
电商智能客服智能体——基于 ReAct 范式的 Agent 架构设计与代码实现(一)
多源信息整合:需要同时查询商品数据库、优惠政策文档等多源数据数值计算需求:涉及折扣计算、满减规则等数学运算上下文依赖:多轮对话中需要保持上下文连贯性安全性要求:计算过程需防止代码注入等安全风险因此,本文设计并实现了一套基于 ReAct 范式的电商智能客服 Agent 系统,旨在解决上述挑战。本文设计并实现了一套基于 ReAct 范式的电商智能客服 Agent 系统。该系统通过显式的推理-行动-观察
基于 ReAct 范式的电商智能客服 Agent 架构设计与代码实现
1 引言
1.1 研究背景
随着大型语言模型(Large Language Models, LLMs)的快速发展,基于 LLM 的智能代理(AI Agent)系统在垂直领域的应用日益广泛。在电商客服场景中,传统的基于规则或检索的问答系统面临着知识更新滞后、推理能力不足等挑战。用户咨询往往涉及多步推理,例如"查询商品价格→获取优惠政策→计算最终价格",这要求系统具备复杂的逻辑推理和工具调用能力。
ReAct(Reasoning + Acting)范式由 Yao 等人于 2022 年提出,通过将推理(Reasoning)与行动(Acting)相结合,使语言模型能够在与外部环境交互的过程中进行多步推理。相较于传统的 Chain-of-Thought(CoT)方法,ReAct 不仅展示推理过程,还显式地执行动作并观察结果,形成"思考-行动-观察"的闭环,显著提升了复杂任务的解决能力。
1.2 问题定义
在电商客服领域,典型的用户咨询具有以下特征:
- 多源信息整合:需要同时查询商品数据库、优惠政策文档等多源数据
- 数值计算需求:涉及折扣计算、满减规则等数学运算
- 上下文依赖:多轮对话中需要保持上下文连贯性
- 安全性要求:计算过程需防止代码注入等安全风险
因此,本文设计并实现了一套基于 ReAct 范式的电商智能客服 Agent 系统,旨在解决上述挑战。
2 系统架构与推理流程
2.1 ReAct 推理流程
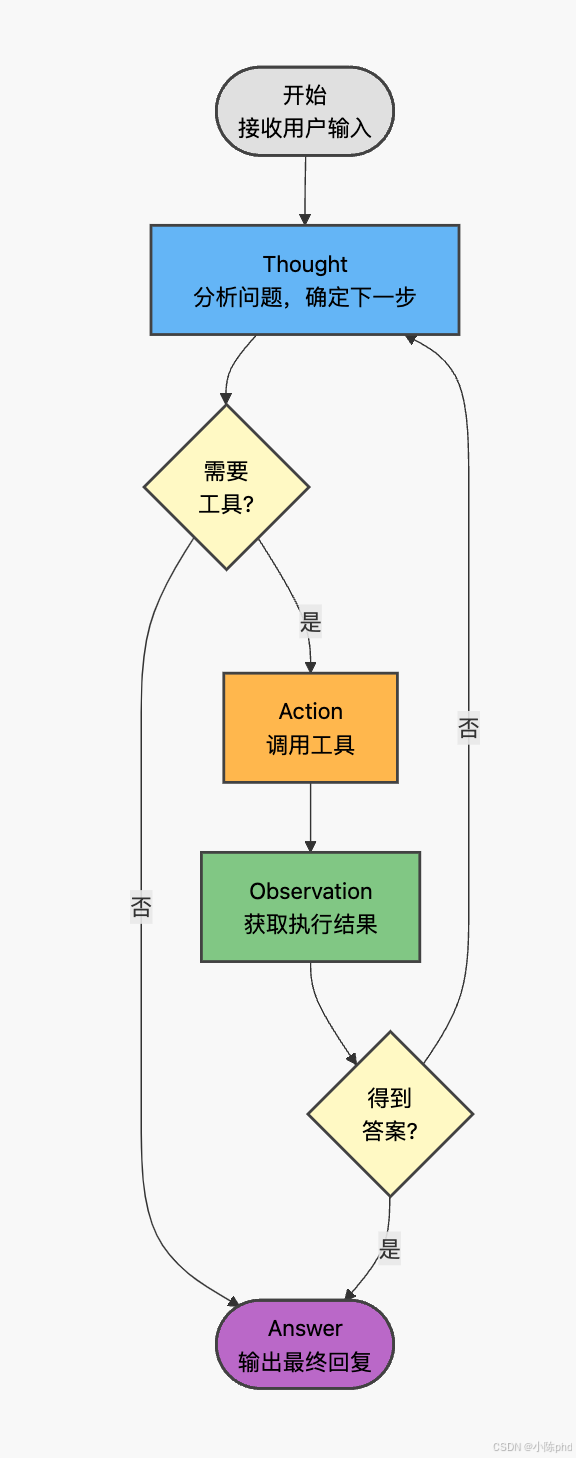
图 1 ReAct 推理流程图
如图 1 所示,ReAct 推理流程遵循以下逻辑:
阶段一:Thought(推理)
Agent 接收用户输入后,首先进入推理阶段。在此阶段,Agent 分析用户问题的意图,评估当前掌握的信息,并规划下一步行动。Thought 是显式的思维过程,使模型能够展示其"思考轨迹"。
阶段二:决策点一(是否需要工具)
基于 Thought 的分析,Agent 判断是否需要调用外部工具获取信息。若问题可直接回答(如常识性问题),则直接进入 Answer 阶段;若需要查询数据库、执行计算等操作,则进入 Action 阶段。
阶段三:Action(行动)
当需要外部信息时,Agent 生成结构化的 Action 指令,指定调用的工具名称及参数。Action 是 Agent 与外部环境交互的接口,通过工具调用获取模型内部知识之外的信息。
阶段四:Observation(观察)
工具执行完成后,返回 Observation 结果。Agent 将 Observation 作为新的上下文信息,用于下一轮推理。
阶段五:决策点二(是否得到答案)
Agent 评估当前信息是否足以回答用户问题。若信息充分,则生成最终 Answer;若信息不足,则返回 Thought 阶段继续推理,形成循环。
阶段六:Answer(回答)
当获得充分信息后,Agent 整合所有推理过程和观察结果,生成最终回复。
该流程的核心优势在于显式推理与环境交互的结合:Thought 使推理过程可解释,Action 扩展了模型的能力边界,Observation 提供了事实性信息,三者协同形成完整的推理闭环。
2.2 系统总体架构
本系统采用分层架构设计,自下而上依次为数据层、工具层、LLM 层、Agent 核心层和主控层,如图 2 所示。
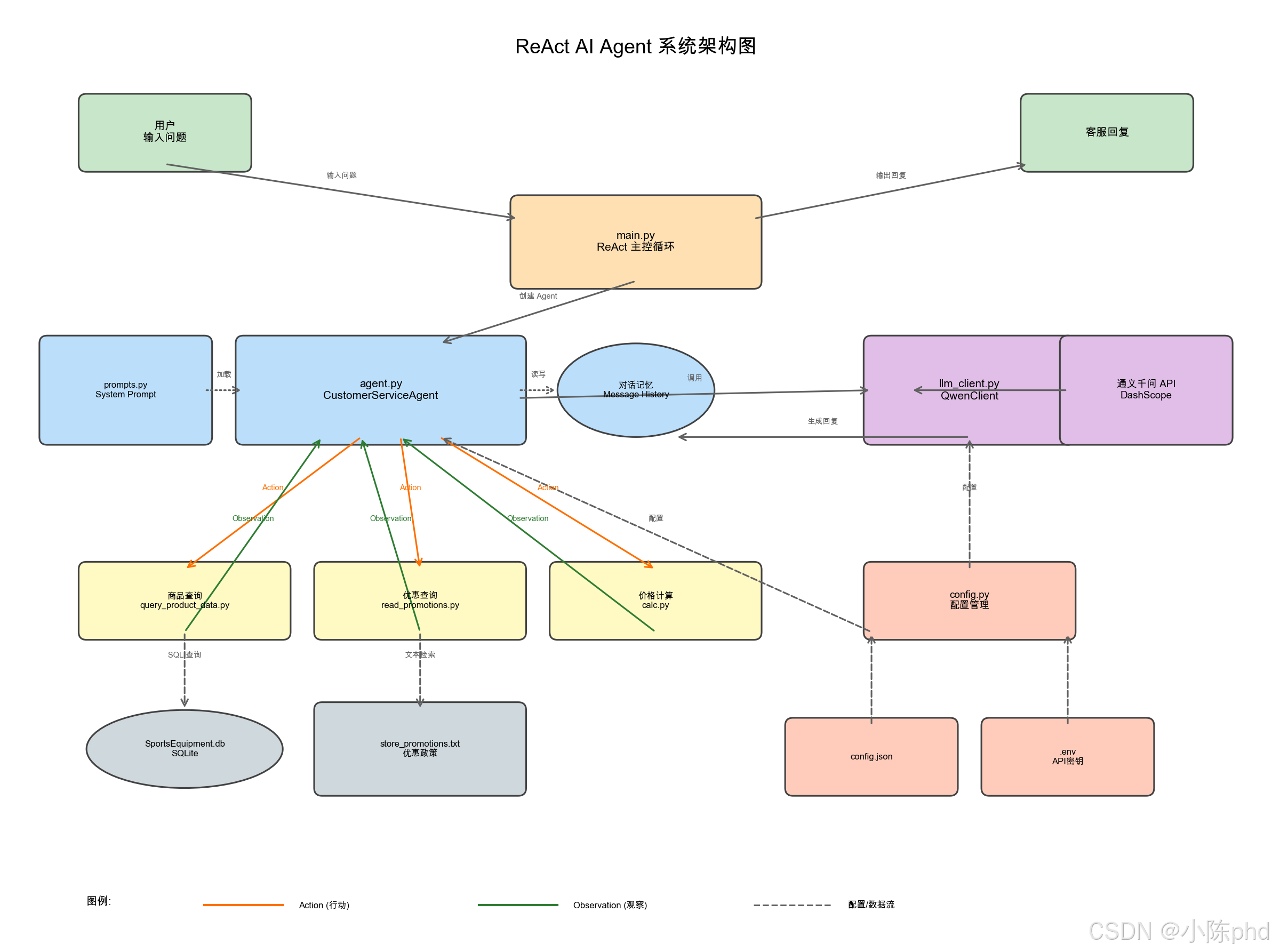
图 2 ReAct AI Agent 系统架构图
各层功能说明如下:
- 用户层:接收用户输入问题,输出客服回复
- 主控层:实现 ReAct 主控循环,解析 Thought、Action、Observation 和 Answer
- Agent 核心层:包含智能代理类、系统提示词和对话记忆管理
- LLM 层:与通义千问 API 进行交互,生成推理结果
- 工具层:提供商品查询、优惠检索和价格计算三个核心工具
- 数据层:包含商品数据库和促销信息文件
- 配置层:管理 API 密钥和模型参数等配置信息
各层之间通过 Action(橙色箭头)和 Observation(绿色箭头)进行交互,形成完整的推理闭环。
2.2 核心技术创新点
2.2.1 ReAct 推理引擎的实现
系统核心是一个基于正则表达式解析的 ReAct 推理引擎,实现了 Thought-Action-Observation-Answer 四元组的提取与处理:
def parse_thought(response: str) -> str | None:
"""从 Agent 响应中解析 Thought"""
pattern = re.compile(r'^Thought:\s*(.+)$', re.MULTILINE)
matches = pattern.findall(response)
return matches[-1].strip() if matches else None
def parse_action(response: str) -> tuple[str, str] | None:
"""解析 Action,返回 (工具名, 参数)"""
pattern = re.compile(r'^Action:\s*(\w+):\s*(.*)$', re.MULTILINE)
matches = pattern.findall(response)
return matches[-1] if matches else None
该设计的关键在于多轮迭代机制:当检测到 Action 时,系统执行对应工具并将 Observation 作为新的输入反馈给 Agent,形成推理闭环,直至获得最终 Answer。
2.2.2 安全计算模块
针对价格计算场景的安全需求,系统实现了基于抽象语法树(AST)的安全计算模块:
ALLOWED_OPERATORS = {
ast.Add: operator.add,
ast.Sub: operator.sub,
ast.Mult: operator.mul,
ast.Div: operator.truediv,
ast.Pow: operator.pow,
ast.USub: operator.neg,
}
def _eval_node(node):
"""递归计算 AST 节点,仅允许白名单内的操作符"""
if isinstance(node, ast.Constant):
return node.value
elif isinstance(node, ast.BinOp):
op_type = type(node.op)
if op_type in ALLOWED_OPERATORS:
return ALLOWED_OPERATORS[op_type](
_eval_node(node.left),
_eval_node(node.right)
)
raise ValueError(f"不支持的操作符: {op_type}")
该方法通过白名单机制严格限制可执行的操作类型,有效防止了代码注入攻击,同时支持基本的数学运算需求。
2.2.3 工具注册与动态调用机制
系统采用字典映射实现工具的动态注册与调用:
TOOLS: Dict[str, Callable] = {
"query_by_product_name": query_by_product_name,
"read_store_promotions": read_store_promotions,
"calculate": calculate,
}
def execute_tool(tool_name: str, tool_args: str) -> str:
if tool_name not in TOOLS:
return f"错误: 工具 '{tool_name}' 不存在"
return str(TOOLS[tool_name](tool_args))
这种设计实现了工具与推理逻辑的解耦,便于后续扩展新的工具功能。
3 关键模块实现
3.1 提示词工程
系统提示词采用结构化的 ReAct 格式,明确约束模型的输出模式:
输出格式要求:
- Thought: 描述你的分析过程
- Action: 调用可用工具,格式为 "工具名: 参数"
- 获得 Observation 后继续推理
- 最终输出: Answer: [你的回答]
提示词设计包含少样本示例(Few-shot Examples),通过具体对话示例引导模型理解 ReAct 的执行流程。
3.2 对话记忆管理
Agent 核心维护一个消息列表 messages,采用 OpenAI 兼容格式存储对话历史:
class CustomerServiceAgent:
def __init__(self, client: QwenClient, config: Config):
self.messages: List[Dict[str, str]] = []
self._init_system_prompt()
def __call__(self, message: str) -> str:
self.messages.append({"role": "user", "content": message})
response = self._execute()
self.messages.append({"role": "assistant", "content": response})
return response
该设计支持多轮对话上下文保持,使 Agent 能够处理复杂的连续咨询场景。
3.3 配置管理
系统采用分层配置策略,支持环境变量与 JSON 配置文件相结合:
@dataclass
class QwenConfig:
model_name: str = "qwen-max"
temperature: float = 1.0
max_iterations: int = 20
class Config:
def get_qwen_api_key(self) -> str:
return os.environ.get("QWEN_API_KEY", "")
敏感信息(如 API 密钥)通过环境变量管理,模型参数通过配置文件调整,实现了安全性与灵活性的平衡。
4 系统运行流程
系统的典型运行流程如下:
- 初始化阶段:加载配置、初始化 LLM 客户端、创建 Agent 实例
- 输入处理:接收用户问题,加入对话历史
- ReAct 循环:
- 调用 LLM 生成响应
- 解析 Thought 并输出(用于展示推理过程)
- 检测 Action,若存在则执行对应工具
- 获取 Observation,作为新输入继续循环
- 检测到 Answer 时终止循环并返回结果
- 输出生成:将最终答案呈现给用户
5 总结与展望
本文设计并实现了一套基于 ReAct 范式的电商智能客服 Agent 系统。该系统通过显式的推理-行动-观察循环,有效解决了电商客服场景中的多源信息整合、数值计算安全性和上下文记忆等关键问题。
未来的优化方向包括:
- 检索增强生成(RAG):将优惠政策检索升级为基于向量数据库的语义检索
- 工具学习优化:引入工具描述的自适应优化机制,提升工具选择的准确性
- 多 Agent 协作:扩展为多 Agent 系统,实现更复杂的任务分解与协作

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)