
Skill一键生成专业性能测试计划,7个Skill技能亲测好用,实现全链路压测落地(第二篇)
一个真实场景
周一早上,你收到业务方的压测需求:"双十一要来了,帮我们测一下订单提交接口,目标并发 5000。"
你打开 JMeter,开始新建测试计划。
并发填 5000,Ramp-up 填多少?你犹豫了一下,填了 300。
持续时间呢?"先跑 10 分钟看看"。
场景怎么配?只有一个接口,那就单线程组吧。
数据从哪来?"到时候让开发造点测试账号"。
压测机够吗?"应该够吧,我笔记本 16G 内存"。
周五下午,你终于跑完了压测。结果惨不忍睹:
- 压到 2000 并发时,你的笔记本 CPU 已经 95%,后面的数据全失真
- 没有预热,冷缓存下的 P95 是 warmed-up 状态的 4 倍
- 100 个测试账号撑了 8 分钟就耗尽,后面 7 分钟缓存命中率 100%,TPS 虚高
- 订单表多了 10 万条脏数据,开发的测试环境被你搞乱了
业务方问:"5000 并发能不能撑住?"你只能回答:"好像……到 2000 就开始卡了?"
好像。好像。好像。
这个场景的问题,不是 JMeter 不会用,而是测试计划本身就是拍脑袋填的。
压测计划阶段有 4 个最容易踩的坑:
| 坑 | 后果 |
|---|---|
| 四目标混为一谈 |
基线测试和容量测试用同一套方案,基线没建准,容量也找不到拐点 |
| 算力不估算 |
压测机先瓶颈,结果全部失真,还以为是被测服务有问题 |
| 场景不分层 |
直接压全链路,瓶颈定位不到具体接口,优化无从下手 |
| 写接口当读接口压 |
数据耗尽后缓存虚高、脏数据污染测试环境、幂等性没验证 |
P02 perf-test-planner 做的事,就是把这些拍脑袋的决策,变成一套有公式、有策略、有分层、有兜底的工程化方案。
perf-test-planner 是什么
perf-test-planner 是性能测试 7 个 Skill 中的第 2 个,定位是测试计划生成。
它不是帮你填 JMeter 的参数,而是帮你回答一系列工程化问题:
-
这次压测的目标是基线、容量、稳定性还是瓶颈定位?不同目标,策略完全不同
-
5000 并发需要几台压测机?有公式,不用猜
-
单接口压完再压混合场景,还是先压全链路?三层分层,顺序不能乱
-
写接口压测后数据怎么清理?幂等性怎么验证?强制规范,不遗漏
-
压测过程中出了异常怎么办?动态风险库,提前备预案
简单说:输入需求澄清文档(或几个参数),输出一份开发、DBA、运维都能直接照着执行的测试计划。
能解决什么问题
问题一:四种压测目标共用一套方案
以前:
业务方说"压一下订单接口",你不管目标是基线、容量还是稳定性,统一固定并发跑 10 分钟。
基线测试需要稳态短跑,你跑了 10 分钟,时间太长;容量测试需要阶梯加压找拐点,你固定并发,找不到拐点;稳定性测试需要长时运行观察泄漏,你只跑了 10 分钟,什么都看不出来。
现在:
P02 内置了四大目标专属策略映射表,输入目标类型,自动匹配方案:
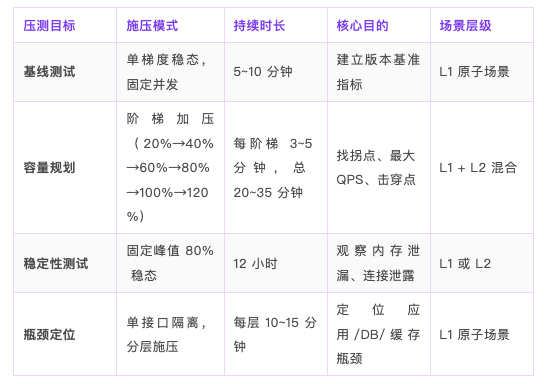
基线测试禁止用阶梯加压,容量测试必须超压到 120%,稳定性测试禁止满载——这些规则自动生效,不需要你记。
问题二:压测机够不够,全靠猜
以前:
目标并发 5000,你用笔记本开 5000 线程,跑到 2000 时 CPU 已经 95%。后面的 3000 线程全是虚的,压测机自己先挂了,你还以为是服务扛不住。
现在:
P02 在生成计划前,先用标准公式估算算力:
单台施压机支持并发 = 600(4C8G 取中值) 所需节点数 = 目标并发 5000 ÷ 600 = 8.3 → 向上取整 10 台 Slave Master 节点 = 1 台(仅调度,不施压) 总计 = 11 台 4C8G
同时给出压测机监控红线:
| 指标 | 警告阈值 | 停止阈值 |
|---|---|---|
|
压测机 CPU |
> 70% |
> 85% |
|
压测机内存 |
> 75% |
> 90% |
|
压测机网络 |
> 60% 带宽 |
> 80% 带宽 |
超过红线,计划会建议降低并发或增加节点,不让压测机成为瓶颈。
问题三:场景不分层,一压就是全链路
以前:
直接上全链路压测,5000 并发同时打登录、加购、下单、支付。结果 TPS 上不去,不知道瓶颈在订单服务还是库存服务还是支付网关,优化无从下手。
现在:
P02 强制三层分层设计,不同压测目标选择不同层级:
L1 — 原子场景(必做):单接口独立压测,Mock 所有外部依赖
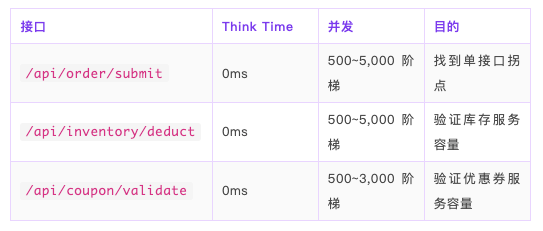
L2 — 混合场景:按真实流量配比组合接口
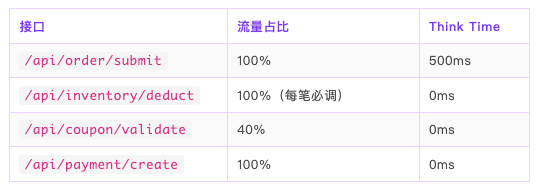
L3 — 全链路场景:串联所有 P0 核心接口,端到端验收
登录 → 加购物车 → 提交订单 → 支付 → 查询订单状态
Think Time 按业务路径配置,单步 1~3s
顺序不能跳:必须先 L1 找到各接口基准,再 L2 验证混合配比,最后 L3 端到端验收。否则瓶颈定位就是瞎猜。
问题四:写接口当读接口压
以前:
订单提交是写接口,你用 5000 并发无限循环压,10 分钟后测试账号全部用完,后面的请求全报"用户不存在"。订单表多了几万条脏数据,开发周一早上发现测试环境被你用乱了。
现在:
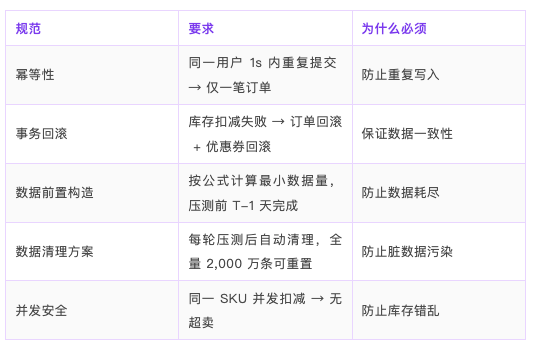
P02 自动识别写接口,强制附加 5 条规范:
写接口数据量有标准公式:
Data_write = C × T × 60 × 2 C = 目标并发(6,000) T = 压测时长(23 分钟) 2 = 写操作余量系数 Data_write = 6,000 × 23 × 60 × 2 = 16,560,000 条
2,000 万条测试数据,压测前一次性构造好,不会跑到一半没数据。
怎么用
触发词:在 WorkBuddy 中输入以下任意一个:生成压测计划性能测试计划perf test plan压测方案设计
最佳实践:直接接在 P01 后面用
P01 perf-requirement-clarifier 的输出里已经有 plan_id、SLA、并发目标、待确认项。把需求澄清文档扔给 P02:
「根据这份需求澄清文档,帮我生成压测测试计划」
P02 会自动读取 P01 的输出,跳过重复问询,直接生成计划。
如果没有 P01,也可以直接描述需求:
「我要对订单提交接口做容量规划,目标并发 5000,帮我生成测试计划」
P02 会追问几个关键问题:压测目标类型、环境规格、是否有写操作、是否需要分布式,然后生成计划。
输出文件:
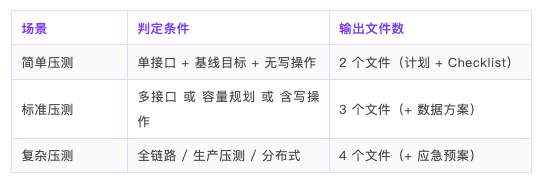
所有文件命名统一继承 plan_id 前缀,比如 jd-order-submit-capacity-20260608-v1-计划.md,方便归档。
完整案例:京东订单提交接口
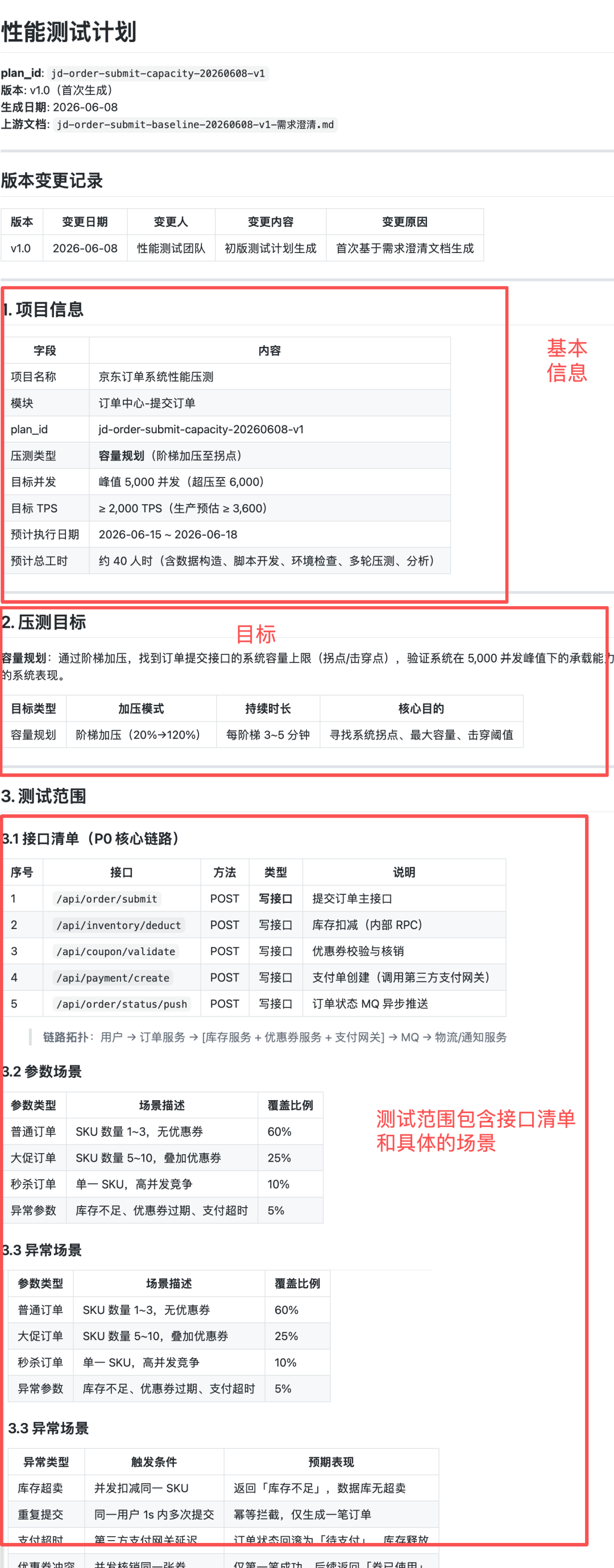
为了让你看到 P02 在复杂场景下的真实输出,我以一个京东订单提交接口为例,走一遍完整流程。
需求背景
-
接口:POST
/api/order/submit(订单提交) -
链路:订单服务 → 库存服务 + 优惠券服务 + 支付网关 → MQ 推送
-
目标:容量规划,找到系统最大承载并发
-
目标并发:5,000(超压至 6,000)
-
场景:电商大促,秒杀 + 普通订单混合
这是一个典型的写接口 + 全链路 + 高并发 + 多依赖的复杂场景,P02 判定为"复杂压测",输出 4 个文件。
核心输出摘要
plan_id:jd-order-submit-capacity-20260608-v1
压测目标:容量规划(阶梯加压至拐点)
施压策略(容量测试 — 阶梯加压):
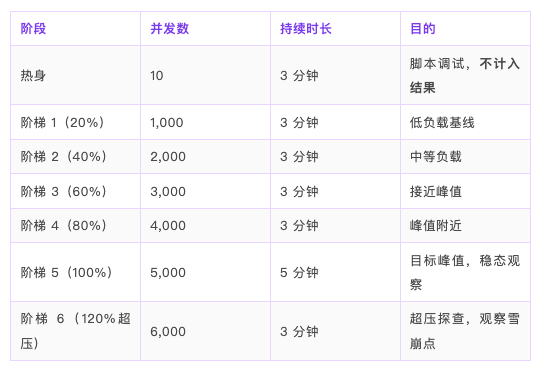
拐点判定:
- 若某阶梯 TPS 不再随并发增加 → 该阶梯为性能拐点
- 若 120% 错误率 > 5% → 该阶梯为击穿点
- 若 120% 直接雪崩 → 以阶梯 5(5,000 并发)作为最大容量
四种施压模式全覆盖:
| 模式 | 场景 | 参数 |
|---|---|---|
|
阶梯加压 |
主方案(容量规划) |
6 阶,每阶 3~5 分钟 |
|
脉冲压测 |
秒杀补充 |
5,000 并发 × 15s × 15 轮 |
|
浪涌压测 |
大促瞬时流量 |
10s 拉满至 5,000,稳态 5 分钟 |
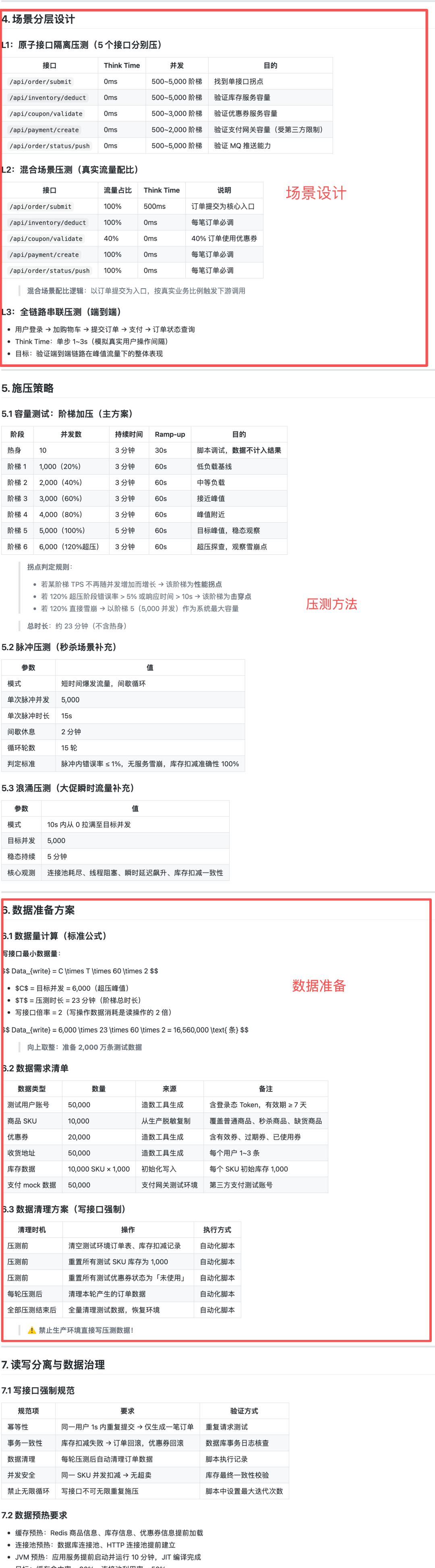
场景三层分层:
-
L1 原子压测:5 个接口分别阶梯加压,找到各自拐点
-
L2 混合场景:真实流量配比(优惠券 40% 命中率)
-
L3 全链路:登录 → 加购 → 提交 → 支付 → 查询,单步 Think Time 1~3s
算力估算:
目标并发 6,000 ÷ 单台 600 = 10 台 Slave Master = 1 台(仅调度) 总计 = 11 台 4C8G
数据准备:
写接口最小数据量 = 6,000 × 23 × 60 × 2 = 16,560,000 条 向上取整:准备 2,000 万条测试数据
| 数据类型 | 数量 | 来源 |
|---|---|---|
|
测试用户账号 |
50,000 |
造数工具生成 |
|
商品 SKU |
10,000 |
生产脱敏复制 |
|
优惠券 |
20,000 |
造数工具生成 |
|
库存数据 |
10,000 SKU × 1,000 |
初始化写入 |
写接口强制规范:
-
幂等性:同一用户 1s 内重复提交 → 仅一笔订单
-
事务回滚:库存扣减失败 → 订单回滚 + 优惠券回滚
-
并发安全:同一 SKU 并发扣减 → 无超卖
-
数据清理:每轮压测后自动清理,全量 2,000 万条可重置
动态风险库(9 条):
| 等级 | 风险 | 示例 |
|---|---|---|
|
致命 |
库存超卖、连接池打满、数据污染 |
同一 SKU 被 5000 并发同时扣减 |
|
严重 |
Redis 热点 Key、MQ 堆积、第三方支付限流 |
秒杀 SKU 被集中访问 |
|
一般 |
响应时间波动、监控延迟 |
网络抖动导致 P95 波动 |
每种风险含预防措施 + 止损方案 + 负责人。
开关状态(容量规划):
| 降级 | 限流 | 熔断 |
|---|---|---|
|
关闭 |
关闭 |
保留(作为最后一道防护) |
容量测试需要找到真实拐点,所以降级和限流关闭;熔断保留,防止真把服务压崩。
生成的测试计划如下:

使用前 vs 使用后
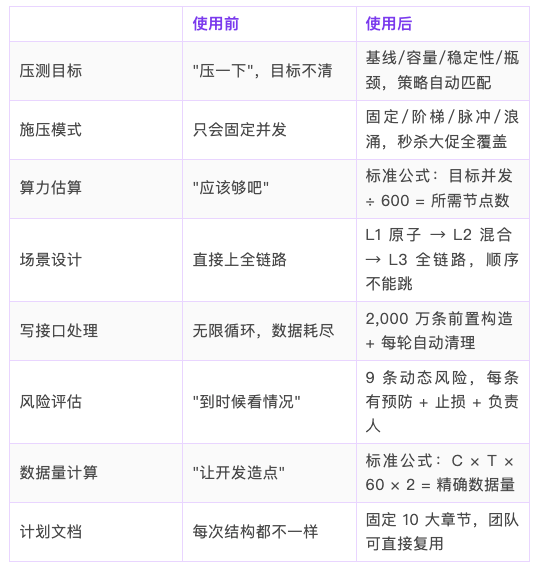
典型节省:5h(主要是场景设计、算力估算、风险评估的时间)
这些 Skill 在哪里能用
和专栏第 1 篇介绍的 7 个 Skill 一样,perf-test-planner 也提供了跨平台通用 Prompt 模板。
| 平台 | 使用方式 |
|---|---|
| WorkBuddy | @skill:perf-test-planner
直接调用,最完整的文件输出 |
| Cursor |
复制 Prompt 模板到 Chat 或 |
| Trae |
复制 Prompt 模板到侧边栏 AI 助手 |
| Claude / ChatGPT / DeepSeek |
新建对话,粘贴 Prompt 模板 |
核心设计:一个文件,多平台使用。 不需要为了换平台重写一套 Prompt。
复制方式:打开 Skill 文件,找到 ---PROMPT START--- 到 ---PROMPT END--- 之间的内容,复制粘贴到目标平台即可。输出质量和 WorkBuddy 一致,只是文件和版本需要手动维护。
总结
性能测试计划不是 JMeter 里填几个参数就完事的。它是一套工程化决策:
-
什么目标 → 决定什么策略
-
多少并发 → 决定多少台机器
-
什么场景 → 决定分层顺序
-
什么接口 → 决定读写规范
-
什么风险 → 决定应急预案
P02 perf-test-planner 把这套决策流程固化成 Skill,让你不再拍脑袋,每一步都有标准、有公式、有兜底。
下一篇,我会介绍 P03 perf-data-builder ,压测数据构造 Skill。解决了"计划怎么做",接下来要解决"数据从哪来"。2,000 万条测试数据,手动造是不可能的,看下 Skill 怎么帮你自动生成。
如果这篇对你有帮助,欢迎随手转发~

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)