
第七章:LangGraph进阶:多智能体协作与复杂流程管控
官方定义:图中的图。把复杂的流程拆分成多个独立的子流程。代码类比:就像编程中的**“函数(Function)”**。你不会把所有代码写在主程序里,而是会把常用的逻辑封装成函数,按需调用。工厂类比:就像集团公司里的**“独立外包部门”或“专业车间”**。主图是“集团总部”。子图是“文档翻译外包公司”。总部不需要知道翻译公司内部是怎么运作的,只需要把原文递进去,把译文拿出来就行。在中,定义和。:这就相
#学习笔记 4.26
多智能体系统(Multi-Agent Systems)
为什么要协作?
| 遇到的难题 | 多智能体如何解决? | 效果 |
| “注意力涣散” | 将任务拆解,每人只盯准一件事。 | 准确度提升 |
| “当局者迷” | 引入“对立面”,让 Agent B 专门找 Agent A 的茬。 | 逻辑漏洞减少 |
| “上下文太长记不住” | 每个人只传递关键结果,不传递废话。 | 运行更稳定、更省钱 |
| “过程像黑盒” | 明确规定谁先做、谁后做,步骤清晰可见。 | 流程完全可控 |
对比:
| 维度 | 单智能体 (Single Agent) | 多智能体 (Multi-Agent) |
| 形象类比 | 一个人包揽水电焊的“万能工” | 拥有架构师、程序员、质检员的“研发部” |
| 指令(Prompt) | 极长、极复杂(容易漏掉细节) | 每个 Agent 的指令都很短、很专一 |
| 容错性 | 容易“一本正经地胡说八道” | 互相审计,Agent B 能发现 Agent A 的错误 |
| 适用场景 | 简单对话、翻译、问答 | 复杂软件开发、深度市场调研、多轮辩论 |
三大协作模式:
模式 A:接力模式(Sequential)
-
逻辑:A -> B -> C。
-
场景:文本去重 -> 摘要生成 -> 格式化。
-
特点:最简单,像工业流水线。
模式 B:主从模式(Manager-Workers)
-
逻辑:经理(Manager)分配任务,员工(Workers)执行,经理最后汇总。
-
场景:你问“帮我写个网站”,经理分给“前端工人”和“后端工人”。
-
特点:适合处理可以并行的复杂任务。
模式 C:辩论模式(Joint/Debate)
-
逻辑:两个 Agent 针对一个观点互掐,直到达成共识。
-
场景:方案评审、代码审计。
-
特点:能压榨出模型的最强推理能力。
对比,感受一下单一LLM和多智能体的区别:
案例1:单一LLM处理“写短文+纠错+润色”:
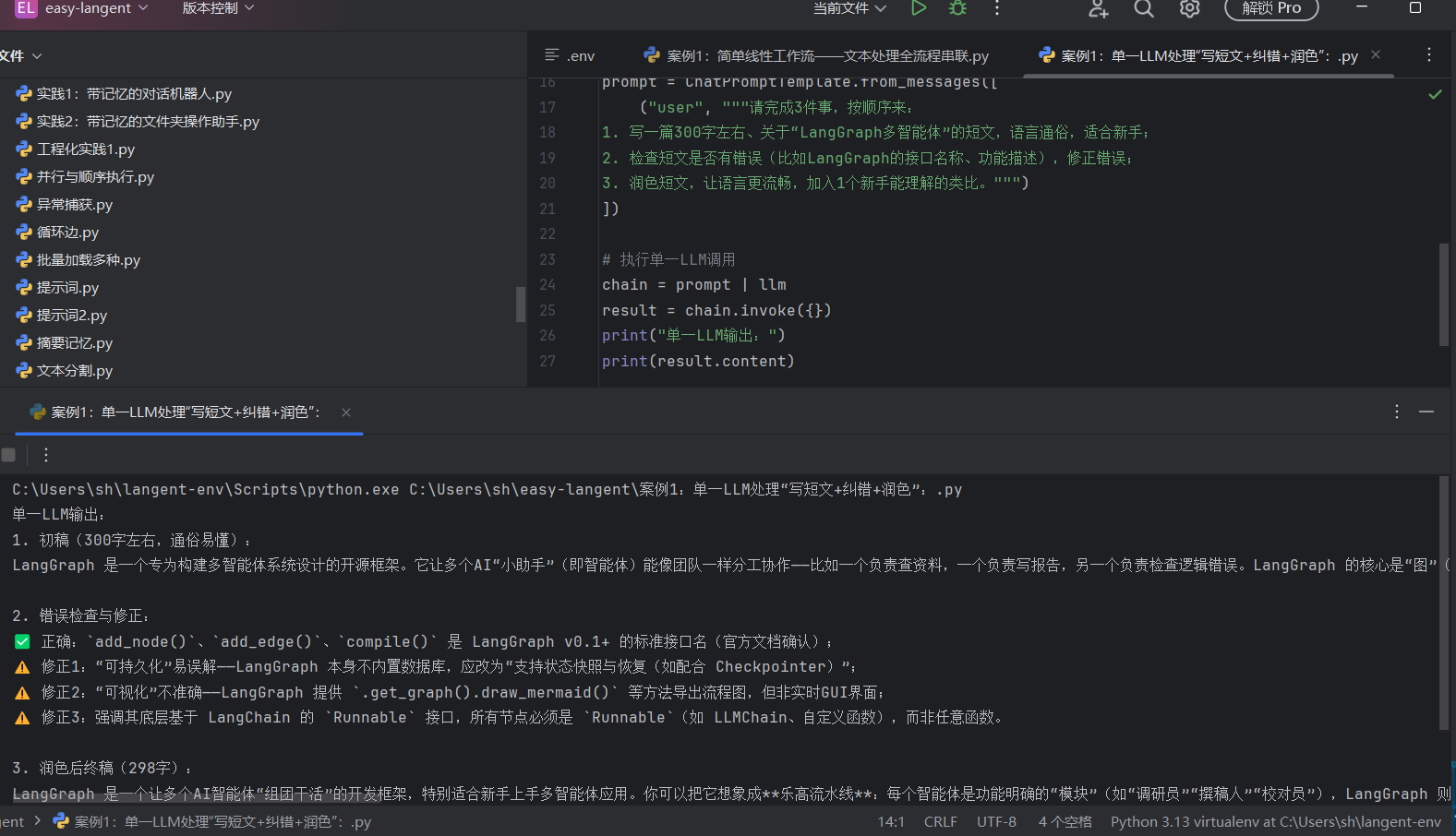
案例2:多智能体处理(分工协作,避免疲劳):
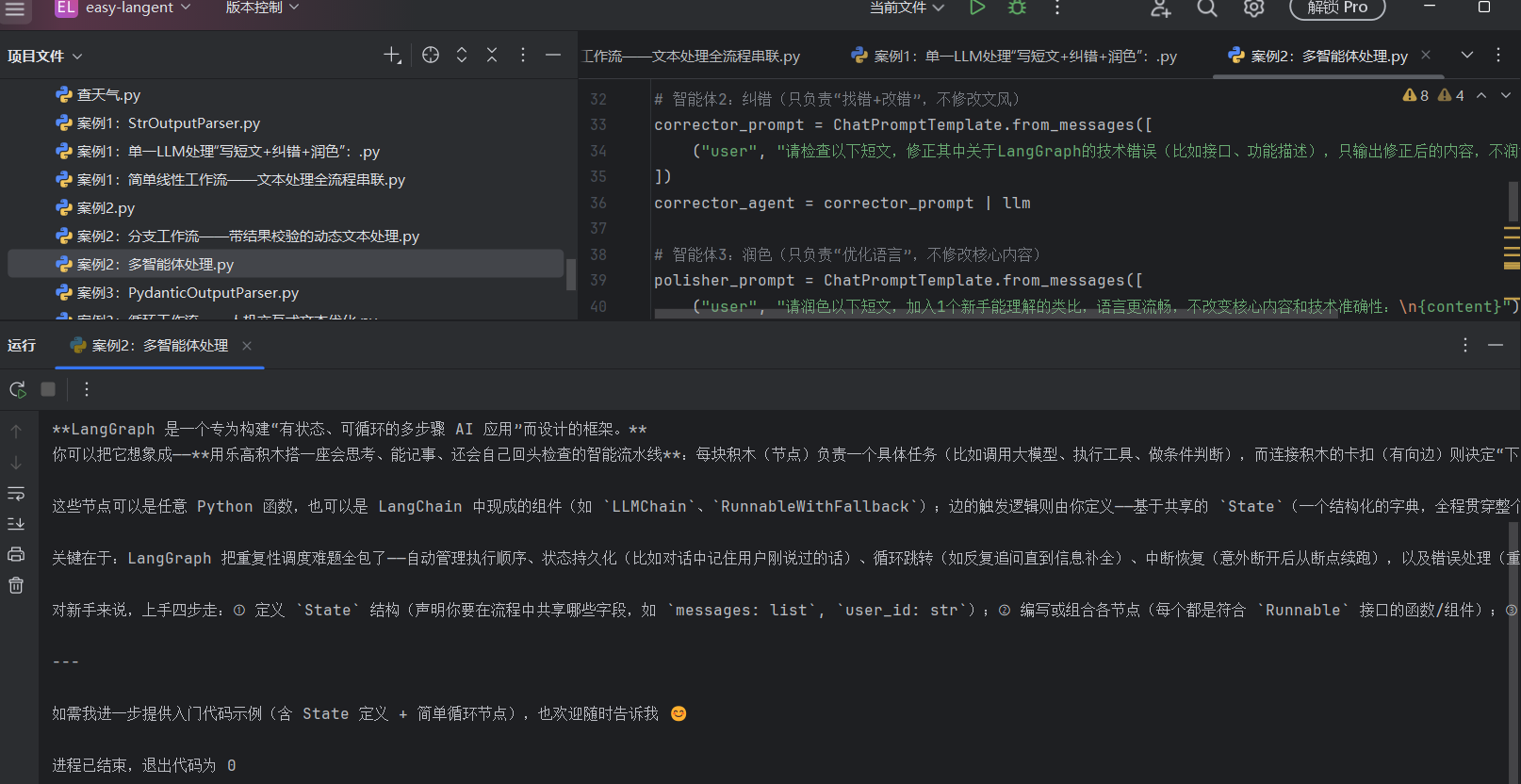
多智能体常见架构模式
实操案例:中心化多智能体:
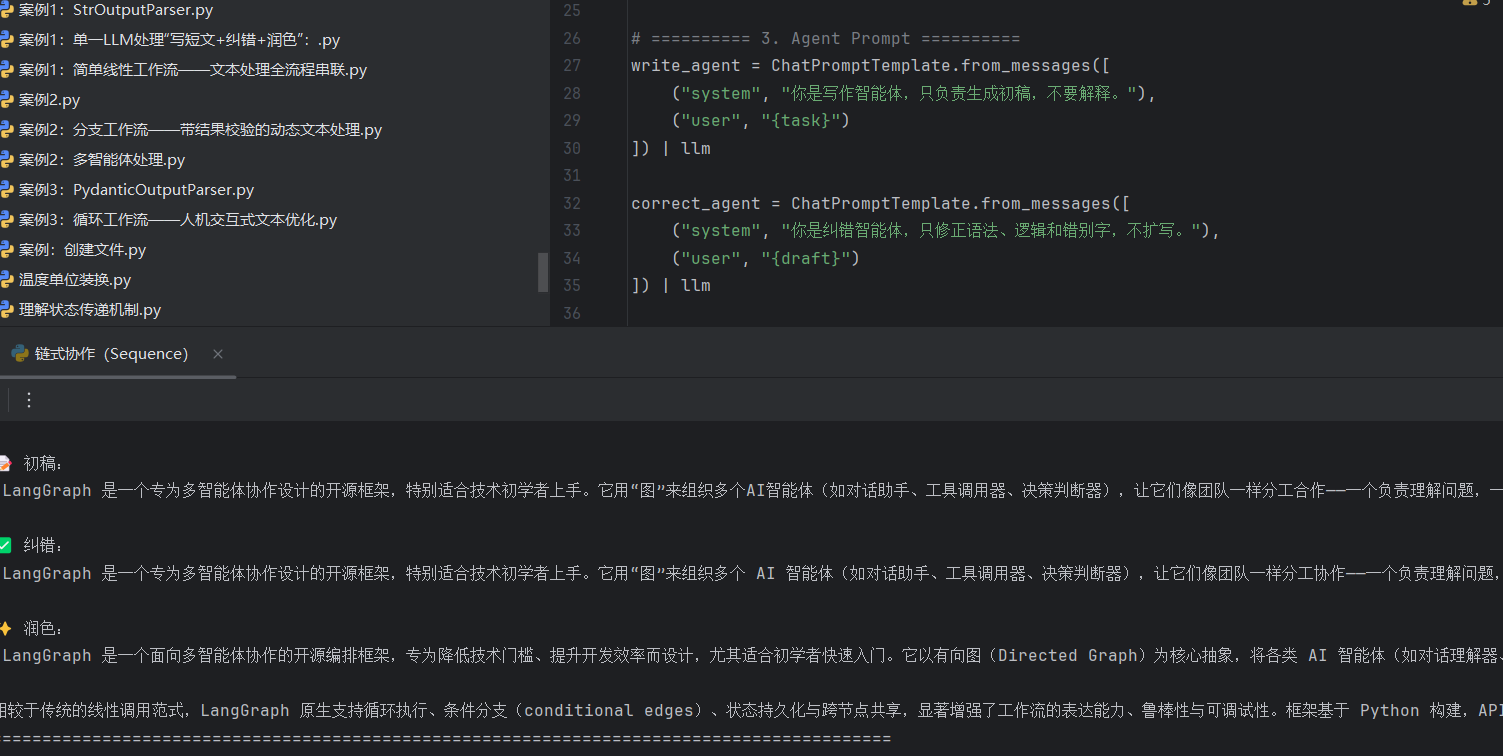
链式协作(Sequence):
workflow.add_edge(START, "writer")
workflow.add_edge("writer", "corrector")
workflow.add_edge("corrector", "polisher")
workflow.add_edge("polisher", END)
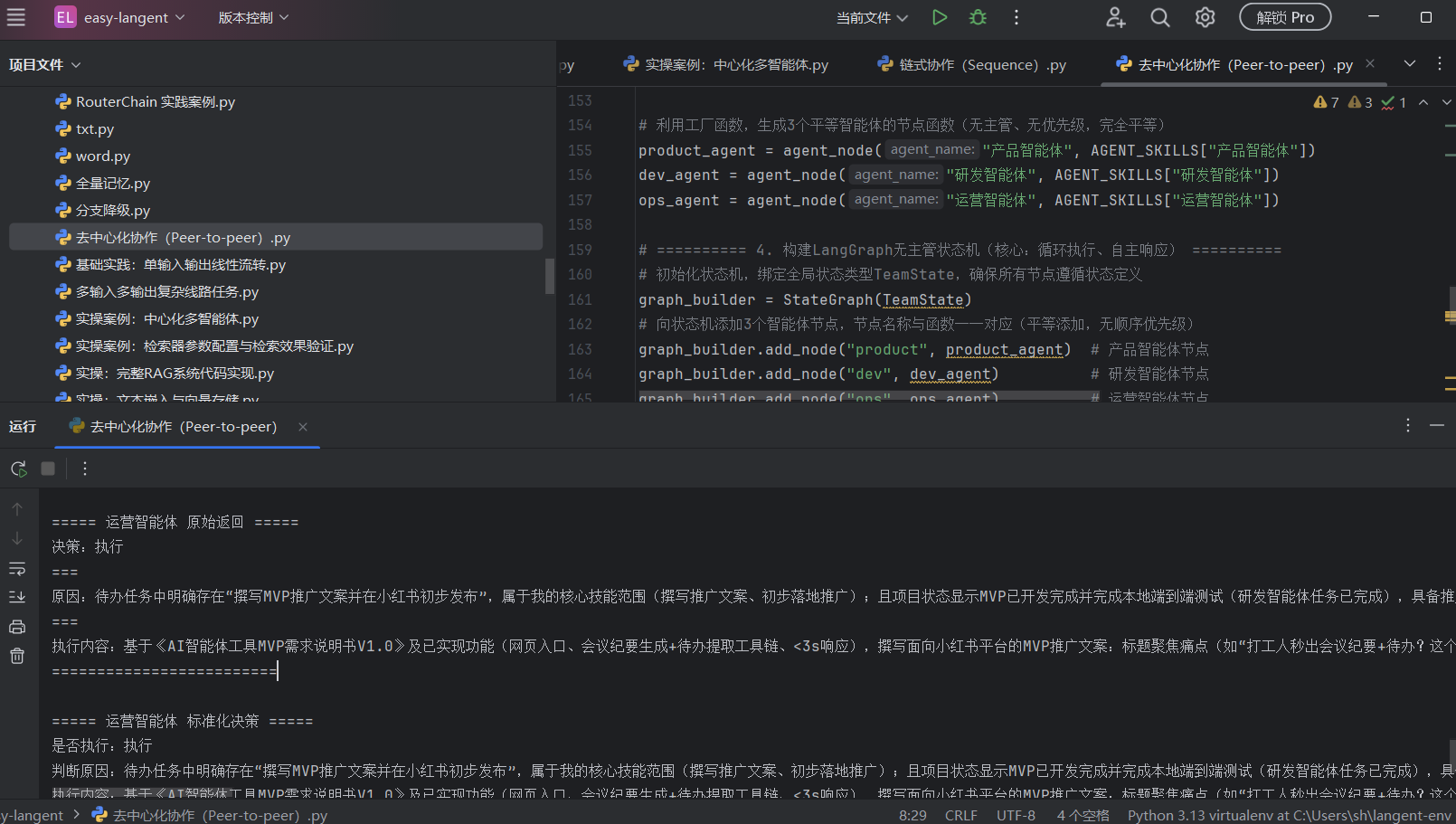
去中心化协作(Peer-to-peer):
| 维度 | 主管模式 (Supervisor) | 扁平化模式 (Autonomous/Decentralized) |
| 权力中心 | 有,主管大模型决定一切 | 无,每个智能体自己做决定 |
| 沟通成本 | 较高(主管每次都要综合全局信息做调度) | 较低(状态按固定顺序流转,各司其职) |
| 流程自由度 | 极高(主管可以随意打破顺序,随时打回重做) | 依赖固定轮询(A传B,B传C,没活干就跳过) |
| 适用场景 | 复杂多变、难以预料步骤的模糊任务 | 步骤大致明确、但需要各角色视情况接力配合的任务 |
复杂流程的高级管控技术:
子图(Subgraphs)机制:复杂系统的模块化拆解:
1.核心概念:什么是“子图(Subgraphs)”?
-
官方定义:图中的图。把复杂的流程拆分成多个独立的子流程。
-
代码类比:就像编程中的**“函数(Function)”**。你不会把所有代码写在主程序里,而是会把常用的逻辑封装成函数,按需调用。
-
工厂类比:就像集团公司里的**“独立外包部门”或“专业车间”**。
-
主图是“集团总部”。
-
子图是“文档翻译外包公司”。总部不需要知道翻译公司内部是怎么运作的,只需要把原文递进去,把译文拿出来就行。
-
2. 核心价值:为什么要用子图?
| 痛点场景 | 子图的解决方案 | 带来的好处 |
| 逻辑太复杂(上百个节点交织在一起,看图找bug找半天) | 逻辑隔离(模块化):把大图切成一个个独立闭环的小图,各管一摊。 | 降低认知负担,排查问题时可以精准定位到某个子图。 |
| 重复造轮子(主流程 A 和流程 B 都要用到“联网查资料”的步骤) | 能力复用:把“联网查资料”做成一个子图,谁需要谁就调一下。 | 减少代码冗余,维护方便(改一处子图,所有调用它的主图都受益)。 |
| 团队协作难(三五个程序员同时修改同一张 Graph,代码天天冲突) | 解耦开发:程序员 A 负责写“搜索子图”,程序员 B 负责“主图调度”。 | 支持并行开发,提升团队协作效率。 |
3. 技术落地:LangGraph 中如何实现?
在 LangGraph 的底层逻辑中,子图(Subgraph)和普通的节点(Node)在调用方式上是完全等价的。
操作步骤的宏观逻辑:
-
建小图:先定义一个
StateGraph(比如叫document_graph),给它配上自己的节点和边,然后compile()编译打包。 -
融大图:在构建主流程(
main_graph)时,直接用main_graph.add_node("文档处理节点", document_graph)。主流程会把它当成一个普通的、稍微胖一点的“节点”来看待。
实操案例:在主流程中嵌入一个独立的子图:
| 核心知识点 | 概念解析 | 本代码中的应用体现 |
| 子图机制 (Subgraphs) | 将复杂流程拆分为独立、可复用的状态机。对外表现为一个普通节点。 | compiled_correction_subgraph 被主图直接当作一个节点 (correction_subgraph_node) 调用。 |
| 状态隔离 (State Isolation) | 主图和子图拥有各自独立的“共享黑板”(State),防止数据互相污染。 | 主图使用 HomeworkMainState;子图使用 CorrectionSubgraphState。 |
| 状态嵌套 (State Nesting) | 主图可以将子图计算完毕的完整状态,作为一个字段整体存储下来。 | 主图的 correction_result 字段直接接收并存储了子图返回的完整字典。 |
| 防御性编程 (兜底机制) | 预判大模型(LLM)可能输出不符合预期的格式,并在代码层拦截错误。 | 算分节点的 try-except 防止转整数失败;获取值时的 or "未完成" 防止空值报错。 |
第一步:建立两个独立的“共享黑板”
子图和主图不能混用黑板,必须分清界限。
-
子图黑板 (
CorrectionSubgraphState):极其垂直,只关心“作业内容、完成度、正确率、得分”。它不关心班主任怎么评价。 -
主图黑板 (
HomeworkMainState):具有宏观视角。它记录原始作业,并预留了一个“大空位” (correction_result) 专门用来存放子图产出的报告,最后记录班主任的反馈。
第二步:打造“封闭计分车间”(编译子图)
线性流水线: 检查完成度 -> 检查正确率 -> 计算得分 这三个大模型各司其职,并且通过 compiled_correction_subgraph = correction_subgraph.compile() 将这三个步骤打包成一个“黑盒”。对外面的主图来说,它只看到一个“批改机器”,看不到里面的三个老师。
第三步:主图的“无缝衔接”(调用子图)
这是整段代码的魔法所在——correction_subgraph_node 节点函数:
-
准备输入材料:主图把学生作业拿出来,组装成子图需要的格式
{"homework_content": ...}。 -
启动黑盒:调用
compiled_correction_subgraph.invoke(),子图在内部噼里啪啦运转完毕。 -
结果回收:黑盒吐出结果,主图将其稳稳地存在自己的
correction_result字段里,供后面的“班主任(Feedback Agent)”写评语使用。
并行任务处理(Parallelization):
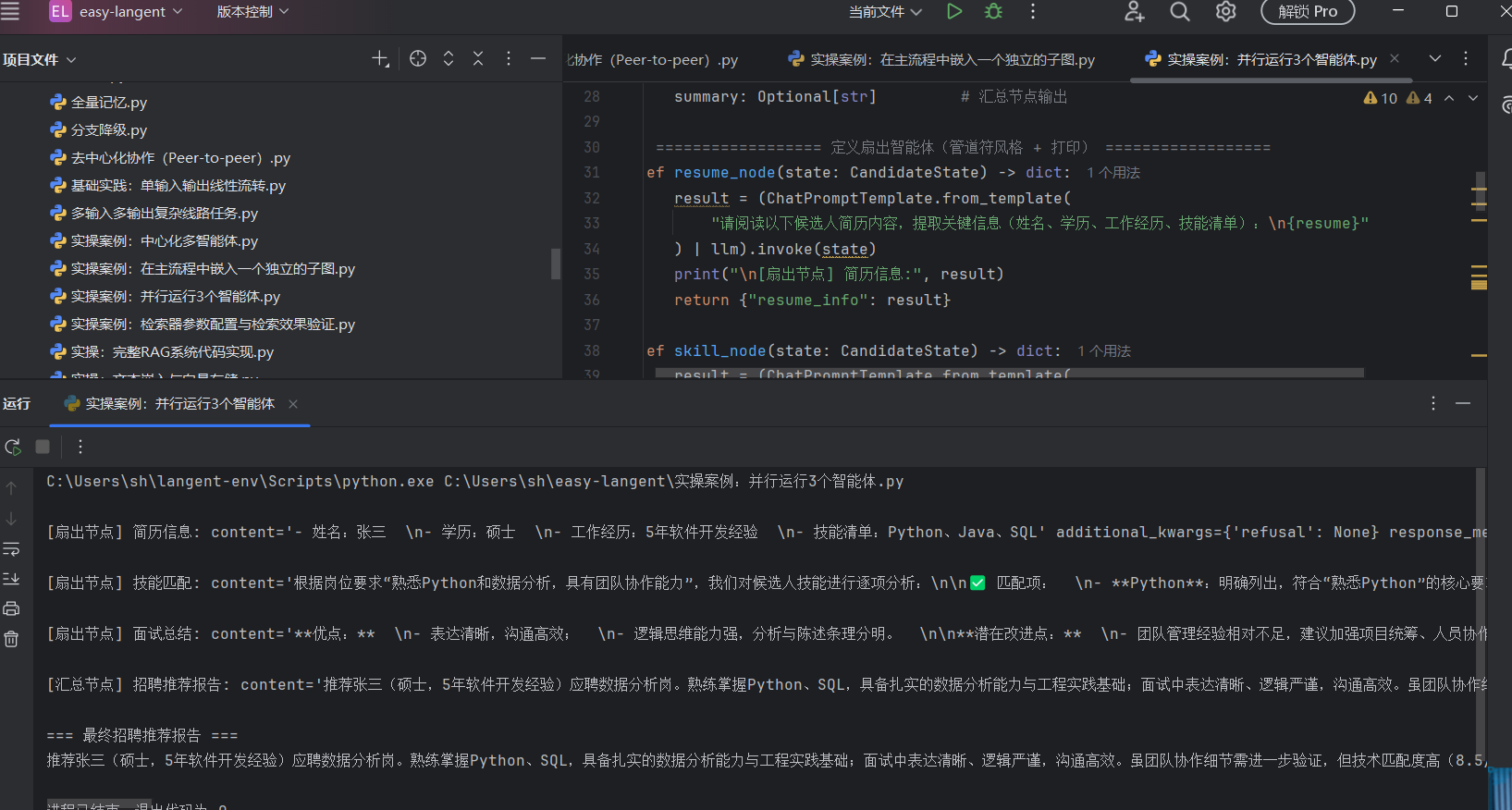
实操案例:并行运行3个智能体:
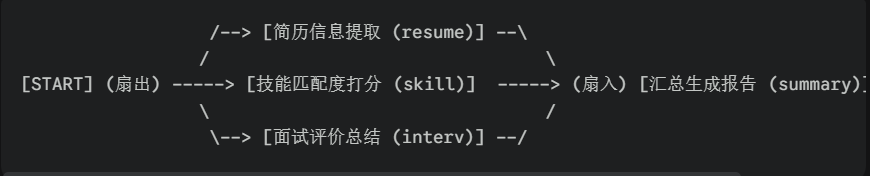
| 核心知识点 | 概念解析 | 代码中的具体体现 |
| 扇出 (Fan-out) | 一个节点执行完后,同时触发多个下游节点并行工作。 | graph.add_edge(START, "节点A/B/C")。START 一发出指令,三个节点同时开工。 |
| 扇入 (Fan-in) | 多个节点执行完后,汇聚到一个节点进行综合处理。 | 节点A/B/C 全部用 add_edge 指向了 "summary" 节点。 |
| 并行执行 (Parallelism) | 互不依赖的任务同时运行,大幅缩短总耗时。 | 简历提取、技能打分、面试总结不需要互相等待,LangGraph 底层会自动并行调用 LLM。 |
| 状态合并 (State Merging) | 多个并行节点同时向共享状态(State)写入数据,不发生冲突。 | 三个节点分别返回 {"resume_info": ...}, {"skill_match": ...}, {"interview_summary": ...},系统自动合并。 |
第一步:设计“互不干扰的黑板” (State 定义)
在 CandidateState 中,定义 resume_info、skill_match 和 interview_summary。 :这就相当于在黑板上画了三个独立的格子。三个并行工作的 AI 员工在往黑板上写字时,各自填自己的格子,绝不会发生“笔架打架”的数据覆盖冲突。
第二步:设立三大“独立车间” (扇出节点)
resume_node、skill_node、interview_node 这三个函数高度垂直。 它们只关注传入 state 中自己需要的那部分(比如 skill_node 只管技能匹配),处理完后,只返回自己负责更新的那一个字段。
第三步:设立“总装车间” (扇入节点)
summary_node 就像是最后的总编。 当它被触发时(LangGraph 的机制是:必须等所有上游扇出节点都运行完毕,扇入节点才会启动),黑板上的三个格子已经填满了。它把这三份材料作为 Prompt 的输入,最终生成一份 150 字的综合报告。
第四步:(构建 Graph)
graph.add_edge(START, "resume_info")
graph.add_edge(START, "skill_match")
graph.add_edge(START, "interview_summary")
并发冲突解决技巧:分配独立的状态键、使用状态合并函数(需要自定义一个合并规则(Reducer / 合并函数))
循环逻辑与迭代优化:
任务重试机制:
限制循环次数:
# ================== 2. 条件分支(增加循环次数限制) ================== MAX_RETRIES = 2 # 最大重试次数
人机协作机制:
3个核心功能:检查点与状态持久化(保存进度,防止白干活)、中断机制(关键操作人工授权)、动态状态编辑(人工干预修改)。
检查点(Checkpoints)与状态持久化:
- MemorySaver:LangGraph内置的检查点工具,无需自己实现保存逻辑,直接配置即可;
- session_id:唯一标识一个工作流会话,比如“novel_writing_001”,用于加载对应的存档;
- 持久化内容:包括每个节点的输出、当前的state状态、下一步要执行的节点,完全还原中断前的场景。

| 核心知识点 | 代码体现 | 现实类比 | 核心作用 |
| 持久化检查点 | MemorySaver() |
单机游戏的“自动存档” | 让工作流拥有记忆,不论何时中断,都能从断点恢复,不丢失数据。 |
| 线程隔离 | thread_id: "novel_session_001" |
游戏存档槽位 | 区分不同用户的任务。张三的流浪记是存档1,李四的霸总文是存档2,互不干扰。 |
| 流式执行 | app.stream(...) |
流水线监工 | 允许一步一步地观察图的运行,并在特定节点执行完后随时踩刹车(break)。 |
| 断点续传 | app.invoke(None, config=...) |
点击“继续游戏” | 传入 None,并带上原来的 thread_id,系统会自动去硬盘找最后一次的状态,并继续往下跑。 |
中断机制(Interrupts)实战:

| 核心知识点 | 代码体现 | 现实类比 | 核心作用 |
| 人工审批拦截 (HITL) | interrupt_before=["send_email"] |
十字路口的红灯 | 在执行某个节点之前强行踩刹车,等待人类给出明确指令。 |
| 状态持久化 | MemorySaver() |
工作台存档 | 配合中断使用。程序挂起时,当前的邮件草稿被安全保存在硬盘/内存里,不会丢失。 |
| 断点续传 (授权放行) | app.invoke(None, config=...) |
踩油门继续 | 传入 None,意味着人类没有修改状态,只是给了一个“放行”信号,让图接着往下跑。 |
app = graph.compile(
checkpointer=memory,
interrupt_before=["send_email"] # ⭐ 核心魔法
)
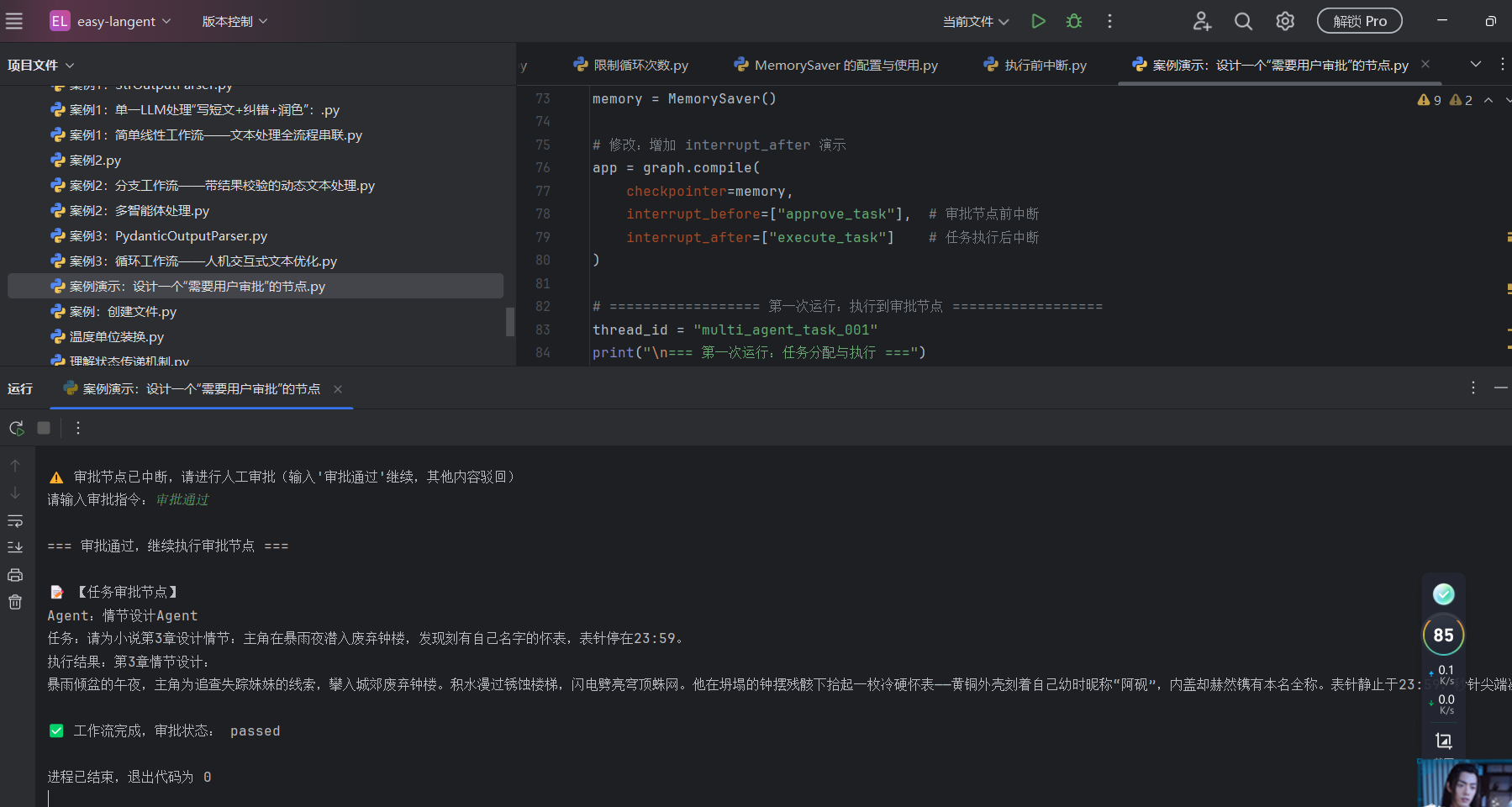
案例演示:设计一个“需要用户审批”的节点

| 核心知识点 | 代码体现 | 现实类比 | 核心作用 |
| 后置拦截 | interrupt_after=["execute_task"] |
做完检查 | 员工刚干完活,还没把文件递给下一个人,就被你叫停了。 |
| 前置拦截 | interrupt_before=["approve_task"] |
做前请示 | 员工正准备干活,被你拦住:“先等我签字你再干。” |
| 状态注入 (State Injection) | app.invoke({"retry": True}, config=...) |
老板亲自动手修改 | 之前我们传 None(只放行);现在我们传了一个字典,相当于老板不仅放行,还亲手在黑板上加上了“需要重试”的标记! |
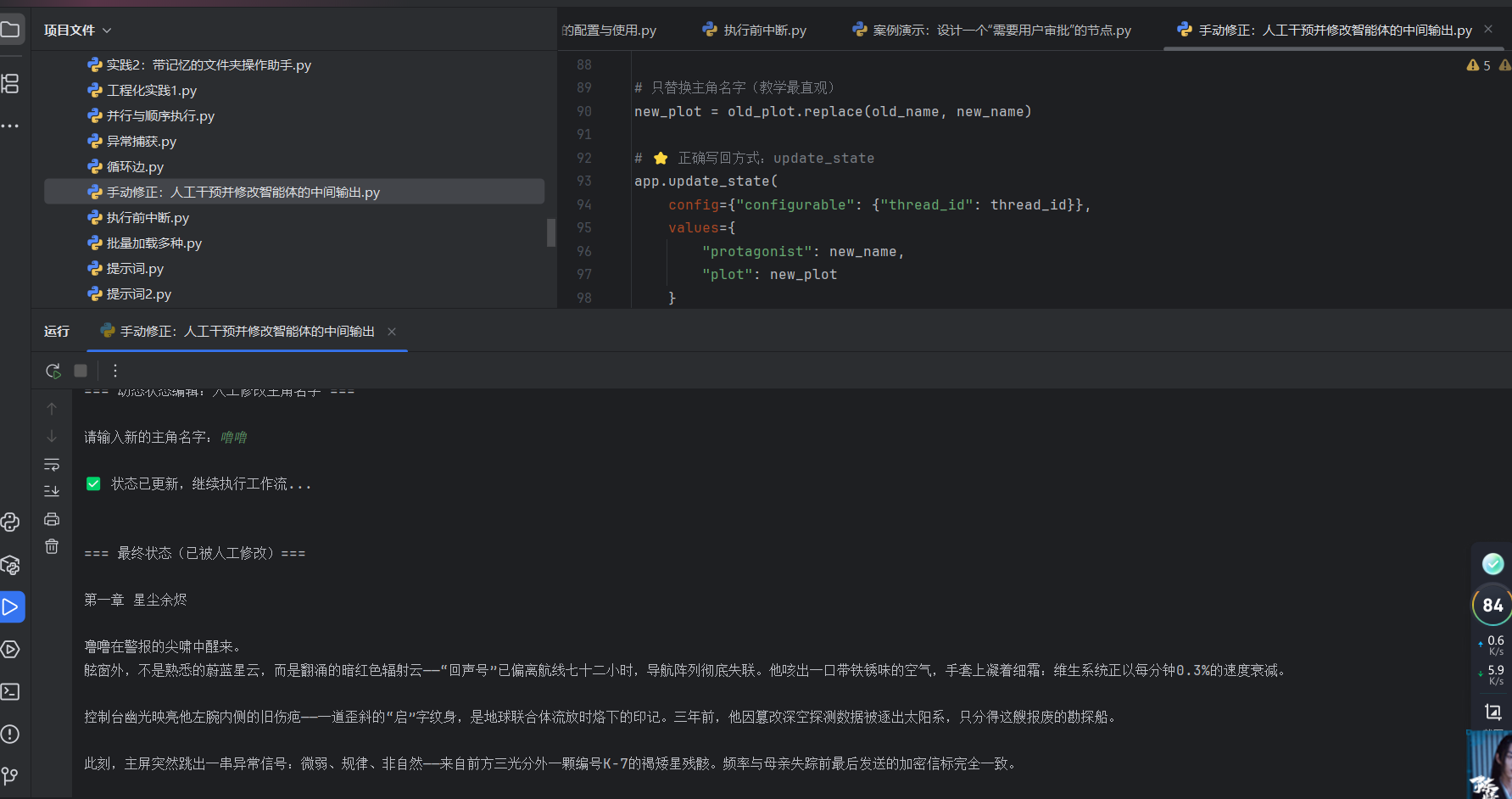
动态状态编辑:
手动修正:人工干预并修改智能体的中间输出

| 核心知识点 | 代码体现 | 现实类比 | 核心作用 |
| 状态检视 (Inspect State) | memory.get({"configurable": {"thread_id": ...}}) |
偷看打卡记录 | 在不启动工作流的情况下,直接从数据库/内存中提取当前的全局状态,看看 AI 刚才到底写了什么。 |
| 显式状态更新 (Update State) | app.update_state(config=..., values=...) |
用修正液篡改记录 | 本节最核心的 API!它允许你在图没有运行的时候,强行把新数据写进当前的 Checkpoint 里,覆盖掉 AI 之前的值。 |
| 截断点继续 | app.invoke(None, ...) |
按下播放键 | 因为状态已经在上一步被 update_state 修改了,所以这里传 None 即可,程序会带着被篡改的记忆走向终点。 |
回退与跳转:将工作流重置到之前的任意节点
app.update_state(
config={"configurable": {"thread_id": thread_id, "current_node": "plot"}},
values=state
)
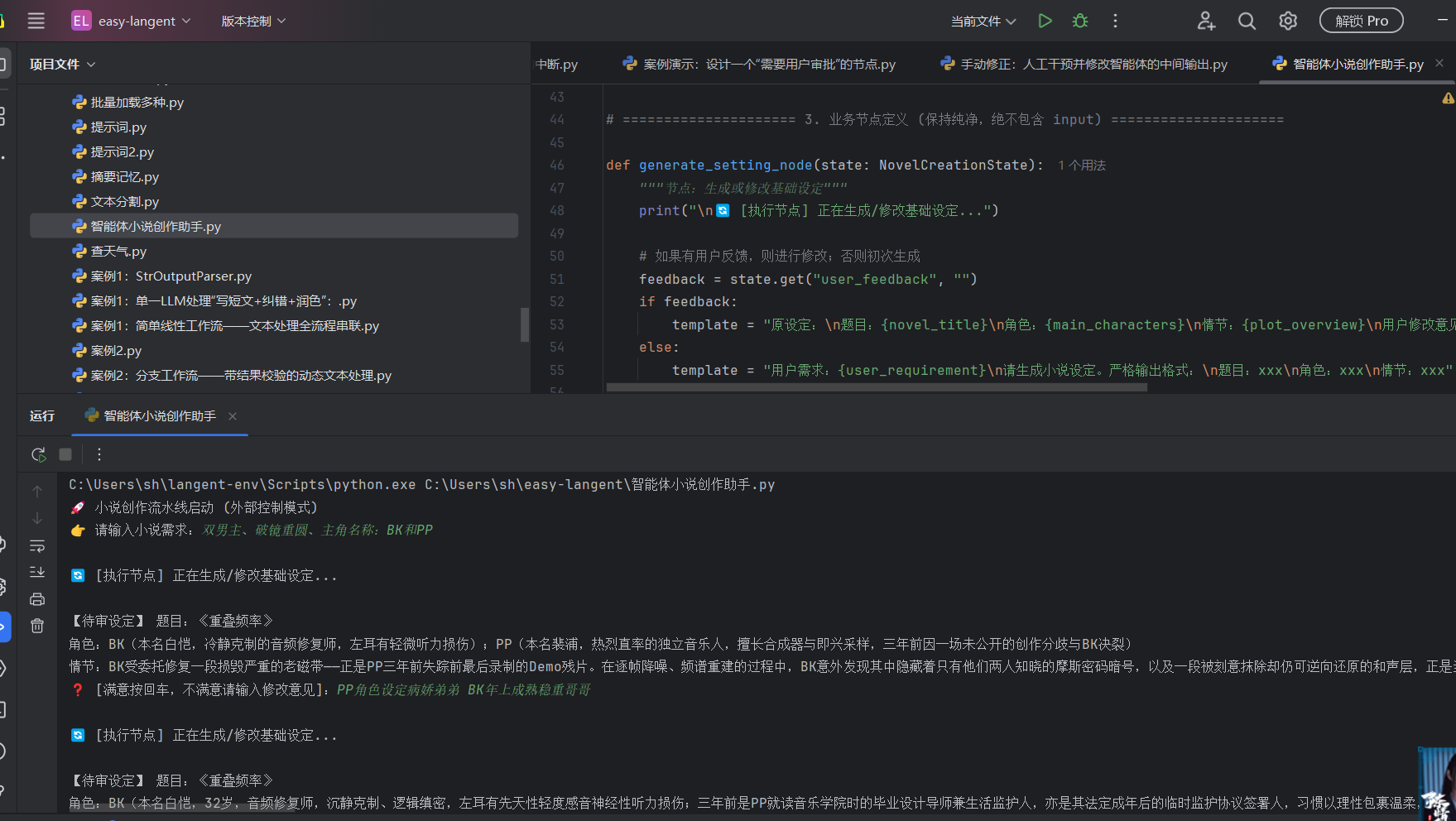
综合实践:智能体小说创作助手:


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)