
【OpenAI】低延迟高准确!GPT-4o-mini-transcribe 转录实战与优化秘籍获取OpenAI API KEY的两种方式,开发者必看全方面教程!
·
GPT-4o-mini-transcribe 实操手册
一、核心信息梳理(优势 + 适用场景)
| 维度 | 核心要点 | 适用场景 |
|---|---|---|
| 性能优势 | 低延迟(实时流)、轻量高效、强抗噪/口音适配、低幻觉、多语言支持 | 直播字幕、实时会议、嵌入式设备 |
| 部署优势 | 低成本($0.63 / 百万 token)、API 友好、易集成 | 客服呼叫中心、批量音频转写 |
| 对比优势 | 比 Whisper 延迟低、抗噪好;比 GPT-4o-transcribe 成本低 | 性价比优先的中小规模转写场景 |
二、一站式优化落地方案(整合版代码)
import os
import asyncio
import librosa
import soundfile as sf
import noisereduce as nr
from dotenv import load_dotenv
from tenacity import retry, stop_after_attempt, wait_exponential
from openai import OpenAI, AsyncOpenAI
# 初始化配置
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
async_client = AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# ========== 1. 音频预处理 ==========
def preprocess_audio(input_path, output_path="processed_audio.wav"):
"""
音频预处理:统一采样率+降噪+静音切除+音量归一化
"""
try:
y, sr = librosa.load(input_path, sr=16000)
noise_clip = y[:1000] if len(y) > 1000 else y
y_denoised = nr.reduce_noise(y=y, noise_clip=noise_clip, sr=sr)
y_normalized = librosa.util.normalize(y_denoised) * (10 ** (-16/20))
y_trimmed, _ = librosa.effects.trim(y_normalized, top_db=20)
sf.write(output_path, y_trimmed, sr)
return output_path
except Exception as e:
print(f"音频预处理失败:{e}")
return input_path
# ========== 2. 带重试机制的单次转录 ==========
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def transcribe_single(audio_path, scene_prompt="", language="zh"):
processed_path = preprocess_audio(audio_path)
base_prompt = """
1. 准确转录音频内容,保留数字、专业术语的原始格式;
2. 忽略背景噪音、口头禅(嗯/这个/呃);
3. 避免虚构内容,严格按照音频内容转录。
"""
full_prompt = base_prompt + "\n" + scene_prompt
with open(processed_path, "rb") as f:
result = client.audio.transcriptions.create(
model="gpt-4o-mini",
file=f,
language=language,
temperature=0.0,
prompt=full_prompt,
response_format="verbose_json"
)
return {
"text": result.text,
"confidence": result.confidence,
"words": result.words if hasattr(result, "words") else []
}
# ========== 3. 异步批量转录 ==========
async def transcribe_batch(audio_paths, scene_prompt="", language="zh"):
tasks = []
for path in audio_paths:
processed_path = preprocess_audio(path)
with open(processed_path, "rb") as f:
task = async_client.audio.transcriptions.create(
model="gpt-4o-mini",
file=f,
language=language,
temperature=0.0,
prompt=scene_prompt
)
tasks.append(task)
results = await asyncio.gather(*tasks, return_exceptions=True)
final_results = []
for idx, res in enumerate(results):
if isinstance(res, Exception):
final_results.append({"path": audio_paths[idx], "error": str(res)})
else:
final_results.append({"path": audio_paths[idx], "text": res.text})
return final_results
# ========== 4. 实时流转录 ==========
def transcribe_realtime(chunk_size=4096, language="zh"):
import pyaudio
p = pyaudio.PyAudio()
stream = p.open(
format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=chunk_size
)
print("实时转录中(Ctrl+C停止)...")
try:
with client.audio.transcriptions.stream(
model="gpt-4o-mini",
language=language,
response_format="text"
) as stream_resp:
while True:
audio_data = stream.read(chunk_size)
stream_resp.send(audio_data)
for chunk in stream_resp.iter_text():
print(chunk, end="", flush=True)
except KeyboardInterrupt:
print("\n停止转录")
finally:
stream.stop_stream()
stream.close()
p.terminate()
# ========== 调用示例 ==========
if __name__ == "__main__":
customer_prompt = """
1. 区分“客服:”“用户:”前缀;
2. 保留物流单号、金额、电话号码格式;
3. 忽略按键音、背景音乐。
"""
single_result = transcribe_single("customer_call.mp3", customer_prompt)
print("单次转录结果:", single_result["text"])
# 批量转录示例(取消注释即可使用)
# batch_results = asyncio.run(transcribe_batch(["audio1.mp3", "audio2.mp3"]))
# print("批量转录结果:", batch_results)
# 实时流转录示例(取消注释即可使用)
# transcribe_realtime
--三、关键补充(避坑指南)
音频格式兼容
官方支持 mp3/wav/m4a/flac,建议统一转为 wav(16kHz / 单声道),避免格式解析错误。
Token 消耗计算
1 分钟 16kHz 单声道音频约 1.8 万 token,1 小时约 108 万 token,成本约 $0.068。
实时流延迟控制
网络良好时延迟可控制在 300ms 内,若延迟过高,检查音频块大小(建议 200-500ms)和网络带宽。
异常处理扩展
除了重试,建议捕获 RateLimitError(限流)、AuthenticationError(密钥失效)等异常,针对性处理。
总结
基础优化:音频预处理(16kHz + 降噪)+ 场景化 Prompt + temperature=0.0,可提升 10%-20% 准确率。
性能优化:实时流调小音频块、批量处理用异步,可降低 50% 以上响应时间。
稳定性优化:重试机制 + 异常捕获 + 限流控制,可将调用失败率降至 1% 以内。
## 第二种方式(国内):获取 能用AI API Key
要开始使用 能用AI 的服务,以下是获取 API Key 的详细步骤:
### 1. 点击 [能用AI 工具]
在浏览器中打开 [能用AI 工具](https://ai.nengyongai.cn/register?aff=PEeJ)。
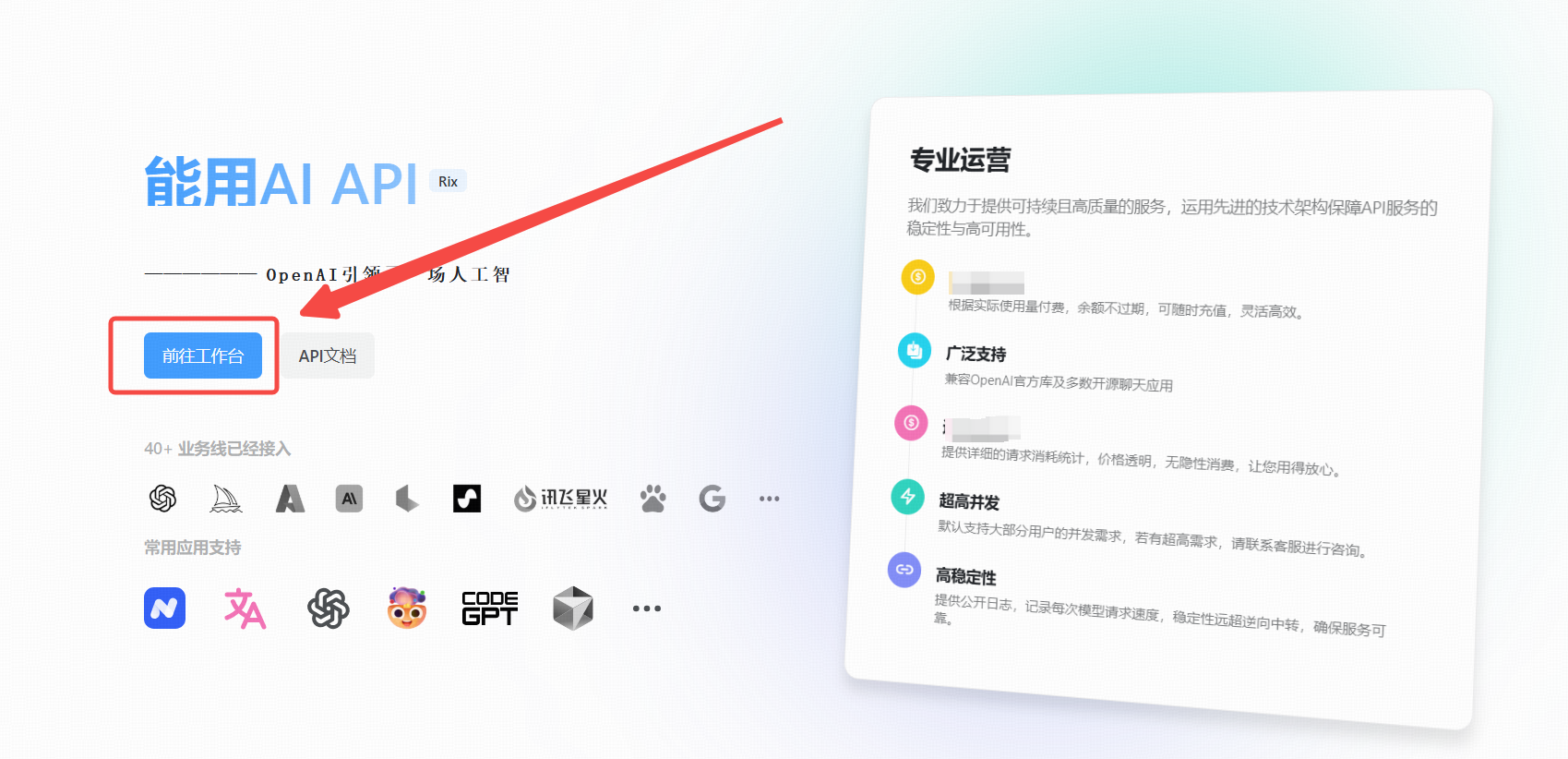
### 2. . 进入 API 管理界面
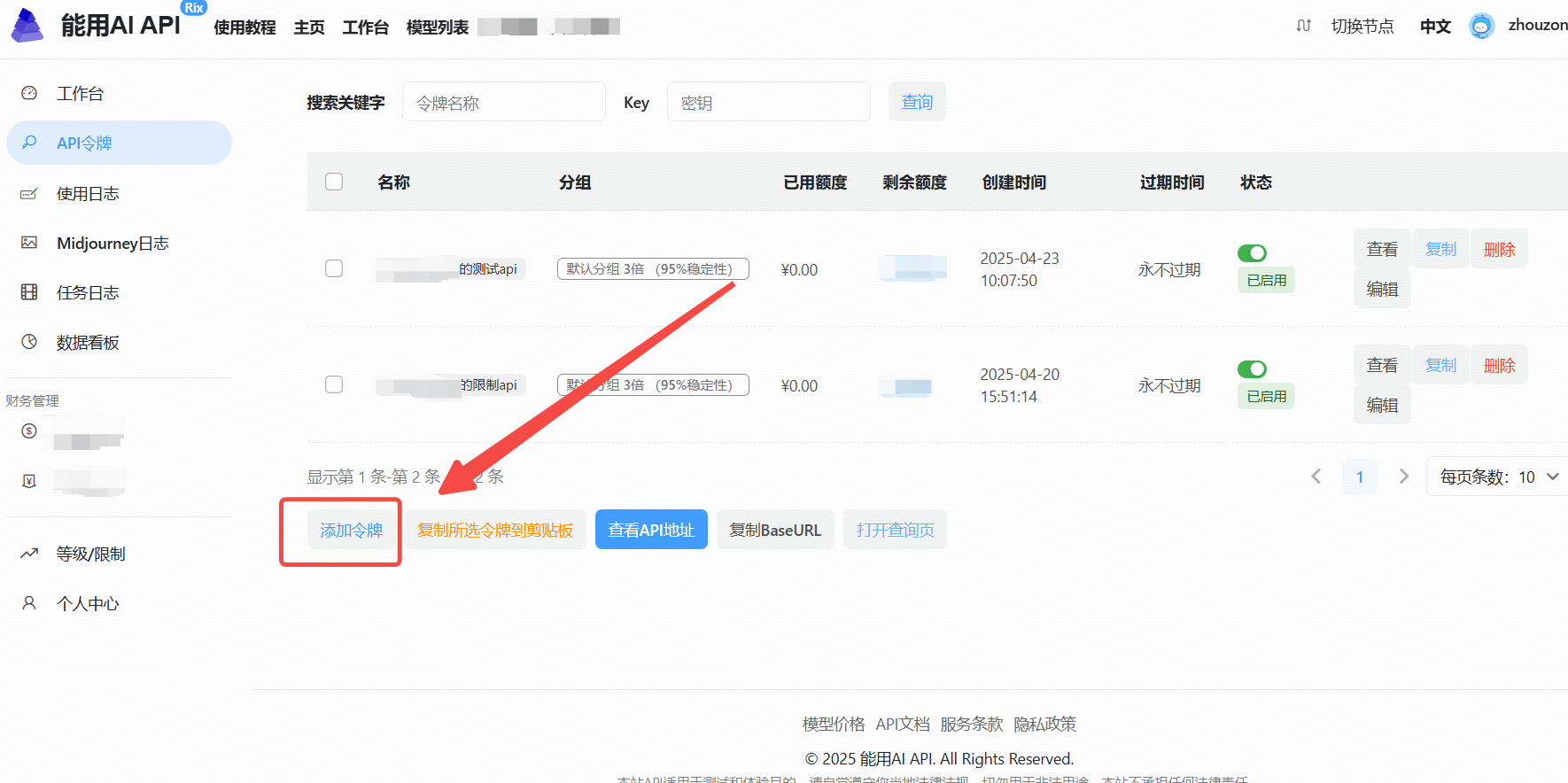
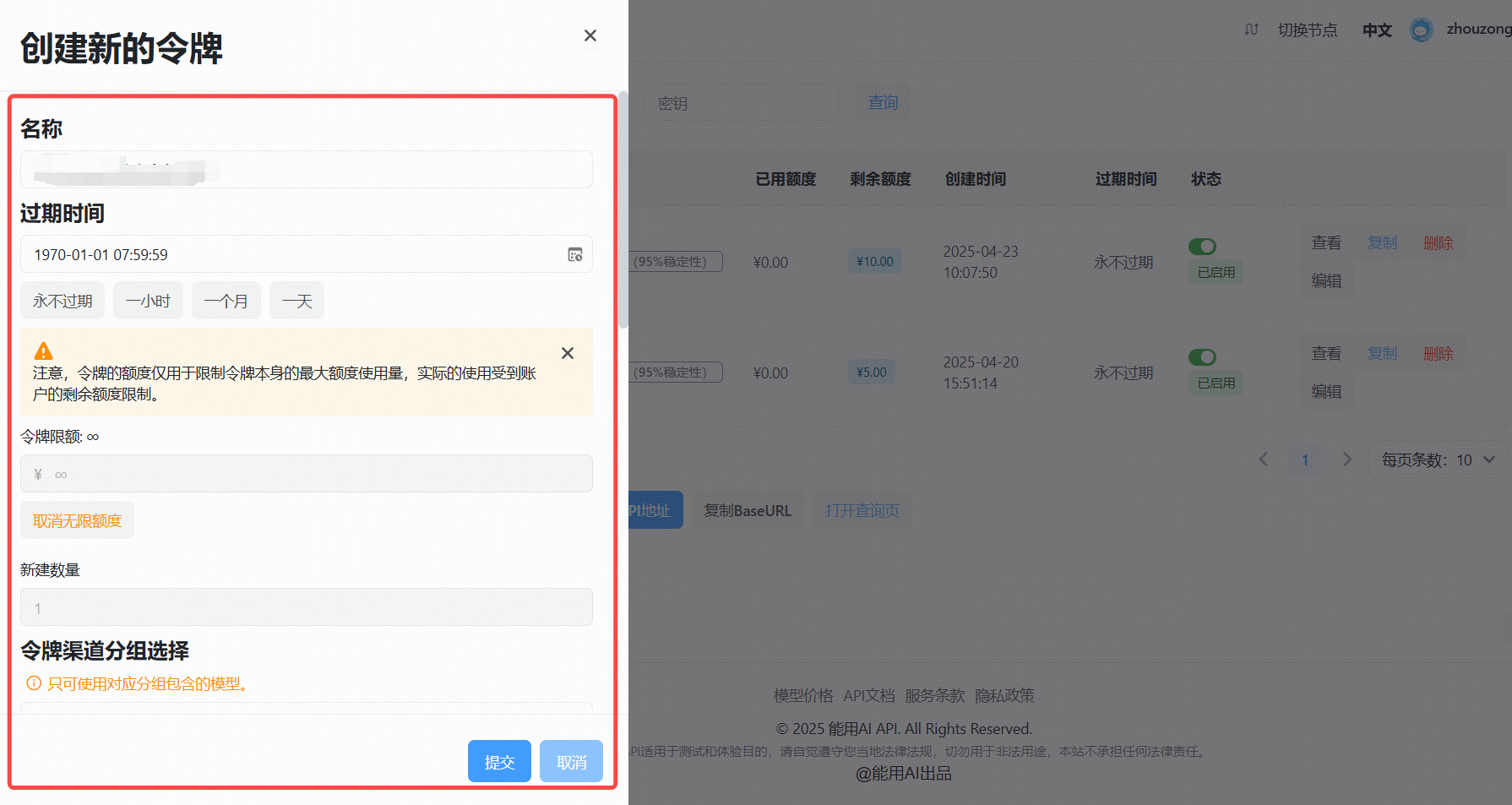
### 3. 生成新的 API Key
创建成功后点击“查看KEY”
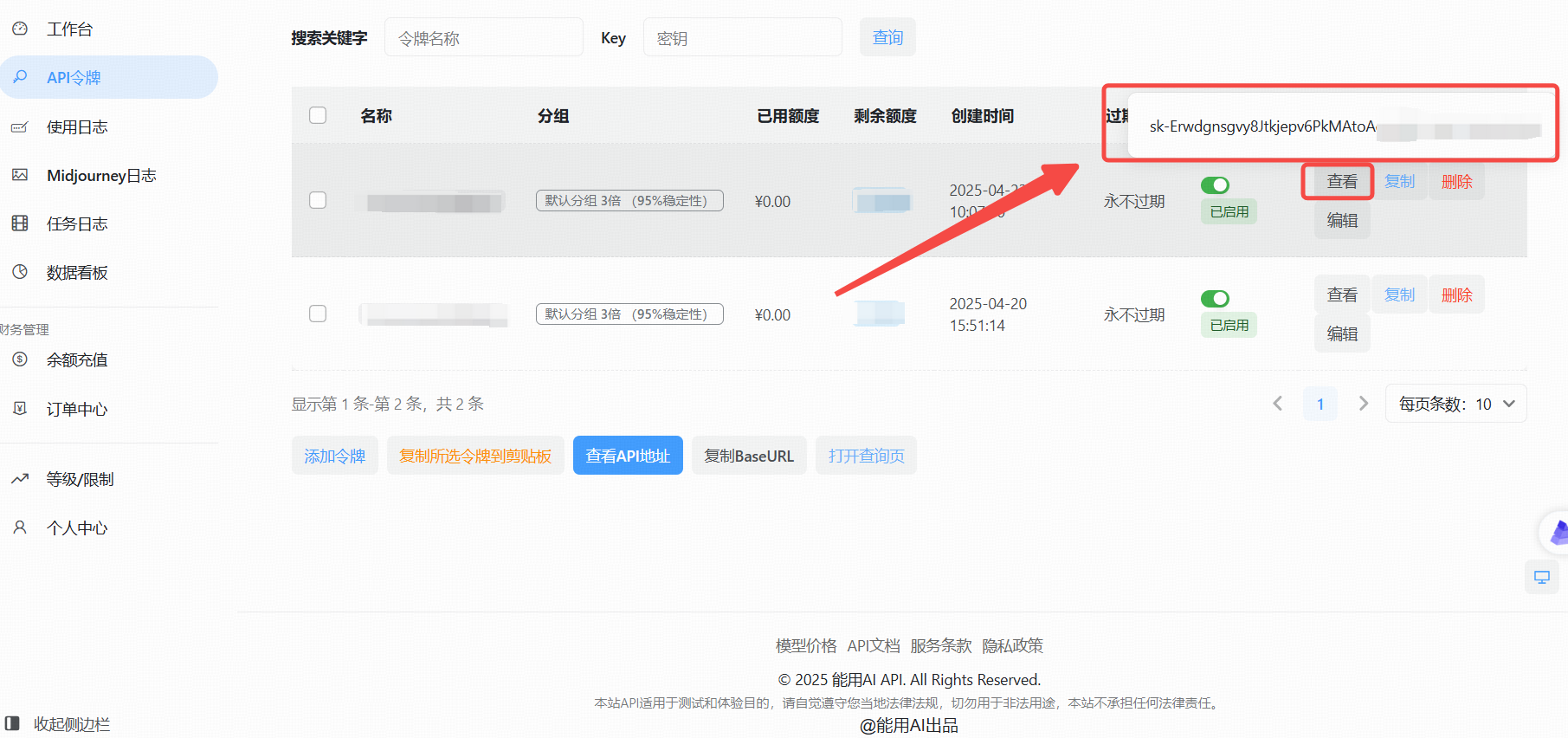
### 4. 调用代码使用 能用AI API
```bash
# [调用API:具体模型大全](https://flowus.cn/codemoss/share/42cfc0d9-b571-465d-8fe2-18eb4b6bc852)
from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4',
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
总结
通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!🌟

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)