
AI Agent 的长短期记忆系统怎么做?记忆是怎么存的?

一、Agent 为什么需要记忆?
没有记忆的 Agent,很像一个“每次见面都重新认识你”的助手。你今天告诉它代码风格要简洁,明天再让它写脚本,它可能又回到默认风格。原因不是模型不聪明,而是它没有把关键偏好沉淀下来。
所以,Agent 记忆不是把所有聊天记录无限塞进 Prompt,而是把“当前任务状态”和“跨任务经验”分开管理:短期记忆负责当下任务不断片,长期记忆负责跨会话持续积累。
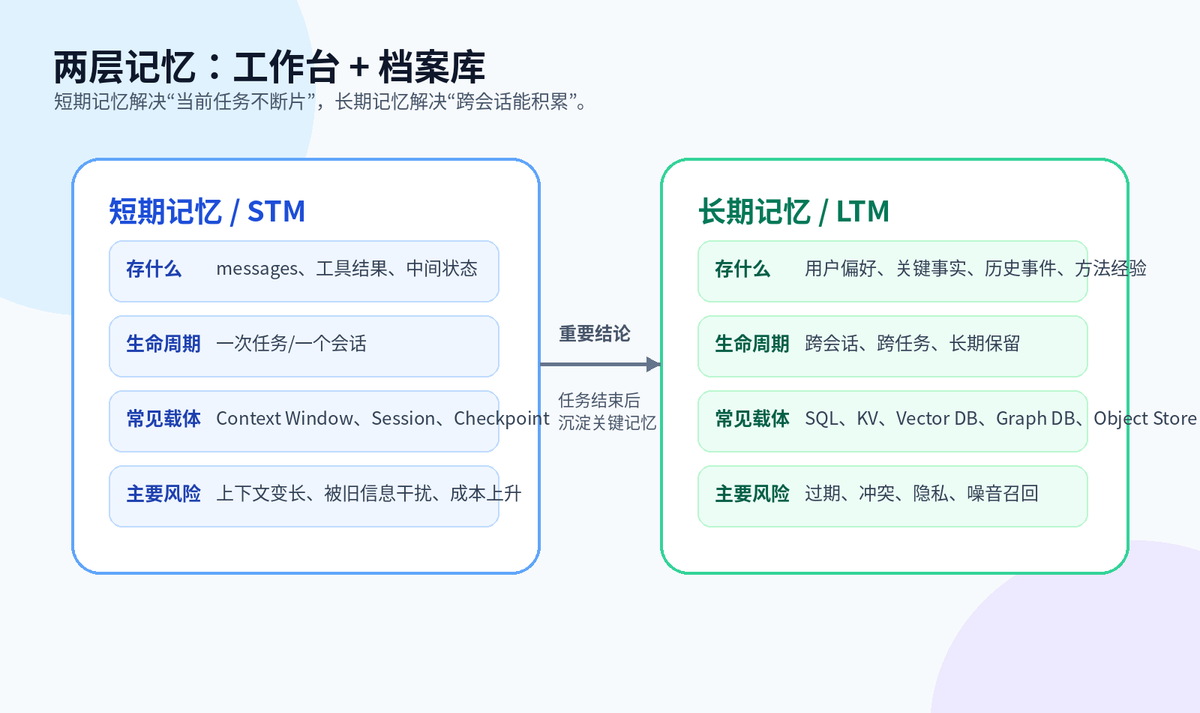
短期记忆与长期记忆的职责边界
二、一句话回答面试官
短期记忆通常存在当前会话的 messages、session 或 checkpoint 里,用来保存用户输入、模型输出、工具结果和任务中间状态;长期记忆通常存在持久化存储里,常见做法是“原文 + embedding + metadata”写入向量库,同时用 SQL/KV/图数据库保存权限、时间、版本、实体关系等结构化信息。
记忆粒度不能太细,也不能太粗。比较合理的是按“独立知识点”“关键事件”“一次完整交互摘要”来存。读取时也不能只拿向量 TopK,最好结合元数据过滤、时间衰减、重要度排序和重排。
三、短期记忆:LLM 当前任务的工作台
短期记忆最常见的形态,就是每次调用模型时传入的 messages 列表。它里面有用户的问题、模型刚才说了什么、调用工具得到了什么结果、当前任务进行到哪一步。
你可以把它理解成一张工作台:东西放在台面上,模型就看得见;台面太乱、太满,模型就容易被旧信息干扰,成本也会越来越高。
from dataclasses import dataclass, field
from typing import Literal
Role = Literal["system", "user", "assistant", "tool"]
@dataclass
class ShortTermMemory:
"""当前会话的工作台:只服务于当前任务。"""
messages: list[dict] = field(default_factory=list)
def add(self, role: Role, content: str):
self.messages.append({"role": role, "content": content})
def get_context(self) -> list[dict]:
return self.messages
def trim(self, max_turns: int = 12):
"""保留最近若干轮,避免上下文无限增长。"""
self.messages = self.messages[-max_turns:]在生产环境里,短期记忆通常还会加上“断点恢复”。比如 Agent 调用工具失败了、任务暂停了、用户刷新页面了,下次还能从 checkpoint 恢复,而不是从头来一遍。
四、长期记忆:跨会话的档案库
长期记忆存的不是所有聊天流水,而是未来还可能有价值的信息。例如用户偏好、项目背景、历史决策、常用流程、失败经验、实体关系。
这类记忆必须能被检索、能被更新、能被删除、能被审计。只说“存在数据库里”是不够的,真正要回答的是:存什么字段?怎么召回?怎么过滤权限?怎么处理旧记忆和新记忆冲突?
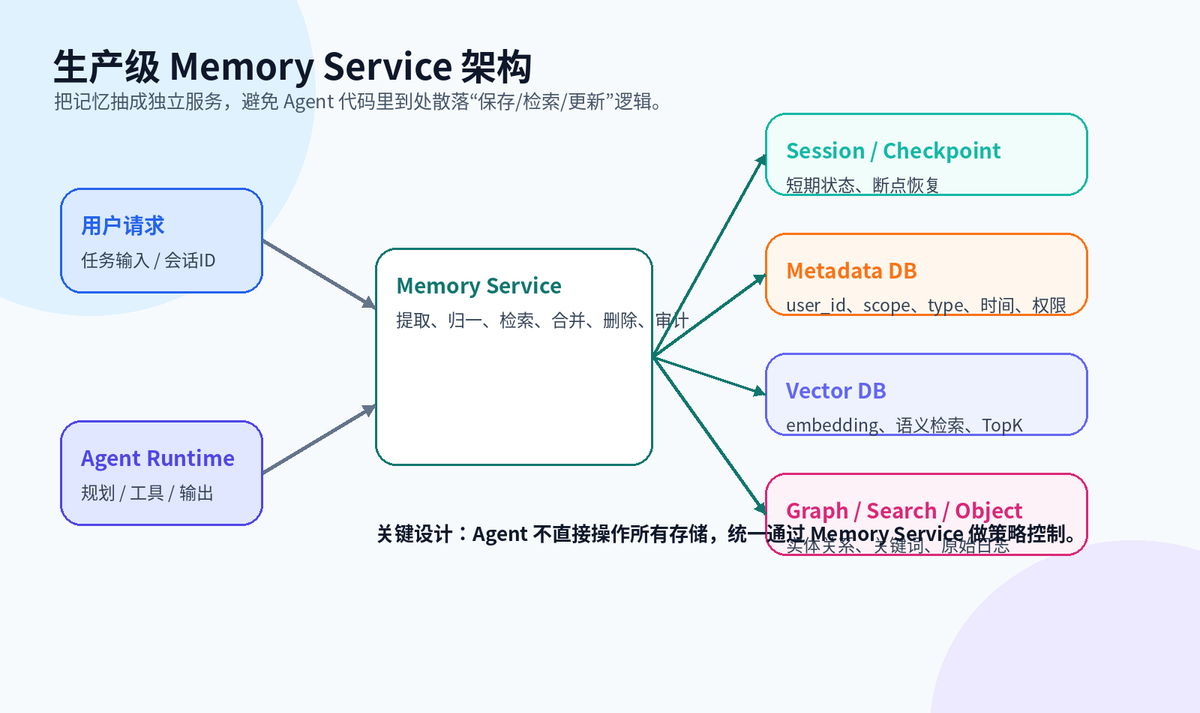
生产级 Memory Service 架构
五、记忆存储的完整闭环
一条记忆从产生到被使用,大致会经历八步:捕获、提取、结构化、向量化、存储、检索、注入、更新/遗忘。
这里最容易出错的是“只写不管”。如果只要用户说一句话就写入长期记忆,记忆库会很快变成垃圾堆。正确做法是先判断这条信息是否值得长期保存,再决定写入粒度、类型和有效期。
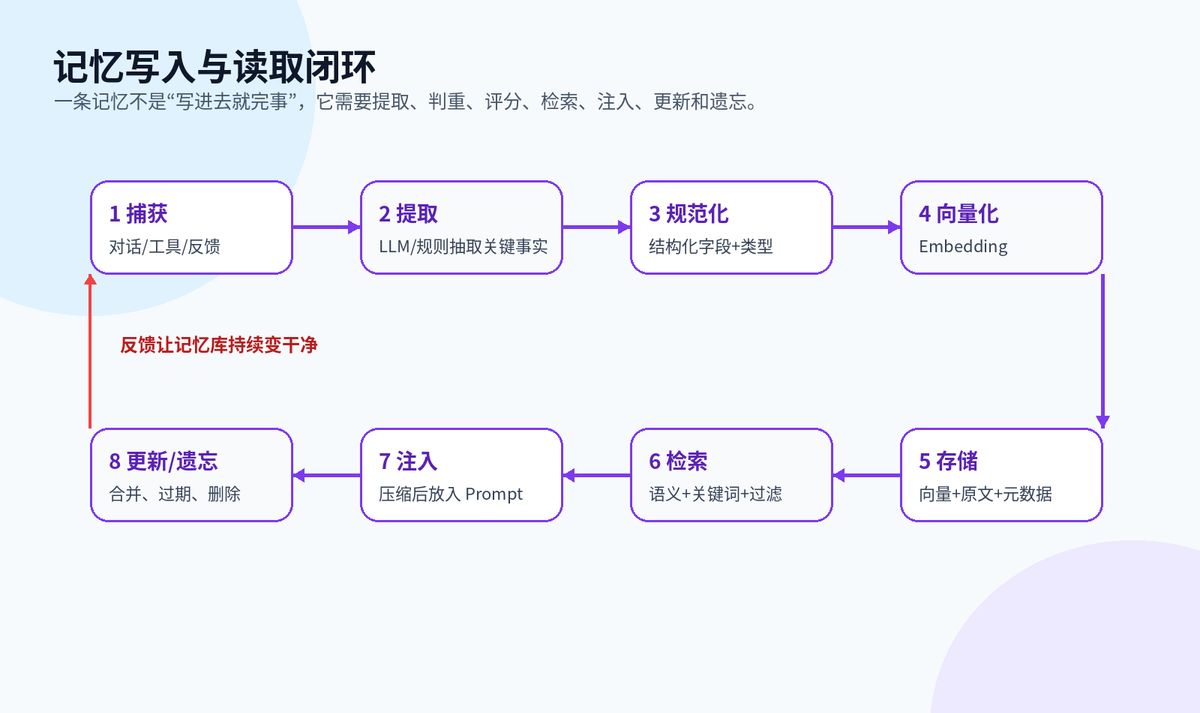
记忆写入与读取闭环
六、长期记忆到底存在哪?
向量数据库很重要,但它不是全部。向量库解决的是“语义相似召回”,不是权限管理、事务一致性、版本管理、原始日志归档和实体关系推理。
工程里更常见的是多存储组合:Redis 存热会话,Postgres 存结构化元数据,Vector DB 存语义索引,Elasticsearch 做关键词和混合检索,Graph DB 存实体关系,对象存储保留原始材料。
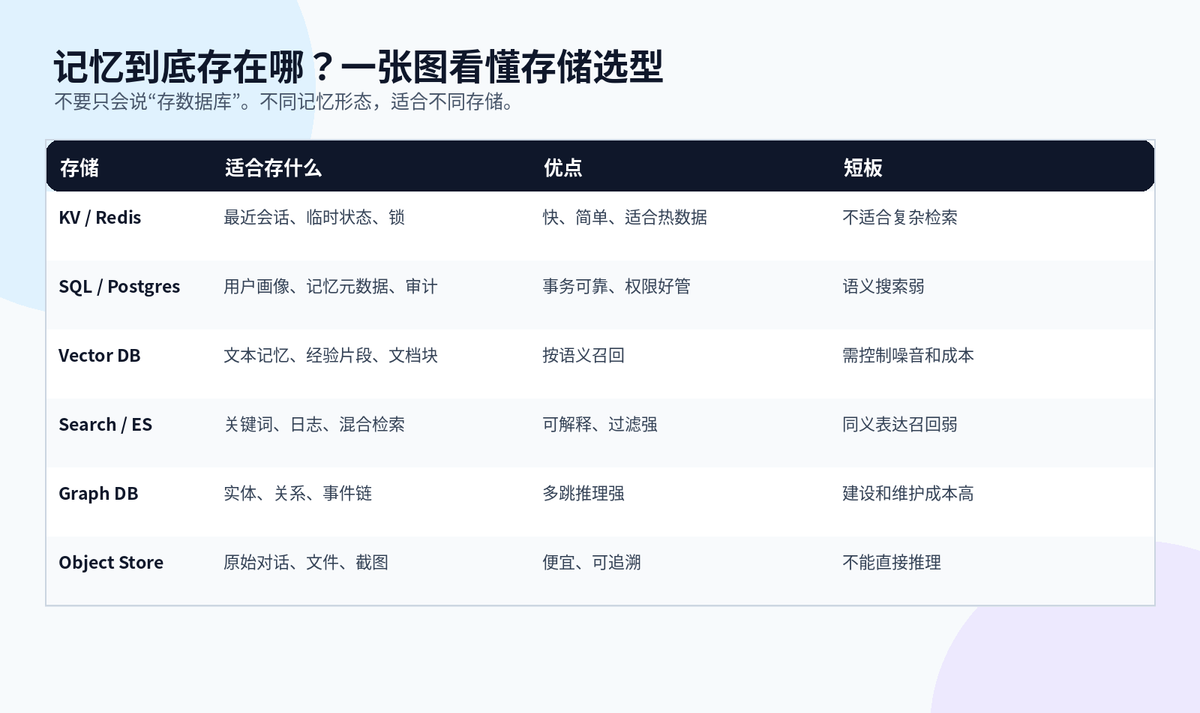
不同存储在记忆系统中的位置
七、一条长期记忆应该怎么设计?
长期记忆的核心不是 content 字段,而是 content、embedding、metadata、namespace、version、score、status 的组合。
content 是真正给 LLM 看的内容;embedding 是语义索引;metadata 负责过滤;namespace 负责隔离;version 和 status 负责更新、失效和删除。
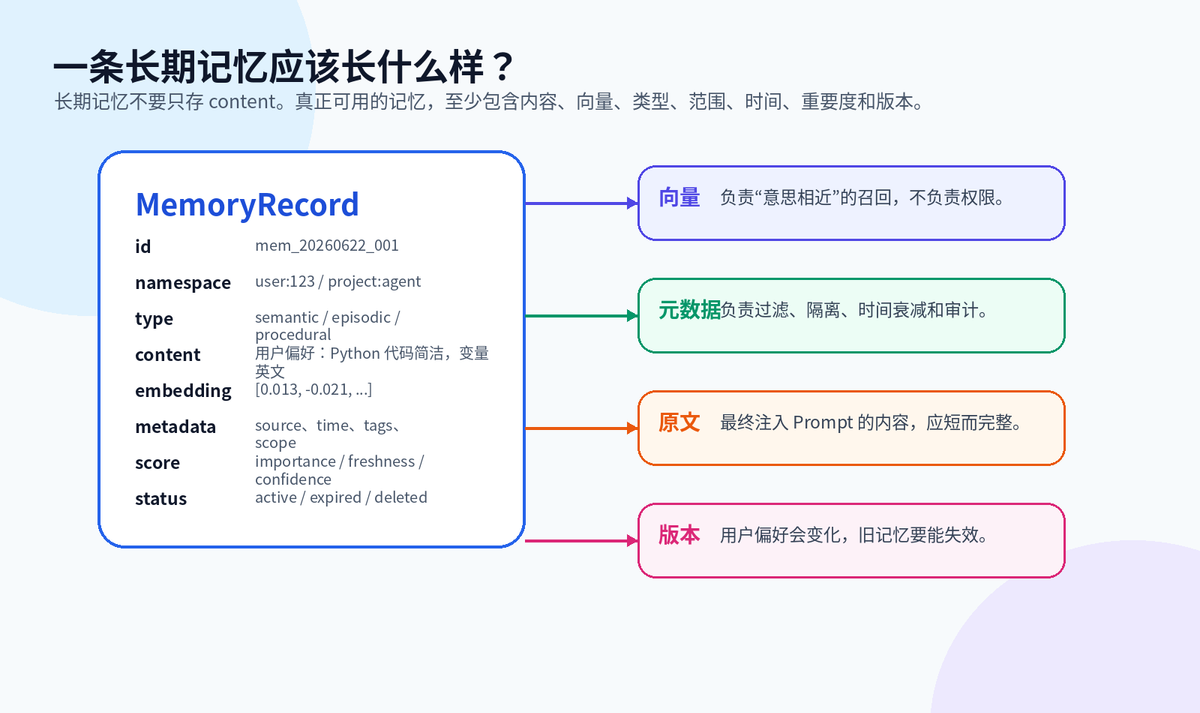
MemoryRecord 数据模型
from dataclasses import dataclass
from typing import Literal, Optional
from datetime import datetime
MemoryType = Literal["semantic", "episodic", "procedural"]
MemoryStatus = Literal["active", "expired", "deleted"]
@dataclass
class MemoryRecord:
id: str
namespace: tuple[str, ...] # 例:("user_123", "coding")
type: MemoryType # 语义 / 情节 / 程序记忆
content: str # 给 LLM 注入的短文本
metadata: dict # source、tags、scope、created_at
embedding: Optional[list[float]] = None
importance: float = 0.5
confidence: float = 0.8
status: MemoryStatus = "active"
created_at: datetime = datetime.utcnow()
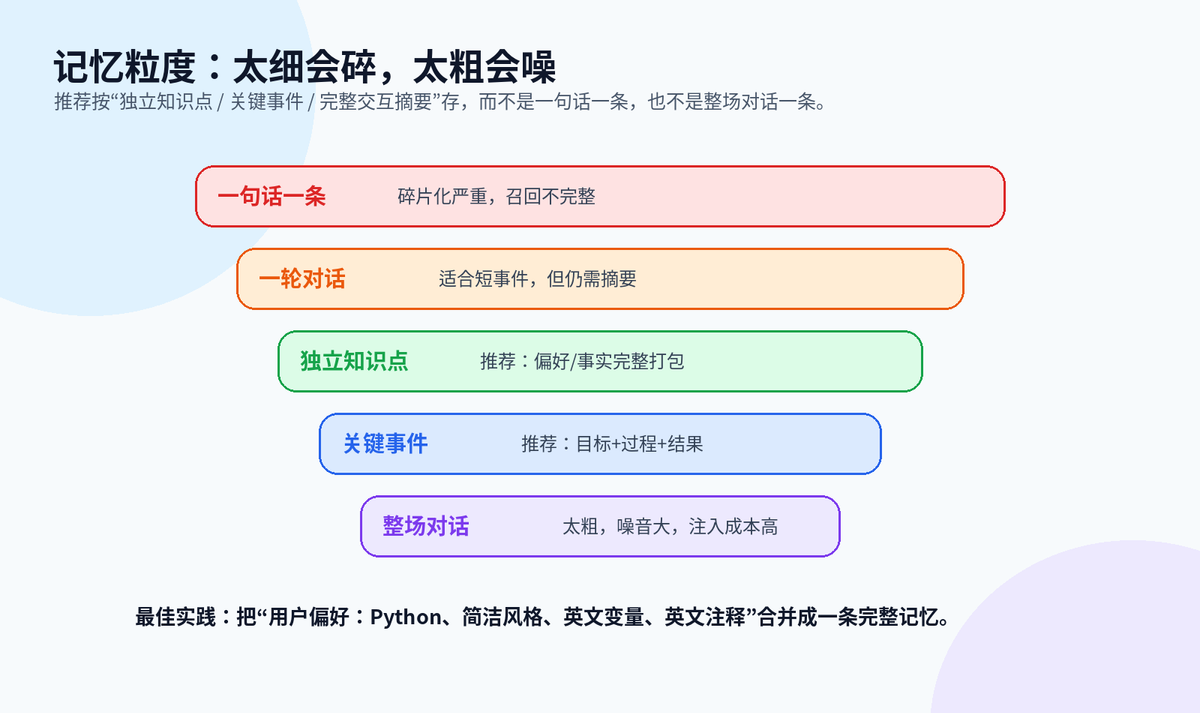
updated_at: datetime = datetime.utcnow()八、记忆粒度:不要一句话一条,也不要一整场对话一条
粒度太细,检索时容易只命中碎片,LLM 拿不到完整背景。粒度太粗,检索命中了也会带入大量无关内容,浪费上下文,还会干扰回答。
更推荐的粒度,是“一个独立知识点”或“一个关键事件”。比如“用户偏好 Python、代码简洁、变量英文、注释英文”应该合并成一条偏好记忆,而不是拆成四条。
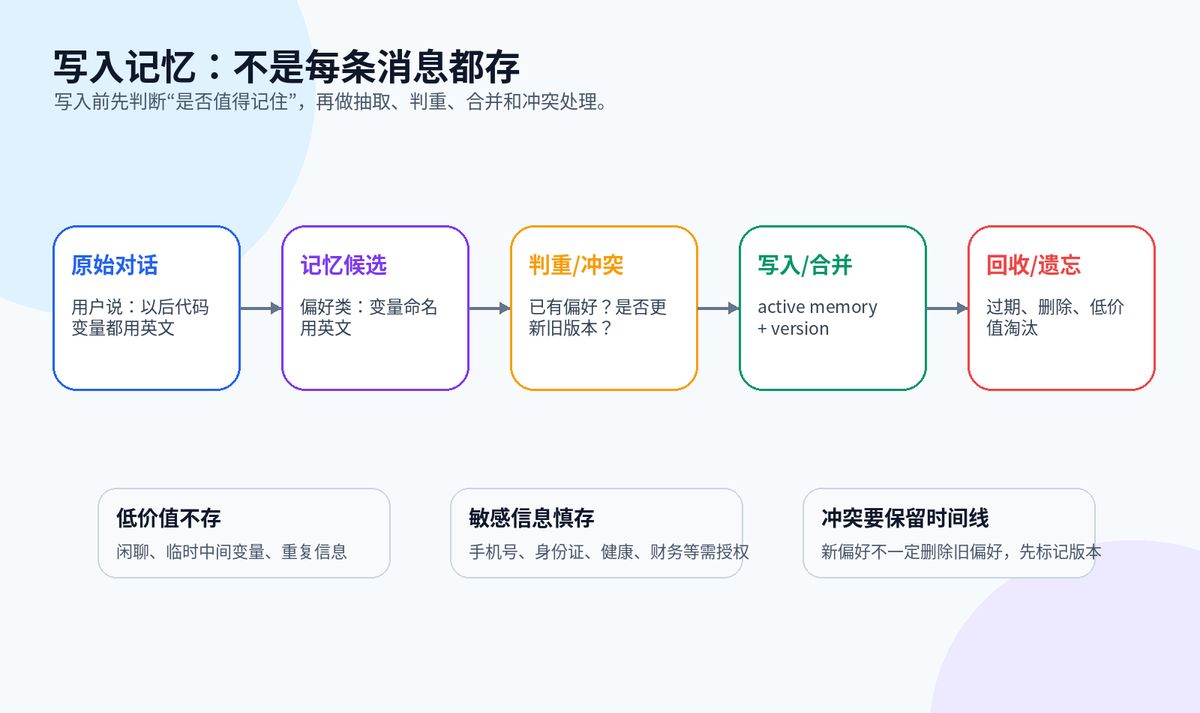
九、长期记忆怎么写入?
写入长期记忆之前,先做一个判断:这条信息以后还会不会影响 Agent 的行为?如果不会,就不要存。
真正可用的写入链路通常是:原始对话 -> 记忆候选 -> 重要性评分 -> 去重/冲突检测 -> 向量化 -> 写入存储 -> 记录审计日志。
def should_write_memory(candidate: dict) -> bool:
"""判断是否值得进入长期记忆。"""
if candidate["type"] not in {"semantic", "episodic", "procedural"}:
return False
if candidate.get("importance", 0) < 0.6:
return False
if candidate.get("contains_sensitive_data") and not candidate.get("user_allowed"):
return False
return True
async def save_memory(memory_store, embedder, record: MemoryRecord):
if not should_write_memory(record.metadata):
return None
# 1. 生成向量
record.embedding = await embedder.embed(record.content)
# 2. 用 namespace 做租户/用户/项目隔离
# 3. content 用于注入 Prompt,embedding 用于语义召回,metadata 用于过滤和审计
await memory_store.put(
namespace=record.namespace,
key=record.id,
value={
"content": record.content,
"type": record.type,
"metadata": record.metadata,
"importance": record.importance,
"confidence": record.confidence,
"status": record.status,
},
embedding=record.embedding,
)
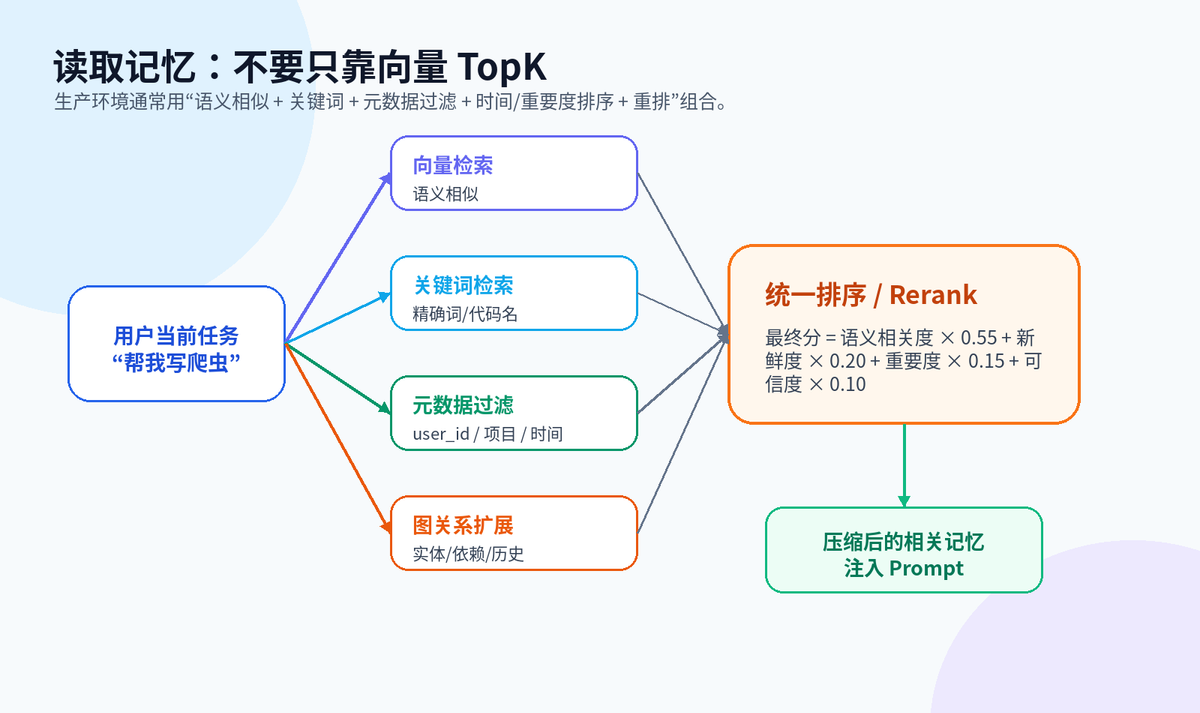
return record.id十、长期记忆怎么读取?
读取记忆时,千万不要简单地“向量 TopK 拿回来直接塞 Prompt”。这样很容易召回过期记忆、无权限记忆、低质量记忆。
更稳的方式是混合召回:先用 namespace 和 metadata 做过滤,再用向量检索找语义相似,再结合关键词检索补充精确匹配,最后按时间新鲜度、重要度、可信度做重排。
def rank_memory(semantic_score: float,
freshness: float,
importance: float,
confidence: float) -> float:
"""记忆排序公式:不要只看语义相似度。"""
return (
semantic_score * 0.55 +
freshness * 0.20 +
importance * 0.15 +
confidence * 0.10
)
async def retrieve_memories(memory_store, query: str, user_id: str, top_k: int = 5):
query_vec = await embedder.embed(query)
candidates = await memory_store.search(
namespace=(user_id, "global"),
embedding=query_vec,
filters={"status": "active"},
limit=30,
)
reranked = sorted(
candidates,
key=lambda m: rank_memory(
semantic_score=m.score,
freshness=m.metadata["freshness"],
importance=m.metadata["importance"],
confidence=m.metadata["confidence"],
),
reverse=True,
)
return reranked[:top_k]十一、更新与遗忘:长期记忆不是越多越好
用户偏好会变,项目状态会变,业务规则会变。如果长期记忆只追加不更新,时间久了反而会误导 Agent。
比较好的做法是:原始日志 append-only 保留用于审计;当前有效画像做可更新记录;旧记忆可以降权、过期、合并或标记删除。这样既保留历史,又不让旧信息污染当前决策。
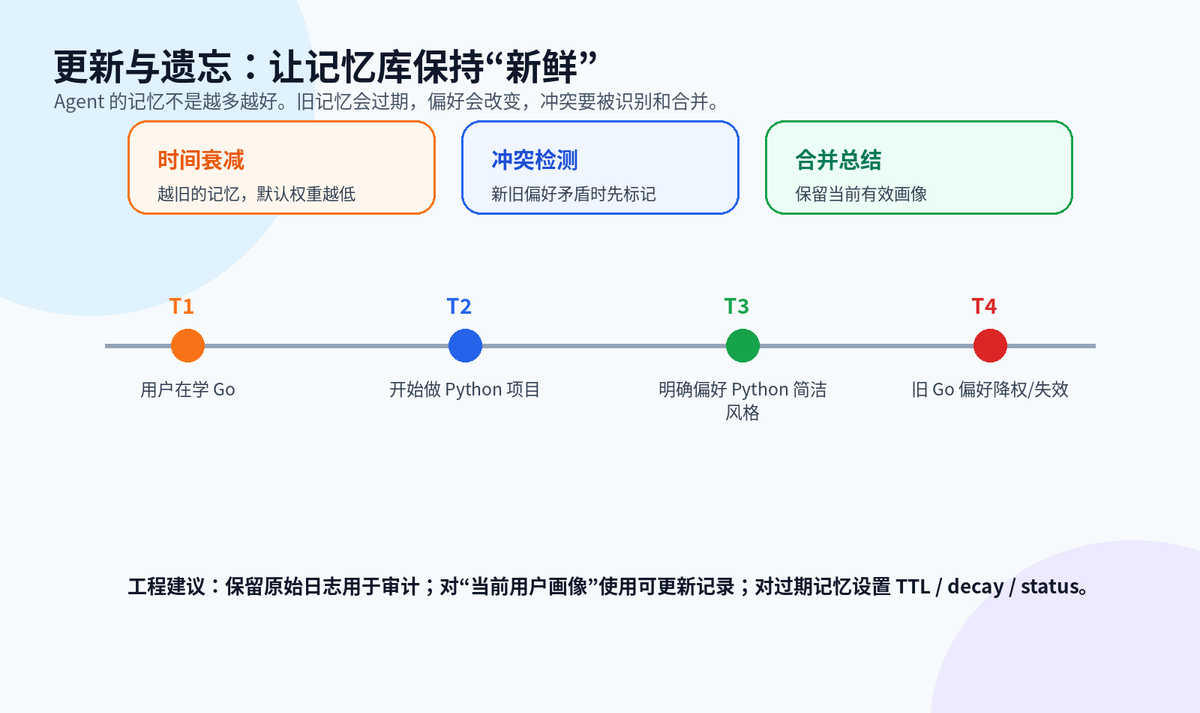
时间衰减、冲突检测与记忆合并
十二、安全治理:记忆越强,越要守边界
长期记忆会保存用户偏好、工作习惯、项目背景,甚至可能涉及敏感信息。只要跨会话保存,就必须设计用户可见、可改、可删的机制。
另外,检索出来的记忆不能直接当成最高优先级指令。记忆只是上下文,不应该覆盖系统安全策略,也不应该被用户通过 Prompt 注入污染。
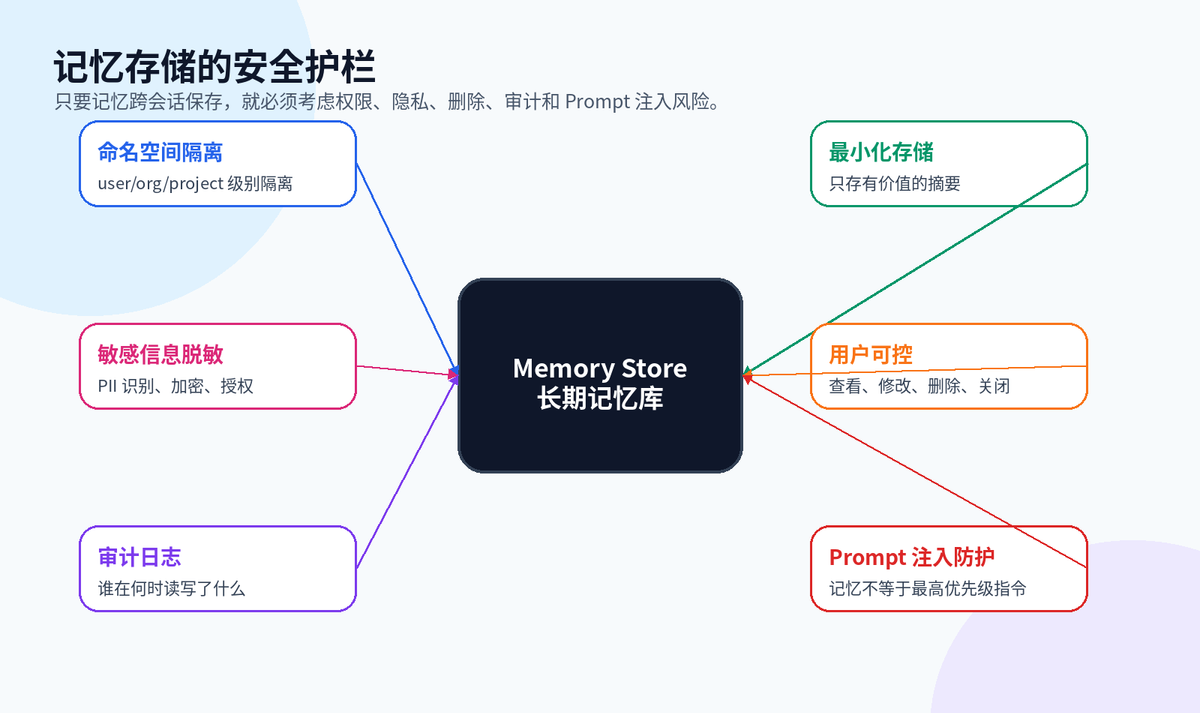
十三、一个更完整的 Agent 记忆执行流程
把上面的设计串起来,一个任务开始时先读取长期记忆,压缩后注入 Prompt;任务执行中靠短期记忆维持状态;任务完成后,再把真正有价值的新结论写入长期记忆。
async def run_agent_with_memory(user_id: str, user_request: str):
# 1. 读取长期记忆:只拿当前用户、当前任务相关的内容
memories = await retrieve_memories(memory_store, user_request, user_id, top_k=5)
memory_context = "\n".join([m.content for m in memories])
# 2. 初始化短期记忆:把相关长期记忆作为背景,而不是把所有历史塞进去
stm = ShortTermMemory()
stm.add("system", f"以下是与本次任务相关的历史记忆:\n{memory_context}")
stm.add("user", user_request)
# 3. Agent 执行任务:过程中持续追加工具结果和中间状态
result = await agent.run(stm.get_context())
stm.add("assistant", result.answer)
# 4. 任务结束:抽取真正值得长期保存的信息
candidates = await memory_extractor.extract(stm.get_context())
for candidate in candidates:
record = MemoryRecord(**candidate)
await save_memory(memory_store, embedder, record)
return result.answer十四、常见踩坑
把长期记忆理解成“SQL LIKE 查询”:关键词不重合时召回不到,必须引入 embedding 或混合检索。
把每句话都存成一条记忆:召回时拿到碎片,LLM 不知道完整偏好。
把整场对话存成一条记忆:内容太长,注入 Prompt 后噪音大。
只写入不更新:用户偏好变化后,旧记忆仍然被召回。
没有 namespace:不同用户、项目、组织之间的记忆可能串库。
没有审计和删除:用户不知道系统记住了什么,也无法撤回。
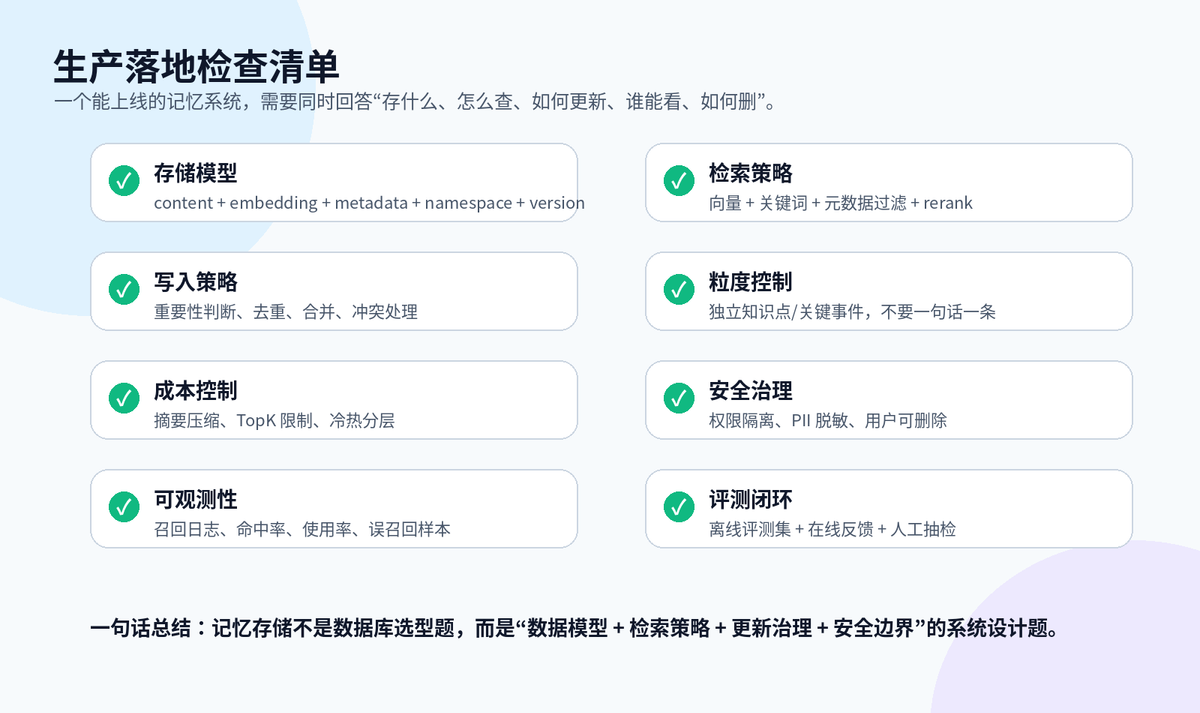
十五、总结
Agent 记忆系统,本质不是“多存点聊天记录”,而是一个可治理的数据系统。
短期记忆像工作台,服务当前任务;长期记忆像档案库,服务跨会话积累。短期记忆重点是压缩和恢复,长期记忆重点是粒度、检索、更新和权限。
真正能上线的方案,一定不是单一向量库,而是 Memory Service + 多存储组合:向量库负责语义召回,SQL/KV 负责结构化管理,搜索引擎补关键词,图数据库补实体关系,对象存储保留原始证据。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)