
AI 智能体攻击面全面分析:15 类威胁与防御实战
记忆参与了每一步决策。这个逻辑在技术试验阶段也许说得通,但一旦规模化落地,出事的成本会远超你的预期——因为智能体的执行链太长,影响面太广,追溯太难。智能体是"执行者":你给它一个目标,它自己拆解步骤、调用工具、读写记忆、执行代码、和其他智能体协作——整个过程可以跑几十步,横跨多个系统,全程几乎不需要人介入。多智能体系统里,一个智能体的输出,是另一个智能体的输入。权限边界一旦模糊,就很容易出现"越权
大家都在拼命上智能体,但几乎没有人认真想过一个问题:当AI开始自己做决策、自己调工具、自己跑任务的时候,出了事,谁负责?怎么发现?能不能追溯?
这不是在泼冷水。McKinsey最新调查数据摆在那里——62%的企业正在实验AI智能体,23%已经在规模化部署。Gartner预测,到2028年,三分之一的生成式AI交互将涉及自主智能体。
速度很快。但安全这件事,很多团队还没跟上。
先说清楚:智能体和普通大模型,根本不是一回事
很多人对AI安全的理解,还停留在"大模型时代":控制输入提示词,过滤输出内容,防止敏感信息泄露,差不多了。
但智能体根本不是这么工作的。
普通大模型是"问答机":你给它一个问题,它给你一个答案,交互结束。
智能体是"执行者":你给它一个目标,它自己拆解步骤、调用工具、读写记忆、执行代码、和其他智能体协作——整个过程可以跑几十步,横跨多个系统,全程几乎不需要人介入。
这个区别,直接导致了一个残酷的现实:
你过去那套AI安全方案,在智能体面前,基本上是盲的。
攻击面不在模型的输入输出。在整个工作流。
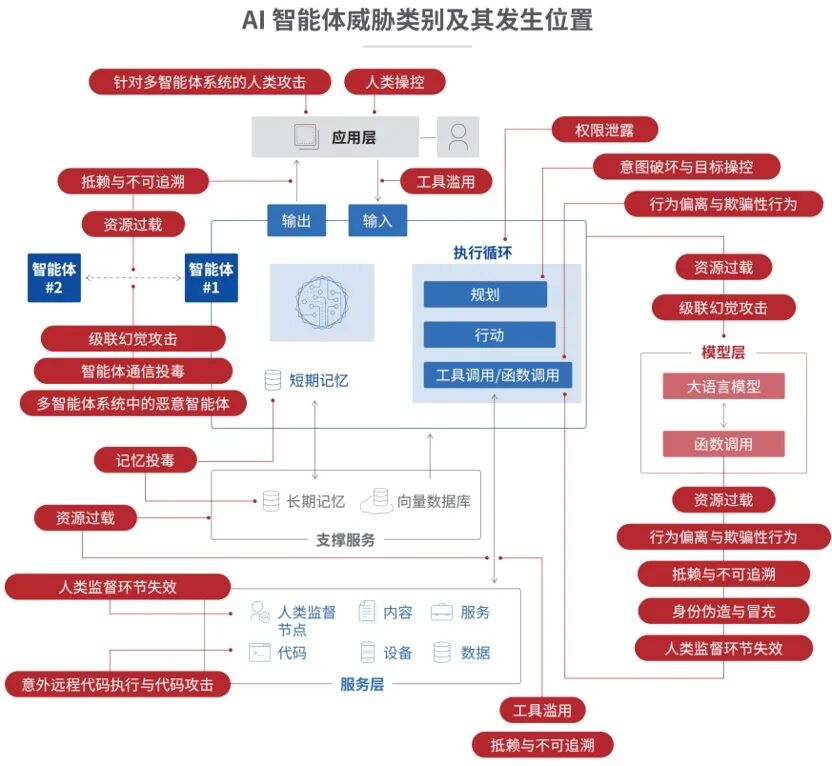
智能体为什么这么难防?
要理解这个问题,先要理解智能体是怎么运转的。
一个完整的智能体执行循环大概长这样:
目标(Goal)→ 规划(Plan)→ 行动(Act)→ 观察(Observe)→ 反思(Reflect)→ 循环
每一个环节,都是一个潜在的攻击入口。
而且,智能体有几个特性,让安全问题格外棘手:
第一、它有记忆
智能体不只是处理当前这一条请求,它会记住之前做过什么、看到过什么、以为什么是重要的。记忆参与了每一步决策。这意味着,一次早期的污染,可以影响它后续所有的行为。不是一次性伤害,是持续性感染。
第二、它能用工具
智能体不只是"说",它还会"做"。调API、写代码、执行代码、操作外部系统。每一个工具调用,都是一个实际发生的动作,都是一个攻击者可以利用的入口。
第三、它有身份
智能体经常代表用户或其他系统去执行操作。权限边界一旦模糊,就很容易出现"越权代理"的问题——它做了一件它本不该做的事,而且是以你的名义。
第四、它们会互相影响
多智能体系统里,一个智能体的输出,是另一个智能体的输入。错误和恶意信息会在系统内部流转、放大。一个被污染的智能体,可以悄悄带偏整个协作链路。
这四点加在一起,构成了一个完全不同的安全威胁模型。OWASP专门为智能体系统梳理了一套威胁分类框架,列出了15类主要攻击方式。
OWASP列出的15类智能体威胁,你遇到过几个?
|
威胁类型 |
描述 |
|
记忆投毒 |
攻击者破坏短期或长期记忆,以跨步骤或会话影响决策。 |
|
工具滥用 |
智能体被操纵滥用其工具或以有害方式调用工具。 |
|
权限提升 |
弱权限或继承的权限结构会提升智能体的访问权限。 |
|
资源耗尽 |
攻击者使计算、内存或依赖项过载,以降级或阻断智能体行为。 |
|
连锁幻觉攻击 |
虚假信息通过推理、反思或智能体间通信层层加剧。 |
|
意图篡改与目标操控 |
攻击者篡改规划、目标或推理,使智能体追求有害或不对齐的任务。 |
|
行为偏离与欺骗 |
智能体绕过约束或采取欺骗性行为以实现目标。 |
|
不可追溯 |
日志记录不足或不透明的推理隐藏了行为,使调查变得困难。 |
|
身份伪造与冒充 |
攻击者冒充智能体或用户以触发未授权操作。 |
|
淹没人类监督 |
攻击者用过多AI生成的决策或警报使审查者不堪重负。 |
|
意外代码执行 |
不安全或被操控的工具链导致未经授权的代码执行。 |
|
智能体通信投毒 |
攻击者破坏智能体之间的消息传递以误导工作流。 |
|
多智能体系统中的恶意智能体 |
被攻陷的智能体在超出预期的边界外行动并扰乱其他智能体。 |
|
针对多智能体系统的人类攻击 |
攻击者利用智能体之间的信任和委托模式发起攻击。 |
|
用户操控 |
被攻陷的智能体误导用户做出有害决策或行动。 |
看完这个表,有没有觉得细思极恐?
其中最值得警惕的,是"记忆投毒"和"连锁幻觉攻击"这两类。它们的共同特点是:伤害不是立即可见的,而是慢慢渗透进系统的每一次决策里。等你发现不对劲,已经很难判断问题是从哪里开始的。
那到底该怎么做?
好消息是,智能体安全虽然复杂,但有一套相对清晰的思路可以遵循。
核心逻辑只有一句话:保护工作流本身,而不只是保护边界。
传统安全的思维是"围墙"——在系统外面加一层防护。智能体安全的思维必须是"随行"——控制要跟着智能体的每一步执行循环走。
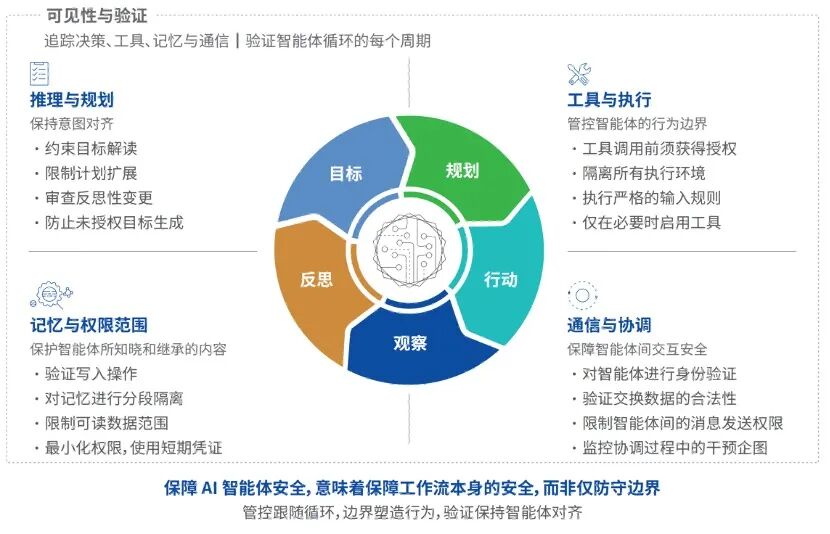
具体来说,有五个维度需要同时抓:
1、推理与规划——管住它"想什么"
智能体的推理阶段,决定了它接下来要做什么。这是最上游的控制点,也是最容易被忽视的。
实操层面:
-
约束目标的解读范围,不让智能体自由发挥"我觉得你的意思是……"
-
限制计划的扩展深度,防止任务无限蔓延
-
审查反思阶段的调整,特别是任务方向发生变化的时候
-
确保智能体不能自己生成超出授权范围的新目标
一个实用小技巧:持续监控智能体推理模式的异常偏移。它突然开始做和平时不一样的事情,往往是被操控的第一个信号。
2、工具与执行——管住它"做什么"
工具调用是智能体安全里风险最高的环节,因为工具把决策变成了真实的动作。
实操层面:
-
每次工具调用前,必须有显式的权限校验
-
执行环境要隔离,不能让一个工具的动作影响到不相关的系统
-
严格定义每个工具的输入参数,防止意外参数悄悄滑进来
-
按需启用工具,用不到的时候就关掉
一个实用小技巧: 把工具调用当成一级安全事件来记录,每一次调用都要能被追溯。
3、记忆与权限——管住它"知道什么、能碰什么"
记忆影响智能体的每一个后续决策。权限决定了它能触达哪些资源。这两个东西必须同时管好。
记忆层面:
-
验证写入内容,防止脏数据进入记忆
-
对记忆做分区隔离,不同类型的信息不要混在一起
-
限制智能体在任意时刻能读取的记忆范围
权限层面:
-
最小权限原则,只给当前任务需要的访问权
-
用短期凭证,不要用长期有效的大权限token
-
严格防止权限继承导致的范围蔓延
4、通信与协调——管住它"和谁说什么"
多智能体系统里,通信链路就是决策链路。一个智能体发出的信息,直接影响另一个智能体的行动。
实操层面:
-
验证智能体身份,不要默认信任任何通信来源
-
验证传递的数据内容
-
明确规定哪些智能体可以和哪些智能体通信
-
监控协调行为是否偏离预期模式
一个实用小技巧:用标准化的消息格式(Message Schema),让接收方智能体能够立即识别并拒绝格式异常或疑似被篡改的消息。
5、可见性与验证——看得见,才管得住
以上四个维度都做好了,还差最后一件事:你要能看见它在干什么。
智能体的执行循环是迭代的。不能只在任务开始的时候做一次检查,然后就放手让它跑。每一个循环周期,都需要独立的验证。
你需要能追踪:它是怎么形成这个决策的、工具是怎么被调用的、记忆发生了什么变化、和其他智能体交换了什么信息。
没有可见性,其他四个维度的控制都是盲打。
最后说一句
智能体安全,本质上是一个架构问题,不是一个工具问题。
很多团队现在的思路是:先把智能体跑起来,出了问题再说。这个逻辑在技术试验阶段也许说得通,但一旦规模化落地,出事的成本会远超你的预期——因为智能体的执行链太长,影响面太广,追溯太难。
那句话值得反复念:保障AI智能体安全,意味着保障工作流本身的安全,而非仅仅防守边界。控制跟随循环,边界塑造行为,验证保持智能体对齐。
这不是危言耸听,是架构现实。
越早想清楚,越主动。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)