
Herems Agent的低调Provider:ByteRover解析,LoCoMo榜首的“低调王者“
在AI Agent记忆领域,Herems Agent新版本公布的记忆Provider的LoCoMo评测排名中榜首的位置有一个陌生的身影:ByteRover。
在AI Agent记忆领域,Herems Agent新版本公布的记忆Provider的LoCoMo评测排名中榜首的位置有一个陌生的身影:ByteRover。LoCoMo总成绩96.1%。
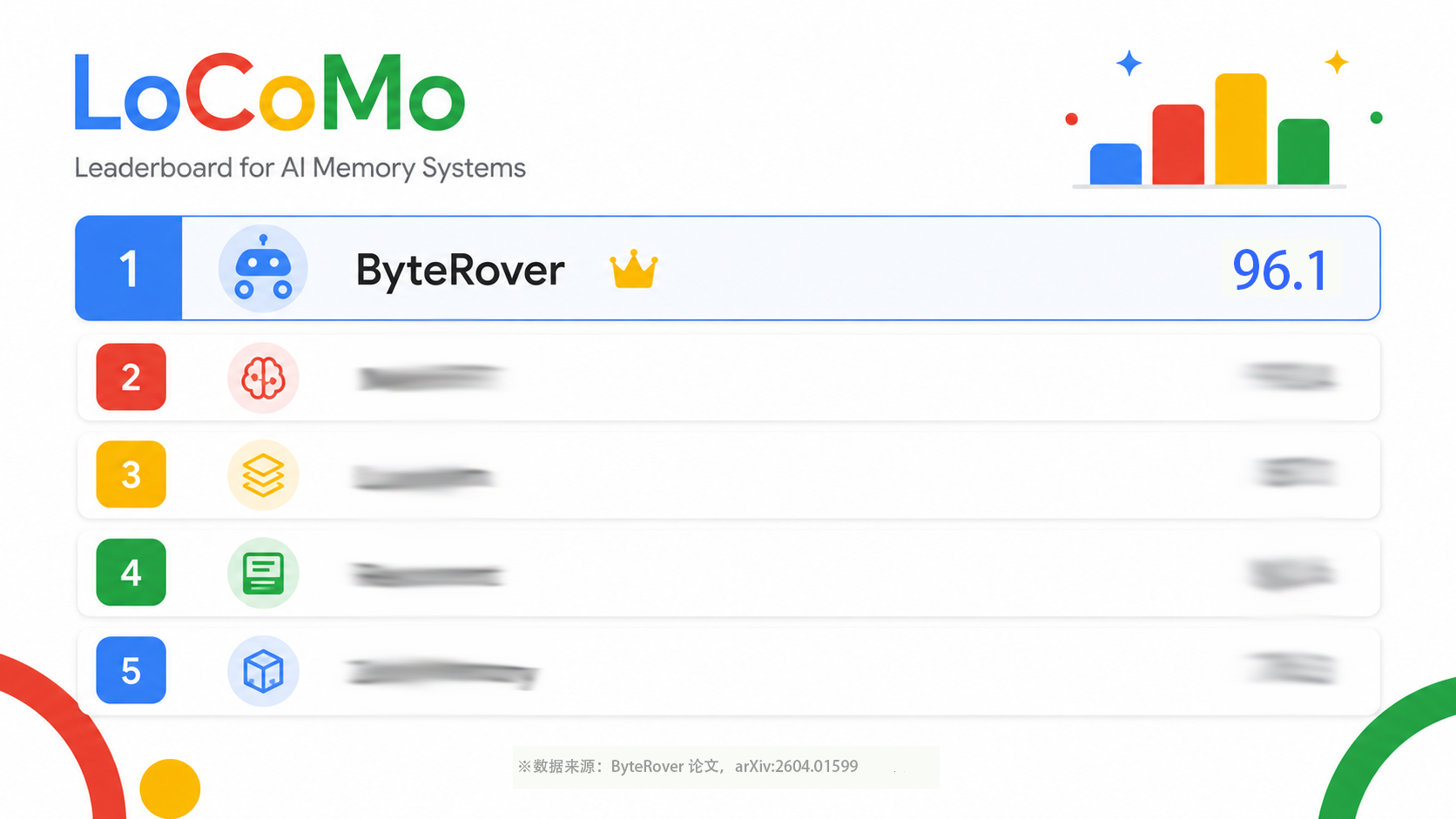
如果你关注AI记忆赛道,可能还记得我之前写过的《同一个AI Agent,换个记忆就像换个人:Hermes Agent的"换脑实验报告"》。那篇文章覆盖了Mem0、ByteRover等八大Provider,在报告中我只写了名气比较大的Mem0而绕过了ByteRover。今天这篇文章,我们再单独聊聊ByteRover。我会从团队背景、核心架构、评测数据三个维度,做一次完整的深度拆解。
ByteRover是谁:从MCP工具到记忆框架的四代进化
团队背景与产品定位
ByteRover是一家专注于AI Agent记忆基础设施的公司,官网为byterover.dev。根据公开信息,团队从2021年一开始是做MCP(Model Context Protocol)相关的工具,后来才逐步聚焦到Agent Memory这个细分赛道的。
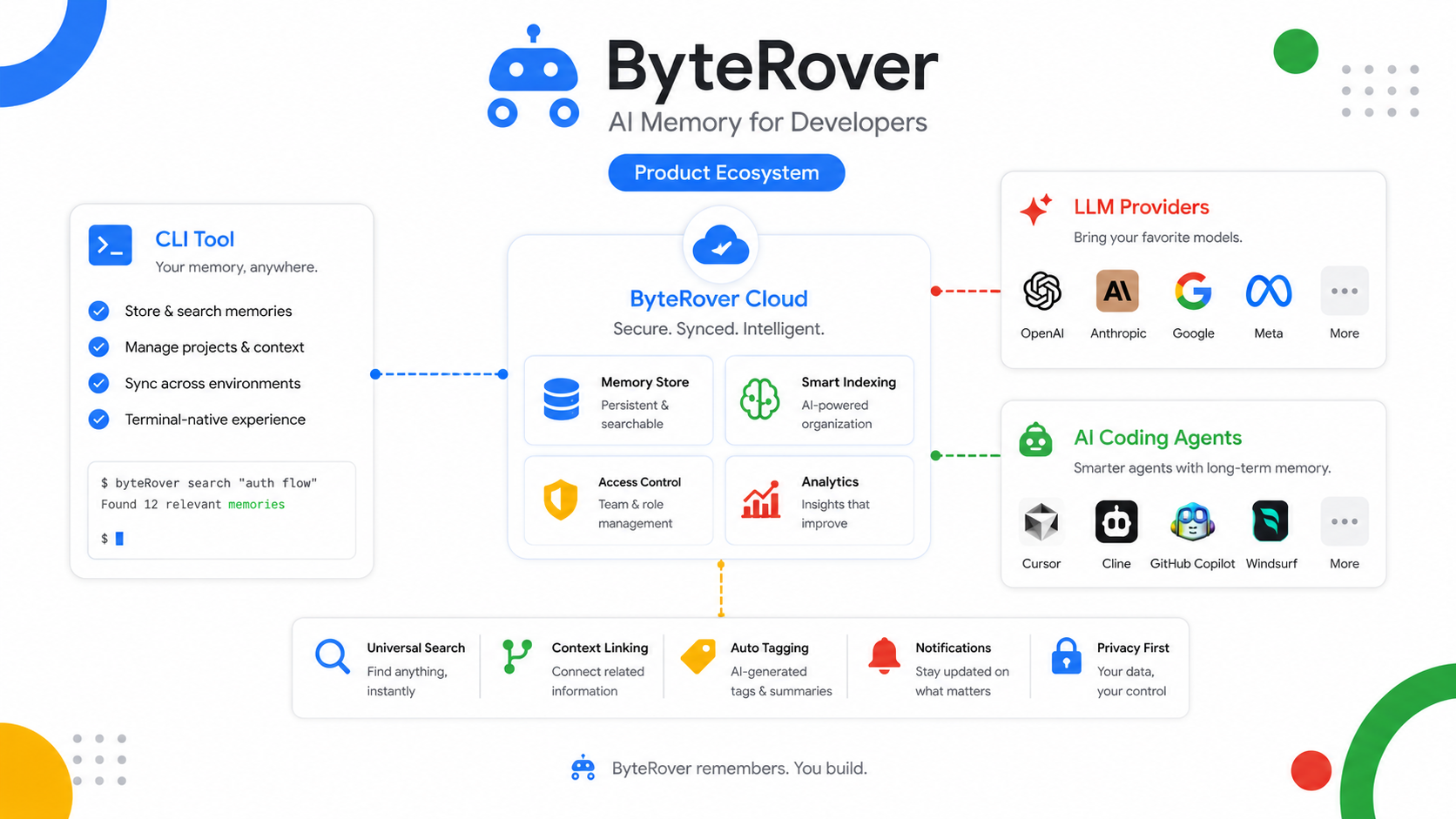
目前ByteRover的产品矩阵包含两个核心产品:
-
ByteRover CLI:面向开发者的命令行工具,最新版本3.8.3(2026年4月23日发布),GitHub仓库为campfirein/byterover-cli
-
ByteRover Cloud:面向企业的云端服务,强调安全合规,支持SOC 2 Type II认证、AES-256加密、TLS 1.2+等企业级特性
在Provider生态支持上,ByteRover覆盖了18个主流LLM Provider(Anthropic、OpenAI、Google、Groq、Mistral、xAI等)和22+个AI Coding Agent(Cursor、Claude Code、Windsurf、Cline等)。这个支持的范围在同类产品中算是相当全面的。
四代的架构演进
ByteRover的技术演进路径很有意思,我简单的梳理了一下,主要分为四代:
1.x时代:基于MCP协议的工具集,定位是"给Agent提供工具调用能力",记忆功能相对简单,本质上是把上下文管理封装成了一套协议。
2.0时代(2024年):这是ByteRover的转折点。团队正式提出了Context Tree(上下文树)概念,配合分层检索架构,LoCoMo得分从大约75%一跃到92.2%(使用Gemini 3 Pro作为justifier)或90.9%(使用纯Gemini 3 Flash全程)。※数据来源:ByteRover官方博客,byterover.dev/blog/benchmark-ai-agent-memory,2026-02-27
2.1.5时代(2025年):在2.0基础上做了细节优化,LoCoMo得分达到96.1%,登顶榜首。这是目前公开可查的最佳成绩。
3.x时代(2026年):主打ACE(Agent-Centric Experience)工作流和CLI全面重构,进一步提升开发体验。
从1.x到3.x,ByteRover的核心演进逻辑是:从"给Agent提供工具"到"让Agent自己管理记忆"。
核心架构解析:四大模块如何协同
ByteRover的技术架构是四个核心模块组成:Context Tree(上下文树)、Agent-Native Curation(代理原生策展)、Tiered Retrieval(五层渐进式检索)、Adaptive Knowledge Lifecycle(自适应知识生命周期)。这四个模块不是简单的堆叠,而是一个有机的整体。下面我逐一拆解:
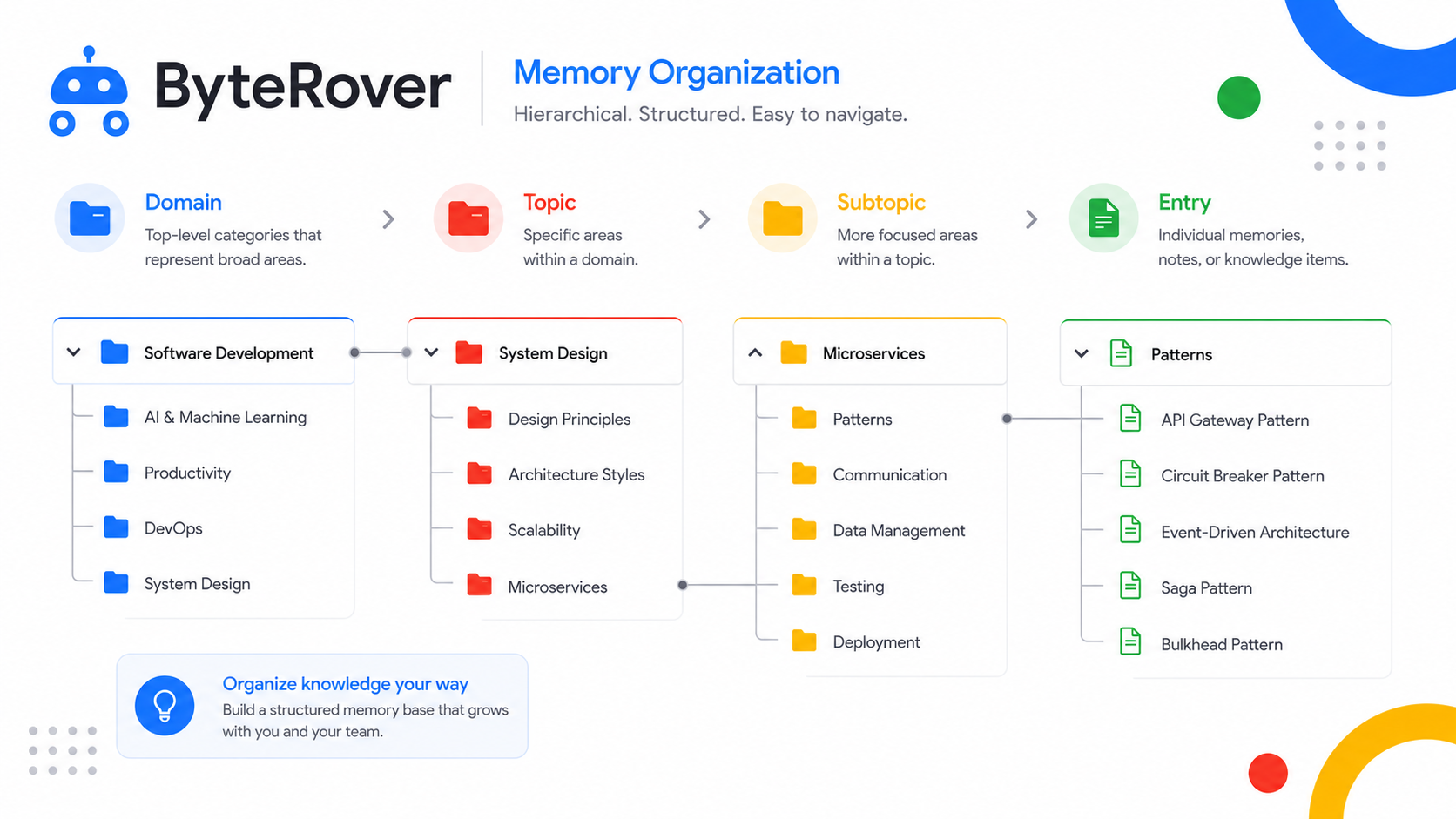
Context Tree:让记忆像文件夹一样组织
传统的记忆系统,大多数是基于向量数据库的:用户的输入被embedding成向量,检索时做相似度匹配。这套方案虽然简单有效,但是有一个根本问题:丢失了记忆之间的结构关系。
你问Agent:"我上周提到的那篇论文,后来作者更新了什么?"向量检索虽然能快速准确的匹配到"论文"和"更新"这些词,但是"上周"这个时间关系、"作者"和"论文"的从属关系,是很难被捕捉到的。
ByteRover的解决方案是Context Tree。
简单的类比一下:你可以把Context Tree理解为电脑里的文件夹结构。最顶层是Domain(域),比如"工作"、"项目A";往下一层是Topic(主题),比如"代码审查";再往下一层是Subtopic(子主题),比如"性能优化";最底层是Entry(条目),具体的记忆内容。
工作/
├── 项目A/
│ ├── 代码审查/
│ │ ├── 2025-03-15_评审发现.md
│ │ └── 2025-03-20_优化建议.md
│ └── 部署/
│ └── 2025-03-22_回滚记录.md
└── 会议/
└── 2025-03-25_周会纪要.md这个树结构有几个关键特征:
纯Markdown存储:所有记忆都是.md文件,人眼可读、可搜索、可版本控制。你不用的时候就是一个文件夹,需要的时候瞬间可以转变为Agent可用的上下文。这对开发者非常友好——出了问题你可以直接打开文件看是什么记忆被误用了。
层级继承:子节点的记忆会继承父节点的信息。"工作/项目A/代码审查"下的条目,默认携带"这是项目A的代码审查"这个背景。
关系显式化:通过文件夹路径,记忆之间的从属、时序、因果关系被显式编码,而不是隐含在向量空间里。
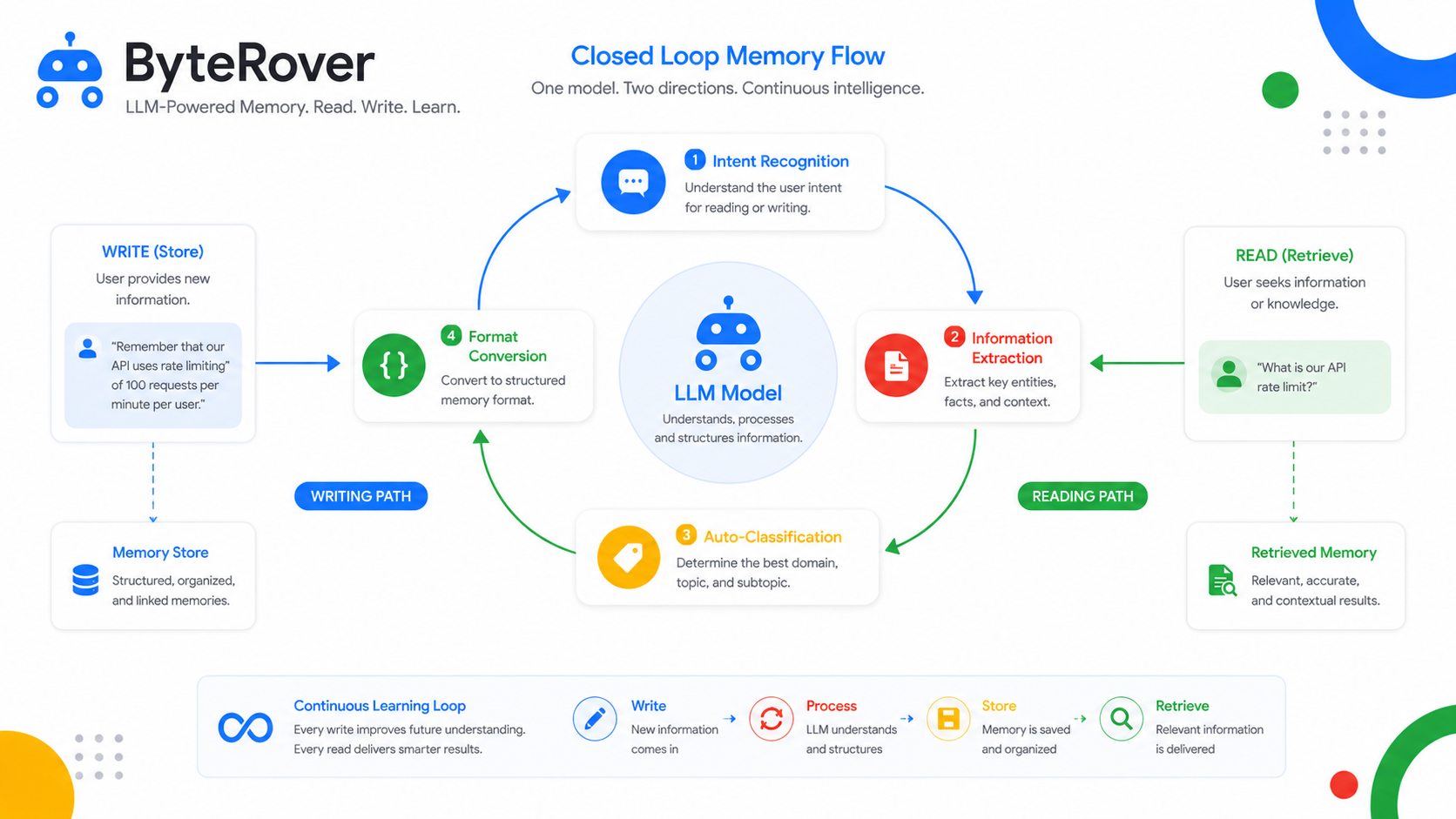
Agent-Native Curation:读和写是一个闭环
传统的记忆系统,读和写是分离的:Embedding模型负责"读"(检索),LLM负责"写"(生成新内容)。两个模型各司其职,互不干扰。
但ByteRover认为:同一个LLM既推理又整编,记忆的才能真正闭环。
这个理念的英文叫做Agent-Native Curation,我把它翻译为智能体原生整编。它的运作流程如下。当Agent处理一个用户请求时,整个流程是这样的:
-
意图识别:LLM判断这个请求是否需要记忆模块参与
-
信息提取:LLM从当前上下文提取值得存储的信息
-
自动分类:LLM决定这条信息应该放在Context Tree的哪个位置
-
格式转换:LLM把信息转成.md格式,必要时添加元数据(时间戳、重要性评分等)
关键是第3步和第4步——是同一个LLM在执行。它既知道"这条信息值得存储",也知道"这条信息应该放在工作/项目A/代码审查下",这两个判断基于同一个推理链路。
这带来的好处是:整编质量直接由推理能力决定。GPT-4级别的模型,整编质量比GPT-3.5高得多。而不是像传统方案那样,检索用embedding、整编用规则,两套系统各玩各的。
Tiered Retrieval:五层渐进式检索
检索速度是很多记忆系统的痛点。用户问一句话,Agent要翻遍整个记忆库,耗时好几秒,用户体验很差。
ByteRover的分层检索(Tiered Retrieval)用了一个很聪明的思路:先用快的方法缩小范围,再用慢但准的方法精修。
整个检索分为五层:
Tier 0 - Hash精确匹配:把高频查询的精确表达做hash缓存,命中则直接返回,延迟接近0。这层处理的是"你昨天问我XX"的场景。
Tier 1 - 精确子串匹配:在Context Tree的Entry级别做字符串匹配,处理显式引用的场景,比如"你说的那篇论文"。
Tier 2 - 相关Entry检索:在Subtopic级别做向量相似度搜索,找到最相关的几个Entry。这是主力检索层。
Tier 3 - 跨Branch聚合:跨越同一Topic下的多个Subtopic聚合信息,处理"我上个月做的所有项目"这类聚合查询。
Tier 4 - 完整Agent推理循环:调用LLM做深度推理,处理复杂的多跳问题。这层的延迟最高,但覆盖的查询比例最小。
ByteRover的论文披露了一个关键数据:在LoCoMo评测中,Tier 4仅占检索量的7%,其余93%都在前四层搞定。
※数据来源:ByteRover论文,arXiv:2604.01599
这意味着大部分查询在Tier 0-3就完成了,延迟控制在sub-100ms。只有那些真正需要深度推理的复杂查询,才会触发Tier 4。
官方公布的延迟数据也印证了这一点:
-
p50冷查询延迟:1.2s(LoCoMo)/ 1.6s(LongMemEval-S)
-
p95冷查询延迟:1.4s(LoCoMo)/ 2.3s(LongMemEval-S)
-
p99冷查询延迟:1.7s(LoCoMo)/ 2.5s(LongMemEval-S)
※数据来源:ByteRover论文,arXiv:2604.01599
这些是"冷查询"(缓存未命中)的延迟。如果命中缓存,延迟会低得多。
Adaptive Knowledge Lifecycle:开启知识的动态演化
最后一个模块是Adaptive Knowledge Lifecycle(自适应知识生命周期)。这是ByteRover区别于"把记忆当静态数据库"的另一关键设计。
现实中,记忆是有"生命周期"的:
-
刚记住的信息:重要性高,但可能不完全准确(需要验证)
-
反复被提及的信息:经过多次检索和验证,置信度提升
-
长期不用的信息:重要性衰减,但不应完全删除(可能在未来被唤醒)
ByteRover用三个维度来量化这个生命周期:
重要性评分(Importance Score):基于检索频率、更新频率、关联强度等因子动态计算。一条被反复检索和引用的记忆,重要性评分会持续上升。
成熟度分级(Maturity Level):新记忆默认为"raw",经过验证后升为"verified",经过多次强化后升为"trusted"。不同成熟度的记忆,在检索时有不同的置信度权重。
时间衰减(Temporal Decay):长期不检索的记忆,重要性会逐步衰减,但不会归零。这个衰减是非线性的——短期内不用的衰减快,长期稳定的衰减慢。
这套机制解决了一个实际问题:Agent的记忆空间不是无限的。通过动态调整重要性,ByteRover可以在有限空间内优先保留高价值记忆。
评测数据深度拆解:96.1%的评分构成
LoCoMo评测全维度拆解
先来看LoCoMo评测中ByteRover 2.1.5的96.1%的各维度构成:
|
系统 |
单跳 |
多跳 |
时序 |
开放域 |
总分 |
|---|---|---|---|---|---|
|
ByteRover 2.1.5 |
97.5% |
93.3% |
97.8% |
85.9% |
96.1% |
※数据来源:ByteRover论文,arXiv:2604.01599
各维度逐项拆解如下:
单跳97.5%:这是ByteRover表现最强的维度。"单跳"指的是简单的事实查询,比如"我叫什么名字"或"我上次看的电影是哪部"。97.5%意味着几乎不会出错。Context Tree的精确匹配机制在这个维度如鱼得水。
多跳93.3%:多跳指的是需要组合多个记忆的查询,比如"我上次和王总开会讨论的那个项目,现在进展怎么样了"。93.3%也很高,但比单跳低了4个百分点。多跳需要跨Entry的信息整合,对Context Tree的层级结构设计要求更高。
时序97.8%:时序推理是ByteRover的传统强项。"上周"、"上个月"、"那次会议之后"这类时间关系,正是Context Tree显式编码的内容。97.8%是四个维度中最高的。
开放域85.9%:这是ByteRover相对薄弱的维度。开放域推理涉及复杂语义理解和常识应用,比如"基于我们之前的对话,我现在遇到的问题可能和那个决定有关"。85.9%已经不低,但比Hindsight的95.1%差了将近10个百分点。
LongMemEval-S:92.8%的另一块拼图
LoCoMo之外,ByteRover还在LongMemEval-S上跑了分,92.8%的总体成绩同样亮眼:
|
类别 |
ByteRover |
|---|---|
|
Knowledge Update |
98.7% |
|
Single-Session User |
98.6% |
|
Single-Session Assistant |
98.2% |
|
Single-Session Preference |
96.7% |
|
Temporal Reasoning |
91.7% |
|
Multi-Session |
84.2% |
|
**Overall** |
**92.8%** |
※数据来源:ByteRover论文,arXiv:2604.01599
几个有趣的发现:
Knowledge Update 98.7%:这是最让我惊讶的数字。"Knowledge Update"指的是Agent能否正确更新已有记忆,比如用户改口说"不对,我上次看的不是这部电影"。98.7%意味着ByteRover几乎能完美处理记忆的更新和修正。
Multi-Session 84.2%:这是相对较低的维度。跨多个会话的长期记忆整合,确实是行业难题。84.2%已经是SOTA水平,但进步空间还很大。
数据可信度:必须说清楚的三个事实
在继续之前,我认为有必要对数据来源做一次可信性说明。因为这些数据不是从第三方评测机构看到的,而是ByteRover团队自测的。
事实一:不论是LoCoMo的96.1%还是 LongMemEval-S 的92.8%,均为ByteRover团队自测,使用自家的benchmark harness,评测prompt来自Hindsight的论文。论文发表于arXiv:2604.01599。
事实二:表格中其他竞品的数据(Mem0的66.9%、Honcho的89.9%等),也是ByteRover在统一评测协议下复测的。相比各团队自报数据,这种做法更公平、更可比。但需要注意的是,部分竞品的数据带有†标记,意味着该数据来自其自有论文,底座模型和judge配置可能不同。
事实三:截至目前(2026年5月),尚无独立第三方复现ByteRover的96.1%数据。这不是说这个数据是假的,而是提醒我们:待有独立评测结果出来后,数据可能会有调整。
短板与局限:96.1%背后的三个局限
任何技术都是有边界的。ByteRover的LoCoMo评测得分96.1%虽然很亮眼,但是以下几个局限,我觉得不容忽视。
开放域推理:落后Hindsight接近10个百分点
LoCoMo的开放域推理维度,ByteRover得分85.9%,而Hindsight是95.1%,差距达到9.2个百分点。
开放域推理为什么重要?因为它测试的是Agent的"常识理解"和"深度语义"能力——这不再是简单的事实匹配,而是需要真正的理解用户的意图、因果关系、隐含信息。
ByteRover在开放域的短板,可能和它的架构设计有关:Context Tree擅长捕捉显式结构(时间、层级、从属),但对于隐式的语义关联(比如"用户这句话背后的潜台词是什么"),向量检索的粗筛机制可能漏掉关键信息。
Hindsight在开放域的95.1%,意味着它有更好的语义理解机制。这可能是ByteRover下一代版本需要重点突破的方向。
商业闭源:不可自部署
ByteRover目前是闭源商业产品,不支持私有化部署。
对于有数据安全要求的企业来说,这是一个不可逾越的阻碍。比如金融机构、医疗行业、政府单位,这些机构往往都要求数据不能出内网,ByteRover的这种云端架构就完全不适用了。
对比Mem0、Zep等开源或可私有化部署的竞品,这是ByteRover的明显短板。虽然官方宣称支持SOC 2 Type II认证和AES-256加密,但对于某些高合规要求的应用场景,这些认证还远远不够。
依赖Gemini底座:换底座效果未知
ByteRover的最佳成绩,是在Gemini 3系列模型上跑出来的。但对于使用其他底座的用户,效果是否会打折、打多少折,目前没有公开数据。
论文没有披露在Claude、GPT-4等其他模型上的评测结果。这意味着:如果你的Agent底座不是Gemini,ByteRover的实际表现可能和96.1%有差距。
写在最后
96.1%的LoCoMo榜首成绩,是ByteRover交出的一份亮眼的成绩单。但这个数字应该只是起点,而不是终点。
ByteRover的核心价值,在我看来不是那个96.1%,而是它提出的Context Tree + Agent-Native Curation + Tiered Retrieval这套组合拳背后的思路,即:让记忆从静态存储变成结构化的动态结构,让Agent从被动读取变成主动整编。
这个方向对不对?市场会给出答案。但至少,它提供了一种新的可能性——一种关于AI Agent到底该怎么"记住"这个世界的可能性。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)