
AI多智能体驱动的测试需求分析平台企业级落地
在测试的工作流中,基于需求分析的准确度是AI分析的一个难点。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
在测试的工作流中,基于需求分析的准确度是AI分析的一个难点。
从海量需求文档中提取可测试的验证点,到编写全面的测试需求分析报告,再到在多轮评审中反复打磨……测试工程师的精力常常被重复劳动所消耗。咱们不仅要仔细阅读每一份需求文档,还要凭经验识别风险点、整理业务规则、构建追踪矩阵……
为了解决这些问题,我们尝试研发了AI 智能测试平台,一个以AI 多智能体(Multi-Agent)为核心驱动的需求分析系统。平台通过 大语言模型 深度理解需求文档,自动完成从"文档解析"到"深度测试需求分析"的全链路智能化处理,并支持人工审阅介入,确保AI 输出与业务预期高度对齐。
AI智能测试平台不是一个简单的文档总结工具,它是一个融合了多智能体协作架构、RAG 向量知识库、多模态文档解析、实时流式交互 与人机协同审阅 的智能化测试分析平台。它旨在将需求分析这一高度依赖经验的环节系统化、智能化,让测试工程师从"文档搬运工"升级为"质量策略制定者"。
无论是快速解读复杂的业务需求文档,还是通过AI生成结构化的测试需求分析报告,AI 智能测试平台都能为测试团队提供一种全新的工作模式。
一、AI多智能体:从"人工阅读"到"智能解析"的跨越
需求分析是测试生命周期中对经验要求最高、耗时最长的环节。面对动辄数十页的需求文档,如何高效提取关键信息并转化为可测试的分析报告?AI智能测试平台的多智能体协作引擎 给出了答案。
1.双Agent 流水线,各司其职
平台采用AutoGen 多智能体框架,设计了一条精密的两阶段Agent 流水线:
需求获取Agent(Requirement Acquisition Agent):
扮演"专业需求文档分析师"角色。它会自动阅读并理解上传的文档内容,提取功能需求、非功能需求、业务背景、用户角色、核心术语、数据需求、依赖约束以及潜在歧义点,输出结构化的需求归纳摘要。
深度分析Agent(Requirement Analysis Agent):
扮演"高级测试需求分析师"角色。基于前一阶段的摘要,进一步输出包含需求结构化框架、风险热点地图、测试策略蓝图、追踪矩阵(RTM)、典型风险场景用例设计以及AI 增强建议的完整《测试需求深度分析报告》。
这种"先归纳、后深析"的双Agent架构,确保了输出质量——第一个 Agent 把文档信息"吃透",第二个 Agent 站在测试专家的视角进行"深度诊断"。
核心代码实现: 基于AutoGen RoutedAgent 的智能体定义
Python
@type_subscription(topic_type='requirement_acquire')
class RequirementAcquireAgent(RoutedAgent):
"""需求获取 Agent —— 自动解析文档、提取结构化需求摘要"""
@message_handler
async def handle_message(self, message: RequirementFileMessage, ctx: MessageContext):
# RAG 入库 + 文档解析
rag = NormalDoucmentRAG(message.files)
doc_content = rag.load_file()
collection_name = f'project_{message.project_id}'
await rag.create_remote_index(collection_name)
# 构建 AssistantAgent + 人工审阅 UserProxyAgent
acquire_agent = AssistantAgent(
name="requirement_acquire_agent",
model_client=deepseek_model_client,
system_message=ACQUIRE_SYSTEM_PROMPT # 专业需求文档分析师角色
)
2.实时流式输出,所见即所得
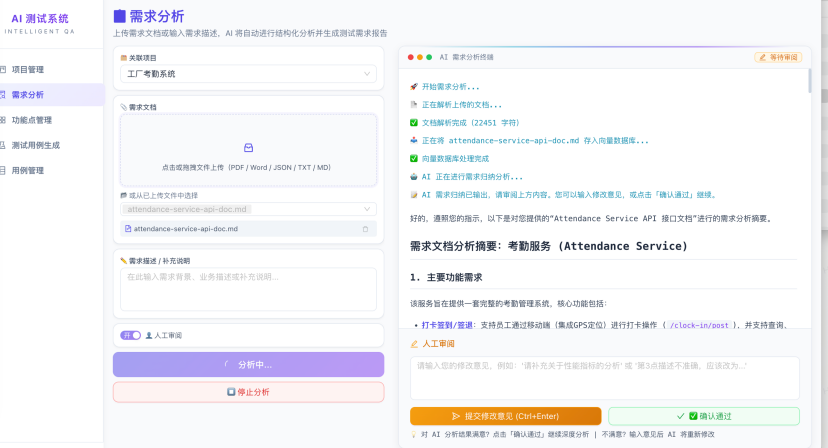
区别于传统的"提交-等待-查看"模式,平台基于WebSocket 实现了真正的流式推送体验。
AI的分析过程如同一位专家在你面前实时书写:每一段归纳、每一条风险识别、每一行报告内容都以"打字机"效果逐字呈现在终端面板中。你无需等待整个分析完成,就能实时跟踪AI 的思路、判断输出方向是否正确,并在必要时随时介入调整。
WebSocket流式推送核心实现:
|
二、人机协同:让AI输出精准对齐业务预期
AI再强大,也难以完全替代领域专家的判断力。AI智能测试平台在架构层面就将"人工审阅"设计为一等公民,实现了真正的人机协同闭环。
1.一键开启人工审阅模式
在开始分析前,只需打开「人工审阅」开关,平台即进入交互式审阅模式:
AI输出需求归纳初稿后,系统自动暂停,等待你的审阅反馈;
你可以输入修改意见(如"请补充关于性能指标的分析"或"第3 点描述不准确");
AI会根据你的意见实时修改并重新输出;
反复迭代,直到你点击「确认通过」,系统才继续进入深度分析阶段。
2.多轮修改智能整合
当审阅经历了多轮修改后,平台会自动调用第三个智能体——整合优化Agent(Summarize Agent)。
它会回顾所有历史对话(包括AI初稿、用户的每次修改意见、AI 的每次修改稿),运用对话记忆(ListMemory)机制,整合输出最终版需求分析。这避免了多轮修改后信息碎片化的问题,确保最终交付物是完整、连贯、最优的版本。
三、多格式文档解析:像专家一样"读懂"各类文档
需求文档的格式五花八门,从正式的PDF到随手记录的 TXT,从 Word 文档到截图图片。传统工具往往只支持单一格式,AI 智能测试平台实现了全格式覆盖。
1.广泛的文件格式支持
平台支持以下格式的需求文档上传与解析:
|
格式 |
说明 |
|
|
使用pdfplumber 深度解析,支持复杂编码与排版 |
|
Word (.doc/.docx) |
通过LlamaIndex SimpleDirectoryReader 解析 |
|
Markdown (.md) |
原生支持,保留结构化格式 |
|
JSON |
结构化数据直接解析 |
|
TXT |
纯文本直接读取 |
|
图片 (.jpg/.png) |
通过通义千问多模态模型(Qwen-VL)进行 OCR 识别 |
2.多模态视觉理解
对于图片类文档(如需求截图、流程图照片),平台集成了通义千问视觉大模型(Qwen-VL-Plus),能够直接"看图说话"——不仅识别文字,还能描述场景、解读图表、提取关键信息。这意味着即使你只有几张需求讨论的白板照片,平台也能将其转化为可分析的结构化文本。
四、RAG知识库:让 AI 拥有"长期记忆"
单次对话的AI缺乏上下文积累,无法跨文档、跨项目进行知识关联。AI 智能测试平台通过 RAG(检索增强生成)架构 解决了这一痛点。
1.向量数据库自动入库
每份上传的需求文档,都会经过以下处理流水线自动入库:
Plaintext
文档上传
→ 文本提取 → 句子级分块(SentenceSplitter, chunk_size=1024)
→ DashScope 向量化(text-embedding-v4, dim=1024)
→ Milvus 向量数据库存储平台基于文件内容哈希(MD5) 实现智能去重——相同内容的文件只入库一次,避免重复计算与存储浪费。每个文件拥有独立的 Collection,支持精确的知识检索。
RAG向量化入库核心实现:
Python
classNormalDoucmentRAG(BaseRAG):
"""文档 RAG —— 自动分块、向量化、入库 Milvus"""
asyncdefcreate_remote_index(self, collection_name: str):
# MD5 去重:相同文件不重复入库
file_hash = hashlib.md5(open(file_path, 'rb').read()).hexdigest()
# 句子级分块 + DashScope 向量化
splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=200)
embed_model = DashScopeEmbedding(
model_name="text-embedding-v4",
output_dimension=1024
)
# 存入 Milvus 向量数据库
vector_store = MilvusVectorStore(
uri=REMOTE_MILVUS_URI,
collection_name=collection_name,
dim=1024
)2.多模式智能问答
平台提供基于Streamlit构建的智能问答助手,支持三种聊天模式:
普通模式:直接与DeepSeek 大模型对话,适合通用问答;
文档模式:上传文档后基于文档内容进行上下文问答,适合临时文档分析;
知识库模式:连接Milvus 远程知识库,在已沉淀的项目知识中进行精准检索与问答。
知识库模式让团队积累的所有需求文档都变成了AI的"长期记忆",新加入的测试工程师也能通过自然语言快速了解历史项目需求。
五、结构化输出:从报告到用例的标准化交付
AI的输出不应该是一段随意的文字,而应该是可直接纳入测试流程的标准化资产。AI智能测试平台在输出规范上做了严格的工程化设计。
1.深度分析报告:五大核心章节
深度分析Agent输出的《测试需求深度分析报告》严格遵循以下结构:
|
章节 |
内容 |
|
1. 需求结构化框架 |
功能分解(含核心★/高风险标记)、非功能需求矩阵、业务规则提取(BR编号体系) |
|
2. 深度分析 |
可测试性评估表(1-5分制)、风险热点地图(高风险 + 缓解措施)、测试策略蓝图(分层策略 + 工具链推荐) |
|
3. 全景视图 |
测试追踪矩阵RTM(核心模块/测试类型/预估用例数/自动化率)、环境与拓扑依赖 |
|
4. 典型风险场景 |
最高风险场景的破坏性测试方案设计(含破坏步骤与预期韧性表现) |
|
5. AI 增强建议 |
基于需求特征提出的高阶测试执行建议 |
2.结构化数据模型
平台使用Pydantic 定义了标准化的数据模型,支持AI 结构化输出:
RequirementList:需求列表(需求名称、类型、所属模块、级别、描述等)
TestCaseList:测试用例列表(用例名称、模块、前置条件、步骤、预期结果、优先级)
这些结构化模型使得AI的输出可以直接序列化为 JSON,方便与下游测试管理系统集成。
六、 技术架构:现代化的全栈工程
AI智能测试平台采用前后端分离的现代化架构,技术栈选型兼顾开发效率与系统性能。
核心技术栈
|
层级 |
技术 |
说明 |
|
前端 |
React 18 + Ant Design 5 |
企业级UI 组件库,亮色科技风主题 |
|
样式 |
Tailwind CSS + 自定义 CSS |
响应式布局+ 精美渐变视觉效果 |
|
构建 |
Vite 5 |
极速热更新,内置代理转发 |
|
后端 |
FastAPI + Uvicorn |
高性能异步Web 框架 |
|
通信 |
WebSocket |
全双工实时流式推送 |
|
AI 框架 |
AutoGen 0.4+ |
微软多智能体编排框架 |
|
LLM |
DeepSeek-Chat |
深度求索大语言模型 |
|
向量化 |
DashScope text-embedding-v4 |
阿里云1024 维文本嵌入模型 |
|
向量库 |
Milvus |
高性能分布式向量数据库 |
|
文档解析 |
LlamaIndex + pdfplumber |
多格式文档加载与索引 |
|
视觉AI |
Qwen-VL-Plus |
通义千问多模态视觉模型 |
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)