
从零搭建读书笔记智能体——Nexent 知识库功能深度实践
从零搭建读书笔记智能体——Nexent 知识库功能深度实践
一、读了就忘?开发者的阅读困境
我有一个书单,存在手机备忘录里,条目已经超过八十本。
真正读完的大概不到三分之一。读完还能说出核心观点的,再砍一半。能在工作里实际用上的,寥寥无几。
这不完全是懒的问题。更根本的原因是:读和用之间缺少一个检索层。书读完了,笔记记在 Notion 里,画线记在 Kindle 里,摘录存在一个叫"reading"的文件夹里,想用的时候根本找不到。搜索靠关键词,得记得当时用了什么词,记不得就全白费。
Obsidian 的双向链接是一个思路,但维护链接本身就是一项工作。Readwise 能自动同步划线,但检索还是表面的文本匹配。我真正想要的是:给它一句话,它帮我在所有笔记里找到语义相关的内容,不管当时用什么词写的。
这件事本质上是一个向量检索问题,再往上包一层对话界面,就是知识库 + 智能体的组合。
上个月试了一下 Nexent,发现它的知识库功能刚好能解决这个问题,而且不需要写代码,配置成本比我预期低很多。这篇文章记录完整的实践过程,重点在知识库这块,读书笔记只是一个切入场景,背后的配置逻辑可以迁移到任何需要"语义检索个人文档"的地方。
在开始之前,有必要说清楚这套方案适合谁:如果你的笔记还很少,不到二三十条,直接问 GPT 就够了;如果你有几十、上百份笔记,且经常需要跨文档检索某个观点或概念,这套配置才真正有价值。积累量越大,知识库的优势越明显。
二、平台上手:在线版与本地部署的选择
Nexent 有两种上手方式。
在线版访问 http://60.204.251.153:3000/zh,注册账号即用,零部署成本,适合先摸一遍功能看看合不合用。需要注意的是,在线试用环境会不定期进行安全整改维护,期间可能暂时无法访问,配置的数据也不保证持久化。如果你在试用期间开发了重要的智能体,建议及时用导出功能保存配置。
本地版用 Docker Compose 拉起来,数据持久、响应快,适合长期使用。官方部署指南写得很清楚,照着走半小时内能跑起来:https://modelengine-group.github.io/nexent/zh/quick-start/installation.html
我两种都用了。在线版适合摸底,本地版适合真正用起来。读书笔记这个场景需要长期积累文档,用本地版更合适,数据不会丢。
界面进去,左侧导航的核心模块:开始问答、快速配置、智能体空间、模型管理、知识库、智能体开发、智能体市场、MCP 工具、记忆管理等等。这篇文章的重头戏在知识库和智能体开发,其他模块点到为止。
三、模型接入:批量导入省掉重复操作
知识库要跑起来,底层需要两个模型:一个大语言模型负责理解和生成,一个向量模型负责把文档转换成可检索的向量。
我用的是硅基流动提供的模型服务,API 兼容 OpenAI 格式。
批量导入:一次拉取,按需启用
如果只用一两个模型,单个填写就行。但我想同时启用几个模型对比效果,逐个填太低效,批量导入是更合理的选择。
操作路径:模型管理 → 批量导入 → 填入 API URL 和 Key → 点击"拉取模型列表"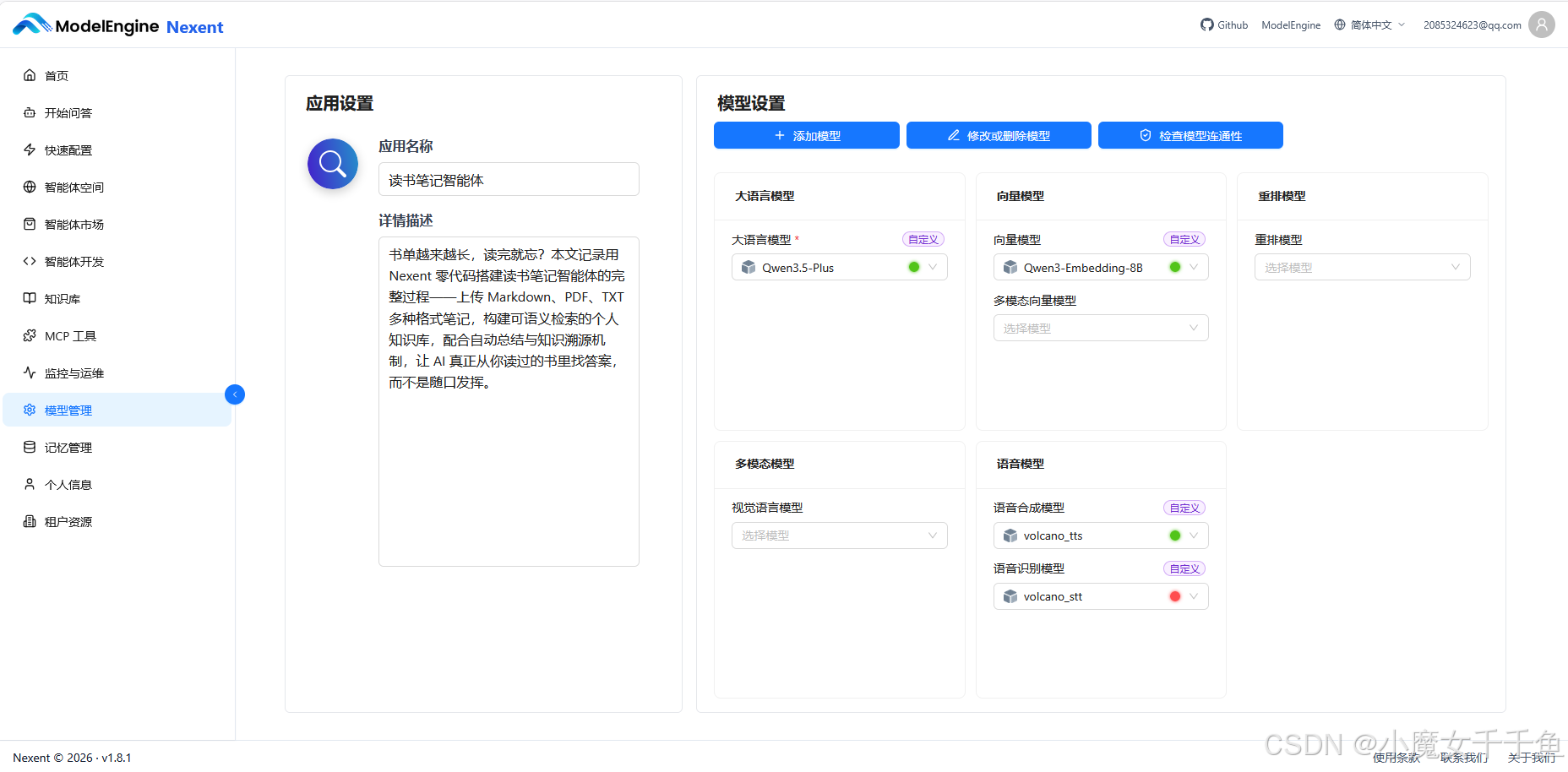
系统会自动把该供应商下的全部可用模型枚举出来,逐个打开开关选出要启用的。我启用了 Qwen3.5-Plus(主力推理模型)和对应的 Embedding 模型用于知识库向量化。
拉取完成后,进入"快速配置"页面,设置系统默认模型:
大语言模型:Qwen3.5-Plus
向量模型:选对应的 Embedding 模型
四、知识库核心实践:把读书笔记变成可检索的语料库
这是本篇文章的重点。
我准备了哪些文档
整理了四类材料上传:
Markdown 格式的读书笔记:用 Obsidian 写的,结构清晰,有标题层级,大约 2000 字
PDF 书摘:从 Kindle 导出的划线合集,经过简单排版,约 15 页
TXT 摘录:随手记的金句和段落,纯文本,没有结构
Word 文档:某本书的系统性笔记,有表格和列表混排
四种格式覆盖了大多数人实际会有的笔记形态,用来观察 Nexent 对不同格式的处理表现。
上传与解析:三个状态,速度差异明显
文件上传后,系统依次经历三个状态:解析中 → 入库中 → 已就绪。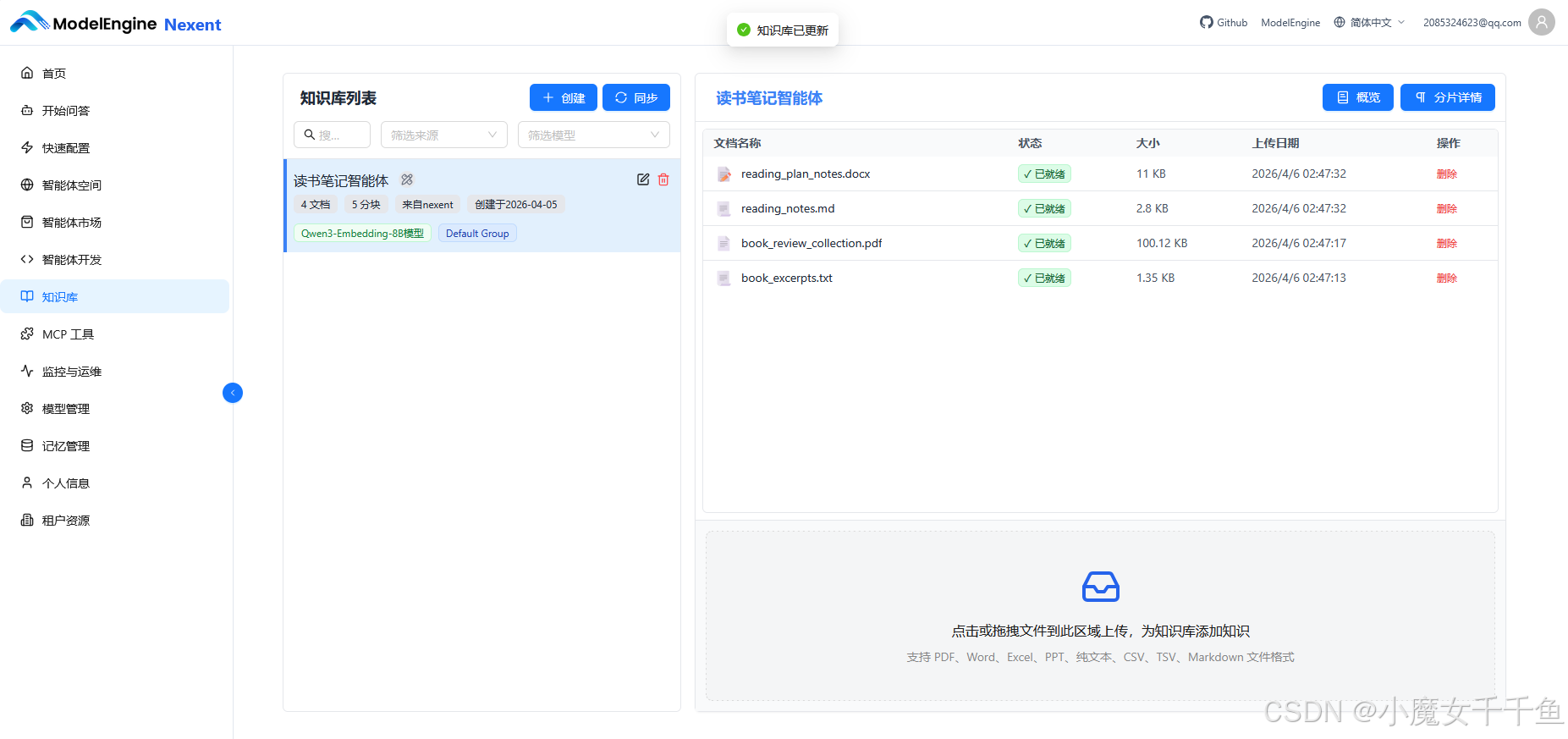
各格式的处理速度:
格式 文件大小 等待时间
Markdown(2000字) 约 8KB 不到 10 秒
TXT(纯文本) 约 5KB 约 15 秒
PDF(15页书摘) 约 1.2MB 约 90 秒
Word(含表格) 约 380KB 约 45 秒
Markdown 和 TXT 处理最快,PDF 最慢。PDF 慢的原因很好理解:需要先解析排版、提取正文,再做向量化,步骤更多。Word 含表格的情况下也明显比纯文本慢。
自动总结功能:最容易被忽视的关键机制
每份文档入库后,点开文档条目,能看到系统自动生成的"摘要"。这个功能初看不起眼,但实际上是多知识库场景下最关键的路由依据。
原理是这样的:当智能体同时挂载了多个知识库,收到问题时,它会先读每个知识库的摘要,判断"这个问题应该去哪个库里找",再去对应的库做向量检索。摘要写得准,路由就准;摘要含糊,检索可能直接走错库。
我对比了四份文档的自动总结质量:
Markdown 笔记的总结质量最好。有标题层级的文档,系统能清晰提取主题——我那份某本书的读书笔记总结准确识别出了书名、核心论点、作者背景,关键词精准。
PDF 书摘的总结明显偏泛化。生成的摘要是"本书涉及商业、管理、个人成长等方面的内容",跟没写差不多。原因大概是 Kindle 导出的格式里夹了大量页码、位置信息,解析后文本碎片化严重,总结模型拿到的是混乱的输入。
TXT 摘录的总结质量居中,纯文本至少没有排版噪音,但因为没有结构,总结只能提炼关键词,缺乏层次感。
Word 文档的总结取决于排版复杂程度。我那份有表格的笔记,总结质量不如纯 Markdown,但比 PDF 好。
实践结论:上传给知识库的文档,越结构化越好。如果有时间做整理,把 PDF 书摘转成 Markdown 再上传,总结质量会有显著提升,对后续检索路由精度的影响是实质性的。
五、智能体开发:打造读书笔记问答助手
知识库配置完,开始搭智能体。
工具选配
读书笔记问答这个场景,主要是使用了两个工具:
| 工具 | 用途 |
|---|---|
| knowledge_base_search | 检索本地读书笔记和书摘 |
| 联网搜索(内置) | 查书评、作者背景、相关延伸阅读 |
没有接任何外部 MCP。读书笔记问答的核心是"从我已有的内容里找",联网搜索只是辅助补充背景,工具组合保持简单。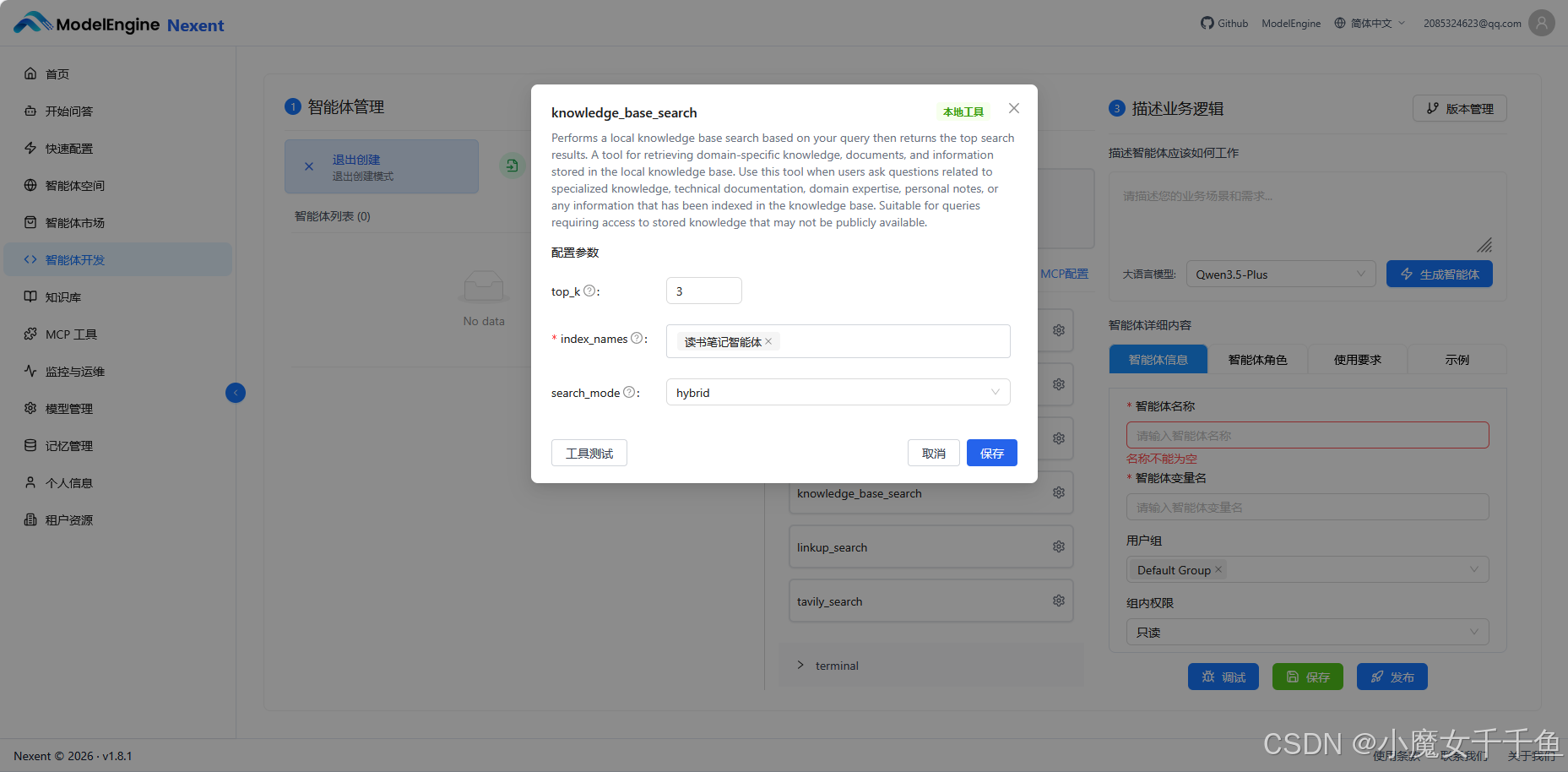
选配知识库
在 knowledge_base_search 工具的配置里,把技术阅读库和人文阅读库都挂载上。有了之前的分库逻辑,智能体在检索时会先根据摘要判断去哪个库找,不用手动指定。
用自然语言描述,一键生成提示词
描述框里我写了这段:
你是我的私人读书助手,帮我从个人读书笔记和书摘中检索信息、整理观点、做跨书籍的内容关联。我的笔记覆盖技术类(编程、AI、系统设计)和人文类(历史、心理、社会学)两大方向。回答问题时,必须引用具体的书名和对应段落或章节,不允许脱离我的笔记内容泛泛总结。如果笔记里没有相关内容,直接告诉我"你的笔记里没有这方面的记录",不要用通用知识补充。
选模型 Qwen3.5-Plus,点"生成智能体",等几秒,完整提示词结构就出来了。
提示词审查:我改了三处
自动生成的质量不错,但有几个地方需要手动调整:
修改一:引用要求不够硬
自动生成的版本写的是"尽量引用来源",这个"尽量"会给模型留下不引用的余地。改成:
原文:回答时尽量注明信息来源
改为:每一条回答必须注明具体来源:书名 + 章节或页码(如有),没有明确来源的内容不得出现在回答中
修改二:没有笔记时的处理逻辑
自动生成的版本在笔记里找不到内容时,会用通用知识补充。这不是我想要的——我需要知道"我读过的书里有没有讲这个",而不是"AI 知不知道这个"。改成:
改为:如果在用户笔记中未检索到相关内容,直接回答"你的读书笔记中没有关于这个话题的记录",不使用通用知识补充,不做延伸推测
修改三:跨书关联的输出格式
加了一条格式要求:当回答涉及多本书时,以书名为分组列出,每本书的内容单独成段,不要混在一起。
两轮调试
第一轮:跨书籍综合问答
问:「我读过的书里,有没有提到过关于"专注力"或者"深度工作"相关的观点,帮我整理一下」
智能体先调用 knowledge_base_search 检索,分别命中了技术阅读库和人文阅读库里的相关内容,按书名分组整理,每本书后面附了对应的笔记段落。回答末尾标注了"依据:[技术笔记库] 《深度工作》第二章;[人文笔记库] 《心流》第四节"。格式符合预期,来源清晰。
第二轮:边界测试
问:「量子计算未来会怎么发展?」
这是一个我的笔记里完全没有内容的话题。智能体回答:「你的读书笔记中没有关于量子计算的记录。如果你想了解这个话题,可以先找几本相关书籍读一读,我很乐意在你有了笔记之后帮你整理和检索。」
没有用通用知识补充,边界处理正确,通过。
这两轮测试下来,最让我满意的不是回答质量本身,而是智能体有了明确的能力边界——它知道自己能做什么、不能做什么,不会因为"显得有用"而随意编造内容。这在知识管理场景里尤其重要,你需要的是一个老实的助手,而不是一个爱发挥的助手。
版本保存与发布
调试满意后,点"保存",系统进入版本列表,当前标记为 v1。Nexent 支持多版本管理,后续如果改了提示词效果变差,可以一键回滚到历史版本,不用担心改坏了回不去。
确认稳定后点"发布",智能体出现在"开始问答"和"智能体空间",正式可用。
六、对话效果:知识溯源是最大亮点
发布后切换到"开始问答",用真实问题测试。
工具调用过程可见
每次智能体检索知识库,界面上会显示中间步骤:
正在检索知识库:query=“专注力 深度工作”…
命中知识库:技术阅读库(3条)、人文阅读库(2条)…
这个透明度很重要。能看到检索了什么、命中了什么,一旦回答不对,也知道是哪一步出了问题,而不是面对一个黑箱。
一次典型对话
问:「《穷查理宝典》里有没有提到关于逆向思维的内容,帮我找一下」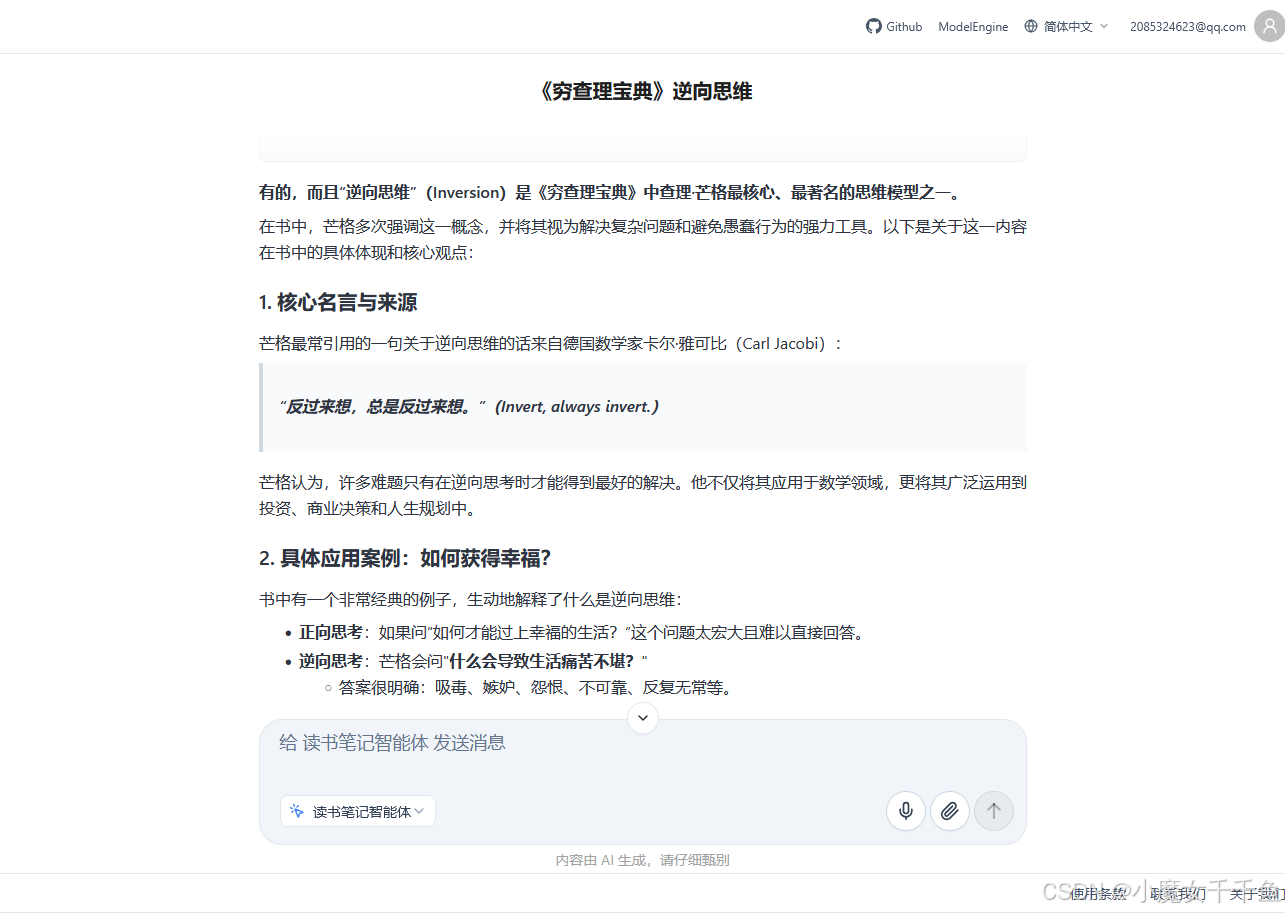
响应流程:
1.knowledge_base_search 检索"逆向思维 穷查理宝典"
2.命中人文阅读库,找到对应书摘片段
3.输出回答,末尾标注"依据:[人文阅读库] 《穷查理宝典》第三讲"
来源清晰,内容可追溯,不是凭空生成的。
同一个问题去问裸 LLM,它会给一段看起来像是从书里来但实际无法验证的总结,没有章节,没有具体段落,你不知道它说的对不对。有了知识库和溯源机制,这个差距是实质性的。
跨书籍关联:真正有价值的功能
问:「我读过的书里,对于"习惯养成"这件事,不同作者的观点有什么异同?」
智能体从技术库和人文库各自检索,找到了三本书里关于习惯的相关段落,分别整理观点,最后做了简短的对比说明。这种跨文档的语义关联,是纯文本搜索做不到的。
更让我惊喜的是一次无意中的测试:问了一个措辞和笔记里完全不同的问题——我笔记里写的是"注意力管理",但我问的是"如何减少分心"。纯关键词搜索根本匹配不上,但向量检索找到了,因为语义上是同一件事。这才是知识库真正的价值所在——不是更好的搜索框,而是理解意思的检索系统。
当然也有局限。如果某本书的笔记本身写得很简略,比如只记了几个词,检索回来的内容也会很碎片,智能体没有足够的上下文去做整合,回答质量会明显下降。知识库的上限,很大程度上取决于笔记本身的质量。这个道理说起来简单,但用了之后才真正有体感:好好写笔记,是让这套工具发挥作用的前提。
七、智能体市场:装一个现成阅读助手对比体验
Nexent 智能体市场里有官方和社区发布的现成智能体,想看看有没有现成的阅读类助手可以参考。
找到一个"文献阅读助手",走一遍安装流程:
选定智能体 → 选择本地使用的模型(不继承原作者的选择,需要手动指定)→ 确认工具权限 → 安装完成,出现在我的智能体列表。
流程整体顺畅,选型和安装在同一页面完成,没有跳转。
但安装完有一个容易踩的坑:该智能体原本配置了知识库(应该是原作者上传的书目数据库),在我的环境里这个知识库不存在,系统会自动基于我自己有权限的知识库重新检索。这个行为本身合理,但安装完成时没有任何提示,我是发现回答质量不对劲后翻文档才找到原因的。
建议官方在安装完成时补一条说明:「该智能体包含知识库检索工具,将基于你当前的知识库运行,如需达到原作者预设效果,请上传对应文档并绑定。」这个提示不大,能省掉很多第一次用市场功能的人的困惑。
八、记忆系统:记住你的阅读偏好
用了一段时间后,开启了记忆系统,感受到了和知识库的互补关系。
知识库是静态的:存放我已经读过的书的笔记和书摘,是固定的参考资料。每次对话,智能体按需从里面检索。
记忆是动态的:每次对话结束后,系统自动提取关键信息存入记忆库——比如"用户对心理学类书籍感兴趣"“用户偏好引用具体章节而非泛泛总结”——下次对话时自动附加到上下文。
实际体验是:用了大约两周后,智能体推荐延伸阅读时开始主动偏向心理学方向(因为我问这类问题最多),不用每次重新说"我对心理学比较感兴趣"。在推荐书籍时,它也会主动按照"你之前倾向于引用具体段落"这个偏好来组织回答,不再泛泛总结。
两者的分工是:知识库管"我读过什么",记忆管"我是一个什么样的读者"。前者是客观的文本库,后者是动态积累的用户画像。两者叠加,智能体对你的理解会越来越准,长期使用下来比刚上手时好用很多。
当然记忆也有局限:粒度比较粗,目前只有"清空全部记忆",没有单条编辑或删除的入口。如果某次对话聊了个不相关的话题,提取出来的记忆可能是噪声,但又没办法单独删掉,只能等它被后来的对话覆盖或者清空重来。这个细节希望后续版本能细化。
九、总结:知识库功能的上限与边界
用了将近一个月,读书笔记问答这个场景基本跑通了。客观总结一下。
做得扎实的地方
知识溯源机制是最有价值的设计。每条回答必须来自知识库里的真实内容,末尾标注来源,信息可追溯。这对"查自己的笔记"这个场景来说是刚需,没有溯源就是在和 AI 闲聊,有了溯源才是在检索自己的知识库。
自动总结的路由逻辑设计合理。多知识库场景下,先读摘要再决定去哪个库检索,这个机制比"所有库一起搜"要精准很多,误召回率明显更低。
工具测试功能很实用。在把 knowledge_base_search 绑给智能体之前,可以单独测试它的检索效果——输入 query,看返回了什么,确认格式和内容符合预期再绑定。这让调试工具问题和调试智能体行为问题分开了,节省了大量排查时间。
版本管理给了改提示词的安全感。可以放心改,改坏了一键回滚,不用每次都小心翼翼地备份。
还需要改进的地方
PDF 解析质量不稳定。多栏排版、公式密集的 PDF,入库后总结质量明显下降。对知识库来说这是核心功能,文档解析的健壮性值得专门投入,尤其是学术类 PDF 的处理。
记忆管理粒度过粗。只有"清空全部",没有单条编辑删除,错误的记忆没法精准清理。
模型接入的错误提示太粗。"连接失败"四个字,没有 HTTP 状态码,没有请求路径,对新用户来说排查成本很高。加几行详细信息能解决大部分入门困惑。
总体来说,Nexent 的知识库功能已经能支撑"语义检索个人文档"这个核心需求,知识溯源的机制设计也比较成熟。对于有大量笔记积累、想做语义检索的用户,配置成本不高,值得花半天时间搭起来试试。
读书笔记只是一个入口,同样的配置逻辑可以迁移到研究资料管理、产品文档问答、团队知识库等任何需要"问自己的文档"的场景。
用了这套工具之后,我的阅读习惯也在悄悄改变。以前读书随手划线,反正找不到;现在读完会多花二十分钟,把核心观点用 Markdown 整理一遍再上传。这个额外的整理过程,反而加深了对书本身的理解。工具改变行为,行为又反过来影响工具的效果,这是我用知识库最意外的收获之一。
Nexent 现在是 v1.8.1,核心链路已经跑通,但还有一些打磨空间。从产品发展的角度看,这是一个正在成长中的平台,愿意花时间配置和反馈的早期用户,也会受益于后续的功能迭代。如果你用下来有什么问题或者建议,GitHub 的 Issues 和 Discord 社区都是反馈渠道,官方响应速度还不错。
GitHub:https://github.com/ModelEngine-Group/nexent
Gitcode:https://gitcode.com/ModelEngine/nexent
本地部署指南:https://modelengine-group.github.io/nexent/zh/quick-start/installation.html
官方文档:https://doc.nexent.tech

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)