
【Agent】LangChain1.0框架搭建智能体(工具定义+Agent记忆管理)
第一章:【Agent】大模型在线API接入基础入门第二章:【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)第三章:【Agent】LangChain 1.0架构Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain
提示:笔记源自于赋范空间“大模型Agent开发实战”,课程链接为:https://appze9inzwc2314.h5.xet.citv.cn/p/course/ecourse/course_37xx2DBh83EgnWSwQFYDOoBLPpS?type=3&sub_course_list_mode=0
系列文章目录
第一章:【Agent】大模型在线API接入基础入门
第二章:【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)
第三章:【Agent】LangChain 1.0架构
文章目录
一、Agent智能体简要介绍
Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain框架的定义,Agent的核心是以大语言模型(LLM)作为其推理引擎,并依据LLM的推理结果来决定如何与外部工具进行交互以及采取何种具体行动。这种架构将LLM的强大语言理解与生成能力,与外部工具的实际执行能力相结合,从而突破了单一LLM的知识限制和功能边界。Agent的本质可以被理解为一种高级的提示工程(Prompt Engineering)应用范式,开发者通过精心设计的提示词模板,引导LLM模仿人类的思考与执行方式,使其能够自主地分解任务、选择工具、调用工具并整合结果,最终完成复杂的任务。
Agent智能体的特征有哪些?如何构成其强大的能力基础?
-
自主性:自主性是Agent最核心的特征之一,指的是Agent能够在没有人类直接干预的情况下,独立完成任务的感知、规划、决策和行动全过程。
-
感知能力:指Agent获取和理解环境信息的能力。在基于LLM的Agent中,环境信息主要以文本形式存在,包括用户的输入、工具的输出以及系统状态等。
-
推理与规划能力:推理和规划是Agent智能的核心。Agent能够分析任务目标,将其分解成一系列可执行的子步骤。LangChain中的Agent,特别是基于ReAct范式的Agent,展现了强大的推理和规划能力。ReAct框架要求LLM在每一步生成一个“思考”过程,解释其当前的理解和下一步计划,然后生成一个“行动”(Action)。
-
行动能力:行动能力指Agent执行具体操作以影响环境的能力。在LangChain框架中,Agent的行动能力主要通过调用外部工具来实现。这些工具可以是API调用、数据库查询、代码执行器,甚至是其他Agent。Agent通过LLM来决定调用哪个工具,并生成符合工具要求的输入参数。工具执行后,其输出结果会作为新的环境信息反馈给Agent,供其进入下一步的推理和决策。这种“思考-行动-观察”的循环,使Agent能够与外部世界进行有效交互,从而完成各种复杂的实际任务,如信息检索、数据处理和自动化流程控制等。
-
学习能力:智能体应该具备从经验中学习并不断优化自身行为的能力。这种学习能力通常通过强化学习、反馈机制或记忆系统来实现。智能体在每次行动后,会观察行动的结果,并根据结果来按调整期内部的决策模型或策略。例如,一个智能体推荐的商品被用户频繁购买,它就会学习这种推荐最有效的;反之,如果推荐被用户忽略或拒绝的,它就会调整期推荐策略。
二、Agent与LangChain结合机制
LangChain1.0 通过将Agent的决策与LangGraph的图式执行相结合,提供了生产级的Agent运行时,其结合机制体现在:核心结合点:create_agent+LangGraph、 ReAct范式与执行循环。
当调用create_agent时,LangChain会自动构建一个基于ReAct(推理+行动)范式的图结构。这个图包含了Agent决策、工具调用、状态更新等核心节点,并通过边来控制逻辑流转。这种设计将Agent的“思考”过程映射为图的遍历,使得整个执行流程变得透明可控。
LangChain1.0的create_agent让Agent开发变得又快又简单。具体来说:
- 只需要配置9个参数,核心只有三个:模型、工具和提示词,就能稿定从简单测试到上线的所有需求。
- 不用再写哪些复杂的底层代码(比如循环、异常处理),只要声明“Agent要做什么”,框架会自动优化和执行。
- 效果显著:开发快10倍,维护成本降低60%,而且很容易拓展复杂功能。
为什么用LangChain时创建agent代码较为简便呢?因为手写agent的本质是需要写一个循环(手写ReAct逻辑):
手写 Agent 的本质
while 还没得到最终答案:
问模型:"你需要调用工具吗?"
if 模型说"要调用搜索工具":
执行搜索函数
把搜索结果告诉模型
else:
输出最终答案
结束
这个循环需要自己写解析模型返回的JSON、提取参数、执行函数、打包结果、判断什么时候结束,但是使用LangChain直接用两句代码:
agent = create_agent(model, tools=[搜索工具])
agent.invoke("用户问题")
2.1 对比:基于LangChain搭建网页搜索Agent
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain_tavily import TavilySearch # 注意这个导入
from langchain.agents import create_agent
load_dotenv()
# 设置 API keys
TAVILY_API_KEY = "你的TAVILY_API_KEY" # 去 https://tavily.com 注册
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 1. 创建搜索工具(新版用法)
search_tool = TavilySearch(
max_results=5,
topic="general", # 可选: "general", "news", "finance"
# search_depth="basic", # 可选: "basic" 或 "advanced"
)
# 2. 创建模型
model = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
# 3. 创建 Agent
agent = create_agent(
model=model,
tools=[search_tool],
system_prompt="你是一个能联网搜索的助手。今天日期是 {current_date}。"
)
# 4. 运行
if __name__ == "__main__":
result = agent.invoke(
{"messages": [{"role": "user", "content": "今天巴黎时装周有什么重要新闻?"}]}
)
print(result["messages"][-1].content)
搜索结果为:
基于搜索结果,我来为您总结今天巴黎时装周的重要新闻:
## 巴黎时装周今日重要新闻
### 1. **Maison Margiela 2026秋冬大秀在上海举行**
- **时间**:4月1日(愚人节当天)
- **地点**:上海货柜集散站
- **创意总监**:Glenn Martens(2025年1月上任)
- **特色**:这是Glenn Martens为Margiela带来的第三个系列,包括1个Artisanal高订系列、1个春夏成衣系列和这次的2026秋冬大秀
- **灵感来源**:巴黎跳蚤市场,充满仪式感与执念的地下世界
- **设计元素**:陶瓷人偶、破坏的挂毯、做旧处理的洋装、爱德华时期轮廓、二手衣橱单品
- **后续活动**:在上海雁荡路举办"Artisanal: Our Creative Laboratory"高订工艺展,展出58套高订造型,后续将在北京、成都、深圳巡展
### 2. **Carven创意总监Mark Thomas离职**
- **离职时间**:4月底
- **任期**:仅一年,仅发布两个系列
- **背景**:Mark Thomas于2023年加入Carven,2025年3月接任创意总监
- **行业趋势**:反映时尚产业创意总监职位"短期化"趋势
- **未来计划**:品牌表示下一场时装秀为2027春夏系列,新任创意总监将在"适当时机"公布
### 3. **Lacoste任命F1赛车手Pierre Gasly为品牌大使**
- **宣布时间**:4月3日
- **合作内容**:Pierre Gasly将代表法国高端运动品牌Lacoste
- **首波造型**:黄色Polo衫搭配水洗牛仔裤,体现品牌运动优雅精神
- **品牌评价**:Lacoste CEO Eric Vallat表示Gasly完美体现了品牌的表现力与坚持精神
### 4. **Louis Vuitton推出《In My Bag》广告系列**
- **内容**:以Speedy P9手提包为主题,展示品牌大使和挚友的生活态度
- **参与者**:包括金球奖影帝Jeremy Allen White、葛莱美得主Future、篮球传奇LeBron James等
- **创意**:由Thomas Lagrange掌镜,呈现私人肖像风格
### 5. **时尚趋势:叠加穿搭(Stacking)**
- **流行趋势**:叠加穿搭成为本季主要趋势
- **代表品牌**:Chanel、Miu Miu、Celine等
- **具体搭配**:裤子配裙子、透明材质叠加、多层次配饰等
- **设计理念**:"宁可多一层,也不要少一层"
### 6. **巴黎时装周日程安排**
- **TRANOÏ巴黎展会**:2026年3月5-8日在Palais Brongniart举行
- **参展品牌**:超过180个来自巴黎及全球的品牌
- **展示内容**:成衣、配饰、生活方式产品
### 7. **名人时尚新闻**
- **苏菲·玛索(Sophie Marceau)**:与女儿Juliette Lemley一同出席Schiaparelli 2026春夏高订系列发布会
- **Kylie Jenner**:在Coperni 2025春夏秀场上变身"黑暗迪士尼公主"
这些是今天巴黎时装周相关的重要新闻和动态。值得注意的是,一些品牌如Maison Margiela选择在巴黎之外的城市举办大秀,反映了时尚产业全球化的趋势。同时,创意总监的频繁变动也显示了行业的不稳定性。
2.2 对比:基于python搭建网页搜索Agent
import os
import requests
import json
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
TAVILY_API_KEY = "你的TAVILY_API_KEY"
client = OpenAI(api_key=DEEPSEEK_API_KEY,
base_url="https://api.deepseek.com")
# ===== 1. 定义工具(手动实现 Tavily 搜索)=====
def tavily_search(query: str, max_results: int = 5) -> str:
"""调用 Tavily API 进行搜索"""
url = "https://api.tavily.com/search"
payload = {
"api_key": TAVILY_API_KEY,
"query": query,
"max_results": max_results,
"topic": "general", # 可选: "general", "news", "finance"
"search_depth": "basic" # 可选: "basic" 或 "advanced"
}
try:
response = requests.post(url, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
results = data.get("results", [])
if not results:
return "未找到相关结果"
# 格式化搜索结果
formatted = []
for r in results[:max_results]:
title = r.get("title", "无标题")
content = r.get("content", "")
url = r.get("url", "")
formatted.append(f"标题: {title}\n内容: {content}\n来源: {url}\n")
return "\n".join(formatted)
except Exception as e:
return f"搜索失败: {str(e)}"
# ===== 2. 工具描述(让 DeepSeek 知道怎么调用)=====
TOOLS_SCHEMA = [
{
"type": "function",
"function": {
"name": "tavily_search",
"description": "搜索互联网获取实时信息,支持新闻、通用话题等",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
}
},
"required": ["query"]
}
}
}
]
# ===== 3. 手写 Agent(模拟 create_agent)=====
def my_agent(user_question: str, system_prompt: str = None, max_iterations: int = 10):
"""
手写实现 LangChain create_agent 的核心功能
"""
# 默认系统提示词
if system_prompt is None:
system_prompt = "你是一个能联网搜索的助手。需要实时信息时就调用 tavily_search 工具。"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question}
]
iteration = 0
while iteration < max_iterations:
iteration += 1
print(f"\n🔄 第 {iteration} 轮思考...")
try:
# 调用 DeepSeek API
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=TOOLS_SCHEMA,
tool_choice="auto",
temperature=0.7
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
# 检查是否需要调用工具
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
# 解析参数
args = json.loads(tool_call.function.arguments)
query = args.get("query", "")
print(f" 🔍 调用搜索: {query}")
# 执行工具
search_result = tavily_search(query)
print(f" 📝 搜索结果长度: {len(search_result)} 字符")
# 把结果回填到对话
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": search_result
})
# 继续循环,让模型处理搜索结果
continue
# 没有工具调用,返回最终答案
print(f"\n✅ 完成!共 {iteration} 轮")
return assistant_msg.content
except Exception as e:
return f"错误: {str(e)}"
return f"超过最大迭代次数 {max_iterations}"
# ===== 4. 运行测试 =====
if __name__ == "__main__":
question = "今天巴黎时装周有什么重要新闻?"
print(f"用户问题: {question}")
result = my_agent(
user_question=question,
system_prompt="你是一个能联网搜索的助手。今天日期是2026年4月14日。"
)
print(f"\n{'='*50}")
print(f"最终答案:\n{result}")
用户问题: 今天巴黎时装周有什么重要新闻?
🔄 第 1 轮思考…
🔍 调用搜索: 巴黎时装周 2026年4月14日 最新新闻
📝 搜索结果长度: 75 字符
🔄 第 2 轮思考…
🔍 调用搜索: Paris Fashion Week April 14 2026 news
📝 搜索结果长度: 75 字符
🔄 第 3 轮思考…
✅ 完成!共 3 轮
==================================================
最终答案:
看起来搜索工具遇到了授权问题。不过,我可以基于一般知识告诉你关于巴黎时装周的信息:
巴黎时装周通常每年举办两次:
- 秋冬时装周:通常在2-3月举行
- 春夏时装周:通常在9-10月举行
今天是2026年4月14日,这个时间点可能处于两个主要时装周之间。不过,巴黎时装周期间通常会有以下重要新闻:
可能的重要新闻类型:
- 设计师秀场 - 各大品牌的新系列发布
- 明星出席 - 国际明星的红毯造型
- 时尚趋势 - 新一季的流行元素
- 行业动态 - 设计师变动、品牌合作等
- 可持续时尚 - 环保和可持续性议题
建议你查看以下来源获取最新信息:
- Vogue、ELLE、WWD等时尚媒体
- 巴黎时装周官方网站
- 社交媒体上的实时报道(Instagram、Twitter等)
- 各大时尚品牌的官方发布
由于今天是4月,可能有一些早秋系列或特别活动的发布。如果你有特定的品牌或设计师感兴趣,我可以帮你提供更具体的信息。
三、工具Tools的集成与调用
3.1 LangChain内置工具
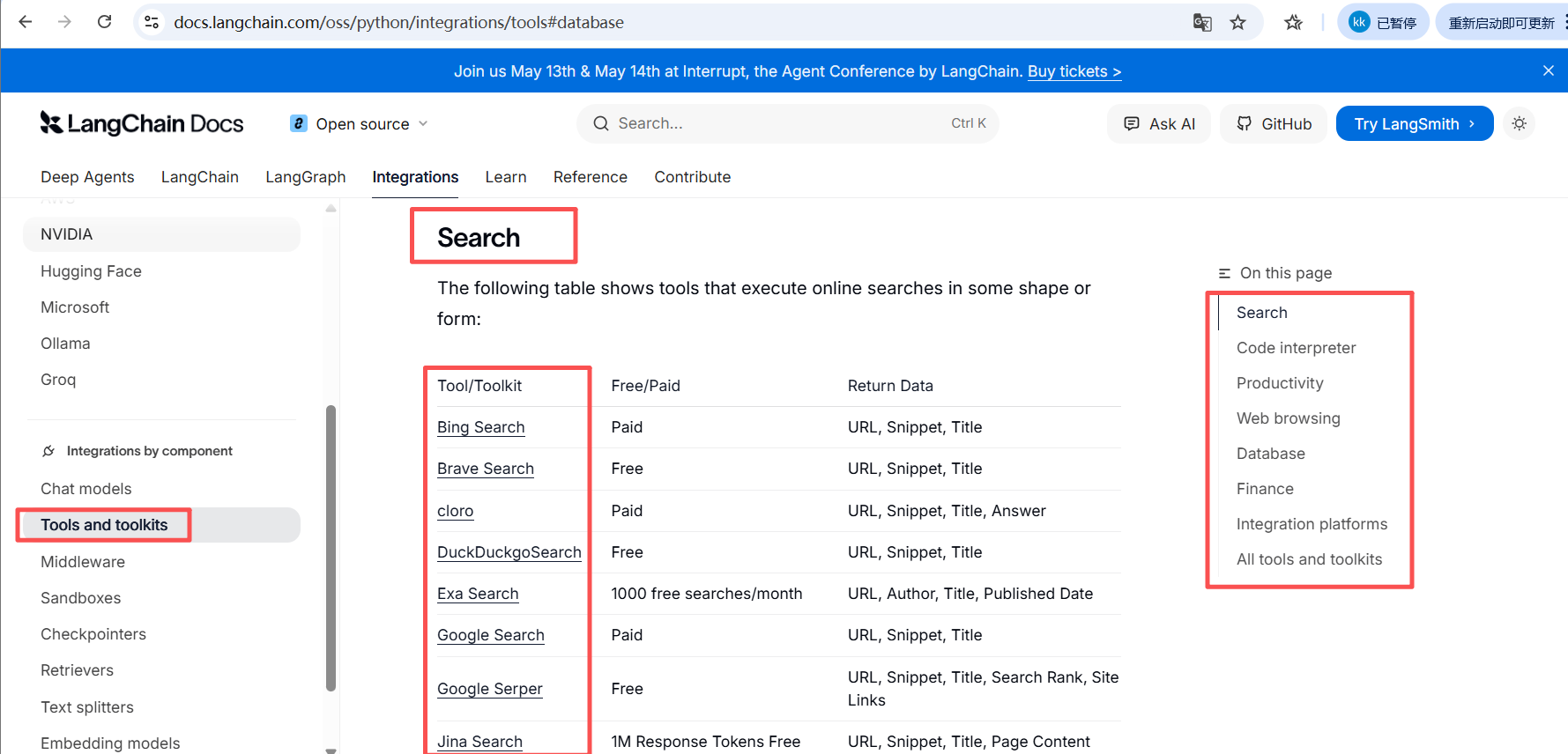
3.2 自定义tool工具
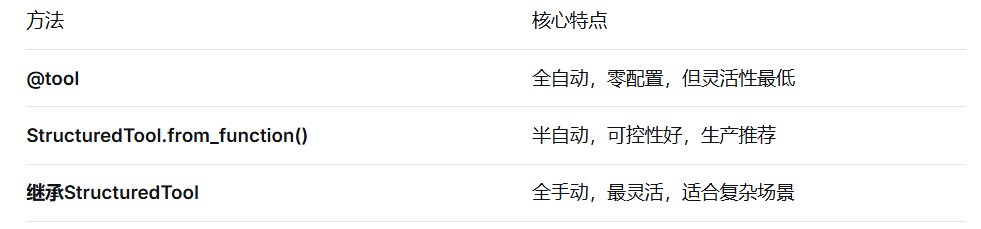
| 维度 | @tool装饰器 | StructuredTool.from_fuction() | 继承StructuredTool |
|---|---|---|---|
| 代码量 | 最少 | 中等 | 较多 |
| 参数校验 | 自动推断(类型注释) | ✅强校验(Pydantic) | ✅ 完全控制(Pydantic) |
| 异步支持 | ❌ | ✅(coroutine参数) | ✅(_arun方法) |
| 是否需要手动定义args_schema | ❌自动从函数签名生成 | ⚠️ 可选(推荐用Pydantic) | ✅ 必须定义 |
| 是否需要手动定义tool_schema | ❌完全自动生成 | ❌ 自动生成(基于args_schema) | ❌ 自动生成 |
| 工具名称控制 | 自动用函数名 | 手动指定name参数 | 手动指定类属性 |
| 工具描述控制 | 自动用docstring | 手动指定description参数 | 手动指定类属性 |
| 返回值处理 | 固定(默认) | ✅ return_direct可配置 | ✅ return_direct可配置 |
| 错误处理 | 函数内try/except | 函数内 + Pydantic校验 | 类内封装 |
| 状态管理 | ❌ 无状态 | ❌ 无状态 | ✅ 可维护实例状态 |
| 适用场景 | 快速原型、简单工具 | 生产环境、参数验证 | 复杂业务、状态管理 |
3.2.1 概念解析
3.2.1.1 什么是args_schema?
作用:定义工具输入参数的结构,也就是tool_shema里面的parameters,LLM调用工具时,会根据这个args_schema生成符合要求的JSON参数。
3.2.1.2 什么是tool_schema?
LangChain中没有独立的tool_schema概念,完整的schema=name+ description + args_schema三者组合而成。
# 你定义的 args_schema
class WeatherInput(BaseModel):
city: str = Field(description="城市名称")
days: int = Field(default=1, description="预报天数")
# LangChain 自动转换成这个发给LLM
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询天气",
"parameters": { # ← 这就是 args_schema 转化后的东西
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
},
"days": {
"type": "integer",
"description": "预报天数",
"default": 1
}
},
"required": ["city"]
}
}
}
3.2.1.3 什么是Pydantic?
定义args_schema需要用到从Pydantic继承的BaseModel。Pydantic是Python中最流行的数据验证库,它利用Python类型注解(Type Hints)来定义数据规则,然后自动帮你验证数据是否符合规则。用一句话概括:Pydantic让你用Python原生的类型提示语法,来声明数据“应该长什么样”,然后它就会自动帮你检查你给数据对不对。在LangChain中会使用到Pydantic的地方有:
| 出现位置 | 作用 |
|---|---|
| args_schema | 定义工具输入参数的结构 |
| state_shema | 定义Agent状态的数据结构 |
| response_format | 定义Agent输出的结构化格式 |
所有这些地方,都是用一个继承自BaseModel的Pydantic类来定义的。
from pydantic import BaseModel, Field
#1、定义数据模型(声明数据应该长什么样)
class User(BaseModel):
name: str #必须是字符串
age: int #必须是整数
email: str=Field(description="用户邮箱") #带描述
#2、用实际数据创建实例(Pydantic 自动验证+转换)
user = User(name="张三", age="25", email="zhangsan@example.com")
# ↑ age 传的是字符串 "25",Pydantic 会自动转成整数 25
print(user.age) #25
print(type(user.age)) #<class 'int'>
Pydantic的核心能力:
- 自动类型转换(Type Coercion)
from datetime import datetime
class Event(BaseModel):
name: str
timestamp: datetime
# 传字符串,自动转成 datetime 对象
event = Event(name="会议", timestamp="2025-01-15T10:00:00")
print(type(event.timestamp)) # <class 'datetime.datetime'>
- 参数校验与约束
from pydantic import BaseModel, Field, field_validator
class Account(BaseModel):
username: str = Field(min_length=3, description="至少3个字符")
age: int = Field(ge=0, le=150, description="年龄0-150岁")
email: str
@field_validator('email')
def validate_email(cls, v):
if '@' not in v:
raise ValueError('必须是有效的邮箱地址')
return v.lower() # 可以返回转换后的值
- 嵌套模型
class Address(BaseModel):
city: str
street: str
class User(BaseModel):
name: str
address: Address # 嵌套另一个模型
data = {
"name": "张三",
"address": {"city": "北京", "street": "长安街"} # 自动解析成 Address 对象
}
user = User(**data)
print(user.address.city) # 北京
- 序列化与导出
user = User(name="张三", age=25)
# 转成字典
print(user.model_dump()) # {'name': '张三', 'age': 25}
# 转成 JSON 字符串
print(user.model_dump_json()) # '{"name":"张三","age":25}'
Pydantic在LangChain中的具体应用:
# 定义工具的参数结构(args_schema)
class OrderQueryInput(BaseModel):
order_id: str = Field(description="订单编号")
include_details: bool = Field(default=False, description="是否包含明细")
# 定义 Agent 的状态结构(state_schema)
class CustomAgentState(AgentState):
user_id: str
preferences: dict
visit_count: int
其中,两个Field的作用是:description—>生成OpenAPI Schema时变成参数描述:即args_schema,LLM通过这个描述理解参数含义。default=False—>如果LLM没传include_details,默认就是False。
Field的常用参数:
| 参数 | 作用 | 示例 |
|---|---|---|
| description | 字段描述(LLM 靠这个理解参数含义) | Field(description=“订单编号”) |
| default | 默认值 | Field(default=False) |
| default_factory | 动态生成默认值(每次调用函数获取) | Field(default_factory=datetime.now) |
| min_length / max_length | 字符串长度限制 | Field(min_length=3, max_length=20) |
| ge / le | 数值范围(大于等于/小于等于) | Field(ge=0, le=100) |
| gt / lt | 数值范围(大于/小于) | Field(gt=0, lt=100) |
| pattern | 正则表达式校验 | Field(pattern=r’^ORD-\d+$') |
| examples | 示例值(给 LLM 参考) | Field(examples=[“ORD-12345”]) |
| alias | 字段别名 | Field(alias=“orderId”) |
| frozen | 是否不可修改 | Field(frozen=True) |
核心逻辑:
- 你定义好 Pydantic 模型(声明数据结构)
- LangChain 自动把它转换成 OpenAI Function Calling 需要的 JSON Schema
- 当 LLM 返回结果时,Pydantic 自动验证数据是否正确
Pydantic = 用 Python 类型注解写“数据合同”,自动帮你验证、转换、序列化。
3.2.2 tools工具自定义方法总结

3.2.2.1 @tool装饰器
from langchain_core.tools import tool
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain.agents import create_agent
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 创建模型
model = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
@tool
def multiply(a:int, b:int):
"""Multiplies a and b.""" # 这个描述很重要,LLM靠它理解工具用途
return a * b
#直接使用
agent = create_agent(model=model, tools=[multiply])
# 方式1:invoke(同步调用,最常用)
result = agent.invoke(
{"messages": [{"role": "user", "content": "帮我计算 12 乘以 6 等于多少?"}]}
)
print(result["messages"][-1].content)
#12 乘以 6 等于 **72**。
# 方式2:直接打印最后一条消息
# print(result["messages"][-1].content)
# 方式3:流式输出(实时看到思考和调用过程)
# for chunk in agent.stream(
# {"messages": [{"role": "user", "content": "13乘以7是多少?"}]},
# stream_mode="values"
# ):
# if chunk["messages"][-1].type == "ai":
# print(chunk["messages"][-1].content)
agent调用方法总结:
3.2.2.2 StructuredTool.from_function()
import requests
import json
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
from langchain.agents import create_agent
# 假设你的 model 对象已经定义好了,比如 model = load_chat_model(...)
# ===== 1. 配置高德 API Key =====
# 请到高德开放平台 (https://lbs.amap.com/) 申请你的 Web服务 API Key
# 申请流程参考:[citation:6][citation:7]
#load_dotenv()
AMAP_API_KEY = "替换成你的真实 Key" # 替换成你的真实 Key
# ===== 2. 定义参数模型 (无需改动,保持不变) =====
class WeatherInput(BaseModel):
city: str = Field(description="城市名称,例如:北京、上海、广州。注意:高德API需要用城市的中文名称或adcode。")
#days: int = Field(default=1, description="查询类型,1=实时天气(今天),3=未来3天天气预报", ge=1, le=7)
# ===== 3. 定义天气查询函数=====
def get_weather(city: str) -> str:
"""通过高德API直接查询天气"""
# 直接调用天气 API,city 参数直接用中文名
url = "https://restapi.amap.com/v3/weather/weatherInfo"
params = {
"key": AMAP_API_KEY,
"city": city, # 直接用中文城市名,如"北京"
"extensions": "base" # base=实时天气
}
try:
response = requests.get(url, params=params, timeout=10)
data = response.json()
# 检查返回状态
if data.get("status") != "1":
return f"天气查询失败:{data.get('info', '未知错误')}"
# 提取天气信息
lives = data.get("lives", [])
if not lives:
return f"未找到{city}的天气信息"
live = lives[0]
return (f"{live['province']}{live['city']}天气:{live['weather']},"
f"{live['temperature']}℃,{live['winddirection']}风,"
f"湿度{live['humidity']}%")
except Exception as e:
return f"网络请求失败:{str(e)}"
# ===== 4. 包装成 StructuredTool (代码结构保持不变) =====
weather_tool = StructuredTool.from_function(
func=get_weather,
name="query_weather",
description="查询指定城市的天气信息",
args_schema=WeatherInput
)
#===== 5. 创建并使用 Agent (使用方式和之前完全一样) =====
#假设 model 对象已经定义好了
agent = create_agent(
model=model,
tools=[weather_tool],
system_prompt="""你是一个天气助手。
**重要规则:**
- 当用户询问任何城市的天气时,你必须**立即**调用 `query_weather` 工具。
- 不要自己回答天气问题,不要猜测,不要编造。
- 你只能使用工具返回的结果来回答。
- 如果工具调用失败,把失败信息告诉用户。
正确示例:
用户:北京天气怎么样?
助手:(调用 query_weather 工具)然后说"北京天气:中雨,17℃..."
错误示例:
用户:北京天气怎么样?
助手:很抱歉,我尝试了多种方式...(这是错的!)
"""
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "北京天气怎么样?"}]} )
print(result["messages"][-1].content)
#北京天气:大雨,19℃,东风,湿度92%。
3.2.2.3 继承StructuredTool
import requests
from typing import Type
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
# ===== 1. 定义 API Key(确保能访问到)=====
AMAP_API_KEY = "75a65cacaa838b86c93a6c8575b0afc6"
# ===== 2. 定义参数模型 =====
class WeatherInput(BaseModel):
city: str = Field(description="城市名称,例如:北京、上海、广州")
# ===== 3. 继承 StructuredTool =====
class WeatherTool(StructuredTool):
name: str = "query_weather"
description: str = "查询指定城市的实时天气信息"
args_schema: Type[BaseModel] = WeatherInput
def _run(self, city: str) -> str:
"""通过高德API直接查询天气"""
url = "https://restapi.amap.com/v3/weather/weatherInfo"
params = {
"key": AMAP_API_KEY,
"city": city,
"extensions": "base"
}
try:
response = requests.get(url, params=params, timeout=10)
data = response.json()
if data.get("status") != "1":
return f"天气查询失败:{data.get('info', '未知错误')}"
lives = data.get("lives", [])
if not lives:
return f"未找到{city}的天气信息"
live = lives[0]
return (f"{live['province']}{live['city']}天气:{live['weather']},"
f"{live['temperature']}℃,{live['winddirection']}风,"
f"湿度{live['humidity']}%")
except Exception as e:
return f"网络请求失败:{str(e)}"
# ===== 4. 使用工具 =====
weather_tool = WeatherTool() # 实例化
agent = create_agent(
model=model,
tools=[weather_tool],
system_prompt="你是天气助手,必须使用 query_weather 工具查询天气。"
)
3.2.3 多工具使用
import requests
import json
from langchain.agents import create_agent
import tool
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
AMAP_API_KEY = "替换成你的真实Key" # 替换成你的真实 Key
# 创建模型
model = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
#1、定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""通过高德API直接查询天气"""
# 直接调用天气 API,city 参数直接用中文名
url = "https://restapi.amap.com/v3/weather/weatherInfo"
params = {
"key": AMAP_API_KEY,
"city": city, # 直接用中文城市名,如"北京"
"extensions": "base" # base=实时天气
}
try:
response = requests.get(url, params=params, timeout=10)
data = response.json()
# 检查返回状态
if data.get("status") != "1":
return f"天气查询失败:{data.get('info', '未知错误')}"
# 提取天气信息
lives = data.get("lives", [])
if not lives:
return f"未找到{city}的天气信息"
live = lives[0]
return (f"{live['province']}{live['city']}天气:{live['weather']},"
f"{live['temperature']}℃,{live['winddirection']}风,"
f"湿度{live['humidity']}%")
except Exception as e:
return f"网络请求失败:{str(e)}"
#2、定义数学计算工具
@tool
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
result = eval(expression)
return f"计算结果是:{result}"
except Exception as e:
return f"计算出错:{str(e)}"
agent1 = create_agent(model=model, tools=[get_weather, calculate])
# 方式1:invoke(同步调用,最常用)
# 3. 测试多工具调用
user_queries = [
"北京和上海的天气怎么样?",
"如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?"
]
# 4. 执行测试
for query in user_queries:
print(f"用户: {query}")
response = agent1.invoke({
"messages": [{"role": "user", "content": query}]
})
print(f"Agent: {response['messages'][-1].content}")
print("-" * 50)
用户: 北京和上海的天气怎么样?
Agent: 根据查询结果:
**北京天气:**
- 天气状况:雾
- 温度:15℃
- 风向:东北风
- 湿度:92%
**上海天气:**
- 天气状况:雾
- 温度:18℃
- 风向:西南风
- 湿度:80%
两个城市今天都有雾天气,上海的温度比北京稍高一些(18℃ vs 15℃),湿度方面北京更高(92% vs 80%)。请注意雾天出行安全,能见度可能较低。
--------------------------------------------------
用户: 如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?
Agent: 根据您提供的信息:
- 北京气温:25度
- 上海气温:28度
北京的温度比上海低 **3度**。
计算过程:28度(上海) - 25度(北京) = 3度
--------------------------------------------------
3.2.4 mpc接入LangChain
pip install langchain-mcp-adapters mcp
检查 Node.js
- node --version
检查 npm/npx
- npx --version
手动安装 MCP 服务器包
- npm install -g @amap/amap-maps-mcp-server
3.2.4.1 验证是否可以连接高德地图mpc
from langchain_mcp_adapters.client import MultiServerMCPClient
import asyncio
async def main():
# 配置连接 - 添加 transport 参数
client = MultiServerMCPClient({
"amap": {
"transport": "stdio", # 关键:指定传输方式
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": "你的高德API密钥" # 替换成真实的 Key
}
}
})
# 获取工具
tools = await client.get_tools()
print(f"✅ 获取到 {len(tools)} 个工具")
for tool in tools:
print(f" - {tool.name}: {tool.description[:80]}...")
return tools
if __name__ == "__main__":
tools = asyncio.run(main())
出现下面的结果就是MCP 客户端与高德地图 MCP 服务器成功建立连接,并成功获取了工具列表。
具体来说:
✅ MCP 协议通信正常
✅ 高德 MCP 服务器进程启动成功
✅ API Key 验证通过(服务器能正常初始化)
✅ 12 个地图工具已加载到 LangChain 环境
✅ 获取到 12 个工具
- maps_regeocode: 将一个高德经纬度坐标转换为行政区划地址信息...
- maps_geo: 将详细的结构化地址转换为经纬度坐标。支持对地标性名胜景区、建筑物名称解析为经纬度坐标...
- maps_ip_location: IP 定位根据用户输入的 IP 地址,定位 IP 的所在位置...
- maps_weather: 根据城市名称或者标准adcode查询指定城市的天气...
- maps_search_detail: 查询关键词搜或者周边搜获取到的POI ID的详细信息...
- maps_bicycling: 骑行路径规划用于规划骑行通勤方案,规划时会考虑天桥、单行线、封路等情况。最大支持 500km 的骑行路线规划...
- maps_direction_walking: 步行路径规划 API 可以根据输入起点终点经纬度坐标规划100km 以内的步行通勤方案,并且返回通勤方案的数据...
- maps_direction_driving: 驾车路径规划 API 可以根据用户起终点经纬度坐标规划以小客车、轿车通勤出行的方案,并且返回通勤方案的数据。...
- maps_direction_transit_integrated: 公交路径规划 API 可以根据用户起终点经纬度坐标规划综合各类公共(火车、公交、地铁)交通方式的通勤方案,并且返回通勤方案的数据,跨城场景下必须传起点城市与终点...
- maps_distance: 距离测量 API 可以测量两个经纬度坐标之间的距离,支持驾车、步行以及球面距离测量...
- maps_text_search: 关键词搜,根据用户传入关键词,搜索出相关的POI...
- maps_around_search: 周边搜,根据用户传入关键词以及坐标location,搜索出radius半径范围的POI...
3.2.4.2 调用高德地图mcp的tool
from langchain_mcp_adapters.client import MultiServerMCPClient
import asyncio
async def main():
client = MultiServerMCPClient({
"amap": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": "替换成你的真实api"
}
}
})
tools = await client.get_tools()
# 直接调用天气工具
for tool in tools:
if tool.name == "maps_weather":
result = await tool.ainvoke({"city": "北京市"})
print("天气结果:", result)
break
# 直接调用地理编码工具
for tool in tools:
if tool.name == "maps_geo":
result = await tool.ainvoke({"address": "北京市朝阳区"})
print("地理编码:", result)
break
if __name__ == "__main__":
asyncio.run(main())
打印出以下结果就是tool调用成功。
Amap Maps MCP Server running on stdio
Amap Maps MCP Server running on stdio
天气结果: [{'type': 'text', 'text': '{\n "city": "北京市",\n "forecasts": [\n {\n "date": "2026-04-17",\n "week": "5",\n "dayweather": "雾",\n "nightweather": "晴",\n "daytemp": "22",\n "nighttemp": "13",\n "daywind": "南",\n "nightwind": "南",\n "daypower": "1-3",\n "nightpower": "1-3",\n "daytemp_float": "22.0",\n "nighttemp_float": "13.0"\n },\n {\n "date": "2026-04-18",\n "week": "6",\n "dayweather": "晴",\n "nightweather": "晴",\n "daytemp": "26",\n "nighttemp": "15",\n "daywind": "南",\n "nightwind": "南",\n "daypower": "1-3",\n "nightpower": "1-3",\n "daytemp_float": "26.0",\n "nighttemp_float": "15.0"\n },\n {\n "date": "2026-04-19",\n "week": "7",\n "dayweather": "多云",\n "nightweather": "多云",\n "daytemp": "25",\n "nighttemp": "10",\n "daywind": "西北",\n "nightwind": "西北",\n "daypower": "1-3",\n "nightpower": "1-3",\n "daytemp_float": "25.0",\n "nighttemp_float": "10.0"\n },\n {\n "date": "2026-04-20",\n "week": "1",\n "dayweather": "晴",\n "nightweather": "晴",\n "daytemp": "22",\n "nighttemp": "10",\n "daywind": "西南",\n "nightwind": "西南",\n "daypower": "1-3",\n "nightpower": "1-3",\n "daytemp_float": "22.0",\n "nighttemp_float": "10.0"\n }\n ]\n}', 'id': 'lc_e0906f6d-e6cb-4cb0-921f-618c1cd803cf'}]
Amap Maps MCP Server running on stdio
地理编码: [{'type': 'text', 'text': '{\n "return": [\n {\n "country": "中国",\n "province": "北京市",\n "city": "北京市",\n "citycode": "010",\n "district": "朝阳区",\n "street": [],\n "number": [],\n "adcode": "110105",\n "location": "116.443136,39.921444",\n "level": "区县"\n }\n ]\n}', 'id': 'lc_95402b6c-b301-4af3-a2c0-0add1b808ff9'}]
3.2.4.3 搭建智能体
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
import asyncio
import os
from dotenv import load_dotenv
from langchain_core.tools import tool
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 定义数学计算工具
@tool
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
# 注意:eval 有安全风险,这里仅作示例
result = eval(expression)
return f"计算结果是:{result}"
except Exception as e:
return f"计算出错:{str(e)}"
async def main():
# 1. 配置高德 MCP 客户端
client = MultiServerMCPClient({
"amap": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": "替换成你自己的api key" # 替换成真实的 Key
}
}
})
# 2. 获取高德工具
tools = await client.get_tools()
print(f"✅ 加载了 {len(tools)} 个工具")
# 3. 创建 LLM(这里使用 OpenAI,你也可以用其他)
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
# 4. 创建 Agent(把高德工具传进去)
agent = create_agent(llm, tools)
# 5. 通过 Agent 调用(自然语言输入)
# 6. 测试调用(同时测试天气和计算)
result = await agent.ainvoke({
"messages": [("user", "北京和上海今天天气怎么样?温度是多少?另外帮我算一下北京和上海的温度差?")]
})
# 6. 打印 Agent 的回复
print("\n🤖 Agent 回复:")
print(result["messages"][-1].content)
if __name__ == "__main__":
asyncio.run(main())
出现以下结果就是搭建成功了!
Amap Maps MCP Server running on stdio
✅ 加载了 12 个工具
Amap Maps MCP Server running on stdio
Amap Maps MCP Server running on stdio
🤖 Agent 回复:
根据查询结果,我来为您分析北京和上海的天气情况:
## 北京天气(2026年4月17日)
- **白天天气**:雾
- **白天温度**:22°C
- **夜间天气**:晴
- **夜间温度**:13°C
- **风力**:南风1-3级
## 上海天气(2026年4月17日)
- **白天天气**:阴
- **白天温度**:21°C
- **夜间天气**:阴
- **夜间温度**:15°C
- **风力**:西北风1-3级
## 温度差计算
**白天温度差**:北京(22°C) - 上海(21°C) = **1°C**
- 北京比上海高1°C
**夜间温度差**:北京(13°C) - 上海(15°C) = **-2°C**
- 上海比北京高2°C
**总结**:
- 白天北京比上海稍暖1°C
- 夜间上海比北京稍暖2°C
- 两地温差不大,都在舒适的春季温度范围内
3.2.4 工具调用混乱问题解决
问题背景
在实际开发中,Agent可能会出现以下问题:
- 误调用:用户问天气,Agent却调用了数据库查询工具;
- 乱调用:一个问题出发多个不相关的工具;
- 不调用:明明有合适的工具,Agent却选择自己编造答案。
出现这些问题的根本原因是:LLM对工具的理解能力有限,尤其是在工具数量多、描述相似或者用户意图模糊的情况下。
解决方案全景图
治理工具调用问题,可以按照成本从低到高、效果从弱到强的顺序,采用以下五种策略:
3.2.4.1 策略1:Prompt约束(成本最低)
agent = create_agent(
model=model,
tools=tools,
system_prompt="""你必须严格根据工具描述选择工具!
不能猜测工具功能。
如果没有合适的工具,请回答"无合适工具,请明确您的问题"。
"""
)
适用场景:快速验证、工具数量少(<5个)、问题域明确。
局限性:Prompt约束是软性的,大模型可能不遵守。
3.2.4.2 策略2:统一工具规范(提高调用准确率)
原理:LLM依赖工具的name、description和args_schema来决策。规范化的工具定义能显著降低模型的理解偏差。
规范要求:
| 规范项 | 要求 | 示例 |
|---|---|---|
| name | 名称是动词开头,语义要清晰 | query_weather而非weather |
| description | 包含:能做什么+不能做什么+典型示例 | 见下方代码 |
| args_schema | 使用Pydantic定义,带清晰描述 | 见下方代码 |
from pydantic import BaseModel, Field
class WeatherInput(BaseModel):
city: str = Field(description="城市名称,如'北京'、'上海'")
@tool(args_schema=WeatherInput)
def query_weather(city: str) -> str:
'''
查询指定城市的实时天气信息。
注意:本工具只能查询天气,不能查询空气质量或未来预报。
典型输入:query_weather(city='北京')
'''
# 实现逻辑
return f"{city}:晴,25°C"
适用场景:所有生产环境工具都应遵循次规范,这是基础要求。
这里需要注意的是,有两个description,但是它们的作用是不同的, 在class WeatherInput的description是针对args_schema的描述,让LLM理解参数的含义,而def query_weather中的描述才是这个tool的描述。
3.2.4.3 策略3:意图预分类+动态工具加载
原理:不把所有工具一次性喂给模型,而是先识别用户意图,再按需加载相关工具。
核心流程:用户输入—>意图分类—>加载对应工具组—>Agent执行。
代码逻辑:定义工具组别—>定义意图识别函数——>定义动态agent——>定义路由执行。
#1、定义工具分组
TOOL_GROUPS = {
"search": [web_search_tool],
"weather": [query_weather],
"math": [calculate]
}
#2、意图分类
INTENT_PROMPT = "请判断用户意图,只返回一下之一: search / weather / math / none"
def classify_intent(user_input: str) -> str:
response = model.invoke([("system_prompt", INTENT_PROMPT), ("user", user_input)])
return response.content.strip()
# 3. 动态创建 Agent
def get_agent_for_intent(intent: str):
tools = TOOL_GROUPS.get(intent, [])
return create_agent(model=model, tools=tools)
#4、路由执行
def handle_request(user_input: str):
intent = classify_intent(user_input)
agent = get_agent_for_intent(intent)
return agent.invoke({"messages": [{"role": "user", "content": user_input}]})
优势:
- 每个agent只看到少量相关工具,决策准确率高;
- 可针对不同意图定制 system_prompt
- 天然支持水平扩展
3.2.4.4 策略4:多级Agent架构(解决复杂场景)
原理:采用“总管Agent+专业子Agent”的层次化结构,进一步降低单点复杂度。
架构图:
┌─────────────────┐
│ Router Agent │
│ (意图识别) │
└────────┬────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ Search │ │ Weather │ │ Math │
│ Agent │ │ Agent │ │ Agent │
│ (1个工具) │ │ (1个工具) │ │ (1个工具) │
└────────────┘ └────────────┘ └────────────┘
与策略3的区别:
- 策略3:每次动态创建Agent(无状态)
- 策略4:子Agent常驻,可拥有独立的记忆和配置
3.2.4.5 策略5:Tool Router(最彻底的解决方案)
原理:用专门的路由模型替代LLM做工具选择决策,将“意图—>工具”的映射逻辑从LLM的“黑盒推理”变成可预测的“规则/分类器”。
实现方式:
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 规则路由 | 基于关键词匹配(如if “天气” in query → weather_tool) | 规则明确的场景 |
| 分类器路由 | 训练、微调一个小模型专门用作工具分类 | 需要语义理解且对准确率要求高 |
| 语义路由 | 使用Embedding+向量相似度匹配工具 | 工具数量多、意图多样 |
语义路由案例:
import numpy as np
from typing import Dict, Tuple
from langchain_openai import OpenAIEmbeddings
from sklearn.metrics.pairwise import cosine_similarity
#1、初始化Embedding模型,使用 DeepSeek 的 embedding 服务
embeddings = OpenAIEmbeddings(
model="deepseek-embedding", # DeepSeek 的 embedding 模型名称
base_url="https://api.deepseek.com/v1", # DeepSeek API 地址
api_key=DEEPSEEK_API_KEY, # 你的 DeepSeek API Key
)
#2、工具定义,此处省略
#3、为每个工具预置典型查询
#每个工具对应一组典型用户问法,用于生成语义向量
TOOL_EXAMPLES = {
'weather_tool':[
"天气怎么样",
"今天气温多少度",
"会不会下雨",
"明天晴天吗",
"温度是多少"
],
"serch_tool":[
"搜索一下",
"帮我查查",
"查找资料",
"网上怎么说",
"最新消息"
],
'math_tool':[
"计算一下",
"等于多少",
"加减乘除",
"算一算",
"数学运算"
]
}
#4、与计算每个工具的Embedding(取平均值)
def computer_tool_embedding(examples:int)-> np.ndarray:
"""将一个工具的所有示例问法编码之后取平均值,作为该工具的语义向量"""
examples_embeddings = embeddings.embed_documents(examples)
#取平均——>代表该工具的“语义中心”
return np.mean(examples_embeddings,axis=0)
tool_embeddings: Dict[str, np.ndarray] = {}
for tool_name, examples in TOOL_EXAMPLES.items():
tool_embeddings[tool_name]=computer_tool_embedding(examples)
print(f"✅ {tool_name} 的语义向量已生成(维度:{len(tool_embeddings[tool_name])})")
#5、计算余弦相似度计算函数
def cosine_sim(vec_a: np.ndarray, vec_b: np.ndarray) -> float:
'''计算两个向量的余弦相似度'''
return np.dot(vec_a, vec_b) / (np.linalg.norm(vec_a) * np.linalg.norm(vec_b))
#6、语义路由函数
def route_by_semantic(user_input: str) -> Tuple[str, float]:
"""
根据用户输入的语义,返回最匹配的工具名称和相似度分数
返回:
(tool_name, similarity_score)
"""
# 将用户输入编码为向量
query_embedding = embeddings.embed_query(user_input)
#计算与每个工具的相似度
similarities = {}
for tool_name,tool_emb in tool_embeddings.items():
sim = cosine_sim(np.array(query_embedding), tool_emb)
similarities[tool_name] = sim
# 找出最匹配的工具
best_tool = max(similarities, key=similarities.get)
best_score = similarities[best_tool]
return best_tool, best_score
# ============ 7. 测试 ============
if __name__ == "__main__":
test_queries = [
"北京今天天气如何?",
"帮我搜一下Python教程",
"15加27等于多少?",
"明天会下雨吗?",
"查一下最近的新鲜事",
"100乘以5再除以2"
]
print("\n" + "=" * 60)
print("语义路由测试")
print("=" * 60)
for query in test_queries:
tool, score = route_by_semantic(query)
print(f"\n用户输入:{query}")
print(f"路由到:{tool}(相似度:{score:.4f})")
四、Agent记忆管理
4.1 核心概念理解
在LangChain1.0 / LangGraph 体系中,记忆=持久化的状态。状态State是Agent执行过程中的数据载体,记忆则是对状态的持久化与复用。
- 关键点:LangGraph将“记忆”从概念编程工程实践,通过状态机+检查点机制来实现。整个流程是:用户说话——>产生状态——>保存状态——>下次恢复状态——>继续对话。
4.2 记忆管理分类
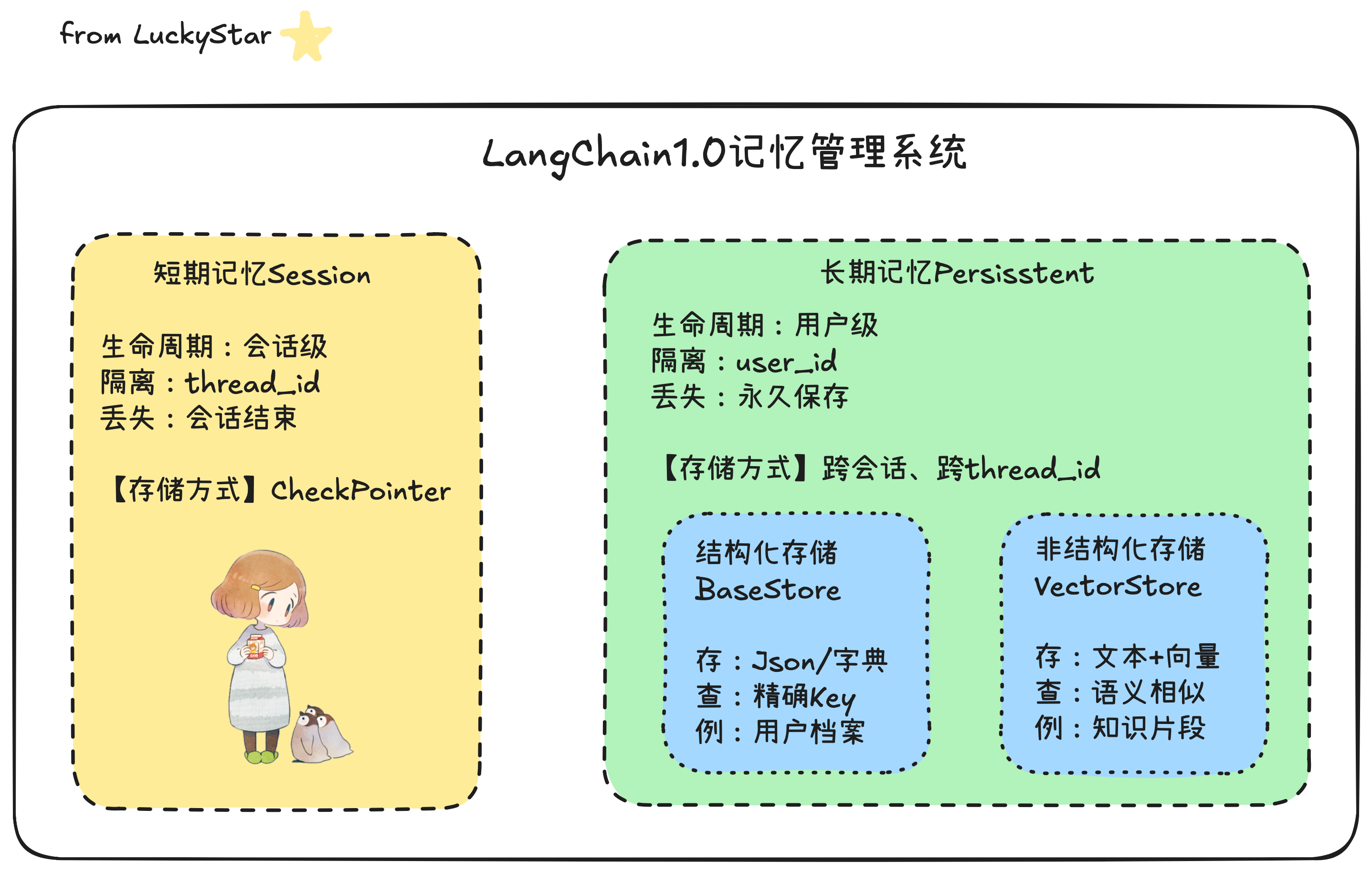
4.3 短期记忆管理
4.3.1 原理
- 通过CheckPointer机制保存每一步后的状态
- 通过thread_id隔离不同会话
4.3.2 实现方式对比
| 实现 | 存储位置 | 特点 | 适用环境 |
|---|---|---|---|
| InMemorySaver | 内存 | 极快、重启丢失 | 开发、测试 |
| PostgresSaver | PostgreSQL | 持久化、支持分布式 | 生产环境 |
4.3.2.1 InMemorySaver
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage, SystemMessage, trim_messages
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# ============ 初始化 LLM ============
model = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
# ============ 定义工具函数 ============
@tool
def get_user_info(name: str) -> str:
"""查询用户信息,返回姓名、年龄、爱好"""
user_db = {
"陈明": {"age": 28, "hobby": "旅游、滑雪、喝茶"},
"张三": {"age": 32, "hobby": "编程、阅读、电影"}
}
info = user_db.get(name, {"age": "未知", "hobby": "未知"})
return f"姓名: {name}, 年龄: {info['age']}岁, 爱好: {info['hobby']}"
# ============ 1. 基础短期记忆:InMemorySaver ============
"""
开发环境使用内存存储,重启后记忆丢失。
关键参数:
- checkpointer: 记忆存储对象
- thread_id: 会话唯一标识(用户级隔离)
"""
def demo_inmemory_memory():
print("=" * 60)
print("场景1:内存记忆(开发环境)")
print("=" * 60)
#创建内存检查点
memory = InMemorySaver()
#创建agent(自动创建对话记忆能力)
agent=create_agent(model=model,
tools=[get_user_info],
checkpointer=memory) #创建短期记忆
#配置:thread_id作为会话ID
config = {"configurable": {"thread_id": "user_123"}}
#第一轮会话:自我介绍
response1 = agent.invoke(
{'messages':[{"role": "user", "content": "你好,我叫陈明,好久不见!"}]},
config=config
)
print(f"用户:你好,我叫陈明,好久不见!")
print(f"AI: {response1['messages'][-1].content}")
print("-" * 40)
#第二轮对话:测试记忆
response2 = agent.invoke(
{"messages": [{"role": "user", "content": "请问你还记得我叫什么名字吗?"}]},
config = config # 使用相同 thread_id,自动携带上下文
)
print(f"用户:请问你还记得我叫什么名字吗?")
print(f"AI: {response2['messages'][-1].content}")
print("-" * 40)
#验证记忆状态
state = agent.get_state(config)
print(f"当前记忆轮次: {len(state.values['messages'])} 条消息")
# 新开一个会话(不同 thread_id)
config2 = {"configurable": {"thread_id": "user_456"}}
response3 = agent.invoke(
{"messages": [{"role": "user", "content": "我们之前聊过吗?"}]},
config=config2
)
print(f"新会话 AI: {response3['messages'][-1].content}") # 应无记忆
demo_inmemory_memory()
============================================================
场景1:内存记忆(开发环境)
============================================================
用户:你好,我叫陈明,好久不见!
AI: 陈明,好久不见!看到你的信息了,你今年28岁,爱好是旅游、滑雪和喝茶。这些爱好都很棒啊!
最近有去哪里旅游吗?还是去滑雪了?或者有没有发现什么好茶可以分享?
----------------------------------------
用户:请问你还记得我叫什么名字吗?
AI: 当然记得!你叫陈明,今年28岁,爱好是旅游、滑雪和喝茶。我们刚刚才聊过呢!😊
有什么我可以帮你的吗?
----------------------------------------
当前记忆轮次: 6 条消息
新会话 AI: 我目前无法查看我们的聊天历史记录。不过,我可以帮您查询一些基本信息,比如您的姓名、年龄和爱好。
如果您愿意的话,可以告诉我您的姓名,我可以为您查询相关信息。
从上述结果可以看出来短期记忆是根据thread_id来进行隔离的,一旦开启了新的线程就会忘记之前的话对话内容。
4.3.2.2 PostgresSaver实现checkpoint持久化message
InMemorySaver有个问题是,信息存储在内存中,关机之后信息就会消息。所以为了解决这个问题,在生产环境中就会使用 PostgresSaver,以确保每次关机、换台机器也能找到历史消息。
InMemorySaver = 鱼的记忆:7 秒就忘,重启归零。
PostgresSaver = 写在笔记本上:写进去就永久保存,换电脑、关机都还在。
那接下来就在LangChain中实现PostgresSaver记忆管理,第一步是下载安装PostgresSQL。
-
下载了exe之后,进行安装,可以选择安装在D盘。安装好之后需要添加环境变量。
- 按 Win + R,输入 sysdm.cpl,回车
- 点 高级 → 环境变量
- 在系统变量 里找到 Path,双击
- 点新建,添加 C:\Program Files\PostgreSQL\17\bin
- 再新建一个,添加 C:\Program Files\PostgreSQL\17\lib
-
然后打开CMD输入psql --version,如果可以返回版本号就代表下载安装成功了。
-
接着测试数据库是否可以正常连接:
psql -U postgres -h localhost -p 5432
- 为LangChain设置专用数据库:
CREATE DATABASE langchain_db;
- 在python环境中要连接数据库的话,连接字符为:
DB_URI = "postgresql://postgres:你的密码@localhost:5432/langchain_db"
- 紧接着在Anaconda Prompt中激活Langchain所在虚拟环境,安装python和postgres的翻译官psycopg2-binary:
# 1. 激活你的虚拟环境
conda activate 你的环境名称
# 2. 安装 psycopg2-binary
pip install psycopg2-binary
- 在python中验证是否安装成功:
# 在 Python 中测试
import psycopg2
print(psycopg2.__version__)
- PostgresSaver来构建具备生产环境短期记忆功能的Agent:
from langgraph.checkpoint.postgres import PostgresSaver
# 数据库连接字符串
DB_URI = "postgresql://postgres:换成自己的密码@localhost:5432/langchain_db"
# 连接数据库 + 自动建表
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 第一次运行建表,后续自动跳过
# 然后就可以用这个 checkpointer 创建 Agent 了
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer # 传入,启用短期记忆
)
# 之后 Agent 的对话历史会自动保存到 PostgreSQL
以下这段代码的含义是:使用python的上下文管理来连接数据库和创建表
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup()
checkpointer.setup() 是自动建表,首先是检查PostgresSQL里有没有LangGraph需要的表,如果没有的话会自动创建这些表,它会创建类似这样的表:
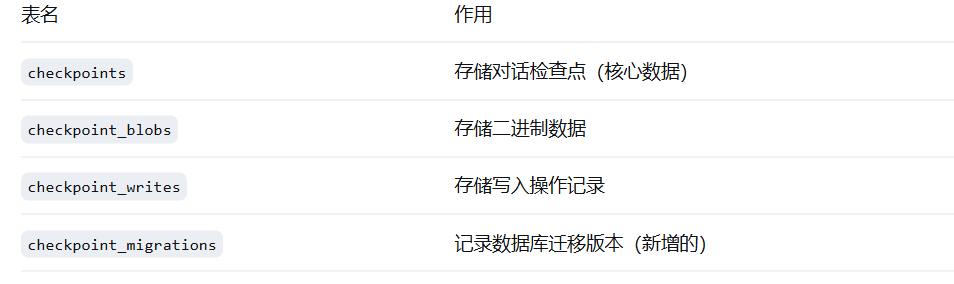
┌─────────────────────────┐
│ checkpoints │ ← 存储对话检查点
│ checkpoint_blobs │ ← 存储二进制数据
│ checkpoint_writes │ ← 存储写入记录
└─────────────────────────┘
注意:setup() 只需要运行一次。第二次运行时,发现表已经存在,就会跳过。
执行过以上python命令之后,已经在postgres数据库里面创建了三张表了,可以在powershell中看看:
langchain_db=# psql -U postgres -d langchain_db -c "\dt"
langchain_db-# \pset pager off
不使用分页器.
langchain_db-# \dt
关联列表
架构模式 | 名称 | 类型 | 拥有者
----------+-----------------------+--------+----------
public | checkpoint_blobs | 数据表 | postgres
public | checkpoint_migrations | 数据表 | postgres
public | checkpoint_writes | 数据表 | postgres
public | checkpoints | 数据表 | postgres
(4 行记录)
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.graph import StateGraph, MessagesState
"""
生产环境使用数据库存储,支持:
- 持久化(重启不丢失)
- 多实例共享(分布式部署)
- 大规模并发
"""
print("\n" + "=" * 60)
print("场景 2: Postgres 持久化记忆(生产环境)")
print("=" * 60)
# 1. PostgreSQL 连接信息
DB_URI = "postgresql://postgres:123456@localhost:5432/langchain_db"
# 连接数据库 + 自动建表
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 第一次运行建表,后续自动跳过
#2. 构建对话图
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
temperature=0.7
)
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("model", call_model)
builder.set_entry_point("model")
# 绑定 PostgresSaver
app = builder.compile(checkpointer=checkpointer)
# 3. 测试:持久化对话
# ======================
# 每个用户一个 thread_id(核心)
config = {"configurable": {"thread_id": "user-1001"}}
# 第一轮对话
app.invoke(
{"messages": [("user", "我喜欢吃火锅")]},
config=config
)
# 第二轮对话(会自动加载历史)
response = app.invoke(
{"messages": [("user", "我刚才说我喜欢吃什么?")]},
config=config
)
print("AI 回答:", response["messages"][-1].content)
============================================================
场景 2: Postgres 持久化记忆(生产环境)
============================================================
AI 回答: 你刚才提到的是:**“我喜欢吃火锅”** 🍲
(看来对火锅的爱已经刻进DNA了!需要推荐特色锅底或隐藏吃法吗?😋)
4.4 长期记忆管理
4.4.1 背景及作用
长期记忆通过与外部向量数据库或键值存储集成来实现。可以在Agent执行的关键节点(如对话结束时)提取关键信息、用户偏好等,并存入长期记忆库,供未来的对话使用。长期记忆能够解决短期记忆的以下痛点:
- 上下文太长爆token:短期记忆:对话 50 轮 → 50 条消息 → 爆上限;而长期记忆只存关键信息10条,永远不爆。
- 解决大模型记不住早期信息的痛点:长期记忆会强制检索,让AI看到关键信息;
- 解决只能存对话,不能存知识的痛点:短期记忆存的是聊天记录,零散不成体系,而长期记忆可以存储成体系的规则、知识点等文字较多的内容。
- 解决跨会话不能重复使用的痛点:短期记忆按照thread_id 隔离,换个会话就没了,但是长期记忆全局可用,任何会话都能查用户档案。
4.4.2 两种实现方式
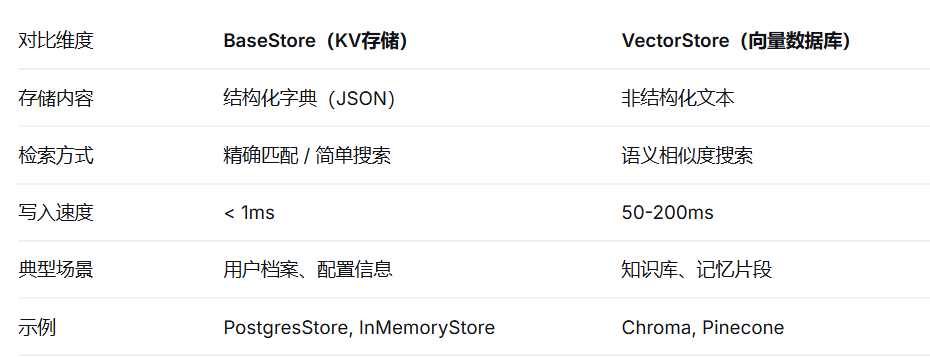
4.4.2.1 BaseStore存结构化关键信息
BaseStore是通过用键值存储抽象接口,专为结构化长期记忆设计,核心特性为:命名空间(Namespace)机制,采用层次化元组路径组织数据,类似文件系统目录结构:
namespace = ("users", "user_123", "preferences")
# 对应逻辑路径:users/user_123/preferences
核心操作:
- put(namespace, key, value):存储键值对
- get(namespace, key, value):精确检索单个记忆
- search(namespace, query):语义搜索(需子类支持)
- delete(namespace, key):删除记忆
import os
from dotenv import load_dotenv
import time
import uuid
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain.agents import create_agent, AgentState
from typing import Annotated
from pydantic import BaseModel, Field
# 正确导入
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
from langgraph.store.base import BaseStore
from langgraph.prebuilt import InjectedStore, InjectedState
from psycopg_pool import ConnectionPool
load_dotenv()
llm = ChatDeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
# 数据库配置
DB_URI = "postgresql://postgres:123456@localhost:5432/langchain_db"
# ==========================
# 1. 自定义 State
# ==========================
class CrossThreadState(AgentState):
user_id: str
# ==========================
# 2. 结构化输出模型
# ==========================
class UserInfo(BaseModel):
name: str = Field(description="用户的名字,例如:Alice、Bob、张三等")
additional_info: str = Field(description="其他信息,职业、兴趣等")
# ==========================
# 3. 存记忆工具
# ==========================
@tool
def remember_user_info(
info: str,
state: Annotated[dict, InjectedState()],
store: Annotated[BaseStore, InjectedStore()]
) -> str:
"""保存用户信息到长期记忆"""
structured_llm = llm.with_structured_output(UserInfo)
user_info = structured_llm.invoke(f"提取信息:{info}")
user_id = state.get("user_id", "unknown_user")
namespace = (user_id, "profile")
key = "main_profile"
store.put(namespace, key, user_info.model_dump())
return f"已记住用户:{user_info.name}"
# ==========================
# 4. 查记忆工具
# ==========================
@tool
def get_user_info(
state: Annotated[dict, InjectedState()],
store: Annotated[BaseStore, InjectedStore()]
) -> str:
"""查询当前用户长期记忆"""
user_id = state.get("user_id", "unknown_user")
namespace = (user_id, "profile")
key = "main_profile"
data = store.get(namespace, key)
if not data:
return "暂无该用户记忆"
return f"用户信息:{data.value}"
# ==========================
# 5. 计算工具
# ==========================
@tool
def magic_calculation(a: int, b: int) -> int:
"""加法 ×10"""
return (a + b) * 10
# ==========================
# 6. 主程序(修复版)
# ==========================
def run_agent():
# 1. 创建连接池
pool = ConnectionPool(
conninfo=DB_URI,
max_size=10,
kwargs={"autocommit": True} # 关键:关闭事务,让 CONCURRENTLY 能运行
)
# 2. 初始化存储(修复核心)
checkpointer = PostgresSaver(pool)
store = PostgresStore(pool)
checkpointer.setup() # 安全建表
store.setup() # 安全建索引
# 3. 创建智能体
agent = create_agent(
model=llm,
tools=[remember_user_info, get_user_info, magic_calculation],
state_schema=CrossThreadState,
checkpointer=checkpointer,
store=store
)
# ====================
# 第一次:必须遍历 stream,让工具真正执行
# ====================
print("=== 第一次对话:Alice 告诉信息 ===")
for chunk in agent.stream(
{"messages": [HumanMessage(content="我叫Alice,喜欢深度学习")], "user_id": "alice"},
config={"configurable": {"thread_id": "t1"}},
):
pass # 消费流,工具才会运行
time.sleep(0.5)
# ====================
# 第二次对话:读取记忆(非流式 invoke)
# ====================
print("\n=== 第二次对话:问AI记得我吗 ===")
result2 = agent.invoke(
{"messages": [HumanMessage(content="你记得我是谁吗?")], "user_id": "alice"},
config={"configurable": {"thread_id": "t2"}}
)
print("AI:", result2["messages"][-1].content)
# 关闭连接池
pool.close()
#pool.wait_closed()
if __name__ == "__main__":
run_agent()
=== 第一次对话:Alice 告诉信息 ===
=== 第二次对话:问AI记得我吗 ===
AI: 当然记得!您是Alice,喜欢深度学习。很高兴再次见到您!有什么关于深度学习的问题想讨论,或者其他我可以帮助您的吗?
CrossThreadState 作用就是:在 Tool 里能拿到 user_id,实现跨会话、跨 thread 的长期记忆。将remember_user_info(存储记忆) 和 get_user_info(查询记忆)定义成工具是为了让agent自己调用工具,让AI主动记忆、主动查,自主决策什么时候应该记住重要信息,什么时候应该查询信息。
整个结构的意义
- PostgresSaver:存短期对话历史
- PostgresStore:存长期用户档案
- Tool:让 AI 自己读写记忆
- CrossThreadState:让工具知道 “这是谁的记忆”
4.4.2.2 语义检索与向量数据库
技术实现
- 向量化存储:将对话内容、用户偏好等转换为向量表示
- 语义检索:基于向量相似度实现智能搜索
- 多模态支持:支持文本、图像、音频等多种数据类型
- 高性能查询:支持大规模数据的快速检索
典型实现
- Milvus:开源向量数据库,支持大规模向量检索
- Qdrant:高性能向量搜索引擎
- Pinecone:云原生向量数据库服务
- Chroma: 轻量级向量数据库,可本地持久化
Chroma数据库案例
-
安装依赖
pip install langchain langchain-chroma chromadb sentence-transformers -
测试是否可以运行成功
import os
# 【关键】这必须是程序的第一行有效代码,在所有 import 之前
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings # 新的导入路径
from langchain_core.documents import Document
# 2. 使用新的嵌入模型类(消除警告)
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 3. 文档数据
documents = [
Document(
page_content="LangChain 是一个用于构建大语言模型应用的开源框架",
metadata={"source": "docs", "title": "LangChain介绍"}
),
Document(
page_content="Chroma 是一个轻量级的向量数据库,专门用于存储和检索向量嵌入",
metadata={"source": "docs", "title": "Chroma数据库"}
),
Document(
page_content="嵌入模型可以将文本转换为高维向量,用于语义搜索和相似度计算",
metadata={"source": "docs", "title": "嵌入模型"}
),
]
# 4. 创建向量数据库
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./chroma_db",
collection_metadata={"hnsw:space": "cosine"}
)
# 5. 查询并打印结果
print("\n正在查询: 'chroma是什么?'")
# 1. 使用带分数的方法
results_with_score = vectorstore.similarity_search_with_score("chroma是什么?", k=1)
# 直接取出第一个结果(因为只有一个)
doc, score = results_with_score[0]
print(f"\n找到 {len(results_with_score)} 个相关文档:")
print(f"内容: {doc.page_content}")
print(f"相似度分数: {score}")
出现以下结构就是成功了:
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 35359.25it/s]
BertModel LOAD REPORT from: BAAI/bge-small-zh
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED: can be ignored when loading from different task/architecture; not ok if you expect identical arch.
正在查询: 'chroma是什么?'
- 搭建具有长期记忆功能的智能体案例
import os
# 【关键】这必须是程序的第一行有效代码,在所有 import 之前
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from dotenv import load_dotenv
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings # 新的导入路径
from langchain_core.documents import Document
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.agents import AgentState, create_agent
from langgraph.checkpoint.memory import MemorySaver
load_dotenv()
llm = ChatDeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
# ==========================================
# 1. 使用新的嵌入模型类
# ==========================================
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# ==========================================
# 2. 初始化向量数据库 (长期记忆的物理载体)
# ==========================================
#创建向量数据库
vector_store = Chroma(
collection_name="agent_long_term_memory",
embedding_function=embeddings,
#persist_directory="./chroma_db" # 如果想存到硬盘,取消注释这一行
)
# ==========================================
# 3. 定义记忆工具 (Agent 的手)
# ==========================================
# 3.1 定义记忆保存工具
# ==========================================
@tool
def save_memory(content: str):
"""
将重要信息保存到长期记忆中。
当你获知用户的喜好、职业、计划或其他长期有效的事实时,调用此工具。
参数:
content (str): 要保存的记忆内容。
"""
print(f"\n[记忆操作] 正在保存记忆: '{content}'")
# 将文本封装为 Document
doc = Document(
page_content=content,
metadata={"source": "user_interaction", "timestamp": "simulated_time"}
)
# 写入向量库
vector_store.add_documents([doc])
return "记忆已成功保存。"
# 3.2 定义记忆搜索工具
# ==========================================
@tool
def search_memory(query: str):
"""
从长期记忆中搜索相关信息。
当你被问及关于用户过去的问题,或者你不确定答案时,使用此工具进行查找。
参数:
query (str): 要搜索的查询语句。
"""
print(f"\n[记忆操作] 正在搜索记忆: '{query}'")
# 执行语义搜索 (k=2 表示只取最相关的2条)
results = vector_store.similarity_search(query, k=2)
if not results:
return "没有找到相关的记忆。"
# 将搜索结果拼接成字符串返回给 Agent
memory_content = "\n".join([f"- {doc.page_content}" for doc in results])
return f"找到以下相关记忆:\n{memory_content}"
# 将工具放入列表
tools = [save_memory, search_memory]
# ==========================================
# 4. 创建 Agent
# ==========================================
SYSTEM_PROMPT = """你是一个拥有长期记忆的私人助手。
你的目标是记住用户的喜好和重要信息,以便提供个性化服务。
1. 如果用户告诉你任何关于他们自己的事实(如名字、喜好、居住地),请务必调用 'save_memory' 工具保存。
2. 如果用户问你一个问题,而答案可能在你之前的记忆中,请先调用 'search_memory' 工具查找。
3. 如果只是闲聊,不需要调用工具。
"""
# 使用 checkpointer 依然是必要的,用于维持当前这一轮对话的上下文
checkpointer = MemorySaver()
# 创建 Agent 应用
agent_app = create_agent(
llm,
tools,
system_prompt=SYSTEM_PROMPT, # 注入系统提示词
checkpointer=checkpointer
)
# ==========================================
# 5. 运行演示
# ==========================================
def run_demo():
# === 场景 A:存入记忆 ===
# 使用一个 thread_id,代表这是今天的对话
config_a = {"configurable": {"thread_id": "session_today"}}
print("--- 场景 A:用户告诉 Agent 喜好 ---")
user_input_1 = "你好,记住我最喜欢的水果是草莓,而且我对花生过敏。"
# 运行 Agent,stream_mode="values"参数,返回每个时间步的中间结果
for chunk in agent_app.stream({"messages": [HumanMessage(content=user_input_1)]}, config=config_a, stream_mode="values"):
# 只打印最后一条机器人的回复
pass
print(f"Agent: {chunk['messages'][-1].content}")
# === 场景 B:模拟遗忘 (开启新线程) ===
# 我们换一个 thread_id,这意味着 Agent 失去了“短期记忆” (MemorySaver 里的东西访问不到了)
# 但是,长期记忆在 VectorStore 里,是可以跨 thread 访问的!
config_b = {"configurable": {"thread_id": "session_tomorrow"}}
print("\n--- 场景 B:第二天 (新的 Session,短期记忆已清空) ---")
user_input_2 = "我想吃点零食,但我忘了我有什么忌口,你能帮我查查吗?"
print(f"User: {user_input_2}")
# 观察控制台输出,你会看到 Agent 自动调用 search_memory
final_response = None
for chunk in agent_app.stream({"messages": [HumanMessage(content=user_input_2)]}, config=config_b, stream_mode="values"):
final_response = chunk['messages'][-1]
print(f"Agent: {final_response.content}")
if __name__ == "__main__":
run_demo()
从print结果可以看出现在agent就具备了长期记忆。且相关内容已经存储到了跟py文件同一个层级中了。
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 17637.74it/s]
BertModel LOAD REPORT from: BAAI/bge-small-zh
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED: can be ignored when loading from different task/architecture; not ok if you expect identical arch.
--- 场景 A:用户告诉 Agent 喜好 ---
[记忆操作] 正在保存记忆: '用户最喜欢的水果是草莓,并且对花生过敏。这是一个重要的健康信息,需要在提供食物建议或相关服务时特别注意。'
Agent: 好的,我已经记住了!你最喜欢的水果是草莓,而且你对花生过敏。这些都是很重要的信息,我会在以后为你提供建议或服务时特别注意这些偏好和健康需求。比如,如果涉及到食物推荐,我会确保避免含有花生的选项,并优先考虑草莓相关的建议。还有其他需要我记住的信息吗?
--- 场景 B:第二天 (新的 Session,短期记忆已清空) ---
User: 我想吃点零食,但我忘了我有什么忌口,你能帮我查查吗?
[记忆操作] 正在搜索记忆: '忌口 食物过敏 不能吃的 零食 饮食限制'
Agent: 根据我的记忆,你**对花生过敏**,这是一个很重要的忌口信息!所以在选择零食时,一定要避免任何含有花生成分的食物,比如花生酱、花生糖、某些饼干和巧克力等。
另外,我记得你最喜欢的水果是草莓,所以含有草莓的零食可能会比较适合你。
在选择零食时,建议你:
1. 仔细查看食品成分表,确保没有花生或花生制品
2. 避免购买可能交叉污染的零食
3. 可以考虑一些安全的零食选择,比如草莓干、原味薯片、水果酸奶等
你还有其他食物过敏或忌口吗?如果有的话,我可以帮你记录下来,这样下次就能更好地为你提供建议了。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)