巧妙的设计——文本学习率。
传统深度学习里的 learning rate,控制的是每次参数更新走多大步。SkillOpt 里没有参数,它就把 learning rate 变成了另一层意思:
这一步最多允许你改几条规则。
默认值是 4 条。
看起来是个芝麻大的限制,对吧?但作用巨大。
因为大段重写很爽。一口气把半篇文章推翻重来,感觉自己在做大事。但风险是什么?你可能删掉了一条本来特别有用的规则,也可能为了修一个 bug,引入三个新 bug。
就像一个编辑改稿子。好编辑不会撕掉半篇文章重写。他用红笔,一条一条改,改一条,对一遍。
第五步:生成候选版本。
被选中的编辑应用到 Skill 文档上,产出一个新版本。
第六步:验货。
这是灵魂。候选版本必须在一个提前预留的验证集上重新跑分。
只有比当前版本严格更好的时候,才会被接受。
注意,是"严格更好"。打平都算失败。平手就拒绝。
这意味着什么?
一个 AI 系统,学会了对自己说"不"。
它提出一个修改,然后自己检验,发现没变好,然后——拒绝了。
提出假说,然后验证。验证失败就推翻。这不就是最朴素的科学方法吗?
关键是,被拒绝的修改也不会白费。
它会进入一个"被拒记录本"。后面优化器再提修改建议的时候,能看到:“哦,上次这个方向试过了,不行,换个路子。”
SkillOpt 的聪明不在会改,而在敢拒绝自己刚刚改的东西。
四、它竟然还会"睡觉"——在你不用它的时候偷偷进化
讲一个更让我起鸡皮疙瘩的东西。
SkillOpt 还有一个配套功能,叫 SkillOpt-Sleep。目前还是 preview 阶段。
它是干什么的?
你白天用 Codex 或者 Claude Code 写代码的时候,系统会把你所有的操作记录存下来。到了晚上,SkillOpt-Sleep 启动,开始做这几件事:
-
1. 把你白天的 session 翻一遍
-
2. 挖出你反复做的那些任务
-
3. 离线重放,分析哪里经常失败
-
4. 提出优化建议,过验证门控
-
5. 把通过的修改整理成一份候选 Skill
-
6. 第二天早上放到你面前,等你 review
这不就是"AI 在你睡觉的时候自己变强"吗?
关键是它不会自动部署。所有修改都是 staged for review——先摆在你面前,你点头了才合入。
你睡觉,它复盘。你醒了,它交作业。
这个思路有多妙?它把 AI 的"自我进化"从一个危险的黑盒操作,变成了一个可控的、可审查的离线流程。
但也要说清楚。目前 SkillOpt-Sleep 还非常早期,PyPI 0.1.0 版本的包里甚至还没正式包含这个模块——issue [#58](javascript:😉 就是在问这个事。要用的话得从 GitHub 源码安装。
把它当 preview 看,不要当成品接入。

五、请先把手从 pip install 上移开。
我知道有人看到这里已经蠢蠢欲动了。
先看数据,再决定要不要冷静。
论文里,SkillOpt 在 6 个 benchmark、7 个模型、3 种执行环境(普通对话、Codex CLI、Claude Code CLI)上做了测试。
结果是这样的——
52 个评测格子,全部最好或并列最好。没有任何一个格子被别人超过。
在 GPT-5.5 上,相对不用 Skill 的裸跑:
-
• 普通对话:+23.5 分
-
• Codex 环境:+24.8 分
-
• Claude Code 环境:+19.1 分
加上这些分之后什么概念?
原来 100 题错 40 道,现在只错大约 17 道。相当于一个及格边缘的学生,一下子跳到了班级前列。
而且最夸张的是:这些提升,不是靠写长 prompt 堆出来的。
最终产出的 best_skill.md,只有 300 到 2000 个 token——比你这条朋友圈还短。
而且在有些任务上,只改了 1 条规则,就涨了 39 分。
比如表格任务 SpreadsheetBench,原始成功率 41.8%。学了啥?就一条:
“先检查 workbook 的实际结构,再决定写静态值还是公式,不要依赖预览信息。”
改完,成功率拉到 80.7%。一条规则,翻了近一倍。
这说明什么?很多 AI agent 缺的不是知识,而是做事的顺序。
再比如数学任务里学到的一条:
“在最强陈述型多选题里,按定理强度给选项排序,优先选有理有据的更强结果选项,而不是选虽然对但更弱的推论。”
这些都不是知识点。是操作纪律。
SkillOpt 最擅长训练的不是知识,而是做事的顺序和方法。
OK,数据很强。但——
这些数字来自作者自己的实验。
用的是 GPT-5.5 这样的前沿模型,跑的是作者精心准备的 benchmark。
你自己的项目,任务分布不一样、工具环境不一样、验证集质量不一样。
论文数字说明它值得试。不说明它可以免测上线。

六、什么样的 Skill 适合优化?记住四个字:能被打分
SkillOpt 的论文相当诚实,专门有一节写了 Limitations。这在 AI 论文里不太常见。
它列出的适用范围,翻译成人话就四个字:能被打分。
展开说就是这四个条件:
第一,任务是可重复的。
一次性任务不值得训练。训练的成本要靠多次复用摊销。就像你不会为了一场考试去买一台打印机——但如果你每周都要考,那就不一样了。
第二,结果能自动评分。
测试通过了没有?JSON 格式对不对?回放状态符不符合预期?答案是不是精确匹配?必须有个裁判,而且要能自动判,不能每次都靠人看。
第三,同样的任务能重复跑。
新旧版本的 Skill 要在同样的题目上公平对比。如果你每次跑任务,数据库状态都不一样、网络环境都不一样,那就没法比了。
第四,Skill 真的能影响结果。
如果一个任务成败主要取决于模型本身的知识盲区、或者数据库里的脏数据,你改 Skill 也没用。
所以适合的方向是:编码 benchmark、API 调试回放、数据清洗、表格生成、文档问答——总之是有标准答案的任务。
不适合的也很明确:
-
• **创意写作、视觉设计。**审美这东西,你让三个设计师投票,三个都不一样。评分太主观。
-
• **部署、权限、资金操作。**一个自动优化器可能为了提高局部成功率,学到更快但不安全的路径。这个代价你付不起。
-
• **整个
AGENTS.md。**那东西是项目宪法。宪法不应该被自动改。它上面写的是"为什么不能这样做",不是为了某次 benchmark 多拿几分。 -
• **大杂烩 Skill。**如果一个文件里塞了十几种不相关的操作,先拆开。一个任务配一个 Skill,一个 Skill 配一个验证集。
最后给一个最直觉的判断标准:
你觉得这个任务能不能写一个自动判卷脚本? 能,那就适合。不能,那就谨慎。
七、它还很新。新到什么程度?连版本号都还带 Alpha。
把这些都交代了,我觉得还得再强调一下项目状态。
2026 年 6 月 15 号的数据:
-
• PyPI 版本:0.1.0
-
• 官方分类器:Alpha
-
• Open issues 里正在讨论:PyPI 包里到底有没有 SkillOpt-Sleep?Codex 插件 Windows 能跑吗?论文用的是哪个版本的 Claude Code CLI?多文件 Skill 怎么处理?
两周多的项目。有人在试用,有人在提 issue,有人在贡献 PR,还有人在半夜踩坑发 issue 问"为什么装了跑不起来"。
这些都是正常信号。一个开源项目的健康程度,某种程度上就体现在 issue 区的活跃度。
但对你来说,这意味着——把它当研究工具和实验框架,别急着接进生产。
最适合的姿势是:选一个窄任务 → 做一个小实验 → 产出候选 best_skill.md → 人工审核 → 分批合入。

八、如果你想试试,我建议你从这么小开始
不是说废话,给你一个真正可以照搬的起步方案:
第一步:选一个狭窄的任务。
不要碰 AGENTS.md。从一条具体的、边界清晰的工作流开始。比如:
-
• 把前端
/api/v3/data/*payload 转成计算层格式 -
• 对某类 API case 做回放验证
-
• 维护一套路由 JSON 的格式校验
第二步:攒 20 到 50 个真实样例。
拆成训练集、验证集、测试集三份。三份不能重叠。验证集在整个训练过程中锁死,不能偷看。
第三步:写一个自动评分器。
这个评分器必须是程序化的。输入是 agent 的操作结果,输出是 0 或 1 或者一个 0 到 1 之间的分。
这一步是整个流程里最难的。不是技术上难,是定义"什么叫做好"这件事本身就难。
第四步:初始 Skill 越短越好。
十行以内。不要把你全部经验塞进去。让 SkillOpt 自己加。你只给一个最基础的框架。
第五步:跑一次训练。
产出候选 best_skill.md。注意——**不要让它自动覆盖你的主 Skill。**只产生候选,人工审核。
第六步:审核 + 回归。
人先看一遍改了什么。然后跑项目最小的回归测试。都过了,再合入。
最后再说一句:
这里最难的不是装包。是验证集的制作。
没有验证集,SkillOpt 就退化成了一套华丽的 prompt 改写器。
有验证集,它才是一个真正的优化器。
把眼光拉远一点
SkillOpt 让我想了一个问题。
我们现在聊 AI agent 的能力,注意力基本都集中在模型本身——GPT 多强、Claude 多强、Qwen 多强。
但你想想:
一份 300 个 token 的 Markdown 文件,能把一个 agent 在某个任务上的成功率从 41.8% 拉到 80.7%。
不用改模型。不用 GPU。不用微调。就一份文本。
这件事本身就很震撼。
它说明:未来的 agent 能力,不只会藏在模型参数里。
它也会藏在一份经过了训练集训练、验证集筛选、被拒绝过很多次、最终活下来的 Markdown 里。
这个 Markdown 文件看起来不起眼。但它是可版本化的。可以被 clone、被 diff、被回滚。可以被 audit,也可以被拒绝。
它不再是一份经验文档。
它是一个可训练的资产。
而把"经验"变成"资产"的关键一步,不是让 AI 多想——
是让它先学会对自己说:
“对不起,这个改法不行,你回去重想。”
延伸阅读:
-
• GitHub: https://github.com/microsoft/SkillOpt
-
• 论文: https://arxiv.org/abs/2605.23904
-
• PyPI: https://pypi.org/project/skillopt/
-
• 官方文档: https://microsoft.github.io/SkillOpt/docs/guideline.html
-
• GitHub Issues: https://github.com/microsoft/SkillOpt/issues

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)