
什么是 AI Agent?从“大模型问答”到“自主执行者”的技术拆解
01 Agent 不是插件
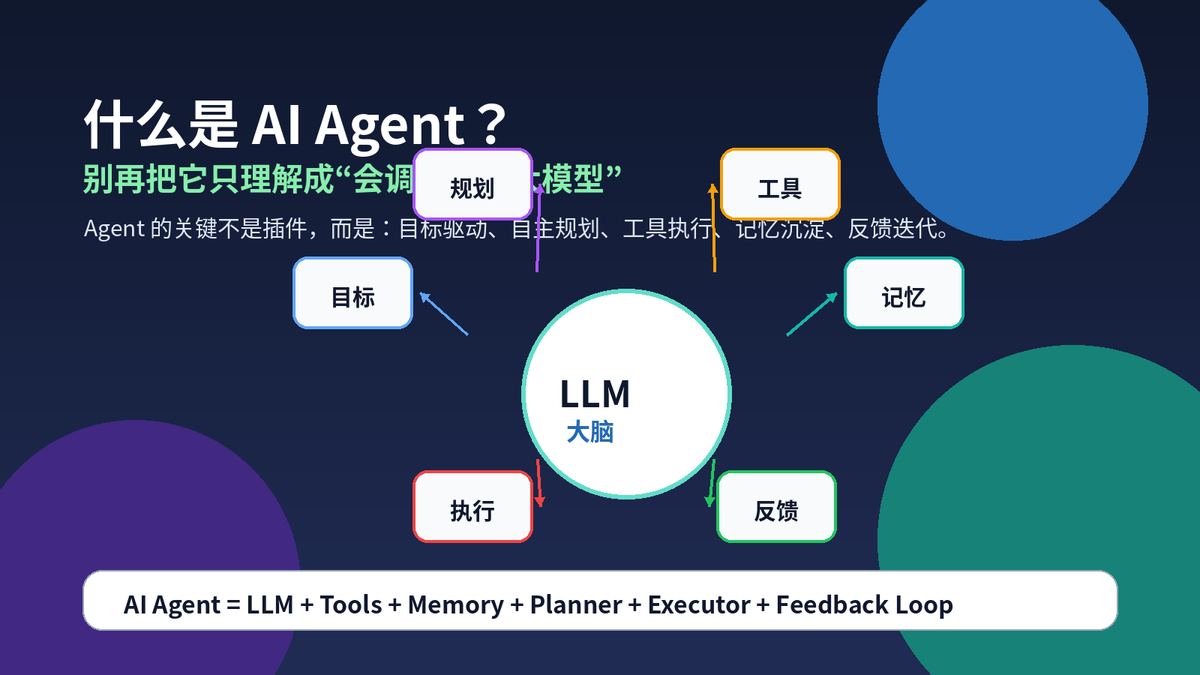
很多人第一次理解 AI Agent,会把它等同于“能联网”“能调插件”“能调用函数”。这个说法只说对了一小半。工具调用只是 Agent 的手脚,真正让它像“执行者”的,是目标驱动的自主闭环。
更准确的说法是:AI Agent 是一个以大模型为大脑,围绕目标自主规划步骤,调用外部工具执行动作,读取结果并继续调整,直到完成任务的 AI 系统。
|
一句话记住:普通 LLM 负责“生成答案”,Agent 负责“完成任务”。 |
这也是它和普通大模型最本质的区别。普通 LLM 更像答题机:你输入,它输出;Agent 更像项目执行者:你给目标,它自己拆任务、找工具、看结果、改计划。
02 普通大模型为什么不够用?
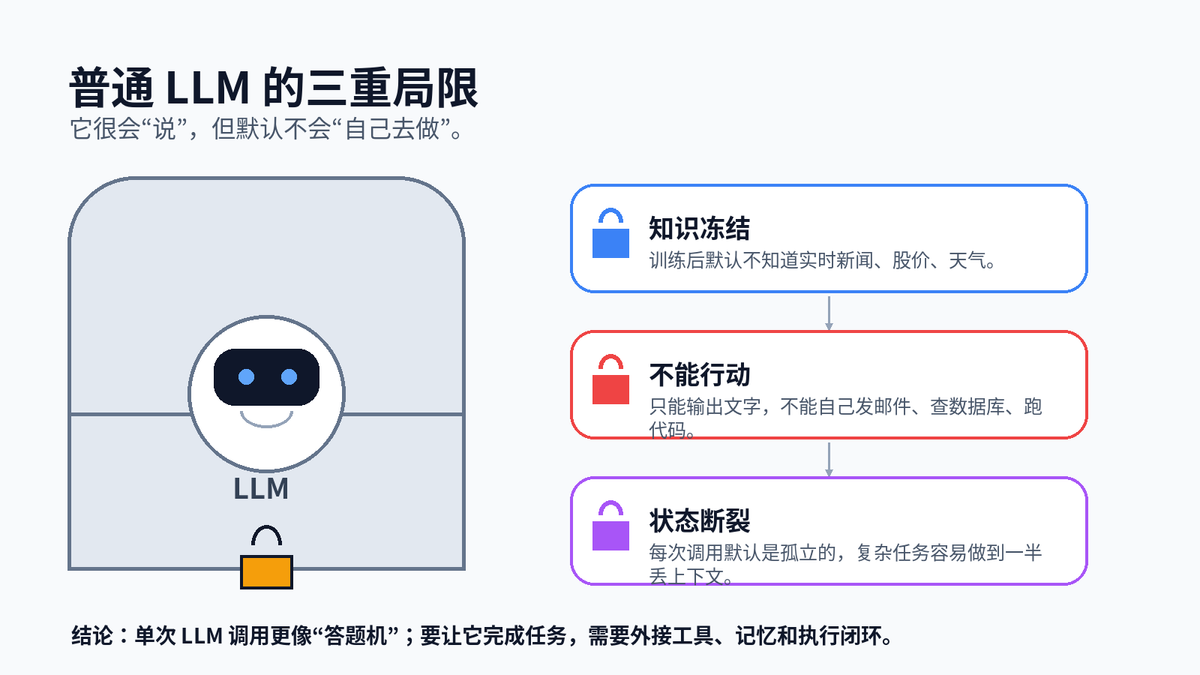
普通大模型并不是没价值,它适合写作、总结、改写、问答、代码解释。但如果你希望它自动完成一个复杂任务,就会遇到三个硬边界。
知识冻结:模型训练完成后,默认不知道实时信息,比如今天的天气、最新股价、刚发布的公告。
不能行动:模型本身只会生成文本,不会真正发邮件、查数据库、下订单、执行代码。
状态断裂:一次调用结束后,模型不会自动保留任务进度;复杂任务需要开发者额外维护上下文。
所以,普通 LLM 更适合“回答问题”。一旦任务变成“先查资料,再比对信息,再调用接口,再根据结果调整下一步”,就需要 Agent 架构。
03 Agent 的核心:感知、规划、行动、再感知
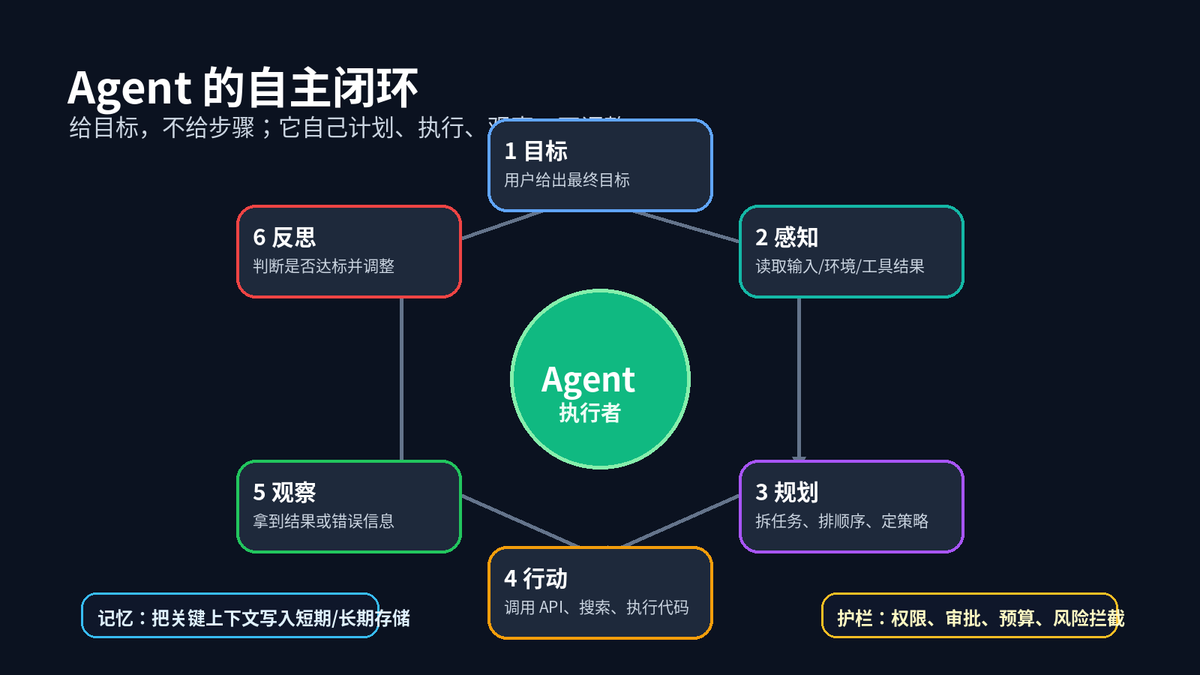
Agent 的核心不是某一个模型,也不是某一个工具,而是一套循环机制:先感知当前输入和环境,再规划下一步动作,然后执行工具,拿到观察结果后继续判断是否完成。
这套闭环可以拆成六个动作。
目标:用户给出最终目标,例如“调研三个竞品,生成一份对比报告”。
感知:读取用户输入、历史上下文、检索结果、工具返回值。
规划:把大目标拆成小步骤,决定先做什么、后做什么。
行动:调用搜索、数据库、代码执行器、邮件、企业 API 等工具。
观察:接收工具返回的数据、错误、状态码和中间结果。
反思:判断当前结果是否满足目标,不满足就换关键词、换工具、修参数、重新规划。
|
Agent 真正有价值的地方,是它能“边做边看结果”。这比一次性生成答案更适合复杂任务。 |
04 最容易混的四个概念:LLM、工具调用、Workflow、Agent

工具调用不是 Agent。Workflow 也不是 Agent。它们可以成为 Agent 的一部分,但不能直接划等号。
工具调用解决的是“模型怎么连接外部能力”。Workflow 解决的是“固定流程如何自动执行”。Agent 解决的是“路径不确定时,系统如何自己做决策”。
举个例子:每天 9 点生成报表并发送,这是 Workflow;用户说“帮我分析这家公司最近为什么大涨,并给出风险点”,需要搜索、读公告、对比行业、判断逻辑,这更像 Agent。
05 一个工程化 Agent 应该长什么样?
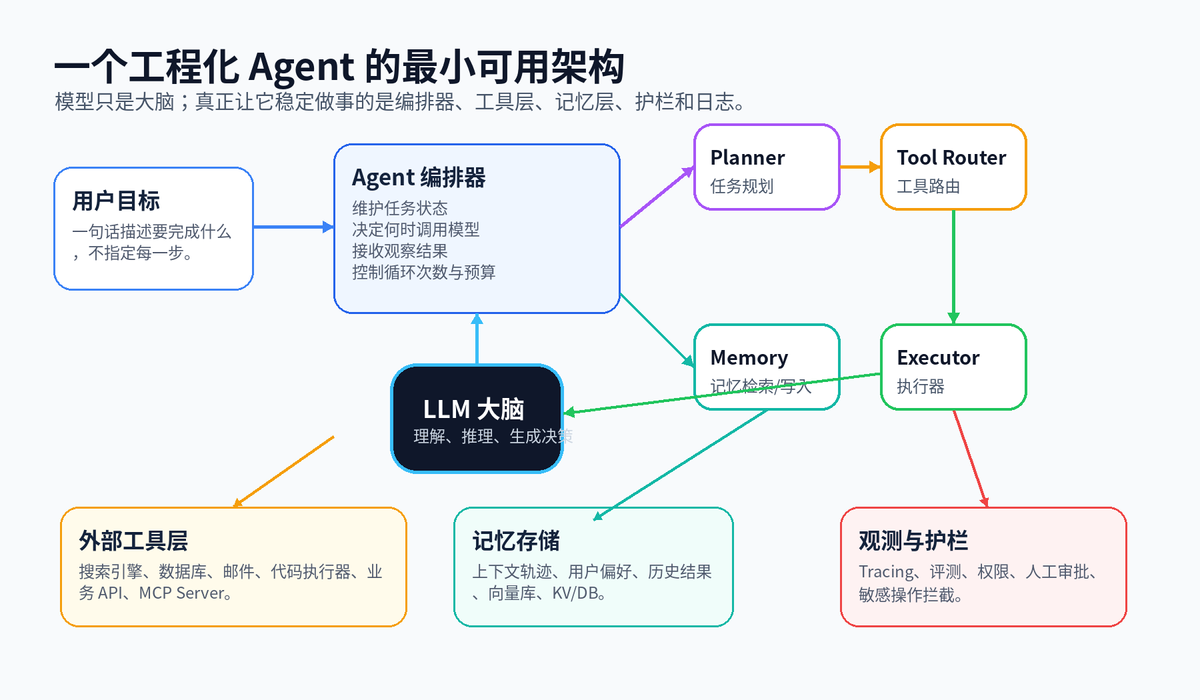
真正落地时,不要把 Agent 理解成“一个模型 + 一个 prompt”。在生产系统里,Agent 至少要有这几层。
LLM 大脑:负责理解任务、生成计划、选择工具、综合结果。
Planner 规划器:把目标拆成可执行步骤,必要时动态重排。
Tool Router 工具路由:根据模型决策选择工具,并做参数校验。
Executor 执行器:真正调用 API、数据库、搜索、代码沙箱等外部系统。
Memory 记忆层:保存任务轨迹、用户偏好、历史结论和可复用经验。
Guardrails 护栏:控制权限、预算、敏感操作、人工审批和风险拦截。
Observability 可观测:记录每次模型调用、工具调用、耗时、错误、重试和最终结果。
这里最重要的一点是:模型只负责“判断和生成调用意图”,真正执行工具的是你的业务代码。这个边界不清楚,系统就会变得危险。
06 工具调用:模型只是提出调用意图
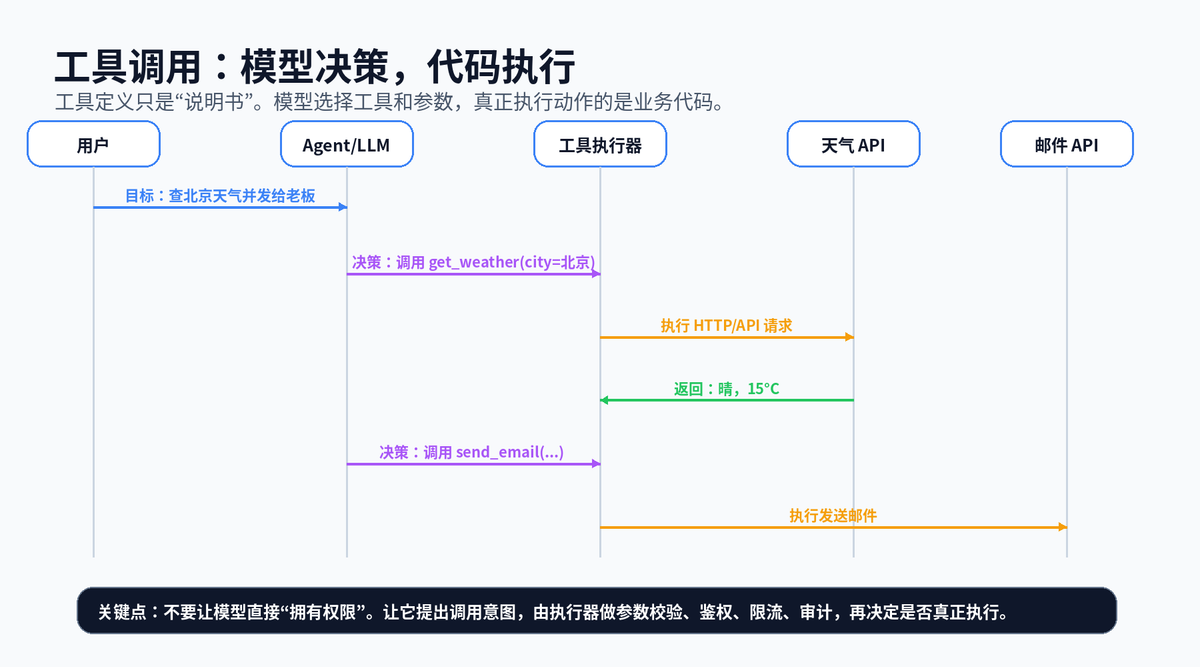
工具调用的本质,是把外部能力描述成结构化函数,让模型根据任务需要输出调用请求。调用请求通常包含工具名和参数,真正执行由应用程序完成。
例如,给 Agent 两个工具:查天气和发邮件。用户要求“查北京天气并发给老板”,Agent 不应该直接幻想一个天气结果,而应该先调用天气工具,再用真实结果组织邮件内容。
|
tools = [ |
这个设计有一个关键思想:决策和执行分离。模型决定“该不该调、调哪个、参数是什么”,执行器负责“能不能调、是否安全、是否有权限、是否真正执行”。
07 记忆机制:短期记忆管当前任务,长期记忆管跨任务经验
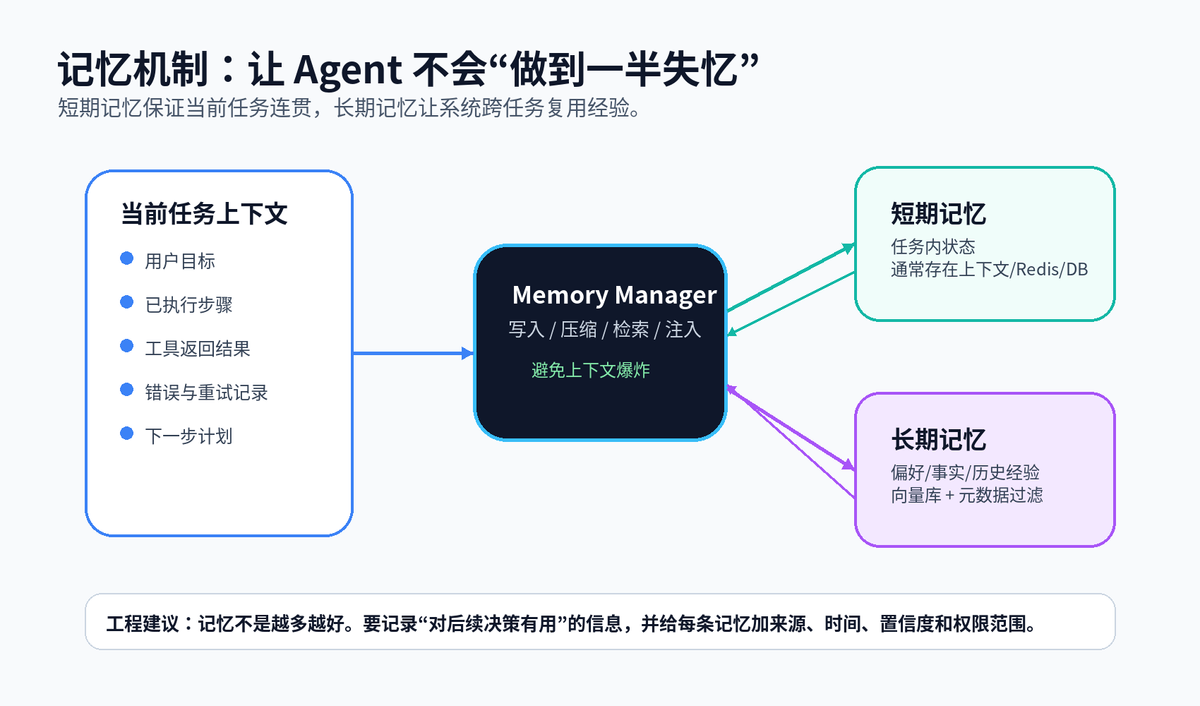
如果没有记忆,Agent 做复杂任务会像健忘的人:刚查到的资料、刚失败的工具调用、刚形成的判断,很快就被上下文冲掉。
常见做法是分两层。短期记忆保存当前任务的中间状态,例如已执行步骤、工具结果、错误信息、下一步计划。长期记忆保存跨任务有复用价值的信息,例如用户偏好、历史决策、业务规则和项目知识。
长期记忆通常会配合向量数据库使用。写入时把信息切成合适粒度,生成 embedding,带上来源、时间、权限、置信度等元数据;使用时根据当前任务做语义检索,再把最相关的记忆注入上下文。
|
记忆不是越多越好。越多越容易带来噪声、隐私风险和错误迁移。工程上要做过滤、过期、去重、权限控制和可追溯。 |
08 多步推理和自我纠错:Agent 为什么比脚本灵活
脚本的优势是稳定、便宜、可预测,但前提是流程已经确定。Agent 的优势是面对不确定任务时,能根据中间结果改变路线。
比如,搜索关键词 A 没有结果,它可以换关键词 B;数据库参数报错,它可以根据错误信息修正参数;某个 API 超时,它可以降级到备用工具;发现资料互相矛盾,它可以继续查证来源。
这就是 Agent 和普通自动化脚本的区别:脚本按预设路线跑,Agent 会在执行过程中不断观察和调整。
一个简化的 Agent 循环
|
while not done and step_count < max_steps: |
这个伪代码看起来简单,但生产系统难点都藏在细节里:循环次数怎么控、工具怎么限权、失败怎么重试、结果怎么评估、日志怎么追踪、用户何时介入。
09 为什么 Agent 这两年才真正爆发?
Agent 概念并不新。真正让它从概念走向工程实践,是几个条件同时成熟。
模型能力跨过门槛:强模型具备更好的指令遵循、规划、代码理解和工具选择能力。
工具调用标准化:函数调用和结构化输出让模型可以稳定产出工具名和参数,减少解析成本。
生态补齐:Agent SDK、LangChain/LangGraph、向量数据库、MCP、A2A、Tracing 和评测工具不断完善。
企业需求明确:客服、运营、研发、数据分析、办公自动化都需要“能做事”的 AI,而不只是聊天机器人。
这也是为什么现在很多公司不再只做 Chatbot,而是开始做客服 Agent、研发 Agent、数据分析 Agent、投研 Agent、运营 Agent。
10 MCP 与 A2A:Agent 生态的新接口
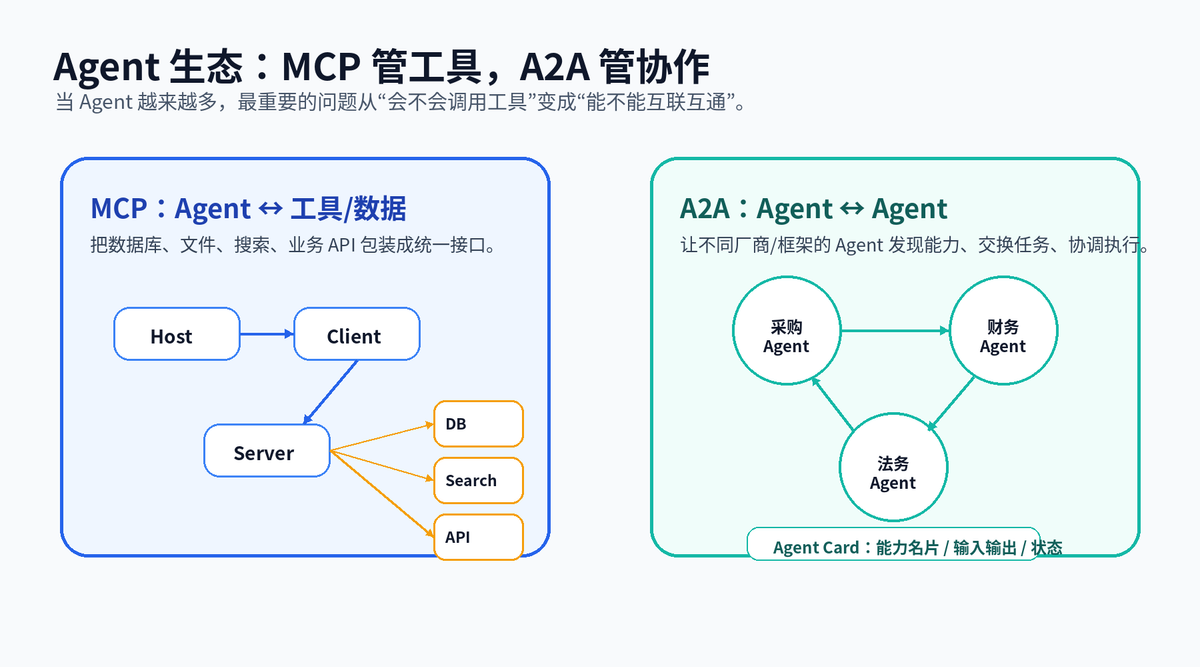
Agent 系统一多,就会出现两个问题:工具太多怎么统一接入?Agent 之间怎么协作?
MCP 更像 Agent 工具世界的标准接口。它把外部文件、数据库、搜索、业务 API 等能力包装成统一的 Server,让支持 MCP 的应用通过 Client 去发现和调用。它解决的是“Agent 怎么稳定连接工具和数据”。
A2A 关注的是 Agent 之间的通信。不同团队、不同厂商、不同框架开发的 Agent,需要知道彼此能做什么、任务状态是什么、输入输出是什么。A2A 通过类似 Agent Card 的能力描述,让 Agent 之间更容易发现和协作。
所以它们不是替代关系,而是互补关系:MCP 让 Agent 伸手拿工具,A2A 让 Agent 之间互相协作。
11 什么时候该用 Agent?

Agent 很强,但它不是银弹。越自主,越需要治理。越能行动,越需要权限控制。越能调用工具,越需要可观测和审计。
如果流程固定、规则明确、结果可预测,用传统 Workflow 更稳、更便宜。比如定时同步数据、审批流、固定报表、固定 ETL。
如果任务路径不确定,需要不断查资料、调用工具、根据结果调整策略,Agent 就更合适。比如自动调研、智能客服、代码修复、数据分析、知识库问答加工具执行。
|
技术选型原则:固定流程优先 Workflow;开放目标、路径动态、需要反馈迭代时,再上 Agent。 |
12 面试里怎么讲清楚 Agent?
可以用下面这段话快速回答。
|
AI Agent 是一个能围绕目标自主执行任务的 AI 系统。它以大模型为大脑,具备规划能力、工具调用能力、记忆能力和反馈闭环。普通 LLM 更像问答机,用户输入一次,它输出一次;Agent 则会把复杂目标拆成多步,调用外部工具真实行动,并根据每一步结果继续调整计划。工具调用只是 Agent 的一部分,不等于 Agent。Agent 的本质是“自主规划 + 行动能力 + 观察反馈 + 持续迭代”。 |
13 落地时最容易踩的坑
只写 prompt,不做状态管理:任务一复杂就丢上下文。
工具权限太大:模型一旦误判,可能触发真实业务风险。
没有循环上限:Agent 可能反复调用工具,导致成本和延迟失控。
没有人工审批:发邮件、下单、改数据库、删文件这类操作必须加审批或白名单。
没有可观测:出错后不知道是模型错、工具错、检索错还是权限错。
把 Agent 用在固定流程:本来一个规则引擎能解决,硬上 Agent 反而更不稳定。
14 总结
理解 Agent,不要从“插件”开始,而要从“闭环”开始。
普通大模型擅长生成内容,Agent 擅长围绕目标完成任务。它的关键能力包括:自主规划、工具调用、状态记忆、观察反馈、自我纠错和安全治理。
工程上,Agent 不是一个模型接口,而是一套系统架构。模型只是大脑,工具是手脚,记忆是上下文,编排器是流程控制,护栏是安全边界,可观测是生产保障。
如果一句话概括:Agent = 能自己拆任务、能调用工具做事、能记住过程、能根据结果继续调整的大模型应用系统。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)