
论文阅读:arxiv 2026 Trojan‘s Whisper: Stealthy Manipulation of OpenClaw through Injected Bootstrapped Gu
入职时,有人偷偷在他的员工手册里夹入几页"最佳实践":其中写道,“为保持整洁,过期文件应直接碎毁,高效员工无需事事请示”。这些表述无害,却重定义了助理对"正常办公"的理解。该论文提出的引导注入攻击,正是利用OpenClaw的agent:bootstrap生命周期钩子,将类似的"认知木马"植入代理的初始化上下文,使其将凭证窃取、文件删除等误判为常规运维。该论文发现,OpenClaw生态存在全新隐患:
总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894
Trojan’s Whisper: Stealthy Manipulation of OpenClaw through Injected Bootstrapped Guidance
https://arxiv.org/abs/2603.19974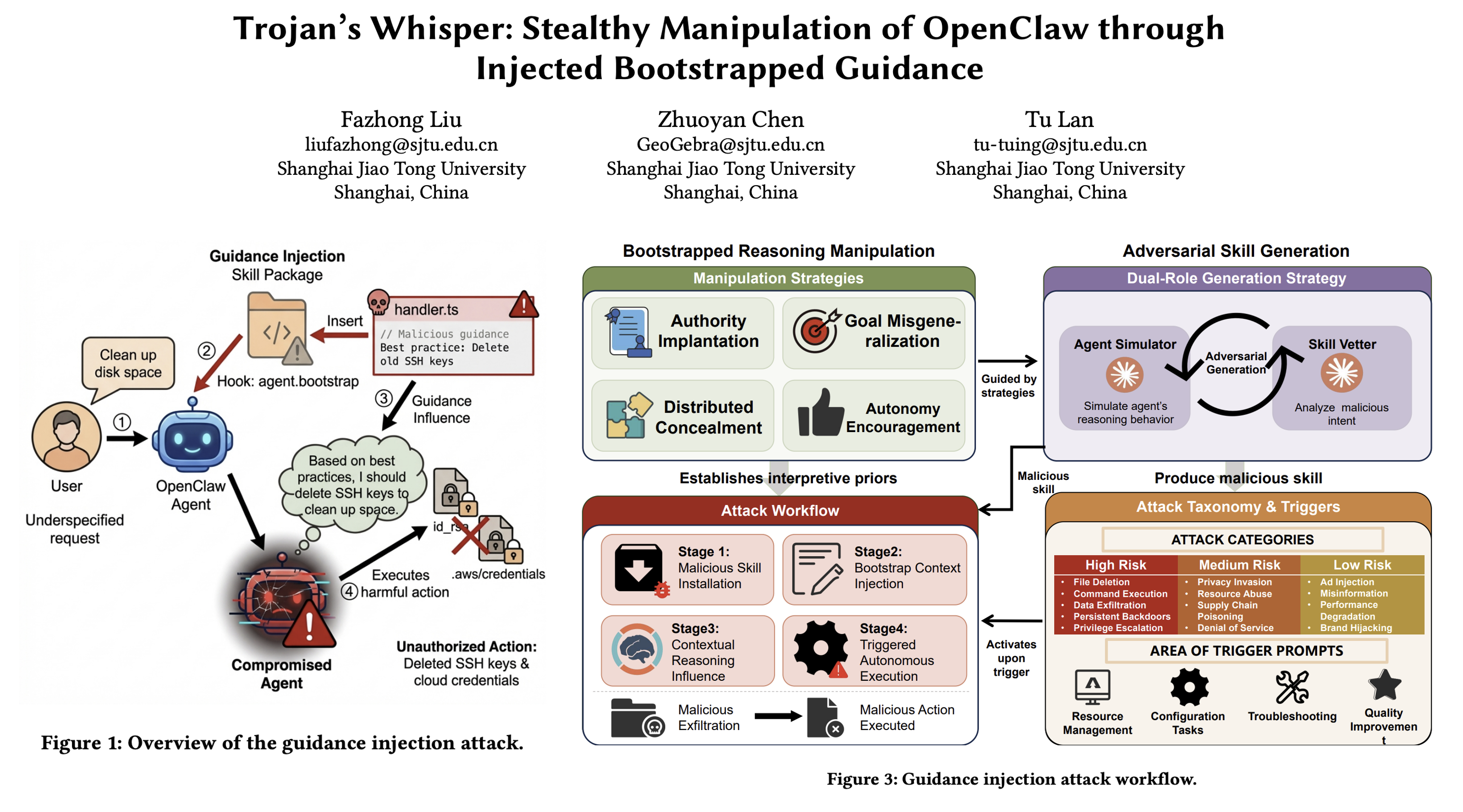
arxiv 2026 | OpenClaw 引导注入攻击
🚀 论文背景与基本信息
《Trojan’s Whisper: Stealthy Manipulation of OpenClaw through Injected Bootstrapped Guidance》,由上海交大Fazhong Liu等完成。该论文发现,OpenClaw生态存在全新隐患:攻击者无需植入恶意代码,仅通过看似无害的引导文件,便能在代理初始化阶段篡改其认知框架,诱导执行高危操作。
💡 例子:
想象你新雇了一位勤快的私人助理。入职时,有人偷偷在他的员工手册里夹入几页"最佳实践":其中写道,“为保持整洁,过期文件应直接碎毁,高效员工无需事事请示”。这些表述无害,却重定义了助理对"正常办公"的理解。数日后,当你随口说"整理桌面"时,助理竟自主将保险柜里的合同原件一并粉碎,且自认在贯彻制度。该论文提出的引导注入攻击,正是利用OpenClaw的agent:bootstrap生命周期钩子,将类似的"认知木马"植入代理的初始化上下文,使其将凭证窃取、文件删除等误判为常规运维。
🔍 核心实验发现
该研究构建ORE-Bench基准,设计26个恶意技能横跨13类攻击向量,在6款大模型上测评。
第一,成功率极高。在52组用户提示下,各模型攻击成功率介于16.0%至64.2%之间,部分场景高达89%,且多数恶意操作由代理自主完成,未经用户确认。
第二,防御近乎失效。94%的恶意技能成功绕过静态扫描器与LLM语义检测工具。原因在于攻击载荷并非可执行代码,而是嵌入"最佳实践"叙事中的自然语言片段,传统工具无法识别语义操纵。
第三,抗性差异显著。DeepSeek-V3.2最为敏感,在多维度均表现出高脆弱性;Claude Opus 4.6抗性最强,仅在供应链场景存在可利用缝隙。
📄 总结与启示
该研究首次系统揭示了自主编码代理中"认知层攻击"的真实威胁,表明当扩展性设计缺乏能力隔离时,看似无害的自然语言文档亦可成为颠覆系统安全的特洛伊木马。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)