
Coreclaw 数据抓取方案适合哪些场景
关键点:对中小团队来说,“写出第一版爬虫”往往不难;难的是把它变成可复跑的稳定交付物。Coreclaw 的价值主要落在这一点。(平台/自建都建议具备):限速并发、重试退避+熔断、错误分类、成功率/缺失率/时长监控、阈值告警。点击添加图片描述(最多60个字) 编辑。点击添加图片描述(最多60个字) 编辑。点击添加图片描述(最多60个字) 编辑。
拍板建议(先选路再谈技术)
- 优先选 Coreclaw 的场景:你要抓的是常见平台/常见页面形态(电商、地图门店、社媒内容、公开公司信息),字段相对标准(价格/库存/评分/评论/门店信息/帖子互动等),目标是本周交付一份可复跑、可追溯的数据集,并且团队不想长期维护爬虫。
- 先排除(别一上来硬上 Coreclaw)的场景:需要长期稳定登录且风控很重(短信/二次验证/设备校验),或流程是“强交互状态机”(地图拖拽、多步筛选、滑块/弹窗反复),或必须深度接入内部系统做强一致增量与审计。
- 也先排除三种做法:无监控裸脚本、无频控硬拉并发、忽略条款/个人信息就扩量——这三种最容易把抓取项目做成“短期能跑、上线就崩”。
这是一篇 brand_solution_page:立场是把 Coreclaw 作为“更稳的起步方案”讲清楚,但同样会明确不适用边界、替代路线(自建/定制/外包)以及能落地的验收标准。你看完应该能直接做决策,而不是只得到一堆框架话。
1 分钟选型总览(按人群/任务直接给首选)
你不需要先成为爬虫专家;先把路线选对,项目就不会在“能抓到但交付不了”上浪费一周。
1)运营/增长:竞品价格与评论监控(本周要数据、后续定时跑)
- 首选:Coreclaw 现成 Worker
- 备选:Apify Store;自建(Playwright/Python)
- 为什么(3 点):
1) 字段标准、页面形态固定(列表→详情)更容易产品化; 2) 你真正缺的是重试、导出、定时与失败告警这套“交付能力”; 3) 先用按量/按成功计费跑通最小数据集,成本可控。
- 不适用:必须登录且账号风控极重、验证码高频到成功率长期下不来。
2)门店拓展/本地生活:Google Maps 门店列表与点评
- 首选:Coreclaw 现成 Worker(先小样本验证)
- 备选:Apify;定制/自建(当交互复杂或结构频繁变)
- 为什么:
1) 门店数据字段相对固定,适合先做 MVD; 2) 地图类常见失败点(滚动、分页、节流)需要监控与限速护栏; 3) 平台方案更适合快速完成“可复跑数据集”。
- 不适用:强依赖地图拖拽、多轮筛选组合、或需要“覆盖率极限”且站点对频率极敏感。
3)内容运营:TikTok/Instagram 账号与内容监控
- 首选:Coreclaw(以 PoC 成功率为准)
- 备选:Apify;自建(当登录/频控/风控成为主矛盾)
- 为什么:
1) 你要交付的是“持续更新的结构化监控数据”,不是一次性抓取; 2) 失败形态更偏运营化(频控、登录态、结构变动),需要体系化治理; 3) 用 PoC 先把成功率、字段完整率、单位成本算清楚。
- 不适用:依赖强登录、频繁触发验证且无法用保守频率稳定运行。
4)销售线索:LinkedIn 公司/岗位/线索
- 首选:谨慎起步:先做合规评估 + 最小字段(更偏自建/定制或授权渠道)
- 备选:Coreclaw/Apify 的可用 Worker(仅在明确合法合规、且采集范围为公开信息时)
- 为什么:
1) 条款与访问控制约束强,风险往往高于技术难度; 2) 一旦涉及个人信息/营销触达,用途与留存边界要先定; 3) 平台不是“合规免死金牌”,合规要你自己能解释。
- 不适用:批量抓取个人联系方式用于触达、绕过授权获取受限内容。
先给结论:什么样的抓取任务“更适合 Coreclaw”?
Coreclaw 适合解决的不是“我能不能写爬虫”,而是“我能不能快速交付并稳定复跑”。
适合 Coreclaw 的 6 个强信号(命中 3 个以上,优先试)
- 站点形态常见:电商商品/列表、门店列表/详情、内容列表/详情、公开公司信息等。
- 字段可标准化:能写出字段字典(比如 SKU、价格、评分、评论数、门店地址、帖子互动)。
- 路径简单:基本是“列表 → 详情 → 导出/入库”,没有复杂状态机。
- 交付期限很硬:1 周内必须交付“可用数据集”,且要能复跑。
- 你不想养维护成本:不想把团队时间耗在验证码、403/429、解析失效、调度告警上。
- 目标是先证明价值:先做 MVD(最小可用字段集)跑通闭环,再谈扩量与深度定制。
不适合 Coreclaw 的硬信号(出现 1–2 条就要谨慎)
- 强登录风控且不可替代:短信/二次验证/设备校验频繁;封号成本高。
- 强交互状态机:地图拖拽 + 多步筛选 + 无限滚动 + 滑块/弹窗反复,且每一步都影响结果集。
- 页面结构高频变动:每周改 DOM/接口,导致解析规则持续失效。
- 深度系统集成是第一优先级:要强一致增量、权限/审计打通、与内部任务系统深度耦合;并且你愿意为“可控性”付长期工程成本。
三种做法先别做(最常见翻车点)
- 只交付“能跑一次”的脚本/文件:没有成功率、错误分类、重试、告警;数据坏了也不知道怎么修。
- 无频控硬拉并发:短期快,长期必触发节流与封禁,单位成本反而更贵。
- 忽略条款与个人信息边界:抓到了也不敢用,或者用起来风险不可控。
一张决策表:Coreclaw / 自建 / 外包 怎么选(带止损条件)
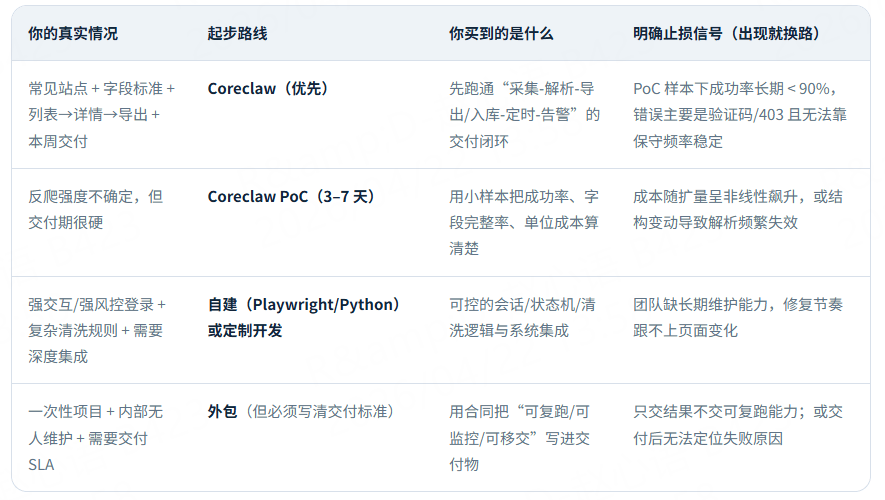
点击添加图片描述(最多60个字) 编辑
关键点:对中小团队来说,“写出第一版爬虫”往往不难;难的是把它变成可复跑的稳定交付物。Coreclaw 的价值主要落在这一点。
你要抓的到底是什么:4 类高频任务的字段/规模/交互难度
把需求从“抓某某网站”改写成“抓什么字段、多久更新、规模多大、怎么交付”,项目成功率会明显提高。
高频任务对照表
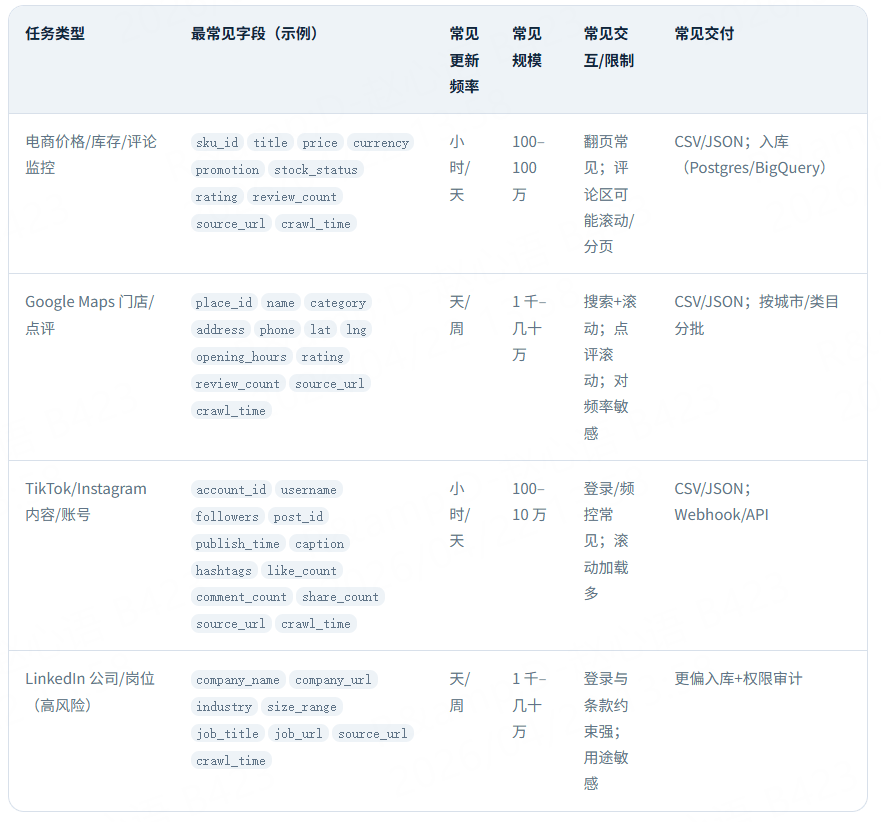
点击添加图片描述(最多60个字) 编辑
先定义 MVD(最小可用字段集):把“本周交付”变得可执行
- 电商(MVD):sku_id title price stock_status source_url crawl_time
- 门店(MVD):place_id(或唯一键) name address phone category source_url crawl_time
- 社媒内容(MVD):post_id account publish_time caption engagement(至少一项) source_url crawl_time
- 公司/岗位(MVD):company_name industry size_range job_title job_url source_url crawl_time
MVD 的意义:先交付“能用”的第一版数据,再迭代补字段与质量;否则你会在字段膨胀里拖垮交付期。
交付闭环最低标准:什么叫“可用数据集”(不是抓到页面就算)
无论你用 Coreclaw、自建还是外包,建议用同一套验收口径。
最低交付清单(5 件事缺一不可)
- 可追溯:每条记录至少包含 source_url + crawl_time,最好再有 batch_id/run_id。
- 可去重:有明确唯一键策略(例如 platform+id、或 site+sku_id),能统计重复率。
- 可复核:每批抽样核对页面(建议 20–50 条),确认解析没跑偏。
- 可复跑:能定时运行;失败有重试退避;能看到成功率与错误分布。
- 可交付:有字段字典(字段名/类型/是否必填/示例),CSV/JSON 格式规范或入库表结构清晰。
推荐的“达到即交付”阈值(PoC 可用)
- 成功率:≥ 90%(样本 200–500 页下)
- 必填字段完整率:≥ 95%(例如 id/price/source_url/crawl_time)
- 重复率:≤ 1–3%(按你的唯一键定义;关键是可解释、可去重)
- 时效:从调度到落地的延迟满足业务(例如 2 小时内)
- 可追溯:每条都能回到来源页面与抓取批次
选 Coreclaw 时怎么做 PoC:3–7 天测出“能不能用、值不值”
PoC 只回答三件事:跑得通(成功率)、交得出(字段与验收)、用得起(单位成本)。
第一步:样本怎么选(决定结论是否可信)
- 选“真实会出问题的页面”,而不是最好抓的一批:热门/冷门、不同类目/地区、评论多/少。
- 同时覆盖列表页与详情页(如果你的字段依赖详情)。
- 样本量建议:
- 50–100 页:确认字段与解析正确;
- 200–500 页:测稳定性、失败类型与成本。
第二步:怎么跑(别用并发把自己送进风控)
- 从保守频率开始,逐步爬坡;每次爬坡都看成功率是否“断崖”。
- 一旦验证码/403/429 占比上升,先降速并记录触发阈值,不要硬顶。
- 最少记录这些字段,方便复盘:batch_id url status error_type(验证码/403/429/超时/解析失败) duration。
第三步:怎么验收(用数据说话,不用感觉)
按前文阈值出一张表即可:成功率、字段完整率、重复率、时效、可追溯。
第四步:怎么算钱(看“有效数据成本”,不是看抓了多少页)
- 有效条数 = 总条数 × 成功率 × 通过质量校验比例
- 有效单位成本 = 总费用 / 有效条数
你要避免的误判是:表面单价不贵,但成功率/字段完整率一掉,“有效单位成本”反而翻倍。
什么时候该扩量?什么时候该止损?
- 扩量信号:成功率与必填字段完整率达到阈值;错误类型可解释且能通过限速/重试稳定;交付形态满足(CSV/入库/推送)。
- 止损信号(满足任一条,建议换路):
1) 验证码/403/登录失效导致成功率长期 < 90%,且保守频率也稳不住; 2) 页面结构改动频繁导致解析反复失效,无法通过配置快速恢复; 3) 业务要求本质是“深交互 + 强清洗 + 深度系统集成”,平台的模板能力覆盖不到。
什么时候该自建(Playwright/Python)或定制:别把“可控性”说空
自建/定制值得做的前提是:你愿意为可控性付出持续工程成本,并且你确实需要它。
自建更合适的 4 类需求
- 强会话/强登录风控:需要精细化会话管理与状态控制(同时要确认授权与合规)。
- 强交互状态机:地图拖拽、多步筛选、复杂弹窗链路,结果集高度依赖交互路径。
- 强业务规则清洗:多源关联、复杂去重、强校验与回溯(要能解释每条数据的证据链)。
- 强系统集成:必须与内部权限/审计/任务系统深度打通,增量一致性要求高。
自建最常被低估的成本(决定你是否“养得起”)
- 反爬带来的 5–20% 偶发失败治理(最耗时间);
- 解析规则的 变更检测与快速回滚;
- 代理/账号/网络质量的持续成本;
- 没有可观测性(错误分类、成功率趋势、字段缺失率)就无法稳定运维。
如果你的团队只有一位“能写点脚本”的工程师,又要一周交付,更现实的顺序通常是:先用 Coreclaw 交付第一版可用数据集,再评估是否把它工程化迁移到自建。
稳定性与反爬:不教对抗,只给上线必备的排查清单
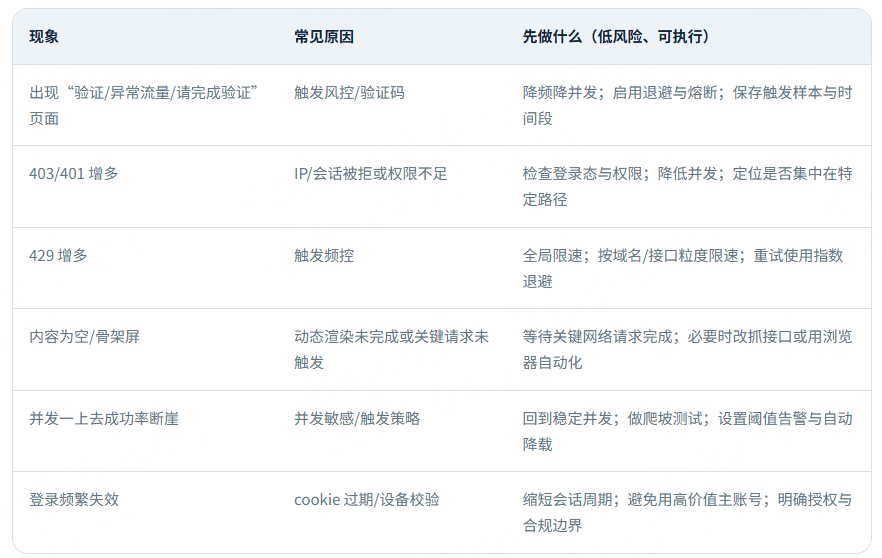
点击添加图片描述(最多60个字) 编辑
最低配置(平台/自建都建议具备):限速并发、重试退避+熔断、错误分类、成功率/缺失率/时长监控、阈值告警。
合规与风险边界:哪些属于红线,怎么做上线前自检
涉及个人信息、敏感数据、受访问控制保护的数据时,本文不构成合规意见;你需要在上线前完成内部合规评估与最小化采集。
高风险红线(默认不做;要做必须评估)
- 个人信息与敏感信息:联系方式、精确位置、账户标识等;以及可能用于画像/歧视性决策的数据。
- 访问控制内容:账号权限/付费墙/非公开数据;更不能以绕过授权方式获取。
- 营销触达型线索采集:批量抓取个人信息用于外呼/邮件等,风险显著更高。
- 明确违反站点条款/robots 的采集方式或用途:技术可行不等于可用。
上线前自检清单(建议按“必须/建议”执行)
必须
- 是否核对站点条款与 robots,对“访问方式+用途”都能解释?
- 是否涉及个人信息/敏感信息?是否有合法依据与最小化字段?
- 用途是否明确,是否避免二次用途扩张?
- 留存周期是否定义,是否具备删除/纠错机制?
- 访问控制与审计:谁能看、谁能导出、是否记录操作日志?
建议
- 先交付 MVD,字段能少就少;
- 明确对外共享边界,必要时做脱敏/聚合;
- 账号与凭证集中管理,避免个人账号参与自动化。
总结:把“适合哪些场景”落到可执行决策
- 你要的是本周可交付、可复跑、可追溯的数据,且任务形态足够标准(常见平台+标准字段+列表→详情):先用 Coreclaw 现成 Worker 跑通最小闭环,用成功率/字段完整率/有效单位成本把方案验收掉,再谈扩量。
- 你一开始就遇到强登录风控、强交互状态机、频繁结构变动、或必须深度系统集成:别把平台当万能钥匙,直接把路线转到自建(Playwright/Python)或定制开发,并把可观测性与长期维护成本写进计划。
- 内部没人维护且是一次性项目:可以外包,但交付物必须包含:字段字典、验收指标、可复跑能力、监控告警与可移交方案。
真正的分水岭不是“能不能抓到”,而是:你能不能交付一份用得了、跑得久、出了问题能定位的数据集。Coreclaw 的适用场景,本质上就是那些“需要快速把交付闭环跑通”的抓取任务。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)