
亚马逊 AI Agent 数据质量工程实践:为什么数据管道才是 AI 决策的真正天花板
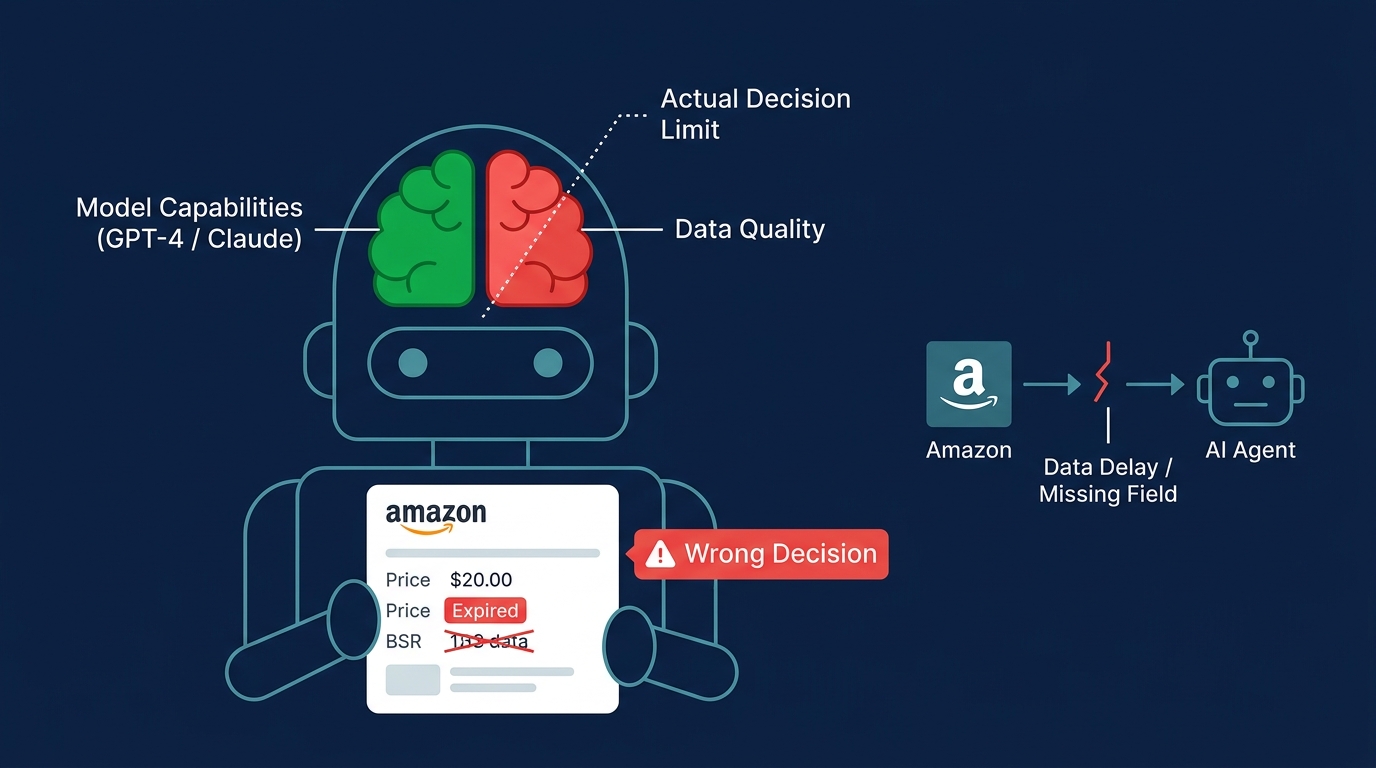
前言:本文面向正在构建亚马逊 AI Agent 的工程师和开发者。核心论点:AI Agent 的决策质量上限由数据质量决定,而非模型能力。文章给出三类数据失效场景的具体分析和对应的工程解法,并介绍 MCP 协议下的原生 Agent 数据接入方案。
一、问题背景:为什么换了更强的模型还是做错决策?
典型的亚马逊 AI Agent 决策链路如下:
任务指令 → 工具调用/数据获取 → 注入 LLM 上下文 → LLM 推理 → 决策输出
↑
数据质量问题在这里发生
模型推理无法修复这一影响
LLM 只负责推理部分。当喂给 LLM 的数据本身有问题时,更强的推理能力只会让错误答案变得更加"有说服力"——更完整的分析框架,更自信的语气,更难被察觉的错误结论。
根据工程实践:超过 90% 的 Amazon AI Agent 决策质量问题,根因在数据管道,而不在模型选择或 Prompt 工程。
二、三类高频数据失效场景
2.1 数据过期(Stale Data)
问题描述
亚马逊核心数据字段的更新频率:
| 字段 | 更新频率 |
|---|---|
| 价格 | 15–30 分钟(竞争激烈类目) |
| BSR 排名 | 每小时 |
| 库存状态 | 实时(FBA 入仓后秒级变化) |
| 限时优惠 | 随时生效/结束 |
常见做法是定时爬虫每天运行一次,数据存入数据库,Agent 查询数据库。这意味着 Agent 在决策时可能使用 24 小时前的数据快照。
典型故障案例
某卖家补货 Agent 逻辑:竞品库存 < 50 件时触发补货信号。数据库显示竞品库存 45 件,Agent 触发补货建议。实际情况:竞品 6 小时前已完成 2,000 件 FBA 入仓。结果:不必要的备货过量,产生额外仓储成本。
故障根因:数据时效性不足,不是 Agent 逻辑错误,不是模型问题。
2.2 字段残缺(Incomplete Fields)
亚马逊商品页面数据分散在多个 DOM 节点,随 A/B 测试持续变化。维护不足的爬虫常见漏采字段:
| 漏采字段 | 决策影响 |
|---|---|
| 变体价格矩阵 | 竞品定价分析不完整 |
| 促销信息(Coupon/限时折扣) | 实际到手价判断偏差 |
| A+ 内容文本 | 品牌差异化分析缺失 |
| 各变体评论分布 | 特定规格质量问题被汇总评分掩盖 |
| BSR 历史趋势 | 无法判断竞品上升/下滑方向 |
Agent 不知道自己不知道什么——它会基于残缺数据产生一个"合理"但基础错误的分析。
2.3 结构错乱(Unstructured Input)
将原始 HTML 直接注入 LLM 上下文的后果:
问题一:噪声稀释信息密度
原始亚马逊页面 HTML 包含大量无关内容:导航菜单、脚注、广告位文字、JavaScript 代码片段。这些内容占用上下文 token,降低有效信息密度。
问题二:精确数字提取错误率高
LLM 从非结构化文本提取精确数值(价格、排名数字)时,受页面格式变化和文本歧义影响,有不可忽视的出错概率。
工程实测数据:
将数据输入从原始 HTML 改为结构化 JSON 后:
- 关键字段提取准确率提升:35–45%
- 上下文 token 消耗降低:约 60%
- 改动范围:零行 LLM 相关代码
三、工程解决方案
3.1 实时数据 API 替代快照数据库
核心要求:
- P95 响应时间:< 3 秒(不阻塞 Agent 推理循环)
- 数据新鲜度:分钟级(采集后即返回,无缓存层)
- 解析失败率:< 1%(抵御页面结构变化)
Pangolinfo Amazon Scraper API在 Agent 实时查询场景:
- 典型响应时间:1.2–2.8 秒
- 数据新鲜度:亚分钟级
3.2 结构化 JSON 输出规范
# ✅ 推荐返回格式
{
"asin": "B0XXXXXXXXX",
"title": "...",
"price": 24.99, # float,不含货币符号
"list_price": 29.99, # float
"is_prime": True, # bool,不用字符串 "Yes"
"is_in_stock": True, # bool
"bsr": [
{"category": "Kitchen & Dining", "rank": 1243},
{"category": "Water Bottles", "rank": 18}
],
"rating": 4.3, # float
"review_count": 2841, # int
"bullet_points": [...], # 保持 array 结构
"updated_at": "2026-06-11T14:52:00Z", # ISO 8601
"is_data_fresh": True,
"collection_success": True
}
# ❌ 采集失败时
{
"asin": "B0XXXXXXXXX",
"price": None, # ← null,不是 0
"error_code": "CAPTCHA_HIT",
"error_message": "Collection failed, retry recommended"
}
# 注意:price: 0 会被 Agent 误判为"竞品清仓甩卖",触发错误降价决策
3.3 按字段分级刷新策略
FIELD_REFRESH_INTERVALS = {
"price": timedelta(minutes=30), # 高频波动
"inventory_status": timedelta(minutes=30),
"bsr_rank": timedelta(hours=1), # 每小时更新
"rating": timedelta(hours=6),
"review_count": timedelta(hours=6),
"title": timedelta(days=1), # 相对稳定
"aplus_content": timedelta(days=3),
"images": timedelta(days=7),
}
def should_refresh_field(asin: str, field: str, last_fetched: datetime) -> bool:
interval = FIELD_REFRESH_INTERVALS.get(field, timedelta(hours=6))
return (datetime.now(timezone.utc) - last_fetched) > interval
按字段分级刷新可以在保证关键字段时效性的同时,把整体 API 调用量降低约 60-70%。
四、Amazon Scraper Skill:MCP 协议下的 Agent 原生数据接入
4.1 为什么需要专门的 Agent 数据工具
传统 API 调用在 Agent 场景的集成成本:
| 需要自己处理 | 工程复杂度 |
|---|---|
| API Key 管理和轮换 | 中 |
| 请求限速和退避策略 | 中 |
| CAPTCHA 失败重试 | 高 |
| 响应格式解析和类型转换 | 中 |
| 数据新鲜度判断 | 中 |
Pangolinfo Amazon Scraper Skill基于 MCP 协议封装,上述复杂度全部在 Skill 内部处理。
4.2 集成示例(概念代码)
# Agent 工具调用示例(伪代码,实际集成参考文档)
agent_tools = [
{
"name": "get_amazon_product",
"description": "Fetch real-time structured data for an Amazon ASIN",
"parameters": {
"asin": "string",
"marketplace": "string", # "US", "UK", "DE", "JP" 等
"fields": "array" # 按需指定返回字段,节省 token
}
}
]
# Agent 调用效果等价于:
result = scraper_skill.call("get_amazon_product", {
"asin": "B0XXXXXXXXX",
"marketplace": "US",
"fields": ["price", "bsr", "inventory_status", "rating"]
})
# 返回结构化 JSON,直接可用于 LLM 推理
# 无需解析,无需类型转换,无需处理采集异常
4.3 完整工具集覆盖
对于需要覆盖亚马逊数据采集全生命周期的团队:
| 数据类型 | 工具/API |
|---|---|
| 商品详情(ASIN 页面) | Amazon Scraper Skill / API |
| 搜索结果 | Amazon Scraper Skill / API |
| Best Sellers 榜单 | Amazon Scraper Skill / API |
| 评论数据 | Reviews Scraper API |
| 全数据集 MCP 接入 | Amazon Data MCP |
五、常见问题
Q: 数据过期了多久算严重影响决策?
取决于类目竞争激烈程度。价格战类目(3C 配件、日用品):超过 2 小时就有风险;相对稳定类目(大件、专业工具):12 小时内通常可接受。建议针对关键 ASIN 设置更高的刷新频率。
Q: 把原始 HTML 喂给 LLM,GPT-4 不是能理解吗?
理解 ≠ 准确提取。LLM 在理解非结构化文本的语义上很强,但在提取精确数值(尤其是页面格式变化后)上有不可忽视的错误率。结构化 JSON 是消除这一不确定性最低成本的方式。
Q: 自己维护爬虫 vs 使用托管 API,怎么选?
日均请求量 < 1,000 次:自维护可接受。1,000–10,000 次:托管 API 开始有成本优势(考虑工程维护成本)。> 10,000 次:托管 API 几乎必然是更优选择。
六、总结
亚马逊 AI Agent 决策质量改善路径:
❌ 错误路径:升级 LLM → 优化 Prompt → 引入 CoT → 仍然决策错误
✅ 正确路径:修复数据时效性 → 补全字段覆盖 → 结构化输入格式 → 显著改善
工程原则:
1. 数据新鲜度 > 数据量
2. 结构化 JSON > 原始 HTML(节省 60% token,提升 35-45% 准确率)
3. null + error_code > 零值(区分"采集失败"和"业务事实")
如果你正在构建亚马逊 AI Agent 并且遇到数据管道的具体问题,欢迎评论区交流。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)