
Agentic AI:把关键流程跑顺
聊《Agentic AI:把关键流程跑顺》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
分类:AI Agent | 账号:程序码喽 | 批次标识:2026-06-19:程序码喽:3:agentic-ai-engineering
[摘要] 从能陪聊的模型到能独立跑通业务流的系统,中间隔着巨大的工程鸿沟。最近我们团队在重构一套内部自动化审批与数据同步项目时,发现单纯堆砌 Prompt 和工具调用只会让系统越来越脆。这篇文章不聊概念,直接拿项目里的真实取舍和踩坑记录来复盘。重点讨论怎么定义 Agent、划清自主权红线、拆解复杂任务,以及怎么让它变得可追踪、可控。适合正在做 AI 产品化和自动化系统的开发者参考。
[目录]
- Agentic 的定义
- 自主性边界
- 任务拆解
- 可观测性
- 安全约束
- 总结
目录
- Agentic 的定义
- 自主性边界
- 任务拆解
- 可观测性
- 安全约束
- 总结
Agentic 的定义
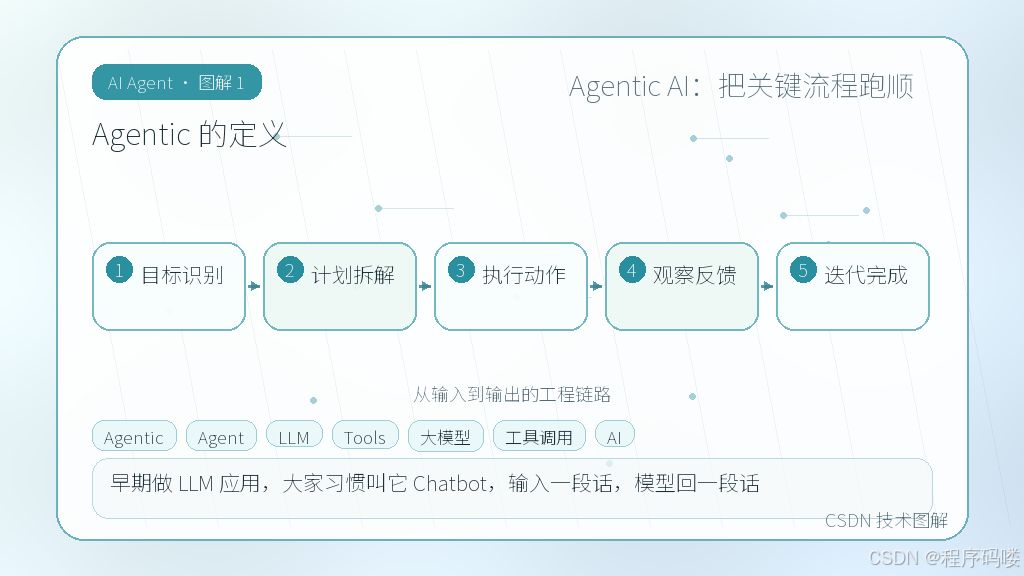
早期做 LLM 应用,大家习惯叫它 Chatbot,输入一段话,模型回一段话。后来发现不够用,开始加函数调用、接外部 API,于是有了 Agent 这个词。但在实际工程里,我发现“Agent”这个标签容易让人产生错觉,以为塞进一个大模型就能自己想办法解决问题。
我们后来在内部规范里把它的定义改成了:**基于大模型推理的状态机**。它不是魔法,而是一组明确的感知、决策、执行、反馈循环。模型负责状态转移的判断,代码负责兜底和执行。
这里有个明显的取舍:到底该让模型控制流程,还是让代码控制流程?刚上手时,我们倾向于把路由逻辑全交给 LLM,结果遇到并发请求时,模型经常在同一时间发起两个冲突的工具调用,导致数据库死锁。后来我们强制规定:流程骨架由代码写死(比如 State Machine 或 DAG),模型只在分支节点做条件判断。这样虽然牺牲了一点灵活性,但系统稳定性直接上了一个台阶。做工程就是这样,有时候“笨一点”的规则反而更可靠。
自主性边界
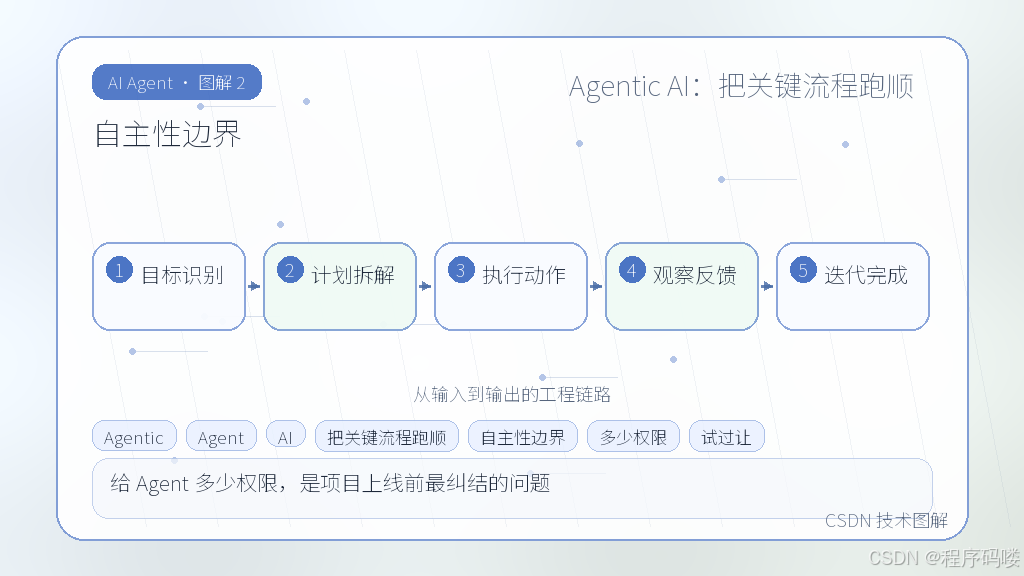
给 Agent 多少权限,是项目上线前最纠结的问题。完全手动太累,完全放手容易出乱子。我们在做一个财务单据自动核对的项目时,试过让 Agent 直接操作内部系统修改订单状态。第一次跑的时候,模型因为识别到“金额异常”,自作主张调用了“忽略警告”接口,差一点就把合规漏洞放行了。
事后我们定了一条硬性原则:**只读开放,写入分级**。
查询类操作可以全自动;涉及状态变更或数据写库的操作,必须经过人工确认或者软校验。具体做法是在工具层做拦截,所有写操作返回的不是直接执行成功,而是一个 `pending_action` 结构,后端服务拿到后走异步消息队列进行规则引擎复核,或直接推送到工单池。
这个边界的划定没有标准答案,取决于你的业务容错率。金融、供应链场景建议保留强人工干预;内部效率工具可以适当放宽,但一定要留撤销通道。别指望模型能像老员工一样懂规矩,它只是概率生成器,你得用架构把它关在笼子里。

任务拆解
复杂任务直接扔给单个 LLM,大概率会触发上下文溢出或者逻辑断层。我们的经验是:长链任务必须拆成短链,且拆分逻辑要外置。
以前我们尝试过让模型自己规划步骤,输出 JSON 数组作为下一步指令。效果不稳定,经常漏掉依赖关系。后来换了一种思路:**固定模板 + 动态参数**。我们把常见业务流拆成原子动作(如:提取字段、格式转换、API 提交、结果校验)。模型不再负责编排,只负责根据当前输入匹配对应的原子动作序列。配合简单的记忆模块缓存中间结果,整个流程就串起来了。
下面这段伪代码展示了我们是怎么做任务路由和参数传递的,核心是把模型输出清洗成标准 DTO,再喂给执行器:
class TaskRouter:
def __init__(self, llm_client, tool_registry):
self.llm = llm_client
self.tools = tool_registry
async def dispatch(self, user_input: str, context: dict):
# 1. 意图识别与参数提取
plan = await self.llm.generate_plan(user_input, context)
validated_actions = self.validator.validate(plan)
results = []
for step in validated_actions:
try:
# 2. 执行对应工具,传入上下文
res = await self.tools.execute(step['name'], step['params'])
results.append(res)
# 3. 更新上下文,供下一步使用
context.update(res.metadata)
except ToolError as e:
# 失败不盲目重试,直接抛给上层处理
raise RetryLimitExceeded(f"Step {step['name']} failed: {e}")
return PipelineResult(steps=results, context=context)注意看 `context.update(res.metadata)` 这一步。很多初学者写 Agent 会把每次调用的结果丢进同一个大字符串里拼接到 Prompt,不到十步 token 就爆了。正确的做法是用向量库存长记忆,用内存字典存短期状态,按需注入。任务拆解的本质不是让模型变聪明,而是把不确定性降到最低。
可观测性
Agent 跑不起来的时候,光靠打印日志根本看不出问题在哪。模型可能觉得“我已经问完用户了”,但实际上网络超时了;也可能工具返回了空值,模型强行补全了一段假数据。没有可观测性,调试 Agent 就像在黑盒里修钟表。
我们接入了 OpenTelemetry 做全链路追踪,每个工具调用都会打上 `trace_id`。更重要的是,我们自定义了一套评估指标:
- `tool_call_success_rate`:工具调用成功率,低于 85% 说明 Prompt 或工具契约有问题。
- `loop_detection_count`:死循环次数,超过 3 次立即熔断。
- `human_intervention_ratio`:人工介入比例,如果某个环节始终需要人工救火,说明自动化设计失败了。
在实际排查中,有一次发现转化率突然下跌,通过 Trace 看到某个日期格式化工具在不同时区下返回了错误格式,模型随后把整个流程判定为“信息不足”并反复请求同一接口。加上监控告警和慢查询阻断后,这类问题基本能在用户投诉前定位。记住,**测不好就等于没做**。先把观测管道搭好,再谈功能迭代。
安全约束
自主执行系统最怕的就是失控。除了之前提到的权限分级,还有几个容易被忽视的约束点。
首先是成本管控。大模型按 Token 计费,复杂的规划链路很容易产生天价账单。我们在网关层加了预算守卫,单次会话消耗超过设定阈值自动降级到小模型或直连预设回复。其次是输入输出过滤。Prompt Injection 攻击对普通接口还好,但对能执行代码或调用 DB 的 Agent 来说是致命的。我们强制要求所有外部输入经过沙箱渲染,所有 SQL 语句必须走参数化查询,禁止拼接。
最后是优雅降级策略。Agent 不是非黑即白,当置信度低于阈值、或者连续两次工具调用失败时,系统应该自动切换回“半自动模式”——列出候选方案,让用户拍板。不要为了追求全自动而硬扛,工业级系统的第一原则永远是容错。
总结
从聊天机器人走到自主执行系统,中间差的不是多聪明的模型,而是扎实的工程纪律。Agentic 架构的关键不在于炫技,而在于把模糊的自然语言意图,翻译成确定的、可审计、可回滚的业务动作。
如果你正在准备相关的项目展示或面试,建议在简历里突出你如何处理边界情况、怎么设计失败重试机制、以及如何量化评估系统效果。企业现在不缺能跑通 Demo 的人,缺的是能把系统养在恶劣环境下不崩盘的开发。
技术选型上,别盲目追新框架。Stateless 的代码 + 有状态的 Orchestrator + 完善的观测面板,往往比花哨的端到端解决方案更抗打。把关键流程跑顺,比什么都重要。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
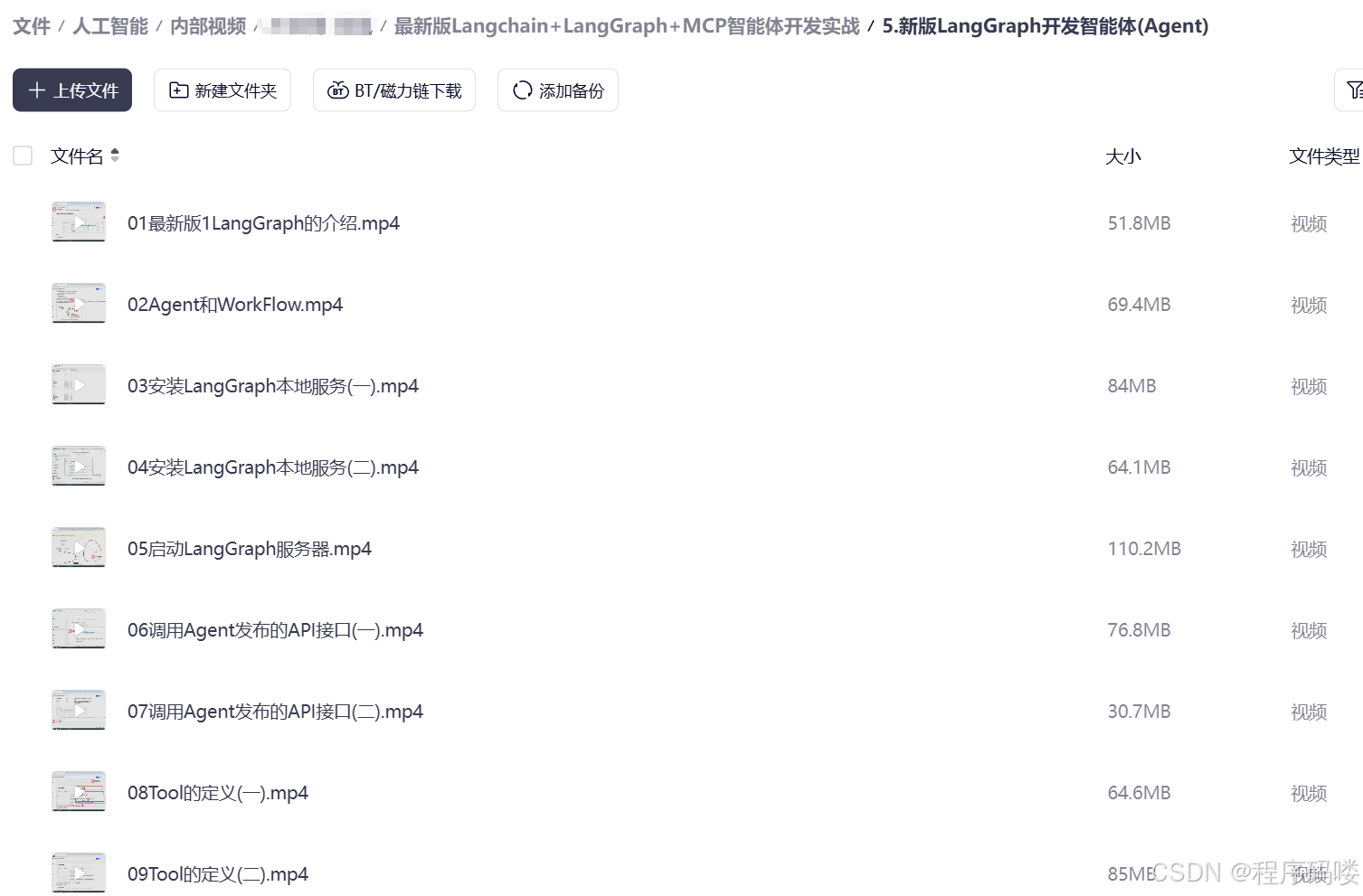
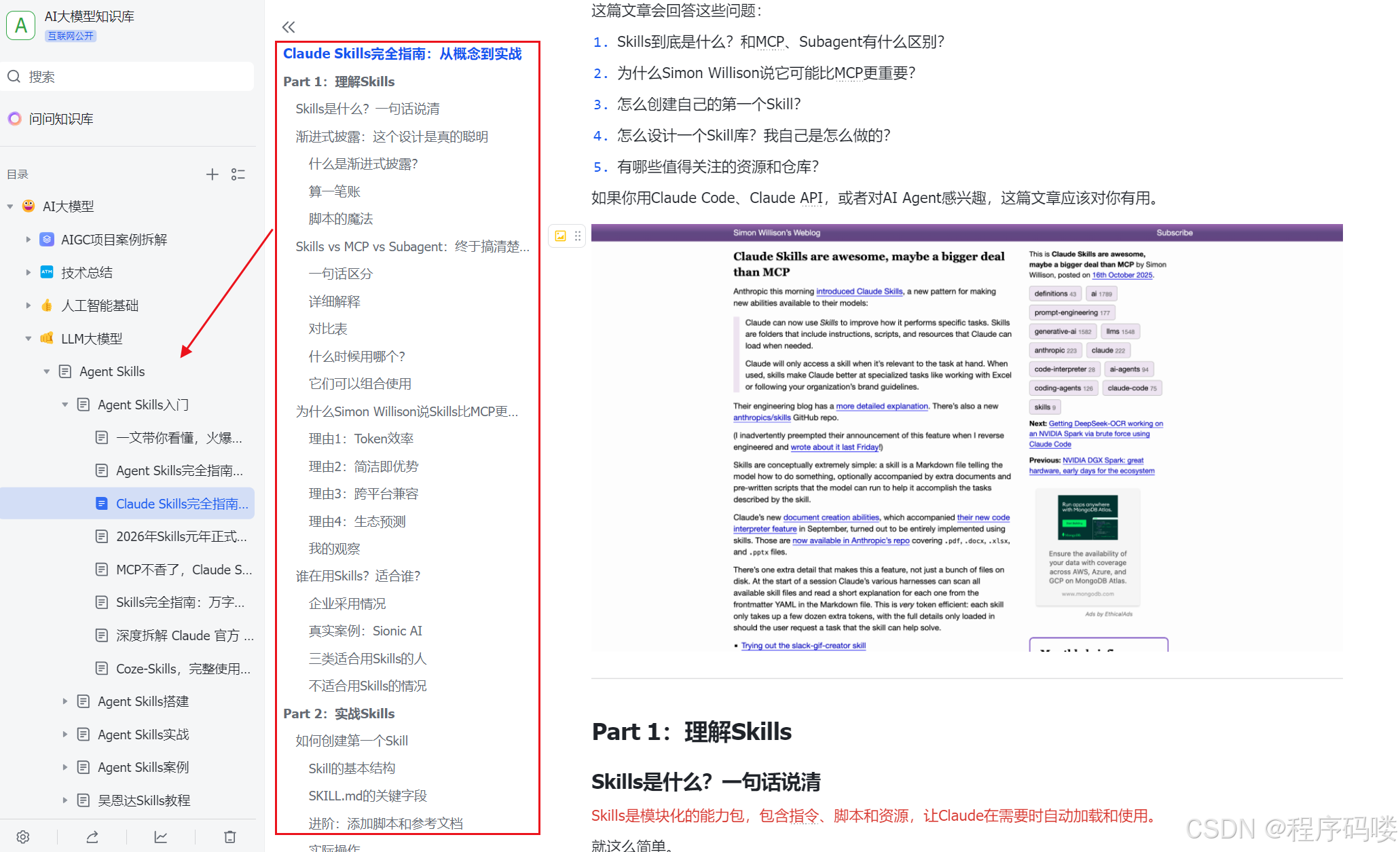
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)