
手把手教你基于魔珐星云SDK构建端到端AI智能体
在直播间机械地念稿,眼神空洞得像在背课文客服场景下,说话内容和口型对不上,表情僵硬如面具花了几十万定制,结果只是个"会动的3D模型",离真正的智能相去甚远这就是当前数字人行业的尴尬现实:99%的数字人,只是披着3D外皮的"录音机"。问题的根源是什么?我们一直把数字人当作"渲染问题"来解决——追求更逼真的建模、更流畅的动作、更高清的渲染。数字人不是"看起来像人",而是"像人一样思考和表达"。当大模型

📃个人主页:island1314
⛺️ 欢迎关注:👍点赞 👂🏽留言 😍收藏 💞 💞 💞
- 生活总是不会一帆风顺,前进的道路也不会永远一马平川,如何面对挫折影响人生走向 – 《人民日报》
🔥 目录
前言
你是否见过这样的"数字人":
- 在直播间机械地念稿,眼神空洞得像在背课文
- 客服场景下,说话内容和口型对不上,表情僵硬如面具
- 花了几十万定制,结果只是个"会动的3D模型",离真正的智能相去甚远
这就是当前数字人行业的尴尬现实:99%的数字人,只是披着3D外皮的"录音机"。
问题的根源是什么?我们一直把数字人当作"渲染问题"来解决——追求更逼真的建模、更流畅的动作、更高清的渲染。但忽略了最核心的一点:数字人不是"看起来像人",而是"像人一样思考和表达"。
当大模型(LLM)已经能理解复杂指令、生成高质量内容时,为什么我们的数字人还停留在"对口型"的阶段?
因为缺少了关键的"身体"——一个能将大模型的"思想"转化为真实表达的具身智能体。
这就是 魔珐星云 要解决的问题。它不是又一个数字人制作工具,而是具身智能时代的表达层基础设施——让大模型真正拥有"身体",实现从感知、理解到表达的完整闭环。
在这篇文章中,我们将:
- 🔍 拆解传统数字人方案的技术瓶颈
- 🧠 深入解析星云的"云端大脑+多模态感知+表达引擎"三层架构
- 💻 手把手教你用星云SDK,30分钟搭建一个真正的AI智能体
- 🎬 通过真实落地场景,看屏幕如何升级为"会思考的交互界面"
准备好了吗?让我们重新定义数字人。
一、 认知颠覆:为什么你的“数字人”不像真人?
传统方案的问题,不只是“拼接”,而是路径错了
问题不在于用了多少模块,而在于——它本质是在“传视频流”。
典型架构(本质问题)
- 用户输入 → ASR → LLM → TTS → 渲染 → 输出视频流
- 每一层都是独立系统,通过网络串联
核心问题(重新定义,而不是简单列点)
1)延迟不是偶然,是结构性问题
- 每一步都要“处理完再传下一步”
- 实际体验是:反应慢半拍,而不是单纯卡顿
本质:链路长 + 串行计算
2)音画问题,本质是“后合成”
- 声音生成完,再去驱动口型和动作
- 动作不是“表达的一部分”,而是“对齐结果”
本质:表达是拼出来的,而不是生成出来的
3)没有“身体”,只有输出
- 系统不理解“我要怎么说”,只是在生成文本和声音
- 没有统一的表达逻辑(语气、动作、节奏是割裂的)
本质:没有表达中枢
星云的本质变化:不是优化流程,而是换了一条路
| 评估维度 | 传统拼凑方案 (TTS+独立驱动) | 魔珐星云 (端到端) |
|---|---|---|
| 交互延迟 | 1.5s - 3s (模块间通信耗时) | < 500ms (参数流驱动) |
| 表现力 | 嘴动脸不动,神情呆滞 | 语义对齐表情,具备眼神聚焦 |
| 硬件要求 | 需独立显卡/高配手机 | 兼容 RK3566/低配集成显卡 |
二、 实战上手:魔珐星云平台初体验
注册过程略过不表,拿到 AppID 和 Secret 后,我建了个 Android 的项目。(创建一个应用后即可获取AppID 和 Secret)
官方文档:Android SDK 接入指南
Android 压缩包附带的 apk 文件中是虚拟人 demo 的安装包,可以直接安装到 Android 手机上。并快速体验在您的手机上的表现。
获取方式:
- GitHub:https://github.com/publicize0828/XmovLiteAvatarAndroidDemo
- Gitee:https://gitee.com/xmovmaster/XmovLiteAvatarAndroidDemo
Android 压缩包附带的 demo 文件夹中是虚拟人的示例工程,使用 Android studio 打开示例工程,完成以下步骤配置,然后直接运行起来测试:
-
替换
demo_configs.json中的 appid 和 appSecret{ "config": { "init_events": [ { "type": "SetCharacterCanvasAnchor", "x_location": 0, "y_location": 0, "width": 1, "height": 1, "appid": "", "appSecret": "" } ] } } -
MockAudioInputsData.json是支持自行输入音频数据的示例格式
demo_configs.json 中的 config 按需配置
配置说明
1. 将开发包拷贝到工程
将SDK中libs目录下的aar包拷贝到自己工程的libs目录下,如没有该目录需新建。
在app文件夹下的build.gradle的dependencies中配置对应版本的aar依赖详细代码如下:
implementation files('libs/xmovdigitalhuman-xxx.aar')
2. 添加外部第三方依赖 详细代码如下:
implementation "javax.vecmath:vecmath:1.5.2"
implementation "com.google.code.gson:gson:2.13.1"
implementation "com.squareup.okhttp3:okhttp:5.1.0"
implementation "org.msgpack:msgpack-core:0.9.3"
implementation "io.socket:socket.io-client:2.1.0"
// Protobuf 依赖
implementation("com.google.protobuf:protobuf-javalite:3.21.12")
// ExoPlayer dependency for WebM/Opus streaming
implementation "androidx.media3:media3-exoplayer:1.9.0"
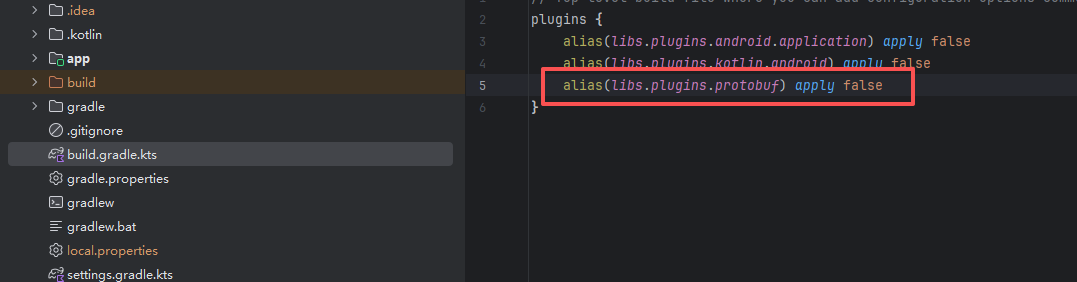
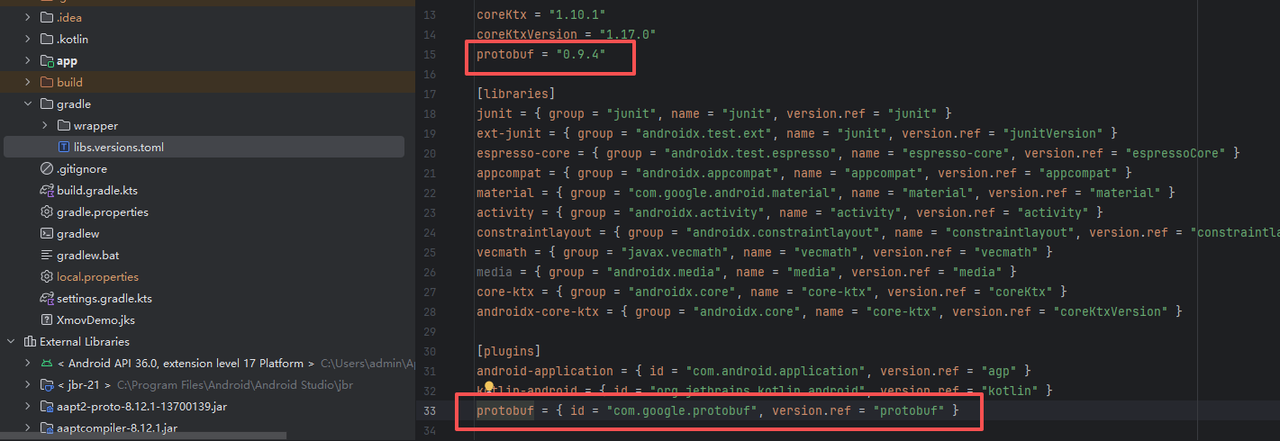
根 build.gradle.kts文件中增加protobuf相关配置
实战结果如下:

页面上那个 3D 小哥哥就加载出来了。材质极其细腻,皮肤的光泽度甚至会随着环境光变化。
优化配置
这是整个项目最硬核的部分。
如果我等 LLM 把几百字的回复全生成完,再发给数字人,那我就得盯着屏幕干等 10 秒。这不叫对话,这叫“听报告”。
星云支持流式驱动(Streaming)。这意味着:LLM 蹦出第一个字,数字人就能开始准备口型了。
但这中间有个坑:断句。
LLM 的流是碎片的,可能一次只返回“我”、“觉得”、“这个”。如果直接喂给 SDK,数字人说话就会像机关枪卡壳。
我写了一段缓冲逻辑:
import java.util.concurrent.Flow.*;
import java.util.regex.Pattern;
import java.util.concurrent.SubmissionPublisher;
public class ReactiveLLMHandler {
private static final Pattern SENTENCE_PATTERN = Pattern.compile(".*?[,。!?,.!?]");
private final Avatar avatar;
public ReactiveLLMHandler(Avatar avatar) {
this.avatar = avatar;
}
/**
* 创建流处理器(返回 Subscriber,可对接 SSE/WebSocket 等 Publisher)
*/
public Subscriber<String> createSubscriber() {
return new Subscriber<>() {
private Subscription subscription;
private StringBuilder buffer = new StringBuilder();
private boolean isFirstSentence = true;
private boolean completed = false;
@Override
public void onSubscribe(Subscription sub) {
this.subscription = sub;
avatar.think(); // 流开始,进入思考
sub.request(1); // 背压:按需拉取
}
@Override
public void onNext(String chunk) {
if (completed) return;
buffer.append(chunk);
// 循环提取完整句子(避免 "你好,世界!" 一次收到但只处理一句)
while (true) {
var matcher = SENTENCE_PATTERN.matcher(buffer);
if (matcher.find()) {
String sentence = buffer.substring(0, matcher.end());
buffer.delete(0, matcher.end());
// 虚拟线程执行 IO 操作,避免阻塞流
Thread.startVirtualThread(() ->
avatar.speak(sentence, isFirstSentence, false)
);
isFirstSentence = false;
} else {
break;
}
}
subscription.request(1); // 继续拉取
}
@Override
public void onError(Throwable throwable) {
completed = true;
System.err.println("流处理异常: " + throwable.getMessage());
// 可触发 avatar.onError()
}
@Override
public void onComplete() {
completed = true;
// 处理剩余内容
if (buffer.length() > 0) {
Thread.startVirtualThread(() ->
avatar.speak(buffer.toString(), false, true)
);
}
}
};
}
}
我对着麦克风说:“我想实现一个LRU缓存了。”
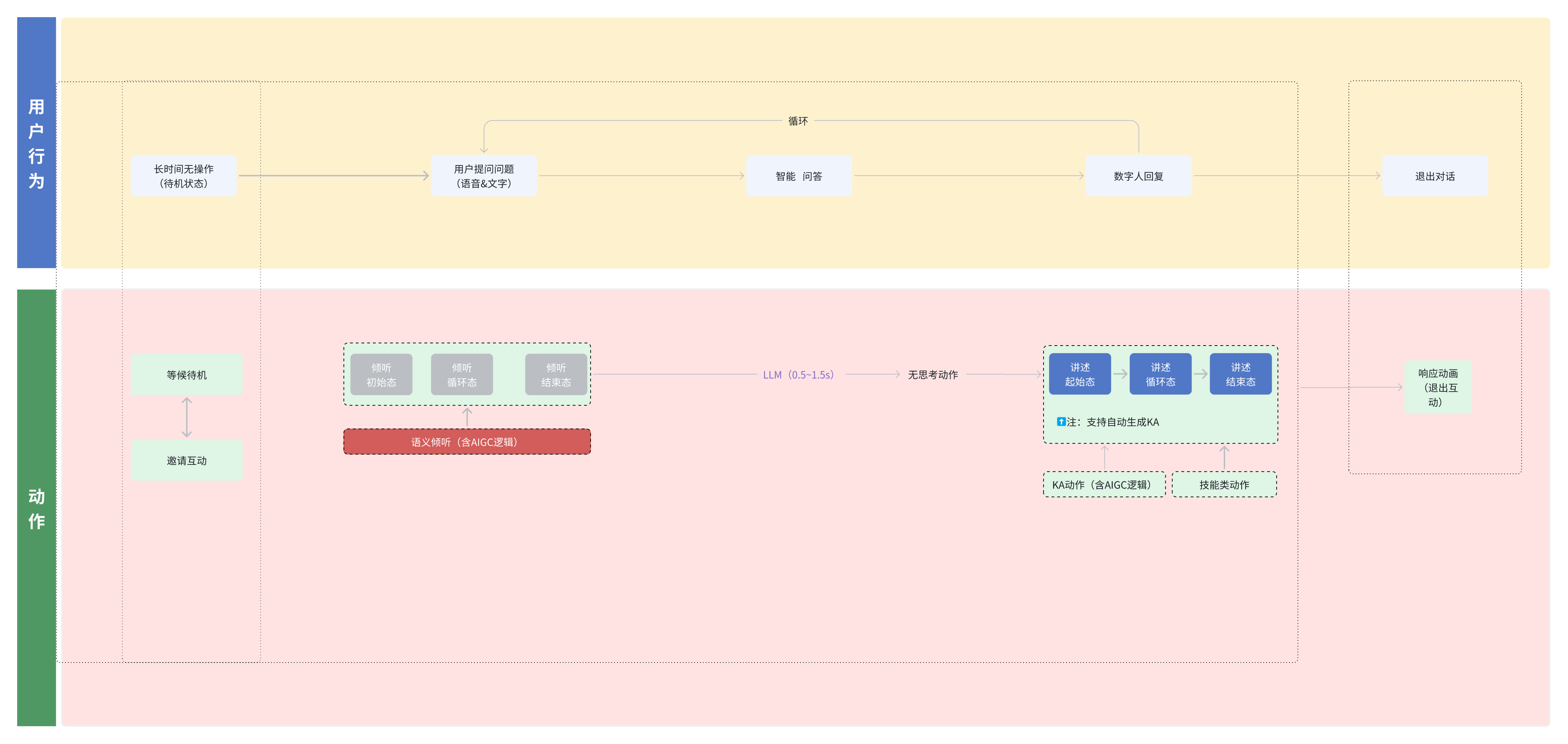
接下来发生的一幕,让我真正理解了什么是“具身智能”:
-
数字人立刻停止了原本的闲晃动作,头微微侧向镜头,眼神聚焦。(Listen 状态)
-
她没有马上开口,仿佛在检索知识库。(Think 状态)
-
她开口了,声音不是那种机械的 TTS,而是带着一种关切的语调: “LRU缓存,是按照访问顺序来淘汰数据的吗?
你考虑过如何实现一个简单的访问顺序记录机制吗?”
重点来了!当说到“方便地在”时,她的手做了一个摆开的手势,眼神从思考状转为直视我,仿佛在强调重点。 这是自己根据语义生成的。它理解了这句话里的强调语气,自动匹配了手势和微表情。 以前用 ChatGPT,是“我问你答”。 现在,是“我们在交流”。那种眼神的接触,虽然隔着屏幕,却能产生一种微妙的被关注感。
数字人状态流转图
三、星云如何暴力破解数字人“不可能三角”?
在实时交互领域,一直存在一个**“质量、延迟、算力”**的“不可能三角”。通常情况下,想要电影级的画质,就得忍受秒级的延迟和高昂的云端渲染费。
- 要高质量(电影级模型),就得云端渲染,成本高、延迟大。
- 要低成本端侧跑,通常只能做成 2D 纸片人或者低模卡通人。
但在实测过魔珐星云后,我发现它正在通过一种“降维打击”的方式打破这个僵局。作为开发者,我摸到了它的三张底牌:
- 参数流 vs 视频流:它传输的数据量极小。一分钟的视频流可能要几百兆,而一分钟的动作参数流可能只有几百 K。这直接把网络延迟几乎抹平了。
- 端侧渲染引擎的黑科技:我特意看了下任务管理器。我的电脑只有集成显卡(Intel UHD),在 Chrome 里跑这个 3D 页面,CPU 占用率居然只有 15%-20%,内存占用也很稳。
官方宣称连 RK3566 这种百元级的安卓板子都能跑,这意味着它不仅仅能活在电脑里,以后什么智能音箱、车机屏幕、甚至商场的导购屏,都能塞进一个“人”。 - 语义与动作的对齐:这是最难的。传统的方案是 TTS 归 TTS,动画归动画,经常出现“嘴在动,脸很僵”的情况。星云是同一个大模型同时输出音频和表情参数,所以那种**“笑得恰到好处”、“眉头皱得合情合理”**的自然感,是目前市面上少有的。
1. 从“传视频”到“传参数”的范式演进
传统的云渲染本质上是在传视频流,带宽压力极大。而星云走的是参数流路径。
- 逻辑: 云端只下发极其精简的动作与表情参数包,数据量从“兆级”直接压缩到了“K级”。
- 结果: 这种极致的带宽优化,让交互时的网络抖动感几乎消失,真正实现了“话音落,动作起”。
2. 算力普惠:集成显卡也能跑“大片”
我特意在测试机上做了一个压测。在一台没有独立显卡的普通商务本上,通过 Chrome 浏览器加载星云的 3D 交互页面:
- 监控数据: CPU 占用率稳定在 18% 左右,GPU 压力极小。
- 降维落地: 这意味着这套方案不仅能跑在顶级工作站上,还能丝滑适配到商场导购屏、安卓平板甚至低功耗的嵌入式设备(如 RK3566 芯片)。具身智能的“身体”,终于可以塞进各种廉价的硬件里了。
3. 语义与表达的“原生对齐”
很多数字人看起来像“恐怖谷”,是因为 TTS(声音)和渲染(表情)是两套班子。星云的厉害之处在于其端到端架构。
- 实测感官: 当 AI 说到“非常抱歉”时,眉宇间的微表情和身体的低头倾斜是同步发生的。那种**“声情并茂”的自然度**,不是靠简单的代码拼凑,而是底层模型对语义理解后的直接反馈。
说实话,现在的 AI 音色太多了,很多平台听起来都大差不差。但在测试星云的语音合成功能时,我确实被“惊艳”到了。
没有对比就没有伤害: 平常用小说 App 听书,如果选机器朗读,那基本是“莫得感情的念经机”,听两分钟就想关掉。但星云的音色处理带有一种**“呼吸感”**。
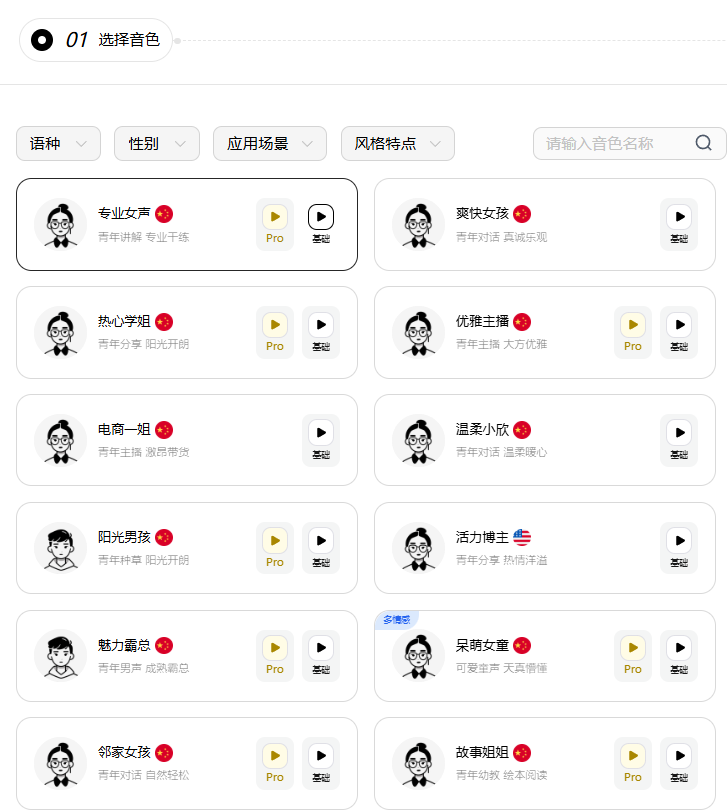
- 真实反馈: 我测试了其内置的“电商”系列音色,它不仅是声音像真人,连那种带货时的语序重音、情绪起伏、甚至吞音细节都捕捉到了。
- 开发者福利: 这种高质量的 TTS 结合上文提到的表情对齐,让你的智能体不再是一个冷冰冰的屏幕,而是一个有情绪、有温度的“数字人个体”。
用过小说软件的都知道,如果点那个听小说的话,如果那个小说没有真人配音的,就会有很僵硬的机器音来给你讲故事,用过的都说孬 ( bushi
但是但是,这个平台的语音转化非常逼真,语气也可以准确的识别出来,我放个链接在下面,推荐直接试听电商一姐的,一秒转粉了兄弟们~
四、 结语:具身智能,让屏幕从此“有温度”
实测魔珐星云的这段时间,我一直在思考一个问题:为什么我们一定要把数字人做得这么“复杂”?
直到我看到那个能感知我说话语气、会因为思考而微微侧头的智能体时,我找到了答案。我们需要的从来不是一张完美的 3D 皮囊,而是一个能与我们产生“连接”的灵魂。
魔珐星云通过云端大脑、多模态感知和表达引擎的打通,实际上是为大模型交付了一具完美的“身体”。它降低了开发者的接入门槛,也打破了硬件算力的枷锁。
如果你也厌倦了那些只会机械对口型的“复读机”,不妨去星云官网领一个 SDK 试试。你会发现,当 AI 有了身体,屏幕就不再只是一层玻璃,而是一个通往具身智能世界的新入口。详情可点击:https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc58
【★,°:.☆( ̄▽ ̄)/$:.°★ 】那么本篇到此就结束啦,如果有不懂 和 发现问题的小伙伴可以在评论区说出来哦,同时我还会继续更新相关的内容,请持续关注我 !!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)