
多 Agent 入门:为什么一个智能体不够用?
文章摘要: 多Agent系统通过任务分解和协作编排解决单Agent臃肿问题。核心思路是将复杂任务拆分为专业Agent,采用两种协作模式:ToolCalling(主管调度)和Handoffs(接力交接)。系统包含三个基础组件:ReactAgent(专业单元)、FlowAgent(编排控制)和OverAllState(全局状态)。编排模式包括并行(ParallelAgent)、串行(Sequentia
做 Agent 应用时,一个很容易遇到的问题是:单个 Agent 承担的事情越来越多。
一开始只是回答问题,后面可能要查工具、做规划、调用接口、整理结果、生成报告。职责一多,Agent 就会变得臃肿:工具选择更难、上下文更长、专业能力也容易混在一起。
Multi-Agent 的思路,就是把复杂任务拆成多个专业 Agent,再通过编排方式让它们协同工作。
为什么需要多智能体
多智能体编排解决的不是“炫技问题”,而是复杂任务拆分问题。
单个 Agent 处理所有任务时,主要会遇到三类问题:
-
工具过多:一个 Agent 拥有太多工具,模型很难稳定做出正确选择
-
上下文过长:对话、记忆和中间状态不断增长,后续跟踪成本变高
-
缺少专业性:复杂任务往往需要规划、研究、分析、评审等不同角色
拆成多个 Agent 后,每个 Agent 只专注一个领域。这样不仅职责更清楚,也方便独立调试、替换和升级。
多 Agent 编排的核心价值
把它归纳成四点:
1. 专业化分工
每个 Agent 专注一个领域,能力更集中。
2. 流程编排
可以像流水线一样,让上一个 Agent 的输出成为下一个 Agent 的输入。
3. 并行提速
互不依赖的任务可以同时执行,减少总耗时。
4. 可维护性
每个 Agent 职责单一,后续定位问题和替换组件更容易。
可以把它想成团队协作:有人负责写,有人负责审,有人负责查资料,有人负责汇总。不是每个人都做所有事,而是每个角色做好自己的部分,再通过流程串起来。
既然已经拆成了多个角色,接下来就会遇到一个问题:这些 Agent 到底怎么协作?是由一个总控统一调度,还是当前 Agent 处理完以后把任务交给下一个 Agent?这就引出了两种常见协作方式。
两种协作方式:Tool Calling 和 Handoffs
多 Agent 协作里,有两个常见模式。
**Tool Calling** 更像“主管调工具”。Supervisor Agent 把其他 Agent 当作工具来调用,工具 Agent 不直接和用户交互。它比较适合任务编排、结构化工作流这类集中式调度场景。
**Handoffs** 更像“接力交接”。当前 Agent 决定把控制权交给另一个 Agent,用户后续可能直接和新的 Agent 交互。它适合跨领域对话、专家接管等场景。

协作方式解决的是“谁来调谁”的问题。再往下落到代码实现,还需要几个基础组件来承载 Agent、流程和状态。
三个核心组件
多 Agent 编排里有三个基础概念:
ReactAgent
最基础的子 Agent 单元。每个专业 Agent 都可以看作一个 ReactAgent 实例。
FlowAgent
负责编排多个 ReactAgent 协作,比如 SequentialAgent、ParallelAgent、RoutingAgent。
OverAllState
全局状态容器。所有 Agent 的输出都可以通过 `outputKey` 存进去,后续 Agent 再通过占位符或状态读取出来。
这里最关键的是数据怎么流动:每个 Agent 处理完,把结果存入状态;后续 Agent 通过 `outputKey` 或 `{key}` 占位符拿到前面的结果。
先把这三个组件认清楚,再看 ReactAgent 的参数会更容易。因为每一个子 Agent 都要有自己的名字、职责、指令和输出键,这些信息会直接影响后面的流程编排。
ReactAgent Builder 参数
ReactAgent 是最基础的子 Agent 单元,后面的串行、并行、路由,底层都会用到它。
几个参数需要先记住:
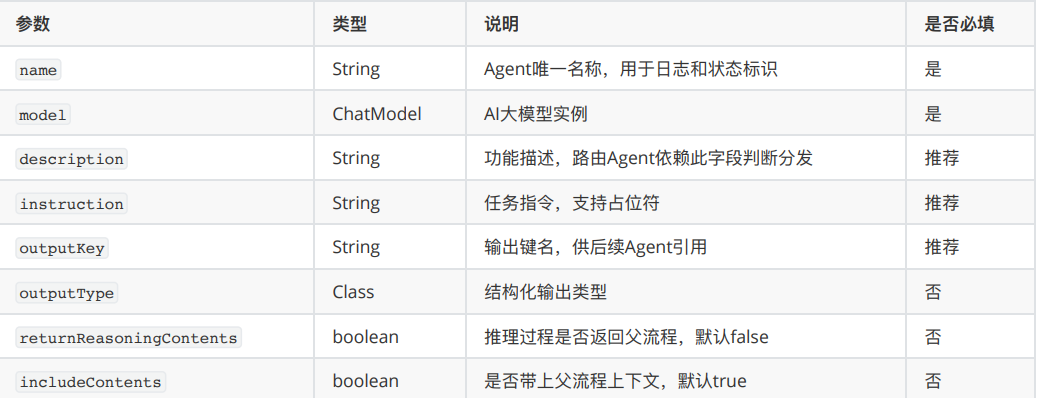
这里最容易忽略的是 `description` 和 `outputKey`。
`description` 不只是注释,后面 RoutingAgent 做智能分发时会依赖它。
`outputKey` 也不是随便起名,后续 Agent 要靠它读取状态,所以命名要清晰。
有了基础 Agent,下一步就是决定多个 Agent 如何排队、并行或分发。不同任务关系,对应不同编排模式。
常见编排模式
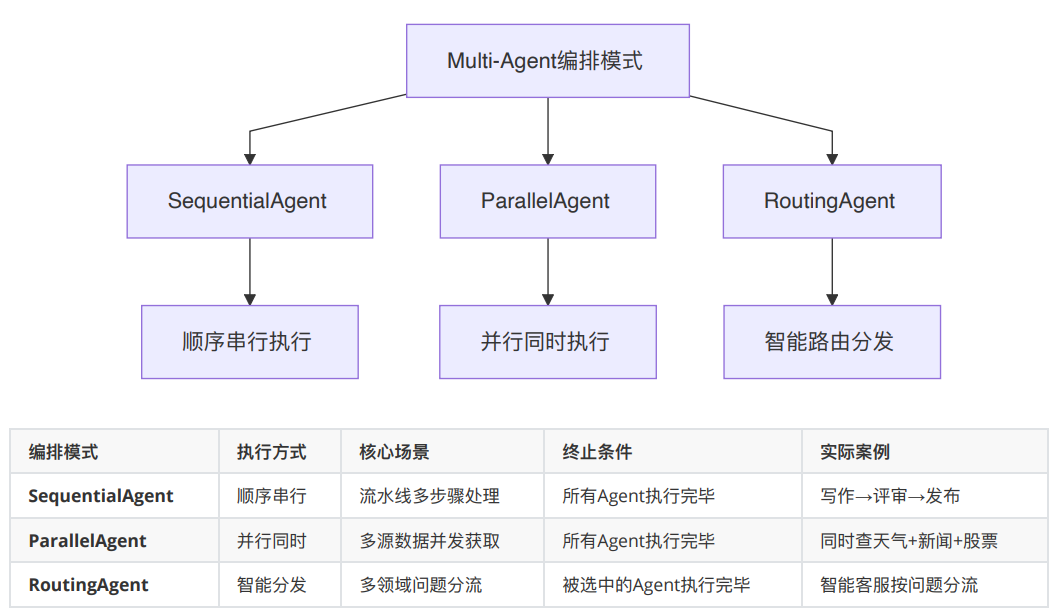
简单判断方式是:
- 有前后依赖,用 SequentialAgent
- 可以同时做,用 ParallelAgent
- 输入类型不同,用 RoutingAgent
- 需要反复优化,用 LoopAgent
不管选择哪种编排方式,Agent 之间都绕不开一个问题:前一个 Agent 的结果,后一个 Agent 怎么拿到?这就是上下文工程和状态传递要解决的事情。
上下文工程与状态传递
Multi-Agent 设计里很关键的一点是:上下文工程决定每个 Agent 能看到什么信息。
每个 Agent 不一定需要看到全部历史,它需要看到的是完成当前任务所需的正确信息。
这通常包括:
- 哪些对话或状态要传给当前 Agent
- 给每个子 Agent 定制什么提示词
- 是否包含中间推理内容
- 每个 Agent 的输入、输出格式如何定义
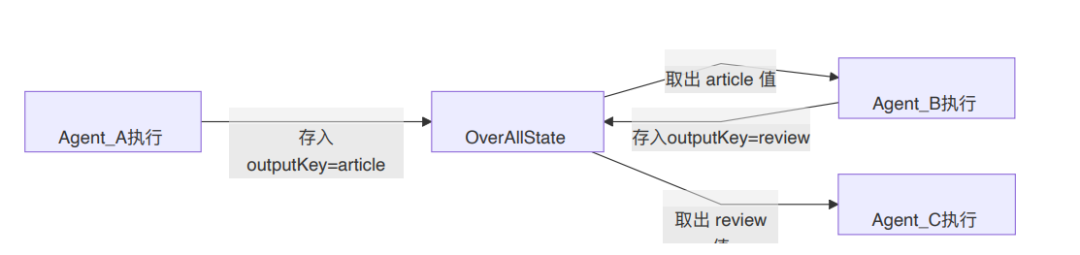
`OverAllState` 就像一个共享文件柜。Agent A 完成后通过 `outputKey=article` 存入结果,Agent B 的 instruction 里就可以用 `{article}` 引用它。
OverAllState 状态容器
`OverAllState` 是多 Agent 系统里的全局状态容器,也就是所有 Agent 共享的数据中心。
它的核心能力有三个:
1. 存储输出
每个 Agent 通过 `outputKey` 把结果存入 State。
2. 读取数据
可以通过 `state.value("key")` 获取任意 Agent 的输出。
3. 占位符替换
`instruction` 中的 `{key}` 会自动从 State 中查找对应值并替换。
可以把数据流理解成这样:
占位符机制
在 Multi-Agent 系统中,`instruction` 支持使用占位符动态引用状态中的数据。
常见占位符有:

占位符的工作原理:
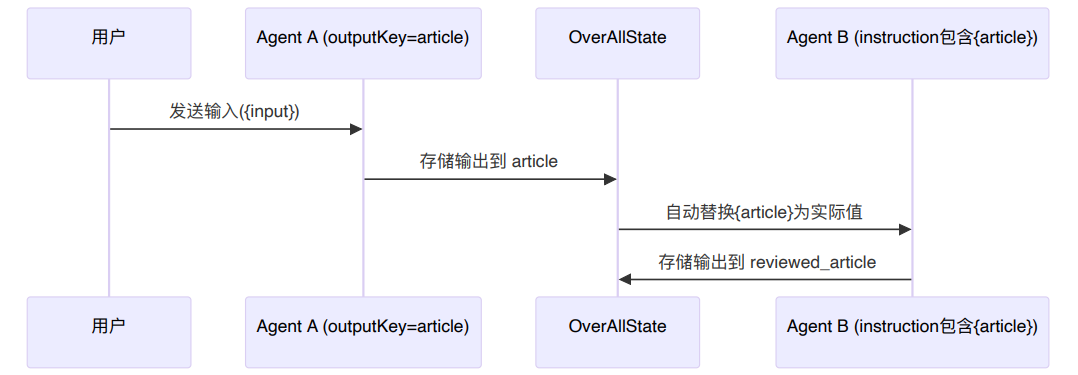
- 自动替换:执行 Agent 的 instruction 时,系统会把占位符替换成实际值
- 状态查找:占位符会从 `OverAllState` 中查找对应 key
- 字符串插入:查到的值会被转换为字符串插入 instruction
- 保留原文:如果对应值不存在,系统会保留原始占位符文本,不会直接报错
这一点在调试时很有用。如果发现 `{article}` 没有被替换,优先检查前置 Agent 的 `outputKey` 是否拼写一致。
// 第⼀个Agent:使⽤ {input} 获取⽤户输⼊
ReactAgent writerAgent = ReactAgent.builder()
.name("writer_agent")
.instruction("你是⼀个知名的作家。请根据⽤户的提问进⾏回答:{input}。")
.outputKey("article")
.build();
// 第⼆个Agent:使⽤ {article} 引⽤第⼀个Agent的输出
ReactAgent reviewerAgent = ReactAgent.builder()
.name("reviewer_agent")
.instruction("请对⽂章进⾏评审修正:\n{article},最终返回评审修正后的⽂章内容")
.outputKey("reviewed_article")
.build();
// 第三个Agent:同时引⽤多个Agent的输出
ReactAgent summaryAgent = ReactAgent.builder()
.name("summary_agent")
.instruction("""
请根据以下信息⽣成最终总结:
⽤户原始需求:{input}
原始⽂章:{article}
评审后⽂章:{reviewed_article}
请对⽐原始⽂章和评审后⽂章的差异,⽣成改进总结报告。
""")
.outputKey("summary")
.build();占位符和 outputKey 的最佳实践
1. 命名要明确
使用 `article`、`review_result`、`weather_data` 这类有意义的名字,避免 `output1`、`result`。
2. 占位符要和 `outputKey` 一致
如果前面写的是 `outputKey("article")`,后面就应该用 `{article}`。
3. 一个 instruction 可以引用多个值
比如汇总 Agent 可以同时引用 `{weather_data}`、`{news_data}`、`{stock_data}`。
4. 注意上下文长度
多值引用会把多个 Agent 的输出塞进同一个 instruction,内容太长时要控制格式和长度。
把这些基础概念串起来以后,就可以进入具体编排模式了。先看 ParallelAgent,因为它的收益最直观:只要任务之间互不依赖,就可以并行执行,减少等待时间。
ParallelAgent:并行编排模式
先从 ParallelAgent 看起,因为它最容易体现多 Agent 的效率优势。
ParallelAgent 适合一类很常见的任务:多个子任务之间没有依赖,可以同时做,最后再把结果汇总起来。
比如同时查天气、新闻、股票数据。它们彼此不依赖,不需要“先查天气再查新闻”,所以没必要串行等待。
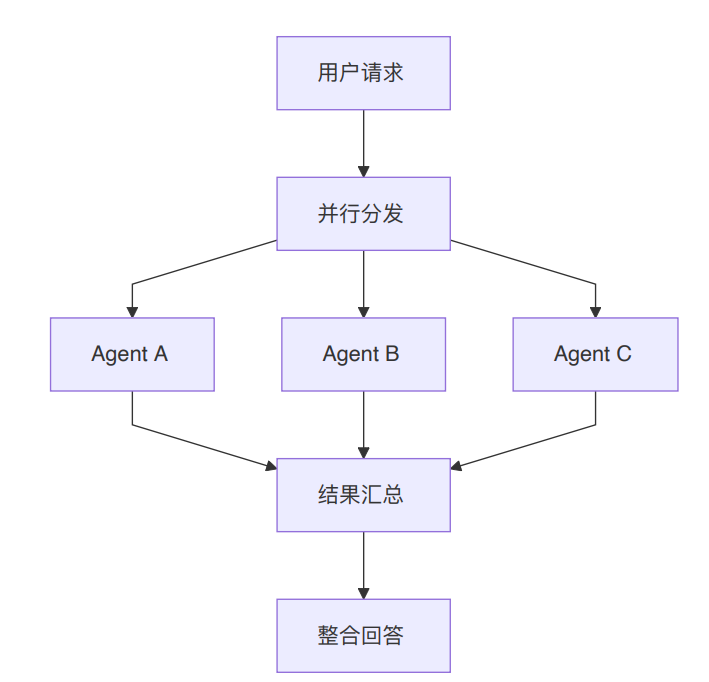
ParallelAgent 是什么
ParallelAgent 的核心定义是:多个 Agent 同时并行执行相同或不同任务,所有结果汇总后统一返回。
它像是把任务同时分给几个人做。每个人做自己的部分,全部完成后,再把结果放到一起。
它最大的优势是耗时。
如果三个 Agent 每个都要 3 秒:
- 串行执行:3 + 3 + 3 = 9 秒
- 并行执行:大约等于最慢的那个 Agent,用时约 3 秒
所以并行模式的总耗时,不是所有 Agent 耗时之和,而是取决于最慢的那个 Agent。
和串行模式的区别
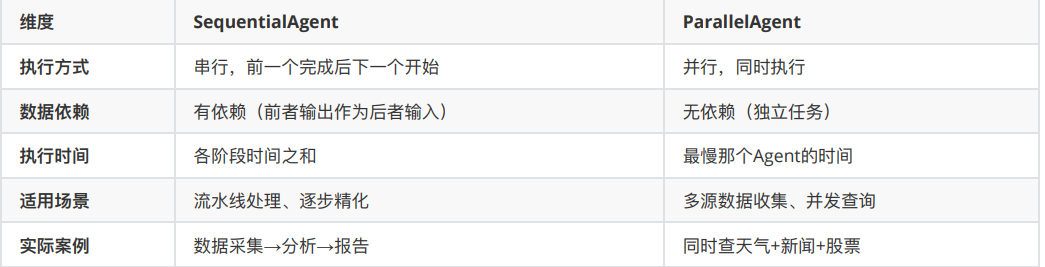
这里最容易用错的是“数据依赖”。如果 Agent B 需要 Agent A 的输出,那就不适合放在同一个 ParallelAgent 里,因为它们是同时执行的。
这种情况应该换成 SequentialAgent,或者采用“先并行采集,再串行汇总”的组合方式。
API 里要记住的点
ParallelAgent 的构建重点是 `subAgents(List.of(...))`,也就是把多个子 Agent 放进去并行执行。
每个子 Agent 必须有独立的 `outputKey`。否则多个 Agent 的结果可能互相覆盖。
// 构建 ParallelAgent
ParallelAgent parallelAgent = ParallelAgent.builder()
.name("parallel_agent") // Agent名称
.description("并⾏任务处理") // 描述说明
.subAgents(List.of(agentA, agentB)) // ⼦Agent列表,并⾏执⾏
.build();
// 调⽤执⾏
Optional result = parallelAgent.invoke("⽤户输⼊内容");真正重要的是它背后的数据规则:
- 所有子 Agent 同时启动
- 每个 Agent 把结果写入自己的 `outputKey`
- 所有结果最终汇总到 `OverAllState`
- 子 Agent 之间不能用占位符互相引用对方输出
多源数据采集案例
一个典型场景是市场监控:同时获取天气、新闻、股票三类信息。
可以拆成三个专业 Agent:
- WeatherAgent:负责查询和分析天气信息,输出到 `weather_data`
- NewsAgent:负责收集和整理财经新闻,输出到 `news_data`
- StockAgent:负责查询股票行情和分析走势,输出到 `stock_data`
这三个任务之间没有直接依赖,所以适合并行执行。
如果每个 Agent 耗时 3 秒,串行需要 9 秒;并行只需要约 3 秒。这个例子很直观地体现了 ParallelAgent 的价值。
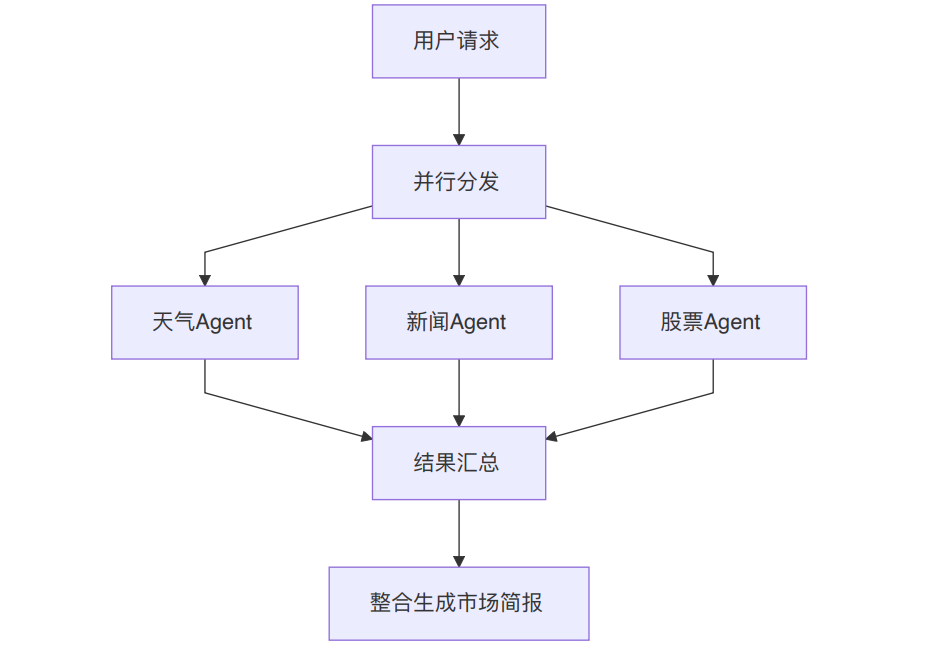
并行编排代码实现
@GetMapping("multi_agent2")
public void multiAgent2() throws Exception {
// 天气专业Agent
ReactAgent weatherAgent = ReactAgent.builder()
.name("WeatherAgent")
.model(chatModel)
.instruction("你专门负责查询和分析天气信息,请提供2020一整年的天气概况")
.outputKey("weather_data")
.build();
// 新闻专业Agent
ReactAgent newsAgent = ReactAgent.builder()
.name("NewsAgent")
.model(chatModel)
.instruction("你专门负责收集和整理最新财经新闻,请提供2020一整年的财经要闻")
.outputKey("news_data")
.build();
// 股票专业Agent
ReactAgent stockAgent = ReactAgent.builder()
.name("StockAgent")
.model(chatModel)
.instruction("你专门负责查询股票行情和分析走势,请提供2020一整年大盘概况")
.outputKey("stock_data")
.build();
ParallelAgent parallelAgent = ParallelAgent.builder()
.name("ParallelAgent")
.description("市场监控系统,并行采集多源数据,并行执行多个Agent")
.subAgents(List.of(weatherAgent, newsAgent, stockAgent))
.build();
Optional<OverAllState> result = parallelAgent.invoke("请提供2020年市场简报");
if (result.isPresent()) {
OverAllState overAllState = result.get();
//分别获取3个agent输出
overAllState.value("weather_data").ifPresent(weatherData -> {
log.info("======WeatherData======: {}", weatherData);
});
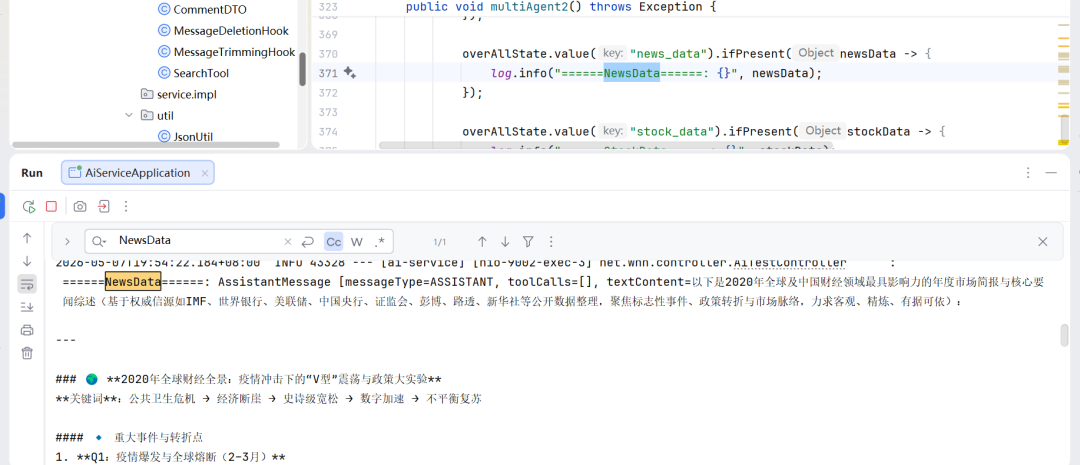
overAllState.value("news_data").ifPresent(newsData -> {
log.info("======NewsData======: {}", newsData);
});
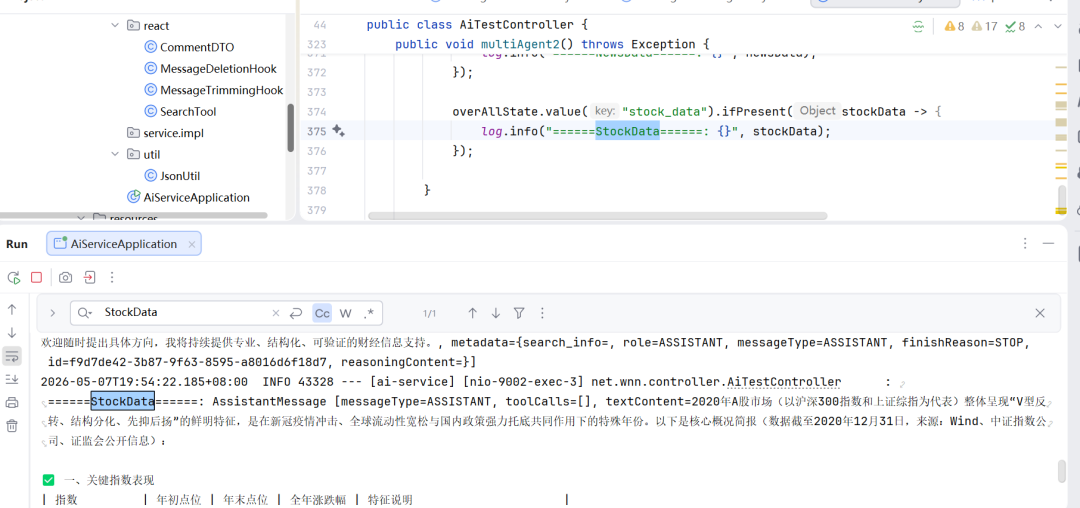
overAllState.value("stock_data").ifPresent(stockData -> {
log.info("======StockData======: {}", stockData);
});
}
}
使用 ParallelAgent 的注意点
1. 子 Agent 之间不能有数据依赖
如果有依赖,就应该使用 SequentialAgent。
2. 每个子 Agent 的 `outputKey` 必须唯一
比如 `weather_data`、`news_data`、`stock_data`,不要都叫 `result`。
3. 不要共享有状态的 Tool 实例
多个 Agent 并发执行时,共享状态可能带来互相影响。
4. 注意 API 调用频率和 Token 消耗
并行不是免费加速。三个 Agent 并行,本质上也是同时发起多次模型调用。
5. 单个 Agent 异常时,其他 Agent 的结果仍可能有效
所以汇总阶段最好考虑部分结果缺失的处理方式。
小结
ParallelAgent 适合“互不依赖、可以同时做”的任务。
它的核心收益是缩短总耗时,核心约束是不能有前后依赖。像天气、新闻、股票这类多源数据采集,就很适合并行执行,然后统一从 `OverAllState` 里读取结果。
但实际业务里,并不是所有任务都能并行。有些流程必须一步一步往下走,比如“写作 -> 评审 -> 汇总”;还有些场景需要先判断用户问题类型,再分发给不同专家 Agent。
所以下一篇继续看两个模式:
- `SequentialAgent`:适合有前后依赖的串行流程
- `RoutingAgent`:适合统一入口下的多类型问题分发
并且会顺带看一个组合思路:把 `ParallelAgent` 作为 `SequentialAgent` 的一个子步骤,先并行采集,再串行汇总。
为了方便大家直接上手,我把本文完整可运行项目源码打包好了,包含依赖、配置、启动类全套,导入就能跑。
需要的朋友可以关注我技术号,后台回复【SpringAI Demo入门】即可领取。后续我会持续更新java+AI实战干货,带你少踩坑、快落地。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)