
【大模型智能体】SkillNet: Create, Evaluate, and Connect AI Skills
SkillNet:构建AI技能的结构化网络 摘要:本文提出SkillNet,一个用于创建、评估和组织AI技能的开放基础设施。针对当前AI智能体缺乏系统化技能积累机制的问题,SkillNet通过统一本体框架将异构技能结构化,支持从多种来源创建技能并建立丰富关联关系。该系统包含20万+技能的存储库、交互平台和Python工具包,采用五维评估标准(安全性、完整性等)确保技能质量。实验表明,在ALFWor
SkillNet: Create, Evaluate, and Connect AI Skills
SkillNet:创建、评估和连接AI技能

当前AI智能体能够灵活调用工具并执行复杂任务,但其长期发展受限于缺乏系统化的技能积累与迁移机制。由于缺乏统一的技能整合框架,智能体常常“重复造轮子”,在孤立情境中重新发现解决方案,而未能利用既有策略。为突破这一局限,我们提出SkillNet——一个用于大规模创建、评估与组织AI技能的开放基础设施。SkillNet在统一本体论框架内结构化技能,支持从异构来源创建技能、建立丰富的关联关系,并围绕安全性、完整性、可执行性、可维护性与成本意识进行多维度评估。该基础设施整合了超过20万项技能的存储库、一个交互式平台以及一套多功能的Python工具包。在ALFWorld、WebShop和ScienceWorld上的实验评估表明,SkillNet显著提升了智能体性能:在多种骨干模型上,平均奖励提高40%,执行步骤减少30%。通过将技能形式化为可演化、可组合的资产,SkillNet为智能体从瞬时经验迈向持久精通提供了坚实基础。
1.引言
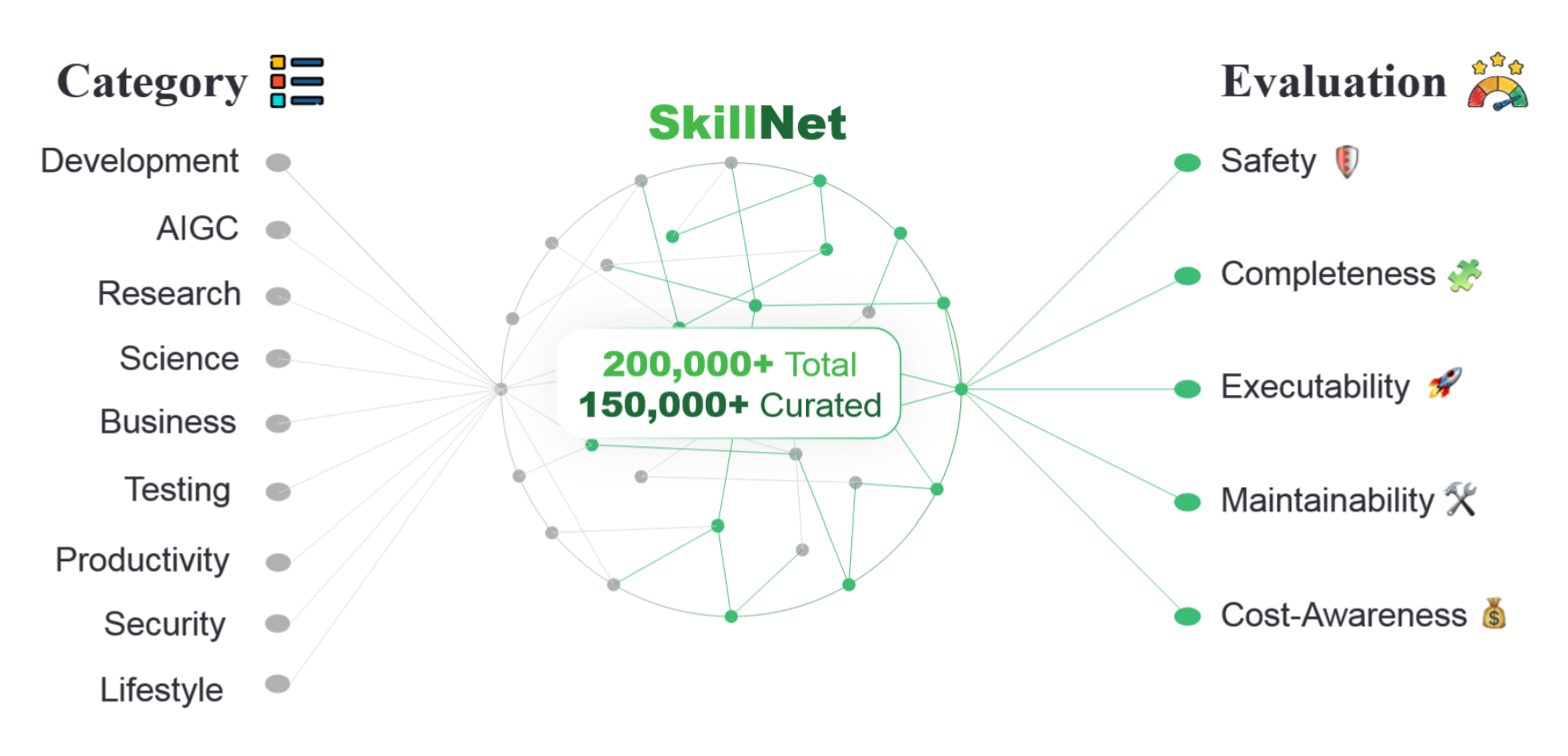
图1 SkillNet概述。SkillNet将大规模智能体技能组织为结构化技能网络,建模丰富的关系(如相似性、组合与依赖关系),支持多维度评估,并提供技能发现、创建与分析的统一接口。
正如理查德·S·萨顿所指出的,“我们正处于经验的时代”[1]。智能越来越不依赖于从零开始的知识获取,而是依赖于对从先前经验中提炼出的启发式方法的高效检索与自适应重用。这一转变标志着智能体时代的到来,人工智能由此超越静态的问答,转向编排长期、可执行的任务[2,3,4,5,6,7,8]。尽管近期在智能体系统方面取得了进展,但一个关键且尚未充分探索的问题依然存在:智能体如何系统性地将片段经验整合为持久且可迁移的专长?
当前AI方法很大程度上依赖人工工程或短暂的上下文学习[9,10,11]。尽管人类擅长将情景经验整合为可复用的图式[12],例如程序员内化算法逻辑而非仅仅记忆语法时,当代AI系统却难以跨越短暂上下文与长期能力之间的鸿沟。缺乏统一的技能巩固与共享机制,智能体在孤立情境中不断“重复造轮子”,即便是成熟的策略也极少影响未来任务。这一差距凸显出AI中显式结构与可扩展表示之间长期存在的张力,这一局限性在审视知识工程的历史演进时尤为明显[13]:
• 符号时代:系统依赖刚性符号逻辑,虽具可解释性,但存在脆弱性和扩展性受限的问题[14,15,16]。
• 深度学习时代:知识变为参数化,以高维权重矩阵形式存在。虽强大,但此类表示不透明且难以模块化复用[17,18]。
• 智能体时代(当前前沿):我们正目睹向智能体技能的汇聚,这些技能作为简单、可迁移的单元,为智能体提供新能力与专业知识,同时将智能从整体参数空间分离出来[19,20,21,22]。
这一历史轨迹表明,技能作为模块化、外显化的知识单元,正自然演进为一种兼顾结构可解释性与可扩展表征的形态。因此,智能体时代的关键挑战已不再仅仅是经验学习,而是将碎片化经验转化为持久、可组合的技能单元,以支撑通用化智能。然而,当前人工智能方法在两方面存在根本性不足。首先,缺乏统一的机制从经验中获取与整合技能。开源代码库、学术论文及智能体执行轨迹中虽蕴含大量宝贵经验[23, 24],但其结构松散、彼此割裂。不同于人类学习者能持续将外部信息内化为有组织的知识图式,智能体无法自动将这些资源提炼为可复用、可执行的技能。因此,技能获取仍是一个手动且离散的过程,而非自主积累的进程[3]。其次,缺乏确保大规模技能质量的原则性框架。若缺乏内在且系统的评估机制,技能库易受“污染”——其可执行性、安全性与鲁棒性仅能通过下游任务成功与否间接判断[25, 26, 27]。这种随机且不透明的验证方式引入技术债,削弱了长期能力增长,并阻碍智能体以可靠且可扩展的方式利用积累的经验。综上,这些不足凸显了对结构化框架的需求:该框架不仅应捕获并组织技能,还需严格评估并互联技能,以实现可靠的大规模知识复用。
为应对这些问题,我们提出SkillNet(图1),这是一个用于大规模创建、评估和组织AI技能的开放基础设施。我们将技能概念化为一种统一的知识表示,它桥接了非结构化的语言理解与结构化的、可机器执行的逻辑。SkillNet构建了一个全面的技能本体,包含三个相互关联的层级:用于功能分类的分类层级、编码依赖关系与组合的关系层级,以及用于模块化部署的技能包层级。为确保这些技能的可靠性,我们提出了一个多维评估框架,从安全性、完整性、可执行性、可维护性和成本感知性五个维度对技能进行评估。
我们的方法将从执行轨迹、开源代码库及文档等多个来源获取的碎片化经验,转化为一个包含超过20万个精选技能的结构化网络。在三个基于文本的模拟环境(ALFWorld、WebShop和ScienceWorld)中的实验结果表明,配备SkillNet的智能体实现了显著性能提升。例如,在各种骨干模型(如DeepSeek V3、Gemini 2.5 Pro和o4 Mini)上,我们的方法在将交互步骤减少30%的同时,将平均奖励提高了40%,这验证了系统性的技能积累能够以累积而非片段的方式有效增强智能体的能力。
我们的贡献总结如下:1. 我们提出了SkillNet,一个统一框架,将碎片化的智能体经验转化为结构化网络,包含模块化、可组合的技能及丰富的关联建模,为可操作的知识工程提供可扩展基础。2. 我们建立了严格的技能评估协议,从安全性、完整性、可执行性、可维护性和成本意识五个维度进行量化衡量,确保大规模技能库的可靠性。3. 我们发布了一个开源生态系统,包括一个包含超过20万个精心整理技能的仓库、一个Python工具包以及全面基准测试,实证表明在智能体规划与执行任务中性能显著提升。
2.Agent Skills
在主体系统的语境中,技能代表了一种轻量级、模块化且可复用的抽象层,用于扩展AI智能体的能力[28]。从概念上讲,技能封装了程序性知识、任务特定指令以及支持性资源,使智能体能够更准确、更高效且更一致地执行复杂任务。
在功能上,技能被组织为包含核心SKILL.md文件的结构化文件夹,该文件定义了技能的元数据和详细指令。元数据通常包括技能名称、用途简要描述及使用条件,而指令则提供执行步骤的逐步指导。技能还可选地包含执行任务所需的脚本、模板、文档及其他资源,从而形成自包含的能力包。
技能的核心目的是为智能体提供按需获取可复用程序性知识和特定情境信息的途径。例如,智能体可利用技能自动化数据分析流程、执行领域特定推理,或生成报告、演示文稿等结构化输出。通过封装这些能力,技能可实现一致且可重复的工作流程,减少对硬编码规则或临时性提示的依赖,并允许知识跨智能体、团队或应用进行共享。
技能通过一个渐进的三步流程运作:1. 发现:智能体最初仅加载最少的元数据(例如名称和描述),以识别出可能适用于给定任务的技能。2. 激活:当任务与某项技能的描述匹配时,智能体读取SKILL.md中的完整指令,并准备任何相关资源。3. 执行:智能体遵循指令,并可选地执行捆绑代码或利用引用的资产来完成该任务。
技能的主要优势之一在于其自文档化特性。嵌入的指令与结构化元数据使其易于理解、审计并迭代改进每项能力。从根本上说,技能作为一种统一的知识表示,整合了实体、关系、工作流及可执行代码,同时涵盖文本语义与符号化结果。这种混合表示使技能能够桥接非结构化语言理解与结构化、机器可执行逻辑。技能具有高度可扩展性,范围涵盖轻量级文本指导直至包含可执行程序与支持资源的复杂包。其基于文件、支持版本控制的特性确保了可移植性,使得同一技能能够以最小适配需求在不同智能体或系统间共享、复用与部署。
请注意,通过将领域特定知识和操作工作流封装为结构化且可复用的形式,技能为制度化业务逻辑提供了一种有效机制。这种结构化的专业知识积累不仅支持领域知识的系统化传播,还通过可复用、可靠且可组合的能力提升了智能体的表现。然而,在实践中,这些技能常常分散于脚本、提示或孤立的工作流中,其质量、可靠性和可复用性很少得到系统化评估。若缺乏统一的框架来组织、验证和演进技能,智能体便无法充分发挥这种模块化知识的潜力,从而限制了其持续演进和适应新任务的能力。这推动了SkillNet的研发。
3.SkillNet
3.1 概述
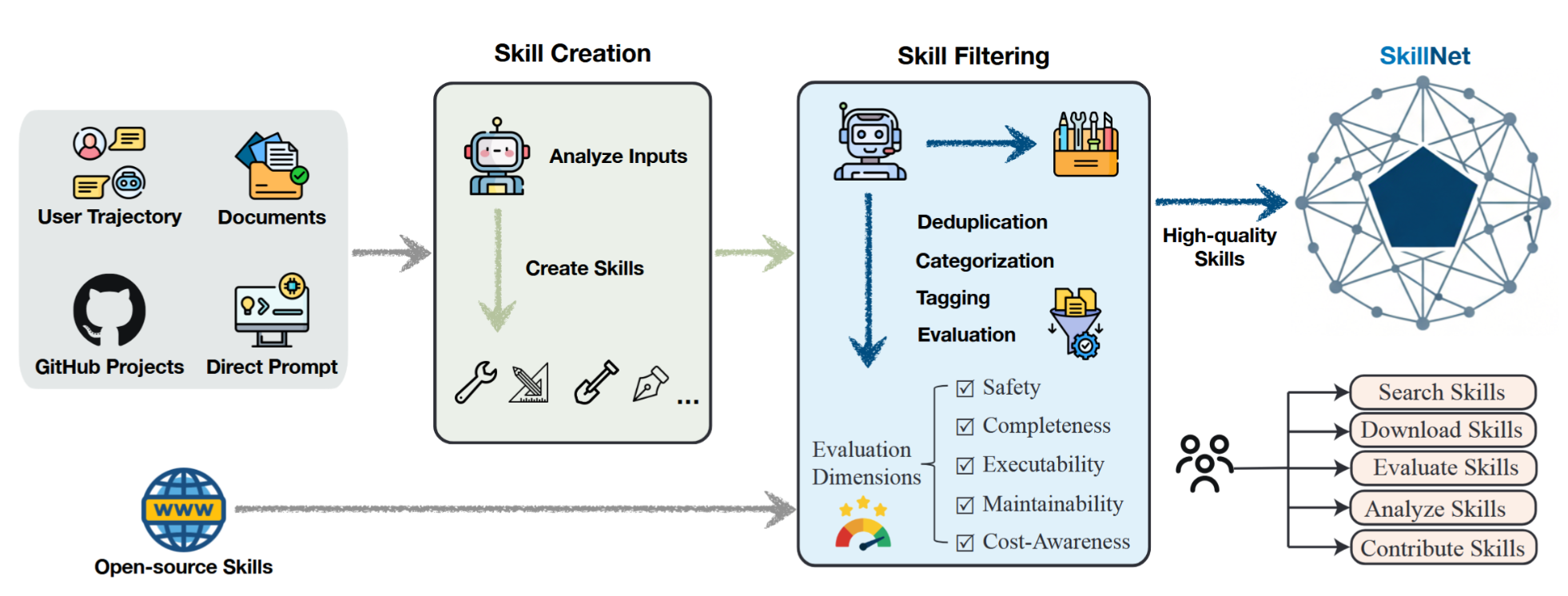
图2 SkillNet的端到端流水线。SkillNet通过自动化技能创建与多维度评估,将异构的用户输入与开放的互联网资源转化为可执行的技能,并将高质量技能组织成结构化网络,以支持搜索、下载、分析与贡献。
图2展示了SkillNet的整体架构,该架构系统地创建、评估并组织智能体系统所需的高质量技能。SkillNet旨在将碎片化的智能体经验与人类知识转化为可复用且可验证的技能实体,从而实现可扩展且可靠的能力增长。SkillNet包含三个核心模块:
技能创建。该模块分析多样化输入,包括用户轨迹、办公文档、GitHub项目、直接提示以及开放互联网资源。基于这些输入,SkillNet通过提取可执行模式并将其结构化为可复用能力,从而生成新技能。
技能评估。所生成的技能会依据多个主要维度进行筛选与评估,包括安全性、完整性、可执行性、可维护性以及成本意识。这一评估流程确保仅保留高质量技能,从而减少冗余、脆弱性及潜在风险。
技能分析。超越孤立的技能,SkillNet自动分析技能之间的结构和功能关系,构建大规模技能图,捕捉相似性、层次结构、组成和依赖模式。这种结构化表示使得能够在技能库上进行全局推理,支持高效的检索、组合和工作流合成。
开放资源。SkillNet在结构化存储库中组织经过精心策划的高质量技能,提供多功能工具箱,使用户与智能体能够高效地搜索、下载、创建、评估、分析并贡献技能。通过提供这些标准化的技能交互接口,SkillNet促进了跨任务、跨领域及跨智能体群体的无缝技能复用与协同演化。
3.2 技能本体
技能本体论将个体技能组织成一个结构化、可组合的网络,如图3所示。该架构分为三个递进层次: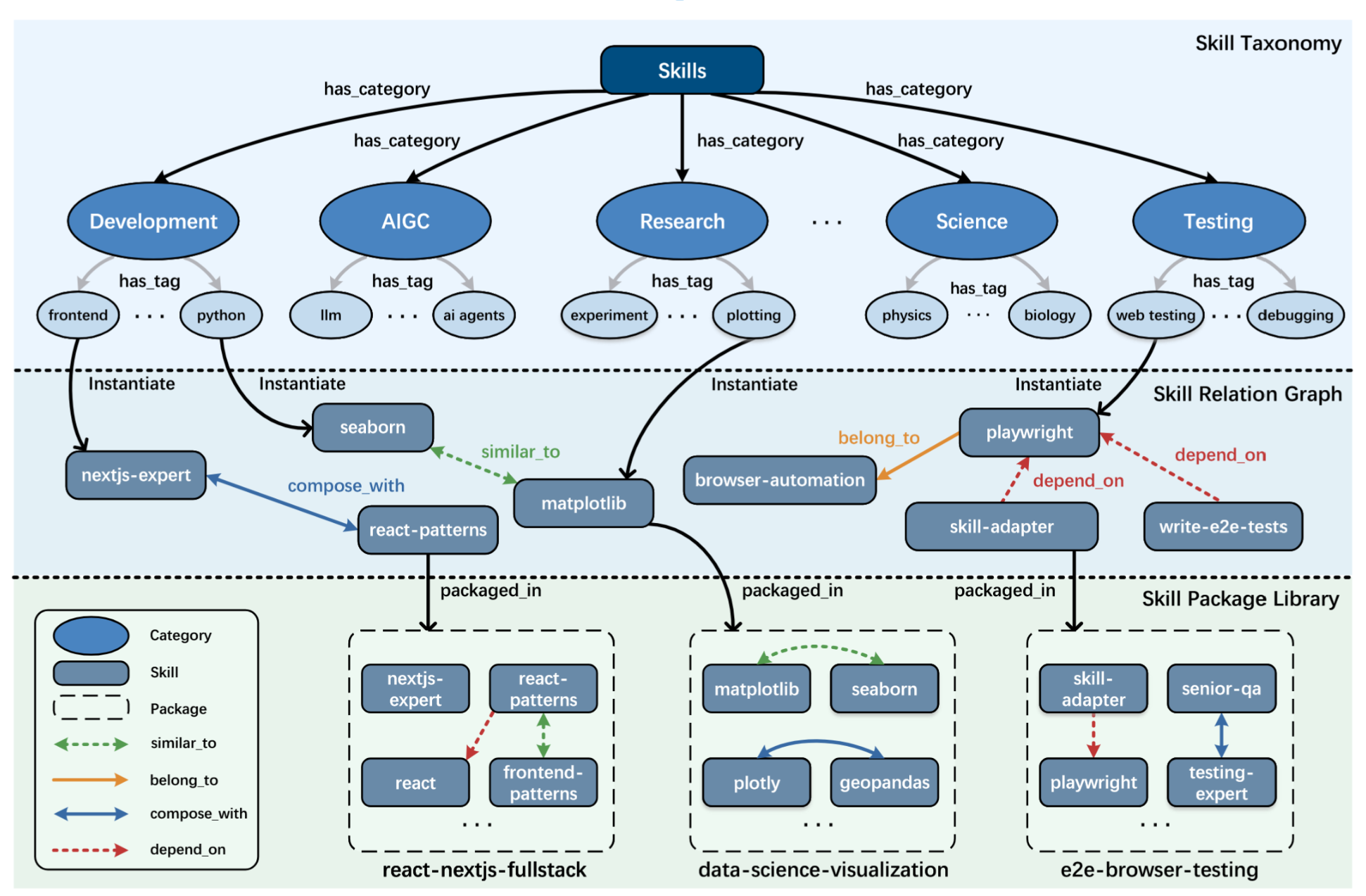
图3 SkillNet的技能本体。它包含三个层次:技能分类(顶部)定义了功能类别;技能关系图(中部)建模了技能间的依赖关系和语义关联;技能包库(底部)将技能组织为模块化、面向任务的包。
技能分类法。该层利用类别和标签关系将技能组织成多级层次结构。它将广泛的领域(例如开发、AIGC、科学……)分类为细粒度的标签(例如前端、大语言模型、物理),提供了一个高层级的语义骨架。
技能关系图。该层将抽象标签实例化为具体的技能实体(例如Matplotlib、Playwright),并通过多关系边(similar_to、compose_with、belong_to、depend_on)定义核心交互逻辑,构成推理与规划的基础骨架。
技能包库。底层代表技能的实际组织结构。单个技能通过packaged_in关系封装为技能包(例如data-science-visualization),从而实现模块化的发布与部署。
请注意,技能本体是动态的,它建模了技能之间的关系。标签可以从分类体系中不断添加,大型语言模型从中推断关系,从而能够实例化一个技能关系图。
3.3 技能创造
SkillNet 将技能概念化为介于抽象陈述性知识与具体可执行程序之间的中间能力单元。具体而言,我们开发了一个自动化创建流程,能够系统性地将异构信息源转化为标准化、可复用的主体技能。
3.3.1 从人类体验到技能抽象
为了构建一个全面且通用的技能库,SkillNet从多样化的数据源中抽象出技能,将异质信息转化为可复用的结构化智能体技能。我们设计了一条多源自动化技能创建流水线,使SkillNet能够从异质的人类知识与经验中归纳出智能体技能。具体而言,SkillNet支持四大类数据源:(1)执行轨迹与对话交互日志,(2)开源GitHub仓库,(3)半结构化文档(包括PDF、PowerPoint和Word文件),以及(4)用户直接提供的自然语言提示。这一过程完全通过大语言模型实现,用户也可自定义底层模型。此外,SkillNet通过开放互联网资源、内部开发及社区贡献持续扩充其技能库,确保可持续的扩展性与覆盖范围增长。
3.3.2 数据驱动的技能过滤与整合
技能的自动构建并不意味着无差别的累积。相反,SkillNet引入了一条数据驱动的过滤与整合流水线,以确保技能库的质量。具体而言,SkillNet采用了一个多阶段的策展流程,包括去重、过滤、分类与打标、评估以及最终的选择性整合。去重通过联合比较技能目录结构和技能Markdown文件的MD5哈希值来执行,有效去除冗余技能。过滤则通过基于规则的验证和基于模型的检查,剔除低质量、不完整或语义无意义的技能。分类与打标将每个技能归入十个功能类别之一(开发、AIGC、研究、科学、商业、测试、生产力、安全、生活方式、其他),并分配细粒度的语义标签以方便检索和组合。随后,应用多维度评估机制决定一个技能是否被收录到SkillNet库中。SkillNet基于本体定义的关系自动建立技能间的关联,最终形成一个结构化的技能包库。这一结构化流水线使SkillNet能够作为一个自演进的技能生态系统运行,而非静态的技能集合,持续提升技能的质量与覆盖范围。
3.4 技能评估
尽管技能创造重要,但技能库的实用性最终取决于其可靠性。为了弥补现有库因缺乏标准化评估而留下的空白,我们提出了一个多维系统评估框架。
我们定义了五个核心维度,以定量评估每项技能的质量与就绪程度:
• 安全性:评估潜在风险,包括危险系统操作(例如未授权的文件删除),以及对提示注入或对抗性操纵的鲁棒性。
• 完整性:评估技能是否囊括所有关键步骤,并明确定义必要的先决条件、依赖关系和执行约束。
• 可执行性:验证技能能否由智能体在沙盒环境中成功实施,识别虚构的工具调用或模糊指令。
• 可维护性:衡量技能的模块化与组合能力,确保其可在不破坏全局依赖关系或后向兼容性的前提下进行局部更新。
• 成本感知:量化执行开销,包括时间延迟、计算资源消耗和API使用成本,以支持效率优化。
为了实现高通量评估,所有维度主要通过基于LLM的自动评估器(以GPT-5o-mini实例化)并依据细粒度评分标准进行初步评估。对于可执行性,我们通过经验验证来补充LLM的判断:包含代码或工具调用的技能在受控沙箱环境中执行,以验证运行时正确性。每个维度分为三个等级:良好、一般和较差。
整个仓库的质量分布如图4(a)所示。我们观察到,尽管安全性和可维护性中“良好”评级占比很高,但可执行性面临更大挑战,被评为“一般”的技能比例更高。这反映了我们严格的筛选标准,确保只有高保真度的技能被优先用于复杂任务执行。
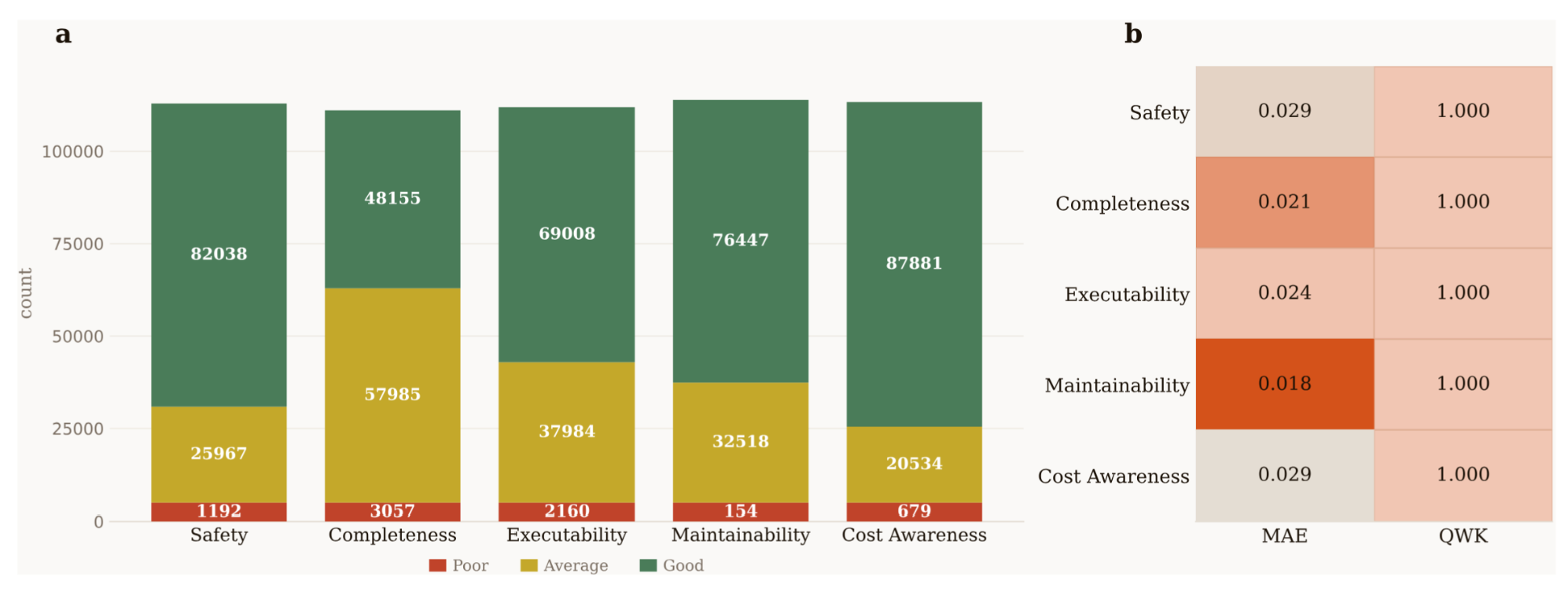
图4 多维技能评估与可靠性分析。(a) SkillNet中精选技能的质量分布,采用三级评分方案评估,其中大多数技能被评为“良好”或“一般”。(b) 在200个随机抽样的技能上对自动评估器进行可靠性验证。热图显示了人工标注者与模型评估器之间的平均绝对误差(MAE)和二次加权kappa(QWK),所有维度上的QWK接近完美且MAE较低,证明了评估框架的鲁棒性和可扩展性。
为验证此自动化管线的可靠性,我们随机抽取了200项技能,并邀请三位具有博士学位的计算机科学标注员进行独立盲审。如图4(b)所示,人工评判与基于大语言模型的评分之间展现出高度一致性。在所有维度上,平均绝对误差(MAE)均低于0.03,二次加权卡帕系数(QWK)持续接近完美水平(1.000)。这些结果证实,我们的自动化评估器为SkillNet生态系统的管理提供了与人类对齐、稳健且可扩展的基础。
3.5 技能分析
超越孤立的技能创建与评估,大规模技能库引入了一项新挑战:如何系统地理解、组织并利用技能之间的关系。为此,SkillNet引入了专门的技能分析模块,该模块能够自动发现并建模技能之间的结构关系,形成结构化且可解释的技能关系图。这使得对大规模技能库进行全局推理成为可能,并支持技能检索、技能组合、依赖解析及工作流合成等高级下游应用。
关系建模。SkillNet将技能分析构建为结构化关系发现问题。给定大量异构技能,系统自动识别并标注技能之间多种类型的语义和功能关系,包括(此处省略任务特定关系,用户可根据需要定义自定义关系扩展模式):
• similar_to:两种技能在执行功能上等效或高度相似的任务,通常可互换使用,从而实现冗余检测、替换和鲁棒性增强。
• belong_to:一个技能作为更大复合工作流中的子组件或原子步骤,捕捉层次化结构并支持技能抽象与模块化。
• compose_with:两个技能在工作流中频繁协同调用,其中一个通常产生供另一个使用的输出,从而实现自动工作流组合与流水线生成。
• depend_on:一个技能无法独立执行,需要前置技能(如环境设置或API初始化),从而实现显式依赖追踪与安全执行规划。
自动化技能关系图构建。SkillNet 能够通过集成语义嵌入和基于大语言模型的关系推理的混合流水线,构建大规模技能关系图。候选关系首先通过相似度匹配、依赖提取、执行轨迹对齐以及大语言模型推理生成,从而实现可扩展且准确的结构化技能关系发现。这些关系共同构成一个有向、带类型的多关系图,其中节点表示技能,边编码细粒度的结构依赖和功能关联。
面向任务的技能集合发布。为促进可重复性与实际应用,SkillNet发布了超过20个面向特定任务的技能集合,涵盖自动化科研、软件开发、数据处理流程、网络自动化等领域。特别地,若干集合专为学术基准设计,我们通过定量评估来检验这一范式的有效性,详见后续章节。这些已发布的集合为研究大规模智能体规划、工作流合成及技能演化提供了结构化且可复用的基础设施,从而为未来结构化智能体智能的研究奠定基础。
3.6 开放资源
SkillNet提供了一个全面的开放基础设施,用于大规模创建、评估和组织AI技能。这包括一个大规模技能库、一个前端网站、一个开放访问API以及一个多功能Python工具包(skillnet-ai),共同构成一个统一的技能管理与应用生态系统。
前端网站允许用户直接无缝浏览、搜索和下载技能。用户可探索技能分类,查看详细的API文档及Python工具包使用指南,并学习如何将SkillNet应用于科研或编程场景。该平台还支持社区贡献,使用户能够提交和分享新构建的技能,从而培育一个协作且持续演进的技能生态体系。
对于API访问,SkillNet支持基于关键词和基于向量的搜索。用户可以通过http://api-skillnet.openkg.cn/v1/search按关键词、类别或语义相似度搜索技能。为了弥合静态仓库与动态执行之间的差距,我们开发了skillnet-ai,一个统一的Python库和CLI工具,能够灵活地与用户集成。通过该工具包,用户可以通过关键词或语义相似性搜索技能,直接从GitHub下载技能到本地工作空间,并从异构源(包括执行轨迹、GitHub仓库、办公文档和自然语言提示)创建结构化技能。该包还支持多维度评估技能(安全性、完整性、可执行性、可维护性和成本意识)以确保实际可靠性,并分析技能之间的关系以揭示依赖关系、层次组合、协作关系及功能相似性。实际使用示例见图5。
SkillNet 已初步从开放互联网资源、自动化创建流程及社区贡献中聚合了超过 20 万个候选技能。经过多阶段筛选与评估,最终仓库中精选出逾 15 万个高质量技能(且该数量持续增长)。这一规模在确保严格质量标准的同时,实现了对多场景的广泛覆盖,使 SkillNet 能够作为可靠的技能基础设施服务于科学研究和实际部署。我们积极鼓励社区贡献,所有社区提交的技能均需接受相同的自动化质量检查。此外,我们还通过随机抽样定期进行人工审核,以确保共享技能仓库的持续可靠性与完整性。
4.定量评估
4.1 设置
为定量评估SkillNet的有效性,我们在三个基于文本的模拟环境中进行了实验。ALFWorld [29]提供了一个具身家庭环境,要求智能体导航并操作物体以完成日常任务;WebShop [30]模拟了真实的在线购物场景,智能体需在指定约束下执行产品搜索、比较和购买操作;ScienceWorld [31]则呈现了一个虚拟科学实验室,智能体必须在此进行实验并操作科学仪器。这三个环境均被构建为部分可观测马尔可夫决策过程(POMDP),要求智能体在不完整且带有噪声的观测下做出序列决策。
我们采用 ReAct [32]、ExpeL [20] 和标准 Few-Shot 方法作为基线方法。ReAct 将推理、行动和观察交错进行,以逐步解决问题。ExpeL 从过往任务中积累经验以提取自然语言洞察,并在推理过程中检索以往的成功轨迹作为上下文示例。Few-Shot 基线随机采样一条完整的专家轨迹,作为静态的上下文示例。相比之下,我们提出的变体通过利用来自 ETO [33] 的专家轨迹,借助 SkillNet 进行增强,以合成基准特定的技能集合(这些集合被整合到 SkillNet 中,用户可以通过创建相应的技能将其扩展到其他数据集)。请注意,上述经验与测试集的可见及不可见划分之间没有重叠,从而防止了数据泄露。在评估过程中,智能体配备这些集合,能够根据当前状态动态选择、激活并执行最相关的技能。我们采用三种代表性的大语言模型:DeepSeek V3.2 [34]、Gemini 2.5 Pro [35] 和 o4 Mini [36] 作为骨干模型。
4.2 结果
表1和图6展示了在不同环境和骨干模型下的量化结果。总体而言,集成SkillNet在任务有效性和执行效率上均带来了显著提升,验证了我们框架的有效性。与ReAct相比,SkillNet将平均奖励提高了40%,同时将交互步骤数平均减少了30%,这表明配备SkillNet的智能体能够在执行更短、更连贯的动作轨迹的同时,更可靠地完成任务。这反映了SkillNet将碎片化经验转化为可重用的程序化抽象的能力,使智能体能够进行结构化规划、减少冗余探索,并以更规范、更系统的方式执行复杂行为。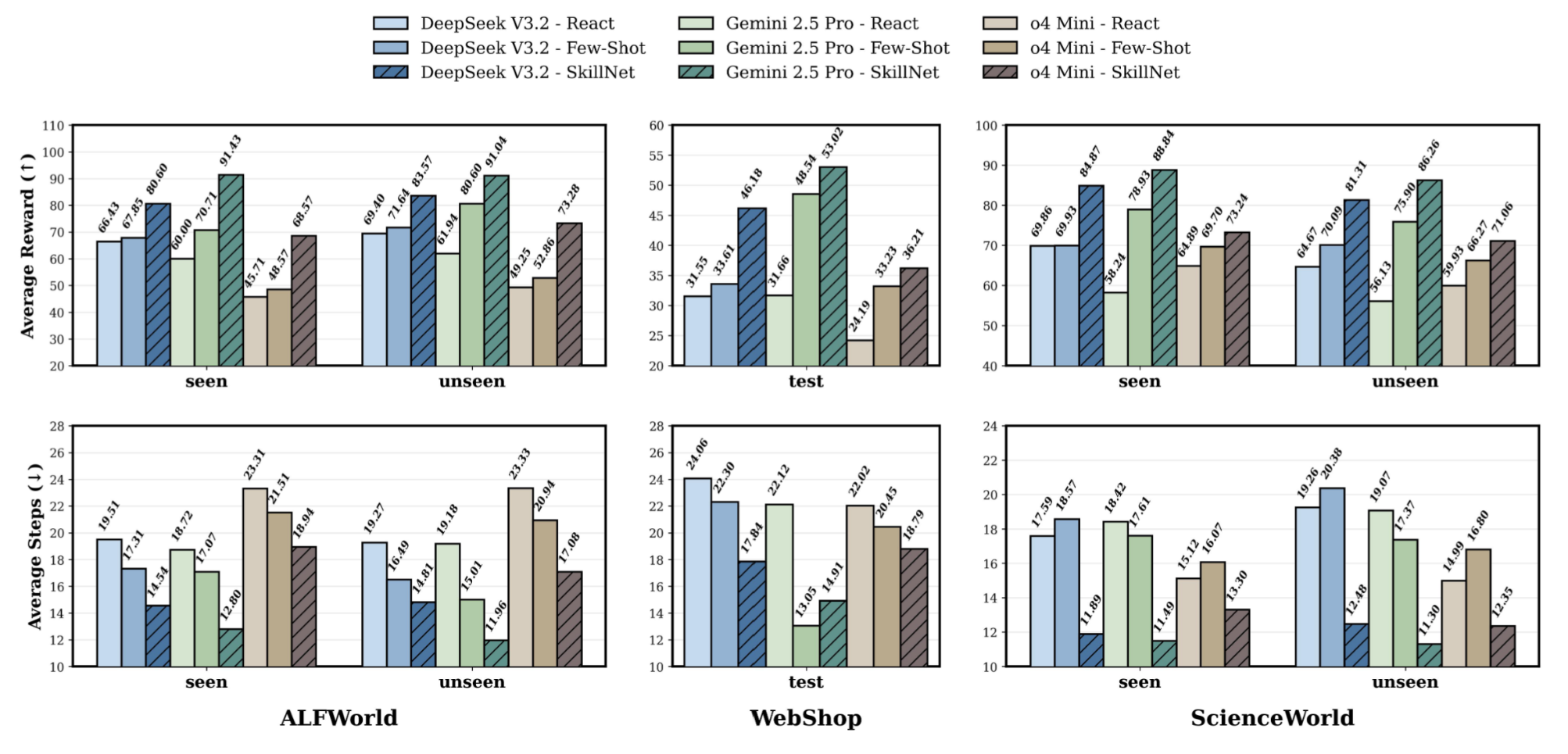
图6 不同方法与模型之间的性能比较。结果表明,SkillNet持续优于React和Few-shot基线,在ALFWorld、WebShop和ScienceWorld上实现了显著更高的平均奖励(上)以及更少的平均步骤(下)。
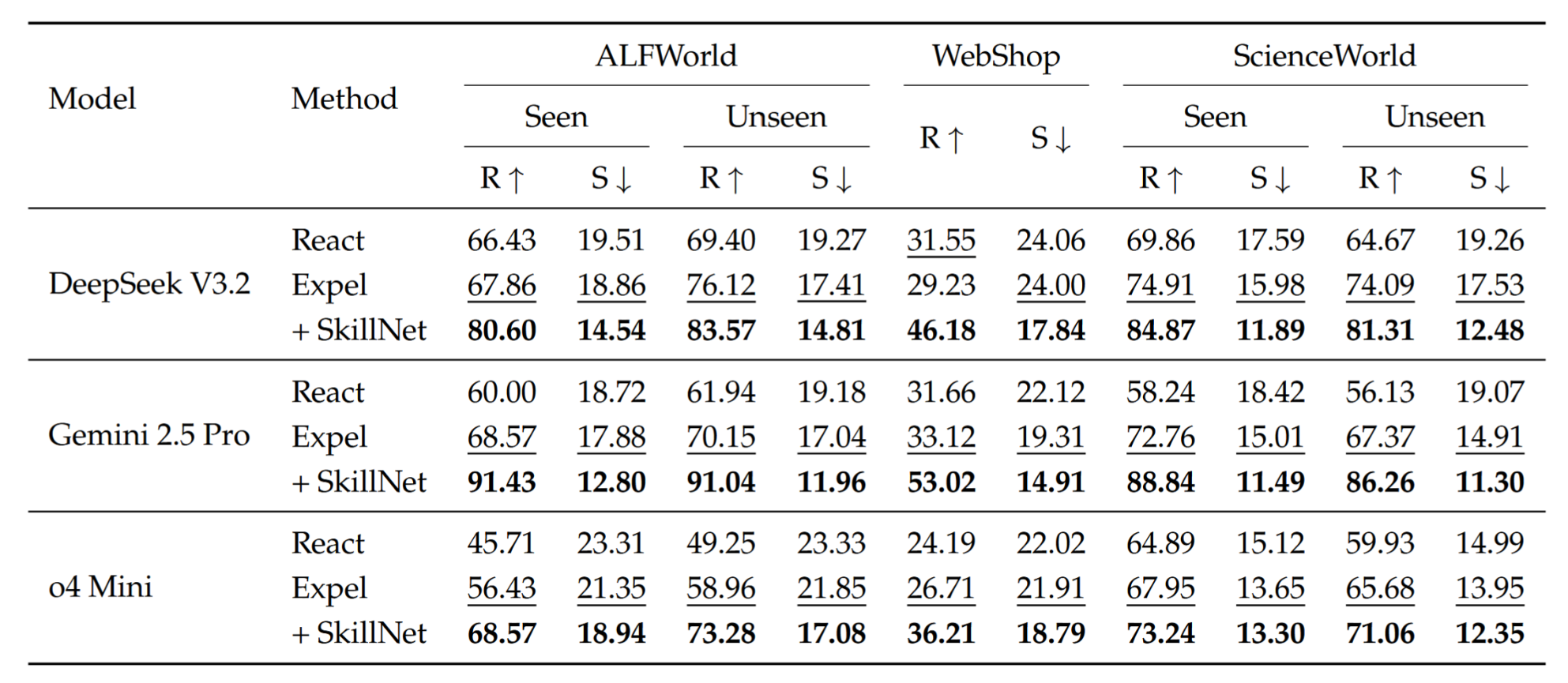
表1 ALFWorld、WebShop和ScienceWorld上的实验结果。R表示平均奖励,S表示平均步数(↑表示数值越大越好,↓表示数值越小越好)。表现最佳的结果以粗体显示,次佳的结果以下划线标出。
重要的是,性能提升在不同规模的基础模型上均保持稳健,从紧凑模型(o4 Mini提升15.7 R)到大型语言模型(Gemini 2.5 Pro提升28.5 R)皆如此。这表明SkillNet提供了超越参数知识的互补能力,通过持久且可执行的技能有效增强了推理能力。此外,在已见和未见场景下观察到的一致增益凸显了SkillNet强大的泛化能力,表明技能抽象与复用促进了跨任务和跨环境的知识迁移。
综合来看,这些结果验证了SkillNet的核心设计原则:通过将技能形式化为独立、系统积累、基于知识的能力单元,智能体的能力能够以渐进式而非片段式的方式得到增强,最终促成领域专业化且持续自我进化的智能体。
5.应用场景
如图7所示,SkillNet通过将专业技能组织成连贯的工作流,弥合了高层次用户意图与可执行的智能体动作之间的差距。下文将详细阐述其在自主科学发现与编码智能体场景中的具体效用。请注意,这些示例均为说明性原型,不代表实际应用。
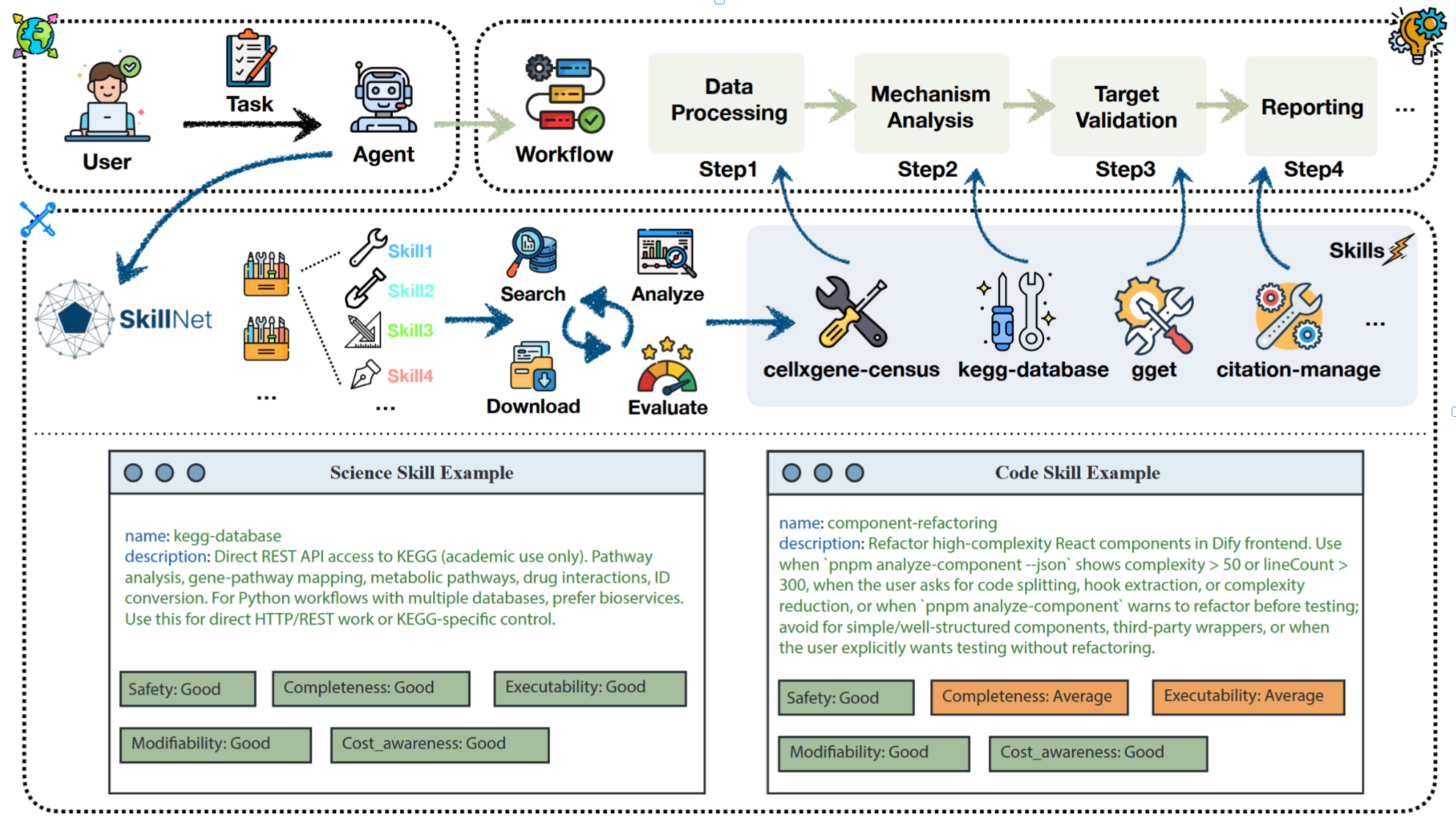
图7 SkillNet应用场景示例。该框架将用户任务分解为可操作的步骤(上方),并在科学与编程场景中展示了代表性技能获取与多维评估(下方)。
5.1 SkillNet用于自主科学发现
在本节中,我们展示了SkillNet如何将异构智能体技能组织成一个连贯、可执行且可评估的研究工作流。该系统执行从大规模生物数据中识别潜在疾病相关基因和候选治疗靶点的科学任务,最终生成具有学术可读性的研究报告。
SkillNet首先调度数据处理技能,对单细胞RNA-seq数据进行清洗和聚类,从而识别关键遗传标记。随后,SkillNet调用机制分析与靶点验证技能,将这些基因映射至生物通路,并交叉验证其临床意义。最后,SkillNet激活报告生成技能,将碎片化的分析结果整合为附带正式引用的结构化科学文档。
该过程深刻体现了SkillNet的核心价值:将零散的研究技能转化为一个结构化、可组合的能力网络。这种架构使AI科学家能够超越单一领域任务的局限,有意义地参与复杂科学发现的完整闭环过程。
5.2 面向自主编码智能体的SkillNet
在本节中,我们构建了一个针对大规模软件工程任务的编码场景,以展示SkillNet在复杂代码理解、重构和功能开发方面的潜力。该场景的目标是在现有生产级代码库中执行功能扩展和结构演化,同时确保正确性、性能和长期可维护性。
工作流始于SkillNet调度代码分析技能,以构建系统架构的结构化表示。随后,它协调需求分解与影响分析技能,将高层功能需求精确映射到具体代码级修改目标,同时评估回归风险。在实施阶段,SkillNet将生成、测试与验证技能组织成一个闭环迭代过程,利用实时反馈驱动自动修正。最后,它调用维护技能,生成具有完整可追溯性的架构更新文档。
这一场景展示了SkillNet的核心价值:将复杂的软件工程挑战重塑为能力组合与协调问题。通过将编码、分析和测试等碎片化技能重组为结构化的智能体技能网络,SkillNet为复杂工程任务提供了可靠且可扩展的自动化范式,使AI能够胜任系统级的软件演化。
5.3 使用OpenClaw与SkillNet
在本节中,我们展示了SkillNet如何与OpenClaw2(一个高度可定制的开源个人AI智能体框架)集成。OpenClaw采用惰性加载技能设计:在会话初始化时,仅将紧凑的技能元数据注入系统提示,而完整指令则在触发时按需加载。SkillNet作为该框架中的一个技能被集成,赋予智能体动态技能获取、质量感知库管理以及经验驱动知识创造的能力。
安装后,SkillNet 会引入三种核心行为模式,这些模式会根据对话上下文自动激活。首先,当用户提出复杂或不熟悉的任务时,智能体会对 SkillNet 仓库执行任务前搜索,以定位相关技能。随后,它会将匹配的技能下载到本地工作区,并读取检索到的 SKILL.md 文件,以提取适用的模式与工具配置。此外,当用户提供 GitHub 仓库 URL 或分享 PDF 等文档时,智能体可直接调用 skillnet create 从该源生成结构化技能,使外部知识立即可用于当前任务。其次,当用户请求技能库整理或质量审计时,智能体会调用 SkillNet 的 analyze 和 evaluate 命令,生成结构化报告,其中包含多维度质量评分以及技能间关系图,涵盖 similar_to、belong_to、compose_with 和 depend_on 等边。最后,在完成一项涉及非明显或可复用知识的任务后,或当用户明确要求经验整合时,智能体会主动调用 skillnet create 将解决方案打包为标准技能,并运行自动评估以验证其质量,然后再将其纳入仓库。
这种集成建立了一个闭环:社区贡献的技能指导任务执行,成功的结果被整合为新技能,定期分析维护知识库质量。OpenClaw + SkillNet 组合并非将每次对话视为孤立事件,而是通过结构化的技能循环将通用型智能体转变为持续自我改进的系统,直接支持可扩展、持续进化的智能体愿景。
6 相关工作
6.1 经验巩固与技能抽象
基于大语言模型的智能体已通过工具、规划和记忆扩展,以在复杂环境中执行长周期任务[3,4,5,6,27]。多项研究探索了智能体如何通过交互和经验获取及优化技能。Reflexion[19]与Expel[20]研究了智能体如何总结失败并提取纠正性反馈。以记忆为中心的方法旨在积累长期经验以支持持续学习[37,38,39,40]。其他研究则探讨了结构化技能学习与跨任务复用,以促进跨领域的泛化与迁移[24,41,42,43,44,45,46,47]。尽管取得了这些进展,大多数方法仍通过将技能隐式编码于提示词、潜在记忆或松散组织的工作流中来表示技能,从而阻碍了系统性的整合、评估与复用。
6.2 技能库与评估
与智能体系统的发展并行,一批社区驱动的技能库[25, 26, 48, 49]和评估[50, 51, 52]已涌现出来,用于整理智能体技能,旨在促进重用、标准化及生态系统级别的协作。例如,像ClawHub这样的平台充当类似npm的版本管理平台,而SkillsMP和Skills.sh则作为聚合GitHub仓库的庞大开源目录。此外,SkillHub引入了高级市场功能,具备预定义的技能栈和基本评分系统。最近,Li等人[53]提出了SkillsBench,这是一个涵盖86项任务、11个领域的基准测试,表明经过整理的智能体技能能够显著提升大语言模型智能体的性能(平均提升16.2个百分点),而自生成的技能则无增益,这揭示了模型受益于消费(技能)但无法可靠地创作(技能)。程序性知识。这些平台提供了共享提示词、工具封装及任务解决模板等宝贵资源。
如表2所总结,现有平台主要作为静态包管理器或市场运营,面临三个关键局限:首先,它们高度依赖人工策展和临时质量控制,缺乏从智能体轨迹或现有代码库中动态生成技能的自动化机制。其次,其评估实践主要关注简单的社区指标(如仓库星标)或终端任务性能,未能提供对安全性、完整性、可执行性、可维护性及成本意识等内在属性的全面洞察。第三,这些技能集合常存在冗余、脆弱性和可组合性差的问题,因为技能被视为孤立实体,限制了其在大型智能体群体中的可扩展性。
这些局限性促使我们需要一个统一的框架来实现技能的组织、验证与演化。与以分布为中心的平台不同,我们提出的SkillNet提供了一套全生命周期的基础设施。它通过基于LLM流水线的自动化技能创建、严格的多维度评估以及将孤立工具编织成结构化技能图谱的关系连接,解决了上述瓶颈,从而为自我演化的智能体生态系统提供了全面的基础支撑。
7 结论、讨论与未来工作
在本工作中,我们介绍了SkillNet,一个用于大规模创建、评估和组织AI技能的开放基础设施。通过系统性地整合经验、结构化技能并提供原则性评估,SkillNet使得智能体能够累积式改进、跨任务可靠执行,并适应复杂的开放式环境。该框架为可扩展的持续学习与稳健的技能组合奠定了基础,弥合了原始模型能力与持续演进智能之间的差距。
概念上,SkillNet 建立在智能体生成能力的三种互补约束的统一视角之上:工作流、记忆和技能。工作流施加明确的程序性结构,确保可靠性,但本质上僵化。记忆积累情境性经验和联想性知识,支持适应性,但缺乏操作边界。技能通过封装可重用的能力单元来桥接这两个极端,既能约束生成,又能将记忆组织为可操作的模式。在这一视角下,技能充当了使记忆可执行、工作流变得灵活的结构化接口。
展望未来,“单人公司”或“单人实验室”的新兴范式设想了一位专家统筹协调智能体社会。通过SkillNet,技能成为知识整合与委托的基本单元:个人管理技能库,智能体将其组合为工作流,记忆则通过经验不断优化它们。这一闭环将孤立的自动化转化为累积的机器专长,使最小化的人类团队能够实现组织级别的智能。
开放世界技能进化。在开放世界环境中实现自动技能发现、抽象化及跨域迁移仍极具挑战性。在工业制造、金融及科学研究等领域,这要求对复杂任务进行动态组合与优化。特定行业的私有SkillNet本身可能成为智能体基础设施的基础组件。此外,将技能进化机制与在线反馈、因果推理及不确定性建模相结合,有望提升技能选择的可靠性。
模型-技能协同。尽管SkillNet为智能体提供了大规模的可执行技能,但这些技能与底层模型能力之间的协同作用仍 未被探索。特别是,如何利用神经符号集成和记忆机制,使技能结构能够引导模型决策路径,并在模型能力演化过程中动态重构技能层次结构与依赖关系,这一问题仍是系统化研究的核心。
多智能体协作与知识共享。在多智能体环境中,SkillNet可作为共享表示与交换层,支持智能体间的协作规划、知识迁移及经验积累。通过将智能体行为持续整合为可复用技能,SkillNet进一步推动数字化身的涌现——其能力逐步从积累的技能中提炼而成。更广泛而言,这一范式或将为集体智能开辟新路径:技能演化为可迁移、可组合的协调单元,数字人格得以继承、共享并扩展超越单个智能体的能力边界。
8 限制
当前工作仍存在若干局限性。首先,技能覆盖范围不可避免地存在不完整性。许多私有或专业领域的能力无法被纳入,而低频或高度隐性的技能难以在知识库中捕获和整合,尤其是当它们难以用显性语言描述时。其次,自构建技能的质量无法完全保证。尽管我们的评估流程过滤掉了一些问题案例,但仍有大量技能缺乏严谨且系统的评估。若恶意用户贡献“污染”或对抗性技能,SkillNet当前的安全评估机制虽能检测部分此类案例,但无法完全消除其影响。第三,目前尚未建立起通过SkillNet将自然语言需求转化为完整智能体的端到端流程;这仍是未来工作的重要方向。我们将持续对系统进行策展、维护与改进。
引用文献
- [1] David Silver and Richard S Sutton. Welcome to the era of experience. Google AI, 1, 2025.
- [2] Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web conference 2022, pages 2778–2788, 2022. URL https://dl.acm.org/doi/10.1145/3485447. 3511998.
- [3] Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, Qi Zhang, and Tao Gui. The rise and potential of large language model based agents: a survey. Sci. China Inf. Sci., 68(2), 2025. URL https://doi.org/10.1007/s11432-024-4222-0.
- [4] Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Sean Follmer, Jeff Han, Jürgen Steimle, and Nathalie Henry Riche, editors, Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST 2023, San Francisco, CA, USA, 29 October 2023- 1 November 2023, pages 2:1–2:22. ACM, 2023. URL https://doi.org/10.1145/3586183.3606763.
- [5] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024. URL https://openreview.net/forum?id=ehfRiF0R3a.
- [6] Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, Yu Qiao, Zhaoxiang Zhang, and Jifeng Dai. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory, 2023. URL https://arxiv.org/abs/2305.17144.
- [7] Runnan Fang, Xiaobin Wang, Yuan Liang, Shuofei Qiao, Jialong Wu, Zekun Xi, Ningyu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Synworld: Virtual scenario synthesis for agentic action knowledge refinement. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 437–448. Association for Computational Linguistics, 2025. URL https://doi.org/10.18653/v1/2025.acl-short.33.
- [8] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 1(2), 2023. URL https://arxiv.org/abs/2303.18223.
- [9] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 1107–1128. Association for Computational Linguistics, 2024. URL https://doi.org/10.18653/v1/2024.emnlp-main.64.
- [10] Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. CoRR, abs/2402.07927, 2024. URL https://doi.org/10.48550/arXiv.2402.07927.
- [11] Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026.
- [12] Douglas L Hintzman. " schema abstraction" in a multiple-trace memory model. Psychological review, 93(4):411, 1986.
- [13] Rudi Studer, V. Richard Benjamins, and Dieter Fensel. Knowledge engineering: Principles and methods. Data Knowl. Eng., 25(1-2):161–197, 1998. URL https://doi.org/10.1016/S0169-023X(97)00056-6.
- [14] Clarence Irving Lewis, Cooper Harold Langford, and P Lamprecht. Symbolic logic, volume 170. Dover publications New York, 1959.
- [15] Roberto Baldoni, Emilio Coppa, Daniele Cono D’elia, Camil Demetrescu, and Irene Finocchi. A survey of symbolic execution techniques. ACM Computing Surveys (CSUR), 51(3):1–39, 2018. URL https://dl.acm.org/doi/10. 1145/3182657.
- [16] Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, et al. Knowledge graphs. ACM Computing Surveys (Csur), 54(4):1–37, 2021. URL https://dl.acm.org/doi/10.1145/3447772.
- [17] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. nature, 521(7553):436–444, 2015. URL https://www.nature.com/articles/nature14539.
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pages 770–778. IEEE Computer Society, 2016. URL https://doi.org/10.1109/CVPR.2016.90.
- [19] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/ 1b44b878bb782e6954cd888628510e90-Abstract-Conference.html.
- [20] Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 19632–19642. AAAI Press, 2024. URL https://doi.org/ 10.1609/aaai.v38i17.29936.
- [21] Boyuan Zheng, Michael Y Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, et al. Skillweaver: Web agents can self-improve by discovering and honing skills. arXiv preprint arXiv:2504.07079, 2025. URL https://arxiv.org/abs/2504.07079.
- [22] Xiaoxiao Li. When single-agent with skills replace multi-agent systems and when they fail. arXiv preprint arXiv:2601.04748, 2026. URL https://arxiv.org/abs/2601.04748.
- [23] Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineering via agentic skill evolution, 2026. URL https://arxiv.org/abs/2601.21557.
- [24] Tianyi Chen, Yinheng Li, Michael Solodko, Sen Wang, Nan Jiang, Tingyuan Cui, Junheng Hao, Jongwoo Ko, Sara Abdali, Leon Xu, Suzhen Zheng, Hao Fan, Pashmina Cameron, Justin Wagle, and Kazuhito Koishida. Cua-skill: Develop skills for computer using agent, 2026. URL https://arxiv.org/abs/2601.21123.
- [25] SkillsMP Team. Skillsmp: Claude skills marketplace. https://skillsmp.com/, 2026. Accessed: 2026-02-06.
- [26] SkillHub Team. Skillhub: A marketplace for claude and agent skills. https://www.skillhub.club/, 2026. Accessed: 2026-02-06.
- [27] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=dHng2O0Jjr.
- [28] Anthropic. Agent skills: An open standard for modular ai agent capabilities. https://agentskills.io/, 2025. Accessed: 2026-02-05.
- [29] Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning, 2021. URL https://arxiv.org/ abs/2010.03768.
- [30] Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2023. URL https://arxiv.org/abs/2207.01206.
- [31] Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader?, 2022. URL https://arxiv.org/abs/2203.07540.
- [32] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210.03629. [33] Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization for llm agents, 2024. URL https://arxiv.org/abs/2403.02502.
- [34] DeepSeek-AI. Deepseek-v3 technical report. https://github.com/deepseek-ai/DeepSeek-V3, 2024. Accessed: 2026-02-07.
- [35] Google DeepMind. Gemini 2.5 technical report and model card (referencing gemini 2.5 pro). URL https: //deepmind.google/models/gemini/pro/. Accessed: 2026-02-07.
- [36] OpenAI. Openai o4-mini model documentation. https://platform.openai.com/docs/models, 2025. Accessed: 2026-02-07.
- [37] Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, volume 267 of Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025. URL https://proceedings.mlr.press/v267/wang25bx.html.
- [38] Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory, 2026. URL https://arxiv.org/abs/2508.06433.
- [39] Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents, 2025. URL https://arxiv.org/abs/2509.24704.
- [40] Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, ChenYu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory, 2025. URL https://arxiv.org/abs/2509.25140.
- [41] Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, and Lin Lee Cheong. Reinforcement learning for self-improving agent with skill library, 2025. URL https://arxiv.org/abs/2512.17102.
- [42] Boyuan Zheng, Michael Y. Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. Skillweaver: Web agents can self-improve by discovering and honing skills, 2025. URL https://arxiv.org/abs/2504.07079.
- [43] Simon Yu, Gang Li, Weiyan Shi, and Peng Qi. Polyskill: Learning generalizable skills through polymorphic abstraction, 2025. URL https://arxiv.org/abs/2510.15863.
- [44] Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, Ge Zhang, Jiaheng Liu, Xingyao Wang, Sirui Hong, Chenglin Wu, Hao Cheng, Chi Wang, and Wangchunshu Zhou. Agent kb: Leveraging cross-domain experience for agentic problem solving, 2025. URL https://arxiv.org/abs/2507.06229.
- [45] Yue Wu, Tianhao Su, Shunbo Hu, and Deng Pan. Skill-based autonomous agents for material creep database construction, 2026. URL https://arxiv.org/abs/2602.03069.
- [46] Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning, 2026. URL https://arxiv.org/abs/2602.08234.
- [47] Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents, 2026. URL https://arxiv.org/abs/2602.02474.
- [48] Vercel. Skills.sh: The open agent skills ecosystem. https://skills.sh/, 2026. Accessed: 2026-02-06.
- [49] OpenClaw. Clawhub: The skill dock for sharp agents. https://clawhub.ai/, 2026. Accessed: 2026-02-22.
- [50] Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, Xuanqing Liu, Haoran Lyu, Ze Ma, Bowei Wang, Runhui Wang, Tianyu Wang, Wengao Ye, Yue Zhang, Hanwen Xing, Yiqi Xue, Steven Dillmann, and Han chung Lee. Skillsbench: Benchmarking how well agent skills work across diverse tasks, 2026. URL https://arxiv.org/abs/2602.12670.
- [51] Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. Agent skills in the wild: An empirical study of security vulnerabilities at scale, 2026. URL https://arxiv.org/abs/2601.10338.
- [52] George Ling, Shanshan Zhong, and Richard Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality, 2026. URL https://arxiv.org/abs/2602.08004.
- [53] Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks. arXiv preprint arXiv:2602.12670, 2026. URL https://arxiv.org/abs/2602.12670.

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)