
用AI从零开发一个完整游戏,我只做了一件事:学会「管」它
它是一个跨平台的agentic skills框架,支持Claude Code、Copilot CLI、Gemini CLI等多个AI编程工具,核心思路是把软件工程里的需求评审、设计评审、代码审查这些规范,变成AI的内置行为。它没有直接开始写代码,而是先问了我8个问题、在浏览器里给我看了3版UI设计稿、写了一份12个任务的实施计划,然后才动手。因为如果一个代理做了12个任务,到后面它的上下文窗口里塞

我让AI帮我做一个小学生数学闯关游戏。它没有直接开始写代码,而是先问了我8个问题、在浏览器里给我看了3版UI设计稿、写了一份12个任务的实施计划,然后才动手。全程我只做了选择题和审核——4020行代码,9次提交,0次返工。
这不是AI变聪明了,是我用了一套叫Superpowers的工作流系统。它是一个跨平台的agentic skills框架,支持Claude Code、Copilot CLI、Gemini CLI等多个AI编程工具,核心思路是把软件工程里的需求评审、设计评审、代码审查这些规范,变成AI的内置行为。
什么是Superpowers?——给AI装上「工程规范」
先说清楚Superpowers不是什么:它不是更强的模型,不是新的API,也不是什么框架。它是一套skill(技能插件)系统,以插件形式安装在AI编程工具里,用来约束AI按照规范流程工作。它不绑定某个特定工具——目前支持Claude Code、GitHub Copilot CLI、Gemini CLI、Cursor等多个主流AI编程助手,通过统一的Agent Skills规范实现跨平台兼容。
举个例子。你跟AI说「帮我写个登录功能」,没有Superpowers的AI大概率直接开始写代码。有了Superpowers之后,AI会先启动brainstorming流程——问你用户是谁、要不要第三方登录、密码策略是什么。问完之后出设计方案让你确认,确认完了再写实施计划,计划通过后才动手写代码。
你可能觉得这样太慢了。但说实话,直接让AI写代码然后反复改,才是真的慢。需求没理清就动手,写出来的东西大概率不是你要的,改来改去浪费的时间远超前期规划。
Superpowers的skill有两种使用方式。一种是自动匹配触发:你正常提需求,AI根据任务类型判断该用哪个skill,自动激活执行。比如你说「帮我加个登录功能」,AI识别到这是新功能开发,自动调用brainstorming skill来梳理需求。另一种是主动调用:你明确告诉AI用哪个skill。不同工具的调用方式不同——在Claude Code里用/brainstorming这样的斜杠命令,在Copilot CLI里通过/skill brainstorming,在Gemini CLI里通过/activate_skill brainstorming。两种方式效果一样,区别只在于你是让AI自己判断,还是你来指定。
第一步:brainstorming——AI没有急着写代码,而是先问了我8个问题
我的需求只有一句话:「开发一个小学生错题闯关本地网页游戏」。AI识别到这是一个新功能开发任务,自动调用了brainstorming skill。

brainstorming有一个硬规则:一次只问一个问题,尽量给选项而不是开放式提问。这很关键——如果AI一口气问我「你要什么功能、什么风格、面向谁」,我大概率会给出模糊的回答。一次一个选择题,需求才能逐步收敛。
实际的8个问题依次是:
年级范围——选了1-6年级全覆盖。题目来源——预录题库而非自动生成。闯关模式——固定关卡制。数据存储——localStorage。题库录入方式——网页表单。题型支持——四种全要(计算题、选择题、判断题、填空题)。
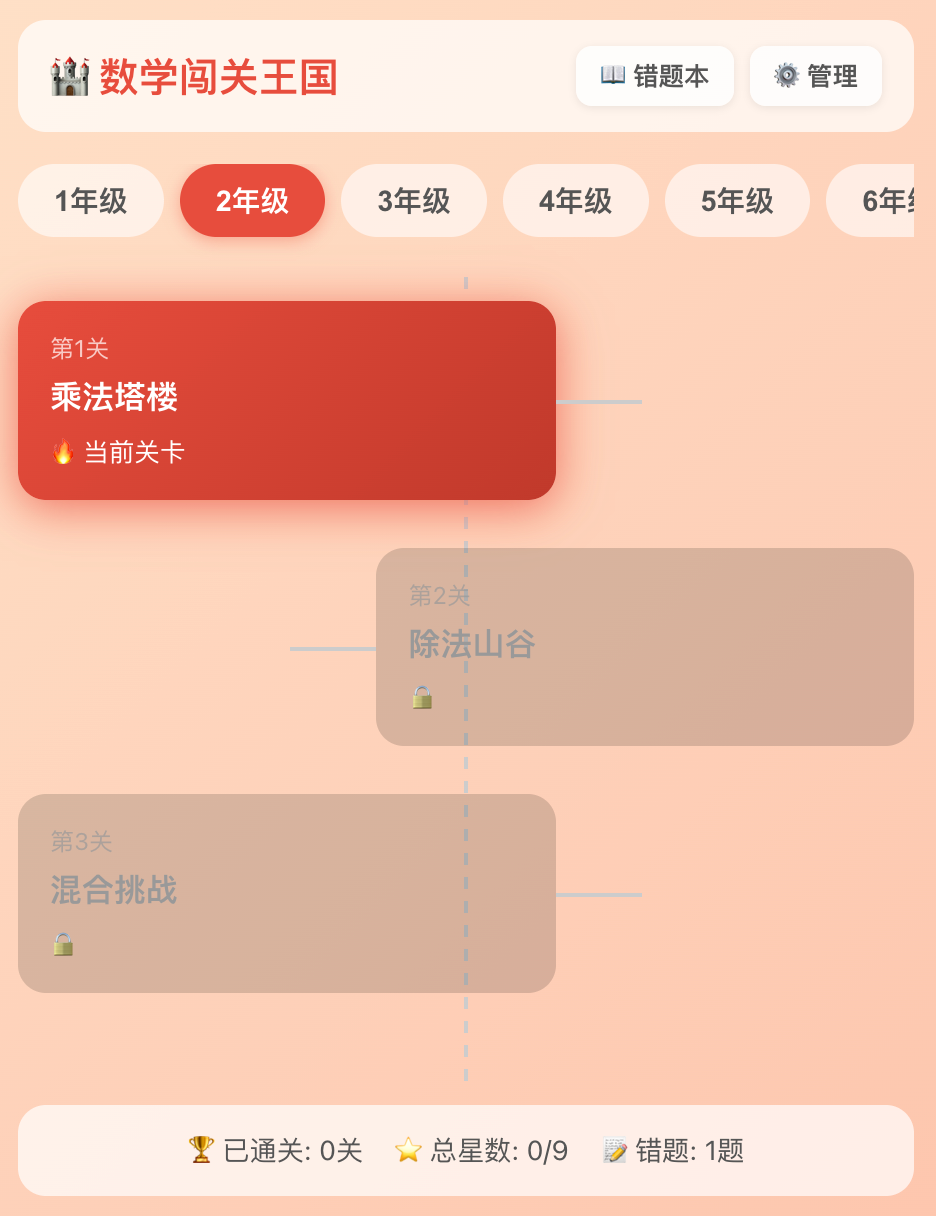
第7个问题到了视觉风格,brainstorming启动了一个叫可视化伴游的功能。它在本机启动了一个HTTP服务,在浏览器里实时渲染了3种UI方案:太空探险风、卡通城堡风、清新竞答风。每种方案都有真实的界面预览——关卡卡片、答题界面、状态栏,不是文字描述。
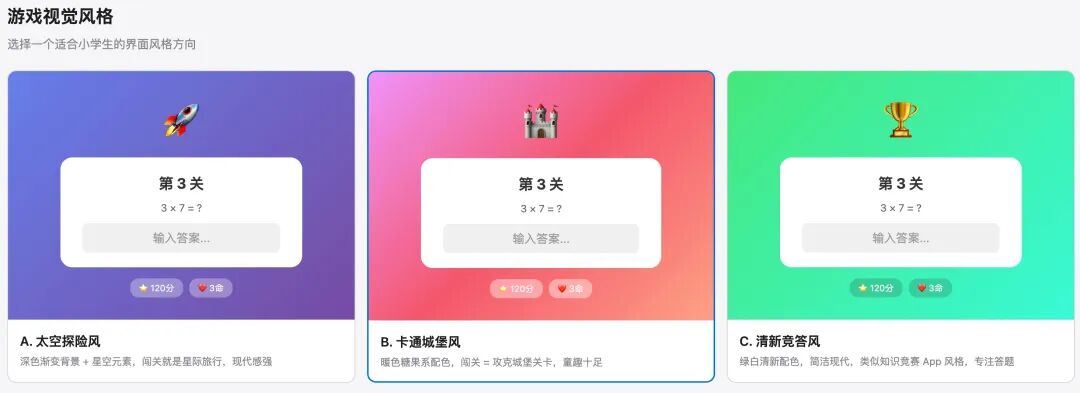
我在浏览器里点击选了「卡通城堡风」,AI读到了我的选择,继续问下一个问题。这种「看图选方案」比文字描述高效太多了——如果只用文字沟通UI,大概率要来回改好几轮。
8个问题问完,AI提出了3种整体方案让我选(地图式、列表式、地图+错题专属模式),推荐了地图式。确认后,AI逐节展示详细设计——整体架构、关卡地图页、答题页+结算页、错题本+管理页,每节都带mockup让我确认。全部通过后,生成了一份完整的设计文档并提交到git。
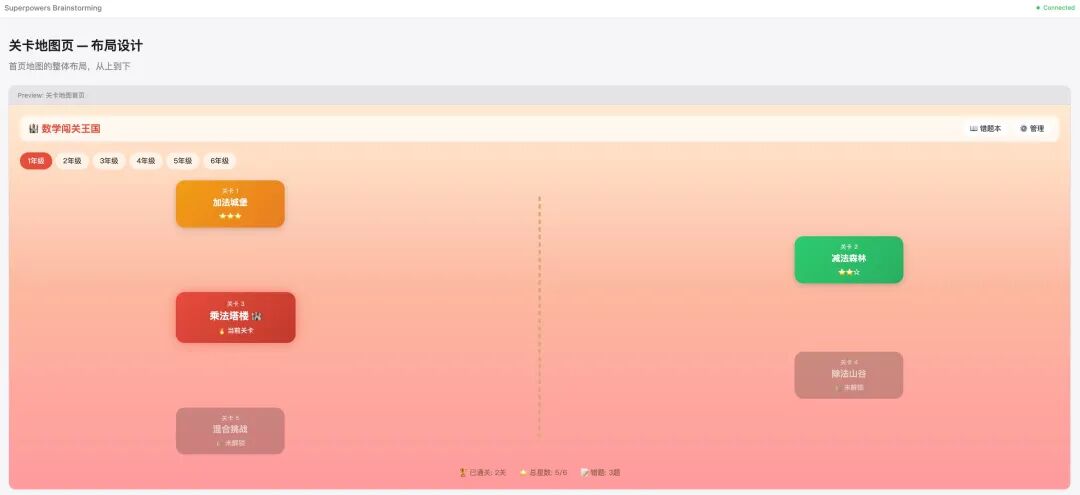
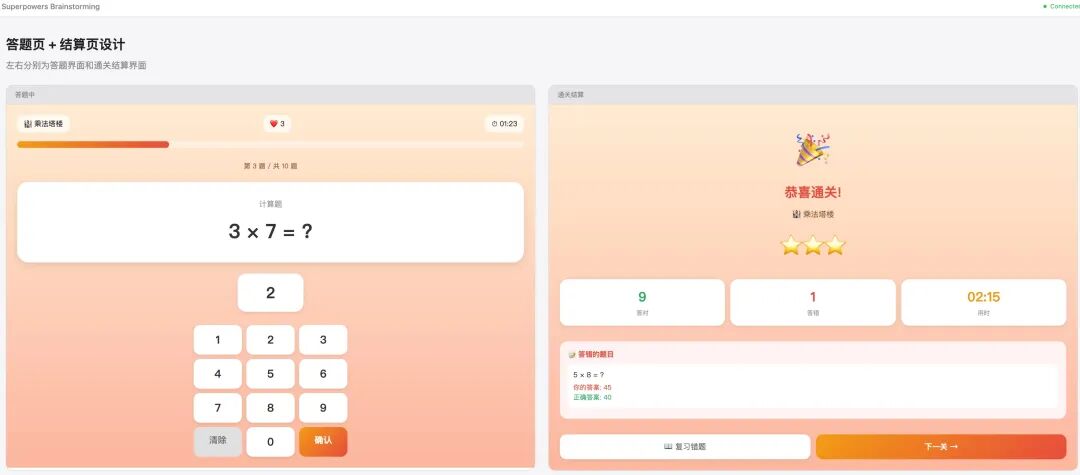
brainstorming的核心产出不是代码,是一份完整的设计文档:5个页面的交互流程、4种数据结构、游戏规则、配色方案。这份文档是后面所有工作的地基。
第二步:writing-plans——把设计文档变成12个可执行的任务
设计文档确认后,AI启动了writing-plans skill。它的职责是把设计文档拆解成一个个bite-sized任务——每个任务2-5分钟就能完成,有明确的输入输出和验收标准。
最终拆出了12个任务:
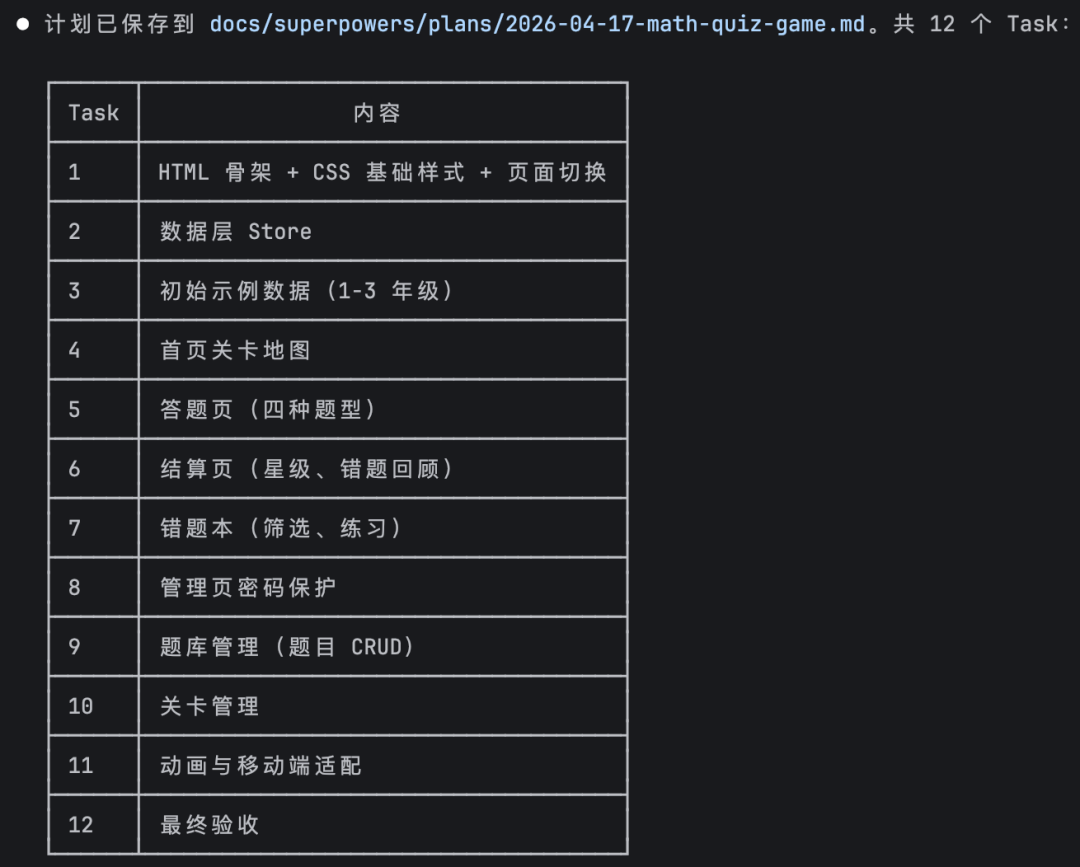
任务1到3打地基——HTML骨架+CSS、数据层Store、初始示例数据。任务4到7做核心页面——关卡地图、答题页、结算页、错题本。任务8到10做管理功能——密码保护、题目CRUD、关卡管理。任务11打磨——动画和移动端适配。任务12是最终验收。
每个任务的描述不是一句话,而是包含了要修改哪些文件、具体要实现什么、怎么验证。比如任务2「数据层Store」,规定了17个方法名、5个localStorage key、3种数据结构、去重规则和星级保留逻辑。后面的实现者拿到这个描述,不需要猜,照着做就行。
计划写完后,AI做了一轮自审——检查有没有遗漏的需求、有没有占位符(TBD/TODO)、类型命名是否前后一致。这跟人类工程师写完方案后自己review一遍是一样的。
写计划这件事听起来浪费时间,实际恰恰相反。12个任务每个都一次通过规格审查,就是因为计划写得够细——实现者不需要做任何设计决策,只需要执行。没有决策就没有歧义,没有歧义就没有返工。
第三步:subagent-driven——12个子代理轮流上阵,我只负责审核
计划确认后进入执行阶段。subagent-driven-development的工作方式是这样的:每个任务派一个全新的子代理去执行,执行完由专门的审查代理检查,通过后才进入下一个任务。

为什么要用「全新子代理」?因为如果一个代理做了12个任务,到后面它的上下文窗口里塞满了前面所有任务的细节,很容易产生幻觉或者跟前面的代码冲突。每个代理只看自己任务需要的上下文,干净利落。
每个任务完成后走两轮审查。第一轮是规格合规审查——spec reviewer拿设计文档逐条对照,检查「做没做对」。它会读实际代码而不是信任实现者的报告,逐行验证每个要求是否真的实现了。第二轮是代码质量审查——检查命名、结构、复杂度等质量问题。
审查不通过怎么办?实现者修复后再审,直到通过。整个流程下来,12个任务9次提交,全部一次通过规格审查——靠的不是运气,是前面计划写得足够细。
还有个细节值得说。任务8到10(密码保护+题目管理+关卡管理)因为耦合度高,合并为一个子代理一次实现。这体现了subagent模式的灵活性——不是机械地一个任务一个代理,而是可以根据实际情况合并或拆分。
subagent模式的核心不是快,而是隔离。每个代理只管一件事,做完了就消失。错误不会跨任务累积,上下文不会互相污染。这跟微服务的思路是一样的——隔离是可靠性的基础。
Superpowers完整skill地图
上面只用了3个skill就完成了一个完整项目。但Superpowers提供的skill远不止这些,按类型可以分为四类:
流程类——控制工作怎么走:
brainstorming需求梳理和设计,本文实战用到的;
writing-plans把设计拆成可执行任务,本文实战用到的;
executing-plans在当前会话里逐任务执行;
subagent-driven-development每个任务派独立子代理,本文实战用到的。
质量类——控制代码质量:
test-driven-development先写测试再写实现;
systematic-debugging遇到bug时系统化排查,而不是瞎猜;
verification-before-completion声称完成前必须跑验证命令;
requesting-code-review/
receiving-code-review代码审查的发起和处理。
协作类——管理开发流程:
dispatching-parallel-agents多个独立任务并行执行;
using-git-worktrees用隔离的worktree做功能开发;
finishing-a-development-branch分支完成后的合并、PR、清理。
扩展类——定制你自己的规范:
skill-creator创建自己的skill,比如团队专属的代码规范。
这些skill的使用方式前面说过,这里再具体一点。自动匹配触发是主要的使用方式——你正常对话就行,AI会根据你描述的任务类型自动选择合适的skill。你说「帮我加个功能」,它自动用brainstorming;你说「这个bug帮我看看」,它自动用systematic-debugging;你说「帮我写个实施计划」,它自动用writing-plans。skill的描述里写清楚了适用场景,AI读到你的需求后会做匹配。主动调用适合你明确知道要用哪个skill的场景。比如你觉得需求已经很清楚了,不想走brainstorming直接写计划,就可以主动指定用writing-plans。调用方式因工具而异,但核心思路一样:告诉AI「用这个skill来处理我的请求」。
实战复盘:4020行代码背后的完整流程
回头看整个项目,时间线是这样的:brainstorming问了8个问题+4轮设计确认 → writing-plans产出12个任务 → 逐任务派子代理实现+审查 → 最终全量验收。
最终产出:一个4020行的单HTML文件,包含5个完整页面(关卡地图、答题、结算、错题本、题库管理),支持4种题型,7个关卡70道题,带动画和移动端适配。
哪些环节最有价值?brainstorming避免了我事后改需求——我最初没想过要密码保护,是brainstorming问到管理入口安全时才想到的。如果直接写代码,中途加这个功能要改的地方就多了。writing-plans让执行变成了体力活——12个任务的实现者不需要做任何设计决策,照着描述写就行。subagent的审查抓住了细节问题——比如某个任务报告「已实现」,审查者读代码发现判断题的答案比较逻辑有遗漏,当场修复了。
哪些可以简化?对于这个规模的项目,轻量任务(纯CSS、数据初始化)的代码质量审查其实可以跳过,规格审查足够了。brainstorming对于非常明确的需求也可以缩短——如果你已经清楚知道自己要什么,2-3个问题就能锁定。
这套方法适合你吗?
Superpowers适合的场景:中等复杂度的独立项目——一个完整的功能模块、一个小工具、一个内部系统。这类项目特点是需要从头到尾可控地交付,但规模还没大到需要完整的工程团队。
不太适合的场景:快速验证想法的原型(brainstorming太重了)、几行代码的小修改(走流程的成本比改代码本身还高)、需要深度业务知识的场景(AI再怎么规范也替不了你的业务判断)。
如果想试一下,建议从brainstorming这一个skill开始。下次你有个新功能要做,不要直接让AI写代码,先说「帮我想想这个功能怎么做」。看看它问的问题、出的方案,跟你自己想的是不是有差距。你会很快感受到「先理清需求」和「直接动手」的区别。
Superpowers是一个开源的agentic skills框架,目前支持Claude Code、GitHub Copilot CLI、Gemini CLI、Cursor等主流AI编程工具。不同工具的安装方式略有不同——在Claude Code和Copilot CLI里通过插件市场安装,在Gemini CLI里通过扩展机制加载。安装后不需要额外配置,AI会自动根据任务匹配对应的skill。具体安装方式可以看GitHub上的文档,搜「superpowers obra」就能找到。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)