
ICLR 2026|Information Gain-based Policy Optimization:用信息增益训练多轮搜索智能体
最终,IGPO 使用与 GRPO 类似的 clipped surrogate objective 更新策略,但不再把同一个 rollout-level advantage 分配给整条输出,而是把每一轮的 discounted return 分配给该轮产生的 decision tokens。在 Qwen2.5-3B-Instruct 上,outcome-only 的平均 F1 为 32.3,IG-o
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
蚂蚁集团
-
论文题目:INFORMATION GAIN-BASED POLICY OPTIMIZATION: A SIMPLE AND EFFECTIVE APPROACH FOR MULTITURN SEARCH AGENTS
-
第一作者:王国庆
-
发表会议:ICLR 2026
-
论文链接:https://arxiv.org/pdf/2510.14967
-
代码链接:https://github.com/GuoqingWang1/IGPO

点击阅读原文查看作者讲解
基于大语言模型的智能体正在从“回答问题”走向“主动使用工具”。在多轮搜索场景中,模型需要先理解问题,再调用搜索工具、阅读返回结果、继续追问或改写查询,最后给出答案。
为了让模型学会这种搜索和推理行为,研究人员通常会使用强化学习(Reinforcement Learning, RL)进行训练。现有方法中,Group Relative Policy Optimization(GRPO)一类算法非常常见:对同一个问题采样多条轨迹,然后根据最终答案是否正确给出奖励。
然而,只看最终答案在多轮任务中会显得过于粗糙。最终答错,并不代表中间每一步都没有价值;最终答对,也不代表中间过程都可靠。如果训练信号只出现在最后一刻,模型很难知道到底是哪一次搜索、哪一段推理真正帮助它接近了正确答案。
更糟糕的是,当同一组 rollout 全部答错或全部答对时,它们会得到相同的 outcome reward。经过组内归一化后,相对优势可能直接变成 0,模型几乎收不到有效梯度。这就是多轮智能体训练中常见的 advantage collapse。
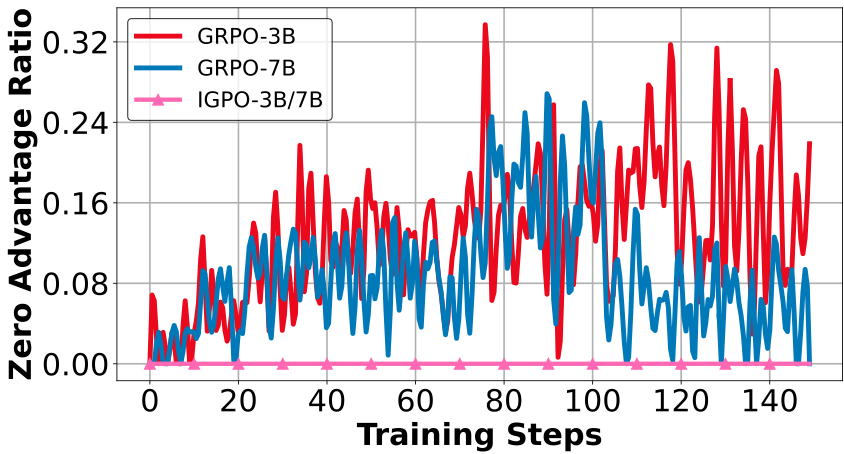
图 1. GRPO 与 IGPO 在训练过程中 zero-advantage group 的比例对比。传统 outcome-only 奖励在多轮任务中容易出现组内奖励完全相同的情况。
为了解决这个问题,本文提出了 Information Gain-based Policy Optimization(IGPO)。IGPO 的核心思想很直接:把智能体的每一轮交互都看成一次“获取信息”的过程。如果某一轮搜索或推理让模型更相信真实答案,那么这一轮就应该得到正奖励;如果这一轮让模型偏离真实答案,则应该得到负奖励。
与依赖外部过程奖励模型、人工标注或 Monte Carlo 估计的方法不同,IGPO 直接使用模型自身对 ground-truth answer 的概率变化来构造逐轮奖励。因此,它既能提供更密集的训练信号,又不需要额外训练 reward model。
本文的主要贡献有如下三点:
1. 新奖励:本文提出基于信息增益的逐轮奖励,将多轮搜索智能体的每一次交互都转化为可优化的训练信号。
2. 新框架:本文将信息增益奖励与最终答案奖励结合,并通过组内归一化和逐轮折扣回报,实现更细粒度的信用分配。
3. 新结果:在多个 in-domain 和 out-of-domain 搜索问答基准上,IGPO 一致超过强基线,并显著提升样本效率,尤其对较小模型更加有效。
接下来,本文将从新奖励、新框架、新结果三个角度,简要介绍 IGPO 如何训练多轮搜索智能体。
1
新奖励:用信息增益给每一轮打分
在本文的任务设定中,数据集由问题和标准答案组成。智能体面对一个问题 q,需要通过外部工具 E(例如搜索引擎)进行多轮交互。前面的 turn 通常包含 [think]、[tool call] 和 [tool response],最后一个 turn 则输出最终答案。
传统 outcome reward 只在最终答案处给一个分数。论文中使用的最终奖励主要是答案与 ground truth 的 word-level F1,如果格式错误,则给一个负的格式惩罚。这个设计简单有效,却很难回答一个关键问题:中间哪一轮是有帮助的?
IGPO 的回答是:看这一轮之后,模型生成真实答案的概率是否提高了。具体来说,对于第 i 条 rollout 的第 t 轮,IGPO 会在当前上下文 q 和 o_i,≤t 下计算模型生成标准答案 a 的平均 log probability。这里使用 teacher forcing,也就是把标准答案放进去,观察模型当前有多“相信”这个答案。
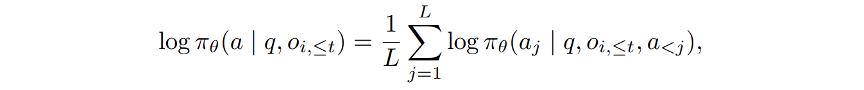
Equation. (3),真实答案的平均 log probability
有了这个概率之后,IGPO 将第 t 轮的信息增益定义为相邻两轮 log probability 的差值。如果第 t 轮之后模型对真实答案的log probability 变高了,说明这一轮带来了有用信息;如果变低了,说明这一轮可能把模型带偏了。
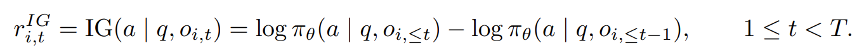
Equation. (4) ,信息增益逐轮奖励
这个定义带来了三个好处。首先,它是 ground-truth aware 的:奖励直接围绕真实答案计算。其次,它是 dense 的:每一轮交互都会产生奖励。第三,它不需要额外的过程奖励模型,也不需要大量额外采样。
当然,最终答案仍然重要。只优化信息增益可能会让模型关注局部过程,而忽视最后的任务目标。因此,IGPO 保留outcome reward,并将它与逐轮信息增益奖励结合起来。
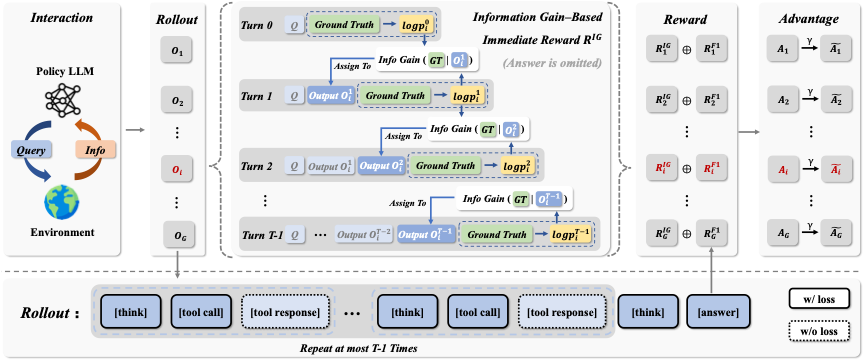
图 2. IGPO 的整体训练流程。逐轮信息增益奖励与最终答案奖励结合,形成 turn-level discounted return,再用于策略优化。
2
新框架:从即时奖励到长期信用分配
在实际训练中,IGPO 不会直接把原始信息增益和最终 F1 混在一起。原因是二者的尺度不同:信息增益来自 log probability 的变化,而最终答案奖励通常是 0 到 1 之间的 F1 分数。
因此,IGPO 对信息增益奖励和 outcome reward 分别做 group-wise z-normalization。这样既保留了组内相对比较,也避免了两类奖励因为数值尺度不同而互相干扰。
此外,一轮搜索动作的影响不一定只体现在当前 turn。一次好的搜索可能为后面几轮提供关键证据;一次错误的查询也可能让后续推理持续偏离。因此,IGPO 沿时间维度计算 turn-level discounted return,将未来奖励折扣累积到当前 turn 上。
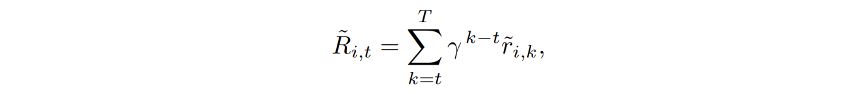
Equation. (6),逐轮折扣回报
最终,IGPO 使用与 GRPO 类似的 clipped surrogate objective 更新策略,但不再把同一个 rollout-level advantage 分配给整条输出,而是把每一轮的 discounted return 分配给该轮产生的 decision tokens。工具返回内容来自外部环境,不是模型决策,因此训练时会被 mask 掉。
为了避免逐轮计算 log probability 带来过高开销,论文还提出了向量化实现:将多份 ground-truth answer 追加到轨迹末尾,并设计自定义 attention mask,让每份答案只能看到对应轮次之前的上下文。这样,所有轮次的信息增益可以在一次forward 中同时计算。
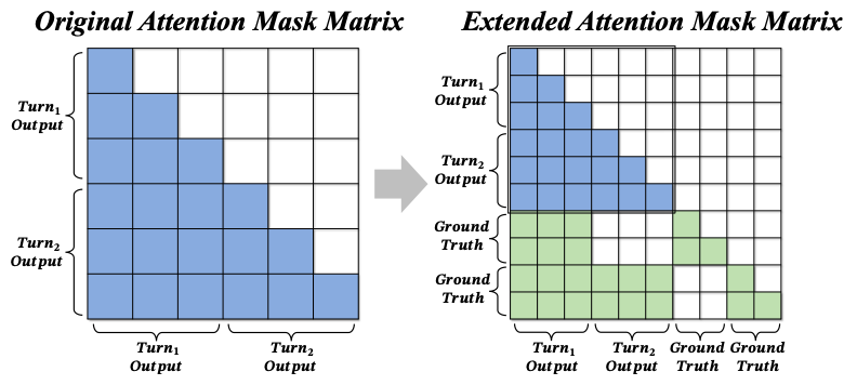
图 3. IGPO 的向量化实现。通过自定义 attention mask,一次 forward 即可计算多轮信息增益。
3
新结果:更准,也更省样本
为了验证 IGPO 的效果,论文在多轮搜索问答场景中进行了系统实验。in-domain 数据集包括 NQ、TQ、HotpotQA 和2Wiki,out-of-domain 数据集包括 MusiQue、Bamboogle 和 PopQA。评价指标为 word-level F1。
主实验使用 Qwen2.5-7B-Instruct 作为 backbone,并使用 verl 框架进行训练。训练时每个 step 采样 32 个 prompt,每个prompt 采样 16 条 rollout,最大工具调用轮数为 10,搜索工具使用 Google Search API。
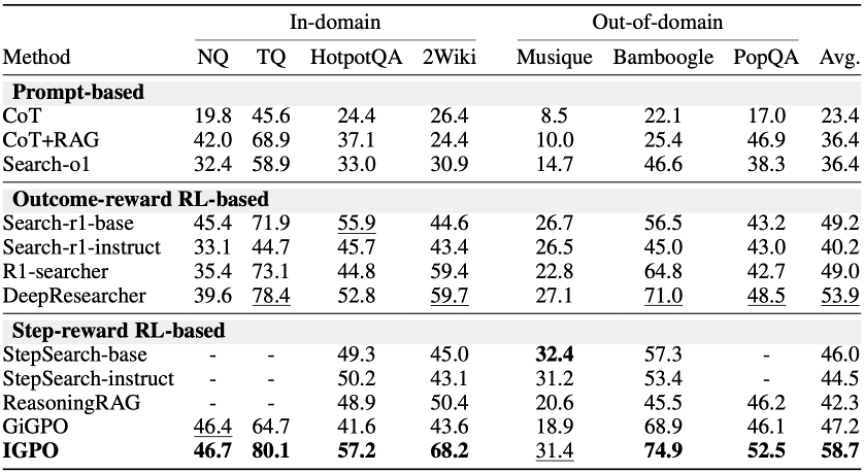
表 1. IGPO 与 prompt-based、outcome-reward RL-based、step-reward RL-based 搜索智能体方法的对比。IGPO 在 7 个数据集上的平均 F1 达到 60.2,超过 DeepResearcher 的 53.9。
从结果可以看到,训练型方法整体显著强于纯 prompt 方法,说明搜索智能体不能只依赖提示词工作流,显式的策略优化非常关键。
在训练型方法内部,现有 step-reward 方法虽然能够提供过程信号,但往往依赖外部知识、reward model 或高方差估计,整体稳定性不足。IGPO 则直接利用模型自身对真实答案的概率变化,因而能够在多个数据集上稳定提升。
论文还将 IGPO 与常见 RL 算法进行了相同配置下的对比。GRPO 的平均 F1 为 51.9,GSPO 为 52.0,PPO 为 51.5,而IGPO 达到 60.2。这说明 IGPO 的收益并不只是来自某个训练技巧,而是来自更细粒度、更稳定的奖励设计。
4
消融实验:信息增益和最终奖励是互补的
论文进一步比较了不同奖励组合:只使用最终 F1 奖励、只使用信息增益奖励,以及同时使用 F1 + IG。结果非常清楚:单独使用任意一种奖励都不如二者结合。
在 Qwen2.5-3B-Instruct 上,outcome-only 的平均 F1 为 32.3,IG-only 为 34.6,而 F1 + IG 达到 48.9。在 Qwen2.5-7B-Instruct 上,outcome-only 为 51.9,IG-only 为 53.5,而 F1 + IG 达到 60.2。
这说明,最终答案奖励负责锚定任务目标,信息增益奖励负责提供中间过程信号。二者结合后,模型既知道最终要答对,也知道哪些中间步骤更可能把它带向正确答案。
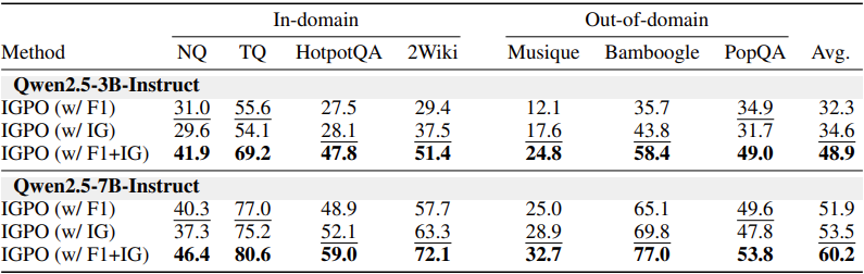
表 2. 不同奖励设计的消融结果。IGPO (w/ F1+IG) 在 3B 和 7B 模型上都取得最优结果,且对较小模型提升更明显。
5
为什么 IGPO 学得更有效
论文还从训练动态角度分析了 IGPO 的作用。一个关键现象是:相比 GRPO,IGPO 能让模型在训练过程中更持续地降低真实答案熵。这说明逐轮信息增益确实在鼓励中间搜索和推理步骤朝着正确答案分布移动。
另一个重要指标是 token efficiency,也就是每使用一定数量的训练 token,模型性能能提升多少。多轮智能体训练往往非常昂贵,因为 rollout 长、工具调用多、采样成本高。实验显示,IGPO 在相同训练 token 下取得更高 F1,且随着训练推进,与 GRPO 的差距持续扩大。
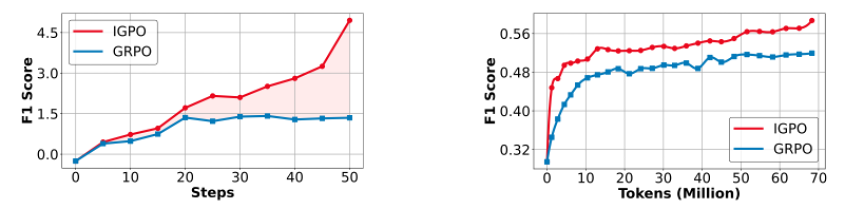
图 4. IGPO 与 GRPO 的 token efficiency 对比。IGPO 在相同训练 token 下取得更高性能,说明逐轮信息增益提高了样本利用率。
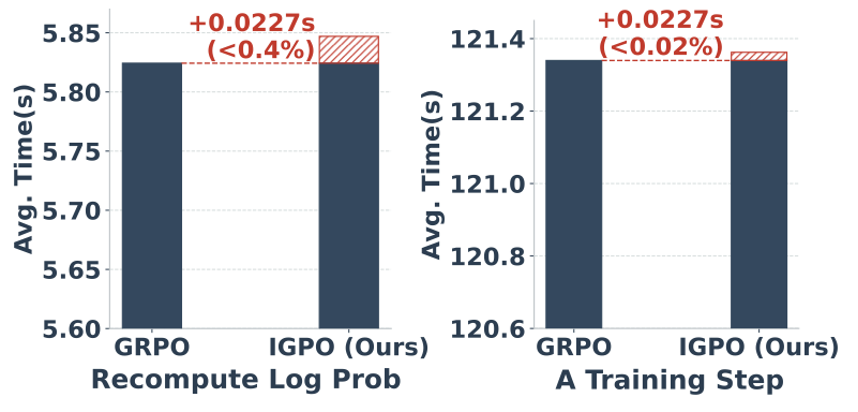
图 5. IGPO 的额外计算开销。信息增益奖励计算的相对开销小于 0.4%,端到端训练延迟增加小于 0.02%。
6
局限:当标准答案不唯一时会放大标注噪声
IGPO 的奖励依赖 ground-truth answer,因此它天然要求训练数据中存在明确、可靠的标准答案。这一点在搜索问答任务中通常成立,但在开放式写作、真实网页操作、复杂工具协作等场景中并不总是成立。
如果问题本身有歧义,或者多个答案都可以被认为是正确的,IGPO 可能会惩罚事实上合理但不匹配标注答案的轨迹。论文中给出了一个例子:问题是 “Who is the author of Childhood?”,但 Childhood 可以指不同作品。模型检索到 Nathalie Sarraute 的 Childhood 虽然在某种解释下合理,却不匹配数据集标注的 Leo Tolstoy,因此会得到负的信息增益。
这说明 IGPO 会放大高质量数据的收益,也会放大 noisy ground truth 的负面影响。对真实应用而言,未来可能需要结合答案去歧义、多参考答案、软标签或人工审核机制,才能把信息增益奖励推广到更开放的任务。
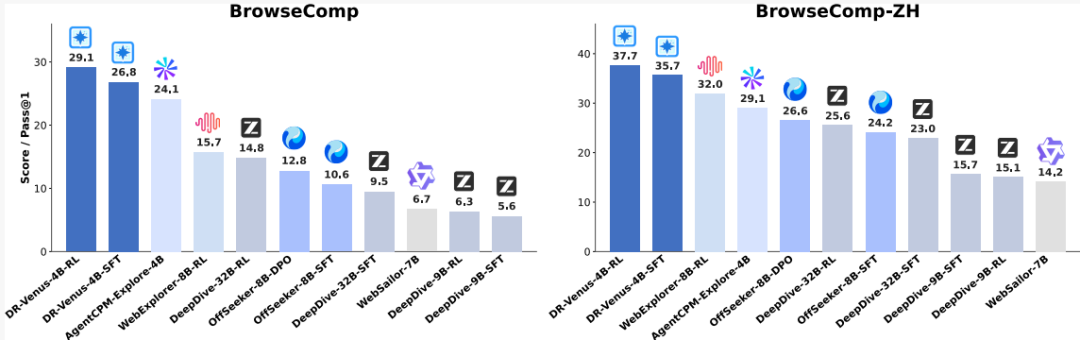
图 6.此外,研究团队还成功训练出了一个小而精的面向端侧部署的Deep Research Agent——DR-Venus-4B (https://huggingface.co/collections/inclusionAI/dr-venus)。
7
总结
本文提出了 Information Gain-based Policy Optimization(IGPO),一个面向多轮搜索智能体的简单有效 RL 框架。IGPO 的核心不是重新设计复杂的 agent 架构,而是重新思考奖励应该出现在什么位置:除了最终答案,每一轮交互本身也应该被评估。
通过将“模型对真实答案的信心是否提升”转化为逐轮信息增益奖励,IGPO 为多轮搜索轨迹提供了更密集、更细粒度的监督信号。它缓解了 outcome reward 的稀疏性、advantage collapse 和信用分配困难,同时通过向量化实现保持了几乎可以忽略的额外计算开销。
实验结果表明,IGPO 在多个 in-domain 和 out-of-domain 问答基准上稳定超过强基线,并显著提升样本效率。尤其对于较小模型,逐轮过程信号能够更有效地帮助模型学习如何搜索、如何修正查询、如何逐步接近正确答案。
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播回放!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)