
【AI Agent】常用架构模式:ReAct、Plan-and-Execute、Reflection
为什么需要 Agent 架构模式,在传统 LLM 应用中,大模型通常是根据用户输入直接生成答案,这种方式适合简单问答,但在真实业务场景中往往不够用。可以把 AI Agent 理解为:Agent = 大脑 + 手脚 + 记忆 + 主见大脑 LLM:负责理解用户意图、推理分析、生成回答。手脚 Tools:负责调用外部工具、API、数据库、搜索引擎或业务系统。记忆 Memory:负责保存上下文、历史记录
文章目录
前言
为什么需要 Agent 架构模式,在传统 LLM 应用中,大模型通常是根据用户输入直接生成答案,这种方式适合简单问答,但在真实业务场景中往往不够用。
可以把 AI Agent 理解为:
Agent = 大脑 + 手脚 + 记忆 + 主见
Agent = LLM + Tools + Memory + Autonomy
其中:
- 大脑 LLM:负责理解用户意图、推理分析、生成回答。
- 手脚 Tools:负责调用外部工具、API、数据库、搜索引擎或业务系统。
- 记忆 Memory:负责保存上下文、历史记录、用户偏好和任务状态。
- 主见 Autonomy:负责根据目标主动判断下一步该做什么,而不是每一步都等待用户明确指令。
例如用户查询订单、生成报告、排查问题、调用接口、修改代码时,系统不仅要回答问题,还需要:
- 理解用户意图
- 拆解任务步骤
- 调用外部工具或业务接口
- 根据工具结果继续判断
- 对最终结果进行检查和修正
因此,Agent 应用通常会引入一些常见架构模式,例如 ReAct、Plan-and-Execute、Reflection 等,用来提升任务执行能力、复杂问题处理能力和结果可靠性。
1、ReAct
ReAct = Reasoning + Acting,整个流程是:Reason(思考)→ Act(行动)→ Observe(观察),循环直到任务完成。
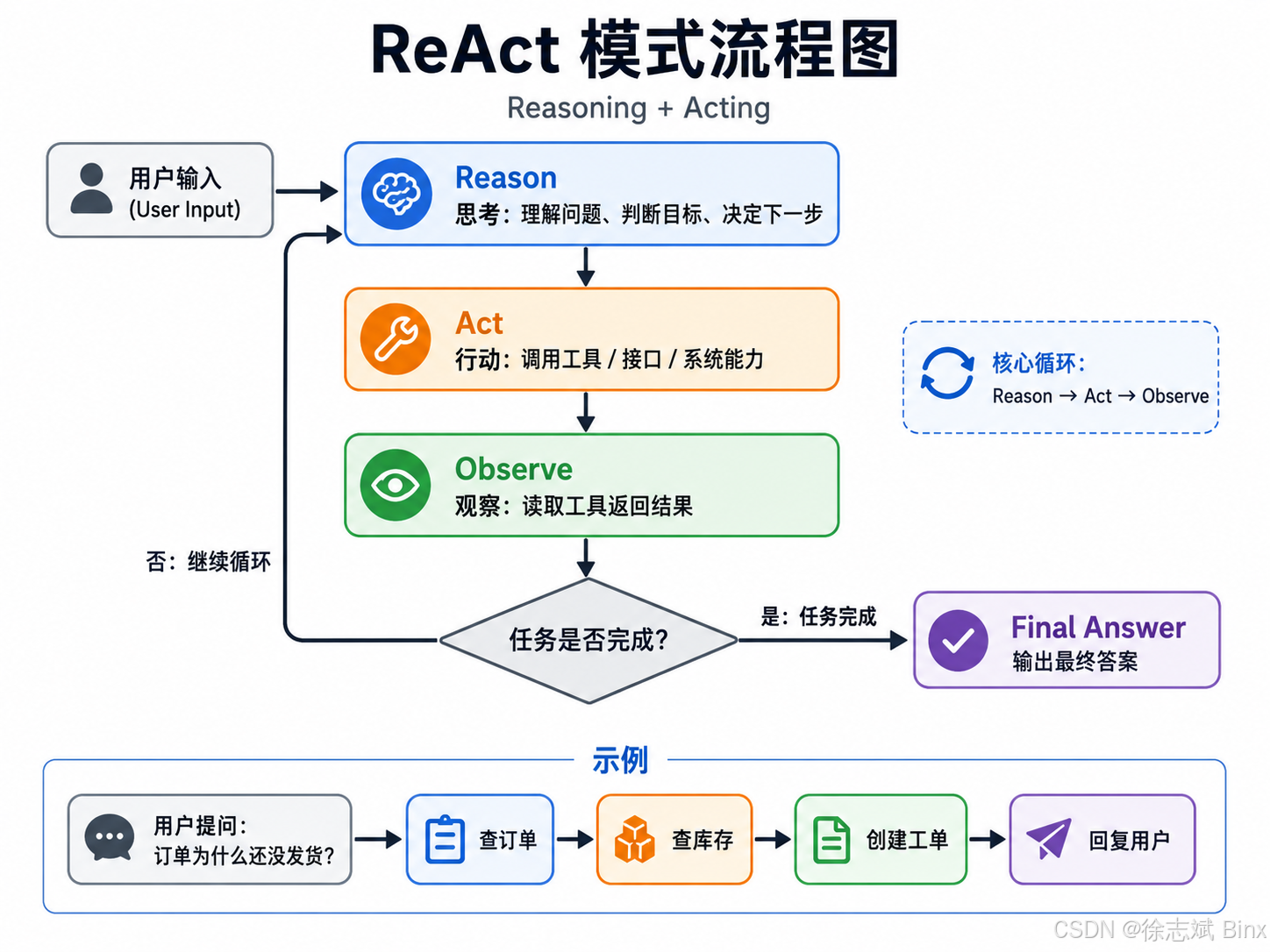
1.1、Reason 思考
Reason 指的是大模型在接收到用户输入后,先对任务进行理解和分析,判断用户真正想完成什么目标,以及下一步应该采取什么动作。
在普通的 LLM 对话中,大模型通常是直接根据已有知识生成回答;而在 ReAct 模式中,大模型不会急着给出最终答案,而是会先进行任务拆解。例如,用户问:
我的订单 20260513001 为什么还没发货?
此时LLM不能直接猜测原因,而是应该先判断:
这个问题需要查询订单状态。
我需要调用订单查询工具。
也就是说,Reason 阶段主要解决的是:
用户想做什么
当前信息够不够
是否需要调用工具
应该调用哪个工具
工具调用需要哪些参数
在 Agent 系统中,Reason 阶段非常关键,因为它决定了 Agent 接下来要不要行动,以及如何行动。
1.2、Act 行动
Act 指的是 LLM 根据 Reason 阶段的判断,选择并调用外部工具,工具调用可以是 HTTP API,也可以是数据库查询、RPC 接口、函数调用,或者业务系统中的某个服务能力。例如:
订单查询接口
库存查询接口
物流查询接口
售后工单接口
数据库查询接口
搜索引擎接口
知识库检索接口
也就是说,Agent 并不是只靠大模型本身回答问题,而是可以通过 Tool 获取外部真实数据。例如:
Reason:用户想查询订单为什么没发货,需要先查订单状态
Act:调用订单查询接口,参数为 orderId=20260513001
所以从工程角度看,Act 本质上就是:
LLM 决定调用哪个工具
系统执行工具调用
工具返回结果响应
1.3、Observe 观察
Observe 指的是 Agent 拿到 Tool 的调用结果后,对结果进行观察和分析,判断任务是否已经完成,或者是否还需要继续调用其他工具。例如订单查询接口返回:
{
"orderId": "20260513001",
"status": "paid",
"deliveryStatus": "waiting_stock",
"stockStatus": "out_of_stock"
}
此时 LLM 会根据这个结果继续判断:
订单已经付款,但因为库存不足暂时无法发货
接下来需要查询补货时间
于是又会进入下一轮循环:
Reason:需要查询库存和补货时间
Act:调用库存接口
Observe:库存为 0,预计 3 天后补货
如果观察结果已经足够回答用户,Agent 就会结束循环,生成最终回复。
例如:
您的订单 20260513001 已付款成功,目前暂未发货的原因是商品库存不足。
系统显示预计 3 天后完成补货,补货后会自动安排发货。
我已经为您创建了售后跟进工单,工单号为 XXXXXXX。
所以 Observe 阶段的核心作用是:
读取工具返回结果
判断结果是否有效
判断任务是否完成
决定是否继续下一轮 Reason → Act → Observe
所以 ReAct 模式本质是一个 Loop 循环,当用户 user 对 LLM 进行输入提示词 input 之后,LLM 大模型先进行 Reasoning 推理思考,判断一下用户具体想要做什么事儿,例如:判断是否需要进行工具调用,如果需要就开始进行 Action 行动,进行 Tool 调用,拿到调用结果后会进行观察 Observe,是否需要带着结果继续向 LLM 大模型进行调用提问,本质是一个循环操作。例如:
用户问题:我的订单 20260513001 为什么还没发货
↓
Reason:判断应该先查订单
↓
Act:调用订单接口
↓
Observe:发现订单已付款,但仓库等库存
↓
Reason:判断应该继续查库存
↓
Act:调用库存接口
↓
Observe:发现库存为 0,知道补货时间
↓
Reason:判断可以创建售后工单
↓
Act:创建工单
↓
Observe:拿到工单号
↓
Final Answer:回复用户
LangChain 框架创建的 Agent 实例默认就采用了 ReAct 范式。所以针对于日常比较简单的搜索、一次性的交互场景,ReAct 模式就比较合适,稍微复杂一点的场景,长一点任务流程,就可以考虑使用 Plan and Execute 模式。
2、Plan-and-Execute
ReAct 是一种循环的思想,Plan and Execute(也称 Planning) 和 ReAct 不一样,ReAct 是边想边做;Planning 是先拆任务,然后逐条执行 Plan,Vibe Coding里面常用的 Plan 模式就是这个思想,适合:长任务、复杂任务、报告生成、项目拆解。例如:
用户:帮我做一个竞品分析报告
Planner:梳理计划
- 确定竞品列表
- 搜集产品功能
- 对比价格
- 分析优缺点
- 输出报告
Executor:执行
逐步执行每个任务计划
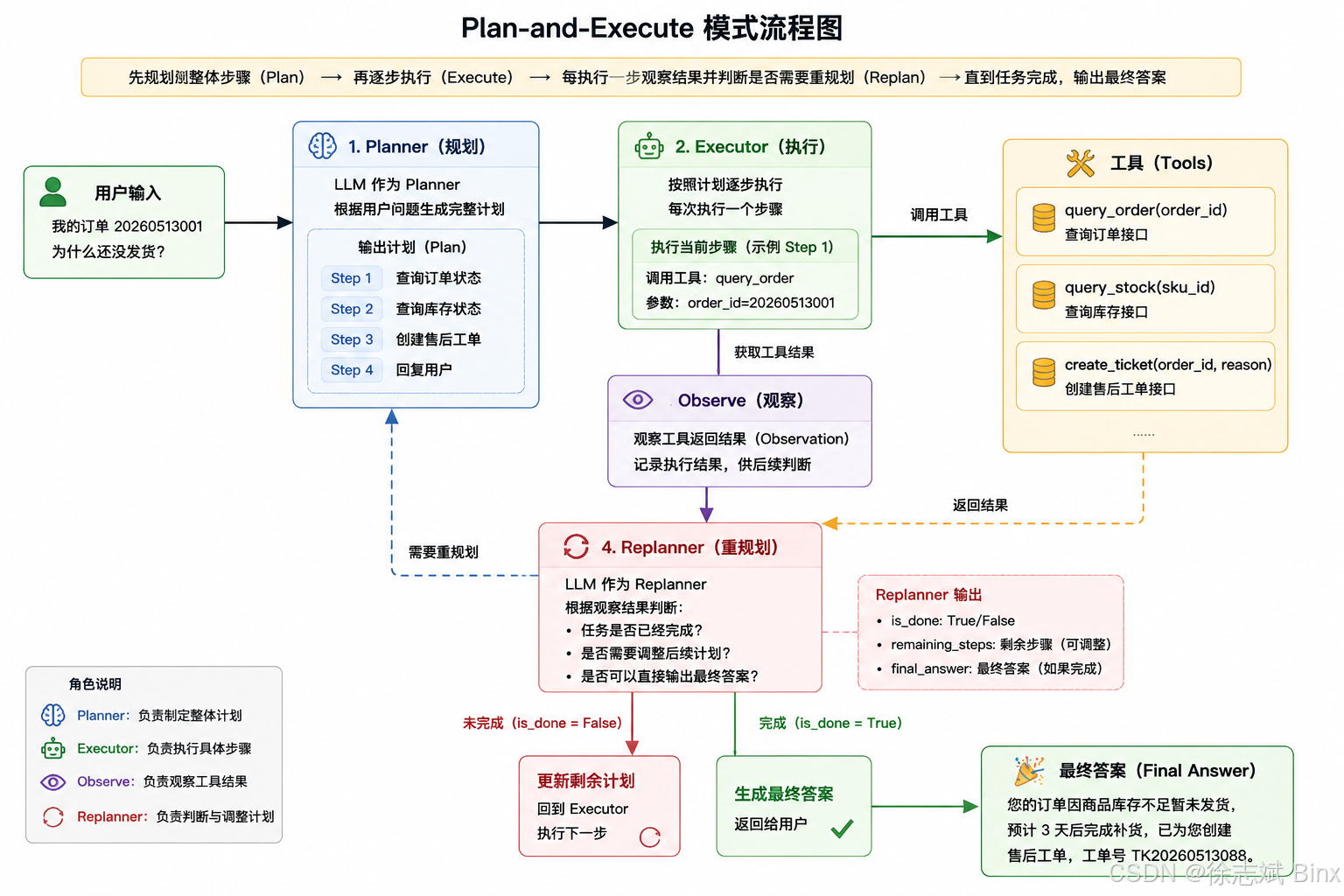
现在力推的 SDD、TDD 的 Vibe Coding 方式,其实就是 Plan and Execute 模式变种。
3、Reflection
在普通的 LLM 应用中,模型通常是一次性生成答案,生成完成后就直接返回给用户。如果答案中存在逻辑漏洞、格式问题、遗漏信息或者代码错误,系统本身很难主动发现。
而 Reflection 模式会在“生成答案”之后增加一个检查环节,让模型像审稿人一样重新审视自己的输出内容,并判断这个结果是否满足用户需求。如果发现问题,就继续修改,直到结果达到要求后再输出最终答案。所以该模式非常适合写代码、论文,非常重视结果正确性。
所以 Reflection 关注的不是“下一步该调用什么工具”,也不是“任务应该怎么拆解”,而是:
当前生成的结果是否正确
当前生成的结果是否完整
当前生成的结果是否符合用户要求
当前生成的结果是否还需要优化
Reflection 模式通常包含三个核心阶段:
Generate:生成初版结果
Reflect:检查和评价结果
Revise:根据检查结果进行修改
大致流程如下:
生成初版结果
↓
检查结果是否有问题
↓
发现问题
↓
修改优化
↓
再次检查
↓
输出最终结果
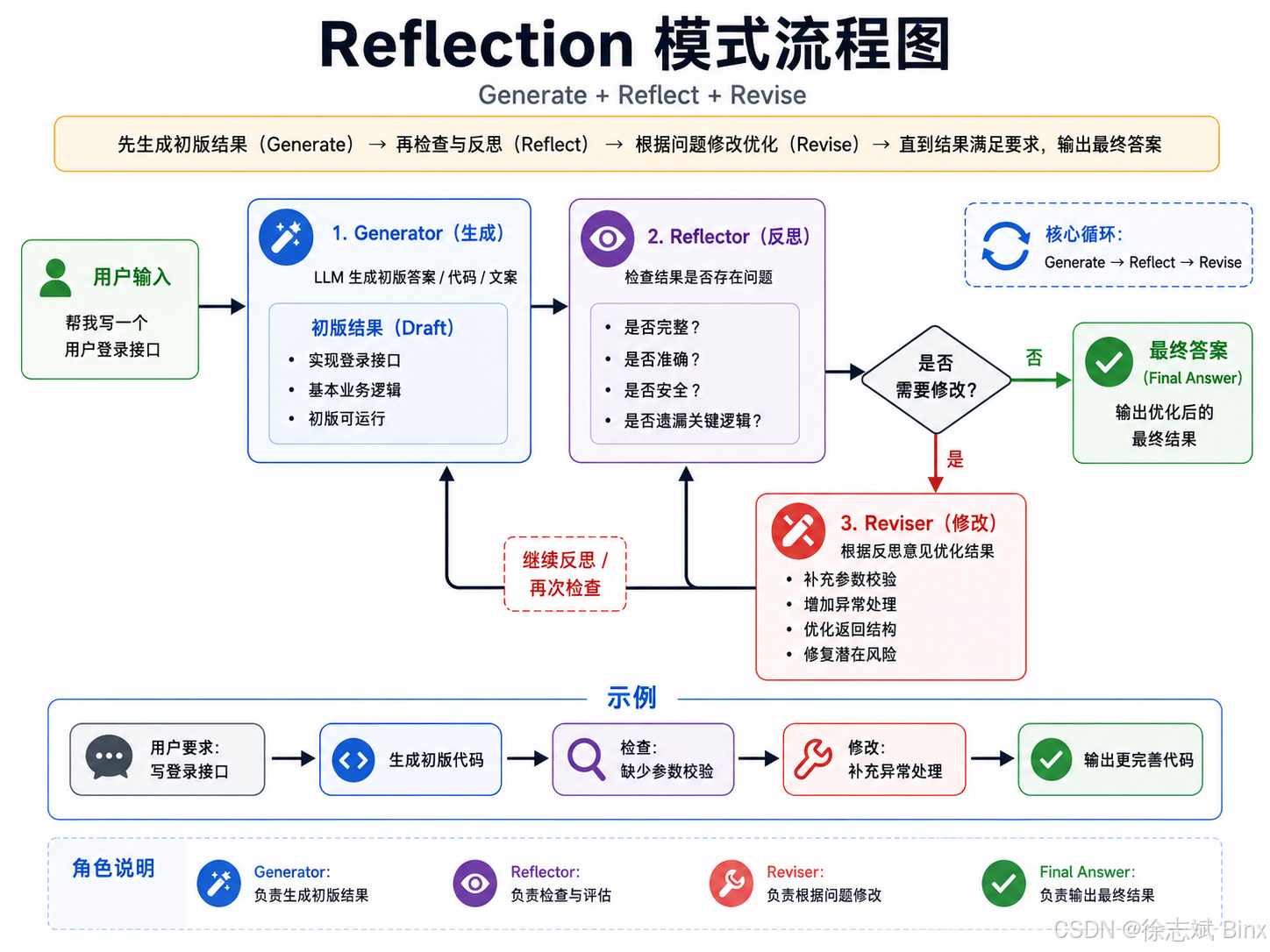
4、最佳实践
对于生产环境来说,我们构建 Agent 应用其实并不是只采用某一种模式进行,而且结合者上述几种和其他模式一起混合使用(并不是绝对的,也可以单一模式使用,要结合场景去判断),从而去构建出更健壮的AI Agent智能体应用。大致流程如下:
用户输入
↓
Planner:理解需求,拆解任务步骤
↓
生成计划 Plan
↓
Executor:执行当前步骤
↓
ReAct:Reason → Act → Observe
↓
得到工具返回结果
↓
Replanner:判断是否继续、跳过、调整计划
↓
如果未完成,继续执行下一步
↓
如果完成,生成初版最终答案
↓
Reflection:检查答案是否准确、完整、可靠
↓
如果有问题,返回修改或重新执行
↓
Final Answer:输出最终答案
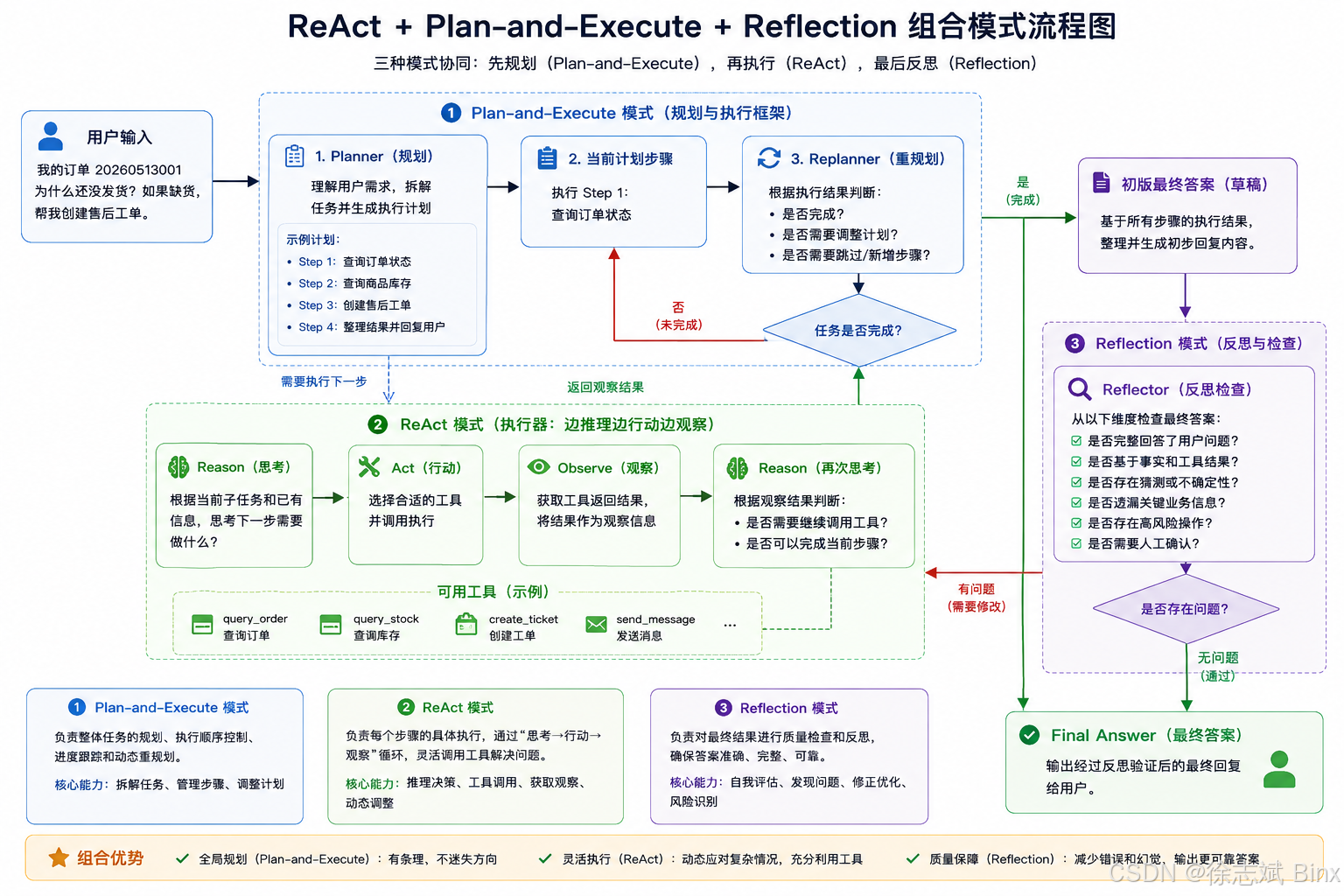
5、总结对比
| 对比维度 | ReAct 模式 | Plan-and-Execute 模式 | Reflection 模式 |
|---|---|---|---|
| 中文理解 | 思考-行动-观察模式 | 规划-执行模式 | 反思-修正模式 |
| 核心思想 | 边思考、边调用工具、边观察结果 | 先生成整体计划,再按步骤执行 | 先生成结果,再检查问题并优化 |
| 执行流程 | Reason → Act → Observe → 循环 → Final Answer | Plan → Execute → Observe → Replan → Final Answer | Generate → Reflect → Revise → Final Answer |
| 关注重点 | 下一步该做什么 | 整体任务怎么拆解和执行 | 结果是否正确、完整、可靠 |
| 适合任务 | 短链路、动态决策、工具调用类任务 | 多步骤、长流程、目标明确的复杂任务 | 对质量要求高、需要检查和修改的任务 |
| 典型场景 | 查订单、查库存、查物流、接口排查、客服问答 | 生成报告、复杂售后处理、项目规划、自动化任务执行 | 代码审查、论文润色、SQL 检查、方案评审、最终答案校验 |
| 是否需要工具调用 | 通常需要 | 通常需要,但由执行阶段调用 | 不一定需要,主要用于检查输出质量 |
| 是否有整体计划 | 一般没有完整计划,边走边判断 | 有,先规划完整步骤 | 没有任务计划,重点是检查已有结果 |
| 是否支持动态调整 | 支持,根据 Observation 决定下一步 | 支持,通过 Replanner 调整计划 | 支持,根据 Reflect 结果修改答案 |
| 优点 | 灵活,适合实时决策和工具调用 | 有全局视角,不容易迷失方向 | 能提升答案质量,减少低级错误 |
| 缺点 | 复杂任务中可能重复调用工具或跑偏 | 规划成本更高,流程更重 | 增加 LLM 调用次数和响应时间 |
| 企业级定位 | 适合作为具体任务执行器 | 适合作为外层任务编排框架 | 适合作为最终质量检查器 |
| 一句话总结 | 解决“下一步做什么” | 解决“整个任务怎么做” | 解决“做得对不对” |

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)