
DeepSeek条件记忆架构深析:Engram模块、U型缩放定律与MoE双轴稀疏设计
文章目录
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
📕所属专栏:🌩专栏①:人工智能; 🌩专栏②:速通人工智能相关论文
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言:为什么 Transformer 需要一个"新维度"?
2026年1月,DeepSeek联合北京大学(含创始人梁文锋)发表了一篇名为《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》的论文。在大模型架构演进几乎被 MoE(Mixture-of-Experts)全面主导的今天,这篇论文提出了一个新的问题:MoE 是稀疏性唯一的维度吗?
1.1 从工程角度看:语言建模的"内耗"问题
让我们先从工程直觉出发。当你向一个 700B 参数的 LLM 提问"中国首都是哪里"时,模型需要做什么?
答案是:和它回答"量子场论中的规范不变性是什么"走几乎完全相同的神经网络前向路径。这个悖论揭示了当前 Transformer 架构的一个深层缺陷——它没有区分"查字典"和"推理演绎"这两种根本不同的计算需求。
从工程层面量化这个问题:
- 静态知识检索(Static Knowledge Retrieval):命名实体、固定搭配、高频短语等——这些知识在训练后就是固定的,理论上 O(1) 查表就够了;
- 组合推理(Compositional Reasoning):多步逻辑、数学推导、代码生成——这些需要深度的神经计算,没有捷径。
然而,现有 MoE 架构的所有稀疏性机制都是"条件计算"(Conditional Computation):根据 token 的隐状态动态路由到不同专家,本质上仍是神经计算。模型只能用"计算"来模拟"检索",这些宝贵的网络层被浪费在了平凡的静态知识重建上。
1.2 从理论角度看:语言建模的"二元性"
更深层地,这篇论文建立在一个理论观察之上:
语言建模 = 组合推理(Compositional Reasoning)+ 静态知识检索(Knowledge Retrieval)
| 子任务 | 本质特征 | 所需原语 |
|---|---|---|
| 组合推理 | 动态、上下文依赖、深层 | 神经计算(深度 Attention + FFN) |
| 静态知识检索 | 固定、局部 N-gram 驱动 | 查表(Table Lookup) |
Transformer 架构缺乏原生的知识查找原语(lookup primitive),导致模型被迫用神经计算层层"重建"本可直接获取的静态知识,这是该论文核心要解决的架构缺陷。
论文的答案是:在 MoE 的"条件计算"稀疏维度之外,引入第二条正交的稀疏轴——条件记忆(Conditional Memory),并通过 Engram 模块将其落地。
2、核心贡献概览
论文的七项核心贡献技术摘要如下:
| 贡献编号 | 贡献要点 | 关键技术词 |
|---|---|---|
| ① | 提出"条件记忆"新稀疏维度 | Conditional Memory,Second Axis of Sparsity |
| ② | 设计 Engram 模块 | N-gram 哈希、多头寻址、上下文门控、多分支集成 |
| ③ | 提出稀疏容量分配问题 | Sparsity Allocation Problem,ρ 参数 |
| ④ | 发现 U 型缩放定律 | U-shaped Scaling Law,最优 ρ* ≈ 75%~80% |
| ⑤ | 规模化验证至 27B | Engram-27B 全面超越等参数等 FLOPs 的纯 MoE 基线 |
| ⑥ | 揭示"意外发现" | 推理/代码/数学任务的提升幅度 > 知识型任务 |
| ⑦ | 算法-系统协同设计 | 100B 参数记忆表卸载到 CPU,吞吐损失 < 2.8% |
最令人意外的是贡献⑥:一个设计用于知识存储的记忆模块,在推理、代码、数学领域的提升反而更大。这个"意外发现"背后的机理,正是整篇论文最深刻的洞见之一,我们在第 6 节详细拆解。
3、Engram 模块:架构设计深析
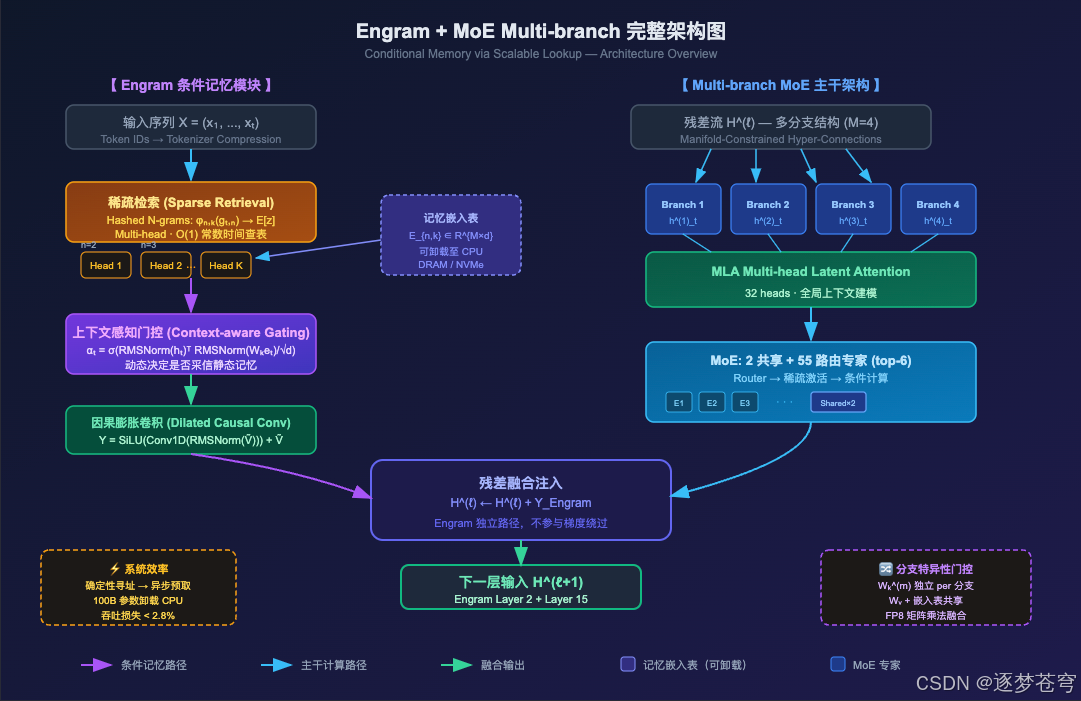
Engram(英文词义为"记忆印迹",来自神经科学)是条件记忆的具体实现。它作为一个附加模块嵌入 Transformer 层中,不是每层都激活,而是仅在特定层(实验中为第 2 层和第 15 层)注入。
每个 token 位置 t t t 在 Engram 中经历两个阶段:
阶段1: 稀疏检索 → e t 阶段2: 上下文门控融合 → Y \text{阶段1: 稀疏检索} \to \mathbf{e}_t \quad\quad \text{阶段2: 上下文门控融合} \to \mathbf{Y} 阶段1: 稀疏检索→et阶段2: 上下文门控融合→Y
H ( ℓ ) ← H ( ℓ ) + Y \mathbf{H}^{(\ell)} \leftarrow \mathbf{H}^{(\ell)} + \mathbf{Y} H(ℓ)←H(ℓ)+Y
3.1 Sparse Retrieval via Hashed N-grams
第一步:词表压缩(Tokenizer Compression)
标准 BPE 分词器会为语义等价的变体分配不同 ID,例如"Apple"(ID 42)、“apple”(ID 7823)、“APPLE”(ID 19001)——这三个语义相同的词占用了三个独立记忆槽,造成嵌入表碎片化。
Engram 引入词表投影层 P : V → V ′ \mathcal{P}: V \to V' P:V→V′,将原始 token ID 映射为规范化标识符:
x t ′ = P ( x t ) (统一小写 + NFKC Unicode 规范化) x'_t = \mathcal{P}(x_t) \quad \text{(统一小写 + NFKC Unicode 规范化)} xt′=P(xt)(统一小写 + NFKC Unicode 规范化)
效果:对 128k 词表的压缩率达到 23.43%,极大减少了嵌入表冗余。Top-5 归并类别包括空白/换行符(163个变体)、字母’a’(54个变体)等。
第二步:多头哈希(Multi-Head Hashing)
对每个 token 位置 t t t,构造其后缀 N-gram:
g t , n = ( x t − n + 1 ′ , ⋯ , x t ′ ) , n ∈ { 2 , 3 } g_{t,n} = (x'_{t-n+1}, \cdots, x'_t), \quad n \in \{2, 3\} gt,n=(xt−n+1′,⋯,xt′),n∈{2,3}
对每种 N-gram 阶数 n n n 和哈希头 k k k,用确定性哈希函数 φ n , k \varphi_{n,k} φn,k(轻量乘法-XOR 哈希)映射到嵌入表中的行:
z t , n , k ≜ φ n , k ( g t , n ) , e t , n , k = E n , k [ z t , n , k ] z_{t,n,k} \triangleq \varphi_{n,k}(g_{t,n}), \quad \mathbf{e}_{t,n,k} = \mathbf{E}_{n,k}[z_{t,n,k}] zt,n,k≜φn,k(gt,n),et,n,k=En,k[zt,n,k]
- 哈希碰撞缓解:使用 K = 8 K=8 K=8 个不同哈希头,不同 N-gram 哈希到同一槽位的概率大幅降低;
- 素数表大小:每张嵌入表 E n , k \mathbf{E}_{n,k} En,k 的大小 M n , k M_{n,k} Mn,k 取素数,改善哈希分布均匀性;
- 综合记忆向量:将所有 N-gram 阶数和哈希头的检索结果拼接:
e t ≜ ∏ n = 2 N ∏ k = 1 K e t , n , k \mathbf{e}_t \triangleq \prod_{n=2}^{N} \prod_{k=1}^{K} \mathbf{e}_{t,n,k} et≜n=2∏Nk=1∏Ket,n,k
关键特性:哈希检索是完全确定性的——只要输入 token 序列确定,检索地址就已确定,不依赖模型运行时状态。这是后续系统效率优化的基石。
3.2 Context-aware Gating 机制
哈希检索得到的 e t \mathbf{e}_t et 是上下文无关的静态先验,面临两个问题:
- 哈希碰撞噪声:不同 N-gram 可能哈希到同一槽位;
- 一词多义歧义:"苹果"在不同语境下(食物 vs 科技公司)对应不同语义,但静态表中只有一个向量。
门控机制采用类 Attention 的设计,由当前隐状态 h t \mathbf{h}_t ht 动态决定是否采信静态记忆:
k t = W K e t , v t = W V e t \mathbf{k}_t = \mathbf{W}_K \mathbf{e}_t, \quad \mathbf{v}_t = \mathbf{W}_V \mathbf{e}_t kt=WKet,vt=WVet
α t = σ ( RMSNorm ( h t ) ⊤ RMSNorm ( k t ) d ) \alpha_t = \sigma\!\left(\frac{\text{RMSNorm}(\mathbf{h}_t)^\top \text{RMSNorm}(\mathbf{k}_t)}{\sqrt{d}}\right) αt=σ(dRMSNorm(ht)⊤RMSNorm(kt))
v ~ t = α t ⋅ v t \tilde{\mathbf{v}}_t = \alpha_t \cdot \mathbf{v}_t v~t=αt⋅vt
其中 σ \sigma σ 是 Sigmoid 函数, α t ∈ ( 0 , 1 ) \alpha_t \in (0,1) αt∈(0,1) 是门控标量:
- 若当前上下文"认为"检索到的记忆是可靠的静态知识 → α t ≈ 1 \alpha_t \approx 1 αt≈1,充分采信;
- 若上下文不确定(歧义场景)或检测到碰撞噪声 → α t ≈ 0 \alpha_t \approx 0 αt≈0,直接忽略。
门控之后,还附加一个因果膨胀卷积(Dilated Causal Convolution)扩大感受野:
Y = SiLU ( Conv1D ( RMSNorm ( V ~ ) ) ) + V ~ \mathbf{Y} = \text{SiLU}(\text{Conv1D}(\text{RMSNorm}(\tilde{\mathbf{V}}))) + \tilde{\mathbf{V}} Y=SiLU(Conv1D(RMSNorm(V~)))+V~
卷积核大小 w = 4 w=4 w=4,膨胀系数 δ \delta δ 等于最大 N-gram 阶数,配合残差连接保证信息不丢失。
3.3 与 MoE 的集成:Multi-branch 架构
论文采用 Manifold-Constrained Hyper-Connections( M = 4 M=4 M=4) 多分支主干:残差流被扩展为 4 条并行分支,每条分支有独立隐状态 h t ( m ) \mathbf{h}_t^{(m)} ht(m)。
Engram 适配多分支时采用参数共享策略:
| 参数类型 | 策略 | 原因 |
|---|---|---|
| 稀疏嵌入表 E n , k \mathbf{E}_{n,k} En,k | 所有分支共享 | 记忆"内容"对所有分支相同,减少参数量 |
| Value 投影 W V \mathbf{W}_V WV | 所有分支共享 | 记忆的"值"维度相同 |
| Key 投影 W K ( m ) \mathbf{W}_K^{(m)} WK(m) | 每个分支独立 | 各分支从不同角度"询问"记忆,实现分支特异性门控 |
每条分支独立计算门控:
α t ( m ) = σ ( RMSNorm ( h t ( m ) ) ⊤ RMSNorm ( W K ( m ) e t ) d ) \alpha_t^{(m)} = \sigma\!\left(\frac{\text{RMSNorm}(\mathbf{h}_t^{(m)})^\top \text{RMSNorm}(\mathbf{W}_K^{(m)} \mathbf{e}_t)}{\sqrt{d}}\right) αt(m)=σ(dRMSNorm(ht(m))⊤RMSNorm(WK(m)et))
最终各分支输出: u t ( m ) = α t ( m ) ⋅ ( W V e t ) \mathbf{u}_t^{(m)} = \alpha_t^{(m)} \cdot (\mathbf{W}_V \mathbf{e}_t) ut(m)=αt(m)⋅(WVet)
工程优化:所有线性投影(1个 W V \mathbf{W}_V WV + 4个 W K ( m ) \mathbf{W}_K^{(m)} WK(m))融合为一次 FP8 矩阵乘法,最大化 GPU 计算利用率。
3.4 系统效率:计算与内存解耦
Engram 在系统层面的核心优势来自其确定性寻址特性。
对比 MoE 路由:
- MoE 路由:依赖运行时隐藏状态 → 必须先计算才知道路由哪个专家 → 无法提前预取
- Engram 检索:纯输入序列驱动,地址在 forward 开始前就可计算 → 完全可以异步预取
这使得 Engram 嵌入表可以卸载到主机内存(CPU DRAM),甚至 NVMe SSD:
时间轴并发图:
Layer N-1(GPU 计算)
↕ 完全并行
PCIe 传输(CPU → GPU,预取 Layer N 所需 Engram 嵌入)
Layer N(GPU 直接使用已到达的嵌入)
↕ 完全并行
PCIe 传输(预取 Layer N+1 所需嵌入)
N-gram 访问遵循 Zipf 分布(幂律分布),这使得多级缓存层次高效可行:
- GPU HBM:存储超高频 N-gram 嵌入(如 “the”, “is”)
- Host DRAM:存储中频 N-gram
- NVMe SSD:存储低频长尾 N-gram
实验验证(H800,100B 参数嵌入表卸载至 CPU):吞吐量损失仅 1.9%~2.8%,工程实用性极强。
4、U 型缩放定律:最优稀疏容量分配
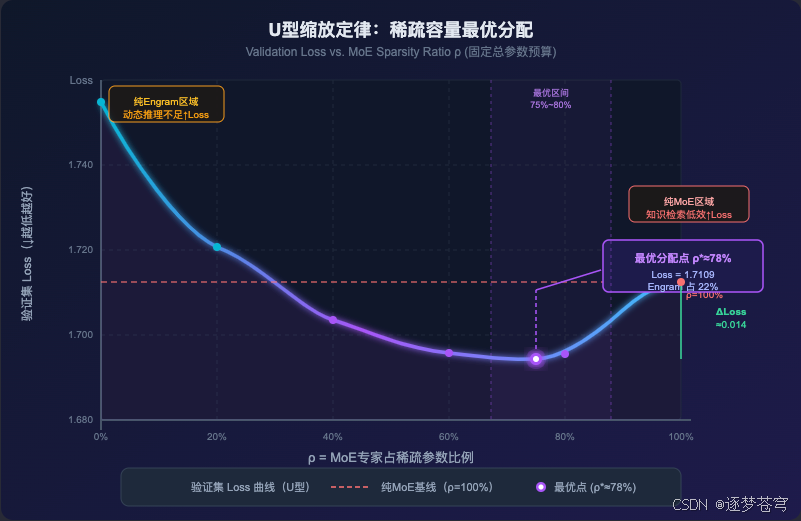
这是论文最重要的理论发现,直接回答了:在固定总参数预算下,MoE 和 Engram 各分多少?
4.1 定律的发现与直觉
首先定义三个参数指标:
P sparse ≜ P tot − P act P_{\text{sparse}} \triangleq P_{\text{tot}} - P_{\text{act}} Psparse≜Ptot−Pact
- P tot P_{\text{tot}} Ptot:总可训练参数量(不含词表 embedding 和 LM Head)
- P act P_{\text{act}} Pact:每 token 激活参数量,决定训练 FLOPs(计算量)
- P sparse P_{\text{sparse}} Psparse:非激活参数量,即"免费"的稀疏参数预算
直觉:MoE 和 Engram 都属于"免费"参数——不管有多少 MoE 专家或记忆槽,每次 forward 只激活固定数量,FLOPs 不变。因此 P sparse P_{\text{sparse}} Psparse 是在不增加推理成本的前提下可以自由分配的预算。
定义分配比例 ρ ∈ [ 0 , 1 ] \rho \in [0,1] ρ∈[0,1](MoE 占稀疏预算的比例):
P MoE ( sparse ) = ρ ⋅ P sparse , P Engram = ( 1 − ρ ) ⋅ P sparse P_{\text{MoE}}^{(\text{sparse})} = \rho \cdot P_{\text{sparse}}, \quad P_{\text{Engram}} = (1-\rho) \cdot P_{\text{sparse}} PMoE(sparse)=ρ⋅Psparse,PEngram=(1−ρ)⋅Psparse
实验在多个计算规模下扫描 ρ \rho ρ,观察验证集 Loss,发现严格的 U 型曲线:
验证 Loss
↑
| ★ ◇ (纯 MoE 基线)
| ★ ◇
| ★ ◇
| ★★★ ◇◇
| ★★ ● ★★◇◇
| (最优区间 ρ*≈78%)
+----+----+----+----+----+----→ ρ
0% 20% 40% 60% 80% 100%
纯Engram 纯MoE
U 型两端各有代价:
- 左端(ρ → 0,Engram 主导):MoE 专家数量不足 → 条件计算能力弱 → 无法应对需要动态推理的任务。记忆可以存储知识,但无法替代推理。
- 右端(ρ → 1,纯 MoE):没有专用静态知识记忆 → 模型被迫用层层神经计算"重建"固定知识 → 大量网络深度被浪费在平凡任务上。
4.2 MoE vs Engram 的最优分配比例
核心实验数据(两个计算规模):
| 计算规模 | 总参数 P tot P_{\text{tot}} Ptot | 纯 MoE 损失(ρ=100%) | 最优混合损失(ρ≈80%) | 改善 Δ \Delta Δ |
|---|---|---|---|---|
| 2 × 10 20 2\times10^{20} 2×1020 FLOPs | ~5.7B | — | — | — |
| 6 × 10 20 6\times10^{20} 6×1020 FLOPs | ~9.9B | 1.7248 | 1.7109 | 0.0139 |
关键结论:
- 最优 ρ ≈ 75%~80%*,即将约 20%~25% 的稀疏预算分给 Engram;
- 最优比例跨规模稳定,说明这是架构级规律,具有强泛化性;
- 即使将 MoE 比例压缩到 ρ ≈ 40%(约只剩 40 个专家),Engram 混合模型仍能追平纯 MoE 基线,说明 Engram 可以部分替代 MoE 的功能。
这个 20%~25% 的 Engram 配额在大规模实验中得到落地验证:Engram-27B 的参数分配比例 ρ = 74.3%,即 55 个路由专家 + 5.7B Engram 记忆表(原本有 72 个路由专家)。
4.3 无限记忆极限下的行为
论文进一步探究:如果不限制 Engram 记忆槽数量,能扩展到多远?
固定 MoE 骨干( P tot ≈ 3 B P_{\text{tot}} \approx 3B Ptot≈3B),不断扩大 Engram 表(从 2.58×10⁵ 槽到 1.0×10⁷ 槽,最多增加约 130 亿参数),观察验证损失。
结果在对数-对数坐标下呈线性,即严格遵循幂律:
L ( N ) ∝ N − α , α > 0 \mathcal{L}(N) \propto N^{-\alpha}, \quad \alpha > 0 L(N)∝N−α,α>0
- 记忆越多,模型越好,且改善是可预测的、平滑的;
- 与 Dense 模型的 Chinchilla 缩放律类似,但 Engram 不增加推理 FLOPs;
- 相比对照方法 OverEncoding(对 N-gram 嵌入取平均),Engram 的扩展效率更高——相同预算下损失改善幅度更大,原因是 Engram 基于上下文动态选取,利用率更高。
这开辟了一个新的扩展维度:计算固定,记忆无限扩展。
5、实验结果:大规模验证
5.1 预训练实验(27B 规模)
四个对比模型在 262B tokens 上等 FLOPs 训练:
| 模型 | 总参数 | 激活参数 | 路由专家 | Engram 参数 |
|---|---|---|---|---|
| Dense-4B | 4.1B | 3.8B | 无(Dense FFN) | 无 |
| MoE-27B(基线) | 26.7B | 3.8B | 2共享+72路由(top-6) | 无 |
| Engram-27B | 26.7B | 3.8B | 2共享+55路由(top-6) | 5.7B |
| Engram-40B | 39.5B | 3.8B | 2共享+55路由(top-6) | 18.5B |
激活参数严格相等(3.8B),训练 token 严格相等(262B),确保 FLOPs 等价对比的公平性。
语言模型损失对比:
| 模型 | Pile 测试 Loss | 验证集 Loss |
|---|---|---|
| Dense-4B | 2.091 | 1.768 |
| MoE-27B(基线) | 1.960 | 1.634 |
| Engram-27B | 1.950 (-0.010) | 1.622 (-0.012) |
| Engram-40B | 1.942 (-0.018) | 1.610 (-0.024) |
5.2 长上下文训练(32K Context)
在预训练后用 YaRN 扩展至 32,768 tokens(30B tokens,5,000 步),关键设计是 Iso-Loss 对照实验:Engram-27B(46k步)与 MoE-27B(50k步)预训练 Loss 完全对齐,消除基础能力差异,使任何性能差异完全归因于架构本身。
结果震撼:在 Iso-Loss 受控设置下,Engram 在复杂长程任务上显著领先:
| 评测任务 | Engram-27B (46k步) | MoE-27B (50k步) | 提升 |
|---|---|---|---|
| 多查询 NIAH(MQ) | 97.0 | 84.2 | +12.8 |
| 变量追踪(VT) | 87.2 | 77.0 | +10.2 |
更令人震惊的极端实验:仅用 82% FLOPs 的 Engram-27B(41k步),在 LongPPL 上即可追平完整训练的 MoE-27B(50k步),在 RULER 上甚至超越。
5.3 关键 Benchmark 数据
Engram-27B vs. MoE-27B 完整对比(等参数、等 FLOPs 的公平对比):
知识密集型任务:
| 基准 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| MMLU (5-shot) | 57.4 | 60.4 | +3.0 |
| MMLU-Redux | 60.6 | 64.0 | +3.4 |
| CMMLU (5-shot) | 57.9 | 61.9 | +4.0 |
| C-Eval (5-shot) | 58.0 | 62.7 | +4.7 |
| CCPM (0-shot) | 79.6 | 87.1 | +7.5 |
推理/代码/数学任务(意外的最大赢家):
| 基准 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| BBH (3-shot) | 50.9 | 55.9 | +5.0 |
| ARC-Challenge | 70.1 | 73.8 | +3.7 |
| HumanEval | 37.8 | 40.8 | +3.0 |
| MATH (4-shot) | 28.3 | 30.7 | +2.4 |
| MGSM (8-shot) | 46.8 | 49.4 | +2.6 |
最关键的发现:BBH(通用推理)提升 +5.0,超过了 MMLU(知识检索)的 +3.0。这不符合直觉,背后机理正是第 6 节的分析重点。
6、深度分析:Engram 到底在做什么?
6.1 Engram ≠ 增加模型深度(实验证明)
这是第 6 章最反直觉的结论标题——实际上论文发现恰恰相反:
Engram 在功能上等价于增加了模型的有效深度(Effective Depth)
理解这个结论的逻辑起点:现有 LLM 在没有原生知识查找原语的情况下,当处理命名实体(如"Diana, Princess of Wales")时,必须消耗多层 Attention 和 FFN 来逐步"拼凑"出这个实体的语义表示。这是用"计算"来模拟"记忆"——本质上是把多层深度的计算资源浪费在了简单的事实关联上。
Engram 的效果:跳过早期静态特征拼凑阶段,相当于"提前完成"了浅层任务,让后续层可以直接从更成熟的表示出发进行高层推理。
6.2 表示对齐与有效深度
论文使用两个可解释性工具进行验证:
LogitLens 分析
方法:将每一层的隐状态投影到词汇表,计算该层输出分布与最终层输出分布之间的 KL 散度。KL 散度越小 = 该层"预测"越接近最终答案 = 表示越成熟。
发现:Engram 变体的 KL 散度在早期层系统性地小于 MoE 基线,且下降更陡峭。这意味着 Engram 模型在更早的层就完成了有效预测所需的表示构建。
CKA 表示对齐分析
方法:使用 Centered Kernel Alignment(CKA)计算 Engram 各层与 MoE 基线各层之间的表示相似性矩阵 S ˉ ∈ [ 0 , 1 ] L × L \bar{S} \in [0,1]^{L \times L} Sˉ∈[0,1]L×L。
定义软对齐指数 a j a_j aj:对每个 Engram 层 j j j,取其与 MoE 各层相似度最高的 top- k k k( k = 5 k=5 k=5)层的加权质心:
a j = ∑ i ∈ I j S i , j ⋅ i ∑ i ∈ I j S i , j a_j = \frac{\sum_{i \in \mathcal{I}_j} S_{i,j} \cdot i}{\sum_{i \in \mathcal{I}_j} S_{i,j}} aj=∑i∈IjSi,j∑i∈IjSi,j⋅i
a j > j a_j > j aj>j 意味着 Engram 第 j j j 层的表示,功能上对应 MoE 基线更深的第 a j a_j aj 层。
实验发现(Few-NERD 命名实体数据集):典型示例是 Engram-27B 的第 5 层,表示与 MoE 基线的第 12 层最为接近。
结论:Engram 通过显式知识查找,在参数量不变的前提下,功能性地"加深"了网络。这解释了为什么推理、代码、数学任务受益更大——这些任务需要网络深度,而 Engram 将"浅层任务"从网络深度竞争中解放出来了。
6.3 门控可视化:什么样的 token 激活 Engram
通过可视化 α t \alpha_t αt 值(高值=红色=Engram 被激活),论文揭示了门控机制学到的清晰规律:
高激活(Engram 接管):
| 语言 | 激活案例 | 类型 |
|---|---|---|
| 英语 | “Alexander the Great”,“Princess of Wales” | 多 token 命名实体 |
| 英语 | “By the way”,“in addition to” | 程式化短语 |
| 中文 | “四大发明”,“张仲景” | 成语/历史人名 |
低激活(骨干 Attention 接管):上下文推理类内容、需要动态关联的语义
这个分工模式与设计意图完全吻合,也从定性角度印证了"条件记忆"概念的有效性。门控机制跨语言泛化,说明 Engram 捕捉的是语言无关的"刻板化语言依赖"(Stereotyped Linguistic Dependencies)规律。
敏感性分析(推理时完全去除 Engram 输出):
| 任务类型 | 去除 Engram 后性能保留比例 | 结论 |
|---|---|---|
| 事实知识(TriviaQA) | 仅 29% | Engram 是事实知识主要存储库 |
| 阅读理解(C3) | 高达 93% | 上下文推理几乎不依赖 Engram |
这个功能二分法精准验证了论文的核心假设:计算(Attention + MoE)与记忆(Engram)分工明确,互补而非冗余。
7、与相关工作的定位:RAG、PKM、外部记忆的本质区别

7.1 对比分析表
| 对比维度 | Engram(本文) | RAG | PKM/PEER | 外部记忆网络 |
|---|---|---|---|---|
| 寻址方式 | 确定性 N-gram 哈希,O(1) | 向量相似度检索,O(log N) | 学习键值匹配,O(K) | 注意力/相似度,O(N) |
| 存储位置 | 模型内(可卸载 CPU/SSD) | 外部向量数据库 | 模型权重(必须在 GPU) | 外部存储系统 |
| 知识粒度 | 词法级(2-3 token N-gram) | 段落/文档级 | 语义键值对 | 任意结构 |
| 可预取性 | ✓✓ 完全确定性,可异步预取 | ✗ 动态触发 | ✗ 依赖运行时状态 | ✗ 高延迟外部调用 |
| 训练集成 | ✓✓ 端到端梯度流 | ✗ 通常推理时挂载 | ✓ 端到端可训练 | ✗ 独立构建 |
| 知识时效 | 固化(训练时),适合稳定模式 | 实时可更新,适合动态知识 | 固化,更新代价高 | 依实现而定 |
| 规模扩展 | 幂律扩展,FLOPs 不变 | 数据库扩展,检索速度下降 | TopK 线性复杂度 | 受系统架构限制 |
7.2 与 FFN 键值记忆理论的联系
Geva 等(2021)发现 Transformer 的 FFN 层在功能上等价于键值记忆:第一层矩阵作为"模式检测器"(键),第二层矩阵将信息投影到残差流(值)。这是 Engram 论文最重要的动机之一。
Engram 可以看作对这一发现的工程化延伸:既然 FFN 本质上在做键值记忆查找,为什么不显式设计一个高效的 O(1) 键值记忆模块,而是让 FFN 用矩阵乘法隐式且低效地模拟它?
7.3 与 N-gram 嵌入方法(SCONE、OverEncoding)的区别
已有 N-gram 嵌入方法通常将记忆注入输入层(第0层),与 GPU 计算串行,无法实现通信-计算重叠。Engram 将记忆注入中间层(第2层和第15层),使得 PCIe 数据传输与前一层 GPU 计算并行,大幅降低实际延迟。
核心差异:Engram 在严格等参数/等 FLOPs 受控实验下依然有优势,而已有方法缺乏这类公平对比。
8、对 DeepSeek V4 和行业的启示
8.1 DeepSeek V4 架构技术猜想
论文作者包含 DeepSeek 创始人梁文锋,业界普遍认为这是 DeepSeek V4 的技术预演。基于论文数据,合理的架构猜想:
DeepSeek V4 可能采用 MoE + Engram 双稀疏轴架构
| 维度 | 推测 | 依据 |
|---|---|---|
| 总参数规模 | 可能远超 V3.2(671B) | Engram 参数不增加 FLOPs,可以"免费"加 |
| 激活参数 | 保持同等量级(~37B) | DeepSeek 一贯极致效率风格 |
| Engram 参数规模 | 数百亿(分布于多机 CPU 内存) | 100B 参数卸载已验证,开销<3% |
| 路由专家数量 | 可能从现有数量减少 | 节省的预算分给 Engram(U型律 ρ*≈78%) |
| 推理架构 | PCIe 异步预取 + DRAM 分布式存储 | 论文已验证工程可行性 |
8.2 工程路线图:三维参数扩展
这篇论文实质上开辟了大模型参数扩展的第三个维度:
维度1:增加 Dense 参数(Chinchilla 缩放律)
→ FLOPs 正比增长,成本高
维度2:增加 MoE 专家数(条件计算稀疏)
→ FLOPs 不变,但推理时需要专家在 GPU 显存
维度3:增加 Engram 记忆槽(条件记忆稀疏)[NEW]
→ FLOPs 不变,参数可卸载到 CPU/SSD
→ 幂律扩展,无限记忆极限
未来大模型可能走向"三轴协同扩展"策略:在固定激活参数(FLOPs预算)的前提下,同时在三个维度上优化参数分配。
8.3 行业深远影响
1. 重新定义稀疏性的边界:MoE 只是稀疏性的一个维度,Engram 证明了记忆稀疏性的价值,未来还可能出现注意力稀疏(MLA已在做)、激活稀疏等更多维度叠加。
2. 算法-硬件协同设计成核心竞争力:Engram 的可行性依赖于对硬件内存层级结构的深刻理解(PCIe 带宽、Zipf 局部性、异步预取)。这类"算法-系统 co-design"能力将成为顶级 AI 实验室的护城河。
3. 重新思考"什么应该被计算,什么应该被记忆":代码补全中的高频 API 调用模式、数学定理的固定形式、特定领域的术语搭配——这些都可以"记忆化",而无需每次深度计算。
4. 知识双轨存储架构的未来:Engram 负责高频词法级静态模式(训练时固化),RAG 负责长尾动态语义知识(推理时检索),两者面向不同层次、可以共存互补。
9、总结与个人思考
这篇论文在概念层面的贡献不亚于 MoE 本身的提出。它系统性地识别了 Transformer 架构的一个深层缺陷,并提供了一个优雅、可工程化的解决方案。
几点值得深思的洞见:
洞见一:"意外发现"不意外
论文发现推理、代码、数学任务提升比知识任务更大,初看违反直觉。但理解了"有效深度"机制后就豁然开朗——Engram 不是直接"提供推理能力",而是通过卸载浅层任务,让现有的计算层深度可以全部用于推理,相当于"间接"提升了推理能力。这个间接效应甚至比直接效应更强大。
洞见二:O(1) 的革命性
Engram 最核心的贡献,不是记忆本身,而是用 O(1) 的确定性哈希替代了 O(N) 或 O(log N) 的相似度检索。这个计算复杂度的跃变,使得参数量与推理成本彻底解耦,开辟了"无限记忆,固定计算"的全新可能。
洞见三:从 PKM/PEER 到 Engram 的工程化飞跃
PKM 等参数化记忆方法已经存在多年,但工程实用性一直是瓶颈。Engram 通过确定性寻址(可预取)、多级缓存(Zipf感知)、FP8 矩阵融合(GPU 效率),将这类方法真正推向了生产可用的阶段。这再次说明:好的想法需要扎实的工程才能落地。
洞见四:DeepSeek 的技术哲学
这篇论文体现了 DeepSeek 一贯的"极致效率"哲学:不追求参数量最大化,而是追求参数效率最大化。Engram 在不增加推理 FLOPs 的前提下,显著提升了模型能力——这是在算力约束下最明智的扩展方向。对于国内 AI 企业在算力受限环境下的研发策略,有重要的参考意义。
论文信息
- 标题:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
- 机构:DeepSeek-AI × 北京大学
- 发表时间:2026 年 1 月
- 核心关键词:Conditional Memory、Engram、N-gram Hashing、U-shaped Scaling Law、Sparsity Allocation
如果这篇技术解析对你有帮助,欢迎一键三连!后续将持续解读 DeepSeek 最新技术论文,追踪 AI 架构前沿进展。有任何技术问题欢迎在评论区交流。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)