
Memoir 论文解读:让导航智能体学会“先想一段,再回忆一段”
Memoir论文提出了一种创新的具身导航方法,通过重新定义"想象"的用途来改进视觉语言导航任务。与以往将想象用于规划不同,Memoir将想象结果作为检索查询,从长期记忆中寻找类似场景下的观察和行为模式。该方法包含三个核心组件:语言条件化的世界模型进行状态推断和未来想象,混合视点级记忆存储环境观察和历史行为,以及经验增强的导航模型动态融合当前观测与检索结果。实验表明,这种&quo
0.简介
如果只用一句话概括 Memoir,它的真正新意不在于“又做了一个带记忆的导航模型”,而在于它重新定义了“想象”的用途。过去很多世界模型工作把 imagination 当成规划器,先在潜在空间里向前滚动,再根据 imagined future 直接决定怎么走;Memoir 则换了一个角度,它把想象结果当成检索查询,去长期记忆里找“我以前在类似局面下看见过什么、又是怎么做决定的”。因此,这篇论文的重要性不只在具身导航这一条具体任务线上,更在于它提出了一个更一般的判断:在持续运行的智能体系统里,预测不一定只是为了规划,也可以是为了回忆。代码仓库在Github上,论文页面是https://arxiv.org/abs/2510.08553
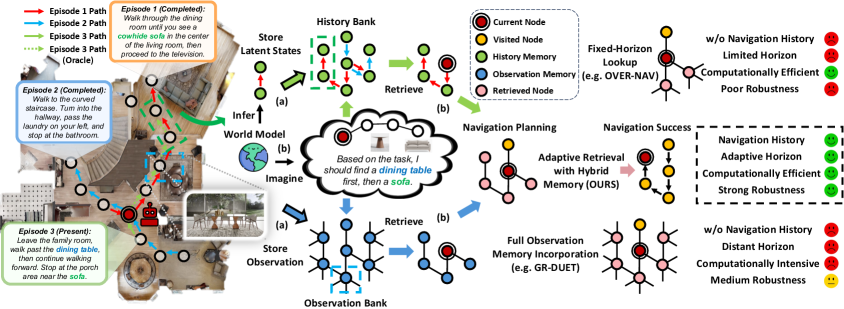
图 1:Memoir 的总体流程。前几轮导航先把经验存进记忆库,当前轮次则通过“想象未来状态”去检索最相关的环境观察和历史行为模式。
1. 为什么这篇论文值得读
要理解 Memoir,先要回到视觉语言导航,也就是 VLN。这个方向的经典起点通常追溯到 2018 年提出的 R2R 数据集。R2R 的任务定义很直观:给定一段自然语言指令,例如“走出客厅,穿过走廊,在右手边第二个房间门口停下”,智能体必须在真实室内场景的离散视点图上完成导航。R2R 的意义非常大,因为它第一次把语言理解、视觉感知和动作决策严密地绑在了一起,建立了后续大部分具身导航研究的公共测试床。但它也有一个天然局限:每个 episode 都是独立的,智能体在每轮任务开始时都会被“清空记忆”,因此它更像是在测试冷启动能力,而不是长期驻留能力。
这个设定与真实机器人所面对的世界并不一致。家庭服务机器人、楼宇巡检机器人或者医院配送机器人,并不会每天都在一个从未见过的全新环境里工作;恰恰相反,它们往往长期活动在同一栋楼、同一层病区或者同一套房屋中。也正因为如此,2023 年的 Iterative Vision-and-Language Navigation 工作提出了 IVLN/IR2R 范式,强调在持久环境中跨 episode 积累经验。它的核心问题不再只是“你能不能根据这一句指令走对”,而是“你会不会因为已经在这里来过很多次,而逐渐走得更快、更稳、更像一个熟悉环境的人”。Memoir 所对准的正是这个更接近现实的设定。
但“有记忆”并不等于“会用记忆”。这也是 Memoir 论文一开头就抓住的症结。现有 memory-persistent VLN 方法大致走了两条路:第一条是把积累到的历史观察几乎整包塞回模型,让模型自己消化;第二条是只在当前点附近做一个固定范围的局部查找。前者的问题是信息冗余过重,记忆越多,噪声越大,计算代价也越高;后者的问题是检索范围过死,模型可能根本碰不到真正有用的经验。更关键的是,很多方法只存“我曾经看见过什么”,却没有认真存“我在那时为什么那样走、那样停、那样转向”。而在导航里,行为模式本身就是知识,不只是副产品。
2. Memoir 到底改了什么
Memoir 的思路可以概括成一句更准确的话:它不是让智能体“直接回忆过去”,而是先让智能体“想象自己接下来可能会遇到什么”,再根据这段想象去调用经验。这个设计非常接近人的日常导航心理。当一个人准备在一套不完全熟悉的房子里去找“靠书桌最近的卧室”时,他不会盲目翻出脑海里所有看过的卧室画面,而是会先粗略想象一下接下来的路和目标特征,然后再联想到哪些旧经验真正相关。Memoir 把这种“先预测、再提取”的认知顺序形式化为了一个模型流程。
这种改动看似只是一层检索机制,实际上却改写了 world model 在系统中的角色。传统世界模型常被视作潜在空间中的环境替身,价值在于“少和真实环境交互,也能做规划或学习”;Memoir 则把世界模型重新变成了一个“神经搜索引擎”。它不需要把 imagined future 完整展开成一条可执行轨迹,也不要求生成高度逼真的未来观测,而是要求想象出的潜在状态足够像一个有效查询,能帮系统从长期记忆中筛出最相关的观察和行为模式。换言之,Memoir 的世界模型重点不是“替你走路”,而是“帮你找对过去的经验”。
在这个框架下,论文提出了三个核心部件。第一是语言条件化的世界模型,它既负责把当前经历编码成潜在状态,也负责向前想象未来状态。第二是混合视点级记忆,也就是 HVM,它把环境观察和导航行为都绑定到视点上,形成双记忆库。第三是经验增强的导航模型,它把当前观测、检索到的历史观察以及历史行为模式分别编码,再动态融合成最终动作分数。三者配合起来,形成的不是“记忆越多越好”的堆料系统,而是“记忆能否被正确调用”的检索系统。

图 2:Memoir 的方法结构。上半部分是语言条件化世界模型的状态推断与未来想象,下半部分是观测检索、历史检索与三分支导航决策。
3. 语言条件化世界模型:它并不是在“生成画面”
很多人看到“世界模型”四个字,第一反应是图像生成或者视频预测,但 Memoir 的实现重点并不在重建像素,而在潜在状态的判别性。论文采用了 RSSM 风格的状态空间建模框架,并把它做成四个子模块:一个推断模型负责根据当前视觉输入和语言指令推断出当前潜在状态;一个转移模型负责从当前状态向前滚动,想象接下来的状态;一个兼容性模型负责度量某个潜在状态与某个观察之间是否匹配;一个奖励模型则用来预测距离目标有多近,从而决定想象何时停止。这里的“奖励”在导航语境下可以理解成一种目标接近度信号,而不是强化学习中狭义的长期回报。
这套世界模型最值得注意的地方有两点。第一,它显式引入了语言条件。也就是说,潜在状态并不是只描述“我站在什么视觉位置”,还会被“我要去哪里、我要找什么”所调制。第二,它使用对比学习而不是像素重建来训练状态与观察的一致性。换句话说,模型不必把未来的房间长什么样一张张生成出来,它只要学会判断“这个 imagined state 更像不像某类目标位置”就足够了。对于检索任务来说,这样的潜在空间反而更合适,因为它强调的是可比较、可匹配,而不是画面逼真度。
论文还加入了多步 overshooting 训练目标,这是一个很关键但容易被忽略的技术点。普通一步状态转移只要求模型在很短的滚动范围内保持合理,而检索却往往需要更长的预测视野,因为有价值的记忆不一定就藏在眼前一两跳。通过多步 overshooting,Memoir 强迫世界模型在更远的预测范围内维持潜在状态的一致性,使 imagined trajectory 不至于一滚就飘。对这篇论文来说,overshooting 的意义并不只是提升建模指标,而是直接关系到检索质量:如果你的预测本身不稳,那么后面所有“按图索骥”的记忆调用都会失真。

4. 混合视点级记忆:既存环境,也存决策
Memoir 的记忆模块之所以叫“混合视点级记忆”,关键在“混合”二字。论文把长期记忆拆成两个互补的库。第一个是 Observation Bank,用来存每个视点的环境观察特征,本质上回答“我在这里看见过什么”;第二个是 History Bank,用来存该视点对应的潜在状态以及从这个状态向前展开的 imagined trajectory,本质上回答“当我处在这里、面临类似任务时,系统曾经倾向于往哪想、往哪走”。前者提供视觉与拓扑背景,后者提供策略与行为模式,这正是过去很多方法没有同时处理好的两类知识。
为什么一定要把这两类信息都锚定在视点上,而不是简单按 episode 堆叠?因为视点是导航中最稳定、最可复用的单位。一个房屋结构可能在几十轮任务中都不变,同一个走廊入口可能反复出现,但任务目标和到达顺序却会变化。如果记忆只按整段轨迹存储,那么模型在调用时很难知道该从哪一段切进去;如果只按画面碎片存储,又会丢掉动作逻辑。把观察和行为模式共同绑定到视点,等于为长期记忆建立了一套“既有地理坐标、又有经验标签”的索引系统,这也是 Memoir 能同时检索“看见过什么”和“怎么做过”的结构基础。

在实际运行时,这两个记忆库会随着 episode 持续更新。智能体每到一个新视点,就把当前视点特征写入 Observation Bank,把由世界模型推断出的当前状态以及从此刻向前想象出的短轨迹写入 History Bank。这里有一个非常漂亮的设计对称性:同一个世界模型,一方面负责把经验编码成可存储的潜在状态,另一方面又负责在推理时生成检索查询。也就是说,存储语言和检索语言是统一的,它们都在同一个潜在空间里完成,这就避免了“训练时这样编码、检索时却用另一套表达”的常见错位。
5. 观测检索和历史检索是怎样工作的
环境观测检索的逻辑并不复杂,但很讲究分层搜索。Memoir 不是把整张持久图上的所有节点拿出来逐个打分,而是按 imagined trajectory 的步数逐层往外找。对于想象出来的第 i 步状态,模型会去当前视点的 i 阶邻域里筛候选视点,再用状态和观察之间的兼容性分数进行过滤。这样做的好处是显而易见的:如果系统想象自己三步后可能会到达某类空间,它优先比较的就是图上三跳范围内的相关节点,而不是把远在另一端的无关观察也纳入同一轮竞争。随后,论文又用分位数过滤和宽度限制控制保留比例,既避免一层筛得过宽,又防止层层传播把图扩张得失控。
更进一步,Memoir 在选中高分节点之后,不是只把这些节点本身塞回当前 episode 图,而是把从当前位置到这些节点的最短路径一并补全回来。这一点很重要,因为导航不是一个只看终点、不看连通关系的匹配问题。一个目标视点即使看起来再像,也必须在当前可行拓扑中有一条合理通路,才能真正帮助决策。论文后面的消融实验也证明了这一点:只检索单个视点不如把邻接关系和中间路径一起拉回来,后者能显著提高 SPL,因为它提供的是更完整的规划上下文,而不只是零散的视觉提示。
历史检索则更像是在匹配“未来走势”而不是静态相似度。系统会把当前 imagined trajectory 与过去存储在 History Bank 中的轨迹模式逐步对齐,只要每一步的状态相似度持续高于阈值,就继续向后匹配;一旦某一步明显不相似,就在那一刻停止。这种逐段匹配比整段轨迹的全局语义相似度更有意义,因为它允许模型只借用过去经验中真正对应当前阶段的那一截,而不是整条照搬。换成更通俗的话说,Memoir 不是在问“以前有没有人做过这道题”,而是在问“以前有没有人从我现在这个局面出发,前面几步的判断方式和我当前设想很接近”。
…详情请参照古月居

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)